Locally Typical Sampling
Clara Meister1 Tiago Pimentel2 Gian Wiher1 Ryan Cotterell1,2
1ETH Z¨urich, Schweiz
2University of Cambridge, Vereinigtes Königreich
clara.meister@inf.ethz.ch tp472@cam.ac.uk
gian.wiher@inf.ethz.ch ryan.cotterell@inf.ethz.ch
Abstrakt
Today’s probabilistic language generators fall
short when it comes to producing coherent and
fluent text despite the fact that the underlying
models perform well under standard metrics
(z.B., perplexity). This discrepancy has puzzled
the language generation community for the last
ein paar Jahre. In this work, we posit that the ab-
straction of natural language generation as a
discrete stochastic process—which allows for
an information-theoretic analysis—can pro-
vide new insights into the behavior of probabi-
listic language generators, Zum Beispiel, Warum
high-probability texts can be dull or repetitive.
Humans use language as a means of com-
municating information, aiming to do so in a
simultaneously efficient and error-minimizing
manner;
in fact, psycholinguistics research
suggests humans choose each word in a string
with this subconscious goal in mind. We for-
mally define the set of strings that meet this
criterion: Those for which each word has an
information content close to the expected in-
the conditional
formation content, nämlich,
entropy of our model. We then propose a sim-
ple and efficient procedure for enforcing this
criterion when generating from probabilistic
Modelle, which we call locally typical sam-
pling. Automatic and human evaluations show
Das, in comparison to nucleus and top-k sam-
pling, locally typical sampling offers com-
petitive performance (in both abstractive
summarization and story generation) in terms
of quality while consistently reducing degen-
erate repetitions.
1
Einführung
ity is the choice of decoding strategy—that is,
the decision rule used to extract strings from a
Modell. Perhaps surprisingly, for many language
generation tasks, decoding strategies that aim to
find the highest-probability strings produce text
that is undesirable (Holtzman et al., 2020; Sehen
et al., 2019; Eikema and Aziz, 2020; Zhang
et al., 2021; DeLucia et al., 2021). Zum Beispiel,
Stahlberg and Byrne (2019) report that in their neu-
ral machine translation experiments, the highest-
probability string is usually the empty string. An
die andere Hand, stochastic strategies, which take
random samples from the model, often lead to text
with better qualitative properties (Fan et al., 2018;
Holtzman et al., 2020; Basu et al., 2021). Wie-
immer, stochastic strategies still have a host of other
problems, while not entirely dispensing with those
seen in maximization-based approaches.1
Es
is unintuitive that high-
probability strings are often neither desirable nor
human-like. Due to this pathology, a number of
studies have concluded that there must be faults
in the training objective or architecture of the
probabilistic models behind language generators
(Welleck et al., 2020; Guan et al., 2020; Li et al.,
2020, Unter anderem). Noch, this conclusion is at odds
with these models’ performance in terms of other
metrics. The fact that modern models can place
high probability on held-out text suggests that
they provide good estimates (in at least some as-
pects) of the probability distribution underlying
human language. We posit that looking at lan-
guage generation through an information-theoretic
lens may shed light on this paradox.
At first glance,
Modern probabilistic models have repeatedly
demonstrated their prowess at modeling natural
Sprache, placing high probability on held-out
corpora from many different domains (Braun
et al., 2020; Hoffmann et al., 2022; Chowdhery
et al., 2022). Yet when used as text generators,
their performance is far from perfect. One of the
largest determinants of the generated text’s qual-
Communication via natural language can in-
tuitively be cast in information-theoretic terms.
In der Tat, there is a long history of studying language
through the lens of information theory (Shannon,
1While maximization-based strategies can produce text
that is generic or degenerate, stochastic strategies occasion-
ally produce nonsensical text. Both types of strategies tend
to eventually fall into repetitive loops.
102
Transactions of the Association for Computational Linguistics, Bd. 11, S. 102–121, 2023. https://doi.org/10.1162/tacl a 00536
Action Editor: Ehud Reiter. Submission batch: 3/2022; Revision batch: 6/2022; Published 1/2023.
C(cid:2) 2023 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
1948, 1951; Hale, 2001; Piantadosi et al., 2011;
Pimentel et al., 2020, Unter anderem). In this para-
digm, linguistic strings are messages used to con-
vey information, and their information content
can be quantified as a function of their proba-
bility of being uttered—often driven by context.
Assuming that humans use language in order to
transmit information in an efficient yet robust
manner (Zaslavsky et al., 2018; Gibson et al.,
2019), the subset of strings typically used by hu-
mans should encode information at some (vielleicht
near-optimal) rate.2 In fact, prior works studying
the uniform information density hypothesis (Erheben
and Jaeger, 2007; Mahowald et al., 2013) empir-
ically observed this property in humans’ use of
natural language.
These insights lead us to re-think what it means
to be a probabilistic language generator. Erste, Wir
contend that language generators, in manchen Fällen,
can be thought of as discrete stochastic processes.
Das, im Gegenzug, allows us to cleanly define typicality
(and the typical set) for these processes. We ar-
gue, Jedoch, that due to discrepancies between
the model behind these generators and the true
distribution over natural language strings, directly
sampling from the typical set is not a good idea.
