Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
Relation Extraction Based on Prompt Information and Feature Reuse
Ping Feng1,2,3*, Xin Zhang2, Jian Zhao2,3, Yingying Wang2, Biao Huang 2
1 Jilin University, Changchun Jilin 130012, Porcelana
2 Changchun University, Changchun Jilin 130022, Porcelana
3 Jilin Provincial Key Laboratory of Human Health State Identification and Function Enhancement, Changchun Jilin 130022, Porcelana
Citación: feng, P.,Zhang, X., zhao, j. et al.: Relation extraction based on prompt information and feature reuse. Datos
Inteligencia. 5 (2023). DOI: https://doi.org/10.1162/dint_a_00192
Abstracto
To alleviate the problem of under-utilization features of sentence-level relation extraction, cual
leads to insufficient performance of the pre-trained language model and underutilization of the
feature vector, a sentence-level relation extraction method based on adding prompt information and
feature reuse is proposed. At first, in addition to the pair of nominals and sentence information, a
piece of prompt information is added, and the overall feature information consists of sentence
información, entity pair information, and prompt information, and then the features are encoded by
the pre-trained language model ROBERTA. Además, in the pre-trained language model, BIGRU
is also introduced in the composition of the neural network to extract information, and the feature
information is passed through the neural network to form several sets of feature vectors. Después,
these feature vectors are reused in different combinations to form multiple outputs, and the outputs
are aggregated using ensemble-learning soft voting to perform relation classification. Además de
este, the sum of cross-entropy, KL divergence, and negative log-likelihood loss is used as the final
loss function in this paper. In the comparison experiments, the model based on adding prompt
information and feature reuse achieved higher results of the SemEval-2010 task 8 relational
conjunto de datos.
Palabras clave: relation extraction; modelo de lenguaje; prompt information; feature reuse; loss function
1. Introducción
Relation extraction, as a basic information extraction task, aims to identify the relationship between
pairs of nominals in a given sentence from a set of predefined relationships of interest. The work
process can be briefly summarized as follows: the triple r(e1, e2) is extracted from the unstructured text.
Where e1 and e2 are entities in the utterance, generally nouns or phrases formed by nouns, and r
denotes the relationship between entities e1 and e2.
Relation extraction plays a crucial role in natural language processing applications that require a
relational understanding of the unstructured text, such as question answering the application,
recommendation algorithm, semantic search, knowledge base filling, and knowledge graph construction.
Many tasks of natural language processing can benefit from accurate relation classification. Por lo tanto,
relation extraction has attracted a lot of attention. The common approach nowadays is to fine-tune pre-
trained language models such as BERT [1], ROBERTA [2], and GPT [3], etc.. to achieve relation
clasificación. The existing sentence-level relation extraction is also mainly based on the language model
with various innovations. Sin embargo, in the process of fine-tuning the language model to the relation
extraction task, the insufficient feature selection makes the language model too fine-tuned to the
downstream task, thus not giving full play to the performance of the language model; at the same time,
the model does not make sufficient use of the feature vector.
∗ Corresponding author: Ping Feng (Correo electrónico: fengping@ccu.edu.cn; ORCID: 0000-0003-4865-1454)
© 2023 Academia China de Ciencias. Publicado bajo una atribución Creative Commons 4.0 Internacional
(CC POR 4.0) licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
t
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
t
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
Mesa 1: Processing of statements in a dataset
Oración (1)
El
publicación .
Relationship
Entity-Origin (e1, e2)
Modification The $ legend $ was derived from a much older # publicación #. @
what is the relationship between legend and publication in the above
oración? @
Oración (2) Mayoría
Relationship Cause-Effect (e2, e1)
Modification Most $ deaths $ from the accident were caused by radiation #
poisoning #. @ what is the relationship between deaths and
poisoning in the abovesentence? @
Oración (3)
El
Relationship
Entity-Destination (e1, e2)
Modification The $ leftovers $ are pushed into the # colon #. @ what is the
relation-ship between leftovers and colon in the above sentence? @
Para tal fin, this paper proposes a sentence-level relation extraction method based on adding prompt
information and feature reuse. The modification of the sentence is shown in Table 1. This method first
adds a prompt message in addition to the original sentence-level features and entity-pair features: » Qué
is the relationship between entity one (e1) and entity two (e2) in the above sentence? «. Then the
sentence features, entity pair features, and prompt features are all encoded by ROBERTA [2]. El
encoded data is then fed into the model, and in the model composition this paper chooses the ROBERTA
[2] language model as a basis for the overall model, and BIGRU is introduced in the process of model
fine-tuning, from which another feature is constructed. In the hidden layer of the model, five features are
proposed in this paper noted as Featurecls, Featurebigru, Featureentity1 , Featureentity2 , Featureprompt.
