g e n eR Al AR T Ic l e
a neural network looks at
leonardo’s(?) Salvator Mundi
stEvEn J . F r a n k An d anDrEa m. F r a n k
T
C
A
R
T
S
B
A
The authors use convolutional neural networks (CNNs) to analyze
authorship questions surrounding the works of Leonardo da Vinci—in
besondere, Salvator Mundi, the world’s most expensive painting and
among the most controversial. Trained on the works of an artist under
study and visually comparable works of other artists, the authors’ system
can identify likely forgeries and shed light on attribution controversies.
Leonardo’s few extant paintings test the limits of the system and require
corroborative techniques of testing and analysis.
The paintings of Leonardo da Vinci (1452–1519) represent a
particularly challenging body of work for any attribution ef-
fort, human or computational. Exalted as the canonical Re-
naissance genius and polymath, Leonardo had imagination
and drafting skills that brought extraordinary success to his
many endeavors—from painting, sculpture and drawing to
astronomy, botany and engineering. His pursuit of perfec-
tion ensured the quality, but also the small quantity, of his
finished paintings. Experts have identified fewer than 20 bei-
tributable in whole or in large part to him. For the connois-
seur or scholar, this narrow body of work severely restricts
analysis based on signature stylistic expressions or working
Methoden [1]. For automated analysis using data-hungry con-
volutional neural networks (CNNs), this paucity of images
tests the limits of a “deep learning” methodology.
Our approach to analysis is based on the concept of im-
age entropy, which corresponds roughly to visual diversity.
While simple geometric shapes have low image entropy, Das
of a typical painting is dramatically higher. Our system di-
vides an image into tiled segments and examines the visual
entropy of each tile. Only those tiles whose entropies at least
match that of the source image are used for training and test-
ing. The benefit of what we call our “Salient Slices” approach
[2] is twofold. The tiles—unlike the high-resolution source
Steven J. Frank (cofounder), Art Eye-D Associates LLC, 779 Salem End Road,
Framingham, MA 01702, USA. Email: steve@art-eye-d.com.
Andrea M. Frank (cofounder), Art Eye-D Associates LLC, 779 Salem End Road,
Framingham, MA 01702, USA. Email: andrea@art-eye-d.com.
Siehe https://direct.mit.edu/leon/issue/54/6 for supplemental files associated
mit diesem Problem.
images they represent—are small enough to be processed
by conventional CNNs. Darüber hinaus, a single high-resolution
image can yield hundreds of usable tiles, making it possible
to successfully train a CNN even when the number of source
images is limited.
We successfully developed and trained CNN models ca-
pable of reliably distinguishing the portraits of Rembrandt
Harmenszoon van Rijn (1606–1669) and landscape paintings
by Vincent Willem van Gogh (1853–1890) from the work of
forgers, students and close imitators. Leonardo’s paintings,
Jedoch, besides being few in number, are of mixed genre
and subject to varying degrees of authentication controversy.
They are also enormously valuable and often hauntingly
beautiful. Grappling with this work revealed capabilities we
doubted our system possessed and led us to techniques of
data augmentation and handling whose success surprised us.
lEonarDo’s p aIntIngs
Leonardo’s subjects include portraits and a variety of reli-
gious subjects. His religious paintings subdivide into several
different pictorial genres—intimate representations of the
Madonna and Child, portrait-like representations of John the
Baptist (Saint John the Baptist, 1513–1516; Louvre) and Christ
(Salvator Mundi, date and current location unknown) sowie
as wider-scale scenes with numerous figures and landscape
Elemente. Just the variety of subject matter posed formida-
ble challenges because our experience with Rembrandt and
van Gogh demonstrated that a model trained in one genre
can fail spectacularly in another: Our Rembrandt portrait
models misclassified his religious scenes and our van Gogh
landscape models could not distinguish between a genuine
self-portrait and a forgery. To have any chance of success,
Dann, a training set utilizing the few confirmed autograph
works of Leonardo would require a comparative set of works
diverse not only in artists (to promote generalization beyond
the training set) but also in genre (to span Leonardo’s subject
matter)—in other words, a comparative training set far larger
than the set of Leonardo paintings. Such deliberate lack of
balance risked a bias toward false negatives [3].
