FeelingBlue: A Corpus for Understanding
the Emotional Connotation of Color in Context
Amith Ananthram1 and Olivia Winn1 and Smaranda Muresan1,2
1Department of Computer Science, Columbia University, USA
2Data Science Institute, Columbia University, USA
{amith,olivia,smara}@cs.columbia.edu
Abstrakt
While the link between color and emotion
has been widely studied, how context-based
changes in color impact the intensity of per-
ceived emotions is not well understood. In diesem
arbeiten, we present a new multimodal dataset for
exploring the emotional connotation of color
as mediated by line, stroke, texture, shape,
and language. Our dataset, FeelingBlue, Ist
a collection of 19,788 4-tuples of abstract
art ranked by annotators according to their
evoked emotions and paired with rationales
for those annotations. Using this corpus, Wir
present a baseline for a new task: Justified Af-
fect Transformation. Given an image I, Die
task is to 1) recolor I to enhance a specified
emotion e and 2) provide a textual justifica-
tion for the change in e. Our model is an
ensemble of deep neural networks which takes
ICH, generates an emotionally transformed color
palette p conditioned on I, applies p to I, Und
then justifies the color transformation in text
via a visual-linguistic model. Experimental re-
sults shed light on the emotional connotation
of color in context, demonstrating both the
promise of our approach on this challenging
task and the considerable potential for future
investigations enabled by our corpus.1
1
Einführung
Color is a powerful tool for conveying emotion
across cultures, a connection apparent in both
language and art (Mohr and Jonauskaite, 2022;
Mohammad and Kiritchenko, 2018). Metaphoric
language frequently uses color as a vehicle for
emotion: Familiar English metaphors include
‘‘feeling blue’’ or ‘‘green with envy’’. Simi-
larly, artists often pick specific colors in order
to convey particular emotions in their work, while
viewer perceptions of a piece of art are affected
by its color palette (Sartori et al., 2015). Previous
1Our dataset, Code, and models are available at https://
github.com/amith-ananthram/feelingblue.
176
studies have mostly been categorical, focusing
on confirming known links between individual
colors and emotions like blue & sadness or yel-
niedrig & happiness (Machajdik and Hanbury, 2010;
Sartori et al., 2015; Zhang et al., 2011). Jedoch,
in the wild, the emotional connotation of color is
often mediated by line, stroke, texture, shape, Und
Sprache. Very little work has examined these as-
sociations. Does the mere presence of blue make
an image feel sad? If it is made bluer, does it feel
sadder? Is it dependent on its associated form or
its surrounding color context? And, if the change
is reflected in an accompanying textual rationale,
is it more effective?
Our work is the first to explore these questions.
We present FeelingBlue, a new corpus of relative
emotion labels for abstract art paired with English
rationales for the emotion labels (siehe Abbildung 1
and Section 3). A challenge with such annotations
is the extreme subjectivity inherent to emotion.
In contrast to existing Likert-based corpora, Wir
employ a Best-Worst Scaling (BWS) annotation
scheme that is more consistent and replicable
(Mohammad and Bravo-Marquez, 2017). More-
über, as our focus is color in context (colors and
their form), we restrict our corpus to abstract art,
a genre where color is often the focus of the
Erfahrung, mitigating the effect of confounding
factors like facial expressions and recognizable
objects on perceived emotions (as observed in
Mohammad, 2011; Sartori et al., 2015; Zhang
et al., 2011; Alameda-Pineda et al., 2016).
To demonstrate FeelingBlue’s usefulness in
explorations of the emotional connotation of color
in context, we introduce a novel task, Justified
Affect Transformation—conditional on an input
image Io and an emotion e, the task is 1) to recolor
Io to produce an image Ie that evokes e more
intensely than Io and 2) to provide justifications
for why Io evokes e less intensely and why Ie
evokes e more intensely. Using FeelingBlue, Wir
Transactions of the Association for Computational Linguistics, Bd. 11, S. 176–190, 2023. https://doi.org/10.1162/tacl a 00540
Action Editor: Yulan He. Submission batch: 9/2022; Revision batch: 11/2022; Published 3/2023.
C(cid:2) 2023 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 1: Representative examples spanning FeelingBlue’s emotion subsets. Each image in an emotion subset
has a score ∈ [−1, 1] derived from its Best-Worst Scaling annotations. Images selected as the ‘‘least’’/‘‘most’’
emotional in a 4-tuple (not shown here) have rationales explaining why they are ‘‘less’’/‘‘more’’ emotional
than the rest. Information about these works can be found at https://github.com/amith-ananthram
/feelingblue.
build a baseline system for two subtasks: Bild
recoloring and rationale retrieval (Abschnitt 4).
We conduct a thorough human evaluation that
confirms both the promise of our approach on this
challenging new task and the opportunity for fu-
ture investigations enabled by FeelingBlue. Unser
results reveal regularities between context-based
changes in color and emotion while also demon-
strating the potential of linguistic framing to mold
this subjective human experience (Abschnitt 5).
Our dataset, Code, and models are available at
https://github.com/amith-ananthram
/feelingblue.
2 Related Work
While the body of work studying the relationship
between color and emotion is quite large, almost
all of it has focused on identifying categorical re-
lationships in text to produce association lexicons
(notable works include Mohammad, 2011; Sutton
and Altarriba, 2016; Mikellides, 2012).
In the domain of affective image analysis,
previous work has mostly explored classifying
the emotional content of images. Machajdik and
Hanbury (2010), Sartori et al. (2015), Zhang
et al., (2011) and Alameda-Pineda et al. (2016)
focus on identifying low-level image features cor-
related with each perceived emotion, mit dem
latter two examining abstract art specifically. Rao
et al., (2019) employ mid- and high-level features
for classification. Some work has investigated the
distribution of emotions in images: Zhao et al.
(2017, 2018) create probability distributions over
multiple emotions and Kim et al. (2018) anschauen
gradient values of arousal and valence, obwohl
none of the works correlate emotion values with
image colors. Ähnlich, Xu et al. (2018) learn
dense emotion representations through a text-
based multi-task model but they do not explore its
association with color.
Image recoloring is a very small subset of work
in the field of image transformation and has mostly
focused on palettes. PaletteNet recolors a source
image given a target image palette (Cho et al.,
2017) while Bahng et al. (2018) semantically gen-
erate palettes for coloring gray-scaled images. NEIN
previous work has examined recoloring images to
change their perceived emotional content. Simi-
larly, the field of text-to-image synthesis, welche
177
has seen major progress recently with models like
DALL-E 2 (Ramesh et al., 2022), has centered
on generating images de novo or on in-painting.
There has been no work that recolors an image
while preserving its original structure.
Ulinski et al. (2012), Yang et al. (2019) Und
Achlioptas et al.
(who also annotate
WikiArt) have explored emotion in image cap-
tioning though their focus is much broader than
color.
(2021)
3 Dataset
Our dataset, FeelingBlue, is a collection of ab-
stract art ranked by the emotions they most evoke
with accompanying textual
justifications (sehen
Figur 1). It contains 5 overlapping subsets of im-
Alter (one each for anger, disgust, fear, happiness,
and sadness) with continuous-value scores that
measure the intensity of the respective emotion in
each image compared to the other images in the
subset.
While WikiArt (Mohammad and Kiritchenko,
2018), DeviantArt2 (Sartori et al., 2015), Und
other emotion corpora contain images with
multi-label continuous emotion scores,
diese
scores were collected for each image in isolation
without accompanying rationales. They reflect
how often annotators believed that a particular
emotion fit an image resulting in a measure of the
presence of the emotion rather than its intensity.
Als solche, their scores are not a suitable way to
order these images by the strength of the emotion
they evoke. Im Gegensatz, our annotations were col-
lected by asking annotators to 1) rank groups of
images according to a specified emotion and 2)
justify their choice.
