DP-Parse: Finding Word Boundaries from Raw Speech
with an Instance Lexicon
Robin Algayres1,3,5 Tristan Ricoul3
Julien Karadayi3 Hugo Laurenc¸on3
Salah Zaiem3 Abdelrahman Mohamed2 Benoˆıt Sagot4 Emmanuel Dupoux1,3,4,5
Meta AI Research, France1, Meta AI Research, USA2, ENS/PSL, Paris, France3,
EHESS, Paris, France4, Inria, Paris, France5,
{robin.algayres, benoit.sagot}@inria.fr
dpx@fb.com
Abstrakt
Finding word boundaries in continuous speech
is challenging as there is little or no equivalent
of a ‘space’ delimiter between words. Popu-
lar Bayesian non-parametric models for text
segmentation (Goldwater et al., 2006, 2009)
use a Dirichlet process to jointly segment sen-
tences and build a lexicon of word types. Wir
introduce DP-Parse, which uses similar prin-
ciples but only relies on an instance lexicon of
word tokens, avoiding the clustering errors that
arise with a lexicon of word types. On the Zero
Resource Speech Benchmark 2017, our model
sets a new speech segmentation state-of-the-art
In 5 languages. The algorithm monotonically
improves with better input representations,
achieving yet higher scores when fed with
weakly supervised inputs. Despite lacking a
type lexicon, DP-Parse can be pipelined to a
language model and learn semantic and syn-
tactic representations as assessed by a new
spoken word embedding benchmark. 1
1
Einführung
One of the first tasks that infants face is to learn the
words of their native language(S). To do so, Sie
must solve a word segmentation problem, seit
words are rarely uttered in isolation but come up
in multi-word utterances (Brent and Cartwright,
1996). Segmenting utterances into word or sub-
word units is also an important step in NLP
applications, where an input string of orthographic
symbols is tokenized into words or sentence piece
before being fed to a language model. While many
writing systems use white spaces that make (ba-
sic) tokenization a relatively simple task, Andere
do not (z.B., Chinese) and turn tokenization into
1Our open-source implementation of DP-Parse: https://
gitlab.cognitive-ml.fr/ralgayres/dp-parse.
a challenging machine learning problem (Li and
Yuan, 1998). A similar situation arises for ‘text-
less’ language models based on units derived from
raw audio (Lakhotia et al., 2021), welche, like in-
fants, do not have access to isolated words or
word-separating symbols.
The most successful approach to unsupervised
word segmentation for text inputs is based on non-
parametric Bayesian models (Goldwater et al.,
2006, 2009; Kawakami et al., 2019; Kamper
et al., 2017B; Berg-Kirkpatrick et al., 2010;
Eskander et al., 2016; Johnson et al., 2007;
Godard et al., 2018) that jointly segment utterances
and build a lexicon of frequent word forms using
a Dirichlet process. The intuition is that frequent
word forms function as anchors in a sentence,
enabling the segmentation of novel words (wie
‘dax’ in ‘did you see the dax in the street?'). Solch
models are tested on phonemized texts obtained
by converting text into a stream of phonemes af-
ter removing spaces and punctuation marks. Sogar
though phonemized text may seem a reasonable
approximation of continuous speech, such mod-
els have given disappointing results when applied
directly to speech inputs. Since the direct compar-
ison between speech-based and text-based models
was introduced in 2014 by Ludusan et al. (2014),
the gap of performance between these two types
of inputs as documented in three iterations of the
Zero Resource Speech Challenge focused on word
segmentation has remained large (Versteegh et al.,
2016; Dunbar et al., 2020). We attribute these dif-
ficulties to two major challenges posed by speech
compared to text inputs: acoustic variability and
temporal granularity, which we address in our
contribution.
The first and most important challenge is acous-
tic variability. In text, all tokens of a word are
1051
Transactions of the Association for Computational Linguistics, Bd. 10, S. 1051–1065, 2022. https://doi.org/10.1162/tacl a 00505
Action Editor: Mauro Cettolo. Submission batch: 4/2022; Revision batch: 6/2022; Published 9/2022.
C(cid:2) 2022 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
represented the same. In speech, each token of
a word is different, depending on background
noise, intonation, speaker voice, speech rate, Und
so forth. Text-inspired speech segmentation algo-
Rhythmen (Kamper et al., 2017B) apply a clustering
step to word tokens in order to get back to word
types. We believe that this step is unnecessary and
is responsible for the low performance of existing
Systeme, as errors in the clustering step are not
recoverable and negatively impact word segmen-
Station. We propose an algorithm that segments
speech utterances based on an instance lexicon of
word tokens, instead of a lexicon of word types.
Each speech segment instance of the training set
is represented as a distinct memory trace, Und
these traces are used to estimate word form fre-
quency using a k-NN algorithm without having
to refer to a discrete word type but still apply-
ing the same Dirichlet process logic. As for the
representation of these word tokens, we follow
recent approaches that use fixed length Speech
Sequence Embeddings (SSE) (Thual et al., 2018;
Kamper et al., 2017B). We use state-of-the-art
SSEs from Algayres et al. (2022) that have either
been trained in a self-supervised fashion or with
weak labels, in order to assess how the segmen-
tation model behaves with inputs of increasing
Qualität.
The second challenge is related to the fact
that the speech waveform being continuous in
Zeit, the number of possible segmentation points
grows very large, making the optimization of seg-
mentation of large speech corpora using Bayesian
techniques intractable. Some models reduce the
number of segmentation points using phoneme
boundaries (Lee and Glass, 2012; Bhati et al.,
2021), syllable boundaries (Kamper et al., 2017B),
or a constant discretization of the time axis into
speech frames, subject to the following trade-off:
Too coarse frames may miss some short word
boundaries, too fine-grained ones may render seg-
mentation intractable on large corpora because of
the quadratic increase in number of segmentations
with frame rate. Here we choose a compromise
with 40ms frames, corresponding to half of the
mean duration of a phoneme, yielding a 4x the-
oretical slowdown compared to phoneme-based
transcripts. Zusätzlich, we introduce an acceler-
ated version of a Dirichlet process segmentation
algorithm that replaces Gibbs sampling of each
boundary by sampling entire parse trees using
Dynamic Programming Beam Search, and updat-
ing the lexicon in batches instead of continuously.
