David Temperley
Eastman School of Music
26 Gibbs St.
Rochester, Nueva York 14604 EE.UU
dtemperley@esm.rochester.edu
An Evaluation System
for Metrical Models
In the young and rapidly expanding field of music
artificial intelligence, one particularly active area of
research has been metrical analysis (also known as
meter-finding, beat tracking, beat induction,
rhythm parsing, and rhythm transcription)—the
problem of extracting metrical information from
música. En efecto, it would probably be fair to say that
no problem in the field has attracted as much at-
tention and energy as this one. Mesa 1 shows a list
de 25 studies that present computational models of
metrical analysis. (The table includes all published
studies—not master’s and Ph.D. theses—that I have
been able to identify and obtain. It includes only
models that have been implemented or at least
completely specified; well-known models in music
theory such as Lerdahl and Jackendoff’s (1983) son
excluded for this reason. Also excluded are models
that identify tempo only without identifying actual
beat locations, such as Brown 1993. In cases where
several studies present close variants of a single
modelo, only one study is listed.)
The models in Table 1 reflect a variety of per-
spectives on the metrical analysis problem. Ellos
might be categorized along several different lines.
One fundamental distinction concerns the nature
of the input; hasta hace poco, almost all systems
worked from symbolic (‘‘note’’) input of some kind,
but in the last few years several models have been
proposed which operate directly from audio data.
Some models assume a quantized input (for exam-
por ejemplo, with durations represented by small integer
valores), whereas some allow the fluctuations in
timing characteristic of human performance; alguno
models generate just a single level of beats,
whereas others generate several. Por supuesto, el
models might also be categorized in terms of their
acercarse (basado en reglas, connectionist, oscillator-
based, probabilístico, etc.), but this is a more com-
plex matter, so I do not consider it in Table 1.
Perhaps the most basic question to address about
a model—though it is not always addressed—is its
Computer Music Journal, 28:3, páginas. 28–44, Caer 2004
(cid:1) 2004 Instituto de Tecnología de Massachusetts.
meta. Some metrical analysis systems are clearly in-
tended to model human cognition; others are sim-
ply designed to solve the practical problem of
meter-finding in whatever way seems most effec-
tivo. The importance of meter-finding as a cogni-
tive process seems self-evident; meter is a basic
part of musical experience and has been shown to
influence other aspects of music cognition as well,
such as melodic similarity (Gabrielsson 1973), ex-
pectation (Jones et al. 2002), harmony perception
(Temperley 2001), performance expression (Sloboda
1983; Palmer 1997), and performance errors (Palmer
and Pfordresher 2003). Sin embargo, the practical prob-
lem is important as well. En particular, generating
music notation for a piece requires identification of
its meter. As argued in Temperley (2001), if we
conceive of a metrical structure as a multi-leveled
framework of beats (whole-note beats, half-note
beats, etcétera, down to the smallest rhythmic
level in the piece), the metrical structure of a piece
essentially provides the information required to
rhythmically notate it. Y, precisely because of
the central role of metrical structure in music cog-
nition (as argued above), it will inevitably come
into play in other problems of musical engineering.
Por ejemplo, tasks such as matching queries to a
musical database, categorizing pieces by style or
mood, or generating an accompaniment for a mel-
ody will surely require the consideration of metri-
cal information.
Whatever the goals and assumptions of a metri-
cal model, an important and obvious question to
ask is, ‘‘How good is it?’’ That is, what percentage
of the time does it actually produce the correct re-
sultado? (The ‘‘correct result’’ can be defined as the
metrical structure inferred by competent listeners.
There might, por supuesto, be some subjective differ-
ences among listeners; one might also take the mu-
sic notation for the piece to represent its meter. Pero
in most cases, I would argue, there will be agree-
ment among these sources.) If a model is intended
as a practical tool for meter-finding, the importance
of this question hardly needs defending. If the
model is intended as a hypothesis about cognition,
28
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 1. Models of Metrical Analysis
Reference
Longuet-Higgins and Steedman (1971)
Longuet-Higgins (1976)
Steedman (1977)
Chafe et al. (1982)
Longuet-Higgins and Lee (1982)
Povel and Essens (1985)
Desain and Honing (1989)
Allen and Dannenberg (1990)
Sotavento (1991)
Miller et al. (1992)
Rosenthal (1992)
Rowe (1993)
Large and Kolen (1994)
McAuley (1994)
Parncutt (1994)
Scheirer (1998)
Temperley and Sleator (1999)
Cemgil et al. (2000a, 2000b)
dixon (2001a)
Eck (2001)
Goto (2001)
Raphael (2001)
Sethares and Staley (2001)
Spiro (2002)
van Zaanen et al. (2003)
Input: Audio
or Symbolic?
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
symbolic
audio
symbolic
symbolic
symbolic or audio
symbolic
audio
symbolic
audio
symbolic
symbolic
Input: Quantized
or Performed?
Output:
Multiple Levels?
quantized
performed
quantized
performed
quantized
quantized
performed
performed
quantized
quantized
performed
performed
performed
performed
quantized
performed
performed
performed
performed
quantized
performed
performed
performed
quantized
quantized
Sí
Sí
Sí
Sí
Sí
No
Sí
No
Sí
Sí
Sí
Sí
Sí
No
No
No
Sí
Sí
No
No
Sí
Sí
Sí
Sí
Sí
the relevance of its level of performance is less
clear. A model could perform perfectly, producing
exactly the correct structure (es decir., the one inferred
by most listeners) en 100 percent of cases, and yet
bear no resemblance whatsoever to the cognitive
process of meter-finding; a model that was only
correcto 20 percent of the time might still turn out
to capture important aspects of the cognitive pro-
impuesto. Yet it seems to be generally accepted in cogni-
tive science that the level of performance of a
cognitive model is at least one valid criterion to
consider in evaluating it, though there are certainly
otros. (One might consider, Por ejemplo, how well
the model accords with other experimental evi-
dence about the cognitive process, whether the
model’s architecture and computational demands
are psychologically plausible, and so on.) Given
two cognitive models A and B, otherwise equal in
cognitive plausibility, if model A’s output is much
mejor (closer to that of humans) than model B’s,
this surely gives model A greater credibility as a
hypothesis about cognition.
En breve, the level of performance of a metrical
model is of central importance to the practical goal
and of at least some importance to the cognitive
meta. Given the large number of metrical models
that have been proposed, entonces, it seems worthwhile
to examine the quality of their performance. El
aim of the current article is actually not to answer
this issue directly, but rather to address a prelimi-
nary question: ‘‘How can we decide how good a
metrical model is?’’ In what follows, I propose a
system for evaluating metrical models with the
goal of measuring their performance and comparing
their strengths and weaknesses in this regard.
Temperley
29
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Four Requirements for an Evaluation System
The problem at hand exemplifies a commonly oc-
curring situation in artificial intelligence and other
fields. The ultimate goal is to develop systems that
can retrieve some kind of information from data;
many models are available for the task, and we
wish to be able to evaluate their success. For such
an evaluation system, I submit that four things are
needed: an agreed-upon way of representing the
kind of information to be retrieved; a suitably large
and representative corpus of data; correct analyses
of the corpus (representing the information to be
retrieved); and an agreed-upon way of comparing a
model’s analyses of the corpus to the correct analy-
ses and scoring the model on its success at match-
ing the correct analyses.
It is useful to consider a successful solution to
the evaluation problem in another domain—com-
putational linguistics. Since the birth of the field, a
central project in computational linguistics has
been the development of systems for natural-
language parsing—recovering syntactic information
from written or spoken text. Until recently, pro-
gress in this area was hindered by the difficulty of
evaluating models and comparing one model to an-
otro. In the early 1990s, this problem was largely
solved by the development of the Penn Treebank
(Marcus et al. 1993). The Penn Treebank is a cor-
pus of several million words of naturally occurring
text gathered from both written and spoken
sources. The treebank is accompanied by syntactic
analyses done by experts—a ‘‘constituent struc-
ture’’ for each sentence showing noun phrases, verb
phrases, clausulas, etc.. Metrics have been proposed
for comparing ‘‘treebank-style’’ analyses (Black et
Alabama. 1991), and programs are available that take two
analyses of a set of sentences—the correct analysis
colocar (known as a ‘‘goldfile’’) and one produced by a
model to be evaluated (a ‘‘testfile’’)—and evaluate
how well the testfile analyses match those of the
goldfile.