Finalmente, feature reuse is performed to form four different outputs, and ensemble-learning soft voting is
used for the output Voting is performed and the voted results are used for predictive relation
clasificación. The main contribution of this method is to add prompt information to the relation
extraction task, which not only solves the problem of insufficient feature information but also allows the
model to give full play to its performance; secondly, feature reuse and ensemble-learning are used to
solve the problem of insufficient utilization of feature vectors and further improve the robustness of
sentence-level relation extraction results; finalmente, in this paper, the same batch of data is fed into the
model twice before and after finally, the same batch of data is fed into the model twice to obtain two
different distributions, and a new loss function consisting of the cross-entropy, KL divergence, y
negative log-likelihood loss of these two distributions is used to optimize the model.
2. Trabajo relacionado
The task of relation classification is a very important part of the knowledge graph construction process.
The methods of relation extraction, in general, include unsupervised relation classification and supervised
relation classification, with supervised relation classification, which is usually considered a multiclassification
problema. The performance of traditional relation classification depends mainly on the quality of features, pero
errors often occur during feature extraction with NLP tools, reducing the overall performance of the model. A
solve this problem of feature extraction errors, Zeng et al. [4], Zheng et al. [5], Zheng et al. [6] successively
proposed the use of convolutional neural networks, recurrent neural networks, and graph neural networks for
relationship extraction. Although these neural networks can encode and convert entity pairs and sentence
information into feature vectors, which provides some improvement in model performance, these approaches
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
t
.
/
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
.
/
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
do not take into account which information in the sentence is more important. Por esta razón, Shen et al. [7],
Zhou et al. [8], Guo et al. [9] proposed models for neural networks with attention mechanisms, which were
added to convolutional neural networks, recurrent neural networks, and graph neural networks, respectivamente, a
further improve the performance of relational extraction models. On top of this, Lee et al. [10] added the
perception of entities to enhance the robustness of the attention mechanism.
After the emergence of language models EMLO [11], BERT [1], GPT [3], etc., language models
were widely used for relation extraction tasks. Alt et al. [12] proposed a new approach based on
Transform [13] architecture for relation extraction, using pre-learned implicit language features
combined with Transform. Wang et al. [14] applied BERT applied to relation extraction and used an
entity-aware self-attention mechanism to inject relation information related to multiple entities in each
layer of the hidden state to achieve the prediction of multiple relations by encoding them once. Wu et al.
[15] similarly proposed a relationship extraction model based on BERT, while encoding the information
of entity pairs into the feature vector as well, thus effectively improving the performance of the model.
Tian et al. [16] employ a graph convolutional neural network based on the attention mechanism on top of
the BERT encoding, which can better parse the information in the dependency tree. Tao et al. [17] extract
syntactic indicators guided by syntactic knowledge and then encode them using language models, cual
mitigates the noise of the data. Han et al. [18] instead propose prompt-based learning that converts the
task of relation classification into a task of completing blanks, using a masking task for predicting
possible relations when the language model is trained.
Since the language model is not so effective in terms of specific domains or specific tasks. Peters et al.
[19] embed the contents of multiple knowledge bases into BERT, and the knowledge-enhanced BERT
also achieves better results in downstream tasks such as relation extraction. Wang et al. [20] configured a
neural adapter for each kind of injected knowledge in order not to let the injected historical knowledge be
washed away, thus allowing the fusion of multiple knowledge bases and making the model have better
resultados.
Recientemente, great progress has also been made in Few-Shot Relation Extraction. Qin y otros. [21] used a
continual few-shot relation learning method based on embedding space regularization and data
augmentation to avoid catastrophic forgetting of previous tasks. Liu et al. [22] proposed a direct addition
method that introduces relational information, generates a relational representation by joining two
relations and then adds it to the model for training and prediction. Chia et al. [23] worked on the task
setting of the zero-shot relation triplet extraction task. Unifying language model prompts and structured
text methods, the relationship samples were generated by conditional processing of relations with
structured prompts templates and decoded according to the triplet search decoding method.
También, ensemble learning is effective in the field of relational extraction, es decir., the performance of
relational extraction models can be improved by ensemble learning. Han et al. [24] used multiple semi-
supervised learning methods to form a new semi-supervised learning method based on ensemble
aprendiendo, which is well applied to relational classification. Kim et al. [25] used four classifiers, CRF,
CRFext, SEARN, and Bi-LSTM, for relational classification, and finally learned the four models together
in an ensemble-learning manner, which also achieved better results. Yang y otros. [26] constructed a more
efficient and robust relationship extractor based on a joint integrated neural network through the
proposed adaptively enhanced multiple LSTM networks attention. Christopoulou et al. [27] usado
BiLSTM-CRF and feature-based CRF models as sub-models thus building ensemble-learning algorithms
and using the integrated algorithms for extracting relationships between drugs and achieving better
resultados. Rim et al. [28] propose a method to combine predictions from CNN and RNN into an integrated
model to perform relational classification and extraction simultaneously, as well as a choice of weighted
cross-entropy as the objective function and an up-sampling strategy to mitigate the negative effects of
category imbalance.
