An End-to-End Contrastive Self-Supervised Learning Framework for
Language Understanding
Hongchao Fang, Pengtao Xie∗
University of California San Diego, USA
p1xie@eng.ucsd.edu
Abstrakt
Self-supervised learning (SSL) methods such
as Word2vec, BERT, and GPT have shown
great effectiveness in language understanding.
Contrastive learning, as a recent SSL approach,
has attracted increasing attention in NLP. Con-
trastive learning learns data representations by
predicting whether two augmented data in-
stances are generated from the same original
data example. Previous contrastive learning
methods perform data augmentation and con-
trastive learning separately. Infolge, Die
augmented data may not be optimal for con-
trastive learning. To address this problem, Wir
propose a four-level optimization framework
that performs data augmentation and contras-
tive learning end-to-end, to enable the aug-
mented data to be tailored to the contrastive
learning task. This framework consists of four
learning stages, including training machine
translation models for sentence augmentation,
pretraining a text encoder using contrastive
learning, finetuning a text classification model,
and updating weights of translation data by
minimizing the validation loss of the classifi-
cation model, which are performed in a unified
Weg. Experiments on datasets in the GLUE
benchmark (Wang et al., 2018A) and on da-
tasets used in Gururangan et al. (2020) dem-
onstrate the effectiveness of our method.
1
Einführung
Self-supervised learning (Bengio et al., 2000;
Mikolov et al., 2013; Devlin et al., 2019; Radford
et al., 2018; Lewis et al., 2020), which learns
data representations by solving prediction tasks
defined on input data without leveraging human-
provided labels, has achieved broad success in
NLP. Many NLP-specific self-supervised learn-
ing (SSL) methods have been proposed, wie zum Beispiel
neural language models (Bengio et al., 2000),
Word2vec (Mikolov et al., 2013), BERT (Devlin
et al., 2019), GPT (Radford et al., 2018), BART
∗Corresponding author.
(Lewis et al., 2020), und so weiter, with various
SSL tasks defined. Zum Beispiel, in Word2vec and
BERT, the SSL task is predicting the identities
of masked tokens based on their contexts. In neu-
ral language models including GPT, the SSL task
is language modeling: Given a history of tokens,
predict the next token.
Kürzlich, contrastive self-supervised learning
(He et al., 2020; Chen et al., 2020) has been
borrowed from vision domains into NLP and has
shown promising success in predicting seman-
tic textual similarity (Gao et al., 2021), machine
Übersetzung (Pan et al., 2021), relation extraction
(Su et al., 2021), und so weiter. The key idea of con-
trastive self-supervised learning (CSSL) Ist: Create
augments of original examples, then learn repre-
sentations by predicting whether two augments
are from the same original data example. In ex-
isting CSSL approaches, data augmentation and
contrastive learning are performed separately. Als
ein Ergebnis, augmented data may not be optimal for
contrastive learning. Zum Beispiel, considering a
back-translation (Sennrich et al., 2016)–based
augmentation method, if the translation model is
trained using news corpora, it is not suitable for
augmenting data for movie review data.
In diesem Papier, we aim to address this issue. Wir
propose a four-level optimization framework that
performs data augmentation and contrastive learn-
ing end-to-end in a unified way, to allow the data
augmentation models to be guided by the con-
trastive learning task and make augmented data
suitable for performing contrastive learning. Wir
assume the end task is text classification. Unser
framework consists of four learning stages. Bei der
first stage, we train four translation models to per-
form sentence augmentation based on back trans-
lation. To account for the fact that translation data
used at this stage and text classification data used
in later stages have a domain discrepancy, Wir
perform reweighting of translation data;
diese
weights are tentatively fixed at this stage and will
1324
Transactions of the Association for Computational Linguistics, Bd. 10, S. 1324–1340, 2022. https://doi.org/10.1162/tacl a 00521
Action Editor: Dipanjan Das. Submission batch: 9/2021; Revision batch: 5/2022; Published 11/2022.
C(cid:3) 2022 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
be updated at a later stage. At the second stage,
we pretrain a text encoder using contrastive learn-
ing on augmented sentences created by the trans-
lation models. At the third stage, we finetune a
text classification model, using the text encoder
pretrained at the second stage as regularization.
At the fourth stage, we measure the performance
of the text classifier on a validation set and up-
date weights of translation data by maximizing
the validation performance. Each level of opti-
mization problem in our framework corresponds
to a learning stage. These stages are performed
end-to-end. Experiments on datasets in the GLUE
benchmark (Wang et al., 2018A) and on datasets
used in Gururangan et al. (2020) demonstrate the
effectiveness of our method.
The major contributions of this paper include:
• We propose
A
four-level optimization
framework to perform contrastive learning
(CL) and data augmentation end-to-end. Unser
framework enables the training of augmen-
tation models to be guided by the CL task
and makes augmented data suitable for CL.
• We demonstrate the effectiveness of our
method on datasets in the GLUE benchmark
(Wang et al., 2018A) and on datasets used in
Gururangan et al. (2020).
2 Related Works
2.1 Contrastive Learning in NLP
Kürzlich, contrastive learning has received in-
creasing attention in NLP. Gao et al. (2021)
proposed a simple contrastive learning–based
sentence embedding method. In this method, Die
same input sentence is fed into a pretrained
RoBERTa (Liu et al., 2019) model twice by ap-
plying different dropout masks and the result-
ing two embeddings are labeled as being similar.
Embeddings of different sentences are labeled as
dissimilar. Pan et al. (2021) proposed a contras-
tive learning method for many-to-many multilin-
gual neural machine translation, where contrastive
learning is leveraged to close the gap among
representations of different languages. Su et al.
(2021) developed a contrastive learning method
for biomedical relation extraction, where linguis-
tic knowledge is leveraged for data augmentation.
Wang et al. (2021) proposed to construct seman-
tically negative examples to perform contrastive
learning, for the sake of improving the robust-
ness against semantical adversarial attacks. Pan
et al. (2022) proposed to perform contrastive
learning on adversarial examples generated by
perturbing word embeddings, in order to learn
noise-invariant representations.
2.2 Contrastive Self-Supervised Learning in
Non-NLP Domains
Contrastive self-supervised learning has been
broadly studied recently in other domains be-
sides NLP. Henaff (2020) proposed a contrastive
predictive coding method for data-efficient clas-
sification. In this method, autoregressive models
are leveraged to predict the future in a latent
Raum. Khosla et al. (2020) proposed a supervised
contrastive learning method. Data examples hav-
ing the same class label are made close to each
other in the latent space while examples with
different class labels are separated farther apart.
Laskin et al. (2020) proposed a method to learn
contrastive unsupervised representations for rein-
forcement learning. In Klein and Nabi (2020), A
contrastive self-supervised learning approach is
proposed for commonsense reasoning.
2.3 Bi-level Optimization
framework is a multi-level optimization
Unser
Rahmen, which is an extension of bi-level op-
timization (BLO). BLO (Dempe, 2002) has been
applied for many applications in NLP, wie zum Beispiel
neural architecture search (Liu et al., 2018), hy-
perparameter tuning (Feurer et al., 2015), Daten
reweighting (Shu et al., 2019; Ren et al., 2020;
Wang et al., 2020), label denoising (Zheng et al.,
2021), learning rate adjustment (Baydin et al.,
2018), meta learning (Finn et al., 2017), data gen-
eration (Such et al., 2020), und so weiter. In these
BLO-based methods, meta parameters (neural ar-
chitectures, hyperparameters, importance weights
of training data examples, usw.) are learned by
minimizing a validation loss and weight parame-
ters are optimized by minimizing a training loss.
3 Method
In diesem Abschnitt, we present our proposed end-to-end
contrastive learning framework.
3.1 Overview
We use back-translation (Sennrich et al., 2016)
to perform data augmentation of sentences. Dann
1325
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 1: Illustration of our framework.
on augmented sentences, contrastive learning is
durchgeführt. Two augmented sentences are labeled
as similar if they originate from the same original
Satz. Two augmented sentences are labeled as
dissimilar if they originate from different original
Sätze. Contrastive losses (Hadsell et al., 2006)
are defined on these similar and dissimilar pairs.
A text encoder is pretrained by minimizing the
contrastive losses.
We assume the end task is text classification.
Our framework consists of the following learn-
ing stages, which are performed end-to end. Bei
the first stage, we train four translation models
to perform data augmentation using back trans-
lation. Each translation pair in the training set is
associated with a weight. At the second stage, An
augmented sentences created by the translation
Modelle, we perform contrastive learning to train a
text encoder. At the third stage, using the encoder
trained at the second stage as regularization, Wir
finetune a text classification model. At the fourth
stage, the classification model trained at the third
stage is evaluated on a validation classification
dataset and the weights of translation pairs at the
first stage are updated by minimizing the valida-
tion loss. The four stages are performed in a four-
level optimization framework. Figur 1 illustrates
our framework. Nächste, we describe the four stages
in detail.