Below, we detail how we compiled this corpus.
3.1 Image Compilation
The images3 in our dataset are drawn from both
WikiArt and DeviantArt.4 As we are most in-
terested in the emotional connotation of color
as constrained by its form, we manually re-
moved images of photographs, statues, Menschen, oder
recognizable objects. This eliminated many con-
founding factors like facial expressions, flowers,
or skulls that might affect a person’s emotional
2www.deviantart.com.
3These images are a mix of copyright protected and public
domain art. We do not distribute these images. Stattdessen, Wir
provide URLs to where they may be downloaded.
4From the 283/500 images that remain available.
response to an image, leaving primarily color
and its visual context. Our final corpus contains
2,756 Bilder.
3.2 Annotation Collection
We began by partitioning our images into overlap-
ping emotion subsets where each image appears
twice, in both subsets of its top 2 emotions accord-
ing to its original corpus (WikiArt or DeviantArt)
scores. As we want meaningful continuous value
scores of emotional intensity, restricting images
to their top 2 emotions ensures that the scored
emotion is present. Within each subset, wir rannten-
domly generated 4-tuples of images such that
each image appears in at least 2 4-tuples. Mit
these 4-tuples in hand, we collected annotations
via Best-Worst Scaling (BWS) (Flynn and Marley,
2014), a technique for obtaining continuous scores
previously used to construct sentiment lexicons
(Kiritchenko and Mohammad, 2016) and to label
the emotional intensity of tweets (Mohammad and
Bravo-Marquez, 2017). Tatsächlich, Mohammad and
Bravo-Marquez (2017) found that BWS is a reli-
able method for generating consistent scaled label
Werte. It produces more replicable results than the
typical Likert scale where annotators often do not
agree with their own original assessments when
shown an item they have already labeled.
In BWS, annotators are presented with n op-
tionen (where often n = 4), and asked to pick the
‘best’ and ‘worst’ option according to a given
criterion. For our task, we present each annotator
with a 4-tuple (d.h., 4 Bilder) of abstract art and an
emotion, and the ‘best’ and ‘worst’ options are the
images that ‘most’ and ‘least’ evoke the emotion
relative to the other images. Zusätzlich, we also
asked each annotator to provide rationales describ-
ing the salient features of their chosen ‘most’ and
‘least’ emotional images. As is common practice
with BWS, for each subset corresponding to an
emotion e, we calculate continuous value scores
for each image I by subtracting the number of
times I was selected as ‘least’ evoking e from the
number of times I was selected as ‘most’ evoking
e and then dividing by the number of times I
appeared in an annotated 4-tuple. We collected 3
annotations per 4-tuple task from Master Work-
ers on Amazon Mechanical Turk (AMT) via the
BWS procedure of Flynn and Marley (2014).
Workers were paid consistent with the minimum
wage.
178
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Emotion
# Images
# Best
# Worst
Total
Spearman-R Maj. Agree % # Labels
Anger
Disgust
Fear
Happiness
Sadness
187
525
396
399
183
1688
1,078
3,072
2,352
2,326
1,084
9,912
1,087
3,078
2,315
2,346
1,050
9,876
2,165
6,150
4,667
4,672
2,134
19,788
0.685 (0.034)
0.676 (0.019)
0.691 (0.017)
0.573 (0.029)
0.672 (0.040)
64, 68, 66
65, 66, 66
65, 66, 66
65, 61, 63
68, 64, 66
2.03, 1.92
2.00, 1.98
1.99, 1.94
2.00, 2.13
1.97, 2.00
Tisch 1: Summary and inter-annotator agreement statistics for our corpus. The first column contains
Die # of unique images in each subset. Der nächste 3 contain the number of annotated 4-tuples of images
in each subset. The final 3 columns contain measures of inter-annotator agreement: 1) the mean/stdv
of the Spearman rank correlations of scores calculated from 30 random splits of each subset, 2) Die %
of annotations that agree with the majority annotation (‘best’, ‘worst’, ‘total’), Und 3) the average # von
distinct labels for each annotation task (‘best’, ‘worst’)
We did not use all of the emotion classes from
the original datasets in our study. Mohammad and
Kiritchenko (2018) found that emotions such as
arrogance, shame, Liebe, gratitude, and trust were
interpreted mostly through facial expression. Wir
also excluded anticipation and trust as they were
assumed to be related to the structural composition
of the artwork rather than color choice. For each
remaining emotion, 50 images from their corre-
sponding subsets were sampled for a pilot study of
the 4-tuple data collection. Surprise was removed
as pilot participants exhibited poor agreement and
did not reference color or terms that evoke color in
its corresponding rationales. This left 5 emotions:
anger, disgust, fear, happiness, and sadness.
We manually filtered the collected annotations
to remove uninformative rationales (such as ‘‘it
makes me feel sad’’). This filtering resulted in
splitting each collected BWS annotation into a
‘best’ 4-tuple (which contains the 4 images and the
most emotional choice among them, accompanied
by a rationale) and a ‘worst’ 4-tuple (which con-
tains the 4 images and the least emotional choice
among them, accompanied by a rationale). Unser
final corpus contains 19,788 annotations, nearly
balanced with 9,912 ‘best’ and 9,876 ‘worst’ (als
in some 4-tuples, either the ‘best’ or the ‘worst’
rationale was retained but not both).
Tisch 1 contains summary and inter-annotator
agreement statistics for our corpus, broken down
by emotion subset. We rely on 3 different measures
to gauge the consistency of these annotations.
The first captures the degree to which differences
among annotations result in changes to the ranking
of the images by BWS score. For each emotion,
we randomly split the 3 annotations for each of its
4-tuples and then calculate BWS scores for both
of the resulting random partitions. Wir machen das 30
mal, calculating the Spearman rank correlation
between the pairs of scores for each partition, Und
present the mean and standard deviation of the
resulting coefficients. The second is a measure of
what percentage of all annotations agree with the
majority annotation for a particular 4-tuple—cases
where all annotators disagree have no majority
annotation. The final is a measure of the # of dis-
tinct choices made by annotators for each 4-tuple.
Given the considerable subjectivity of the annota-
tion task, these inter-annotator agreement numbers
are reasonable and consistent with those reported
by Mohammad and Kiritchenko (2018) for the rel-
atively abstract genres from which our corpus is
drawn. Happiness, the only emotion with a positive
valence, exhibits the worst agreement.
We present images, rationales, and scores from
our corpus in Figure 1.
3.3 Corpus Analysis
We explore a number of linguistic features (color,
shape, texture, concreteness, emotion, and simile)
in FeelingBlue’s rationales to better understand
how they change with image emotion and color.