In der Tat, for language generators that do not use
an end-of-string (EOS) state, this is exactly what is
done by ancestral sampling—a decoding strategy
not known for providing high-quality text. In-
spired by research on human sentence processing,
we then define the more restrictive notion of local
typicality, and argue that if we want text generated
from a model to be ‘‘human-like,’’ we should per-
haps enforce this information-theoretic criterion
in generations ourselves. Zu diesem Zweck, we develop
a new algorithm, which we call locally typi-
cal sampling. Concretely, we hypothesize that
for text to be perceived as natural, each word
should have an information content close to its
expected information content given prior context.
When sampling from probabilistic language gen-
erators, we should limit our options to strings
that adhere to this property. In experiments on
abstractive summarization and story generation,
we observe that, compared to nucleus and top-k
sampling: (ich) locally typical sampling reduces the
number of degenerate repetitions, giving a REP
2Information rate may be defined with respect to time
(as is the case with spoken language) or with respect to
a specific linguistic unit, such as a word (as is the case
with text).
value (Welleck et al., 2020) on par with human
Text, Und (ii) text generated using typical sam-
pling is generally closer in quality to that of hu-
man text.3
2 Two Views of Language Modeling
In this work, we discuss language models4 in an
information-theoretic light. Our first step towards
this goal is to re-frame their presentation. Con-
cretely, we put forth that there are actually two
lenses through which we can view language mod-
eling productively. Under the traditional lens, Wir
can think of a language model as a distribution
over full strings: A language model constitutes
the distribution of a single string-valued random
Variable. Under an alternative lens, we can think
of a language model as a discrete stochastic pro-
Prozess: a collection of indexed random variables.
We compare and contrast these views formally,
and then show how to use the language process
view to derive a new sampling algorithm in §5.
2.1 A Single String-Valued
Random Variable
We codify the traditional view of language mod-
eling in the following definition. Let V be an
alphabet—a non-empty, finite set.
Definition 2.1 (Language Model). A language
model p is a probability distribution over all
strings y ∈ V ∗.5 Under this view, we can think
of a language model as describing a single V ∗-
valued random variable.
Under Definition 2.1, it is common to express a
language model in the following factorized form
P(y = y1 · · · yT ) =
T(cid:2)
t=1
P(yt | j
but out of convention, we take Yt for t ≤ 0 to be
BOS, d.h., conditioning p on just BOS signifies the
initial distribution of the process.
Definition 2.2 is very generic. In words, Es
just says that a language process is any discrete
process where we sample a new word9 given the
previously sampled words. The first question that
naturally comes to mind is when the definitions of
a language model and a language process coincide.
As it turns out, there is a simple answer.
Definition 2.3 (Tightness). Let Y = {Yt}∞
t=1
be a language process over alphabet V with dis-
6The ubiquity of Eq. (1) has led some authors to defining
language models in the locally normalized form, wenngleich
globally normalized language models are also perfectly fine
to consider (Goyal et al., 2019).
7Some authors erroneously omit EOS from their definition.
Jedoch, we require a distinguished symbol EOS to be able
to locally normalize the language model and make it a valid
probability distribution.
8This process is discrete both in time and in value.
9One could just as easily define a language process over
subwords, morphemes, or characters.
tribution p. A language process is tight (Booth
and Thompson, 1973) if and only if
(cid:3)
|j|(cid:2)
y∈(V ∗⊗{EOS})
t=1
P(Yt = yt | Y
this just says that we can always reach every word
in our alphabet via some path no matter where
we currently are. In our context, ergodicity also
relates to the problem with EOS. If we convert a lan-
guage model into a language process (as discussed
11Beachten Sie, dass, grundsätzlich, human language is not Markov,
in so far as many linguists believe human language is capa-
ble of arbitrarily deep center-embeddings (Chomsky, 1957,
1995). Yet research suggests that humans do not make use
of this property in practice (Reich, 1969; Karlsson, 2010),
and so we do not consider the Markovian property of most
models as a limitation to their ability to model natural lan-
guage in practice.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
in §2.1) and make the EOS state absorbing,12 Das
language process must be non-ergodic, as once it
encounters EOS, no other state is reachable.
2.4 Estimating a Language Model from Data
Language models are typically estimated from
language data. The standard method for estimating
the parameters of p is via maximization of the
log-likelihood of a training corpus S
L(θ; S) = −
(cid:3)
|j|(cid:3)
y∈S
t=1
log p(yt | j
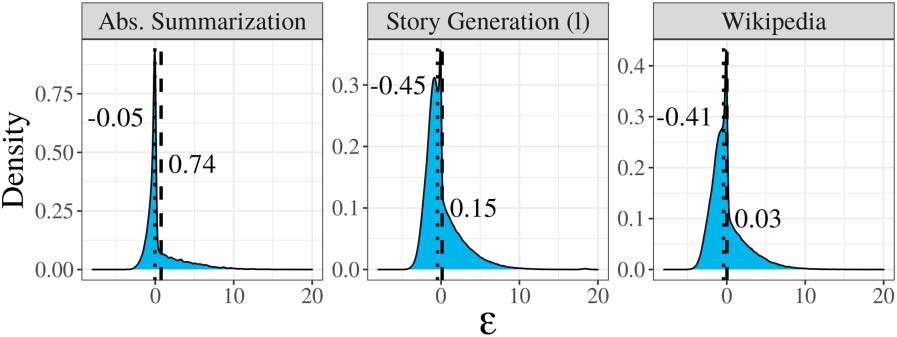
sufficiently large T , the following conditions hold:
(cid:4)
ich)
y∈T (T )
ε
P(j) > 1 − ε
ii) (1 − ε)2T (H(Y )−ε) ≤ |T (T )
ε
| ≤ 2T (H(Y )+ε)
12This would be done by setting the transition probability
P(Yt = EOS | Y
this means that we should expect every word
in natural-sounding sentences to be close to the
expected information content under ˜p, d.h., Die
conditional entropy given prior context.