Although the current sentence-level relation extraction methods have achieved great success, hay
still much room for improvement: the feature information extraction for sentences is not sufficient,
making the language model overly fine-tuned to downstream tasks, resulting in the language model not
fully exploiting its performance; the utilization of feature vectors is not sufficient; the choice of loss
functions is too obsolete.
Por lo tanto, inadequate extraction of information about sentence features means that there is no
information other than entity pair information as well as sentence information. If additional information
4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
t
.
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
could be added to identify the features of the relation extraction task so that more information would be
encoded and injected into the model. It would also allow the language model to have more understanding
of the relation extraction task, which may enable the language model to perform to its full potential.
Segundo, underutilization of feature vectors refers to the fact that the feature vectors are used only once
during the propagation of the neural network, Por ejemplo, the R-BERT method proposed by Wu et al.
[15] utilizes the sentence and entity pair information only once. If the feature vector can be used more
veces, it may have a better improvement on the relation extraction results. To overcome the above
problemas, this paper proposes a sentence-level relation extraction method based on adding prompt
information and feature reuse.
3. A Relation Extraction Model Based on Prompt Information and Feature Reuse
The model is presented in three main areas: the encoding layer, the model details, and the model
optimization. In the encoding layer, the details of how the logarithmic data is modified and the features
of the encoded matrix-vector are presented. In terms of model details, this paper subdivides the model
into three parts: input layer, feature acquisition layer, and feature reuse layer, as shown in Figure 1.
Finalmente, for the optimization part of the model, this paper presents the way the loss function used is
composed.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
t
/
.
/
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
.
/
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. Overall model diagram, overall divided into three parts (a) Input Layer, (b) Característica
Acquisition Layer, (C) Feature Reuse Layer
3.1. Encoding Layer
For all the data in the dataset first perform a replacement operation, replacing «
dataset with the special tokens » $ «, «< e2>«, «» is replaced by the special tokens «#», and finally at the end of the sentence add a prompt message » What is the relationship between entity one (e1) and entity two (e2) in the above sentence? «, and add the special tokens «@» before and after the prompt message. Por ejemplo, a statement in the dataset » El
What is the relationship between legend and publication in the above sentence? @ » as input.
en este documento, we use the pre-trained Roberta mode to encode the input sentences. For the input
format specific to the Roberta model, we need to add «[CLS]» y «[SEP]» before and after the sentence
to indicate the beginning and end of the sentence respectively. For the proposed model in this paper, five
vector matrices are designed as inputs to the model. For modified statements S after Roberta encoding,
all statements are set to a maximum length L, and statements of insufficient length are made up with
zeros. The sentence S can then be represented as a set of word vectors inputids noted as 𝐼𝑖 =
𝑖 }. To perform the self-attention operation on the specified words, Roberta follows the
{𝑥1
𝑖 , … , 𝑥𝐿
𝑖 , 𝑥2
5
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
matrix-vector attentionmask proposed in Bert notated as 𝑀𝑎 = {𝑥1
𝑎}. The matrix-vector 𝑀𝑎 in
which all positions are one, except for the complementary zero position, which is zero. The vector
matrices of entity one, entity two, and prompt message are denoted as 𝑀𝑒1 = {𝑥1
𝑒1}, 𝑀𝑒2 =
𝑝}, the vector matrices 𝑀𝑒1 , 𝑀𝑒2 , 𝑀𝑝 have zero values at all
{𝑥1
positions except for the position identified by the special symbol, which is one. That is the vector
matrices for each of the five inputs are 𝐼𝑖, 𝑀𝑎, 𝑀𝑒1, 𝑀𝑒2, 𝑀𝑝.
𝑒2}, 𝑀𝑝 = {𝑥1
𝑝, … , 𝑥𝐿
𝑒2, … , 𝑥𝐿
𝑒1, … , 𝑥𝐿
𝑎, … , 𝑥𝐿
𝑒2, 𝑥2
𝑒1, 𝑥2
𝑝, 𝑥2
𝑎, 𝑥2
3.2. Model Details
This section will be divided into three parts to introduce the detailed parts of the model. The three
sections are Input Layer, Feature Acquisition Layer, and Feature Reuse Layer, which describe the model
in detail in terms of input, feature acquisition, and model type optimization. The specific details are
como se muestra en la figura 1.
3.2.1. Input Layer
In the input layer of the model, the matrix-vector 𝐼𝑖 and the matrix-vector 𝑀𝑎 are first fed into the pre-
trained Roberta mode, which outputs a hidden layer H. Then the matrix-vector 𝑀𝑒1, the matrix-vector
𝑀𝑒2, and the matrix-vector 𝑀𝑝 are input into the model to be multiplied by the hidden layer H. De
este, information can be extracted about the entity pair with the whole sentence and the prompt part with
the whole sentence.