To measure color, we count both explicit color
Bedingungen (z.B., ‘red’, ‘green’) and implicit refer-
zen (z.B., ‘milky’, ‘grass’). As the artwork is
abstract and can only convey meaning through
‘‘line, stroke, color, texture, bilden, and shape’’
(IdeelArt, 2016), the use of adjectives and nouns
with strong color correlation is a likely reference
to those colors in the image. For explicit color
Bedingungen, we use the base colors from the XKCD
179
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
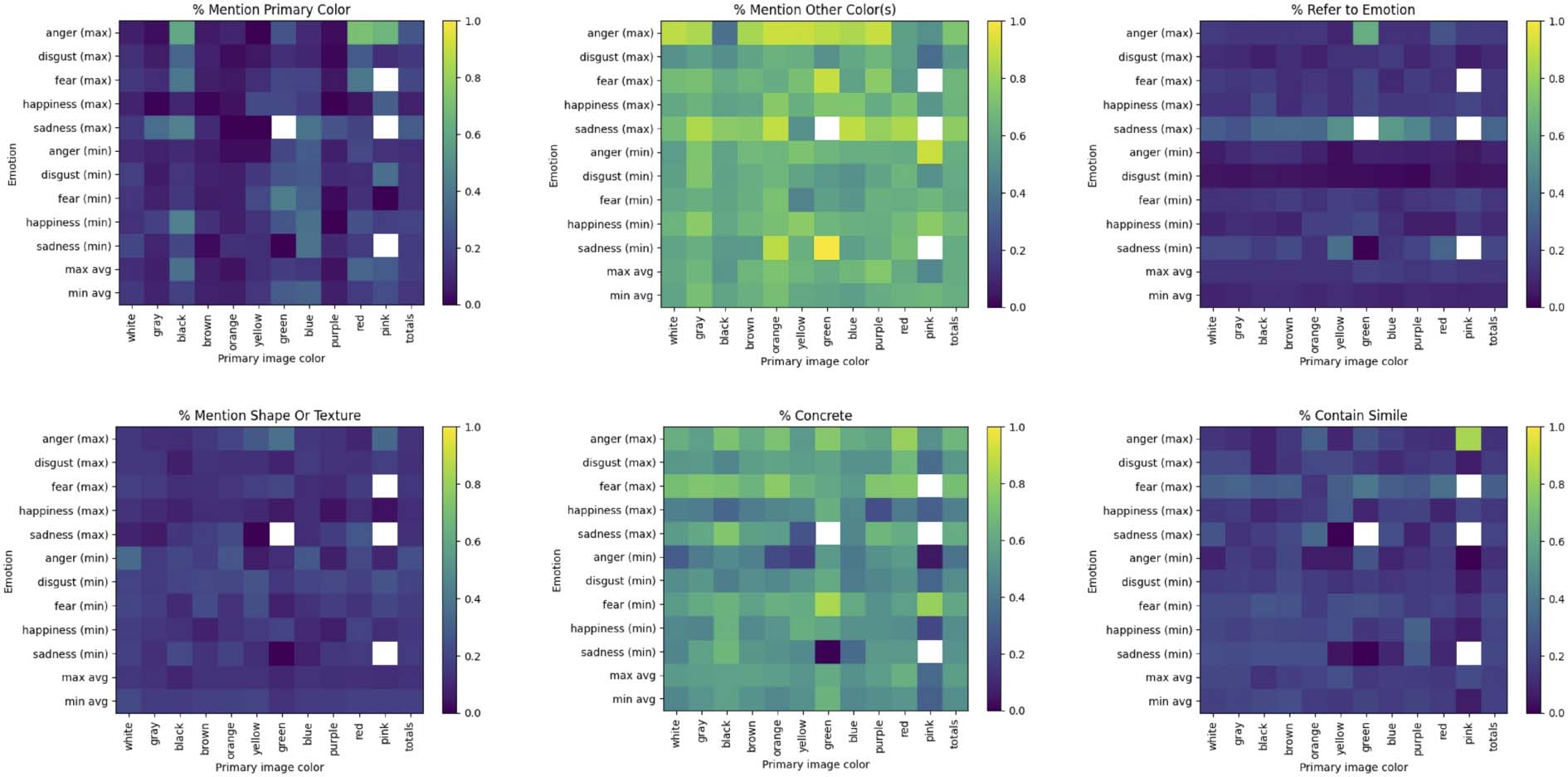
Figur 2: An analysis of the linguistic features of the rationales in FeelingBlue, binned by emotion, Die
corresponding image’s primary color and whether it was ‘least’ or ‘most’ emotional. White bins contain no
rationales.
dataset (Monroe, 2010). For implicit color ref-
erences, we use the NRC Color Lexicon (NRC)
(Mohammad, 2011), taking the words with asso-
ciated colors where at least 75% of the responders
agreed with the color association. In order to com-
pare color references with the main color of each
Bild, the primary colors of each image were
binned to the 11 color terms used in the NRC ac-
cording to nearest Delta-E distance. This results in
an uneven number of rationales per color bin. Der
implicit color terms were mapped directly to the
color bins; each explicit color term was mapped
to its nearest.
Shape words were collected by aggregating
lists of 2D shapes online and corroborating them
with student volunteers. For texture words, Wir
used the 98 textures from Bhushan et al. (1997).
Concreteness was measured as a proxy for how
often the rationales ground the contents of an
image in actual objects and scenery, like referring
to a gradient of color as a ‘sunset’ or a silver
streak as a ‘knife’. To calculate concreteness, Wir
used the lexicon collected by Brysbaert et al.
(2014), which rates 40,000 English lemmas on a
scale from 0 Zu 5. After empirical examination,
we threshold concreteness at 4 and ignore all
of the explicit color terms, shapes and textures.
Rationales were labeled as concrete if at least one
word in the rationale was above the concreteness
threshold. Similes were identified by presence of
‘like’ (but not ‘I like’) such as ‘‘The blue looks
like a monster’’.
In Abbildung 2 we present heatmaps which break
down this exploration. In Summe, 69.3% of the
rationales refer to color, highlighting the cen-
tral role color plays in FeelingBlue. We see that
51.2% contain explicit color references and 36.1%
contain implicit references (with a 26% über-
lap). Surprisingly, the majority of these references
were not to the primary color of each image.
This suggests that viewers were drawn to colors
which were either more central in the canvas or
contrasted against the primary color. A notable
exception is ‘red’ for ‘anger’: when the image is
primarily red, it is mentioned 80% of the time in
the rationale for the angriest images. Interessant,
when the image is primarily green the rationale
explicitly mentions ‘anger’, as if the image evokes
‘anger’ despite the coloring. This is a surprising
contrast to the sad images, where ‘blue’, deeply
tied to ‘sadness’ in English, is hardly mentioned
when the main color is blue, but for those same im-
Alter, the rationales explicitly call the image ‘sad’.
It may be that blue is so intrinsically tied to ‘sad-
ness’ that responders felt sad without consciously
linking the two.
The happiest images are described as ‘bright’
and ‘graceful’ while the saddest are ‘dark’ and
‘muddy’. Though the least happy are ‘dark’ as
well, they are also ‘simple’ and ‘dull’, während die
180
least sad are ‘simple’, ‘light’, and ‘empty’. Als
the language varies across these valence pairs
(z.B., least happy/most sad), this suggests that
the rationales reflect the full continuum of each
emotion.
Shapes are referred to much less frequently, A
mere 11.4%, and texture is mentioned in only 4.9%
of the rationales. Jedoch, despite the images be-
ing of abstract art, 52.4% of the rationales were
‘concrete’ (mit 17.9% containing simile), aufdecken-
ing the importance of grounding in rationaliza-
tions of the emotional connotation of color.
4
Justified Affect Transformation
We define a new task to serve as a vehicle for
exploring the emotional connotation of color in
context enabled by our corpus: Justified Affect
Transformation. Given an image Io and a target
emotion e ∈ E, the task is:
1. change the color palette of Io to produce
an image Ie that evokes e more intensely
than Io
2. provide textual justifications, one explaining
why Io evokes e less intensely and another
explaining why Ie evokes e more intensely
By focusing on changes in color (conditional
on form), we can understand the affect of different
palettes in different contexts. And by producing
justifications for those changes, we can explore
the degree to which the emotional connotation can
be accurately verbalized in English.
To solve this task, we propose a two step ap-
proach: 1) an image recoloring component that
takes as input an image Io and a target emotion
e ∈ E and outputs Ie, a version of Io recolored to
better evoke e (Abschnitt 4.1); Und 2) a rationale re-
trieval component that takes as input two images,
Io and Ie, an emotion e ∈ E, and a large set of
candidate rationales R, and outputs a ranked list of
rationales Rless that justify why Io evokes e less
than Ie and a ranked list of rationales Rmore that
justify why Ie evokes e more than Io (Abschnitt 4.2).