For the problem of natural-language parsing, entonces,
it can be seen that all four of the requirements listed
above have been met. This achievement has led to a
surge of progress in natural-language parsing. (Para
discussion, see Manning and Schu¨ tze 2000.) En
what follows, I consider possible solutions to these
four requirements for the metrical-model evalua-
tion problem.
Previous Work on the Evaluation
of Metrical Models
For the most part, issues of evaluation have re-
ceived little attention in the literature on metrical
análisis. Many studies present no quantitative per-
formance measures for the models presented. En el
last few years, sin embargo, some important proposals
have been offered in this area.
The appropriate way of evaluating a metrical
model depends on the nature of the model. Nosotros
might distinguish first between models accepting
only quantized input and those accepting per-
formed input. In quantized-input models, tiempo-
points are generally represented as multiples of a
short rhythmic value or ‘‘base unit,’’ such as a
sixteenth-note. Such models generally assume that
the metrical structure is perfectly regular through-
afuera. In such a case, each level of the metrical struc-
ture can be characterized by two numbers: uno
indicating its period (in base units), or the distance
between beats; the other indicating the phase
(again in base units)—how long after the beginning
of the piece the first beat occurs. A level generated
by the model could be said to be correct if its pe-
riod and phase exactly match one of the levels in
the correct metrical structure. This is essentially
the approach used by Desain and Honing (1999).
Desain and Honing evaluate three metrical models
(the model of Longuet-Higgins and Lee 1982 y
two later variants of it) using three test corpora: a
set of randomly generated rhythms, a set of ‘‘metri-
cal’’ rhythms (in which each note is exactly one
beat long at some metrical level), and a corpus of
national anthem melodies. Each of the three mod-
els tested generates only a single beat level. Para
each model, the authors present data regarding the
proportion of input cases for which the model’s
beat matches the main beat level in the correct
estructura (in both period and phase); they also pres-
ent data comparing the model’s beat to other beat
levels in the correct structure. (Van Zaanen et al.
30
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2003 use the same anthem corpus and a similar
testing strategy.) Desain and Honing’s approach
seems very sensible for evaluating quantized-input
modelos. In what follows, we focus mainly on
performed-input models; as can be seen from Table
1, most models in recent years have addressed per-
formed input.
An approach to evaluating performed-input met-
rical models is presented by Cemgil et al. (2000b).
This requires data in which the locations of beats
are explicitly indicated. (Just one level of beats is
assumed.) Assume that the correct beat level for a
piece is S (cid:2) s1, s2, . . ., sI (where each sn is the time
point of a beat), and the model’s output beat level
is T (cid:2) t1, t2, . . ., tJ. The score W for the closeness of
any two beats si and tj is expressed using a Gaus-
sian window function (so that two exactly simulta-
neous beats receive a score of 1). The similarity
function between S and T is then
i
R max W (s , t )
j
(I (cid:3) j) / 2
i
j
• 100
This formula takes each correct beat, pairs it with
the closest beat to it in the model’s output, y
adds together the W scores for these beat pairs.
This is then divided by the average of I and J
(which means that the model’s output will be pe-
nalized if it has many more beats than the correct
estructura) and multiplied by 100. The result is a
single number that roughly indicates the percent-
age of correct beats that were matched by the
model’s beats. Using this evaluation technique,
Cemgil et al. (2000b) tested their own model on
keyboard performances of the Beatles song ‘‘Yester-
día,’’ played multiple times by different performers
and under different tempo instructions (fast, nor-
mal, or slow). (The model was essentially given the
correct initial tempo and phase.) dixon (2001b)
later tested his model against that of Cemgil et al.
using a similar evaluation method and the same
data set, and he reported overall scores of 94 (cid:4) 9
for his model versus 91 (cid:4) 7 for the model of Cem-
gil et al.
A somewhat similar approach is proposed by
Goto and Muraoka (1997) for testing an audio-input
metrical model. The system requires that the audio
input be supplemented with markers, added by
mano, indicating the correct beat locations. Goto
and Muraoka present an audio-input model that
outputs multiple levels of beats; the model is eval-
uated in the following way. For each correct beat
cn, the closest beat Bm in the model’s output is
found, and an error is calculated, which is the time
difference between Cn and Bm as a proportion of the
interval between correct beats. The longest cor-
rectly tracked portion of the piece is found (es decir., el
longest span in which the error is less than a cer-
tain value). The test set consisted of 40 songs (de
popular music recordings without drums), each at
el menos 1 min long, by a variety of artists. The au-
thors define a correct analysis as one in which
(1) the longest correctly tracked portion begins no
later than 45 sec after the beginning of the piece
and extends to the end, y (2) the mean, variance,
and maximum of the error are within certain val-
ues. (Por ejemplo, the mean error must be less than
0.2.) By this criterion, the model analyzed 87.5 por-
cent of the input songs correctly at the quarter-note
nivel.
The approaches of Cemgil et al. and Goto and
Muraoka offer valuable contributions toward the
evaluation of performed-input metrical models.
Sin embargo, they also encounter certain difficulties.
En particular, they require the location of every beat
to be exactly specified, when in fact the exact loca-
tion of beats is often somewhat indeterminate.
Consider a MIDI file of a classical piece generated
from a piano performance (or an audio file, for that
asunto). There will likely be many chords in which
several notes are understood as simultaneous and
coinciding with a certain beat. But most likely they
will not be played exactly simultaneously; so where
exactly is the beat? There may also be beats with
no coinciding note, so again the exact location of
the beat is uncertain. This problem can be solved
by having human annotators provide the beat infor-
mation according to their intuition. But this solu-
tion is far from ideal; such hand-annotation is
time-consuming and also somewhat subjective. Él
seems that, in evaluating a metrical analysis, nosotros
should focus on the aspects of the metrical struc-
ture that are clear and uncontroversial. Certain
beats correspond with certain notes, and other
beats may be in between but not necessarily at
Temperley
31
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
determinate locations. (Concrete examples of this
will be given later.)
One method that addresses this problem is what
could be called the ‘‘score-time’’ system. En esto
sistema, the correct metrical structure for a piece is
used to generate a quantized rhythmic representa-
tion such that each event has a correct location or
‘‘score-time’’ in the piece. Por ejemplo, if quarter-
note beats are defined as integers, a note on the
first quarter-note beat is at score-time 0.0, a note
on the next beat is at 1.0, and a note one eighth-
note later is at 1.5. Such a system for rhythmic rep-
resentation has been used for various purposes—for
ejemplo, in score-performance matching (Heijink
et al. 2000). A metrical model could then operate
by assigning a score time to each note; el modelo
could be evaluated according to (Por ejemplo) el
proportion of notes that were assigned the correct
score-time. Notice that such a model need not de-
cide the exact location of indeterminate beats that
contain no notes. Sin embargo, this system in effect
only represents one level of meter: generally the
main beat level or ‘‘tactus.’’ Score-times do not in-
dicate higher metrical levels, p.ej., whether tactus
beats are grouped in duples or triples (though such
information could be indicated in other ways; ver
for example Cemgil et al. 2000a). This measure is
also rather inflexible. If a model inserted one extra
beat near the beginning of the piece, then all of the
score-times for subsequent events would be judged
as incorrect, which seems unduly harsh.
In what follows, I propose an alternative ap-
proach to metrical evaluation. This builds on the
‘‘score-time’’ idea, but allows multiple metrical
levels and also permits a more flexible comparison
of metrical analyses. It should be stated at the out-
set that the system is intended primarily for
symbolic-input models. Whether it will also be
useful for audio-input models is an open question; I
return to this at the end of the article.