3.2.2. Feature Acquisition Layer
The hidden layer H is used as the output of Roberta, and the feature vector 𝐻0 contains the information
of the whole sentence. Denote 𝐻1 as the feature vector of sentence information 𝐹𝑐 = {𝑦1
𝑐 }, el
𝐿𝐻 represents the length of the output of the hidden layer H. Then put the feature vector 𝐻0 as the input
of BIGRU, so that the information of the whole sentence can be extracted by BIGRU again, de este modo
strengthening the features of the input. For each element in the BIGRU input sequence, the following
function is computed for each layer:
𝑐, … , 𝑦𝐿𝐻
𝑐, 𝑦2
𝑟𝑡 = 𝜎(𝑊𝑟[ℎ𝑡−1, 𝐻0]) (1)
𝑧𝑡 = 𝜎(𝑊𝑧[ℎ𝑡−1, 𝐻0]) (2)
′ = tanh(𝑊ℎ′[𝑟𝑡 ⊙ ℎ𝑡−1, 𝐻0) (3)
ℎ𝑡
′ (4)
ℎ𝑡 = 𝑧𝑡 ⊙ ℎ𝑡 + (1 − 𝑧𝑡) ⊙ ℎ𝑡
where σ is the sigmoid activation function, ⊙ is the product of terms, 𝑊𝑟 , 𝑊𝑧 , and 𝑊ℎ′ are the
parameters of the GRU network. The ℎ𝑡 is considered as the output of BIGRU, and ℎ𝑡 is denoted as the
feature vector 𝐹𝑏 = {𝑦1
𝑏 } extracted by BIGRU.
𝑏, 𝑦2
𝑏, … , 𝑦𝐿𝐻
Algoritmo 1: Figure out the average vector.
Input: Roberta’s hidden layer vector, 𝐻0, masked vector Mask-Tensor, 𝑀𝑛;
Output: The average of the masked vector, Avgn;
1: function AVG (𝐻0, 𝑀𝑛)
2: Add one dimension to the middle of a two dimensional vector 𝑀𝑛 to make
a three di-mensional vector;
3: Figure out the length L of the nonzero number in vector 𝑀𝑛;
4: Sum the matrix vector 𝑀𝑛 and the matrix vector 𝐻0, Sum;
5: 𝐴𝑣𝑔𝑛 = Sum / l;
6: return 𝐴𝑣𝑔𝑛 ;
7: end function
As shown in Algorithm 1, take the matrix-vector 𝑀𝑒1 , the matrix-vector 𝑀𝑒2 , matrix-vector 𝑀𝑝
respectivamente, and 𝐻0 multiplying by each other, assuming that 𝐻0 the vectors are represented as {β1,…,
β 𝐿𝐻} with the following equation.
6
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
t
.
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
𝐿𝐻
𝑀𝑠𝑢𝑚 = ∑
𝑖=1
𝑥𝑖β𝑖 = 𝑥1β1
𝑇 + 𝑥2β2 + ⋯ + 𝑥𝐿𝐻β𝐿𝐻 (5)
Taking the calculated matrix-vector 𝑀𝑠𝑢𝑚 and dividing it by the length of the masked part of each
𝑒1 },
𝑝 }. That is, five eigenvectors are obtained in the feature
matrix-vector to obtain the final average vector, the resulting result is denoted as 𝐹𝑒1 = {𝑦1
𝐹𝑒2 = {𝑦1
acquisition layer 𝐹𝑐, 𝐹𝑏, 𝐹𝑒1, 𝐹𝑒2, 𝐹𝑝 as the input to the next step.
𝑒2}, 𝐹𝑝 = {𝑦1
𝑝, … , 𝑦𝐿𝐻
𝑒2, … , 𝑦𝐿𝐻
𝑒1, … , 𝑦𝐿𝐻
𝑒2, 𝑦2
𝑒1, 𝑦2
𝑝, 𝑦2
3.2.3. Feature Reuse Layer
Algoritmo 2: Figure out the hidden layer output.
Input: Feature𝑐, Feature𝑏, Feature𝑒1, Feature𝑒2, Feature𝑝 as a characteristic innput, Características;
Output: Output containing all characteristics, Out;
1: function Figure-Out (Característica)
2: Create an output array Out𝑖
3: for choose Feature𝑖 in Features do
4: Featurei = LayerNorm (Feature𝑖);
5: Featurei = Dropout (Feature𝑖);
6: Featurei = Tanh (Feature𝑖);
7: Featurei = Linear (Feature𝑖);
8: end for
9: Add multiple Featurei to the array Out𝑖;
10: Normalize list Out𝑖 to form the final output, Out;
11: return Out;
12: end function
Five features 𝐹𝑐 , 𝐹𝑏 , 𝐹𝑒1 , 𝐹𝑒2 , 𝐹𝑝 are taken as input in the feature reuse layer. As shown in
Algoritmo 2. The features are processed using Algorithm 2, first by regularizing the input feature vectors;
Entonces, in order not to overfit the model, it goes through the dropout layer, dropping some random
neuronas. Finalmente, after passing the function Tanh, the linear model is used to make the reduced
dimensional output. The output obtained from each feature is then stitched together to obtain O1. Putting
𝐹𝑐 and 𝐹𝑏 then go through the same operation separately, and the output from the linear layer to get O2
and O3. Finalmente, put 𝐹𝑒1, 𝐹𝑒2, 𝐹𝑝 are also passed through Algorithm 2 to obtain O4. Where the specific
linear operation formula is as follows:
𝑂𝑖 = 𝑤𝑖 tanh(𝐹𝑖) + 𝑏𝑖 (6)
The obtained outputs O1, O2, O3 and O4 are then passed through SoftMax to obtain 𝑂1
′ , 𝑂2
′ , 𝑂3
′ and
′ the specific formula is as follows:
𝑂4
𝑒ℎ(𝑥,𝑦𝑖)
𝑛
𝑗=1
𝑒ℎ(𝑥,𝑦𝑖)
Finalmente, using the idea of ensemble-learning soft voting, the probabilities of each classification
∑
𝑃(𝑦|𝑥) =
(7)
outcome in each output are summed and averaged to find the final relation classification output.