This achieves a 10-times speed-up compared
to Johnson et al. (2007)’s implementation, mit
similar or superior performances.
Because of our ‘no clustering’ approach, Wir
cannot evaluate our model using the word type-
based metrics of the Zero Resource speech seg-
mentation challenge (Versteegh et al., 2016;
Dunbar et al., 2017). Hier, we use the two classes
of metrics: boundary-related metrics (Token and
Boundary F-score) that do not refer to types,
and high-level word embedding metrics. Die Idee
is use a downstream language model to learn
high level word embeddings and evaluate them
on semantic and Part-Of-Speech (POS) dimen-
sionen. We rely on a semantic similarity task from
Dunbar et al. (2020) and introduce two new
metrics.
The combination of our contributions yields an
overall system, DP-Parse, that sets a new state-
of-the-art on speech segmentation for five speech
corpora by a large margin. By doing various
ablation and anti-ablation studies (replacing unsu-
pervised components by weakly supervised ones)
we pinpoint the components of the system where
there is still margin for improvement. Insbesondere,
we show that using better embeddings obtained
with weak supervision, it is possible to double the
segmentation F-score and substantially improve
our new semantic and POS scores.
2 Related Work
2.1 Speech Sequence Embeddings
Speech Sequence Embedding (SSE) models take
as input a piece of speech signal of any length and
outputs a fixed-size vector. The main objective of
these models is to represent the phonetic content of
a given speech segment. A naive SSE model would
be to extract frame-level features of a speech
sequence, using for
instance Wav2vec2.0 or
HuBERT (Baevski et al., 2020; Hsu et al., 2021),
and mean-pool the frames along the time axis. A
more subtle approach is to train a self-supervised
systems on positive pairs of speech sequences.
The model learns speech sequence representa-
tion thanks to contrastive loss functions (z.B.,
the infoNCE loss as in Algayres et al. [2022];
Jacobs et al. [2021] or the Siamese loss as in
Settle and Livescu [2016]; Riad et al. [2018])
or reconstructive losses (z.B., Correspondance
Auto-Encoder from Kamper [2018] where the first
1052
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
element of the pair is compressed and decoded into
the second element). Kürzlich, a growing body of
work leverage multilingual labeled dataset to build
SSEs that can, to an extent, generalize to unseen
languages (Hu et al., 2020A,B; Jacobs et al.,
2021). In this work, we use a state-of-the-art self-
supervised system SSE model from Algayres et al.
(2022).
2.2 Speech Segmentation
Three main class of models have been proposed to
solve speech segmentation: matching-first models
(Park and Glass, 2007; Jansen and Van Durme,
2011; Hurtad, 2017) attempt to find high quality
pairs of identical segments and cluster them based
on similarity, thereby building a lexicon of word
types that may not cover the entire corpus (Bhati
et al., 2020; R¨as¨anen et al., 2015). Segmentation-
first models try to exhaustively parse a sentence
(Lee et al., 2015; Kamper et al., 2017A,B; Kamper
and van Niekerk, 2020), while jointly learning
a lexicon (and therefore also involving match-
ing and clustering). Segmentation-only models
discover directly the likely word boundaries in
running speech using prediction error (Bhati et al.,
2021; Cuervo et al., 2021), without relying on any
lexicon of word types. Our approach is a new
hybrid of the last two lines of research: Like a
segmentation-first model, we jointly model lex-
icon and segmentation, but our lexicon is not a
lexicon of types, thereby escaping matching and
clustering errors, like in segmentation-only mod-
els. This model shows good performances across
different languages as measured by the Mean
Average Precision on pre-segmented spoken
Wörter.
2.3 Evaluating Speech Segmentation
Across the different word segmentation studies,
the evaluation has been done according to two
general classes of metrics: matching and cluster-
ing metrics for word embeddings (MAP, NED,
grouping F-score, Type F-score), and segmenta-
tion metrics for boundaries (Token and Boundary
F-scores) (Carlin et al., 2011; Ludusan et al.,
2014). All of these metrics presuppose that the
optimal segmentation strategy is aligned with the
text-based gold standard (based on spaces and
punctuation). Noch, it is entirely possible that such
segmentation is not optimal for downstream appli-
Kationen, as witnessed by the fact that most current
language models use subword units like BPEs
Figur 1: The core components of DP-Parse. The al-
gorithm is a loop between two main steps (Schritt 1.
Und 2.) in the spirit of the Expectation Maximization
Algorithmus. Given an initial coarse word segmentation,
we estimate Lw and L0w (d.h., the Dirichlet Process
Parameter) with k-NN density estimation over SSEs.
The estimated parameters are used to derive a new
word segmentation, which in turn serves to re-estimate
Lw and L0w .
or sentence pieces (Devlin et al., 2018). Dort-
Vordergrund, we propose a third class of segmentation
metrics based on downstream language modeling
tasks. Chung and Glass (2018) showed that gold
word boundaries provide sufficient information to
learn good quality semantic embeddings from raw
audio using a skipgram or word2vec objective,
as assessed by semantic similarity benchmarks
adapted to speech inputs. These datasets were also
used to compile the sSIMI benchmark in the Zero
Speech Challenge 2021 (Nguyen et al., 2020), Aber
turn out to give very low and noisy results (mindestens
for small training sets). Hier, we introduce two
new metrics evaluating semantic and grammatical
similarity that we show to be more stable.