3.2 Stage I: Training Machine Translation
Model for Sentence Augmentation
Figur 2 shows the workflow of data augmenta-
tion. For an input sentence x, we augment it us-
ing back-translation (Sennrich et al., 2016). In our
experiments, the language of the classification
data is English. We use an English-to-German
maschinelle Übersetzung (MT) model to translate x
to y. Then we use a German-to-English MT
model to translate y to x(cid:4). Then x(cid:4) is regarded as
Figur 2: The workflow of data augmentation based on
back translation.
an augmented sentence of x. Ähnlich, we use an
English-to-Chinese MT model and a Chinese-to-
English MT model to obtain another augmented
sentence x(cid:4)(cid:4). We use German and Chinese as the
two auxiliary languages because 1) both of them
are resource-rich languages that have abundant
translation data for model training; 2) they are
sufficiently different from each other to achieve
higher diversity in augmented examples.
ich
To perform data augmentation based on back
Übersetzung, we train four machine translation (MT)
Modelle: English-to-German, German-to-English,
English-to-Chinese, and Chinese-to-English. Let
Weg, Wge, Wec, and Wce denote these four MT
Modelle, and let Deg = {D(eg)
}N (eg)
i=1 , Dge =
ich
{D(ge)
i=1 , Dec = {D(ec)
}N (ge)
}N (ec)
i=1 , and Dce =
ich
{D(ce)
}N (ce)
denote the corresponding datasets
i=1
ich
used to train these four models. Some trans-
lation data have a large domain discrepancy
with the text classification data and should be
excluded from training the translation models.
Ansonsten, the translation models trained using
such out-of-domain translation data may not be
able to generate meaningful augmentations for
the text classification data due to the domain dis-
crepancy. To identify and remove out-of-domain
, and d(ce)
translation data, for d(eg)
, D(ec)
,
ich
ich
, A(ec)
, A(ge)
we associate them with weights a(eg)
,
ich
ich
und ein(ce)
, which are in [0, 1]. If the weight is close
ich
Zu 0, it means that the corresponding example
has a large domain discrepancy with classification
texts and should be excluded from training the
MT models. These weights are used to reweight
the training losses. At this stage, we solve the
following optimization problems:
, D(ge)
ich
ich
ich
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
W ∗
eg(Aeg) = argmin
Weg
W ∗
ge(Alter) = argmin
Wge
W ∗
ec(Aec) = argmin
Wec
W ∗
ce(Ace) = argmin
Wce
(cid:2)N (eg)
i=1
(cid:2)N (ge)
i=1
(cid:2)N (ec)
i=1
(cid:2)N (ce)
i=1
A(eg)
ich
(cid:2)mt(D(eg)
ich
; Weg),
A(ge)
ich
(cid:2)mt(D(ge)
ich
; Wge),
A(ec)
ich
(cid:2)mt(D(ec)
ich
; Wec),
A(ce)
ich
(cid:2)mt(D(ce)
ich
; Wce),
(1)
1326
ich
ich
ich
ich
where Aeg = {A(eg)
i=1 , Age = {A(ge)
}N (ge)
}N (eg)
i=1 ,
ich
i=1 , and Ace = {A(ce)
Aec = {A(ec)
}N (ce)
}N (ec)
i=1 .
; Weg) is an MT loss defined on d(eg)
(cid:2)mt(D(eg)
.
ich
ich
Wenn ein(eg)
is close to 0 (indicating d(eg)
has large
ich
domain discrepancy with classification texts), Das
loss is made close to 0, effectively excluding d(eg)
from training the MT model. These data weights
are tentatively fixed at this stage and will be up-
dated later. They cannot be updated at this stage
by minimizing the training losses. Ansonsten,
trivial solutions will be yielded where all these
weights are zero. Note that W ∗
eg depends on Aeg
(cid:2)mt(D(eg)
since W ∗
; Weg)
eg depends on
ich
which is a function of Aeg.
N (eg)
i=1 a(eg)
(cid:3)
ich
ich
eg(Aeg)
Given an original English sentence x, Wir
into W ∗
to get a translated
feed it
then fed into
German sentence, welches ist
W ∗
ge(Alter) to get a translated English sentence
X(cid:4). In der Zwischenzeit, we feed x into W ∗
ec(Aec) Zu
get a translated Chinese sentence, welches ist
then fed into W ∗
ce(Ace) to get another trans-
lated English sentence x(cid:4)(cid:4). X(cid:4) and x(cid:4)(cid:4) are two
augmented sentences of x. Since translation
models are trained using in-domain translation
examples that have large domain similarity
with classification data, augmented examples
generated by translation models are likely to
be in the same domain as classification data as
well; contrastive learning performed on these in-
domain augmented examples is likely to produce
latent representations that are suitable for repre-
senting classification data.
3.3 Stage II: Contrastive Learning
At the second stage, we perform CSSL pretrain-
ing. Given two augmented sentences, if they orig-
inate from the same original sentence, they are
labeled as a positive pair; if they are from differ-
ent sentences, they are labeled as a negative pair.
Let x(cid:4) and x(cid:4)(cid:4) denote two sentences augmented
from the same original sentence x. Let {yi}K
i=1
denote K augmented sentences derived from orig-
inal sentences different from x. Let U denote a
text encoder such as BERT and f (T; U ) denote
the embedding of a sentence t extracted by U .
Let s(R, T; U ) = exp(sim(F (R; U ), F (T; U ))/τ )
where sim(·, ·) denotes cosine similarity and τ
is a temperature parameter. Let A denote {Aeg,
Alter, Aec, Ace} and W ∗(A) denote {W ∗
eg(Aeg),
ec(Aec), W ∗
W ∗
ce(Ace)}. We define the
ge(Alter), W ∗
following contrastive loss (Hadsell et al., 2006)
on x:
(cid:2)C(X; U, W ∗(A)) = − log
S(X(cid:4), X(cid:4)(cid:4); U )
(cid:2)
S(X(cid:4), X(cid:4)(cid:4); U ) +
.
K
i=1 s(X(cid:4), yi; U )
(2)
Note that x(cid:4), X(cid:4)(cid:4), Und {yi}K
by W ∗(A). Bei
following optimization problem:
Das
i=1 are generated
Die
solve
stage, Wir
U ∗(W ∗(A)) = argminU
(cid:2)
(cid:2)C(X; U, W ∗(A)).
(3)
X
3.4 Stage III: Finetuning Text Classifier
At the third stage, we finetune a text classification
model where the text encoder is regularized by
the encoder trained at the second stage. Let V
and H denote the text encoder and classification
head in the classification model. Let D(tr)
cls and
D(val)
denote the training and validation sets of a
cls
classification dataset. The third stage amounts to
solving the following problem:
V ∗(U ∗(W ∗(A))), H ∗ =
Lcls(D(tr)
argmin
V,H
cls ; V, H) + λ(cid:5)V − U ∗(W ∗(A))(cid:5)2
2,
(4)
where Lcls(·) is classification loss. (cid:5) · (cid:5)2
2 is an
L2 regularizer that encourages the text encoder V
to be close to the encoder U ∗(W ∗(A)) pretrained
at the second stage. λ is a tradeoff parameter.
3.5 Stage IV: Update Weights of
Translation Data
At the fourth stage, the classification model fine-
tuned at the third stage is evaluated on the vali-
dation set and the weights of machine translation
(MT) examples are updated by minimizing the
validation loss:
minA Lcls(D(val)
cls
; V ∗(U ∗(W ∗(A))), H ∗).
(5)
3.6 Four-Level Optimization Framework
Putting these pieces together, we have the
following four-level optimization framework.
(Stage IV:)
minA Lcls(D(val)
cls ; V ∗(U ∗(W ∗(A))), H ∗)
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
1327
s.t. (Stage III:)
V ∗(U ∗(W ∗(A))), H ∗ =
Lcls(D(tr)
argmin
V,H
cls ; V, H) + λ(cid:5)V − U ∗(W ∗(A))(cid:5)2
2
(Stage II:)
U ∗(W ∗(A)) = argminU
(Stage I:)
(cid:2)
X
(cid:2)C(X; U, W ∗(A))
be developed for the memory/computation cost
reduced framework in Section 3.7. Let ∇2
Y,X
F (X, Y ) denote ∂f (X,Y )
∂X∂Y . Following Liu et al.
(2018), bei
the first stage (where the training
data are translation examples), we approximate
W ∗
ce(Ace)
using one-step gradient descent updates of Weg,
Wge, Wec, and Wce:
ec(Aec), and W ∗
ge(Alter), W ∗
eg(Aeg), W ∗
A(eg)
ich
(cid:2)mt(D(eg)
ich
; Weg)
W ∗
eg(Aeg) ≈ W (cid:4)
A(ge)
ich
(cid:2)mt(D(ge)
ich
; Wge)
Weg − ηw∇Weg
eg =
(cid:2)N (eg)
i=1
W ∗
eg(Aeg) = argmin
Weg
W ∗
ge(Alter) = argmin
Wge
W ∗
ec(Aec) = argmin
Wec
W ∗
ce(Ace) = argmin
Wce
(cid:2)N (eg)
i=1
(cid:2)N (ge)
i=1
(cid:2)N (ec)
i=1
(cid:2)N (ce)
i=1
A(ec)
ich
(cid:2)mt(D(ec)
ich
; Wec)
A(ce)
ich
(cid:2)mt(D(ce)
ich
; Wce)
(6)
3.7 Reducing Memory and
Computation Cost
In the proposed formulation in Eq. (6), es gibt
four translation models and two text encoders.