′ + 𝑂2
output = 1
′ ) (8)
′ + 𝑂3
′ + 𝑂4
4⁄ (𝑂1
3.3. Model Optimization
Since deep neural networks are prone to overfitting, regularization methods such as dropout are
usually used to reduce the generalization error of the model during the training process. The dropout
removes a random portion of units in each layer of the neural network to avoid overfitting the model. Es
due to the randomness of dropout that Liang et al. [29] proposed a dropout-based loss function.
7
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
t
/
/
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
t
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
Cifra 2: Dropout specific process
en este documento, we add cross-entropy to the loss function based on the above approach. The final loss
function consists of cross-entropy, KL divergence, and negative log-likelihood loss. Primero, let each batch
of data pass through the forward neural network twice, before and after, and two different distributions
can be obtained from Figure 2, respectively P1 and P2. Due to the randomness of dropout, the forward
pass is also slightly different in spite of passing the same model twice. P1 left path is dropped with the
output distribution and P2 right path is dropped with the output distribution is not the same. For this
𝑖
como
purpose the KL divergence is used to describe the difference between two distributions noted as 𝐿𝑘𝑙
follows:
𝑖 =
𝐿𝑘𝑙
1
2
(𝐷𝑘𝑙(𝑃1
𝑖
𝑖(𝑦𝑖|𝑥𝑖)||𝑃2
𝑖(𝑦𝑖|𝑥𝑖)||𝑃1
𝑖(𝑦𝑖|𝑥𝑖)) + 𝐷𝑘𝑙(𝑃2
and the negative log-likelihood loss 𝐿𝑁𝐿𝑙
𝑖
𝑖(𝑦𝑖|𝑥𝑖))) (9)
are used to find a difference
Then the cross-entropy 𝐿𝐶𝐸
value of the two results respectively.
𝑖 = −𝑃1
𝐿𝐶𝐸
𝑖 = −𝑙𝑜𝑔𝑃1
𝐿𝑁𝐿𝑙
𝑖
𝑖
, 𝐿𝐶𝐸
Finalmente, the losses 𝐿𝑘𝑙
𝑖
= (1 − 𝛼)(𝐿𝐶𝐸
𝐿𝑙𝑜𝑠𝑠
4. Experiments and Analysis
𝑖(𝑦𝑖|𝑥𝑖)𝑙𝑜𝑔𝑃1
𝑖(𝑦𝑖|𝑥𝑖) − 𝑃2
𝑖(𝑦𝑖|𝑥𝑖)𝑙𝑜𝑔𝑃2
𝑖(𝑦𝑖|𝑥𝑖) (10)
𝑖(𝑦𝑖|𝑥𝑖) (11)
are summed to obtain a final loss function 𝐿𝑙𝑜𝑠𝑠
𝑖
(12)
𝑖
) + 𝛼𝐿𝑘𝑙
.
𝑖 + 𝐿𝑁𝐿𝐿
𝑖
𝑖(𝑦𝑖|𝑥𝑖) − 𝑙𝑜𝑔𝑃2
, and 𝐿𝑁𝐿𝑙
𝑖
The experiments attempt to demonstrate the enhancement of prompt information, feature reuse, y
loss functions on the performance of the model, thus further enhancing the effectiveness of existing
relation classification methods. The dataset is first presented, then the model in this paper is compared
with existing methods, and finally, the impact of each part of the model on the model results is explored.
4.1. Dataset
For the data part, the dataset used in this paper is the SemEval-2010 task 8 relational dataset. El
dataset contains 10717 muestras, 8000 samples for training, y 2717 samples for testing. The dataset
contiene 9 semantic relationship types and 1 other relationship type Other, the relationships are ordered.
The directionality of the relations effectively doubles the number of relations, since entity pairs are
considered to be correctly labeled only if the order is also correct. Cause-Effect (e1, e2) is different from
Cause-Effect (e2, e1). So ultimately 19 relationships exist, for the relationships contained in the dataset
and the number of individual relationships as shown specifically in Table 2.