3 Method: Instance-based Dirichlet
Process Parsing
This section describes the building blocks and
notations used by DP-Parse as depicted in
Figur 1 und Tisch 1, jeweils. At a high level,
DP-Parse is a new adaptation of Goldwater’s
Dirichlet process algorithm (Goldwater et al.,
2009) for speech inputs. At the heart of Goldwater’s
algorithm is a hierarchical Bayesian model that
generates a joint distribution of a lexicon of words
(a word is a sequence of phonemes) and a corpus
(a sequence of words). The associated learning
1053
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
u
a unit u is a block of 40 ms of speech signal
1, . . . , w0
w = (u0, . . . , uw)
Ew ∈ IRp
C = {v0, . . . , vN }
Cseg = {(w0
D = {w0, …wP }
L0 = {Ew0 , . . . , EwP
}
L = {Ew0 , . . . , Ewn
L0w
}
p0 ), …}
Lw
a segment w is a sequence of units
a fixed length embedding of a segment w computed by a SSE model
a corpus C is a set of utterances (segments without silence found by VAD)
a segmented corpus Cseg is a set of sequences of segments
the list of all possible subsegments in C that are possible words (between 40ms and 800ms)
a kNN index of embeddings from D
a kNN index of all embeddings from the segments in Cseg
the frequency of Ew in L0
the frequency of Ew in L
Tisch 1: Notations used in Section 3.
algorithm optimizes the likelihood of an observed
corpus as a function of the (unobserved) lexicon
and corpus segmentation. It does so by alternat-
ing between two EM steps: (Schritt 1) estimating
the most probable lexicon given a segmentation,
Und (Schritt 2) sampling among the most probable
segmentation given the lexicon. More precisely,
at each Step 1, the algorithm estimates the proba-
bility of a segmentation from two sets of numbers:
the probability P 0
W (w) that a given speech seg-
ment w is a word, and Lw the frequency of a
given word w in the (segmented) input corpus.
They are estimated by building tables of counts
of phoneme-n-grams and words given a segmen-
Station, jeweils. At Step 2, these numbers are
combined using Equation 3 (Abschnitt 3.3) und ein
new segmentation is sampled. Our adjustments to
the original algorithm are the following:
• Section 3.1: Phonemes are replaced by
40ms speech frames (from a pretrained
self-supervised learning algorithm), Wörter
are replaced by fixed-length SSEs (using a
pretrained self-supervised embedder).
• Section 3.2: The tables of counts for com-
puting P 0
W (w) and Lw are replaced by
k-Nearest-Neighbors (k-NN) indexes of em-
beddings (L0, and L, jeweils) which can
be viewed as instance lexicons of all possible
n-frames and of segmented ‘words’, bzw-
aktiv. The count estimates are obtained
using Gaussian kernel density estimation over
k-NN.
• Section 3.3: We make a small adaptation to
theDirichlet process formula.
• Section 3.4: Instead of alternating between
the two steps at each boundary as in the
original Gibbs sampling algorithm, welches ist
very time-consuming, we sample segmenta-
tions over entire utterances using a segment
lattice, and update the lexicon over a batch
of utterances.
• Section 3.5: We initialize the system by se-
lecting as an initial lexicon a list of short
enough utterances, and precompute all the
constant values (L0 and P 0
W (w)) to optimize
for speed.
So modified, the algorithm is no longer depen-
dent on input type and can work either with
discrete representations
represented as
sequences of 1-hot vectors of phonemes) or con-
tinuous ones (Rede, represented as embeddings).
(Text,
3.1 Speech Sequence Embeddings
We represent speech as 20ms frames obtained by
selecting the 8th layer of a pretrained Wav2vec2.0
Base system from Baevski et al. (2020). Jede
two successive frames are tied together so that
a speech sentence is a series of 40ms speech
blocks. To represent a speech segment, wir gebrauchen
the SSE model from Algayres et al. (2022): A
self-supervised system trained with contrastive
learning where positive pairs are obtained by
data-augmentation of the speech signal. Das
model shows good performance across differ-
ent languages as measured by the Mean Average
Precision on pre-segmented spoken words. Der
SSE model
the pre-extracted
Wav2vec2.0 frames and applies a single 1-D con-
volution layer with GLU (kernel size: 4, number of
Kanäle: 512, stride: 1) and a single transformer
takes as input
1054
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
layer (attention heads: 4, size of attention matri-
ces: 512 Neuronen, and feed forward layer: 2048
Neuronen). A final max-pooling layer along the time
axis is applied to obtain a fixed-size vector. To
save computation, we reduce the dimensionality
of Algayres et al.’s (2022) SSE model from 512 Zu
64 with a PCA trained on random speech segments
extracted from the corpus at work.
In addition to their unsupervised SSE model,
Algayres et al. (2022) provide a weakly supervised
Ausführung. They trained it with the same contrastive
loss (infoNCE) using positive pairs obtained with
a time-aligned transcription of the speech signal.
The weakly supervised version will be used as a
topline model, as it scores much higher on Mean
Average Precision than the self-supervised one.
3.2 Density Estimation from
Gaussian-smoothed k-Nearest-Neighbors
In text, the exact frequency of a string of letters can
be computed by counting how often it occurs in
the corpus. In speech, due to acoustic variability,
most of the counts would be 1, and clustering
methods cause too many errors to obtain reliable
count estimates (more details in Appendix A.2.1).
Hier, we follow the method in Algayres et al.
(2020) using Gaussian filtering over k-NNs. Let
us assume that all speech segments w of a corpus
are represented as embeddings Ew and stored in
a k-NN index L0. To compute L0w the frequency
of w in L0, we extract the k nearest-neighbors of
Ew: (E1, . . . , Ek)2 and sum over them, weighted
by a decreasing function of their distance to w.
Intuitively, embeddings close to Ew are more
likely to be instances of the same segments than
distant ones. For weighting, we use a Gaussian
kernel centred on Ew as in the following equation:
L0w
≈ F (w) =
k(cid:2)
j=1
exp−β(cid:5)Ew−Ej (cid:5)2
2
(1)
F is the Parzen-Rosenblatt window method for
density estimation (Parzen, 1962) and returns a
continuous value between 0 and k, estimating
L0w . It rests on two hyper-parameters: k, welche
is set to 1000, and β, the standard deviation of
the Gaussian kernel. To set β, we follow the
observation from Algayres et al. (2022): Around
50% of the segments in the development dataset
2We remove from the list the embeddings corresponding
to overlapping segments.
of the Zerospeech Challenge 2017 appear to have
a frequency of one. daher, we set β during
runtime so that 50% of the L0w calculated get a
frequency of one (d.h., an F value below a small
(cid:3) > 0). We did not change these hyper-parameters
for any of the tested languages.
