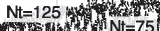Paul Vogt*,**
Tilburg University
Evert Haasdijk†
Vrije Universiteit Amsterdam
Palabras clave
Social learning, language games, idioma
evolution, agent-based modeling,
population-based adaptive systems
Modeling Social Learning of
Language and Skills
Abstract We present a model of social learning of both language
and skills, while assuming—insofar as possible—strict autonomy,
virtual embodiment, and situatedness. This model is built by integrating
various previous models of language development and social learning,
and it is this integration that, under the mentioned assumptions,
provides novel challenges. The aim of the article is to investigate what
sociocognitive mechanisms agents should have in order to be able to
transmit language from one generation to the next so that it can be
used as a medium to transmit internalized rules that represent skill
conocimiento. We have performed experiments where this knowledge
solves the familiar poisonous-food problem. Simulations reveal under
what conditions, regarding population structure, agents can successfully
solve this problem. In addition to issues relating to perspective taking
and mutual exclusivity, we show that agents need to coordinate
interactions so that they can establish joint attention in order to form
a scaffold for language learning, which in turn forms a scaffold for
the learning of rule-based skills. Based on these findings, Concluimos
by hypothesizing that social learning at one level forms a scaffold for
the social learning at another, higher level, thus contributing to the
accumulation of cultural knowledge.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
1 Introducción
In the past decade, a lot of effort has been put into computational studies regarding the social learning
of behaviors [1, 33, 41]. Simultáneamente, many computational studies have investigated how languages
can evolve in populations of autonomous agents (ver, p.ej., [11, 28, 59] for overviews). Drawing on such
previous efforts, we present a model in which both skills and languages are transmitted from one gen-
eration to another by means of social learning.
Artificial models that implement the social learning of skills have been developed to allow individual
agents to “blindly” copy the overt behavior displayed by other agents (possibly humans) by associating
sensory information with motor actions (p.ej., [35, 36]), often by having students receive the same sen-
sory information as the teachers (p.ej., [2, 24, 41]). Some other models work by trying to emulate the
means-ends relations of observed behaviors and copying these [34]. Both types of social learning have
been found among nonhuman primates (p.ej., [55]) and other animal species (p.ej., [19, 25]), así como
* Contact author.
** Tilburg Centre for Cognition and Communication, Tilburg University, PO Box 90153, 5000 LE Tilburg, Los países bajos.
Correo electrónico: p.a.vogt@uvt.nl
† Department of Computer Science, Vrije Universiteit Amsterdam, De Boelelaan 1081a, 1081 HV Amsterdam, Los países bajos.
Correo electrónico: e.haasdijk@few.vu.nl
© 2010 Instituto de Tecnología de Massachusetts
Artificial Life 16: 289–309 (2010)
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
among human subjects (p.ej., [21, 26]). Humanos, sin embargo, also have the ability of learning through what
Gergely and Csibra [20] have called pedagogy learning, in which opaque, or covert, conocimiento (p.ej., mental
representations of how to achieve some goal) is communicated via some medium, such as language.
Although agent-based models provide an ideal tool for investigating the social learning of mental
representaciones [15], relatively few such models have been developed so far (in most models, only visible
behavior is copied or emulated). In some models the weights of neural networks or other internal
knowledge are exchanged; ver, Por ejemplo, [3, 23]. Además, there are a number of approaches in
distributed AI that resemble social learning, such as rule sharing in ensembles of learning classifier systems
[8]. Sin embargo, all these approaches are highly unrealistic from a biological point of view, because the
internal representations are shared explicitly among the interacting agents. Claramente, biological systems
do not explicitly share internal representations; these are communicated through other media, semejante
as chemicals, physical postures, gestures, or language.