ε
We verify this relationship empirically using
data from human language processes. In Abbildung 1,
we show the distribution of the difference between
the information content of yt and the expected
information content of Yt, nämlich, − log ˆp(yt |
j
114
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Prompt
Reference
Nucleus
η = 0.95
Top-k
k = 30
Temp
τ = 1.0
Mirostat
τ = 3
Typical
τ = 0.2
Story Generation (WritingPrompts)
A kid doodling in a math class accidentally creates the world’s first functional magic circle
in centuries.
It was dark and Levi was pretty sure he was lying on his back. There was firelight flickering
off of what was left of a ceiling. He could hear something but it was muffled. He was almost
positive it was screaming. When he tried to move he felt an excruciating pain in his left side
that caused him to cry out…
‘‘Why do you draw a circle?’’ He asked as he handed the piece of paper over to her. Sie
rolled her eyes and looked down at the picture, ‘‘Because I like math!’’ ‘‘Then what?’’ ‘‘I like
to draw the circles.’’ She ran a hand through her curls and looked away. ‘‘See, I have three
circles.’’ ‘‘Hmph, I didn’t think I saw that in your class.’’ A younger student brought up the
ceiling and murmured…
‘‘Aha. Aah! That makes three.’’ Professor Gosh sighed. ‘‘Oh my God, you had to have been
there.’’ ‘‘Well, I’m not sure if that’s the right term, but this circle is going to work.’’ ‘‘But I
just told you that it wasn’t working, didn’t you, you little sh**? I’m not kidding! That circle
is gon na work!’’ ‘‘So what now?’’…
It was teachers duty to ensure that our kingdom is pure and pure and successful, however it
does not mean we do not try to be as rebellious as any other kingdom. Most of our teachers
are suitable for rulership, being knowledgeable in sadistic rec thunking of time stopping
magic circle created by several apprentices…
ready to go home, when a little kid starts to sketch a circle. ‘‘No. Just stop. It’s not working.’’
‘‘But the circle turns to smoke and then to a flame. It’s not working, I know it is!’’ Another
kid, who was also drawing a circle with his phone, starts to scream. The teacher, looking at
the circle, lost his patience and started to yell…
As soon as he got the clock on his desk he jumped up. The noise it was making had changed
his day forever. His hair, normally unkempt, now glistened and he had to have more hair
because of it. ‘‘Yes!’’ He had declared triumphantly as he watched his father fumble around
in the backpack in search of a little compass he always kept with him. He took it from the
desk and quickly walked out the door to see what had happened. He wasn’t the first child in
the world to draw something…
Tisch 4: Sample generations for story generation from GPT-2 large finetuned on the WRITINGPROMPTS
dataset; examples correspond to ID 1 in the test set. Decoding strategy hyperparameters are chosen
based off of best performance in human evaluations shown in Table 1.
Another ethical consideration worth discussing
concerns the use of language models for text gen-
eration. Text generated by these models may con-
tain malicious content, either by design of the user
or as a byproduct of the training data/algorithm.
While we hope the results of our work will not be
misused, they may nonetheless provide insights
for those employing these models with ill-intent
as to how machine-generated text can be made
more ‘‘human-like,’’ and thus more convincing.