3.3 Dirichlet Process Formula
This section explains how Goldwater et al. (2009)
formulate the Dirichlet Process and our modifica-
tion. Let v(cid:6) be a non silent section from a speech
corpus C found by a Voice Activity Detection
(VAD). A segmentation of v(cid:6) is written v(cid:6)
seg and
is composed of a series of segment (w1, . . . , wl).
The probability of v(cid:6)
seg is, under the unigram hy-
pothesis, the product of the probability of each
segment to be a real spoken word:
PS(S(cid:6)
seg) =
l(cid:3)
i=0
PW (wi)
(2)
To model the probability of a segment w to be
a real word, Goldwater et al. (2009) use the
following formulation of the Dirichlet Process:
PW (w|C, Cseg) =
Lw
#L + α0
+
α0P 0
W (w)
#L + α0
(3)
The first term of Equation 3 accounts for how
often the token w has been segmented in Cseg.
Its numerator Lw is the count estimate of w in
L. The second part of Equation 3 is the intrinsic
probability of w to be a word regardless of its
appearance in Cseg. This intrinsic probability is
called the base distribution P 0
W and is controlled
by the concentration parameter α0.
To find a formulation for P 0
W , the intuition
from Goldwater et al. (2009) is simple: frequently
appearing tokens are more likely to be true words
than rare ones. Noch, their formulation of P 0
W cannot
be easily adapted to the segmentation of speech
Daten. Our contribution here is to propose a new
formula for P 0
W that follows the same intuition:
P 0
W (w) =
L0w
#L0
(4)
where L0w is the count estimate of w in L0 (Die
lexicon of all possible segments in C). #L0 being
the total number of segments in L0, P 0
W is then
the probability to find w in among the tokens
in C.
1055
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
3.4 Segmentation Lattice
In Goldwater et al. (2009), the learning algorithm
uses Gibbs sampling, where word boundaries are
sampled one at a time, requiring all parameters
of the Dirichlet Process model to be recomputed
after each sample. On text data, it is not a problem,
as updating the model’s parameters (Lw and L0w )
is fast: No k-NN search is needed, Parameter
are computed exactly by matching and count-
ing strings. It becomes a bottleneck for speech
segmentation where the parameters are computed
with density estimation and k-NN search. Eins
way to alleviate this problem is to incorporate
the dynamic programming version of the Gibbs
sampler from Mochihashi et al. (2009). Ein anderer
Weg, as in this paper, is to build a segmentation
lattice over each utterance and sample among the
n-best segmentations.
Hier, we assume that the corpus C has been
pre-segmented in a set of utterances using a VAD
Algorithmus. After each Step 1 from Figure 1 we can
compute the log probability, log(PW (w)) aus
Gleichung 3, that each token in an utterance is
a real word. Noch, instead of directly using this
probability, we introduce a per-token penalty score
that favors short tokens:
(cid:4)
(cid:5)
Q(X) =
γ
x − 1
δ
(5)
This penalty is added to the Dirichlet process log
probability as follows:
S(w) = log(PW (w) + (cid:3)) + Q(len(w))
(6)
Wo (cid:3) is a very small number to handle cases
where PW (w) = 0, len(w) is the number of 40ms
speech frames in w.
For each utterance in C, we create a segmen-
tation lattice that provides a compact view for
all possible segmentation paths. A segmentation
path is a sequence of consecutive segmentation
arcs that covers the full utterance. Each arc starts
and finishes in-between the units and is bounded
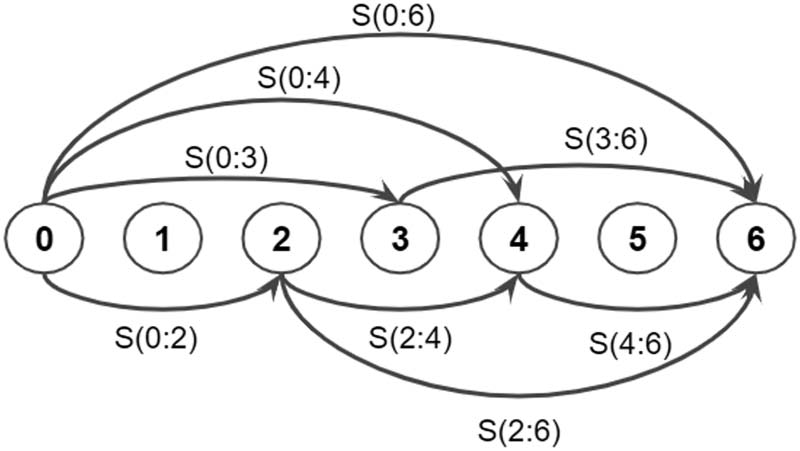
within a minimal and maximal length. An ex-
ample of a segmentation lattice can be found in
Figur 2. Each segmentation arc is associated with
its S score from Equation 6. For each utterance, Die
n-best segmentations are computed with Dynamic
Programming Beam Search, and we sample from
a softmax of their total S scores. One advantage
of this procedure is that it is possible to parallelize
utterance segmentation across large batches and
Minimum segment length
Maximum segment length
NEIN. of segments in L0
Concentration parameter α0 (eq. 3)
NEIN. of neighbors in k-NN (eq. 1)
Lattice beam size
Duration penalty q (eq. 5)
40MS
800MS
1M
100
100
10
γ = 1.8
δ = 2 (Text)
δ = 4 (Rede)
Tisch 2: DP-Parse hyper-parameters.
only update the lexicon L after each batch. In our
experiments, we take the entire corpus C to be a
single batch.