©2021 ISAST
https://doi.org/10.1162/leon_a_02004
LEONARDO, Bd. 54, NEIN. 6, S. 619–624, 2021 619
Von http heruntergeladen://direct.mit.edu/leon/article-pdf/54/6/619/2028761/leon_a_02004.pdf by guest on 07 September 2023
A
B
Feige. 1. Leonardo, Salvator Mundi. (A) prior to restoration. (B) In 2017 when sold at Christie’s, New York, after restoration. (Public domain)
Like Rembrandt, Leonardo ran an extensive studio, em-
ploying assistants and teaching students. If anything, Die
contributions made by these associates to the works of the
master is even less well understood than for Rembrandt and
potentially more significant in many cases, leading to an
entire category of “apocryphal” Leonardo works. Even for
works that appear to have a single author, experts routinely
question whether that author is Leonardo. Excluding all
paintings whose attributions to Leonardo have been cred-
ibly questioned would leave fewer than half a dozen images
for both training and testing.
Yet a further complication is the current state of some
Leonardo works. The most definitive provenance is that of
The Last Supper (C. 1490S; convent of Santa Maria delle Gra-
zie, Milan), an enormous mural that began to deteriorate
shortly after its completion and that is now far too damaged
to serve as a training image. Restoration efforts that have
been made over the centuries have sometimes involved sig-
nificant repainting. The recent and highly publicized con-
troversy surrounding Salvator Mundi, the world’s most
expensive painting, is another case in point. Once presumed
to be a later copy of a lost original, the panel was purchased
In 2005 and restored by the eminent conservator Dianne
Modestini. Although the degree of restoration was consid-
erable, Leonardo’s sfumato technique is evident throughout
the painting (Feige. 1).
Since then, it has gained some scholarly acceptance as
Leonardo’s original [4,5] or as partially by Leonardo [6],
while others reject the attribution entirely [7]. If we could
overcome the considerable technical challenges described
above and manage the irreducible authorship uncertainties
surrounding Leonardo’s work, we might be able to contribute
to the discussion as well as explore the effects of restoration
on our CNN’s performance.
mEthoDology
Our first task would be to assemble all finished paintings
at least arguably attributable to Leonardo and assess the
strengths of their attributions. Based on this assessment, Wir
would need a strategy for assessing classification accuracy
by reserving for testing the smallest possible number of Leo-
nardo works in order to maximize the size of the Leonardo
training set. To complete the training set, we would need
comparative works by many artists portraying subject matter
similar to our Leonardo training images and with varying
degrees of pictorial similarity to those images; and somehow,
in the end, we would have to wind up with Leonardo and
non-Leonardo training tiles roughly equal in number and
also sufficiently numerous to support reliable training.
Tisch 1 summarizes the works we used, their subject mat-
ter, the certainty of attribution and the use to which we put
tiles derived from the image.
We chose La Belle Ferronnière as a test image due to its
visual similarity to Lady with an Ermine, so its absence from
the training set would have a smaller impact than sacrific-
ing a more distinctive image. La Bella Principessa may seem
an unlikely candidate for a test image: It is a chalk drawing
rather than a painting and its attribution is uncertain. Noch
620 Frank and Frank, A Neural Network Looks at Leonardo’s(?) Salvator Mundi
Von http heruntergeladen://direct.mit.edu/leon/article-pdf/54/6/619/2028761/leon_a_02004.pdf by guest on 07 September 2023
tablE 1. Funktioniert, attribution status and use in study
title (Jahr)
subject matter
attribution status
Mona Lisa (1503–1506)
Portrait
Substantially unquestioned
The Annunciation (1472)
Religious scene, multiple figures
and landscape
Substantially unquestioned
use
Training
Training
The Baptism of Christ
(1470–1480)
Portrait (one angel painted by
Leonardo)
Generally unquestioned
Training (using isolated
Leonardo angel)
Madonna of the Carnation (1478)
Madonna and child
Substantially unquestioned, möglicherweise
with some overpainting
Ginevra de’ Benci (1474–1478)
Portrait
Generally unquestioned
Benois Madonna (1478)
Madonna and child
Generally unquestioned
Virgin of the Rocks (Louvre version)
(1483–1486)
Religious scene, multiple figures
and landscape
Substantially unquestioned
Training
Training
Training
Training
Lady with an Ermine (portrait of
Cecilia Gallerani) (1490)
Portrait
Generally unquestioned
Training
The Virgin and Child with Saint
Anne (1503)
Religious scene, multiple figures
and landscape
Substantially unquestioned
Training
Saint John the Baptist
(1513–1516)
Religious scene, single figure
Generally unquestioned
Training
Portrait of a Musician (1490)
Portrait
Generally unquestioned
Virgin of the Rocks (London
Ausführung) (1491–1508)
Religious scene, multiple figures
and landscape
Generally unquestioned
La Bella Principessa (1495–1496)
Portrait
Questioned
La Belle Ferronnière (1490–1497)
Portrait
Generally unquestioned
Madonna Litta (mid-1490s)
Madonna and child
Isleworth Mona Lisa (1508–1516)
Portrait
Questioned
Questioned
Seated Bacchus (1510–1515)
Religious (Genre) scene, single
figure
Workshop of Leonardo
Training
Training
Test
Test
Comparative
Comparative
Comparative
all models that successfully classified both La Belle Ferron-
nière and a large proportion of the non-Leonardo images also
invariably classified La Bella Principessa as the work of Leo-
nardo with high probability. Vor allem, swapping it for Portrait
of a Musician in the training set adversely affected model
Leistung. Clearly the strength of a classification does not
guarantee that the image will contribute positively to train-
ing; the effect of the internal CNN weights on a test image to
produce a classification, mit anderen Worten, is not the same as the
influence of the image on the CNN weights during training.