115
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
A Additional Results
Decoder
Reference
Beam (k=5)
Story Generation (l)
Story Generation (M)
Coherence
4.36 (±0.31)
−
Fluency
4.25 (±0.23)
−
Interestingness Coherence
4.02 (±0.27)
−
4.56 (±0.25)
−
Fluency
4.2 (±0.27)
−
Interestingness
4.15 (±0.2)
−
Summarization
Fluency
4.43 (±0.25)
4.47 (±0.24)
Relevance
4.18 (±0.27)
4.23 (±0.28)
Temperature (τ =0.9)
4.32 (±0.25)
4.16 (±0.19)
4.47 (±0.27)
4.02 (±0.22)
4.26 (±0.29)
4.19 (±0.24)
4.36 (±0.25)
4.13 (±0.26)
Temperature (τ =1)
4.36 (±0.28)
4.25 (±0.22)
4.47 (±0.30)
4.02 (±0.32)
4.2 (±0.29)
4.18 (±0.22)
4.42 (±0.26)
4.15 (±0.28)
Nucleus (η=0.9)
4.32 (±0.25)
4.28 (±0.24)
4.48 (±0.31)
3.99 (±0.27)
4.16 (±0.32)
4.13 (±0.21)
4.39 (±0.27)
4.13 (±0.3)
Nucleus (η=0.95)
4.3 (±0.28)
4.28 (±0.29)
4.49 (±0.26)
4.00 (±0.19)
4.24 (±0.35)
4.14 (±0.17)
4.44 (±0.26)
4.08 (±0.29)
Top-k (k=30)
Top-k (k=40)
Mirostat (τ =3)
Typical (τ =0.2)
4.35 (±0.25)
4.21 (±0.24)
4.53 (±0.27)
4.03 (±0.24)
4.2 (±0.3)
4.16 (±0.22)
4.44 (±0.24)
4.18 (±0.26)
4.34 (±0.27)
4.24 (±0.23)
4.53 (±0.25)
4.00 (±0.27)
4.17 (±0.31)
4.11 (±0.18)
4.39 (±0.27)
4.26 (±0.23)
4.55 (±0.27)
4.02 (±0.22)
4.16 (±0.32)
4.17 (±0.22)
4.41 (±0.25)
−
4.17 (±0.33)
−
4.36 (±0.29)
4.24 (±0.24)
4.55 (±0.25)
4.07 (±0.26)
4.23 (±0.32)
4.14 (±0.26)
4.37 (±0.28)
4.16 (±0.29)
Typical (τ =0.95)
4.35 (±0.28)
4.24 (±0.23)
4.53 (±0.26)
4.04 (±0.21)
4.18 (±0.31)
4.18 (±0.22)
4.42 (±0.28)
4.22 (±0.27)
Tisch 5: Breakdown of human ratings on quality metrics per task; results for story generation are from
finetuned versions of GPT-2 medium (M) and large (l). Values in blue are variances.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
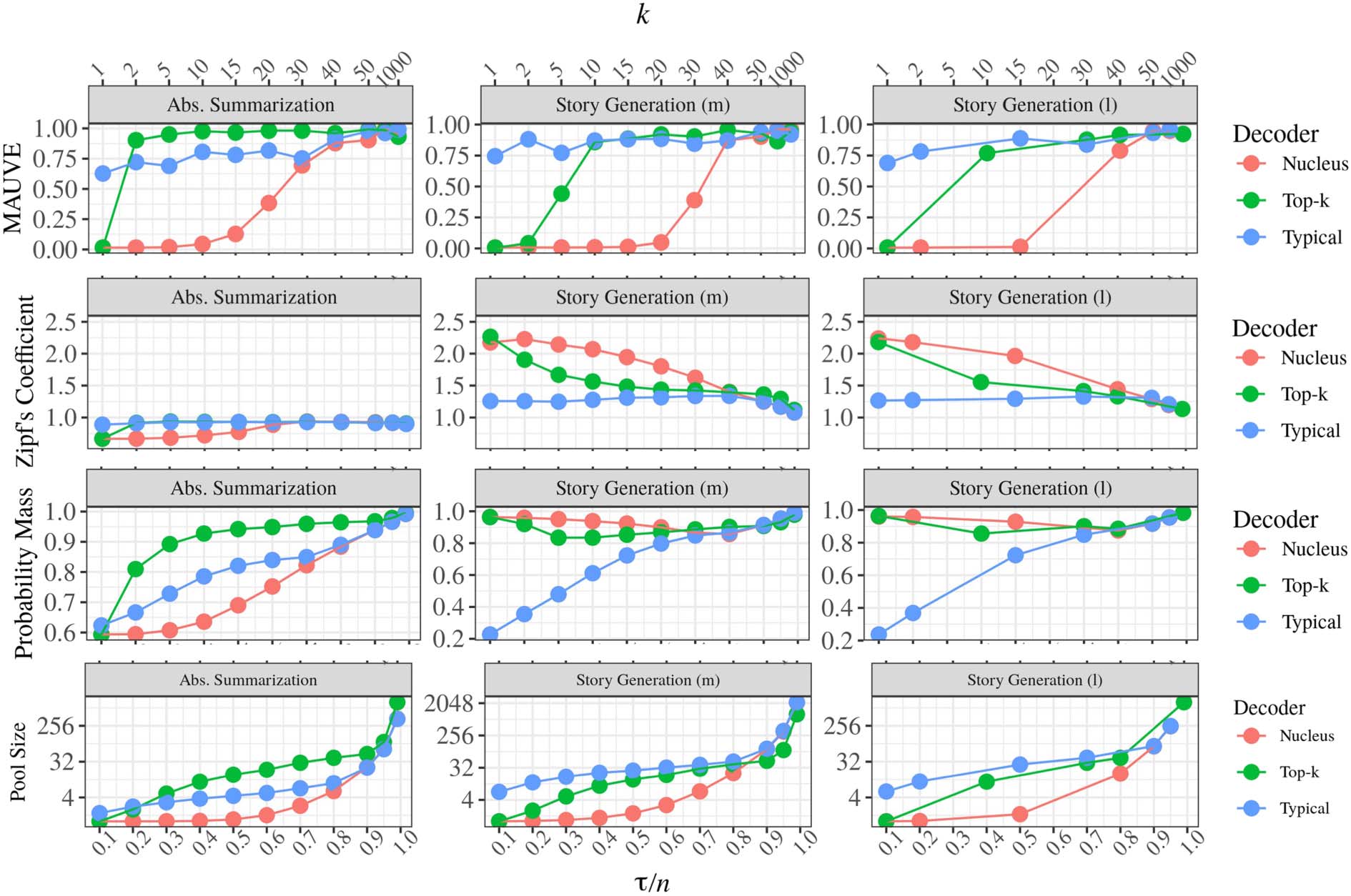
Figur 3: MAUVE, Zipf’s coefficient, (average) probability mass of candidate token pool, Und (average)
candidate token pool size as a function of decoder hyperparameters for nucleus, top-k, and locally
typical sampling.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
116
Verweise
Matthew Aylett and Alice Turk. 2004. Der
smooth signal redundancy hypothesis: A func-
tional explanation for relationships between re-
dundancy, prosodic prominence, and duration
in spontaneous speech. Language and Speech,
47(1):31–56. https://doi.org/10.1177
/00238309040470010201, PubMed: 15298329
Sourya
Basu, Govardana
Sachitanandam
Ramachandran, Nitish Shirish Keskar, Und
Lav R. Varshney. 2021. Mirostat: A perplexity-
controlled neural text decoding algorithm. In
Proceedings of the 9th International Confer-
ence on Learning Representations.