A Representation System
We must first consider how to represent the input
data—the data to be analyzed. Following many
other models, I will assume a representation con-
sisting of a list of notes encoded with ‘‘ontime’’ and
‘‘offtime’’ (both in msec) and pitch (in integer nota-
ción, with middle C (cid:2) 60). Such a representation,
similar to a MIDI file, is sometimes known as a
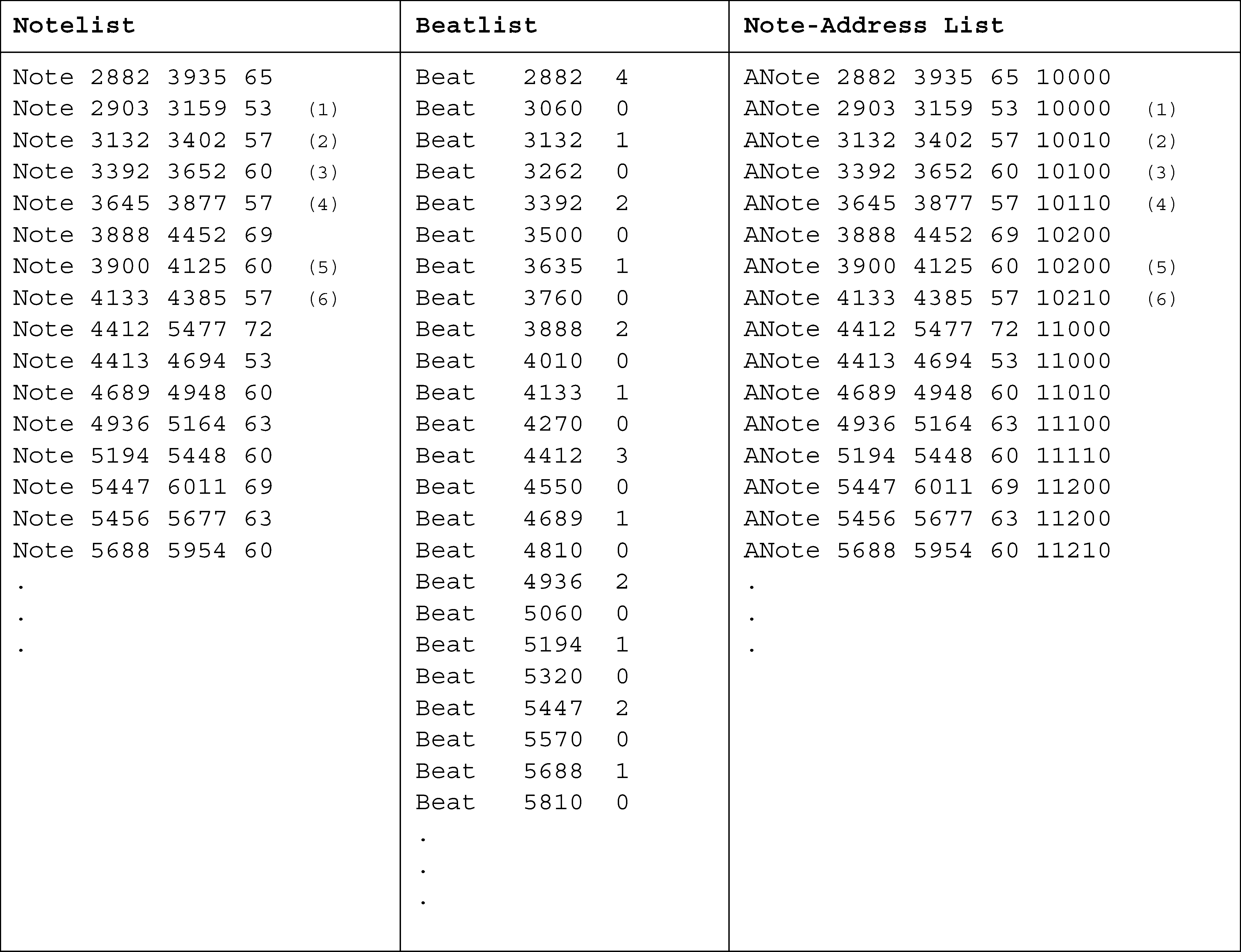
‘‘notelist.’’ Figure 1 shows the opening of a Mozart
piano sonata; the leftmost column below the score
shows the notelist for the first two measures. (El
numbers in parentheses have been added for refer-
ence in the following discussion.) Notice that this
system does not assume that the events are quan-
tized (except at the very low level of msec); the no-
telist in Figure 1 was generated from a performance
on a MIDI keyboard, and it can be seen that the
timing is somewhat irregular.
We now turn to the representation of the metri-
cal structure itself. Most metrical models produce
some kind of representation of beats aligned with
the music that was given as input. Beats are simply
points in time, subjectively understood as accented,
though not necessarily coinciding with any event.
Some systems (as discussed above) generate several
levels of beats, or—to put it another way—beats of
varying strength, where ‘‘strong’’ beats are present
at higher levels and ‘‘weak’’ beats only at lower
niveles. A metrical structure can be represented
graphically as a framework of dots (Lerdahl and
Jackendoff 1983), as shown in Figure 1 above the
staff. In Temperley and Sleator (1999), we proposed
encoding such a structure as a list of beat state-
mentos, each one with a timepoint and a level num-
ber representing the highest level at which that
beat is present; the ‘‘beatlist’’ for the first two mea-
sures of the metrical grid in Figure 1 is shown in
the middle column below the score. We assume a
structure of five metrical levels, numbered 0–4,
with higher numbers representing higher levels;
nivel 2 is the ‘‘tactus’’ or main beat, the quarter-
note level in this case. (The assumption of five lev-
els seems optimal for common-practice music in
general, though some pieces may call for more or
fewer levels; see Lerdahl and Jackendoff 1983 y
Temperley 2001 for discussion.)
Given this representation scheme, one possible
idea for an evaluation system is as follows. Let us
assume a corpus of pieces or excerpts encoded in
notelist format. Each excerpt could be annotated
32
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. Mozart, Sonata
KV 332, I, mm. 1–5, espectáculo-
ing metrical grid (arriba
the staff), notelist, beatlist,
and note-address list.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
with the correct beatlist; this could then be com-
pared with a beatlist generated by the model being
probado (similar to the approaches of Goto and Mu-
raoka 1997 and Cemgil et al. 2000b). A problem
arises here, as has already been mentioned: the lo-
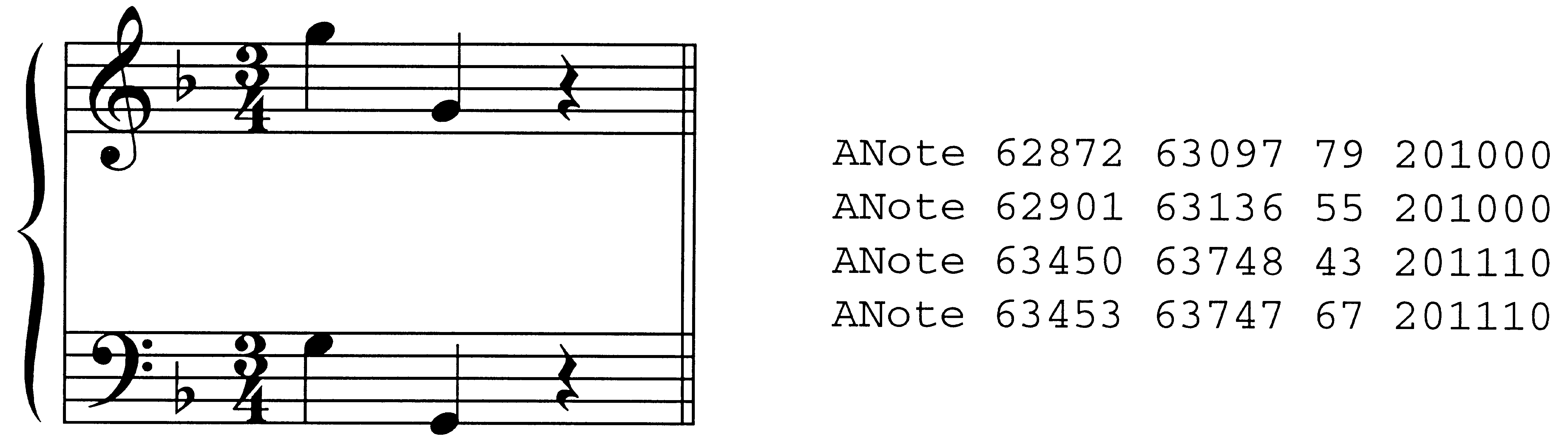
cation of beats is often indeterminate. En figura 1,
the first notes in the right hand and the left hand
are understood as coinciding with the first beat, pero
they are not exactly simultaneous. Is the beat lo-
cated at 2882, 2903, or somewhere in between?