Confining our Leonardo training set to works whose at-
tributions are reasonably secure and hoping somehow to
make do with only two test images left us with 12 Leonardo
training images—a number that seemed untenably small,
particularly compared to the number of comparative (nicht-
Leonardo) training images we ultimately found necessary
to produce accurate classifications. Our final comparative
training set consisted of 37 images in subject-matter catego-
ries corresponding to those listed in Table 1 and in roughly
similar proportions. We drew our various training and test
sets from a pool of 64 comparative paintings by artists in-
cluding Leonardo’s teacher, Andrea del Verrocchio; his stu-
dents Giovanni Antonio Boltraffio and Andrea Solario; Die
Renaissance master Raffaello Sanzio da Urbino (Raphael),
who admired and was influenced by Leonardo; unidentified
“School of Leonardo” painters; Albrecht Dürer, whose work
has been mistaken for Leonardo’s; and others, including An-
tonio del Pollaiuolo, Guido Reni, Anna Maria Sirani, Andrea
Solari, Georgione and Giovanni Bellini.
We considered various strategies for boosting the num-
ber of Leonardo training tiles and equalizing the number of
Leonardo and non-Leonardo tiles. Our first effort, folgen-
ing downsampling of the high-resolution source images to
a consistent resolution of 25 pixels/canvas cm, was to isolate
heads and faces from the paintings and use an extreme level
of tile overlap so that even a single head-size image would
yield hundreds of overlapping candidate tiles, which we sifted
using our entropy criterion. Insbesondere, our Leonardo tiles
(obtained from the heads in our 12-image training set) über-
lapped by 92% and our non-Leonardo tiles (obtained from
the heads of 24 non-Leonardo images) von 88%. Although the
difference may seem small, the additional overlap for Leo-
Von http heruntergeladen://direct.mit.edu/leon/article-pdf/54/6/619/2028761/leon_a_02004.pdf by guest on 07 September 2023
Frank and Frank, A Neural Network Looks at Leonardo’s(?) Salvator Mundi 621
nardo tiles resulted in a twofold increase in their number
relative to the non-Leonardo tiles and substantially equalized
the populations of Leonardo and non-Leonardo tiles. Der
price of this data augmentation was significant data redun-
dancy, and the increase in Leonardo tile numbers means that
the tiles collectively contained only half the unique informa-
tion present in the non-Leonardo tiles (which are themselves
highly redundant). The effect is exacerbated further by the al-
ready small size of a head image, which limits the maximum
tile size and, daher, the amount of visual information that
can be analyzed.
Despite our pessimism given these severe data limita-
tionen, the models we generated at the maximum usable tile
size performed quite well, achieving 94% accuracy. At this
preliminary stage, using heads from only two Leonardo test
Bilder (and from 13 comparative test images), we consid-
ered models producing even a single false negative—i.e. ein
improperly classified Leonardo—to be failures. But obviously
we would need further strategies to validate what could easily
represent a misleadingly favorable result; more Leonardo test
Bilder, were they available, might reveal those results to be
lucky anomalies.
The results did seem to suggest that the sheer quantity of
tiles might be more important to classification success than
their unique information content. Thus emboldened, Wir
considered using the same approach on the full-size images,
which would allow us to test many more candidate tile sizes.