3.5 Initializing DP-Parse
We create a corpus C as a collection of utterances
by applying the pyannote VAD (Bredin et al.,
2019) with a threshold of 200 MS. Wie gezeigt in
Figur 1, initialization (Schritt 0) contains several
sub-steps. Der erste (0.1) is to provide an initial
segmentation of C, using a simple heuristic: Alle
sentences shorter than 800ms are treated as word
tokens, the other ones are discarded. The intuition
is that short sentences could be words in isolation,
which provides the seed for an initial lexicon.
The second sub-step (0.2) is to create the list
D composed of the embeddings of all possible
speech segments in C that are possible words,
which we set to be anything between 40ms and
800MS (by 40ms increments). To embed a speech
segment, we use the SSE model in Section 3.1.
In der Praxis, we found that
The third sub-step (0.3) consists in the construc-
tion of L0: a k-NN index of all embedded segments
in D.
randomly
subsampling D to one million embedded seg-
ments worked well (see grid-search in Appendix
A.2.2), and we precompute L0w as explained in
Abschnitt 3.2.
4 Evaluation Metrics and Settings
4.1 Boundary Level Segmentation Metrics
In the Zerospeech Challenge 2017 (Dunbar et al.,
2017), two metrics measure how well discovered
boundaries match with the gold word boundaries.
These metrics, the Boundary and Token F-score,
are obtained by comparing the discovered sets of
tokens to the gold one obtained by force-aligning
spoken sentences with their transcription. Der
evaluation is done in phoneme space and each
discovered boundary is mapped to a real phoneme
boundary: If a boundary overlaps a phoneme by
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
1056
Figur 2: An example of a segmentation lattice for
a small utterance of 6 Einheiten, with a constraint on
word tokens to be bounded between 2 Und 6 Einheiten. A
segmentation path is a sequence of segmentation arcs
that covers the whole utterance. Each arc starts and
ends in-between units and is associated with its score
S from Equation 6.
more than 30ms or more than half of the phoneme
Länge, the boundary is placed after that phoneme
(otherwise it is placed before).
4.2 Semantic and POS Embedding Metrics
The idea here is to evaluate segmentation through
its effect on a downstream language model. Der
evaluation is less direct than the segmentation
metrics above, as it assumes that the segmentation
is used to turn a spoken utterance into a series
of fixed size SSEs, themselves used to train a
continuous-input Speech Language Model (LM).
The metrics will therefore reflect each of these
components (segmentation, SSE, Speech LM), Aber
by keeping the SSE and Speech LM components
constants, we can hope to study systematically
the effect of the segmentation component. Unser
evaluation focuses on word-level representations,
which we call here High-Level Speech Embed-
dings (HLSE). They are the speech equivalent of
Word2Vec representations (Mikolov et al., 2013),
yet coming from an inexact segmentation. Hier,
we assume that a Speech LM has been trained
on SSE inputs on a given dataset with a given
segmentation and can be used at test time to pro-
vide embeddings associated to a set of test words.
As our segmentation models work on whole ut-
terances, we present the test words in continuous
utterances and then mean pool the HLSEs from
the Speech LM that overlap with that word to ob-
tain a single vector. An overview of the building
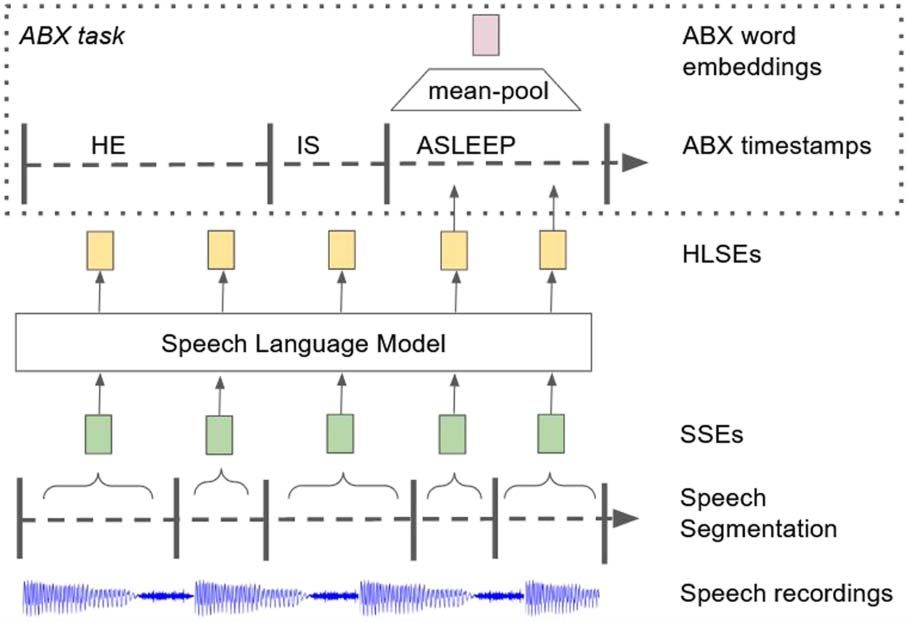
of generic HLSEs and their evaluation is shown
in Abbildung 3.
We introduce two zero-shot tasks to evalu-
ate HLSEs that do not require training a further
Figur 3: Method for deriving HLSEs for semantic and
POS evaluations. Speech is segmented and converted
into SSEs before being used to train a Speech LM. Bei
test time, the HLSEs that overlap with the ABX times-
tamps by more than 40ms are mean-pooled to form the
ABX word embeddings (here the word ‘asleep’).
classifier, and are purely based on distances be-
tween these embeddings. They are based on
machine-ABX, a type of distance-based metric
introduced in Schatz et al. (2013) which computes
a discrimination score over sets of (A, B, X)
triplets. For each triplet, A and X belong to the
same category and B plays the role of a distractor.
The task for the model is to find the distrac-
tor in each triplet based on the cosine distance
between the HLSEs of A, B, and X. Der erste
Aufgabe (ABXsem), have A and X to be synonyms
whereas B is semantically unrelated to neither A
or X. The second task, ABXP OS, have A and
X share the same POS-tags whereas B has a dif-
ferent one. The triplets are all extracted from the
Librispeech corpus training set. See Appendix A.1
for details on the construction of the triplets.