(The beatlist in Figure 1 arbitrarily aligns the beat
with the first of these two onsets.) Además,
many beats have no coinciding note. In Figures 2a
and 2b (excerpts from later in the same piece),
where exactly is the second quarter-note beat of
metro. 12, or the third quarter-note beat in m. 40? El
same could be said of all the level-0 beats in Figure
1, none of which coincide with notes. En efecto, uno
might question whether level-0 beats are even pres-
ent in this passage. The location of these indeter-
Temperley
33
Cifra 2. Three excerpts
from Mozart, Sonata KV
332, I, showing note-
address lists at right.
(Figures 2a and 2b show
five-value note-addresses;
Figure 2c shows six-value
note addresses.)
(a) metro. 12
(b) metro. 40
(C) metro. 8
34
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
minate beats could perhaps be determined in
perceptual terms—we do have some intuitions
about where the second beat of m. 12 ocurre (prob-
ably roughly halfway between the first and third
quarter-note beats)—but for a human annotator to
produce the correct answer would be quite diffi-
cult.
As suggested earlier, for the purposes of metrical
evaluación, we should focus on what is uncontro-
versial. And some things do seem uncontroversial:
in Figure 2a, the notes of the first chord fall on the
beat, even though they may not be exactly simulta-
neous. This is followed by an empty beat (aunque
its exact timepoint is indeterminate), seguido por
another chord on the third beat of the measure.
(Notice also that the exact location of beat 2 of m.
12 is not needed for the purpose of converting the
beatlist into notation. As long as it is known that
the first chord coincides with the first level-2 beat
of the measure, and the second chord with the
third level-2 beat, with one other level-2 beat
somewhere in between, this is all that is required.)
One representation system that meets this re-
quirement is what I will call the ‘‘note-address’’
system—shown in the right-hand column of Figure
1 for the opening of the Mozart sonata excerpt. Él
can be seen that the list of events here includes all
the information of the original notelist, pero el
Note statements have become ANote statements,
consisting of an ontime, offtime, pitch, and ‘‘note
address’’—a number representing the note’s posi-
tion in the metrical grid. This number should re-
ally be thought of as a five-valued vector, but it can
be represented as a single integer, as none of the
values ever exceed 9 except for the leftmost one.
(We assume five levels for now, though in principle
more or fewer could be used.) Each value in the
vector corresponds to a level of the metrical grid
(the rightmost value corresponds to level 0). El
value represents the number of beats at that level
that have elapsed at that point in the piece since
the previous beat at the next level up.
Como ejemplo, consider the first six eighth notes
of the left hand, indicated by the numbers in paren-
tesis. For the quarter-note level (correspondiente a
the third digit from the right in the note addresses),
the first and second of these notes have the value 0
(no quarter-note beats have occurred since the last
dotted-half-note beat), the third and fourth have
valor 1 (one beat has occurred), and the fifth and
sixth have value 2 (two beats have occurred). El
highest-level (leftmost) value of the address, cual
is always set to 1 at the start of the piece, representar-
sents the number of highest-level beats that have
elapsed in the piece as a whole (since there is no
higher level from which to count). Eventually this
could become a 2- or 3-digit number, producing ad-
dresses like 20-1-0-0-0 (as in Figure 2b). One could
actually assign addresses to the beats themselves;
in a perfectly regular duple grid, this would be
equivalent to counting binary numbers (10000,
10001, 10010, 10011, 10100, . . .), with the excep-
tion that the leftmost digit is not binary. Sin embargo,
if we assign addresses only to notes, we avoid the
earlier-discussed problem of having to decide on
the location of indeterminate beats.
The note-address system also solves the problem
created by nominally simultaneous notes. As ob-
served earlier, the notes of a chord are generally un-
derstood as occurring on the same beat (and would
be represented that way in notation), sin embargo lo son
rarely performed exactly simultaneously. Thus as-
signing the ‘‘beat’’ to a single timepoint is diffi-
cult—indeed impossible, if we want all the notes of
the chord to be represented as coinciding with the
beat. The solution provided by the note-address
system can be seen in Figure 1. In m. 1, the first
right-hand and first left-hand notes can be given
the same address, even though they do not exactly
coincide, representing that they are understood as
being simultaneous in metrical terms and should
be notated that way.
One further refinement of the note-address sys-
tem is needed. It is generally accepted in metrical
theory that not all notes necessarily coincide with
beats; alguno, like trills, turns, and grace notes, son
‘‘extrametrical’’ (Temperley 2001). Figure 2c shows
an example from m. 8 of the Mozart excerpt. Two
notes in the right-hand (notated in small note-
cabezas, as is customary) do not really occur on any
beat. To accommodate extrametrical notes, nosotros en-
troduce one further (rightmost) digit of the note-
address. This digit is 0 for any note that coincides
with a beat; for a note that is between two beats,
Temperley
35
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
the address of the note is the address of the previ-
ous beat, except with 1 as the final digit. If there
are multiple, non-coinciding notes between the two
beats, the final digit of their addresses reflects their
ordering in time: the first extrametrical note in Fig-
ure 2c is labeled 410111, the second 410112. (problema-
lems would arise if there were more than nine
non-coinciding notes between two beats, pero esto
seems unlikely to occur.) A note address therefore
has six values, which we will refer to as levels 4, 3,
2, 1, 0 (for the five metrical levels), and –1 (the ex-
trametrical level).
The note-address system is not perfect. For one
thing, not only does it fail to represent the location
of beats with no coinciding note, it sometimes
even fails to represent their existence. In Figure 2a,
Por ejemplo, there is no explicit indication of the
second beat of the measure (which would be at ad-
vestido 61100). En este caso, the existence of the miss-
ing beat is implicit in the fact that the following
note has the address 61200; this implies that there
must have been a 61100 también. A more worrisome
case is shown in Figure 2b. Aquí, the third beat of
metro. 40 is not represented even implicitly. If we just
looked at the note addresses for the passage (incluso
including the address of the following downbeat,
210000), we could not even be certain that m. 40
were a triple-meter measure. We should bear in
mente, entonces, that certain errors metrical models
might make would not be recognized under the
note-address system: Por ejemplo, if a metrical
model omitted the third beat in m. 40, or added a
fourth beat (or an extra ten beats) at the end of the
measure. The seriousness of this problem is un-
clear; it depends on how often metrical models ac-
tually make these kinds of errors. (El problema
could be addressed in various ways, Por ejemplo, por
supplementing each highest-level beat with infor-
mation about the duple or triple divisions of the
grid at each level.) Some other limitations of the
note-address system will be discussed in later sec-
ciones.
The Corpus
In selecting a corpus for testing, two considerations
are important. Primero, the criteria used in assembling
the corpus should be as systematic as possible.
Rather than selecting 20 pieces that one knows and
happens to have handy, one should, si es posible, de-
vise objective criteria for inclusion in the corpus.
(The danger is, por supuesto, that those pieces we
know and have handy are likely to be the ones we
usado, or at least thought about, in developing our
model.)
Another requirement is that the corpus should be
a representative sample of the larger corpus that
the models to be tested were designed to analyze.
This is problematic in the current case. Many mod-
els have specifically addressed themselves to
‘‘common-practice’’ music (roughly speaking,
Western art music from 1700 a 1900). (Even here,
there may not be total agreement on what
common-practice music includes.) Other models
have sought to accommodate other kinds of music,
such as jazz, rock, and non-Western music
(Scheirer 1998; Cemgil et al. 2000b; Goto 2001; Se-
thares and Staley 2001). De este modo, I certainly do not
claim that the corpus proposed below would be a
suitable or fair one for all of the models listed in
Mesa 1.