Once again we were pessimistic, this time because of the
mixed genres. dennoch, as we did for Rembrandt and van
Gogh, we tested a succession of tile sizes ranging from 100
× 100 Zu 650 × 650 pixels and found peak accuracy for Leo-
nardo to occur at 350 × 350 pixels—close to the optimal size
for Rembrandt. That accuracy was only 82%, unfortunately,
but we obtained steady improvement as we increased the size
of the comparative training set. Of course that also required
a relative increase in the overlap of the Leonardo tiles, Und
in fact, both Leonardo and non-Leonardo tiles needed more
overlap in order to generate sufficient tile populations. We fi-
nally achieved equal and sufficient numbers of Leonardo and
comparative tiles at overlaps of 94% Und 92%, jeweils.
Because of the two-dimensional geometry involved, Die 2%
difference in overlap resulted in three times as many tiles per
Leonardo image relative to the non-Leonardo images. Using
unser 12 Leonardo training images and 33 non-Leonardo train-
ing images (but substantially similar numbers of Leonardo
and non-Leonardo tiles), we obtained an in-sample accuracy
von 97% on a test set with 31 non-Leonardo and our two Leo-
nardo test images, with no false negatives.
Now we needed a way to corroborate the results tentatively
suggested by a test set severely deficient in Leonardo images.
We adopted several expedients. First we shuffled our com-
parative training and test sets, preparing four new tile sets
with randomly selected splits of 32 test images and 32 train-
ing images. We trained and tested 350 × 350 models for each
of the new sets. The best-performing models derived from
each new set exhibited test accuracies within a relatively nar-
row band (90–94%) Und, as expected, underperformed our
curated training set. One of the four sets failed to produce
a model free of false-negative classifications, suggesting that
successfully classifying our two Leonardo test images while
also properly classifying most of the comparative test images
(i.e. avoiding false positives) is not trivial.
As an external test, we used our best-performing mod-
els from both the curated and random tile sets to classify
Seated Bacchus, once erroneously attributed to Leonardo, Zu
see whether a painting that had once fooled experts could re-
veal deficiencies in our (inadequately tested) Modelle. Tatsächlich,
all successful models—i.e. the ones free of false negatives—
strongly classified Seated Bacchus as not painted by Leonardo
(with the best model derived from the curated set assigning a
100% classification probability). This provides some evidence
that our models are not prone to false positives.
We also tested our best-performing models from both the
curated and random tile sets on Madonna Litta and Isleworth
Mona Lisa, hoping to find consistency among models not-
withstanding the different training sets. All successful mod-
els classified Isleworth Mona Lisa as not painted by Leonardo
[8]. The results were more complex for Madonna Litta. Der
best models from our curated set and one of the random
sets solidly classified this painting as not by Leonardo. Der
two other successful random sets each yielded two models
Das, despite identical accuracy scores, classified Madonna
Litta differently from each other. dennoch, in each case,
the model that more strongly classified Seated Bacchus and
Isleworth Mona Lisa as not painted by Leonardo also classi-
fied Madonna Litta as not by Leonardo. This behavior—with
classification tendencies moving together consistently and
progressively—suggests model stability across training sets,
which would be expected of any reliable and methodologi-
cally sound model.
Endlich, to further test model stability, we tried altering the
architecture of our CNN. Insbesondere, we increased the num-
ber of convolutional layers from five to eight and increased
the size of the convolution “kernel”—the CNN’s feature ex-
tractor—in the early layers. Models based on this eight-layer
architecture consistently outperformed their five-layer coun-
terparts, with the best curated-set model achieving 100% clas-
sification accuracy and all the random-set models delivering
accuracies of 82% Zu 97% with no false negatives. Hier, the best
models derived from the curated set and all random sets very
strongly classified Seated Bacchus, and solidly classified Isle-
worth Mona Lisa and Madonna Litta, as not Leonardo works.
rEsults: Who paIntED SalvatOr Mundi ?
This suggestive level of corroboration convinced us that we
were ready to analyze Salvator Mundi. We used the best five-
layer and eight-layer models generated from our curated da-
taset to create the probability maps shown in Color Plate C
(A) and Color Plate C (B).