Similar approaches to social learning have been taken within the ALife community regarding simu-
lating language evolution. Most models that simulate language evolution include individual agents who
learn from other agents aspects of language, such as phonemic systems [16, 39], vocabularies [38, 47],
syntax [5, 27], or grammar [49, 58]. Approaches to learning have included imitation [16], and copying
comportamiento [38], as well as using socially provided corrective feedback [51]. Most approaches to develop-
ing shared vocabularies or syntax have allowed agents to exchange not only the public signals, pero también
the private mental representations (the meanings). As mentioned, such explicit meaning transfer is
highly unrealistic from a biological point of view, but in addition, using such methods can affect the
results substantially [58, 62].
Alternative approaches have assumed that individual agents were autonomous, embodied, and situ-
ated, and that they could not explicitly transfer internal representations, so that the language needed to
be grounded in the environment, both physically and socially [64]. Grounded models come in two vari-
ants: those implemented on real physical robots and those using simulated robots. Those implemented
on physical robots face many of the same consequences of embodiment and situatedness that humans do
and thus form ideal platforms to verify models of human cognition [59]. Sin embargo, scalability in popula-
tion sizes and the long duration of experiments makes the use of physical robots very expensive and hard
to achieve.
To overcome these problems of time and scalability, many grounded models have been developed
and tested in simulations [6, 10, 44, 60]. The advantage of such models is that they are relatively straight-
forward to scale in population size, though still limited by the computational power required [60]. El
downside of most simulations is that the environment is typically very simplistic, having relatively few
types of objects described in terms of very few relevant features. Por ejemplo, the studies carried out
with the Talking Heads simulation toolkit have used only four features: three RGB channels and one
shape feature [60, 61].
Another aspect that is often absent in language evolution models is the functionality of language in
relation to some life task for agents, which is required for language to become really meaningful to an
agent [66]. Por ejemplo, language can have the function of assisting reproduction and mate choice [65],
coordinating some survival task [32], or sharing knowledge about edible and inedible foods [9, 10].
Studies that have involved some functionality of language, sin embargo, typically have used evolutionary
algorithms for the communication systems to emerge and have tended to ignore lifetime social learning.
The model we present in this article integrates a lot of previous work on modeling language evolu-
tion and social learning in a simulation in which the population needs to distinguish poisonous food
from edible food as a survival task [37, 54]. The objective is not to present novel learning techniques or
to study real behavior, nor to exceed already explored boundaries of (Por ejemplo) population size or
language complexity. En cambio, the innovation here is the integration of various techniques into a model
that comes closer to the real world than most previous models in autonomy, virtual embodiment, situ-
atedness, population size, language functionality, skill learning, and social interactions. Claramente, there have
been studies in which the scales of these factors have exceeded ours, but not in a combined fashion.
The model has been developed in a framework to study the emergence of humanlike cultural societies.
We have therefore based our development—as much as possible—on sociocognitive theories.
290
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
The primary purpose of this article is to investigate what sociocognitive mechanisms our proto-
human agents require in order to distribute both language and skills over generations in simulations
that assume—insofar as is possible—strict autonomy, embodiment, and situatedness. The article will
focus less on the mechanisms for learning skills than on those required for transmitting language.
The model integrates our earlier model of social learning of skills [23] (explained in Section 2.1) con
an improved version of the language-game model presented in [64] (mira la sección 2.2). En la sección 3 nosotros
show how the resulting model can lead to the effective sharing of survival skills among a population of
knowers (es decir., agents who already have the skills) y estudiantes (es decir., those who have yet to acquire the
habilidades). Secciones 4 y 5 discuss and conclude the article.
2 The Model
The model was developed as part of the NEW TIES project,1 which aimed to develop a simulation
platform in which a cultural society could evolve through evolution, individual learning, and social learn-
En g [17, 22]. In the research presented here, we used the platform to set up a 2D grid-world environment
containing both edible and inedible plants. When agents eat the edible plants, they gain a fixed amount
of energy, and when they eat the inedible plants, they lose a fixed amount of energy.