Mesa 2: Specific Number Of Data Types In The Dataset
Relation
Cause-Effect
Instrument-Agency
Tren
1003
504
8
Prueba
328
156
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
t
/
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
/
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
Product-Producer
Content-Container
Entity-Origin
Entity-Destination
Component-Whole
Member-Collection
Message-Topic
Otro
Totle
717
540
716
845
941
690
634
1410
8000
231
192
258
292
312
233
261
454
2717
4.2. Parameter Setting
en este documento, we use the grid search algorithm to adjust the optimal parameters, the maximum
sentence length L ∈ {120, 150, 200, 250, 300}, the size of each batch of data BATCH-SIZE ∈ {4, 8,
16}, the total number of training EPOCHS ∈ {8, 10, 12, 14, 16}, the neural network dropout
DROPOUT-RATE ∈ {0.1, 0.2, 0.3, 0.4, 0.5}, the LEARNING-RATE ∈ {1e-5, 2e-5, 3e-5, 4e-5, 5e-6},
loss function KL scatter percentage ratio KL-RATE ∈ {0.4, 0.5, 0.6, 0.7, 0.8}, hidden layer length H-L
∈ {100, 150, 200, 250, 300}. The optimal configuration of parameters is obtained as L=150, BATCH-
SIZE=10, EPOCHS=12, DROPOUT-RATE=0.1, LEARNING-RATE= 1e-5, KL-RATE=0.7, H-L=200.
4.3. Comparison of Different Methods
Mesa 3: Different models for relation extraction
Modelo
TRE
Entity-Aware BERT
R-BERT
PTR
Skeleton-Aware BERT
RPR
F1-score
87.1
89.0
89.25
89.9
90.36
90.70
The proposed model, denoted as RPR, is compared with the previous methods TRE [12], Entity-
Aware BERT [14], R-BERT [15], PTR [18], and Skeleton-Aware BERT [17]. The specific results are
mostrado en la tabla 3.
(1) Comparison with TRE [12] método. The TRE approach learns implicit linguistic features from a
plain text corpus and combines them in a self-attention Transformer architecture. It does not
take into account information other than entity pairs and sentence-level information. Whereas,
the RPR method adds prompt information to be able to better extract features about the relation
extraction task.
(2) Comparison with Entity-Aware BERT [14] comparison of the methods. The Entity-Aware BERT
method can accomplish the multi-entity relation extraction task by encoding only once.
Sin embargo, it does not take into account the utilization of feature information. The RPR method,
por otro lado, reuses entity pairs as well as sentence-level information multiple times,
effectively alleviating the problem of the underutilization of feature vectors.
(3) Comparison with R-BERT [15] método. The R-BERT method uses a pre-trained BERT language
model and merges information from the target to handle the relation classification task. But it
9
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
t
.
/
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
/
.
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
does not sufficiently extract information from the target. The RPR approach, with the addition of
a prompt to emphasize the target information, allows the language model to be fully understood.
(4) Comparison with PTR [18] comparison of the methods. The PTR approach proposes prompt-
based learning by adding a piece of information other than entity pairs, nivel de oración
información, and applying the mask training task of the language model to predict the
clasificación, but it does not take into account that the predicted categories are too exotic, cual
leads to unsatisfactory results. The RPR method, with the addition of information, still follows
the idea of the classification task and is able to better infer the classification and achieve better
resultados.
(5) Comparison with Skeleton-Aware BERT [17] comparison of methods. The Skeleton-Aware
BERT method extracts syntactic indicators guided by syntactic knowledge and merges syntactic
indicators and whole sentences into a better relational representation. But it does not take into
account the performance of the language model and the degree of feature utilization. The RPR
method uses a better ROBERTA language model, as well as feature reuse of the components of
each part of the model, which improves the accuracy and F1-score values.
4.4. Effect of Model Components on the Model
This paper has demonstrated strong empirical results based on the proposed method, and to further
understand the specific contribution of each component of the proposed method, the following control
group experiment was set up for this purpose. For the pre-trained language models, BERT and
ROBERTA were used as the base models to set up control trials, respectivamente. Two types of inputs are
used in this paper, one using the original input to mark special symbols for only two entities in the
oración, and the other input using a prompt-based input, a prompt message is added at the end of the
oración. For the specific models, three groups are also used, the first group is based on the pre-trained
language model for classification, the second group adds BILSTM on top of the pre-trained language
modelo, and the third group adds BIGRU on top of the pre-trained language model. For the loss functions,
two groups are used in this paper, one just using the cross-entropy loss function and the other using the
loss function proposed in this paper. All experiments were performed using grid tuning reference to
obtain the final results under the optimal parameters.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
t
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
.