Both maps exhibit largely similar probability distributions,
classifying the “blessing” hand and a portion of the back-
ground as not painted by Leonardo. One possible explana-
tion for the blue classification of the background and, im
five-layer map, a portion of the chest garment is the degree
622 Frank and Frank, A Neural Network Looks at Leonardo’s(?) Salvator Mundi
Von http heruntergeladen://direct.mit.edu/leon/article-pdf/54/6/619/2028761/leon_a_02004.pdf by guest on 07 September 2023
tablE 2. probabilities assigned by models
random set #
Modell #
accuracy
False negatives
False positives
salvator mundi
Set 0
Set 1
Set 2
Set 3
33
21
22
24
32
17
20
0.93
0.97
0.91
0.91
0.82
1
0.97
0
0
0
0
0
0
0
2
1
3
3
6
0
1
0.82
0.55
0.8
0.81
0.93
0.55
0.64
of damage to (and consequent extensive restoration of) those
Bereiche. But in fact, despite considerable damage to the facial
region, it is strongly classified as Leonardo in the restored
painting. Our maps therefore suggest that the restorer did
a magnificent job, and that the most important parts of the
painting are indeed Leonardo’s work. (The small area of light
blue along the hair and forehead in the left-side probability
map is likely spurious spillover from the dark blue classifica-
tion of the adjacent background; this spillover arises from the
way probabilities are combined among the fairly large tiles to
produce the final map.) The left-hand map, generated by the
more accurate model, confines the lower blue portion to the
blessing hand. Artists who employed assistants and taught
students (Rembrandt, Zum Beispiel) often directed those who
could emulate the master’s technique to paint “unimportant”
elements such as hands, either for efficiency or as an exercise
[9]. During restoration, a prominent pentimento—a change
in composition made by the artist in the finished work—was
observed in the thumb of the blessing hand [10].
In der Tat, the blessing hand has been the subject of much
scholarly controversy. One expert believes that “much of the
original painting surface [of Salvator Mundi] may be by Bol-
traffio, but with passages done by Leonardo himself, nämlich
Christ’s proper right blessing hand, portions of the sleeve, sein
left hand and the crystal orb he holds” [11]. Another argues
the opposite:
The flesh tones of the blessing hand, Zum Beispiel, appear
pallid and waxen as in a number of workshop paintings. . . .
It is therefore not surprising that a number of reviewers of
the London Leonardo exhibition initially adopted a skepti-
cal stance towards the attribution of the New York Salvator
Mundi [12].
Given all of this, the probability distribution given by our
most accurate model does not appear to be an unreasonable
eins.
The overall probabilities assigned to Salvator Mundi by the
best eight-layer and five-layer models are, jeweils, 0.74
Und 0.62. What about models generated using the random
datasets? The results for eight-layer models are summarized
in Table 2.
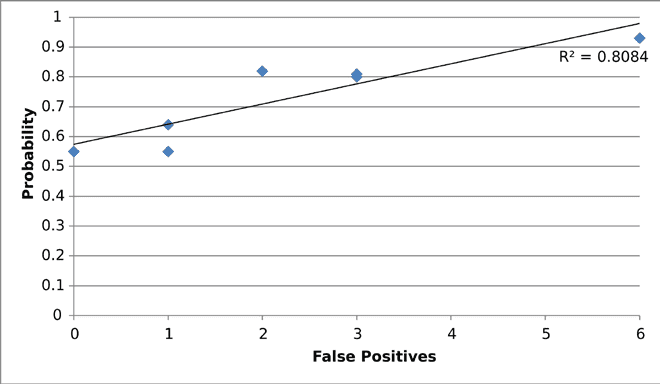
Auffallend, as illustrated in Fig. 2, there is an almost linear
relationship (R2 = 0.81) between the number of false positives
produced by a model and the overall probability score that it
assigns to Salvator Mundi.
ConClusIon
With enough training and test images and curatorial atten-
tion to their distribution and character, our Salient Slices
technique produces classifications consistent with the cur-
rent scholarly consensus. Yet even with image bases that
appear unmanageably small, high degrees of data augmen-
tation combined with corroborative testing strategies per-
mit meaningful classifications, even at the subimage level.
We hope that Salvator Mundi, whose present whereabouts
are unknown, emerges from hiding and assumes its rightful
place in Leonardo’s oeuvre.