Agents have a visual system with which they can detect their immediate surroundings with a total
visual angle of 90° (45° left and 45° right) and a visual reach of 10 cells. Agents receive visual stimuli
regarding the objects in their visual field and output actions that move them around, pick up or put down
objects, eat, and communicate or interact otherwise with others (p.ej., giving or taking objects to/from
other agents). Obviamente, agents cannot look through objects. Actions of agents are decided upon by
their individual controllers, which are implemented as decision Q-trees (DQTs). These trees can adapt
through evolution, individual learning, and/or social learning, but for the purpose of the current study,
they only adapt through social learning.
A DQT is a decision tree that contains test nodes, bias nodes, and action nodes (Cifra 1). The test
nodes test whether the agent has categorized a concept from its current context, which includes visual
estímulos, objects it may carry, and internal states. The concepts are formed from one or more categories
that relate to some feature of an object, such as shape, color, direction, sexo, or action. If the test on a test node
succeeds, the agent traverses to the next node in the left branch; de lo contrario, it traverses to the next node
in the right branch.
The bias nodes allow the agent to select from a multiple of branches based on a specific bias toward
certain subtrees. The biases determine the probability with which a certain branch is visited in the tree.
Note that a bias node can have more than two branches. These biases could be determined genetically
through evolution, and ontogenetically through individual learning and social learning. In our model, el
biases only change through social learning. When the learning process visits a certain bias node, the bias
toward the learned subtree will increase, as explained in Section 2.1.
The leaves of the DQT are action nodes, which include simple actions, such as move, turn-left,
or turn-right, first-order predicates such as eat(X), and second-order predicates such as give
(a,oh). The arguments can be any object, but if, Por ejemplo, an agent attempts to eat a non-food item,
this action will fail. The agent traverses the DQT until an action node is reached. The agent then performs
the action at the cost of a certain amount of energy. When the agentʼs energy drops below zero or the
agent reaches a certain age, the agent dies. Sin embargo, in order to focus entirely on the social learning of
language and skills, we maintained a constant population size by initializing all agents with sufficient en-
ergy and a maximum age to survive the entire simulation regardless of the energy intake and consumption.
The remainder of this section presents in more detail the implementation of the social learning of
skills and of language. Por conveniencia, we start explaining the social learning of skills as if the language
1 NEW TIES stands for New Emerging World models through Individual, Evolutionary, and Social learning. For more details and soft-
mercancía, consult http://www.new-ties.eu.
Artificial Life Volume 16, Número 4
291
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
Cifra 1. A simplified example of a decision Q-tree (DQT). The diamonds represent test nodes, the trapezoids bias nodes,
and the rounded rectangles action nodes.
were already in place. We will then explain how the words in the language arise and become shared
among the population.
2.1 Social Learning of Skills
The model implementing the social learning of skills is essentially the same as the one presented in [23],
but in that study the language for all agents was predefined, so messages were always conveyed perfectly.
A few changes have been made in order to accommodate language learning.
We have chosen for a push model, where teachers volunteer knowledge pieces that the students
then may accept. Other options, such as a pull model where agents request knowledge from other
agents, or a combined model where agents can advertise that they believe that they have useful knowl-
edge to share and other agents can then request that knowledge (similar to the “plumage” concept in
[46]) could be implemented as well. While this choice may seem improbably altruistic when considering
the agents as participating in a competitive “struggle for life,” it allows us to focus our investigations on
the feasibility and efficacy of social learning.
Social learning is implemented in the following sequence that every agent carries out at every
time step:
1. An agent chooses to initiate teaching a skill with a probability proportional to its own
estimation of communicative success cs (mira la sección 3.2), provided the agent is not engaged
in a language-learning interaction (mira la sección 2.2) and it sees one or more agents. El
dependence on cs is to prevent agents that are unskilled in language from teaching other
agents too often.
2. Of all the agents in the visible range, the teacher then selects the one with the lowest energy as
the student.
3. If the agent decides to send a message, the trace (or path) through its DQT that led to the
current action (p.ej., the rule [not carry plant; see agent]⇒ talk) is chosen as the
knowledge to be exchanged.