4.1 Image Recoloring
Our image recoloring model takes an image Io
and an emotion e as inputs and outputs a recolored
image Ie, ∀e ∈ E that better evokes the given
emotion. In an ideal scenario, this model would be
trained on a large corpus that directly reflects the
task of emotional recoloring: differently colored
versions of the same image, ranked according to
their emotion. Such a corpus is difficult to con-
struct. Stattdessen, we use our corpus, FeelingBlue,
which contains 3-tuples, (Iless, Imore, e), Wo
Iless and Imore are entirely different images and
Iless evokes e less intensely than Imore.
Our image recoloring model is an ensemble of
neural networks designed to accommodate this
challenging training regime. It consists of two
subnetworks, an emotion-guided image selector
and a palette applier, each trained independently.
The emotion-guided image selector takes two im-
ages and an emotion and identifies which of the
two better evokes the emotion. The palette applier
(PaletteNet, Cho et al. (2017)) takes an image and
a c-color palette and applies the palette to the
image in a context-aware manner.
To produce Ie from Io for a specific emotion
e, we begin with a randomly initialized palette pe,
apply it to Io with the frozen palette applier to
produce Ie and rank Io against Ie with the frozen
emotion-guided image selector. We update pe via
backpropagation so that the recolored Ie more in-
tensely evokes e according to the emotion-guided
image selector (siehe Abbildung 3). We avoid generat-
ing adversarial transformations by restricting the
trainable parameters to the colors in the image’s
palette (instead of the image itself), forcing the
backpropagation through the emotion-guided im-
age selector to find a solution on the manifold of
recolorizations of Io. Zusätzlich, we avoid local
minima by optimizing 100 randomly initialized
palettes for each (Io, e) pair, allowing us to se-
lect a palette from the resulting set that balances
improved expression of e against other criteria.
Our emotion-guided image selector, palette ap-
plier and palette training objectives are detailed in
the Section 4.1.1, 4.1.2, Und 4.1.3 jeweils.
4.1.1 Emotion-Guided Image Selector
We begin by training our emotion-guided image
selector. This model takes two images (I1, I2)
and an emotion e as input and predicts which
of the two images more intensely evokes e. Der
architecture produces dense representations from
the final pooling layer of a pretrained instance
of ResN et (He et al., 2016), concatenates those
representations and a 1-hot encoding of e and
passes this through lES fully connected (F C) lay-
ers, re-concatenating the encoding of e after every
181
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 3: Our ensemble architecture for recoloring an image Io to enhance a specified emotion e. We begin by
training both PaletteNet and our Emotion-Guided Image Selector. Dann, we randomly initialize 100 palettes and
L-channel shifts and apply them to Io with our frozen PaletteNet, produzieren 100 candidate Ie. We compare these
candidate Ie to Io with our frozen Emotion-Guided Image Selector, produzieren 100 predicted image scores. Dann,
we update only our palettes and L-channel shifts via backpropagation, minimizing a cross entropy loss between
the predicted image scores and our intended selection (Ie). This process continues iteratively until convergence.
layer. We apply a dropout rate of dES to the
output of the first lES/2 F C layers and employ
leaky ReLU activations to facilitate backpropa-
gation through this network later. The model’s
prediction is the result of a final softmax-activated
layer.
To encourage the model to be order agnos-
tic, we expand our corpus by simply inverting
each pair (producing one ‘‘left’’ example with
the more intense image first and another ‘‘right’’
example with it second). We optimize a stan-
dard cross entropy loss and calculate accuracies
by split (‘‘train’’ or ‘‘valid’’), Seite (‘‘left’’ or
‘‘right’’), and emotion. We choose the checkpoint
with the best, most balanced performance across
these axes.
4.1.2 Palette Applier
Our palette applier takes an image Io and c-color
palette p as input and outputs a recolored version
of the image Ir using the given palette p. Its ar-
chitecture is that of PaletteNet (Cho et al., 2017),
a convolutional encoder-decoder model. The en-
coder is built with residual blocks from a randomly
initialized instance of ResN et, while the decoder
relies on blocks of convolutional layers, Beispiel
norm, leaky ReLU activations, and upsampling
to produce the recolored image Ir. The outputs
of each convolutional layer in the encoder and
the palette p are concatenated to the inputs of the
corresponding layer of the decoder, ensuring that
the model has the signal necessary to apply the
palette properly. The palette applier outputs the
A and B channels of Ir. As in Cho et al. (2017),
Io’s original L channel is reused (siehe Abbildung 3).
We train this model on a corpus of recolored
tuples (Io, Ir, P) generated from our images as in
Cho et al. (2017). For each image Io, we convert
it to HSV space and generate rP A recolored
variants Ir by shifting its H channel by fixed
amounts, converting them back to LAB space
and replacing their L channels with the original
from Io. We extract a c-color palette p for each of
these recolored variants Ir using ‘‘colorgram.’’5
We augment this corpus via flipping and rotation.
We optimize a pixel-wise L2 loss in LAB space
and choose the checkpoint with the best ‘‘train’’
and ‘‘valid’’ losses.
4.1.3 Palette Generation
We use frozen versions of our emotion-guided
image selector ES and palette applier P A to
generate a set of c-color palettes pe, ∀e ∈ E
and L-channel shifts be, ∀e ∈ E which, Wann
applied to our original image Io, produce recol-
ored variants Ie, ∀e ∈ E, each evoking e more
intensely than Io.
We produce pe and be iteratively, initializing p0
e
to c random colors and b0
e to 0 at t = 0. Dann,
we update pt
e to Io and
shifting its L channel by bt
e, producing a recolored
variant I t
e. This recolored variant is compared
against Io by the emotion-guided image selector
e by applying pt
e and bt
5https://github.com/obskyr/colorgram.py.
182
for its specific emotion e (using both ‘‘sides’’
of ES). We optimize a cross entropy (CE) loss
over these predictions with the recolored image
I t
e as the silver-label choice. We choose the final
e, ∀e ∈ E after backpropagation converges or
I t
T steps.
I t
e = P A(Io, pt
L = CE(ES(I t
e, ∀e ∈ E
e) + bt
e, Io, e), 0) + CE(ES(Io, I t
e, e), 1)
To avoid getting stuck in local minima, Wir
optimize 100 randomly initialized palettes for each
emotion e. Choosing the palette with the smallest
loss produces similar transformations for certain
emotions (such as fear and disgust). One desirable
property for Ie, ∀e is color diversity. To prioritize
Das, we consider the top 50 palettes according to
their loss for each emotion e and select one palette
for each e such that the pairwise L2 distance
among the resulting Ie is maximal.6
4.2 Rationale Retrieval
Our rationale ranking model takes as input two
Bilder, Iless and Imore, an emotion e ∈ E, Und
a set of candidate rationales R drawn from Feel-
ingBlue. It then outputs 1) Rless, a ranking of
rationales from R explaining why Iless evokes e
less intensely and 2) Rmore, a ranking of ratio-
nales from R explaining why Imore evokes e more
intensely.
The architecture embeds Iless and Imore with
CLIP (Radford et al., 2021), a state-of-the-art
multimodal model trained to collocate web-scale
images with their natural language descriptions via
a contrastive loss. We concatenate these CLIP
embeddings with an equally sized embedding of e
and pass this through a ReLU-activated layer pro-
ducing a shared representation t. We apply dropout
dRR before separate linear heads project t into
CLIP ’s multimodal embedding space, resulting
in tless and tmore.