Feige. 2. The more lenient a model is in
classifying close calls as Leonardo’s, Die
more of Salvator Mundi it will classify as by
Leonardo. The best model from random set #3,
mit 100% accuracy, assigns Salvator Mundi
an overall probability of 0.55 and produces
the probability map in Color Plate C (C),
nearly identical to Color Plate C (B). Weil
both training and test sets were generated
randomly, we have more confidence in the
map of Color Plate C (A), which reflects
curatorial efforts to balance types of work in
training and test sets; a perfect score achieved
by a randomly generated set likely has some
stochastic (lucky) origin. But persistence of
general probability pattern across models
generated with different training sets and
different model architectures seems again to
offer a measure of cross-validation. (© Art
Eye-D Associates LLC)
Von http heruntergeladen://direct.mit.edu/leon/article-pdf/54/6/619/2028761/leon_a_02004.pdf by guest on 07 September 2023
Frank and Frank, A Neural Network Looks at Leonardo’s(?) Salvator Mundi 623
references and notes
1 Bernard Berenson, Italian Painters of the Renaissance (London:
Phaidon, 1952) S. 65–67.
2 Steven Frank and Andrea Frank, “Salient Slices: Improved Neural
Network Training and Performance with Image Entropy,” Neural
Computation 32, NEIN. 6, 1222–1237 (2020).
3 François Chollet, Deep Learning with Python (New York: Manning,
2018) P. 241.
4 Martin Kemp, Robert Simon and Margaret Dalivalle, Leonardo’s
Salvator Mundi and the Collecting of Leonardo in the Stuart Courts
(Oxford, VEREINIGTES KÖNIGREICH.: Oxford Univ. Drücken Sie, 2020).
5 Luke Syson et al., Leonardo da Vinci: Painter at the Court of Milan
(London: National Gallery, 2011).
6 Carmen Bambach, “Seeking the Universal Painter: Carmen C. Bam-
bach Appraises the National Gallery’s Once-in-a-Lifetime Exhibition
Dedicated to Leonardo da Vinci,” Apollo 175, NEIN. 595, 82–85 (1 Februar-
Und 2012).
7 Charles Hope, “A Peece of Christ,” London Review of Books 42,
NEIN. 1 (2 Januar 2020) P. 19.
8 The best image we could obtain for this now-hidden work is of
unfortunately poor quality, and image artifacts appear to have
distorted our probability maps. While useful to confirm behavior
consistency among models, the classifications we obtained for this
painting are not otherwise meaningful.
9 Ernst van de Wetering, Rembrandt’s Paintings Revisited (New York:
Springer, 2017).
10 Christie’s, “Salvator Mundi—The Rediscovery of a Masterpiece:
Chronology, Conservation, and Authentication”: www.christies
.com/features/Salvator-Mundi-timeline-8644-3.aspx (zugegriffen 22
Mai 2020).
11 Bambach [6].
12 Frank Zöllner, Leonardo da Vinci: The Complete Paintings and Draw-
ings (Köln: Taschen, 2017) S. 440–445.
Manuscript received 13 Februar 2020.
steven J. FrAnK is a computer scientist and intellectual
property lawyer. AnDreA M. FrAnK is an art historian, für-
merly the Curator of Visual Resources at Boston College. Sie
are cofounders of Art Eye-D Associates LLC.
624 Frank and Frank, A Neural Network Looks at Leonardo’s(?) Salvator Mundi
Von http heruntergeladen://direct.mit.edu/leon/article-pdf/54/6/619/2028761/leon_a_02004.pdf by guest on 07 September 2023
CoLoR PL ATE C: a nEural nEt Work looks at
lEonarDo’s(?) SalvatOr Mundi
C
A
E
E
T
T
A
A
l
l
P
P
R
R
Ö
Ö
l
l
Ö
Ö
C
C
A
B
C
Overall probability assigned to Salvator Mundi as a function of false positives the model produces. (A) Probability map for
Salvator Mundi generated from best eight-layer model trained on the curated dataset. (B) Probability map generated from
best five-layer model trained on the curated dataset. The maps color-code probabilities assigned to examined regions of an
image at a granular level: Red corresponds to high-likelihood (≥ 0.65) classification as Leonardo, gold to moderate-likelihood
(0.5 ≤ p < 0.65) classification as Leonardo, green to moderate-likelihood (0.5 > p > 0.35) classification as not Leonardo,
and blue to high-likelihood (≤ 0.35) classification as not Leonardo. (C) Probability map for Salvator Mundi generated from
best random set. (© Art Eye-D Associates LLC) (See the article in this issue by Steven J. Frank and Andrea M. Frank.)
Von http heruntergeladen://direct.mit.edu/leon/article-pdf/54/6/619/2028761/leon_a_02004.pdf by guest on 07 September 2023
651