4. The teacher encodes a message using its lexicon (ver la siguiente sección). Only when all concepts that
make up the DQT trace are encoded into words is the message actually sent. Thus we ensure
that the relevant knowledge is transferred entirely (though possibly incorrectly) in order to
reduce errors in transmitting knowledge. It is also another measure to prevent agents that are
insufficiently skilled in language from teaching. The message is sent using a predefined syntax
that marks negation and the separation of test nodes and action nodes.
5. When an agent receives such a message, it stochastically chooses to integrate or disregard it. Él
would have been more natural to allow agents to choose the adoption of knowledge according
to other heuristics, such as the strength of social ties based on previous interactions, social
292
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
estado, or perceived fitness of the sender. We have opted for a stochastic process in order to
focus more on the ability of social learning. Sin embargo, by setting the probability of adoption to
pag = 0.2, we provide that agents do not always adopt knowledge. Además, it is likely that if this
probability is too high (p.ej., pag = 1.0), learning may suffer from overfitting or other biases.
6. When the agent accepts the message, it decodes all words into concepts in order to recreate the
trace through the DQT, using the predefined syntax.
7. Only when all words in the message were decoded into existing concepts (agents that have
not yet mastered the language to some degree may fail to do so, while others may do so
inaccurately) will the agent actually incorporate the received knowledge. This way we promote
the inclusion of complete rules and also allow agents to include rules only when they have
achieved a reasonable level of language competence.
8. When an agent s chooses to incorporate a DQT path P it received from an agent t, agent s
selects the most similar path P′ in its own DQT according to the following criteria:
(a) The percentage of matching tests
(b) The number of tests in P but not in P′
(C) The number of tests in P′ but not in P
If the percentage of matching elements in P′ is 100%, the bias for the action that P′ results
en, as well as all other bias nodes above that action in the tree, is adapted by incrementing
a frequency counter, which determines the probability that the bias node will be visited.
De lo contrario, the agent engages in a kind of dialectics, it inserts a bias node at the first point
of divergence between P and P′. The remainder of P′ is inserted as one option at that node;
a subtree corresponding to the non-matching entries in P is inserted as the alternative.
Cifra 2 illustrates this procedure.
Steps 1–4 implement the sender (teacher or speaker) part of the model, while steps 5–8 implement
the receiver (student or hearer) part. Agents can be both senders and receivers in the same time step,
but only with different partners.
2.2 Social Learning of Language
Social learning of language is based on Steelsʼ language-game model [47], in which a population of
agents can develop (or evolve) a language from scratch. In such models, agents are given an inter-
action protocol (the language game) that allows them to exchange expressions, invent new expressions,
Cifra 2. The result of integrating the path [not carry plant; see agent]⇒ talk into the DQT from Figure 1.
Artificial Life Volume 16, Número 4
293
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
and acquire them from other agents. As a result of the local interactions and learning mechanisms, a
common language can emerge through self-organization, leading to a cultural evolution of language.
The current model is based on a previous implementation within the NEW TIES platform as de-
scribed in [64], but is modified in crucial aspects to improve the performance and to make it compatible
with the social learning of skills. In the previous model [64], agents could not communicate about actions,
nor could they correctly learn to communicate about observer-dependent features such as directions and
distances. Además, agents could previously only communicate about visible object features, whereas in
this implementation agents are required to talk about paths through their DQTs to which the recipient
has no access. Sin embargo, in order to learn novel word-meaning mappings, receivers need to have (visual)
access to those meanings. Emulation might work as well, but is more complicated, so we opted to dis-
tinguish between language-learning interactions and skill-learning interactions. In the former, agents communi-
cate about visible objects and events, whereas in the latter, senders will communicate about what they
are currently doing by transmitting the activated path through their DQTs, as explained in the previous
sección. The remainder of this section presents the language model in more detail.