Storing these models and performing computa-
tion on them will incur a lot of memory and com-
putation costs. In diesem Abschnitt, we discuss how to
reduce such costs, via parameter sharing (Sachan
and Neubig, 2018). For the two encoders—one
pretrained during contrastive learning and the
other finetuned during text classification, we can
let them share the same weight parameters. Als
solch, the third stage becomes:
H ∗(U ∗(W ∗(A))) =
argmin
H
Lcls(D(tr)
cls ; U ∗(W ∗(A)), H),
(7)
and the fourth stage becomes:
minA Lcls(D(val)
cls ; U ∗(W ∗(A)), H ∗(U ∗(W ∗(A)))).
(8)
W ∗
ge(Alter) ≈ W (cid:4)
Wge − ηw∇Wge
ge =
(cid:2)N (ge)
i=1
W ∗
ec(Aec) ≈ W (cid:4)
Wec − ηw∇Wec
ec =
(cid:2)N (ec)
i=1
W ∗
ce(Ace) ≈ W (cid:4)
Wce − ηw∇Wce
ce =
(cid:2)N (ce)
i=1
A(eg)
ich
(cid:2)mt(D(eg)
ich
; Weg),
(9)
A(ge)
ich
(cid:2)mt(D(ge)
ich
; Wge),
(10)
A(ec)
ich
(cid:2)mt(D(ec)
ich
; Wec),
(11)
A(ce)
ich
(cid:2)mt(D(ce)
ich
; Wce),
(12)
ce)
ec, W (cid:4)
eg, W (cid:4)
ge, W (cid:4)
At the second stage, we use these approximate
Modelle (including W (cid:4)
Zu
generate augmented sentences and define con-
trastive losses on these augmented sentences.
Let W (cid:4) denote {W (cid:4)
}. The sum-
mation of all contrastive losses can be writ-
(cid:3)
X (cid:2)C(X; U, W (cid:4)). Then we approximate
ten as
U ∗(W ∗(A)) using one-step gradient descent up-
date of U with respect to
X (cid:2)C(X; U, W (cid:4)):
ge, W (cid:4)
eg, W (cid:4)
ec, W (cid:4)
(cid:3)
ce
U ∗(W ∗(A)) ≈ U (cid:4) = U − ηu∇U
(cid:2)
X
(cid:2)C(X; U, W (cid:4)).
(13)
For the four translation models, they involve four
encoders and four decoders, for three languages.
For the same language, we let its encoders and
decoders in the four translation models share
the same parameters. By doing this, the eight
encoders/decoders are reduced to three encoders/
decoders.
At the third stage (where the training data are
classification examples), we plug the approxi-
mation U ∗(W ∗(A)) ≈ U (cid:4) into Eq. (4) and get
an approximate objective. Then we approximate
V ∗(U ∗(W ∗(A))) and H ∗ using one-step gradient
descent update of V and H with respect to the
approximated objective:
3.8 Optimization Algorithm
We develop an optimization algorithm to solve
the problem in Eq. (6). A similar algorithm can
V ∗(U ∗(W ∗(A))) ≈ V (cid:4) =
V − ηv∇V (Lcls(D(tr)
cls ; V, H) + λ(cid:5)V − U (cid:4)(cid:5)2
2),
(14)
1328
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 3: Dependency between variables and gradients.
Algorithm 1: Optimization algorithm.
while not converged do
1. Update MT models using Eq. (9) Zu
Eq. (12)
2. Update text encoder U in contrastive
SSL using Eq. (13)
3. Update text encoder V and
classification head H in the
classification model using Eq. (14) Und
Eq. (15)
4. Update machine translation example
weights A using Eq. (16)
end
H ∗ ≈ H (cid:4) = H − ηh∇H Lcls(D(tr)
cls ; V, H). (15)
At the fourth stage (where the validation data are
classification examples), we plug the approxima-
tions V ∗(U ∗(W ∗(A))) ≈ V (cid:4) and H ∗ ≈ H (cid:4) into
Eq. (5) and get an approximated validation loss,
then update A by performing one-step gradient
descent with respect to the approximated valida-
tion loss.
A ← A − ηa∇ALcls(D(val)
cls
; V (cid:4), H (cid:4)).
(16)
ec, W (cid:4)
ge, W (cid:4)
eg, W (cid:4)
ec, W (cid:4)
ge, W (cid:4)
eg, W (cid:4)
After A is updated, W (cid:4)
ce in
Eqs. (9–12), which are functions of A, need to
be updated as well. Weiter, U (cid:4) in Eq. (13), welche
is a function of W (cid:4)
ce, needs to be
updated as well. V (cid:4) in Eq. (14), which is a function
of U (cid:4), needs to be updated. After V (cid:4) is updated,
A in Eq. (16), which is a function of V (cid:4), needs to
be updated again. A further updated A will ren-
der all other variables to be updated again. Das
update process iterates until convergence. In each
iteration, we update each variable with one-step
gradient descent, then move to updating the next
Variable. The iterative algorithm is summarized in
Algorithm 1. Blue arrows in Figure 3 show the
dependency between variables.
Nächste, we discuss how to calculate the gradient
; V (cid:4), H (cid:4)) in Eq. (16). According to
∇ALcls(D(val)
cls
the chain rule, we have:
∇ALcls(D(val)
cls
∂V (cid:4)
∂U (cid:4)
∂W (cid:4)
∂W (cid:4)
∂A
∂U (cid:4)
; V (cid:4), H (cid:4)) =
∇V (cid:4)Lcls(D(val)
cls
; V (cid:4), H (cid:4)).
(17)
From Eq. (14), we have:
∂V (cid:4)
∂U (cid:4) = −ηvλ∇U (cid:4),V (cid:5)V − U (cid:4)(cid:5)2
2,
(18)
From Eq. (13), we have:
∂U (cid:4)
∂W (cid:4) = −ηu∇W (cid:4),U
(cid:2)
X
(cid:2)C(X; U, W (cid:4)),
(19)
From Eqs. (9–12), we have:
∂W (cid:4)
eg
∂Aeg
= −ηw∇2
Aeg,Weg
N (eg)(cid:2)
i=1
A(eg)
ich
(cid:2)mt(D(eg)
ich
; Weg),
(20)
∂W (cid:4)
ge
∂Age
∂W (cid:4)
ec
∂Aec
∂W (cid:4)
ce
∂Ace
= −ηw∇2
Alter,Wge
= −ηw∇2
Aec,Wec
= −ηw∇2
Ace,Wce
N (ge)(cid:2)
i=1
N (ec)(cid:2)
i=1
N (ce)(cid:2)
i=1
A(ge)
ich
(cid:2)mt(D(ge)
ich
; Wge),
(21)
A(ec)
ich
(cid:2)mt(D(ec)
ich
; Wec),
(22)
A(ce)
ich
(cid:2)mt(D(ce)
ich
; Wce).
(23)
Green arrows in Figure 3 show the dependency
during gradient calculation. The gradients in
Eqs. (9-15) and Eqs. (18–23) can be automati-
cally calculated using auto differentiation (z.B.,
autograd in PyTorch). The gradient in Eq. (17)
needs to be manually implemented. When ap-
proximating optimal solutions at Stage I-III and
updating A at Stage IV, we calculate stochastic
1329
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
CoLA RTE
2490
8551
1043
277
3000
1063
QNLI
104743
5463
5463
STS-B MRPC WNLI
3668
5749
408
1500
1725
1379
635
71
146
SST-2 MNLI (m/mm)
67349
872
1821
392702
9815/9832
9796/9847
QQP
363871
40432
390965
AX
–
–
1104
Train
Dev
Test
Tisch 1: Split statistics of GLUE datasets.
gradients on mini-batches instead of full gradients
on the entire dataset.
4 Experimente
In diesem Abschnitt, we evaluate our framework on
eleven English understanding tasks in the GLUE
(Wang et al., 2018B) benchmark and eight text
datasets used in Gururangan et al. (2020)
4.1 Tasks and Datasets
For text classification, we use two collections of
datasets. The first collection is from the Gen-
eral Language Understanding Evaluation (GLUE)
benchmark, which has 11 tasks,
einschließlich 2
single-sentence tasks including CoLA (Warstadt
et al., 2019) and SST-2 (Socher et al., 2013), 3
similarity and paraphrase tasks including MRPC
(Dolan and Brockett, 2005), QQP,1 and STS-B
(Cer et al., 2017), Und 5 inference tasks including
MNLI (Williams et al., 2018), QNLI (Rajpurkar
et al., 2016), RTE (Dagan et al., 2005), and WNLI
(Levesque et al., 2012). Tisch 1 shows the split
statistics of GLUE datasets. The second collection
is from Gururangan et al. (2020), including CHEM-
PROT (Kringelum et al., 2016), RCT (Dernoncourt
und Lee, 2017), ACL-ARC (Jurgens et al.,
2018), SCIERC (Luan et al., 2018), HYPERPAR-
TISAN (Kiesel et al., 2019), AGNEWS (Zhang et al.,
2015), HELPFULNESS (McAuley et al., 2015), Und
IMDB (Maas et al., 2011). In our method, Wir
split the original training set into a new training
set and a validation set, with a ratio of 1:1. Der
new training set is used as D(tr)
cls and the valida-
tion set is used as D(val)
.
cls
For machine translation, we use 3K English-
Chinese and 3K English-German language pairs
randomly sampled from WMT17.2 For contras-
tive learning, it is performed on all input texts
(excluding labels) of training datasets in the 11
GLUE tasks.