Another task, sSIMI from Nguyen et al. (2020),
also evaluates high-level representations of spo-
ken words in a zero-shot and distance-based
Mode. Noch, sSIMI differs from our ABX tasks
in two important ways. Erste, sSIMI presents test
words as pre-segmented chunk of speech without
the context of the original sentence to help the
Speech LM. Zweite, the task for the Speech LM
is to predict a semantic similarity score given
by human annotators to pairs of words. Der
Speech LM encodes the pre-segmented spoken
words into HLSEs and the distance between the
HLSEs is correlated with the human judgements.
The correlation coefficient r is used as the final
sSIMI score.
1057
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
4.3 Datasets and Experimental Settings
The Zerospeech Challenge 2017 (Dunbar et al.,
2017) provides five corpora to evaluate speech
segmentation systems. These corpora are com-
posed of speech recordings from different lan-
guages split into sentences using Voice Activity
Detection. Three corpora (Mandarin, 2h30; En-
glish, 45H; French, 24H) are used for development,
and two ‘surprise’ corpora for testing (Deutsch,
25H; Wolof, 10H). On each corpus, a separate SSE
model from Algayres et al. (2022) is trained and
a separate run of DP-Parse is performed to pro-
duce a full-coverage segmentation. DP-Parse’s
hyper-parameters from Table 2, as well as q’s
Formel (Gleichung 5), were grid-searched to max-
imize token-F1 segmentation scores over the
three development datasets. The two remain-
ing test sets are used to show generalization of
DP-Parse to new unseen languages. More details
on hyper-parameter search is found in Appendix
A.2.2.
For the ABX and sSIMI tasks, we train a BERT
model as a Speech LM on the training set of
the Librispeech dataset (Panayotov et al., 2015),
zusammengesetzt aus 960 hours of English recordings.
We proceed by first training a SSE model from
Algayres et al. (2022) on the Librispeech. Dann,
this latter dataset is segmented using DP-Parse.
Each segmented speech sequence is aggregated
into a single vector using the pre-trained SSE
Modell. Segmented sentences are used to train a
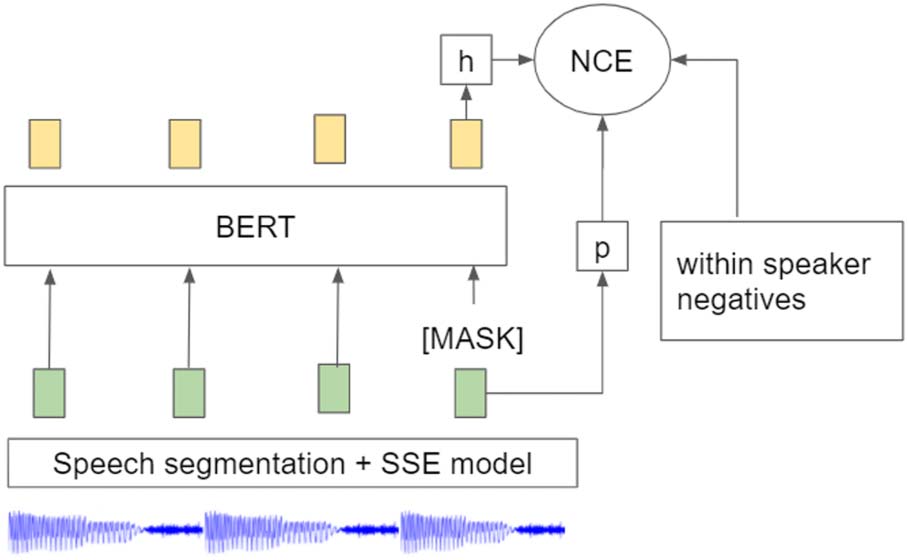
BERT model with masked language modeling
and the Noise Contrastive Estimation (NCE) loss
(Gutmann and Hyv¨arinen, 2010) (siehe Abbildung 4).
The BERT model is composed of 12 layers, 12
attention heads per layer with 768 neurons each
and a FFN size of 3072 Neuronen. To compute the
NCE, two heads p and h are composed respec-
tively of one fully connected linear layer with
256 neurons and two fully connected layers with
ReLU activation with also 256 Neuronen. Batches
are composed of utterances from a single speaker,
und das 200 negative samples for the NCE are
chosen within the batch. Fifteen percent of SSEs
are masked in each batch during training. Only the
BERT is trained, gradients are not propagated into
the SSEs. As BERT is a multi-layer transformer
Modell, the scores for ABX tasks and sSIMI are
obtained by grid-searching the layer that performs
best on the dev set of each task and evaluating
that same layer on the corresponding test sets.
Figur 4: Our method to train a BERT model on SSEs.
Speech is segmented into segments that are converted
into vectors by a frozen SSE model. BERT is trained
with the NCE loss. p and h are used to project vectors
into a common space to compute the NCE objective.
The negative samples are random SSEs from the same
speaker.
Mandarin
(2h30)
French
(24H)
DP Unigram
DP-Parse
61m39s
0m55s
240m44s
25m12s
English
(45H)
62m11s
62m11s
Speed-up factor
67.3
9.6
9.8
Tisch 3: Time performances on 8 CPUs for the
standard configuration of DP-Parse (10 Iterationen)
and the Dirichlet Process Unigram (2000 itera-
tionen) implemented by Johnson et al. (2007).
The development and test sets for the ABX tasks
are composed of triplets of sentences extracted
from the training set of the Librispeech corpus.
For sSIMI, the development and test set both
contain two subsets: one with spoken words ex-
tracted from the Librispeech training set and one
with spoken words synthesized with WaveNet
(van den Oord et al., 2016).