Taylor L. Booth and Richard A. Thompson.
1973. Applying probability measures to abstract
languages. IEEE Transactions on Computers,
C-22(5):442–450. https://doi.org/10
.1109/T-C.1973.223746
Mark Braverman, Xinyi Chen, Sham Kakade,
Karthik Narasimhan, Cyril Zhang, and Yi
Zhang. 2020. Calibration, entropy rates, Und
memory in language models. In Proceedings
of the 37th International Conference on Ma-
chine Learning, Volumen 119, pages 1089–1099.
PMLR.
Leo Breiman. 1957. The individual ergodic theo-
rem of information theory. The Annals of Math-
ematical Statistics, 28(3):809–811. https://
doi.org/10.1214/aoms/1177706899
Tom Brown, Benjamin Mann, Nick Ryder,
Melanie Subbiah, Jared D. Kaplan, Prafulla
Dhariwal, Arvind Neelakantan, Pranav Shyam,
Girish Sastry, Amanda Askell, Sandhini
Agarwal, Ariel Herbert-Voss, Gretchen Krueger,
Tom Henighan, Rewon Child, Aditya Ramesh,
Daniel Ziegler, Jeffrey Wu, Clemens Winter,
Chris Hesse, Mark Chen, Eric Sigler, Mateusz
Litwin, Scott Gray, Benjamin Chess, Jack
Clark, Christopher Berner, Sam McCandlish,
Alec Radford,
Ilya Sutskever, and Dario
Amodei. 2020. Language models are few-
In-
shot
formation Processing Systems, Volumen 33,
pages 1877–1901. Curran Associates, Inc.
In Advances in Neural
learners.
Noam Chomsky. 1957. Syntactic Structures.
Mouton and Co., Den Haag. https://doi
.org/10.1515/9783112316009
117
Noam Chomsky. 1995. The Minimalist Program.
MIT Press, Cambridge, MA.
Aakanksha Chowdhery, Sharan Narang, Jacob
Devlin, Maarten Bosma, Gaurav Mishra, Adam
Roberts, Paul Barham, Hyung Won Chung,
Charles Sutton, Sebastian Gehrmann, Parker
Schuh, Kensen Shi, Sasha Tsvyashchenko,
Joshua Maynez, Abhishek Rao, Parker
Barnes, Yi Tay, Noam Shazeer, Vinodkumar
Prabhakaran, Emily Reif, Nan Du, Ben
Hutchinson, Reiner Pope, James Bradbury,
Jacob Austin, Michael Isard, Guy Gur-Ari,
Pengcheng Yin, Toju Duke, Anselm Levskaya,
Sanjay Ghemawat, Sunipa Dev, Henryk
Michalewski, Xavier Garcia, Vedant Misra,
Kevin Robinson, Liam Fedus, Denny Zhou,
Daphne Ippolito, David Luan, Hyeontaek Lim,
Barret Zoph, Alexander Spiridonov, Ryan
Sepassi, David Dohan, Shivani Agrawal, Markieren
Omernick, Andrew M. Dai, Thanumalayan
Sankaranarayana Pillai, Marie Pellat, Aitor
Lewkowycz, Erica Moreira, Rewon Child,
Oleksandr Polozov, Katherine Lee, Zongwei
Zhou, Xuezhi Wang, Brennan Saeta, Markieren
Diaz, Orhan Firat, Michele Catasta, Jason
Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff
Dean, Slav Petrov, and Noah Fiedel. 2022.
PaLM: Scaling language modeling with path-
ways. CoRR, abs/2204.02311.
Christophe Coup´e, Yoon Mi Oh, Dan Dediu,
and Franc¸ois Pellegrino. 2019. Different lan-
guages, similar encoding efficiency: Com-
parable information rates across the human
communicative niche. Science Advances, 5(9).
https://doi.org/10.1126/sciadv.aaw2594,
PubMed: 32047854
Thomas M. Cover and Joy A. Thomas. 2012.