1https://www.quora.com/q/quoradata/First
-Quora-Dataset-Release-Question-Pairs.
2http://www.statmt.org/wmt17/translation
-task.html.
4.2 Experimental Settings
For translation models, we use those experimented
in Britz et al. (2017), which are encoder-decoder
models with attention. The encoder and decoder
are both 4-layer bi-directional LSTM networks
with a hidden size of 512. The attentions are ad-
ditive, with a dimension of 512. For classifiers,
BERT is used for GLUE and RoBERTa is used for
datasets in Gururangan et al. (2020). The gumbel-
softmax trick (Jang et al., 2017; Maddison
et al., 2017) is leveraged to deal with the non-
differentiability of words.
We use MoCo (He et al., 2020) to implement
the contrastive learning method. Text encoders
are initialized using pretrained BERT (Devlin
et al., 2019) or pretrained RoBERTa (Liu et al.,
2019). In MoCo, the size of the queue (welches ist
the hyperparameter K in Section 3.3) was set to
96606. The coefficient of MoCo momentum of
updating the key encoder was set to 0.999. Der
temperature parameter (which is the hyperparam-
eter τ in Section 3.3) in the contrastive loss was
set to 0.07. A multi-layer perceptron head was
gebraucht. For MoCo training, a stochastic gradient
descent solver with momentum was used. Mini-
batch size was set to 16. Initial learning rate was
set to 4 · 10−5. Learning rate was adjusted using
cosine scheduling. Weight decay was used with a
coefficient of 1 · 10−5.
For classification on GLUE tasks, the classifi-
cation head is set to a linear layer. The maximum
sequence length was set to 128. The tradeoff pa-
rameter λ in Eq. (4) is set to 0.1. Minibatch size
was set to 16. The learning rate was set to 3 · 10−5
for CoLA, MNLI, STS-B; 2·10−5 for RTE, QNLI,
MRPC, SST-2, WNLI; Und 1 · 10−5 for QQP. Der
number of training epochs was set to 100.
Hyperparameter Tuning Details For most hy-
perparameters in MoCo and LSTM, we use the
default values given in He et al. (2020) and Britz
et al. (2017). The tradeoff parameter λ is tuned
In {0.01, 0.05, 0.1, 0.5, 1} on the development
set. For each configuration of λ, we run our
method on D(tr)
cls (one half of the training set) Und
1330
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
D(val)
(the other half of the training set). Dann wir
cls
measure the performance of the trained model on
the development set. The λ value yielding the
best performance is selected. We tuned the hy-
perparameters of baselines extensively, bei dem die
tuning time for each baseline is roughly the same
as that for our method.
4.3 Baselines
We compare our methods with the following
baselines. Let Ours-SPS denote the proposed
(6) which performs soft
framework in Eq.
parameter-sharing (SPS) between V and U via
regularization, and let Ours-HPS denote the
framework in Section 3.7 which performs hard
parameter-sharing (HPS) where V and U are the
same.
• Vanilla RoBERTa (Liu et al., 2019). Der
Transformer-based encoder is initialized with
pretrained RoBERTa. A text classification
model is formed by stacking the pretrained
encoder and a classification head, with an
architecture that is the same as that in Liu
et al. (2019). The classification head is a
feedforward layer, where the nonlinear ac-
tivation function is tanh. Learned encoding
of the special token [CLS] is fed into the
classification head to predict the class label.
Then we finetune the classification model on
a classification dataset.
• Vanilla BERT (Devlin et al., 2019). Das
approach is similar to vanilla RoBERTa. Der
only difference is that the Transformer-based
encoder is initialized by pretrained BERT
(Devlin et al., 2019) instead of RoBERTa.
• TAPT: Task Adaptive
Pretraining
(Gururangan et al., 2020). In this approach,
given a target dataset Dt,
the pretrained
BERT or RoBERTa on external data is fur-
ther pretrained on the input sentences in Dt
by predicting masked tokens.
• SimCSE (Gao et al., 2021). In this approach,
the same input sentence is fed into a pre-
trained RoBERTa encoder twice by applying
different dropout masks, to get two differ-
ent embeddings. These two embeddings are
labeled as being ‘‘similar’’. Embeddings of
different sentences are labeled as being ‘‘dis-
similar’’. Contrastive learning is performed
on these ‘‘similar’’ and ‘‘dissimilar’’ pairs.
• CSSL-Separate. In this approach, data aug-
mentation, contrastive learning, and text
classification are performed separately. Wir
first train machine translation models and
use them to perform sentence augmentation.
Then on augmented sentences, we perform
contrastive learning. Endlich, using the text
encoder pretrained by contrastive learning
as initialization, we finetune the classifi-
cation model. When performing contrastive
learning, the text encoder is initialized using
pretrained RoBERTa or BERT.
• CSSL-MTL. This approach is similar to
CSSL-Separate, except that the CSSL task
and classification task are performed jointly
in a multi-task learning (MTL) Rahmen,
by minimizing the weighted sum of their
losses. The weight is 0.01 for CSSL loss and
Ist 1 for classification loss.
4.4 Ergebnisse
4.4.1 Results in BERT-Based Experiments
In BERT-based experiments, the text encoder is
initialized using BERT, before contrastive learn-
ing is performed. Tables 2 Und 3 show the results
on GLUE test sets, in BERT-based experiments.
Our methods including Ours-SPS and Ours-HPS
outperform all baselines on average scores. Out of
Die 11 tasks (MNLI-m and MNLI-mm are treated
as two separate tasks), Ours-SPS outperforms all
baselines on 8 tasks; Ours-HPS outperforms all
baselines on 7 tasks. These results demonstrate the
effectiveness of our end-to-end frameworks. Via
parameter sharing, Ours-HPS has much smaller
memory and computation costs than Ours-SPS,
with a small sacrifice of classification perfor-
Mance. The inference costs of our methods are
similar to those of baselines. During inference,
only V and H are needed, which are the same as
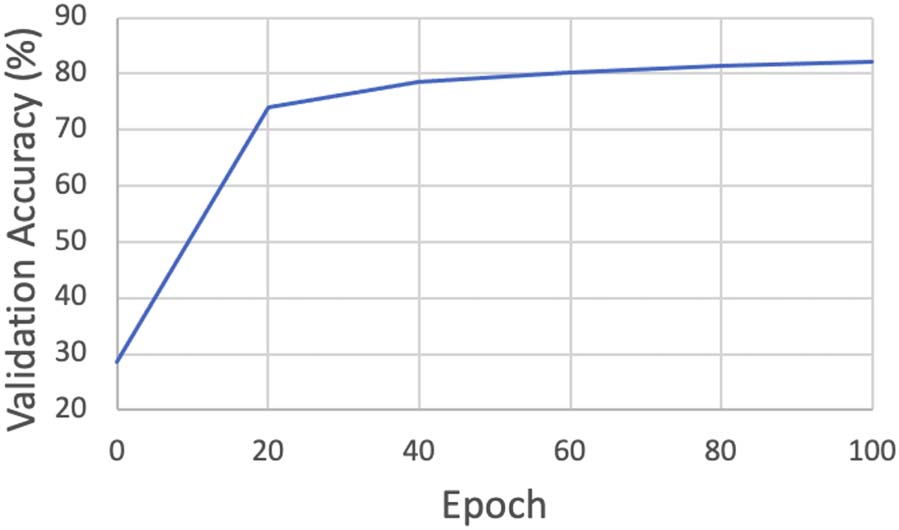
baseline models. Figur 4 shows the accuracy
curve of Ours-HPS on the RTE validation set
(D(val)
) under different runs. As can be seen,
cls
our algorithm converges well.
We present
the following analysis. Erste,
the reason that our methods outperform CSSL-
Separate and CSSL-MTL is that in our meth-
Odds, data augmentation and contrastive learning
are performed end-to-end where the training of
translation models (used for data augmentation)
1331
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Train Time Memory Train Data Parameters
(millions)
345
345
690
713
713
713
356
(millions)
1.019
1.019
1.019
1.025
1.025
1.025
1.025
(hours)
6.3
13.5
16.4
16.1
16.9
28.2
17.4
(GB)
11.7
11.8
12.1
12.0
12.2
20.5
12.7
CoLA
(Matthew)
60.5
61.3
59.5
59.4
59.7
63.0
62.4
BERT
TAPT
SimCSE
CSSL-Separate
CSSL-MTL
Ours-SPS
Ours-HPS
SST-2 RTE QNLI MRPC
(Acc./F1)
(Acc.)