In Temperley (2001), I presented the ‘‘Kostka-
Payne Corpus’’ (hereafter the KP Corpus)—a set of
46 excerpts from the common-practice repertoire
taken from the workbook accompanying Stefan
Kostka’s and Dorothy Payne’s textbook Tonal Har-
mony (1995). The corpus includes all excerpts from
the workbook of at least eight measures in length;
it contains a total of 541 notated measures and
9,057 notas. Although the corpus is not especially
big (a larger one would certainly be desirable), él
has two important advantages: the excerpts were
selected by an objective criterion; and they span a
range of periods, genres, and composers within the
common-practice idiom, so that the corpus can be
considered a reasonably good sample of common-
practice music. Notefiles were generated for all the
excerpts in the corpus; these notefiles are quan-
tized (es decir., generated from notation) and thus have
perfectly regular timing (using tempi that seemed
reasonable to me). Sin embargo, para el 19 excerpts
from the corpus for solo piano, I had a skilled
(doctoral-level) pianist perform the excerpts and
generated notefiles from those as well. (We will call
36
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
this the KP Performed Corpus.) In the quantized
notefiles, no extrametrical notes were included; en
the performed notefiles, the performer was allowed
to include whatever extrametrical notes were de-
sired. The performances contained a few extrane-
ous notes (performance errors) that were
subsequently deleted from the performed files (ow-
ing to the difficulty of deciding on the ‘‘correct’’
metrical location of these); notes erroneously omit-
ted from the performed files were not restored.
Note-address files were generated for all excerpts
in the corpus (both the quantized files and the per-
formed ones) using the format shown in earlier ex-
amples (specifically, the six-value address format
shown in Figure 2c). This was done by running the
input files through the Melisma meter-finding pro-
gram (discussed later), sometimes adjusting the pa-
rameters in ad hoc ways to get the output as close
to correct as possible and then hand-correcting any
remaining errors. With very few exceptions, este
was unproblematic: it was clear, both for the quan-
tized files and the performed files, what the correct
address of each note should be. It was sometimes
not obvious which metrical level should be defined
as the tactus (nivel 2); I used my own musical judg-
ment for these decisions. (In some slow move-
mentos, Por ejemplo, the length of the tactus beats if
the notation were taken literally—e.g., quarter-note
beats in a 2/4 meter—would be over two seconds,
beyond most estimates for the upper range of the
perceived tactus.) Note-addresses were encoded
only up to the notated measure indicated in the
puntaje; ‘‘hypermetrical’’ levels (above the measure)
were not included owing to their subjective nature.
Comparing Goldfiles and Testfiles
We now have a way of representing metrical struc-
turas (the note-address system), a corpus of data,
and correct analyses of the data in the required for-
mat. The final requirement is a way of comparing a
note-address file produced by a metrical model (a
‘‘testfile’’) with the correct analysis (the ‘‘goldfile’’).
We assume for now that the goldfile and testfile
contain exactly the same events (identified by their
pitches and timepoints), though we will modify
this assumption slightly below. Por lo tanto, allá
should be no difficulty in matching events in the
goldfile with their corresponding events in the test-
file. The problem is to compare the note addresses
for corresponding events between the two files.
One very simple approach would be to use ‘‘ex-
act matching,’’ that is, to score the testfile on the
proportion of its events that are assigned exactly
the same address in the goldfile. This would be a
fairly harsh and unforgiving metric. Por ejemplo,
suppose a model erroneously inserted an extra mea-
sure at the beginning of the piece but otherwise an-
alyzed the piece exactly correctly. The leftmost
value of each note address after the inserted mea-
sure would be incorrect (one greater in the testfile
than in the goldfile), so almost every note address
in the piece would be incorrect—though the
model’s analysis was in fact almost completely cor-
recto. (A similar problem arises with the ‘‘score-
time’’ method of meter representation, as discussed
earlier.)
A fairer approach would be to assign the testfile a
score for every level, indicating the proportion of
events that were correctly labeled at that level.
This is the approach taken here, implemented in a
program called compare-na. This program takes as
input two note-address files, a goldfile and a test-
file. For every level L that is present in the note-
addresses in the goldfile (except for the top level—
this is explained later), a score is assigned that
indicates the proportion of events whose note-
address value at level L is the same in the testfile
as in the goldfile. The program also produces an
overall score, which is simply the average of the in-
dividual level scores. (It is not clear how meaning-
ful this is. One could also consider a weighted
puntaje, with some levels—e.g., the tactus level—
weighted more than others. Alternativamente, as I
prefer, one could simply take the level scores indi-
vidually as indicators of the model’s success at the
tactus level, higher levels, and lower levels.)
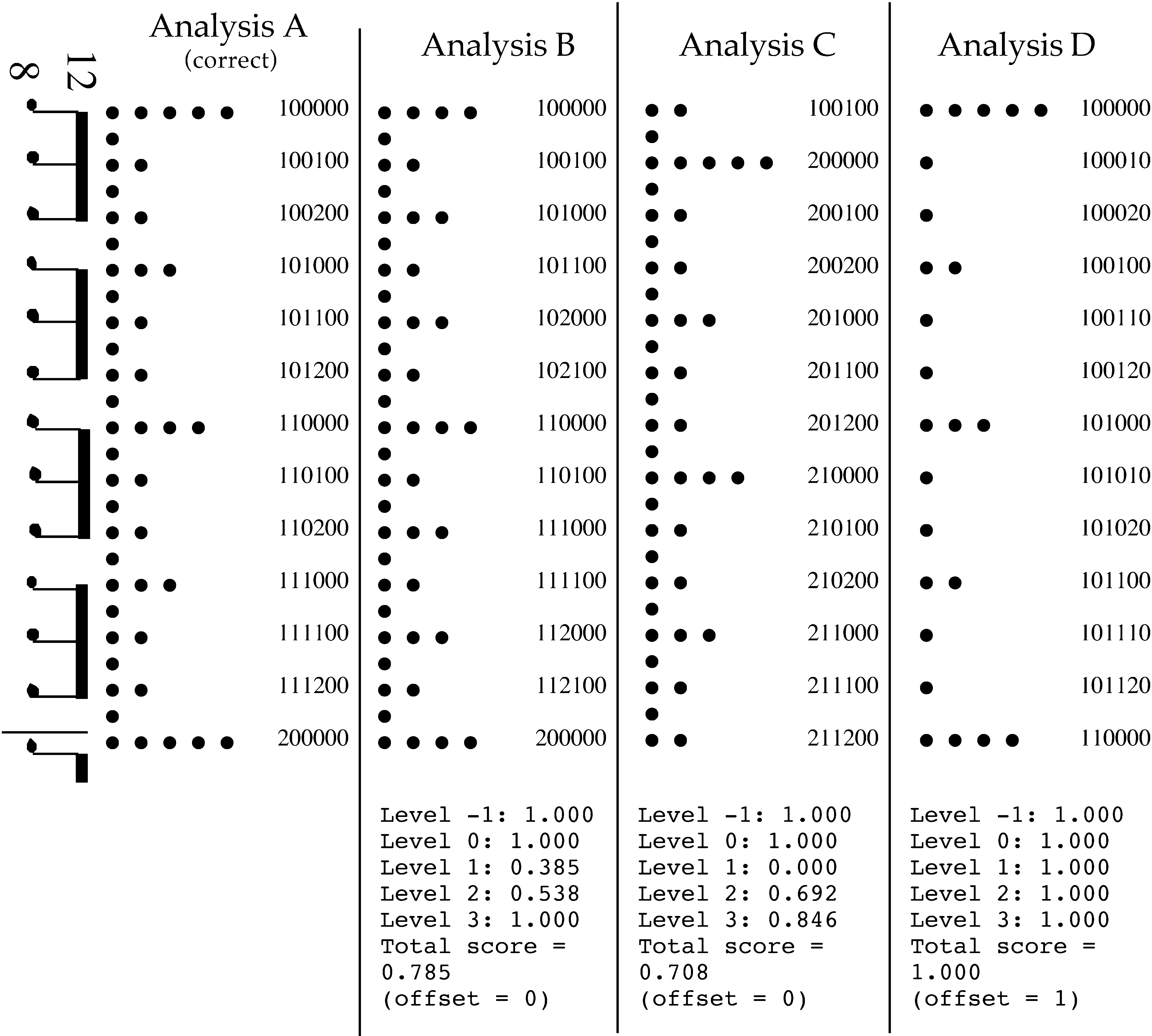
Un ejemplo se muestra en la Figura 3 to give a flavor
of this scoring system. A rhythmic pattern is
shown at left—a simple eighth-note pattern in a
12/8 meter. Four analyses are shown in the form of
Temperley
37
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 3. A rhythmic pat-
tern showing four analyses
as metrical grids and note-
address lists. Analysis A is
the correct analysis. Para
analyses B, C, y D, el
scores for each analysis
compared to analysis A,
according to the note-
address evaluation system,
are shown below.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
metrical grids, the correct one (analysis A) y
three incorrect ones; the note-address list implied
by each grid (for each note of the pattern) is shown
at the right. The scores yielded by compare-na for
analyses B, C, y D, when compared with analysis
A, are shown below each analysis. In all four analy-
ses, no notes are analyzed as extrametrical, de este modo
the rightmost digit is 0 for all notes. Because all
analyses agree totally with analysis A for level –1,
they all receive a score of 1.000 at this level. En
analyses B and C, as in analysis A, every note is an-
alyzed as coinciding with a level 1 beat, so the
second-from-the-right digit is 0 for all notes as
Bueno. (We will discuss analysis D in a moment.)