/
t
i
Cifra 3: Results of the specific effects of each component of the model on the model
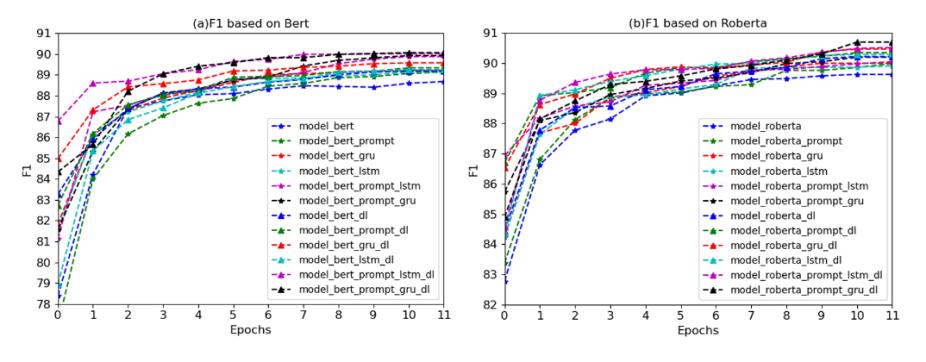
In Figure 3 (a), (b)it can be seen that the overall model reaches its maximum value with about 10
Epochs of fine-tuning and stabilizing. It can also be seen that the model model-roberta-prompt-gru
achieves the maximum value of all models. And the overall performance of the model is also improved
after using the improved loss function in this paper compared with the previous model using only the
cross-entropy loss function.
Mesa 4: Experimental comparison based on the BERT
Modelo
F1-score
Modelo
F1-score
10
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
bert
bert-prompt
bert-bilstm
bert-bigru
bert-bilstm-prompt
bert-bigru-prompt
88.68
89.14
89.22
89.14
89.88
89.93
bert-dl
bert-prompt-dl
bert-bilstm-dl
bert-bigru-dl
bert-bilstm-prompt-dl
bert-bigru-prompt-dl
89.19
89.34
89.26
89.58
90.02
90.07
Mesa 5: Experimental comparison based on the ROBERTA
Modelo
roberta
roberta-prompt
roberta-bilstm
roberta-bigru
roberta-bilstm-prompt
roberta-bigru-prompt
F1-score
89.63
89.99
90.00
89.91
90.05
90.20
Modelo
roberta-dl
roberta-prompt-dl
roberta-bilstm-dl
roberta-bigru-dl
roberta-bilstm-prompt-dl
roberta-bigru-prompt-dl
F1-score
90.22
90.35
90.30
90.47
90.52
90.70
From Table 4, and Table 5, it can be seen that a large number of experiments were done in this paper
to verify the conclusions. Where dl represents the loss function used in this paper indicates. The overall
performance of the Roberta model is better than that of Bert, and the effectiveness of the loss function
proposed in this paper can also be seen in the table. And also the maximum value of 90.70 is obtained in
Roberta-bigru-prompt-dl.
5. Conclusion and Future Work
en este documento, an approach to sentence-level relation extraction based on adding prompt information
and feature reuse is proposed. By adding a prompt message, the sentence is made more informative and
allows the pre-trained ROBERTA mode to better understand the relation extraction task. Sobre esta base,
certain feature information is also reused in the model to constitute multiple output results, and the idea
of integrated learning is used to soft-vote the output results, which enhances the robustness of the
experimental results. Finalmente, the model is optimized by using cross-entropy, KL divergence, and the sum
of negative log-likelihood losses as loss functions, and better results are achieved on the SemEval-2010
tarea 8 relational dataset. This also enables more accurate identification of the relationships between
entities in the knowledge graph building blocks in various fields such as medicine, movie, and music, y
provides a reliable guarantee for the accuracy of the knowledge graph construction. The direction of
future work is to be able to introduce graph neural networks while employing prompt information and
feature reuse, which can better capture the information of sentence and entity pairs.
Contribuciones de autor
Xin Zhang was responsible for experimental idea construction, method design, data analysis and
thesis writing. Ping Feng was responsible for the thesis review and revision, experimental investigation,
and experimental supervision. Yingying Wang, Jian Zhao and Biao Huang are responsible for project
management and experimental hardware preparation.
Agradecimientos
This work is supported by the project of the Ministry of Education (research on the construction and
application of quantum encryption cloud service system based on big data analysis of web content
(2019JB328L06)) and the scientific research planning project of the Jilin Provincial Education Department
(construction and application of medical knowledge graph for chronic diseases of the elderly
(JJKH20210614KJ)).
Referencias
[1] Devlin, J., et al.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT (1): 4171-
4186 (2019)q
1
11
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
t
/
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
.