85.4/89.3
94.9
85.9/89.5
94.4
85.9/89.8
94.3
85.8/89.6
94.5
86.0/89.6
94.7
86.1/89.9
95.8
86.3/89.9
95.3
(Acc.)
92.7
92.4
92.9
92.8
92.5
93.2
92.5
(Acc.)
70.1
70.3
71.2
71.4
71.2
72.5
72.4
Tisch 2: Results on GLUE test sets, using BERT for model initialization. The results are obtained
from the GLUE evaluation server. The best results are bolded. The second best results are bolded and
underlined. Models evaluated on AX are trained on the training dataset of MNLI. Matthew denotes
Matthew correlation. Acc. denotes accuracy.
MNLI-m/mm
(Accuracy)
QQP
(Accuracy/F1)
STS-B (Pearson/
Spearman)
WNLI
(Accuracy)
AX
(Matthew)
Average
BERT
TAPT
SimCSE
CSSL-Separate
CSSL-MTL
Ours-SPS
Ours-HPS
86.7/85.9
85.7/84.4
87.1/86.4
87.3/86.6
87.4/86.8
86.7/86.2
86.8/86.2
89.3/72.1
89.6/71.9
90.5/72.5
90.6/72.7
90.9/72.9
90.0/72.9
89.8/72.8
87.6/86.5
88.1/87.0
87.8/86.9
87.4/86.6
87.3/86.6
88.2/87.3
88.3/87.3
65.1
65.8
65.8
65.5
65.4
66.9
66.1
39.6
39.3
39.6
39.6
39.6
40.3
40.2
80.5
80.6
80.8
80.8
80.8
81.7
81.4
Tisch 3: Continuation of Table 2. Pearson, Spearman, and Matthew denote the corresponding
correlations.
unique properties of classification data. In con-
trast, in Ours-HPS, the classification model and
the CSSL-pretrained text encoder are required to
be exactly the same, which might be too restric-
tiv. Andererseits, it is worth noting that
the classification performance gap between Ours-
HPS and CSSL-pretrained is not very large while
the memory and computation cost of Ours-HPS
are much smaller.
Dritte, overall, CSSL-MTL works better than
CSSL-Separate. Out of the 11 tasks, CSSL-MTL
outperforms CSSL-Separate on 6 tasks and is on
par with CSSL-Separate on 1 Aufgabe. The reason
is that in CSSL-MTL, contrastive learning and
classification are performed jointly, which en-
ables these two tasks to mutually benefit from
each other. Im Gegensatz, in CSSL-Separate, con-
trastive learning and classification are performed
separately. While contrastive learning influences
classification, classification does not provide any
feedback to contrastive learning. Vierte, CSSL-
Separate and SimCSE are in general on par with
each other. The only difference between these
two methods is that CSSL-Separate uses back-
translation for data augmentation while SimCSE
uses dropout masks. This shows that these two
Figur 4: Accuracy on RTE validation set (D(val)
cls ).
is guided by the contrastive learning performance
and the augmented sentences are encouraged to
be suitable for performing the contrastive learning
Aufgabe. Im Gegensatz, in CSSL-Separate and CSSL-
MTL, data augmentation and contrastive learn-
ing are performed separately. Folglich, Die
augmented data may not be optimal for perform-
ing contrastive learning. Zweite, the reason that
Ours-SPS outperforms Ours-HPS is that in Ours-
SPS, while the classification model is regular-
ized by the CSSL-pretrained text encoder, Sie
are not exactly the same. This gives the classi-
fication model some flexibility in capturing the
1332
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
CoLA
(Matthew Corr.)
SST-2
(Accuracy)
RTE
(Accuracy)
QNLI
(Accuracy)
MRPC
(Accuracy/F1)
BERT (from Lan et al.)
BERT (our run)
TAPT
SimCSE
CSSL-Separate
CSSL-MTL
No-CL
No-FT
No-BT
Domain-Reweight
Fix-Weight-Separate
Fix-Weight-MTL
DANN
CAN
Ours-Transformer-MT
Ours-SPS
Ours-HPS
60.6
62.1
61.2
62.0
62.3
62.7
62.3
62.4
62.8
62.7
62.7
62.9
62.4
62.3
63.2
63.6
63.3
93.2
93.1
93.1
93.5
93.7
93.7
93.2
93.6
93.7
93.8
93.8
93.8
93.7
93.6
93.9
94.0
93.9
70.4
74.0
74.0
73.5
72.0
72.6
74.0
72.3
74.0
72.5
72.8
73.2
72.2
72.3
74.2
74.8
74.4
92.3
92.1
92.0
92.2
92.5
92.3
92.2
92.4
92.5
92.6
92.6
92.4
92.4
92.4
92.6
92.9
92.7
88.0/–
86.8/90.8
85.3/89.8
86.8/90.9
87.0/90.9
87.1/90.9
86.9/90.8
87.0/90.9
87.1/90.9
87.1/90.9
87.1/90.9
87.2/90.9
87.1/90.9
87.2/90.9
87.2/90.9
87.8/91.1
87.3/90.9
Tisch 4: Results on GLUE development sets, using BERT for model initialization. The result is the
median of five runs. Due to randomness of model initialization, our median performance is not the
same as that reported in Lan et al. (2019).
augmentation methods work equally well for con-
trastive learning on texts. Fünfte, CSSL-Separate
and SimCSE outperform TAPT. In TAPT, Die
self-supervised task is masked token prediction.
This shows that contrastive learning is a more
effective self-supervised learning method than
masked token prediction. Sixth, CSSL-Separate
and SimCSE perform better than BERT, welche
further demonstrates the effectiveness of con-
trastive learning. Seventh,
the improvement
achieved by our methods is more prominent on
smaller datasets such as WNLI and RTE. Das ist
Weil, for smaller datasets, it is more necessary
to leverage unlabeled data via contrastive learn-
ing to learn overfitting-resilient representations.
Eighth, for tasks that have similar data size, Die
improvement of our method is more prominent on
similarity tasks than on other types of tasks. Für
Beispiel, QQP and MNLI have similar data size;
our method achieves better improvement on QQP,
which is a similarity task, than on MNLI, welche
is an inference task.
Tables 4 Und 5 show the results of BERT-based
experiments on the development sets of GLUE.
Our methods outperform all baselines on differ-
ent tasks. The analysis of reasons is similar to that
for Tables 2 Und 3. Note that our method can
be applied to other text encoders besides BERT.
Zum Beispiel, our method can be applied to
Turing-NLR-v5 (Bajaj et al., 2022). This encoder
achieves
state-of-the-art performance on the
GLUE leaderboard, with an average score of 91.2.
4.4.2 Results in RoBERTa-Based
Experimente
In RoBERTa-based experiments, text encoders
are initialized using RoBERTa, before contrastive
learning is performed. These experiments are con-
ducted on datasets used in Gururangan et al.
(2020). Tisch 6 shows the results. Our methods
outperform all baselines. The analysis of reasons
is similar to that for results in Tables 2 Und 3.
4.4.3 Ablation Studies
To verify whether the individual components in
our method are necessary, we perform the fol-
lowing ablation studies.
• No contrastive learning (No-CL). Contras-
tive learning is removed from the framework.
For each text-label pair (X, j) ∈ D(tr)
cls , Die
input text x is fed into the four translation
models to generate two augmentations x(cid:4)
and x(cid:4)(cid:4). Dann (X(cid:4), j) Und (X(cid:4)(cid:4), j) are utilized
as augmented data to train the classification
model directly.
1333
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
MNLI-m/mm
(Accuracy)
QQP
(Accuracy/F1)
STS-B (Pearson Corr./
Spearman Corr.)
WNLI
(Accuracy)
BERT (from Lan et al.)
BERT (our run)
TAPT
SimCSE
CSSL-Separate
CSSL-MTL
No-CL
No-FT
No-BT
Domain-Reweight
Fix-Weight-Separate
Fix-Weight-MTL
DANN
CAN
Ours-Transformer-MT
Ours-SPS
Ours-HPS
86.6/–
86.2/86.0
85.6/85.5
86.4/86.1
86.6/86.4
86.6/86.5
86.3/86.1
86.6/86.5
86.7/86.6
86.6/86.5
86.7/86.6
86.7/86.6
86.6/86.4
86.6/86.5
86.7/86.8
86.9/87.0
86.9/86.9
91.3/–
91.3/88.3
91.5/88.7
91.2/88.1
91.4/88.5
91.5/88.6
91.3/88.4
91.4/88.4
91.5/88.7
91.5/88.6
91.5/88.7
91.6/88.8
91.5/88.5
91.6/88.5
91.6/88.9
91.9/89.2
91.7/89.1
90.0/–
90.4/90.0
90.6/90.2
90.5/90.1
90.2/89.9
90.4/90.1
90.5/90.2
90.4/90.0
90.7/90.3
90.4/90.0
90.4/90.0
90.5/90.2
90.3/90.1
90.2/90.1
90.7/90.3
91.0/90.8
90.8/90.5
–
56.3
53.5
56.3
56.3
56.3
56.3
56.3
56.3
56.3
56.3
56.3
56.3
56.3
56.3
56.3
56.3
Tisch 5: Continuation of Table 4.