In analysis B, only level 2 of the metrical grid is
incorrect: in essence, the passage is analyzed as 6/4
instead of 12/8. En este caso, the level-2 values of
the addresses are mostly incorrect, as are the level-
1 valores, leading to low scores for level 2 (0.538)
y nivel 1 (0.385). In analysis C, niveles 2, 3, y 4
are all ‘‘out-of-phase’’ by one eighth-note beat (como si
the piece was notated in 12/8 with the barlines one
note too late). Many of the address values at levels
2 y 3 are now incorrect, as are all of the level 1
valores. Values for levels 0 and –1, sin embargo, are un-
affected.
These examples point out an important, y
rather counterintuitive, aspect of the note-address
sistema. What would normally be thought of as an
error at a particular metrical level will generally af-
fect not only the address values at that level, pero
the values at the next lower level as well. Para esto
reason, también, it seems superfluous to compare the
highest metrical levels of the addresses, porque
any difference in this level will cause differences at
the next level down. Thus the evaluation system
38
Computer Music Journal
compares note-addresses only up to and including
the second-highest level present in the goldfile.
(Notice the address assigned to the upbeat in
analysis C. For the first beat in the piece, we assign
a value of 1 to the highest level present in the
beatlist; all other values are set to 0 except for the
highest level at which that beat is present—level 1
in this case—which is set to 1.)
Important questions arise here regarding how the
similarity between two metrical structures should
be judged. By one criterion, analyses A and C in
Cifra 3 are very similar: both reflect a 12/8 metri-
cal structure, and the structures are also the same
in terms of the periods (intervals between beats) en
each level. Yet the metrical strength of each event
is incorrect; en efecto, from this point of view, analy-
sis C is maximally incorrect. In analysis B, el
‘‘time signature’’ (the duple/triple relationships
among levels) is incorrect, but at least some of the
events have the correct metrical strength. Which of
these two analyses is more similar to analysis A?
The note-address system, along with the compari-
son method proposed here, seems to give fairly in-
tuitive results regarding the similarity between
estructuras. Por ejemplo, analysis B scores higher
overall than analysis C here (0.785 versus 0.708), como
I think it should. Sin embargo, there may be no single
correct answer in this regard; it may depend on the
specific goals for which the model is intended.
Suppose, for the rhythmic pattern shown in Fig-
ura 3, a model produced the output shown in anal-
ysis D. This analysis essentially matches analysis
A, except that the levels of the two analyses are
not aligned: the tactus (dotted quarter note) is level
2 in the goldfile but level 1 in the testfile. It is un-
clear how this situation should be handled. If the
two address lists were compared exactly as they
son, the testfile would receive the very low overall
score of 0.462. This solution is surely too harsh;
analysis D is not as incorrect as a score of 0.462
would suggest.
Another approach would be to compare each
level in the testfile with whichever level in the
goldfile addresses it matches most closely. Esto es
the approach taken by compare-na: different ‘‘off-
sets’’ of the testfile relative to the goldfile are tried,
and the one is chosen that yields the best match.
The program also outputs the offset value that was
chosen; an offset of 1 means that level L in the
goldfile was matched to level L–1 in the testfile. En
an offset of 1, analysis D yields a perfect overall
score of 1.000. (Level –1 in the goldfile has no cor-
responding level in the testfile; all address values
not explicitly indicated in the testfile are assumed
ser 0.) Some might consider this approach too
forgiving. Generally, the perception of a certain
beat level as the tactus or main beat is assumed to
be an important aspect of metrical cognition; el
correct identification of this level might well be re-
garded as part of the meter-finding problem. (Uno
solution would be to consider different alignments
of the goldfile and testfile addresses, but factoring
in a penalty for level misalignment.)
The compare-na program also contains a toler-
ance parameter for timing. Some models, como
the model of Temperley and Sleator (1999), slightly
alter the timepoints of events. One reason for this
is that it allows the notes of a chord—rarely played
exactly simultaneously—to be made simultaneous
and thus aligned with the same beat. Once the time-
points of an event are altered in the testfile, este
could cause problems for the matching of events
between the testfile and the goldfile. The tolerance
parameter addresses this problem; if the tolerance
es 50 mseg, a goldfile event with an onset time of
T can be matched to any testfile event of the same
pitch with an onset time of T (cid:4) 50 mseg. (If for
some reason no matching testfile event within the
specified tolerance is found for a goldfile event,
that goldfile is judged as unmatched at all levels.)
Given a series of outputs (from different pieces or
excerpts) from compare-na, the program tally-na av-
erages the figures for each level over the entire cor-
pus (weighting each excerpt in the corpus equally).
A sample output of tally-na is shown below:
level–1: average proportion correct (cid:2) 0.998 (46)
nivel 0: average proportion correct (cid:2) 0.966 (46)
nivel 1: average proportion correct (cid:2) 0.928 (46)
nivel 2: average proportion correct (cid:2) 0.899 (44)
nivel 3: average proportion correct (cid:2) 0.814 (29)
Overall corpus score (cid:2) 0.931; number with zero
offset (cid:2) 36 out of 46
The numbers in parentheses indicate the number
of excerpts for which that level was eligible for
Temperley
39
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
evaluation in the goldfile data. (Bear in mind that
the goldfile addresses only reflect levels that are ex-
plicitly indicated in the notation, and also that the
highest level of the addresses is never evaluated.
This means that, Por ejemplo, nivel 3 is only eligi-
ble for evaluation if level 4 is present in the goldfile
addresses.) An overall corpus score is also given,
which simply averages all the overall scores for
each excerpt. The program also gives information
about how many testfile analyses reflected the cor-
recto (‘‘zero’’) level offset.
Experiments with Melisma
As an illustration of the evaluation system pro-
posed above, I present an evaluation of the meter-
finding program proposed by Temperley and Sleator
(1999), part of the Melisma system for music analy-
hermana (Temperley 2001). A brief description is needed
of the Melisma metrical model. The model is a
preference rule system that considers a large num-
ber of possible analyses and chooses the one that is
optimal on balance with regard to several criteria.
The main criteria are as follows: (1) prefer for beats
at each level to be aligned with event-onsets, el
more onsets the better; (2) prefer for beats to be
aligned with longer events; (3) prefer for beats to be
regularly spaced at each level. (At the tactus level,
‘‘regularity’’ simply implies that each beat inter-
val—between two adjacent beats—should be close
in length to the previous beat interval; at higher
and lower levels, regularity refers to the relation-
ship between levels, es decir., a consistently duple or tri-
ple relationship between levels is preferred.) El
model contains about a dozen user-settable param-
eters (regarding the relative weight of the prefer-
ence rules and other things); these were set on a
trial-and-error basis, before any testing was done
using the KP Corpus.
Mesa 2 shows results of some tests performed on
both the KP Corpus and the KP Performed Corpus.
For each corpus, the first row shows, for each level,
the number of excerpts for which that level was el-
igible for consideration. Next is shown the perfor-
mance statistics for the Melisma model using the
default parameters of the model (as defined in the
most recently released 2001 version of the system).