Gegeben (Iless, Imore, rless, rmore), with rless and
rmore ∈ R, we optimize CLIP ’s contrastive loss,
encouraging the logit scaled cosine similarities
between tless|more and CLIP embeddings of R to
be close to 1 for rless|more and near 0 for the rest.
We weight this loss by the frequency of rationales
in our corpus and reuse CLIP ’s logit scaling
factor.
6As this is NP-complete, we use an approximation.
183
4.3 Training Details
4.3.1 Corpus
We extract pairs of images ordered by the emo-
tion they evoke from FeelingBlue. Each 4-tuple is
ranked according to a particular emotion e result-
ing in a ‘Least’, (cid:2), ‘Most’, M, and two unordered
middle images, u1 and u2. This provides us with
5 ordered image pairs of (less of emotion e, mehr
of emotion e): ((cid:2), u1), ((cid:2), u2), ((cid:2), M), (u1, M),
Und (u2, M) which we use to train both our im-
age recoloring and our rationale retrieval models.
Note that while FeelingBlue restricts us to the 5
emotions for which it contains annotations, beide
the task and our approach could be extended to
other emotions with access to similarly labeled
Daten.
4.3.2 Vorverarbeitung
We preprocess each image by first resizing it to
224 × 224, zero-padding the margins to maintain
aspect ratios, converting it from RGB to LAB
Raum, and then normalizing it to a value between
−1 and 1. As LAB space attempts to represent
human perception of color, it allows our model
to better associate differences in perceived color
with differences in perceived emotion. We note
here that our emotion-guided image selector relies
on fine-tuning a version of ResN et pretrained
on images in RGB space, not LAB space. Daher,
we incur an additional domain shift cost in our
fine-tuning. While this cost could be avoided by
training ResN et from scratch in LAB space (pro-
haps on a corpus of abstract art), our experimental
results show that it appears to have been more
than offset by the closer alignment between input
representation and human visual perception.
4.3.3 Hyperparameters
For all of our models, we extract c = 6 color
palettes. Our Emotion-Guided Image Selector uses
a pre-trained ResN et − 50 backbone and lES = 6
fully connected layers. It was trained with dropout
dES = 0.1 (Srivastava et al., 2014), learning rate
lrES = 5e − 5, and a batch size of 96 für 30
epochs using Adam (Kingma and Ba, 2015). Unser
Palette Applier was trained for 200 epochs with a
batch size of 128 using the same hyperparameters
as Cho et al. (2017). To generate our palettes,
we use learning rate lrP G = 0.01 and iterate up
to T = 2000 Schritte. Und schlussendlich, our Rationale
Retrieval model was trained with dropout dRR =
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 4: Samples from our model’s evaluation. The top row depicts an image with all of its recolorings.
The bottom left displays rationales retrieved for the depicted (Iless, Imore) distinct image pair. The bottom
right displays rationales retrieved for the depicted (Io, Ie) recolored image pair. Clockwise: Landscape by
Arthur Beecher Carles, Highway and Byways by Paul Klee, Flowers by August Herbin, and Farbspiele by
Ernst Wilhelm Nay.
0.4, learning rate lrRR = 1e − 4 and a batch size
von 256 für 100 epochs using Adam.
5 Results and Discussion
To understand our approach’s strengths, we eval-
uate our image recoloring model and rationale
retrieval model both separately and together.
Evaluation Data for Imaging Recoloring. Der
evaluation set for our image recoloring model con-
tains 100 images—30 are randomly selected from
our validation set and the remaining 70 are unseen
images from WikiArt. We generate 5 recolorized
versions Ie of each image Io corresponding to each
of our 5 emotions, ergebend 1000 recolored
variants for evaluation (see Section 5.1).
Evaluation Data for Rationale Retrieval. To
evaluate our rationale retrieval model as a stan-
dalone module we choose an evaluation set
consisting of 1000 image pairs, 200 für jede
emotion. For this dataset, each pair of images con-
tains different images. Wieder, 30% are randomly
selected from images in our FeelingBlue valida-
tion set and the remaining 70% consist of unseen
images from WikiArt. To identify and order these
(Iless, Imore) image pairs, we use the continuous
labels produced by our BWS annotations for the
former and WikiArt’s agreement labels as a proxy
for emotional content in the latter. We retrieve and
evaluate the top 5 Rless and Rmore rationales for
jede (Iless, Imore) (see Section 5.2).
Image Recoloring+
Evaluation Data for
Rationale Retrieval. Endlich, to evaluate our
models together, we retrieve and evaluate the
top 5 Rless and Rmore rationales for all 1000
recolored (Io, Ie) pairs, which we refer to as
‘‘recolored image rationales’’ (Abschnitt 5.2).
As our domain (art recolorings) and class set
(emotions) are both non-standard, automatic im-
age generation metrics like Fr´echet Inception
Distance (FID) (Heusel et al., 2017) that are
trained on ImageNet (Deng et al., 2009) Sind
ill-suited to its evaluation (Kynk¨a¨anniemi et al.,
2022). Daher, given the novel nature of this task,
we rely more heavily on human annotation. Jede
evaluation task is annotated by 3 Master Workers
on Amazon Mechanical Turk (AMT). Their com-
pensation was in line with the minimum wage.
184
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 5: Image recoloring results. (Top left) Krippendorff’s α, the fraction of recolorings with the specified
majority label by intended emotion and the fraction of recolorings with the specified label (from any annotator) von
intended emotion. (Bottom left) The label distributions of our top 7 most frequent annotators. (Rechts) The confusion
matrix between our intended transformations (x-axis) and the emotion effects indicated by our annotators (y-axis).
Bold indicates the top label per intended emotion / annotator. Italics indicates where ‘‘more‘‘ beats ‘‘less’’.
We ensure the quality of these evaluations via a
control task which asks annotators to identify the
colors in a separate test image. We did not restrict
these evaluation tasks to native English speakers.
As associations between specific colors and emo-
tions are not universal (Philip, 2006), this may
have had a negative effect on both our agreement
and scores.
In Summe, we collected 9000 evaluation anno-
tations which we release as FeelingGreen, ein
additional complementary corpus that could be
instructive to researchers working on this task.
5.1 Image Recoloring Results
To evaluate the quality of our image recoloring, für
each pair of images (Io, Ie), we asked annotators
whether the recolored image Ie, when compared
to Io, evoked less, an equal amount or more
of all 5 of our emotions. Given that our image
recolorization model is only designed to increase
the specified emotion e, a task that only measures
e would be trivial as the desired transformation
is always more. Umgekehrt, asking annotators to
identify e would enforce a single label constraint
for a problem that is inherently multilabel.
As is clear from the agreement scores reported
in Abbildung 5, emotion identification is very sub-
jective, a fact corroborated by Mohammad and
Kiritchenko (2018) for the abstract genres from
which our images are compiled. daher, in ad-
dition to reporting the percentage of tasks for each
emotion with a specific majority label, we include
1) cases where at least 1 annotator selected a given
label and 2) the performance of our system ac-
cording to our top 7 annotators when considered
individually.
The scores in Figure 5 demonstrate the diffi-
culty of this task. More often than not, the major-
ity label indicates that our system left the targeted
emotion unchanged. In the case of happiness, Wir
successfully enhanced its expression in 33.5% von
tasks, the sole emotion for which more beats both
less and equal. Jedoch, the opposite holds for
anger where we reduced its expression in 33% von
tasks while increasing it in just 16.5%. As less
angry and more happy are similar in terms of va-
lence, this suggests a bias in our approach reflected
in the confusion matrix in Figure 5. Perhaps the
random initialization of palettes and our prefer-
ence for a diverse set of recolorings for a given
Io result in multi-colored transformations which,
while satisfactory to our emotion-guided image
selector, appear to most annotators as happy.