5 Ergebnisse
5.1 Results on Word-level Segmentation
Regarding text segmentation, DP-Parse compares
favorably to the original Dirichlet Process Un-
igram model from Goldwater et al. (2009). Es
produces a 21-point increase in token F1 com-
pared with the original version (Und 3 points
increase in boundary F score) for a 10× runtime
speed-up (Tisch 3) under the Adaptor Grammar
implementation of Johnson et al. (2007).
Regarding speech segmentation, we compare
DP-Parse with the three best speech segmentation
1058
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Modell
Mand.
Dev
French
Engl.
Test
German Wolof
avg.
Mand.
Dev
French
Engl.
Test
German Wolof
Token F1 ↑
Boundary F1 ↑
10.7
4.4
12.1
8.1
16.0
28.2
11.7
5.1
8.3
6.30
15.3
30.9
9.8
4.1
8.6
19.2
21.9
31.3
5.4
3.0
7.5
14.5
13.4
34.4
12.4
4.2
14.8
10.9
17.5
39.2
10.0
4.2
10.3
11.8
16.8
35
52.4
49.1
52.2
54.5
59.3
69.9
49.4
46.3
48.4
43.3
55.9
70.0
48.2
43.7
46.1
56.7
60.0
68.4
41.3
38.1
40.9
52.3
51.5
64.4
55.0
40.6
54.2
52.8
59.0
75.5
avg.
49.2
43.6
48.4
51.9
57.1
69.4
Speech data
Every 120ms
Syllables×
SEA+
ES-Kmeans∨
DP-Parse∗
DP-Parse∗
+ weak sup.
Text data
DP Unigram‡
DP-Parse∗
34.9
50.0
57.0
68.1
64.7
78.5
33.6
67.4
38.8
69.1
45.7
66.6
79.5
76.0
86.1
84.3
88.9
89.8
71.6
83.5
77.3
84.1
80.7
83.5
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Tisch 4: Token and Boundary F1 scores (the higher, the better) for speech and text segmentation models
across development and test set from the Zerospeech Challenge 2017. The average scores are computed
over the five datasets. *: ours, ×: R¨as¨anen et al. (2015), +: Bhati et al. (2020), ∨: Kamper et al. (2017B),
‡: Goldwater et al. (2009).
models submitted at the Zerospeech Challenge
2017 (Bhati et al., 2020; Kamper et al., 2017B;
R¨as¨anen et al., 2015). Tisch 4 reports the token F1
and boundary F1 obtained by these models over
Die 5 datasets of the Zerospeech Challenge 2017.
Across all corpora, DP-Parse outperforms its com-
petitors by at least 5 points in both boundary and
token F1. We also introduce a naive baseline that
draws boundaries every 120 milliseconds, disre-
garding the content of the speech signal. It turns
out to be surprisingly competitive with all speech
segmentation systems except DP-Parse. Letzteres
is the only existing speech segmentation system
that beats the naive baseline on all languages.
Most speech segmentation systems from the
Zerospeech Challenge 2017 rely on off-the-shelf
self-supervised representations of speech. Der
hope is that, without modification, these systems
would benefit from future improvements in speech
representations and mechanically lead to higher
segmentation scores. Noch, such hopes have never
been guaranteed by explicit experiments. Hier, Wir
test for the ability of DP-Parse to improve with bet-
ter inputs. For that, we use the weakly supervised
version of the SSE model from Algayres et al.
(2022) trained with 10 hours of labelled speech
Daten. On this type of input, DP-Parse doubles its
token F1 score.
5.2 Results on Semantic and POS Metrics
In Table 5, the segment-based sections show how
a BERT model can benefit from speech segmen-
tation and SSE modeling on the tasks ABXsem,
ABXP OS and sSIMI. To do that, we trained
BERT models along the pipeline depicted in
Figur 4.
Let us first analyze the scores on the ABX tasks.
The section unsupervised, segment-based shows
that DP-Parse and two less-performant segmen-
tation strategies lead to comparable ABX scores.
Noch, the weak supervision section shows that by
improving the quality of the SSEs with weak su-
pervision, DP-Parse performs higher than other
segmentation methods. The partial supervision
section shows that with either perfect word bound-
aries or perfect segment representation (1-hot
vectors), the ABX scores increase even more.
Endlich, the full supervision is regular text-based
LM that serves as a topline model.
As baseline systems, we propose frame-based
approaches that do not use speech segmenta-
tion nor SSEs. Speech-to-frames models like
Wav2vec2.0, HuBERT, or CPC (Baevski et al.,
2020; Hsu et al., 2021; van den Oord et al., 2019)
are trained with masked language modeling in the
spirit of text-based LM but on the raw speech
signal. daher, these models should have al-
ready acquired some knowledge of semantics
and POS-taggings. We evaluate speech-to-frames
models directly on ABXsem, ABXP OS and
sSIMI. To do that, we simply skip the Speech LM
as well as the segmentation and SSE steps from
the method in Figure 3. Speech-to-frames models
are used to encode the whole speech sentences
from the ABX triplets, and the frames within the
word boundaries provided by the ABX tasks are
mean-pooled to form the HLSEs. The results show
that Wav2vec2.0 Large and HuBERT Large are
1059
Input
Segments
SSE
BERT
Dev Set
Test Set
Darstellungen
CPC+
W2V2 base×
HuBERT base‡
W2V2 large×
HuBERT large‡
No supervision, frame based
–
–
–
–
–
–
–
–
–
–
W2V2 base [8]×
W2V2 base [8]×
W2V2 base [8]×
No supervision, segment based
unsup†
unsup†
unsup†
120MS
Syllables∨
DP-Parse
W2V2 base [8]×
W2V2 base [8]×
W2V2 base [8]×
Weak supervision, segment based
weak-sup†
weak-sup†
weak-sup†
120MS
Syllables∨
DP-Parse
Partial supervision, segment based
W2V2 base [8]×
W2V2 base [8]×
Text
gold words
gold words
DP-Parse
unsup†
weak-sup†
1-hot
Full supervision, segment based
Text
gold words
1-hot
–
–
–
–
–
(cid:2)
(cid:2)
(cid:2)