Dataset
RoBERTa TAPT SimCSE CSSL-Separate CSSL-MTL Ours-SPS Ours-HPS
CHEMPROT
ACL-ARC
SCIERC
HYPERPARTISAN
AGNEWS
HELPFULNESS
IMDB
81.91.0
87.20.1
63.05.8
77.31.9
86.6 0.9
93.90.2
65.13.4
95.00.2
82.60.4
87.70.1
67.41.8
79.31.5
90.45.2
94.50.1
68.51.9
95.50.1
83.20.2
87.60.1
69.52.6
80.50.7
90.92.7
94.70.1
68.71.7
95.70.1
82.90.5
87.60.1
68.73.1
80.91.3
91.43.3
94.30.1
69.20.5
95.60.1
83.40.3
87.70.1
70.83.7
81.20.9
90.71.9
94.50.1
69.51.1
95.30.1
84.50.4
88.00.1
75.62.9
82.11.1
92.32.1
95.10.1
70.90.2
96.00.1
84.20.3
87.90.1
75.31.5
81.90.6
91.81.6
94.90.1
70.40.4
95.80.1
Tisch 6: Results of RoBERTa-based experiments on datasets used in Gururangan et al. (2020). Der
results of vanilla RoBERTa and TAPT are taken from Gururangan et al. (2020). Each method runs
four times with random initialization. In the xy formatted results, x denotes average and y denotes
Standardabweichung. Following Gururangan et al. (2020), the results on CHEMPROT and RCT are micro-
F1; the results on other datasets are macro-F1. The best results are bolded. The second best results
are bolded and underlined.
• No finetuning (No-FT). At the third stage,
the encoder V in the classification model is
set to U ∗(W ∗(A)) without being finetuned.
• Replacing back-translation with SimCSE
(No-BT). Instead of learning machine trans-
lation models for text augmentation, wir gebrauchen
the augmentation method proposed in Sim-
CSE (Gao et al., 2021) for augmentation.
• Domain-Reweight. In CSSL-Separate, Wir
reweight self-supervised training examples
based on their domain relatedness to classifi-
cation data, and perform contrastive learning
on reweighted examples. Domain related-
ness is calculated using an H-divergence
based metric (Elsahar and Gall´e, 2019).
• Fix-Weight-Separate and Fix-Weight-MTL:
Learn translation sample weights using our
method, fix them, then run CSSL-Separate
and CSSL-MTL on reweighted translation
examples.
1334
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
• Compare with other domain adaptation meth-
Odds, including DANN (Ganin et al., 2016) Und
CAN (Kang et al., 2019). We use these meth-
ods to align the domains of input sentences
in the translation and classification datasets.
• Ours-Transformer-MT: In Ours-HPS, us-
ing Transformer
(speziell, pretrained
BERT) für maschinelle Übersetzung, instead of
using attentional LSTM.
Tables 4 Und 5 show results on GLUE develop-
ment sets, using BERT for model initialization.
We make the following observations. Erste, unser
full methods work better than No-CL, No-FT,
and No-BT. In these three ablation baselines, eins
component (which is contrastive learning, fine-
tuning classifier, back translation, jeweils) Ist
removed from our full methods, yielding simpler
Methoden. These results show that each component
is useful and should not be removed, and simpler
methods do not perform comparably well. Zweite,
our methods work better than Domain-Reweight.
The reason is that our methods perform reweight-
ing of translation data together with performing
other tasks (including training translation models,
contrastive learning, finetuning, and validation),
in an end-to-end manner. In this way, weights
of translation data are influenced by other tasks
and learned towards maximizing the classifica-
tion performance. Im Gegensatz, Domain-Reweight
performs reweighting of self-supervised training
examples separately from other tasks. Weights
calculated in this way are not guaranteed to be op-
timal for maximizing classification performance.
Andererseits, Domain-Reweight outperforms
CSSL-Separate, which shows that it is benefi-
cial to reweight self-supervised training examples
based on their domain relatedness to classifica-
tion data. Dritte, our methods work better than
Fix-Weight-Separate and Fix-Weight-MTL. Der
reason is that our methods generate augmented
sentences and perform CL end-to-end while
Fix-Weight-Separate and Fix-Weight-MTL per-
form these two tasks separately. In our end-to-end
Rahmen, guided by the performance of CL,
the training of translation models is dynamically
changing to generate augmented sentences that
are better for improving CL. Andererseits, In
Fix-Weight-Separate and Fix-Weight-MTL, Die
generation of augmented examples is not influ-
enced by the CL task. Folglich, the gener-
ated augmentations may not be optimal for CL.
Method
E→G G→E
E→C
C→E
MTL
Ours
14.8
16.1
15.3
16.7
14.2
15.5
14.6
16.0
Tisch 7: BLEU scores on test sets. E, G, C denote
English, Deutsch, Chinese, jeweils. E → G
denotes English-to-German translation.
Andererseits, Fix-Weight-Separate and
Fix-Weight-MTL outperform CSSL-Separate and
CSSL-MTL, which further demonstrates the ben-
efits of reweighting translation examples based
on their domain similarity to classification data
and the weights learned by our methods can ac-
curately reflect domain similarity. Vierte, unser
methods work better than the two domain adap-
tation methods DANN and CAN. The reason is
because many translation examples have large
domain discrepancies with classification texts; Es
is difficult to adapt these translation examples
into the domain of classification data. Our meth-
ods learn to remove such examples instead of
forcefully adapting them. Fünfte, comparing Ours-
Transformer-MT (using BERT for translation)
and Ours-HPS (using LSTM), we can see that
BERT works slightly worse than LSTM. Während
BERT is more expressive, it has more weight pa-
rameters to learn than LSTM, which incurs higher
risk of overfitting.
We also check whether our framework can im-
prove machine translation (MT). Since the end
goal of our work is improving text classification,
we evaluate MT performance on selected transla-
tion examples that have large domain similarity
to classification data. Domain similarity is cal-
culated using H-divergence (Elsahar and Gall´e,
2019). Translation examples whose normalized
H-divergence is smaller than 0.5 are selected.
MT models are trained on selected training ex-
amples and evaluated on selected test examples.
Tisch 7 compares the BLUE (Papineni et al.,
2002) scores (on test sets) of the four MT models
trained in our framework and those trained via
MTL (minimizing the sum of training losses of
the four models) without using our framework. Als
can be seen, the models trained in our framework
perform better. The reason is that our framework
trains the translation models to generate linguisti-
cally meaningful augmented texts; by doing this,
the translation models are encouraged to generate
translations with higher linguistic quality.
1335
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Sentence
Weight
The government recently called for more balanced
Entwicklung, even proposing a ‘‘green index’’ to
measure growth.
President-elect Donald Trump’s campaign narrative
was based on the assumption that the US has fallen
from its former greatness.
Russia considers the agreements from the 1990s un-
just, based as they were on its weakness at the time,
and it wants to revise them.
Publicity for the new film claims that it is ‘‘the first
live-action film in the history of movies to star, Und
be told from the point of view of, a sentient animal.’’
Gore told the world in his Academy Award-winning
movie (recently labeled ‘‘one-sided’’ and contain-
ing ‘‘scientific errors’’ by a British judge) to expect
20-foot sea-level rises over this century.
Jia’s movie is episodic; four loosely linked stories
about lone acts of extreme violence, mostly culled
from contemporary newspaper stories.
0
0
0
1
1
1
Tisch 8: Some randomly sampled translation
examples with importance weights close to 0
Und 1.
whose weights are close to one are more relevant
to movie reviews.
5 Conclusions, Diskussion, Und
Future Work
In diesem Papier, we propose an end-to-end frame-
work for learning language representations based
on contrastive learning. Different from existing
contrastive learning methods that perform data
augmentation and contrastive learning separately
and thus cannot guarantee that the augmented data
is optimal for contrastive learning, our method per-
forms data augmentation and contrastive learning
end-to-end in a unified framework so that data
augmentation models are specifically trained for
being suitable for contrastive learning. Our frame-
work consists of four learning stages: 1) Ausbildung
machine translation models for text augmentation;
2) contrastive learning; 3) training a classification
Modell; 4) updating weights of translation data by
minimizing the validation loss of the classification
Modell. We evaluate our framework on 11 English
understanding tasks in the GLUE benchmark and
8 datasets in Gururangan et al. (2020). On both test
set and development set, the experimental results
demonstrate the effectiveness of our method.
One major limitation of our method is that it
has larger computational and memory costs, fällig
to the extra overhead of solving a four-level opti-
mization based problem and storing MT models.
Figur 5: How the accuracy of the RTE development
set changes with λ.