Another possibility is that distinct shape (z.B.,
an unambiguous circle) constrains the emotional
potential of color. To test this, we calculate the
max CLIP (Radford et al., 2021) similarity be-
tween each work of art and terms in our shape
185
When we consider our annotators individually,
our recolorings were effective for at least one
annotator in more than half of the tasks for each
emotion. Tatsächlich, annotators 2 Und 6 indicated that,
when not equal, our system enhanced the intended
emotion. This suggests an opening for emotional
recolorings conditioned on the subjectivity of a
particular viewer. We leave this to future work.
We display an example recoloring in Figure 4.
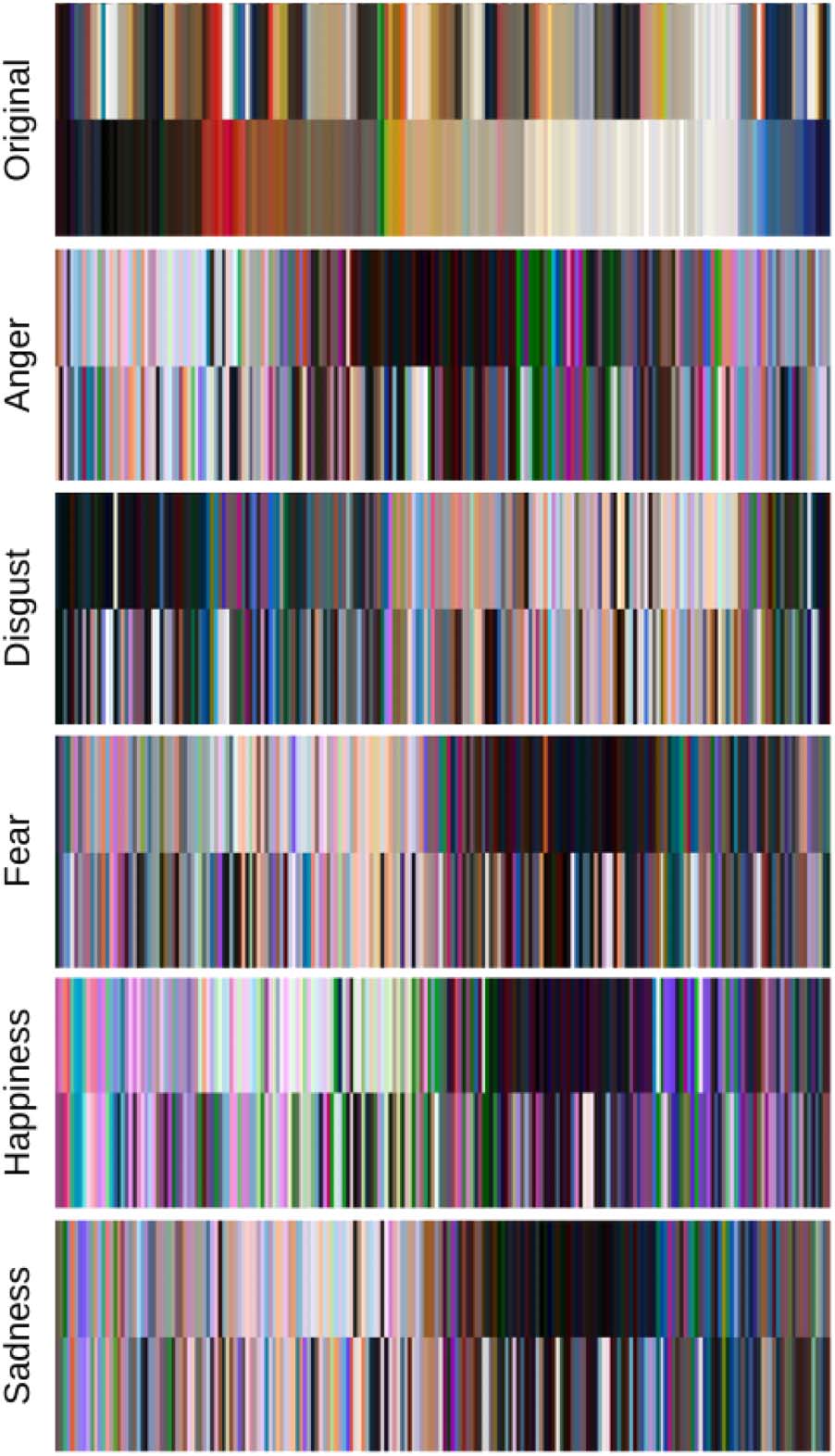
Zusätzlich, in Abbildung 6, we present a visualiza-
tion of the recolorings produced by our system.
When read from top (each Io’s top 2 colors)
to bottom (its corresponding Ie’s top 2 colors,
∀e ∈ E), some interesting properties emerge. Es
is clear that our diverse image selection heuristic
described in Section 4.1.3 is effective, ergebend
few overlapping color bands for the same image
Io across all 5 emotions. Wie erwartet, recolor-
ing for happiness results in brighter palettes but
überraschenderweise, when the original image begins with
a light palette, our system prefers dark primary
colors and bright secondary colors, das ist, ex-
treme visual contrast. While a few trends for other
emotions are also identifiable, the lack of a sim-
ple relationship between emotion and generated
palette or even original image color, emotion and
generated palette suggests that the model is using
other deeper contextual features (less prominent
colors and the image’s composition) to produce
its recoloring.
5.2 Rationale Retrieval Results
We evaluate the rationales from Rless and Rmore
against two criteria: ‘Descriptive’ and ‘Justifying’.
‘Descriptive’ indicates that the rationale refers to
content present in the specified image (for Rless
this is Io and for Rmore this is Ie) and allows us
to measure how well our rationale retrieval model
correlates image features with textual content, für
Beispiel, by retrieving rationales with appropriate
color words. ‘Justifying’ means that the rationale
is a reasonable justification for why the specified
image evokes more or less of the target emotion
than the other image in its pair. This allows us to
measure whether the model 1) picks rationales that
identify a difference between the two images and
2) more generally picks rationales that describe
patterns of image differences that correspond to
perceived emotional differences.
For every image and its more emotional coun-
terpart (either the paired image or its recolored
Figur 6: A summary view of our recolorings. Der
first row features the top 2 colors in every Io in
our evaluation set (where the bottom band displays
each Io’s primary color and the top band displays its
secondary color in the same position). The other 5 rows
depict the top 2 colors for every recolored variant Ie in
the same position as its Io. In these 5 rows, the bands
are mirrored with primary on top and secondary on the
bottom.
lexicon7 and consider the difference in scores be-
tween the 40 works in the bottom quintile and the
40 works in the top quintile (with the least dis-
tinct and most distinct shape according to CLIP).
We find that on average an additional 1.5%, 4.5%
(for ≥ 2 annotators and ≥ 1 annotator labeling)
of our recolorings were effective (d.h., labeled as
mehr) when comparing the bottom shape quintile
to the top shape quintile while less and equal fell
von 0%, 2% Und 3%, 1.5% jeweils. This lends
some credence to the notion that dominant shapes
restrict the breadth of emotions color can connote.
7We embed ‘‘an image of [SHAPE]” for each SHAPE.