Elements of Information Theory. John Wiley
& Sons.
Alexandra DeLucia, Aaron Mueller, Xiang Lisa
Li, and Jo˜ao Sedoc. 2021. Decoding methods
for neural narrative generation. In Proceedings
of the 1st Workshop on Natural Language Gen-
eration, Evaluation, and Metrics (GEM 2021),
pages 166–185, Online. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2021.gem-1.16
Sander Dieleman. 2020. Musings on typicality.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Sergey Edunov, Myle Ott, Michael Auli, Und
David Grangier. 2018. Understanding back-
translation at scale. In Proceedings of
Die
2018 Conference on Empirical Methods in
Natural Language Processing, pages 489–500,
Brussels, Belgien. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D18-1045
Bryan Eikema and Wilker Aziz. 2020. Is MAP
decoding all you need? The inadequacy of
the mode in neural machine translation. In
Proceedings of the 28th International Confer-
ence on Computational Linguistics, COLING,
pages 4506–4520, Barcelona, Spanien (Online).
International Committee on Computational Lin-
guistics. https://doi.org/10.18653/v1
/2020.coling-main.398
Angela Fan, Mike Lewis, and Yann Dauphin.
2018. Hierarchical neural story generation. In
Proceedings of the 56th Annual Meeting of
the Association for Computational Linguis-
Tics (Volumen 1: Long Papers), pages 889–898,
Melbourne, Australia. Association for Compu-
tational Linguistics.
August Fenk and Gertraud Fenk. 1980. Konstanz
im Kurzzeitged¨achtnis-Konstanz im sprach-
f¨ur ex-
lichen Informationsfluß. Zeitschrift
perimentelle und angewandte Psychologie,
27(3):400–414.
Edward Gibson, Richard Futrell, Steven T.
Piantadosi, Isabelle Dautriche, Kyle Mahowald,
Leon Bergen, and Roger Levy. 2019. Wie
efficiency shapes human language. Trends in
Cognitive Sciences, 23(5):389–407. https://
doi.org/10.1016/j.tics.2019.02.003,
PubMed: 31006626
Kartik Goyal, Chris Dyer, and Taylor Berg-
Kirkpatrick. 2019. An empirical investigation
of global and local normalization for recur-
rent neural sequence models using a continu-
ous relaxation to beam search. In Proceedings
of the 2019 Conference of the North American
Chapter of
the Association for Computa-
tional Linguistics: Human Language Tech-
nologies, Volumen 1 (Long and Short Papers),
pages 1724–1733, Minneapolis, Minnesota.
Verein für Computerlinguistik.
Jian Guan, Fei Huang, Zhihao Zhao, Xiaoyan
Zhu, and Minlie Huang. 2020. A knowledge-
enhanced pretraining model for commonsense
story generation. Transactions of the Associa-
tion for Computational Linguistics, 8:93–108.
John Hale. 2001. A probabilistic Earley parser
as a psycholinguistic model. In Second Meet-
Die
ing of
Verein für Computerlinguistik.
https://doi.org/10.3115/1073336
.1073357
the North American Chapter of
Jordan Hoffmann, Sebastian Borgeaud, Arthur
Mensch, Elena Buchatskaya, Trevor Cai, Eliza
Rutherford, Diego de Las Casas, Lisa Anne
Hendricks, Johannes Welbl, Aidan Clark, Tom
Hennigan, Eric Noland, Katie Millican, George
van den Driessche, Bogdan Damoc, Aurelia
Guy, Simon Osindero, Karen Simonyan, Erich
Elsen, Jack W. Rae, Oriol Vinyals, and Laurent
Sifre. 2022. Training compute-optimal large
language models. CoRR, abs/2203.15556.
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes,
and Yejin Choi. 2020. The curious case of
text degeneration. In Proceedings of
neural
the 8th International Conference on Learning
Darstellungen.
Fred Karlsson.
2010.
3. Syntactic
recur-
In Recursion and Hu-
sion and iteration.
man Language. De Gruyter Mouton, Berlin,
New York. https://doi.org/10.1515
/9783110219258.43
Urvashi Khandelwal, He He, Peng Qi, and Dan
Jurafsky. 2018. Sharp nearby, fuzzy far away:
How neural language models use context. In
Proceedings of the 56th Annual Meeting of
the Association for Computational Linguis-
Tics (Volumen 1: Long Papers), pages 284–294,
Melbourne, Australia. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/P18-1027
Konrad Knopp. 1954. Theory and Application of
Infinite Series. London, Blackie & Son Ltd.
Jey Han Lau, Alexander Clark, and Shalom
Lappin. 2017. Grammaticality, acceptabil-
ität, and probability: A probabilistic view
of linguistic knowledge. Cognitive Science,
41(5):1202–1241. https://doi.org/10
.1111/cogs.12414, PubMed: 27732744
Roger Levy and T. Florian Jaeger. 2007. Speakers
optimize information density through syntactic
118
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
reduction. In Advances in Neural Information
Processing Systems, Volumen 19. MIT Press.
https://doi.org/10.18653/v1/2020
.acl-main.615
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Erheben, Veselin Stoyanov, and Luke Zettlemoyer.