4.4.4 Parameter Sensitivity
Figur 5 shows how the classification accuracy
on the development set of RTE changes with
the tradeoff parameter λ of Ours-SPS. As can
be seen, when λ increases from 0 Zu 0.1, Die
accuracy increases. This is because a larger λ
encourages more knowledge transfer from the
CSSL-pretrained encoder to the classification
Modell. The representations learned in the con-
trastive SSL task help the classification model to
learn. Jedoch, as we continue to increase λ, Die
accuracy decreases. This is because the classifi-
cation model is too much biased to the CSSL-
pretrained encoder and is less tailored to the
classification data.
4.4.5 Qualitative Results
Tisch 8 shows some randomly sampled translation
examples where the learned importance weights
(ai in Eq. (6)) are close to 0 oder 1, when the classi-
fication task is SST-2 (the percentage of data gets
near-zero weights is 35.2%). Due to space lim-
itations, we only show the English sentences in
translation pairs. As can be seen, translation sen-
tences with near-zero weights have a large domain
discrepancy with the SST-2 data. SST-2 mainly
contains movie reviews while these zero-weight
sentences are mainly about politics. Due to this
domain discrepancy, these translation data is not
suitable to train data augmentation models for
SST-2. Our framework can effectively identify
such out-of-domain translation data and exclude
them from the training process. This is another
reason that our end-to-end framework achieves
better performance than baselines which lack the
mechanism of removing out-of-domain transla-
tion data. Andererseits, in Table 8, Sätze
1336
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
To reduce these costs, in addition to tying pa-
rameters, we will explore other techniques in
future, such as reducing the update frequencies
of MT models and MT data weights, applying
diversity-promoting regularizers (Xie et al., 2017)
to speed up convergence, performing core-set
based mini-batch selection (Sinha et al., 2020) Zu
speed up convergence, und so weiter.
For future work, we plan to study more chal-
lenging loss functions for self-supervised learning.
We are interested in investigating a ranking-based
loss, where each sentence is augmented with a
ranked list of sentences that have decreasing dis-
crepancy with the original sentence. The auxiliary
task is to predict the order given the augmented
Sätze. Predicting an order is presumably more
challenging than binary classification (as adopted
in existing contrastive SSL methods) and may
facilitate the learning of better representations.
Verweise
Payal Bajaj, Chenyan Xiong, Guolin Ke,
Xiaodong Liu, Di He, Saurabh Tiwary, Tie-Yan
Liu, Paul Bennett, Xia Song, and Jianfeng Gao.
2022. Metro: Efficient denoising pretraining
of large scale autoencoding language models
with model generated signals. arXiv preprint
arXiv:2204.06644.
Atılım G¨unes¸ Baydin, Robert Cornish, David
Mart´ınez Rubio, Mark Schmidt, and Frank
Holz. 2018. Online learning rate adaptation
with hypergradient descent. In Sixth Interna-
tional Conference on Learning Representations
(ICLR), Vancouver, Kanada, April 30 – May 3,
2018.
Yoshua Bengio, R´ejean Ducharme, and Pascal
Vincent. 2000. A neural probabilistic language
Modell. Advances in Neural Information Pro-
cessing Systems, 13.
Denny Britz, Anna Goldie, Minh-Thang Luong,
and Quoc Le. 2017. Massive exploration of
neural machine translation architectures. In
Verfahren der 2017 Conference on Em-
pirical Methods in Natural Language Process-
ing, pages 1442–1451, Copenhagen, Denmark.
Verein für Computerlinguistik.
Daniel Cer, Mona Diab, Eneko Agirre, I˜nigo
and Lucia Specia. 2017.
Lopez-Gazpio,
SemEval-2017 task 1: Semantic textual sim-
ilarity multilingual and crosslingual focused
evaluation. In Proceedings of
the 11th In-
ternational Workshop on Semantic Evalua-
tion (SemEval-2017), pages 1–14, Vancouver,
Kanada. Association for Computational Lin-
guistics.
Ting Chen, Simon Kornblith, Mohammad
Norouzi, and Geoffrey Hinton. 2020. A simple
framework for contrastive learning of visual
Darstellungen. In Proceedings of the 37th In-
ternational Conference on Machine Learning,
Volumen 119 of Proceedings of Machine Learn-
ing Research, pages 1597–1607. PMLR.
Ido Dagan, Oren Glickman, and Bernardo
Magnini. 2005. The Pascal recognising text-
ual entailment challenge. In Machine Learn-
ing Challenges Workshop, pages 177–190.
Springer.
Stephan Dempe. 2002. Foundations of Bilevel
Programming. Springer Science & Business
Medien.
Franck Dernoncourt and Ji Young Lee. 2017.
PubMed 200k RCT: A dataset for sequential
sentence classification in medical abstracts. In
Proceedings of the Eighth International Joint
Conference on Natural Language Processing
(Volumen 2: Short Papers), pages 308–313,
Taipeh, Taiwan. Asian Federation of Natural
Language Processing.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Und
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
Verständnis. In NAACL.
William B. Dolan and Chris Brockett. 2005.
Automatically constructing a corpus of sen-
Die
tential paraphrases.
Third International Workshop on Paraphrasing
(IWP2005).
In Proceedings of
Hady Elsahar and Matthias Gall´e. 2019. To an-
notate or not? Predicting performance drop
under domain shift. In Proceedings of
Die
2019 Conference on Empirical Methods in
Natural Language Processing and the 9th
International
Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP),
pages 2163–2173. https://doi.org/10
.18653/v1/D19-1222
1337
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Matthias Feurer, Jost Springenberg, and Frank
Hutter. 2015. Initializing Bayesian hyperpa-
rameter optimization via meta-learning.
In
Proceedings of the AAAI Conference on Arti-
ficial Intelligence, Volumen 29. https://doi
.org/10.1609/aaai.v29i1.9354
Chelsea Finn, Pieter Abbeel, and Sergey Levine.
2017. Model-agnostic meta-learning for fast
adaptation of deep networks. In Proceedings
of the 34th International Conference on Ma-
chine Learning-Volume 70, pages 1126–1135.
JMLR. org.
Yaroslav Ganin, Evgeniya Ustinova, Hana
Ajakan, Pascal Germain, Hugo Larochelle,
Franc¸ois Laviolette, Mario Marchand, Und
Victor Lempitsky. 2016. Domain-adversarial
training of neural networks. The Journal of
Machine Learning Research, 17(1):2096–2030.
Tianyu Gao, Xingcheng Yao, and Danqi Chen.
2021. SimCSE: Simple contrastive learning of
sentence embeddings. In Proceedings of the
2021 Conference on Empirical Methods in Nat-
ural Language Processing, pages 6894–6910,
Online and Punta Cana, Dominican Republic.
Verein für Computerlinguistik.
Suchin Gururangan, Ana Marasovic, Swabha
Swayamdipta, Kyle Lo,
Iz Beltagy, Doug
Downey, and Noah A. Schmied. 2020. Don’t
language models to
stop pretraining: Adapt
domains and tasks. In Proceedings of ACL.
https://doi.org/10.18653/v1/2020
.acl-main.740
Raia Hadsell, Sumit Chopra, and Yann LeCun.
2006. Dimensionality reduction by learning
an invariant mapping. In 2006 IEEE Com-
puter Society Conference on Computer Vision
and Pattern Recognition (CVPR’06), Volumen 2,
pages 1735–1742. IEEE.
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie,
and Ross Girshick. 2020. Momentum contrast
for unsupervised visual representation learning.
In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition,
pages 9729–9738.
Olivier Henaff. 2020. Data-efficient image recog-
nition with contrastive predictive coding. In
International Conference on Machine Learn-
ing, pages 4182–4192. PMLR.
Eric Jang, Shixiang Gu, and Ben Poole. 2017.
Categorical reparameterization with gumbel-
softmax. ICLR.
David Jurgens, Srijan Kumar, Raine Hoover,
Daniel A. McFarland, and Dan Jurafsky. 2018.
Measuring the evolution of a scientific field
through citation frames. TACL.
Guoliang Kang, Lu Jiang, Yi Yang, and Alexander
G. Hauptmann. 2019. Contrastive adaptation
network for unsupervised domain adaptation.
In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition,
pages 4893–4902. https://doi.org/10
.1109/CVPR.2019.00503
Prannay Khosla, Piotr Teterwak, Chen Wang,
Aaron Sarna, Yonglong Tian, Phillip Isola,
Aaron Maschinot, Ce Liu, and Dilip Krishnan.
2020. Supervised contrastive learning. In Ad-
vances in Neural Information Processing Sys-
Systeme, Volumen 33, pages 18661–18673. Curran
Associates, Inc.
Johannes Kiesel, Maria Mestre, Rishabh Shukla,
Emmanuel Vincent, Payam Adineh, David
Corney, Benno Stein, and Martin Potthast.
2019. SemEval-2019 Task 4: Hyperpartisan
news detection. In SemEval. https://doi
.org/10.18653/v1/S19-2145
Tassilo Klein and Moin Nabi. 2020. Contrastive
self-supervised learning for commonsense rea-
the 58th Annual
soning. In Proceedings of
Meeting of the Association for Computational
Linguistik, pages 7517–7523.