/
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
[2] Liu, y., et al.: RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019)
[3] Radford, A., et al.: Improving language understanding by generative pre-training. OpenAI (2018)
[4] Zeng, D., et al.: Relation Classification via Convolutional Deep Neural Network. COLECCIONAR: 2335-2344 (2014)
[5] zhang, S., et al.: Bidirectional Long Short-Term Memory Networks for Relation Classification. PACLIC (2015)
[6] zhang, y., chi, PAG., Manning, C.D.: Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. EMNLP:
2205-2215 (2018)
[7] shen, y., Huang, X.J.: Attention-Based Convolutional Neural Network for Semantic Relation Extraction. COLECCIONAR: 2526-2536
(2016)
[8] zhou, PAG., et al.: Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. LCA (2) (2016)
[9] guo, Z., zhang, y., Lu, w.: Attention Guided Graph Convolutional Networks for Relation Extraction. LCA (1): 241-251 (2019)
[10] Sotavento, J., SEO, S., Choi, Y.S.: Semantic Relation Classification via Bidirectional LSTM Networks with Entity-Aware Attention
Using Latent Entity Typing. Symmetry 11(6): 785 (2019)
[11] Peters, M.E., et al.: Deep Contextualized Word Representations. NAACL-HLT: 2227-2237 (2018)
[12] Alt, C., Hübner, METRO., Hennig, l.: Improving Relation Extraction by Pre-trained Language Representations. AKBC (2019)
[13] Vaswani, A., et al.: Attention is All you Need. NIPS: 5998-6008 (2017)
[14] Wang, h., et al.: Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers. LCA (1): 1371-1377 (2019)
[15] Wu, S., Él, y.: Enriching Pre-trained Language Model with Entity Information for Relation Classification. CIKM: 2361-
2364(2019)
[16] tian, y., et al.: Dependency-driven Relation Extraction with Attentive Graph Convolutional Networks. ACL/IJCNLP (1): 4458-
4471 (2021)
[17] tao, P., et al.: Enhancing Relation Extraction Using Syntactic Indicators and Sentential Contexts. ICTAI: 1574-1580 (2019)
[18] Han, X., et al.: PTR: Prompt Tuning with Rules for Text Classification. AI Open 3: 182-192 (2022)
[19] Peters, M.E., et al.: Knowledge Enhanced Contextual Word Representations. EMNLP/IJCNLP (1): 43-54 (2019)
[20] Wang, r., et al.: K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters. ACL/IJCNLP (Findings): 1405-1418
(2021)
[21] Qin, C., Joty, S.: Continual Few-shot Relation Learning via Embedding Space Regularization and Data Augmentation. LCA (1):
2776-2789 (2022)
[22] Liu, y., et al.: A Simple yet Effective Relation Information Guided Approach for Few-Shot Relation Extraction. LCA
(Findings): 757-763 (2022)
[23] Chia, Y.K., et al.: RelationPrompt: Leveraging Prompts to Generate Synthetic Data for Zero-Shot Relation Triplet Extraction.
LCA (Findings): 45-57 (2022)
[24] Han, Z., Yin, S.: Research on semi-supervised classification with an ensemble strategy. ICSMA: 681-684 (2016)
[25] kim, y., Meystre, SM: Ensemble method-based extraction of medication and related information from clinical texts. j. Am.
Medical Informatics Assoc. 27(1): 31-38 (2020)
[26] Cual, D., Wang, S., li, Z.: Ensemble Neural Relation Extraction with Adaptive Boosting. IJCAI: 4532-4538 (2018)
[27] Christopoulou, F. et al.: Adverse drug events and medication relation extraction in electronic health records with ensemble deep
learning methods. j. Am. Medical Informatics Assoc. 27(1): 39-46 (2020)
[28] Rim, k. et al.: Reproducing Neural Ensemble Classifier for Semantic Relation Extraction inScientific Papers. LREC: 5569-5578
(2020)
[29] Liang, X., et al.: R-Drop: Regularized Dropout for Neural Networks. NeurIPS: 10890-10905 (2021)
Biografía del autor
Ping Feng is an associate professor and master supervisor at Changchun University.She is
currently pursuing her PhD at the College of Computer Science and Technology, Jilin
Universidad. Her current research interests include knowledge graph embedding and
knowledge acquisition.
ORCID: 0000-0003-4865-1454
Xin Zhang is a graduate student in the College of Cyber Security, Changchun University.
His current research interests include knowledge graphs, relation extraction, and link
predicción.
ORCID: 0000-0002-7055-3650
Jian Zhao is a professor and master supervisor advisor at Changchun University. Su
current research interest is in cyber security.
ORCID: 0000-0003-3265-6461
12
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
t
.
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
.
/
t
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Inteligencia de datos recién aceptada MS.
https://doi.org/10.1162/dint_a_00192
Yingying Wang is a graduate student in the College of Cyber Security, Changchun
Universidad. Her current research interests include Knowledge graph, aprendizaje automático,
cybersecurity.
ORCID: 0000-0002-7150-1908
Biao Huang is a graduate student in the College of Cyber Security, Changchun
Universidad. His current research interests include image captioning, aprendizaje automático, y
cybersecunty.
ORCID:0000-0002-2957-904X
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
d
norte
/
i
t
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
t
/
/
.
1
0
1
1
6
2
d
norte
_
a
_
0
0
1
9
2
2
0
7
2
3
8
3
d
norte
_
a
_
0
0
1
9
2
pag
d
/
t
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
13