Recall that the score for each level indicates a sim-
ple average of the scores for that level over all the
excerpts. No es sorprendente, the overall performance
on the KP files (0.931) was somewhat higher than
on the KP-performed files (0.908)—recall that the
former is generated from notation, the latter from
MIDI keyboard performances—though the differ-
ence is not very large. Regarding the values for dif-
ferent levels, it should be remembered that errors
at one level are mainly reflected in the scores for
the next level down, so the relatively low scores for
niveles 2 y 3 in the KP Corpus mainly indicate er-
rors at levels 3 y 4. (The high score for level 3 en
the KP Performed Corpus is surprising, but only
nine of the performed excerpts contained eligible
data for level 3, so the sample was fairly small.)
As a further test, the Melisma program was run
on piano renditions of the Beatles songs ‘‘Michelle’’
and ‘‘Yesterday’’ using the performances used for
testing by Cemgil et al. (2000b) and Dixon (2001b).
(MIDI files of these are publicly available online at
www.nici.kun.nl/mmm/archives.) Cemgil et al.
and Dixon used many performances of the same
two songs; the current test just used one perfor-
mance of each song (the first performance by the
first subject in the ‘‘classical’’ category, played at a
‘‘normal’’ tempo). Correct note-address files were
generated, and these were compared with the out-
put of the Melisma program. The results are shown
en mesa 3. On ‘‘Yesterday,’’ the tactus level was
largely correct (as indicated by the high values for
nivel 1), as were lower levels; nivel 3 was not as
bien, as it switched from duple meter to triple me-
ter for one section of the piece. On ‘‘Michelle,’’ the
program’s analysis was almost completely correct;
the only errors were due to a few triplet-quarter
notas, and a few ‘‘smudged’’ chords (in which notes
intended as simultaneous were not interpreted as
such by the program).
As well as allowing comparison between models,
the evaluation system proposed here might greatly
facilitate the development and improvement of
modelos. It is now very easy, Por ejemplo, to make a
change in the Melisma meter system, run the sys-
tem on the KP Corpus, generate note-address files
40
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 2. Tests of the Melisma Meter Model on the Kostka-Payne Corpus Using the Note-Address
Evaluation System
Corpus and Model Used
Nivel 3
Nivel 2
Nivel 1
Nivel 0
Level –1
Correct
Offset
En general
Score
KP Corpus (46 excerpts)
# of excerpts with data
Melisma score
With default parameters
Without length factor
With harmonic factor
29
44
46
46
46
0.814
0.664
0.707
0.899
0.774
0.926
0.928
0.895
0.921
0.966
0.955
0.965
0.998
0.997
0.997
KP Performed Corpus (19 excerpts)
# of excerpts with data
9
18
19
19
19
Melisma score
With default parameters
Without length factor
With harmonic factor
0.984
0.620
0.892
0.778
0.524
0.855
0.922
0.740
0.880
0.945
0.850
0.947
0.960
0.937
0.963
—
36
36
37
—
15
13
15
—
0.931
0.877
0.923
—
0.908
0.743
0.909
Mesa 3. Tests of the Melisma Model on Beatles Songs
Input piece
Nivel 3
Nivel 2
Nivel 1
Nivel 0
Level –1
‘‘Yesterday’’
‘‘Michelle’’
0.836
1.000
0.755
0.971
0.958
0.971
0.986
0.980
1.000
1.000
Correct
Offset?
Sí
Sí
En general
Score
0.907
0.984
automatically from the resulting beatlists, y
compare these to the correct note-address files to
see if the change resulted in better, worse, or un-
changed performance.
Como ejemplo, one might wonder how crucial
the consideration of length (the preference for
aligning beats with longer notes) is for the meter-
finding process. This was examined by altering a
parameter of the Melisma system so that all notes
are assumed to be just 0.1 sec in length (shorter
than the vast majority of actual notes)—thus, in ef-
fect, removing length distinctions between notes.
Los resultados se muestran en la tabla. 2. For the KP Cor-
pus, ignoring note-length distinctions results in a
fairly modest decrease in performance from 0.931
a 0.877; for the KP Performed Corpus, the loss of
length information had a greater effect, reduciendo
performance from 0.908 a 0.743.
Efforts are also underway to improve the Me-
lisma model through the incorporation of other fac-
tores. One obvious factor to include is harmony. Es
generally agreed that harmonic structure can
greatly influence metrical structure (particularly at
higher metrical levels), in that strong beats tend to
be perceived at points of harmonic change (Lerdahl
and Jackendoff 1983; Temperley 2001). To incorpo-
rate the influence of harmony, the KP Corpus was
run through the Melisma harmony program, creat-
ing a harmonic analysis of segments labeled with
roots; the notelists plus harmonic information were
then ‘‘piped’’ back into the meter program, modi-
fied to include a preference for strong beats on
changes of harmony. After some parameter tweak-
En g, the best performance that could be obtained is
mostrado en la tabla 2 for both the KP Corpus and the
KP Performed Corpus. For both corpora, it can be
seen that the score for level 2 is indeed somewhat
mejorado, but scores for levels 3 y 1 are wors-
terminado; en general, the ‘‘harmonic-factor’’ model and the
default model are roughly equal in performance
(the difference between their overall scores is less
than 1 percent for both the quantized and per-
Temperley
41
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
formed corpora). In situations such as this, un mayor
corpus would be desirable; differences in perfor-
mance of 1 percent are probably not significant on
the KP Corpus. (It would also be desirable to have
one large portion of the corpus for model develop-
ment and parameter-tuning, and another ‘‘held-
out’’ portion for testing.)
Conclusions
It is hoped that the system presented here will fa-
cilitate the testing and comparison of metrical
modelos. Although the system does have certain
limitations, as discussed above, it offers a rational
way of comparing metrical structures whose results
accord reasonably well with intuition. The KP Cor-
pus presented here also has limitations, especially
the fact that it represents only common-practice
música, which may not be fair to the aims of some
metrical models. Por supuesto, the note-address sys-
tem could also be used with a different corpus (como
illustrated by the tests on Beatles songs presented
arriba), providing that the corpus is annotated with
note-address information. Notice that the system
does not in any way require note addresses with
five levels; it could function perfectly well with,
decir, tres niveles.
Perhaps the greatest limitation of the note-
address system is that it is limited to symbolic in-
put. This is unfortunate, given the considerable
number of models proposed in recent years that
take audio data as input. The note-address system
podría, in principle, be used with audio models. El
problem is that the indeterminacy of beat locations
encountered with symbolic input is vastly greater
with audio input. Even with a single note, bajo-
stood as coinciding with a beat, it is often unclear
where exactly the note begins (and thus where the
beat is located). Para resolver este problema, the input
files would have to be annotated with markers in-
dicating the beat positions; at this point the ap-
proach becomes very similar to that of Goto and
Muraoka (1997). Sin embargo, the idea of note ad-
dresses might still be useful; even with audio in-
put, one might argue that some beat locations are
more certain than others (p.ej., the location of a beat
that coincides with a note is more certain than a
beat that does not), and a metrical model should
perhaps only be evaluated on its identification of
the more certain ones. Another problem is that, en
the symbolic-input case, the model is given the ad-
dress locations—i.e., the note onsets—whereas in
the audio-input case, it is part of the model’s task
to find these locations. (In the audio situation, a
model might assert an address where there was not
one or fail to assert one where there was one.)
De este modo, the usefulness of the note-address system for
audio-input metrical models remains to be seen.
Expresiones de gratitud
Thanks are due to Henkjan Honing for valuable
feedback on an earlier version of this article.
Referencias
allen, PAG., y r. Dannenberg. 1990. ‘‘Tracking Musical
Beats in Time.’’ Proceedings of the 1990 Internacional
Computer Music Conference. San Francisco: interna-
tional Computer Music Association, páginas. 140–143.
Negro, MI., et al. 1991. ‘‘A Procedure for Quantitatively
Comparing the Syntactic Coverage of English Gram-
mars.’’ Proceedings of the Fourth DARPA Speech and
Natural Language Workshop. San Francisco: morgan
Kauffman, páginas. 306–311.
Marrón, j. C. 1993. ‘‘Determination of the Meter of Musi-
cal Scores by Autocorrelation.’’ Journal of the Acousti-
cal Society of America 94:1953–1957.
Cemgil, A. T., PAG. Desain, y B. Kappen. 2000a. ‘‘Rhythm
Quantization for Transcription.’’ Computer Music
Diario 24(2):60–76.