2020. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
Übersetzung, and comprehension. In Proceed-
Die
ings of
Verein für Computerlinguistik,
pages 7871–7880, Online. Association for
Computerlinguistik. https://doi.org
/10.18653/v1/2020.acl-main.703
the 58th Annual Meeting of
Jiwei Li, Michel Galley, Chris Brockett,
Jianfeng Gao, and Bill Dolan. 2016. A
diversity-promoting objective function for neu-
ral conversation models. In Proceedings of
Die 2016 Conference of the North American
Chapter of the Association for Computational
Linguistik: Human Language Technologies,
pages 110–119, San Diego, Kalifornien. Associ-
ation for Computational Linguistics.
Margaret Li, Stephen Roller, Ilia Kulikov, Sean
Welleck, Y-Lan Boureau, Kyunghyun Cho, Und
Jason Weston. 2020. Don’t say that! Making
inconsistent dialogue unlikely with unlikeli-
hood training. In Proceedings of
the 58th
Annual Meeting of the Association for Compu-
tational Linguistics, pages 4715–4728, Online.
Verein für Computerlinguistik.
Kyle Mahowald, Evelina Fedorenko, Steven
T. Piantadosi, and Edward Gibson. 2013.
wählen
Info/information theory: Speakers
shorter words in predictive contexts. Cogni-
tion, 126(2):313–318. https://doi.org/10
.1016/j.cognition.2012.09.010, PubMed:
23116925
Brockway McMillan. 1953. The basic theorems
of information theory. The Annals of Mathe-
matical Statistics, 24(2):196–219. https://
doi.org/10.1214/aoms/1177729028
Clara Meister, Elizabeth Salesky, and Ryan
Cotterell. 2020A. Generalized entropy regular-
ization or: There’s nothing special about label
smoothing. In Proceedings of the 58th An-
nual Meeting of the Association for Computa-
tional Linguistics, pages 6870–6886, Online.
Verein für Computerlinguistik.
Clara Meister, Tim Vieira, and Ryan Cotterell.
2020B. If beam search is the answer, what
was the question? In Proceedings of the 2020
Conference on Empirical Methods in Natural
Language Processing, Online. Association for
Computerlinguistik. https://doi.org
/10.18653/v1/2020.emnlp-main.170
Clara Meister, Gian Wiher, Tiago Pimentel,
and Ryan Cotterell. 2022. On the probability–
quality paradox in language generation. In Pro-
ceedings of the 60th Annual Meeting of the
Verein für Computerlinguistik (Bd-
ume 2: Short Papers), pages 36–45, Dublin,
Ireland. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2022.acl-short.5
Stephen Merity, Caiming Xiong,
James
Bradbury, and Richard Socher. 2017. Pointer
sentinel mixture models. In Proceedings of
the 5th International Conference on Learning
Darstellungen.
the 1st Conference of
Moin Nadeem, Tianxing He, Kyunghyun Cho,
and James Glass. 2020. A systematic char-
acterization of sampling algorithms for open-
ended language generation. In Proceedings
von
the Asia-Pacific
Chapter of the Association for Computational
Linguistics and the 10th International Joint
Conference on Natural Language Processing,
pages 334–346, Suzhou, China. Association
für Computerlinguistik.
Ramesh Nallapati, Bowen Zhou, Cicero dos
Santos, Caglar Gulc¸ehre, and Bing Xiang.
2016. Abstractive text summarization using
sequence-to-sequence RNNs and beyond. In
Proceedings of The 20th SIGNLL Conference
on Computational Natural Language Learning,
pages 280–290, Berlin, Deutschland. Association
für Computerlinguistik. https://doi
.org/10.18653/v1/K16-1028
Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott,
Michael Auli, and Sergey Edunov. 2019. Face-
book FAIR’s WMT19 news translation task
Vorlage. In Proceedings of the Fourth Con-
ference on Machine Translation (Volumen 2:
Shared Task Papers, Day 1), pages 314–319,
119
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Florence, Italien. Association for Computational
Linguistik.
Gabriel Pereyra, George Tucker, Jan Chorowski,
Łukasz Kaiser, and Geoffrey E. Hinton. 2017.
Regularizing neural networks by penalizing
confident output distributions. In Proceedings
of the 5th International Conference on Learn-
ing Representations.
Steven T. Piantadosi, Harry Tily, and Edward
Gibson. 2011. Word lengths are optimized for
efficient communication. Proceedings of the Na-
tional Academy of Sciences, 108(9):3526–3529.
https://doi.org/10.1073/pnas.1012551108,
PubMed: 21278332
Krishna Pillutla, Swabha Swayamdipta, Rowan
Zellers, John Thickstun, Sean Welleck, Yejin
Choi, and Zaid Harchaoui. 2021. MAUVE:
Measuring the gap between neural text and
In
human text using divergence frontiers.
Advances in Neural Information Processing
Systeme, Volumen 34, pages 4816–4828. Curran
Associates, Inc.