186
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Descriptive
Distinct Image
Justifying
Beide
Descriptive
0.021
0.006
–
0.012
Recolored Image
Justifying
−0.073
Beide
–
@k, wi-k
@k, wi-k
@k, wi-k
@k, wi-k
@k, wi-k
@k, wi-k
0.577, 0.577
0.716, 0.716
0.717, 0.897 0.587, 0.801 0.475, 0.683 0.842, 0.963 0.753, 0.908 0.682, 0.851
0.719, 0.989
0.596, 0.968
0.683, 0.904 0.555, 0.779
0.489, 0.908
0.441, 0.655
0.845, 0.999
0.826, 0.952
0.749, 0.995
0.734, 0.905
0.683, 0.971
0.655, 0.839
0.469, 0.469
0.845, 0.845
0.761, 0.761
0.692, 0.692
0.669, 0.669
0.694, 0.694
0.796, 0.796
0.729, 0.729
0.726, 0.912 0.650, 0.852 0.527, 0.738 0.789, 0.935
0.703, 0.877
0.794, 0.994
0.733, 0.990
0.698, 0.979
0.816, 0.954 0.704, 0.884 0.630, 0.818
0.662, 0.866
0.614, 0.614
0.613, 0.792
0.613, 0.946
0.524, 0.920
0.448, 0.660
0.644, 0.979
0.580, 0.798
0.545, 0.545
α
k
1
2
5
C
1
2
5
C
Our Model (k = 2)
Class-Sampled (C)
Feature
has color
no color
is concrete
not concrete
simile
no similar
%
60.3
39.7
72.7
27.3
27.8
72.2
Descriptive
0.765
0.773
0.760
0.792
0.764
0.770
Justifying
0.665
0.686
0.665
0.695
0.655
0.680
Beide
0.564
0.590
0.565
0.599
0.566
0.578
%
54.9
45.1
64.2
35.8
23.1
76.9
Descriptive
0.724
0.774
0.732
0.773
0.727
0.752
Justifying Both
0.523
0.569
0.529
0.569
0.537
0.546
0.626
0.664
0.630
0.667
0.637
0.645
Tisch 2: Rationale retrieval results. (Top) Distinct image and recolored image results: Krippendorff’s
α, IR precisions (@k, within-k) for k ∈ {1, 2, 5} and class-sampled (C) rationales explaining why Io
evokes e less intensely (first four rows) and why Ie evokes e more intensely (last four rows) across three
Kriterien (Descriptive, Justifying and Both). (Bottom) Prevalence and IR precision (@k) for rationales
grouped by ‘‘specificity’’ features: color, concreteness and simile. Bold indicates the higher score
between our k = 2 predictions and C.
variant), we asked annotators to evaluate the top
five rationales from the pair’s Rless and Rmore
according to both criteria. As a strong baseline,
we include 2 class-sampled rationales C ran-
domly sampled from the subset of rationales in
FeelingBlue justifying image choices for the same
emotion and direction (z.B., more angry). Daher,
these rationales exhibit language that is direction-
ally correct but perhaps specific to another image.
Alle 7 rationales were randomly ordered so an-
notators would not be able to identify them by
Position.
Tisch 2 reports agreement and two different
metrics for each of our criteria across both the
‘‘distinct image’’ and ‘‘recolored image’’ sets:
precision@k and precision-within-k, the percent
of top-k rationale groups where at least one ration-
ale satisfied the criterion. Because the validation
and unseen splits had similar scores, we present
only the union of both. As with our image recol-
oring evaluation (and emotion annotations more
generally), agreement scores are again quite low
(though better for ‘Descriptive’ than ‘Justifying’).
Der 2 class-sampled rationales (C) are a very
strong baseline for our model to beat – our model
retrieves rationales by comparing combined image
representations to the full set of rationales (across
all emotions and for both directions), instead of
drawing them from the specified emotion and di-
rection subset as is the case for the class-sampled
rationales. That precision for the class-sampled ra-
tionale is relatively high shows that people tended
to gravitate towards similar features as salient to
the emotional content of different images. Trotzdem,
our model regularly outperforms this baseline.
One explanation for the surprising strength of
the ‘‘class-sampled’’ rationales is that broader,
more generally applicable rationales are over-
represented in FeelingBlue relative to specific
rationales that only apply to certain images. To
explore this, in Table 2 we also present the preva-
lence and scores of rationales from our model
and the ‘‘class-sampled’’ baseline along three
different axes of specificity: color, concrete lan-
guage and simile (as identified in Section 3.3).
The results show that not only was our model
187
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
more likely to prefer specific rationales, it also
used them more effectively. Because specificity
is more easily falsifiable than non-specificity, unser
model’s preference for specificity depresses its ag-
gregate scores relative to the baseline (Simpson’s
paradox).
Endlich, it is interesting that annotators regularly
found rationales for our recolored image pairs
(Io, Ie) to be ‘Justifying’ despite the relatively
worse agreement with the intended emotion. Als
we ask annotators to consider a rationale ‘Justify-
ing’ assuming the intended emotional difference
is true, we cannot conclude that the rationales
change the annotators’ opinion about the recolor-
ing. But it does show that people can recognize
how others might respond emotionally to an image
even if they might not agree. We include example
retrievals for both variants in Figure 4.
6 Abschluss
We introduce FeelingBlue, a new corpus of ab-
stract art with relative emotion labels and English
rationales. Enabled by this dataset, we present a
baseline system for Justified Affect Transfor-
mation, the novel task of 1) recoloring an image
to enhance a specific emotion and 2) Bereitstellung einer
textual rationale for the recoloring.
Our results reveal insights into the emotional
connotation of color in context: its potential is
constrained by its form and effective justifications
of its effects can range from the general to the
specific. They also suggest an interesting direction
for future work—how much is our emotional
response to color affected by linguistic framing?
We hope that FeelingBlue will enable such future
inquiries.
Danksagungen
We would like to express our gratitude to our
annotators for their contributions and the artists
whose work they annotated for their wonderful art.
Zusätzlich, we would like to thank our reviewers
and Action Editor for their thoughtful feedback.
Verweise
2016. IdeelArt: The online gallerist.
Panos Achlioptas, Maks Ovsjanikov, Kilichbek
Haydarov, Mohamed Elhoseiny, and Leonidas
J. Guibas. 2021. Artemis: Affective language
for visual art. In Proceedings of the IEEE/
CVF Conference on Computer Vision and
Pattern Recognition, pages 11569–11579.
https://doi.org/10.1109/CVPR46437
.2021.01140
Xavier Alameda-Pineda, Elisa Ricci, Yan Yan,
and Nicu Sebe. 2016. Recognizing emotions
from abstract paintings using non-linear ma-
trix completion. In Proceedings of the IEEE
Conference on Computer Vision and Pattern
Recognition, pages 5240–5248. https://
doi.org/10.1109/CVPR.2016.566
Hyojin Bahng, Seungjoo Yoo, Wonwoong Cho,
David Keetae Park, Ziming Wu, Xiaojuan Ma,
and Jaegul Choo. 2018. Coloring with words:
Guiding image colorization through text-based
palette generation. In Proceedings of the Euro-
pean Conference on Computer Vision (ECCV),
431–447. https://doi.org/10
Seiten
.1007/978-3-030-01258-8_27
Nalini Bhushan, A. Ravishankar Rao, Und
Gerald L. Lohse. 1997. The texture lex-
icon: Understanding the categorization of
relation-
visuell
Sci-
ship
enz, 21(2):219–246. https://doi.org
/10.1207/s15516709cog2102_4
und ihre
Bilder. Kognitiv
texture
texture
Bedingungen
Zu
Marc Brysbaert, Amy Beth Warriner, Und
Victor Kuperman. 2014. Concreteness ratings
für 40 thousand generally known English
word lemmas. Behavior Research Methods,
46(3):904–911. https://doi.org/10.3758
/s13428-013-0403-5, PubMed: 24142837
Junho Cho, Sangdoo Yun, Kyoungmu Lee, Und
Jin Young Choi. 2017. PaletteNet:
Image
recolorization with given color palette. In Pro-
ceedings of the IEEE Conference on Computer
Vision and Pattern Recognition Workshops,
volume 2017-July, pages 1058–1066. https://
doi.org/10.1109/CVPRW.2017.143
Jia Deng, Wei Dong, Richard Socher, Li-Jia
Li, Kai Li, and Li Fei-Fei. 2009. ImageNet:
A large-scale hierarchical
image database.