Cemgil, A. T., et al. 2000b. ‘‘On Tempo Tracking: Tem-
pogram Representation and Kalman Filtering.’’ Journal
of New Music Research 29:259–273.
Chafe, C., B. Mont-Reynaud, y yo. Rush. 1982. ‘‘Toward
an Intelligent Editor of Digital Audio: Recognition of
Musical Constructs.’’ Computer Music Journal
6(1):30–41.
Desain, PAG., and H. Honing. 1989. ‘‘The Quantization of
Musical Time: A Connectionist Approach.’’ Computer
Music Journal 13(3):56–66.
Desain, PAG., and H. Honing. 1999. ‘‘Computational Models
42
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
of Beat Induction: The Rule-Based Approach.’’ Journal
of New Music Research 28:29–42.
dixon, S. 2001a. ‘‘Automatic Extraction of Tempo and
Beat from Expressive Performances.’’ Journal of New
Music Research 30:39–58.
dixon, S. 2001b. ‘‘An Empirical Comparison of Tempo
Trackers.’’ Eighth Brazilian Symposium on Computer
Music, n.p., 832–840.
Eck, D. 2001. ‘‘A Positive-Evidence Model for Rhythmi-
cal Beat Induction.’’ Journal of New Music Research
30:187–200.
McAuley, j. 1994. ‘‘Time as Phase: A Dynamic Model of
Time Perception.’’ Proceedings of the Sixteenth An-
nual Meeting of the Cognitive Science Society. Hills-
dale, Nueva Jersey: Erlbaum, páginas. 607–612.
Molinero, B. o., D. l. Scarborough, y j. A. jones. 1992.
‘‘On the Perception of Meter.’’ In M. Balaban,
k. Ebcioglu, and O. Laske, eds. Understanding Music
with AI: Perspectives on Music Cognition. Cambridge,
Massachussetts: AAAI Press, páginas. 428–447.
Palmer, C. 1997. ‘‘Music Performance.’’ Annual Review
of Psychology 48:115–138.
Gabrielsson, A. 1973. ‘‘Studies in Rhythm.’’ Acta Univ-
Palmer, C., y P. q. Pfordresher. 2003. ‘‘Incremental
ersitatis Upsaliensis 7:3–19.
Goto, METRO. 2001. ‘‘An Audio-Based Real-Time Beat Track-
ing System for Music with or without Drum-Sounds.’’
Journal of New Music Research 30:159–171.
Goto, METRO., and Y. Muraoka. 1997. ‘‘Issues in Evaluating
Beat Tracking Systems.’’ IJCAI-97 Workshop in Issues
in AI and Music—Evaluation and Assessment, n.p.,
9-dieciséis.
Heijink, h., et al. 2000. ‘‘Make Me a Match: Una evaluación-
tion of Different Approaches to Score-Performance
Matching.’’ Computer Music Journal 24(1):43–56.
jones, METRO. r., et al. 2002. ‘‘Temporal Aspects of Stimulus-
Driven Attending in Dynamic Arrays.’’ Psychological
Ciencia 13:313–319.
Planning in Sequence Production.’’ Psychological Re-
vista 110:683–712.
Parncutt, R. 1994. ‘‘A Perceptual Model of Pulse Salience
and Metrical Accent in Musical Rhythms.’’ Music Per-
ception 11:409–464.
Povel, D.-J., y P. Essens. 1985. ‘‘Perception of Tempo-
ral Patterns.’’ Music Perception 2:411–440.
Raphael, C. 2001. ‘‘Automated Rhythm Transcription.’’
Proceedings of the 2nd Annual International Sympo-
sium on Music Information Retrieval. Bloomington,
Indiana: Universidad de Indiana, páginas. 99–107.
Rosenthal, D. 1992. ‘‘Emulation of Human Rhythm Per-
ception.’’ Computer Music Journal 16(1):64–76.
Rowe, R. 1993. Interactive Music Systems. Cambridge,
Kostka, S., y D. Payne. 1995. Workbook for Tonal Har-
Massachusetts: CON prensa.
mony. Nueva York: McGraw–Hill.
Large, mi. w., y j. F. Kolen. 1994. ‘‘Resonance and the
Perception of Musical Meter.’’ Connection Science
6:177–208.
Sotavento, C. 1991. ‘‘The Perception of Metrical Structure:
Experimental Evidence and a Model.’’ In P. Howell,
R. Oeste, y yo. Cruz, eds. Representing Musical Struc-
tura. Londres: Prensa académica, páginas. 59–127.
Lerdahl, F., y r. Jackendoff. 1983. A Generative The-
ory of Tonal Music. Cambridge, Massachusetts: CON
Prensa.
Longuet-Higgins, h. C. 1976. ‘‘Perception of Melodies.’’
Naturaleza 263:646–653.
Longuet-Higgins, h. C., and C. S. Sotavento. 1982. ‘‘The Per-
ception of Musical Rhythms.’’ Perception 11:115–128.
Longuet–Higgins, h. C., y M. j. Steedman. 1971. ‘‘On
Interpreting Bach.’’ Machine Intelligence 6:221–41.
Manning, C. D., and H. Schu¨ tze. 2000. Foundations of
Statistical Natural Language Processing. Cambridge,
Massachusetts: CON prensa.
marco, METRO. PAG., B. Santorini, y M. A. Marcinkiewicz.
1993. ‘‘Building a Large Annotated Corpus of English:
The Penn Treebank.’’ Computational Linguistics
19:313–330.
Scheirer, mi. D. 1998. ‘‘Tempo and Beat Analysis of
Acoustic Musical Signals.’’ Journal of the Acoustical
Society of America 103:588–601.
Sethares, W.. A., and T. W.. Staley. 2001. ‘‘Meter and Peri-
odicity in Musical Performance.’’ Journal of New Mu-
sic Research 30:149–158.
Sloboda, j. A. 1983. ‘‘The Communication of Musical
Metre in Piano Performance.’’ Quarterly Journal of
Psicología experimental 35:377–396.
Spiro, norte. 2002. ‘‘Combining Grammar-Based and
Memory-Based Models of Perception of Time Signa-
ture and Phase.’’ In C. Anagnostopoulou, METRO. Ferrand,
y un. Smaill, eds. Music and Artificial Intelligence.
Berlina: Saltador, páginas. 183–194.
Steedman, METRO. 1977. ‘‘The Perception of Musical Rhythm
and Metre.’’ Perception 6:555–569.
Temperley, D. 2001. The Cognition of Basic Musical
Structures. Cambridge, Massachusetts: CON prensa.
Temperley, D., y D. Sleator. 1999. ‘‘Modeling Meter
and Harmony: A Preference-Rule Approach.’’ Com-
puter Music Journal 23(1):10–27.
van Zaanen, METRO., R. Bod, and H. Honing. 2003. ‘‘A
Memory-Based Approach to Meter Induction.’’ Pro-
ceedings of ESCOM 2003, n.p., páginas. 250–253.
Temperley
43
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Apéndice A
All of the materials (data files and programs) de-
scribed here are available at the Melisma Web site,
www.link.cs.cmu.edu/melisma. (Programs are writ-
ten in C and are available in source form.) Estos
include the following:
1. Notefiles for the complete KP Corpus
(notefiles/kp) and KP Performed Corpus
(notefiles/kp-perf). (These files are also
available as MIDI files: midifiles/kp,
midifiles/kp-perf.)
2. The correct note-address files for the KP
Corpus and KP Performed Corpus (nafiles/
kp-correct, nafiles/kp-perf-correct).
3. compare-na: a program that compares two
note-address files and evaluates their simi-
larity.
4. tally-na: a program that takes a series of
outputs of compare-na and averages them.
5. The source code for the Melisma meter-
finding program.
6. gen-add: a program for generating note-
address files from the ‘‘note-beat files’’ (nota-
list plus beatlist) produced by the Melisma
meter program. (This could be useful for
those who wish to experiment with modifi-
cations of the Melisma program. It may also
be useful, perhaps with some alterations, a
those whose models already produce a note-
beat file or something similar to it and who
wish to convert this to note-address format.)
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
/
2
8
3
2
8
1
8
5
4
1
3
7
0
1
4
8
9
2
6
0
4
1
7
9
0
6
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
44
Computer Music Journal