Jens Kringelum, Sonny Kim Kjærulff, Søren
Brunak, Ole Lund, Tudor
ICH. Oprea, Und
Olivier Taboureau. 2016. ChemProt-3.0: A
global chemical biology diseases mapping. In
Datenbank. https://doi.org/10.1093
/database/bav123, PubMed: 26876982
Zhenzhong Lan, Mingda Chen, Sebastian
Guter Mann, Kevin Gimpel, Piyush Sharma, Und
Radu Soricut. 2019. AlBERT: A lite bert for
self-supervised learning of language represen-
tations. In International Conference on Learn-
ing Representations.
Michael Laskin, Aravind Srinivas, and Pieter
Abbeel. 2020. CURL: Contrastive unsupervised
representations for reinforcement learning. In
Proceedings of the 37th International Confer-
ence on Machine Learning, Volumen 119 von
1338
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Proceedings of Machine Learning Research,
pages 5639–5650. PMLR.
Hector Levesque, Ernest Davis, and Leora
Morgenstern. 2012. The Winograd schema
Herausforderung. In Thirteenth International Confer-
ence on the Principles of Knowledge Represen-
tation and Reasoning.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Erheben, Veselin Stoyanov, and Luke Zettlemoyer.
2020. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
Übersetzung, and comprehension. In Proceed-
ings of
Die
Verein für Computerlinguistik,
pages 7871–7880. https://doi.org/10
.18653/v1/2020.acl-main.703
the 58th Annual Meeting of
Hanxiao Liu, Karen Simonyan, and Yiming
Yang. 2018. Darts: Differentiable architecture
suchen. In International Conference on Learn-
ing Representations.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Von, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. RoBERTa: A robustly op-
timized BERT pretraining approach. arXiv
preprint arXiv:1907.11692.
Yi Luan, Luheng He, Mari Ostendorf, Und
Hannaneh Hajishirzi. 2018. Multi-task identi-
fication of entities, Beziehungen, and coreference
for scientific knowledge graph construction.
In Proceedings of
Die 2018 Conference on
Empirical Methods in Natural Language Pro-
Abschließen, pages 3219–3232, Brussels, Belgien.
Verein für Computerlinguistik.
https://doi.org/10.18653/v1/D18
-1360
Andrew L. Maas, Raymond E. Daly, Peter
T. Pham, Dan Huang, Andrew Y. Ng, Und
Christopher Potts. 2011. Learning word vectors
for sentiment analysis. In ACL.
C. Maddison, A. Mnih, and Y. Teh. 2017. Der
concrete distribution: A continuous relaxation
of discrete random variables. In Proceedings
of the International Conference on Learning
Darstellungen. International Conference on
Learning Representations.
based recommendations on styles and substi-
tutes. In ACM SIGIR. https://doi.org
/10.1145/2766462.2767755
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg
S. Corrado, and Jeff Dean. 2013. Distributed
representations of words and phrases and their
compositionality. Advances in neural informa-
tion processing systems, 26.
Lin Pan, Chung-Wei Hang, Avirup Sil, Und
Saloni Potdar. 2022. Improved text classifica-
tion via contrastive adversarial training. AAAI.
Xiao Pan, Mingxuan Wang, Liwei Wu, and Lei Li.
2021. Contrastive learning for many-to-many
multilingual neural machine translation. In Pro-
ceedings of the 59th Annual Meeting of the
Association for Computational Linguistics and
the 11th International Joint Conference on Nat-
ural Language Processing (Volumen 1: Long Pa-
pers), pages 244–258. https://doi.org
/10.18653/v1/2021.acl-long.21
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu. 2002. BLEU: A method for
automatic evaluation of machine translation.
In Proceedings of the 40th Annual Meeting of
the Association for Computational Linguistics,
pages 311–318. Association for Computational
Linguistik. https://doi.org/10.3115
/1073083.1073135
Alec Radford, Karthik Narasimhan, Tim
Salimans, and Ilya Sutskever. 2018. Improv-
ing language understanding by generative pre-
Ausbildung. Technical report, OpenAI.
Pranav Rajpurkar,
Jian Zhang, Konstantin
Lopyrev, and Percy Liang. 2016. Squad:
100,000+ Fragen
for machine compre-
hension of text. In Proceedings of the 2016
Conference on Empirical Methods in Natural
Language Processing,
2383–2392.
https://doi.org/10.18653/v1/D16
-1264
Seiten
Zhongzheng Ren, Raymond Yeh, and Alexander
Schwing. 2020. Not all unlabeled data are
equal: Learning to weight data in semi-
supervised learning. In Advances in Neural
Information Processing Systems, Volumen 33,
pages 21786–21797. Curran Associates, Inc.
Julian McAuley, Christopher Targett, Qinfeng
Shi, and Anton Van Den Hengel. 2015. Image-
Devendra Sachan and Graham Neubig. 2018.
Parameter sharing methods for multilingual
1339
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
self-attentional translation models. In Confer-
ence on Machine Translation.
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Improving neural machine trans-
lation models with monolingual data. In Pro-
ceedings of the 54th Annual Meeting of the
Verein für Computerlinguistik
(Volumen 1: Long Papers), pages 86–96.
https://doi.org/10.18653/v1/P16
-1009
Jun Shu, Qi Xie, Lixuan Yi, Qian Zhao, Sanping
Zhou, Zongben Xu, and Deyu Meng. 2019.
Meta-weight-net: Learning an explicit map-
In Advances
ping for
in Neural Information Processing Systems,
pages 1919–1930.
sample weighting.
Samarth Sinha, Han Zhang, Anirudh Goyal,
Yoshua Bengio, Hugo Larochelle, and Augustus
Odena. 2020. Small-gan: Speeding up gan train-
ing using core-sets. In International Conference
on Machine Learning, pages 9005–9015.
PMLR.
Richard Socher, Alex Perelygin, Jean Wu, Jason
Chuang, Christopher D. Manning, Andrew Y.
Ng, and Christopher Potts. 2013. Recursive
deep models for semantic compositionality over
a sentiment treebank. In Proceedings of the
2013 Conference on Empirical Methods in Nat-
ural Language Processing, pages 1631–1642.
Peng Su, Yifan Peng, and K. Vijay-Shanker.
2021. Improving bert model using contrastive
learning for biomedical relation extraction.
the 20th Workshop on
In Proceedings of
Biomedical Language Processing, pages 1–10.
Felipe Petroski Such, Aditya Rawal, Joel Lehman,
Kenneth Stanley, and Jeffrey Clune. 2020. Gen-
erative teaching networks: Accelerating neural
architecture search by learning to generate
synthetic training data. In International Confer-
ence on Machine Learning, pages 9206–9216.
PMLR.
Alex Wang, Amanpreet Singh, Julian Michael,
Felix Hill, Omer Levy, and Samuel R.
Bowman. 2018A. GLUE: A multi-task bench-
mark and analysis platform for natural lan-
guage understanding. arXiv preprint arXiv:
1804.07461. https://doi.org/10.18653
/v1/W18-5446
Alex Wang, Amanpreet Singh, Julian Michael,
Felix Hill, Omer Levy, and Samuel R.
Bowman. 2018B. GLUE: A multi-task bench-
mark and analysis platform for natural language
In International Conference
Verständnis.
on Learning Representations. https://doi
.org/10.18653/v1/W18-5446
Dong Wang, Ning Ding, Piji Li, and Haitao
Zheng. 2021. Cline: Contrastive learning with
semantic negative examples for natural lan-
guage understanding. In Proceedings of the
59th Annual Meeting of
the Association
for Computational Linguistics and the 11th
International Joint Conference on Natural Lan-
guage Processing (Volumen 1: Long Papers),
pages 2332–2342. https://doi.org/10
.18653/v1/2021.acl-long.181
Yulin Wang, Jiayi Guo, Shiji Song, and Gao
Huang. 2020. Meta-semi: A meta-learning ap-
proach for semi-supervised learning. CoRR,
abs/2007.02394.
Alex Warstadt, Amanpreet Singh, and Samuel
R. Bowman. 2019. Neural network acceptabil-
ity judgments. Transactions of the Associa-
tion for Computational Linguistics, 7:625–641.
https://doi.org/10.1162/tacl a 00290
Adina Williams, Nikita Nangia, and Samuel
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding through in-
Referenz. In Proceedings of the 2018 Confer-
ence of the North American Chapter of the
Verein für Computerlinguistik: Hu-
man Language Technologies, Volumen 1 (Long
Papers), pages 1112–1122. https://doi
.org/10.18653/v1/N18-1101
Pengtao Xie, Aarti Singh, and Eric P. Xing.
2017. Uncorrelation and evenness: Ein neues
In Interna-
diversity-promoting regularizer.
tional Conference on Machine Learning,
pages 3811–3820. PMLR.
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun.
2015. Character-level convolutional networks
for text classification. In NeurIPS.
Guoqing Zheng, Ahmed Hassan Awadallah, Und
Susan Dumais. 2021. Meta label correction
for learning with weak supervision. AAAI.
https://doi.org/10.1609/aaai.v35i12
.17319
1340
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
1
2
0
6
2
1
6
1
/
/
T
l
A
C
_
A
_
0
0
5
2
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3