(cid:2)
(cid:2)
(cid:2)
(cid:2)
(cid:2)
(cid:2)
(cid:2)
ABXsem ↑
ABXP OS ↑
ABXsem ↑
ABXP OS ↑
51.22 [2]
54.96 [8]
54.65 [8]
57.69 [13]
58.04 [23]
59.65 [7]
59.09 [6]
61.09 [8]
59.64 [8]
61.44 [6]
64.24 [8]
67.89 [5]
71.38 [5]
75.38 [4]
53.67 [2]
55.78 [8]
55.65 [8]
59.86 [13]
57.77 [23]
70.66 [7]
68.58 [6]
68.15 [7]
70.04 [8]
70.89 [7]
72.65 [7]
75.46 [7]
77.75 [6]
78.57 [4]
53.86 [2]
56.20 [8]
55.12 [8]
58.88 [13]
58.95 [23]
58.64 [7]
58.49 [6]
62.73 [8]
59.43 [8]
60.28 [6]
64.82 [8]
67.17 [5]
71.04 [5]
74.89 [4]
54.68 [2]
56.86 [8]
56.77 [8]
60.93 [13]
57.19 [23]
71.68 [7]
68.81 [6]
69.35 [7]
70.58 [8]
71.03 [7]
72.67 [7]
75.61 [7]
77.64 [6]
78.49 [4]
Dev Set
sSIMI ↑
Test Set
sSIMI ↑
6.14 [2]
3.85 [9]
3.53 [8]
2.04 [11]
4.14 [7]
4.10 [9]
0.96 [9]
4.54 [5]
5.83 [7]
0.51 [9]
5.19 [9]
4.34 [2]
5.21 [9]
0.68 [8]
6.82 [11]
0.55 [7]
4.19 [9]
3.48 [9]
3.49 [5]
5.81 [7]
0.79 [9]
4.51 [9]
6.82 [5]
2.72 [5]
21.42 [2]
6.30 [5]
6.83 [5]
19.54 [2]
83.23 [3]
81.07 [3]
84.12 [3]
80.09 [3]
41.78 [1]
36.83 [1]
Tisch 5: Semantic and Part-of-Speech discrimination scores (the higher, the better). Segment-based
models compute SSEs for each segment (obtained by speech segmentation) on which a BERT model is
trained with a NCE loss. Frame-based models are pre-trained baseline models without speech segmen-
tation nor BERT training. sSIMI scores are average over the Librispeech and synthetic subsets. Layers
used are given between brackets. +:van den Oord et al. (2019), ×:Baevski et al. (2020), ‡:Hsu et al.
(2021), ∨: R¨as¨anen et al. (2015), †: Algayres et al. (2022).
strong baseline systems for our ABX metrics. Noch,
they score in average below the segment-based
approaches.
Regarding the scores obtained on sSIMI from
Nguyen et al. (2020), the table of results (Tisch 5)
shows important downsides on this task compared
to our ABX tasks. Erste, the scores sometimes
show large inconsistencies across development
and test sets, which is not the case for the ABX
tasks. Zweite, while our ABX tasks are sensi-
tive to improvements in speech segmentation and
SSE modeling, sSIMI is not and show comparable
scores across most sections of Table 5. One reason
for that could be that self-supervised speech sys-
Systeme (Wav2vec2.0, HuBERT, and CPC) sowie
as SSE models from Algayres et al. (2022) Sind
not trained to encode short sequence of speech,
especially extracted as chunks from a sentence.
6 Conclusion and Open Questions
We introduce a new speech segmentation pipeline
that sets the state-of-the-art on the Zerospeech’s
datasets at 16.8 token F1. The whole pipeline
needs no specific tuning of hyper-parameters,
making it ready to use on any new languages. Wir
showed that the problem of speech segmentation
can be reduced to the problem of learning dis-
criminative speech representations. In der Tat, verwenden
different level of supervision, our pipeline reaches
up to 35 token F1 score. daher, as long as
the field of unsupervised representation learning
makes headway, this method should automatically
produce higher token F1 scores.
A first avenue of improvement of the current
work is in the SSE component. Hier, we took
the system described in Algayres et al. (2022) out
of the box, and we showed good performance in
speech segmentation compared to the state of the
Kunst, but there was still a large margin of improve-
ment compared to text-based system. A recent
unpublished paper (Kamper, 2022) came to our
attention based on the non-lexical principle and
showed similar or slightly better results than ours
on a subset of the ZR17 language. Kamper (2022)
also uses a segmentation lattice that resembles ours
for inference. Noch, as we have shown, our system
is monotonous with input embedding quality, Und
can therefore reach much better performance if
the speech sequence embedding component were
better trained. Further work is needed to improve
the SSE component based on purely unsupervised
Methoden.
Despite our computational speedup, our current
system would face challenges to scale up the ap-
proach to larger datasets than Librispeech. Während
it uses FAISS, an optimized search library, es ist
unclear that storing each instance of a possible
1060
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
0
5
2
0
4
5
1
9
6
/
/
T
l
A
C
_
A
_
0
0
5
0
5
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
segment is necessary. One interesting avenue of
research would therefore be to downsample both
instance lexicons to alleviate space complexity
and/or to trade storage with compute by recal-
culating the embeddings on-line.
Another interesting improvement would be
to compute bigram probabilities instead of un-
igram probabilities, as previously explored in
Goldwater et al. (2009). Noch, this possibility looks
challenging, as explained in Appendix A.2.3.
Endlich, our method showed promising results
in terms of semantic and POS encoding when
taken as a preprocessor for a language model.
Such a phenomenon is displayed by our new
in-context semantic tasks, but not by a previous
without-context semantic task from Nguyen et al.
(2020). Further work is needed to show whether
this can translate into high quality generations
when used as a component to generative systems
(Lakhotia et al., 2021).
A Appendix
A.1 Construction of Triplets for ABXsem
and ABXP OS
ich , ta
ich , ea
ich , sa
Let’s write the series of triplet from our ABX
tasks: (Ai, Bi, Xi)0≤i