Tiago Pimentel, Clara Meister,
and Ryan
Cotterell. 2022. Cluster-based evaluation of
automatically generated text. arXiv preprint
arXiv:2205.16001.
Tiago Pimentel, Clara Meister, Elizabeth Salesky,
Simone Teufel, Dami´an Blasi, and Ryan
Cotterell. 2021. A surprisal–duration trade-off
across and within the world’s languages. In
Verfahren der 2021 Conference on Em-
pirical Methods in Natural Language Process-
ing, pages 949–962, Online and Punta Cana,
Dominican Republic. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/2021.emnlp-main.73
Tiago Pimentel, Brian Roark,
and Ryan
Cotterell. 2020. Phonotactic complexity and its
trade-offs. Transactions of the Association for
Computerlinguistik, 8:1–18. https://
doi.org/10.1162/tacl a 00296
Alec Radford, Jeffrey Wu, Rewon Child, David
Luan, Dario Amodei, and Ilya Sutskever.
2019. Language models are unsupervised mul-
titask learners.
Peter A. Reich. 1969. Der
finiteness of
Sprache. Language, 45(4):831–843.
natürlich
https://doi.org/10.2307/412337
Carson T. Sch¨utze. 2016. The empirical base of
linguistics: Grammaticality judgments and lin-
guistic methodology. Classics in Linguistics 2.
Language Science Press, Berlin. https://
doi.org/10.26530/OAPEN 603356
Abigail See, Aneesh Pappu, Rohun Saxena,
Akhila Yerukola, and Christopher D. Manning.
2019. Do massively pretrained language mod-
els make better storytellers? In Proceedings of
the 23rd Conference on Computational Natural
Language Learning (CoNLL), pages 843–861,
Hongkong, China. Association for Computa-
tional Linguistics.
Claude E. Shannon. 1948. A mathematical the-
ory of communication. Bell System Technical
Zeitschrift, 27:623–656.
Claude E. Shannon. 1951. Prediction and en-
tropy of printed English. Bell System Technical
Zeitschrift, 30(1):50–64. https://doi.org/10
.1002/j.1538-7305.1951.tb01366.x
Felix Stahlberg and Bill Byrne. 2019. On NMT
search errors and model errors: Cat got your
tongue? In Proceedings of
Die 2019 Con-
ference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
Abschließen (EMNLP-IJCNLP), pages 3356–3362,
Hongkong, China. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D19-1331
Chris van der Lee, Albert Gatt, Emiel van
Miltenburg, Sander Wubben,
and Emiel
Krahmer. 2019. Best practices for the hu-
man evaluation of automatically generated
Text. In Proceedings of the 12th International
Conference on Natural Language Generation,
pages 355–368, Tokio, Japan. Association for
Computerlinguistik. https://doi
.org/10.18653/v1/W19-8643
Sean Welleck, Ilia Kulikov, Stephen Roller, Emily
Dinan, Kyunghyun Cho, and Jason Weston.
2020. Neural text generation with unlikelihood
Ausbildung. In Proceedings of the 8th International
Conference on Learning Representations.
Thomas Wolf, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue, Anthony
Moi, Pierric Cistac, Tim Rault, R´emi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
120
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao,
Sylvain Gugger, Mariama Drame, Quentin
Lhoest,
and Alexander M. Rush. 2020.
Transformers: State-of-the-art natural language
Verarbeitung. In Proceedings of the 2020 Con-
ference on Empirical Methods in Natural
Language Processing: Systemdemonstrationen,
pages 38–45, Online. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/2020.emnlp-demos.6
Yonghui Wu, Mike Schuster, Zhifeng Chen,
Quoc V. Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin Gao,
Klaus Macherey, Jeff Klingner, Apurva Shah,
Melvin Johnson, Xiaobing Liu, Lukasz Kaiser,
Stephan Gouws, Yoshikiyo Kato, Taku Kudo,
Hideto Kazawa, Keith Stevens, George Kurian,
Nishant Patil, Wei Wang, Cliff Young, Jason
Schmied, Jason Riesa, Alex Rudnick, Oriol
Vinyals, Gregory S. Corrado, Macduff Hughes,
and Jeffrey Dean. 2016. Google’s neural ma-
chine translation system: Bridging the gap
between human and machine translation.
CoRR, abs/1609.08144.
Noga Zaslavsky, Charles Kemp, Terry Regier, Und
Naftali Tishby. 2018. Efficient compression
in color naming and its evolution. Proceed-
ings of
the National Academy of Sciences,
115(31):7937–7942. https://doi.org/10
.1073/pnas.1800521115, PubMed: 30021851
Hugh Zhang, Daniel Duckworth, Daphne
Ippolito, and Arvind Neelakantan. 2021. Trad-
ing off diversity and quality in natural language
Generation. In Proceedings of the Workshop
on Human Evaluation of NLP Systems (Hum-
Eval), pages 25–33, Online. Association for
Computerlinguistik.
George Kingsley Zipf. 1949. Human Behavior
and the Principle of Least Effort. Addison-
Wesley Press, Oxford, Vereinigtes Königreich.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
3
6
2
0
6
7
8
6
5
/
/
T
l
A
C
_
A
_
0
0
5
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
121