In 2009 IEEE Conference on Computer Vi-
sion and Pattern Recognition, pages 248–255.
IEEE. https://doi.org/10.1109/CVPR
.2009.5206848
Terry N. Flynn and Anthony A. J. Marley. 2014.
Best-Worst Scaling: Theory and methods,
188
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Handbook of Choice Modelling. Edward Elgar
Veröffentlichung. https://doi.org/10.4337
/9781781003152.00014
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Und
Jian Sun. 2016. Deep residual learning for im-
age recognition. In Proceedings of the IEEE
Conference on Computer Vision and Pattern
Recognition, pages 770–778.
Martin Heusel, Hubert Ramsauer, Thomas
Unterthiner, Bernhard Nessler,
and Sepp
Hochreiter. 2017. GANs trained by a two time-
scale update rule converge to a local Nash
Equilibrium. Advances in Neural Information
Processing Systems, 30.
Hye-Rin Kim, Yeong-Seok Kim, Seon Joo
Kim, and In-Kwon Lee. 2018. Building emo-
tional machines: Recognizing image emotions
through deep neural networks. IEEE Trans-
actions on Multimedia, 20(11):2980–2992.
https://doi.org/10.1109/TMM.2018
.2827782
Diederik P. Kingma and Jimmy Ba. 2015.
Adam: A method for stochastic optimization.
In 3rd International Conference for Learning
Darstellungen (ICLR), San Diego, Kalifornien.
Svetlana Kiritchenko and Saif M. Mohammad.
2016. Capturing reliable fine-grained sentiment
associations by crowdsourcing and Best-Worst
Scaling. In NAACL-HLT, pages 811–817, San
Diego, Kalifornien. https://doi.org/10
.18653/v1/N16-1095
Tuomas Kynk¨a¨anniemi, Tero Karras, Miika
Aittala, Timo Aila, and Jaakko Lehtinen.
2022. Die Rolle von
In
Inception Distance. arXiv preprint
Fr´echet
arXiv:2203.06026.
ImageNet classes
Jana Machajdik and Allan Hanbury. 2010. Affec-
tive image classification using features inspired
by psychology and art theory. In Proceedings
von
the 18th ACM International Conference
on Multimedia, pages 83–92. https://doi
.org/10.1145/1873951.1873965
Byron Mikellides. 2012. Colour psychology:
The emotional effects of colour perception.
In Colour Design, Sonst, pages 105–128.
https://doi.org/10.1533/9780857095534
.1.105
Saif Mohammad. 2011. Even the abstract have
color: Consensus in word-colour associations.
In Proceedings of
the 49th Annual Meet-
ing of
the Association for Computational
Linguistik: Human Language Technologies,
pages 368–373, Portland, Oregon, USA. Asso-
ciation for Computational Linguistics.
Saif Mohammad and Felipe Bravo-Marquez.
2017. Emotion intensities in tweets. In Pro-
ceedings of the 6th Joint Conference on Lexical
and Computational Semantics (*SEM 2017),
pages 65–77, Vancouver, Kanada. Association
für Computerlinguistik. https://doi
.org/10.18653/v1/S17-1007
Saif Mohammad and Svetlana Kiritchenko. 2018.
WikiArt Emotions: An annotated dataset of
emotions evoked by art. In Proceedings of the
Eleventh International Conference on Lan-
guage Resources and Evaluation (LREC 2018).
Christine Mohr and Domicele Jonauskaite. 2022.
Why links between colors and emotions may
be universal.
Randall Monroe. 2010. Color survey results.
Gill Philip. 2006. Connotative meaning in
English and Italian colour-word metaphors.
Metaphorik, 10.
Alec Radford, Jong Wook Kim, Chris Hallacy,
Aditya Ramesh, Gabriel Goh, Sandhini
Agarwal, Girish Sastry, Amanda Askell,
Pamela Mishkin,
Jack Clark, Gretchen
Krueger, and Ilya Sutskever. 2021. Learning
transferable visual models from natural lan-
guage supervision. In International Confer-
ence on Machine Learning, pages 8748–8763.
PMLR.
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol,
Casey Chu, and Mark Chen. 2022. Hierarchical
text-conditional image generation with CLIP
latents. arXiv preprint arXiv:2204.06125.
Tianrong Rao, Xiaoxu Li, and Min Xu. 2019.
Learning multi-level deep representations for
image emotion classification. Neural Process-
ing Letters, pages 1–19.
Andreza
Sartori, Victoria Yanulevskaya,
Almila Akdag Salah, Jasper Uijlings, Elia
Bruni, and Nicu Sebe. 2015. Affective analysis
of professional and amateur abstract paintings
189
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Analyse, pages 292–298, Brussels, Belgien.
Verein für Computerlinguistik.
Jufeng Yang, Yan Sun, Jie Liang, Bo Ren, Und
Shang-Hong Lai. 2019. Image captioning by in-
corporating affective concepts learned from
both visual and textual components. Neuro-
computing, 328:56–68. https://doi.org
/10.1016/j.neucom.2018.03.078
He Zhang, Eimontas Augilius, Timo Honkela,
Jorma Laaksonen, Hannes Gamper, and Henok
Alene. 2011. Analyzing emotional semantics
image fea-
of abstract art using low-level
tures. In International Symposium on Intelli-
gent Data Analysis, pages 413–423. Springer.
https://doi.org/10.1007/978-3-642
-24800-9 38
Sicheng Zhao, Guiguang Ding, Yue Gao,
and Jungong Han. 2017. Approximating
Bild
discrete probability distribution of
emotions by multi-modal
fusion.
Merkmale
Transfer, 1000(1):4669–4675. https://doi
.org/10.24963/ijcai.2017/651
Sicheng Zhao, Xin Zhao, Guiguang Ding, Und
Kurt Keutzer. 2018. EmotionGAN: Unsuper-
vised domain adaptation for learning discrete
probability distributions of image emotions. In
Proceedings of the 26th ACM International
Conference on Multimedia, pages 1319–1327.
https://doi.org/10.1145/3240508
.3240591
using statistical analysis and art theory. ACM
Transactions on Interactive Intelligent Systems
(TiiS), 5(2):1–27. https://doi.org/10
.1145/2768209
Nitish Srivastava, Geoffrey Hinton, Alex
Krizhevsky,
and Ruslan
Ilya Sutskever,
Salakhutdinov. 2014. Dropout: A simple way
to prevent neural networks from overfitting.
The Journal of Machine Learning Research,
15(1):1929–1958.
Tina M. Sutton and Jeanette Altarriba. 2016.
Color associations to emotion and emotion-
laden words: A collection of norms for stimulus
construction and selection. Behavior Research
Methoden, 48(2):686–728. https://doi.org
/10.3758/s13428-015-0598-8, PubMed:
25987304
Und
Morgan Ulinski, Victor Soto,
Julia
Hirschberg. 2012. Finding emotion in im-
Die
age descriptions.
Erste
International Workshop on Issues of
Sentiment Discovery and Opinion Mining,
pages 1–7. https://doi.org/10.1145
/2346676.2346684
In Proceedings of
Peng Xu, Andrea Madotto, Chien-Sheng Wu,
Ji Ho Park, and Pascale Fung. 2018. Emo2Vec:
Learning generalized emotion representation
by multi-task training. In Proceedings of the
9th Workshop on Computational Approaches
to Subjectivity, Sentiment and Social Media
190
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
4
0
2
0
7
4
9
0
9
/
/
T
l
A
C
_
A
_
0
0
5
4
0
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3