2.2.1 The Lexicon
The lexicon is implemented as an association matrix that maintains co-occurrence frequencies fij of
words wi and meanings mj (Mesa 1). Each time a word wi is heard in a learning context CL, the co-
occurrence frequencies between this word and all meanings mj ∈ CL are increased by one. The learning
context is only constructed during language-learning interactions, as described later. Esencialmente, este
implements cross-situational learning [42, 43, 56], where the meaning of a word is acquired by keeping track
of which meanings co-occur with a word. A unique meaning tends to win the competition with other
meanings as a result of the covariation between words and meanings across situations.
All words wi for which an agent has unique interpretations in meanings mj are stored in a separate,
individual list of word-meaning mappings, m = {〈wi, mj〉}. Each time an agent has updated the co-
occurrence frequencies of a word wi, it will evaluate which meaning mj has the highest co-occurrence
frequency fij. If this yields a unique interpretation, the word-meaning mapping is added to M; de lo contrario
the mapping has not been learned yet. Si, sin embargo, there is a tie with other meanings, the agent will apply
the mutual exclusivity constraint [31, 45] by discarding those meanings that are already interpretations
for other words. This may or may not yield a unique interpretation, but if it does, this interpretation
is added to the list of mappings M.
When different situations in which a given word is heard relate to different learning contexts in which
the wordʼs meaning always co-occurs, but not any other meaning, cross-situational learning (XSL) es
sufficient for learning a consistent set of word-meaning mappings. Sin embargo, in the current environment
and setup, some concepts always coincide with other concepts. Por ejemplo, a female agent is always
an agent, so each time the agent hears the word for female, both concepts female and agent are
present in the learning context. Although it is possible to allow the agents to learn that the word “female”
maps onto the conjunction of these concepts, we have decided to let the agents associate words with
Mesa 1. An illustration of the lexicon that agents construct and in which associations between concepts (columnas) y
palabras (filas) are stored based on their co-occurrence frequencies.
agent
femenino
masculino
eat
“agent”
“female”
“male”
“eat”
5
2
3
1
2
2
0
0
3
0
3
1
1
0
1
1
294
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
single concepts. Ahora, because the concept agent sometimes coincides with the concept male, el
word for agent can be learned through XSL alone (ver tabla 1). Once the word for agent is learned,
an agent can infer that the word for female would not be used to denote agent; otherwise the word
for agent would have been used. This constraint is similar to the mutual exclusivity constraint that
children appear to use [31], and also relates to the principle of contrast [13]. Note that the implementation
differs from the implementation of the principle of contrast described earlier in [64], where it was
implemented by a specific update of the weights.
2.2.2 Production
To achieve social learning of skills, we have decided to let agents communicate about paths (or traces)
through their DQT controllers. For language learning, sin embargo, agents need to construct a learning
context that contains the meanings of the words expressed; pero, as already mentioned, a recipient agent
cannot determine the DQT traces without using language. So, learning language from this informa-
tion alone would be infeasible. To facilitate the context construction, we let the agents engage in joint
attentional activities by pointing to an object (more on this will follow in Section 2.2.5). Sin embargo, a path
through a DQT can relate to multiple objects; the rule [not see agent; see plant]⇒ eat can
relate to three different objects. Since pointing to three objects is likely to amplify the confusion, nosotros
have opted to separate language-learning interactions from skill-learning interactions.
• Language-learning interactions (LLIs). For these interactions, speaker agents select
one object (called the topic), which is visible to both the speaker and the hearer. The hearerʼs
attention is drawn to that object through a pointing gesture implemented as a signal that hands
the objectʼs identifier to the hearer. The object is categorized so that each feature maps onto
one predefined concept.2 This results in the target list of concepts for which the speaker will
teach the hearer the words acquired by the speaker.
• Skill-learning interactions (SLIs). For these interactions, the target is set as the list of
concepts that constitute the test labels and action from the DQT controller evaluated at
that time step. The syntax of the DQT is adopted as the syntax of the speakerʼs expression,
so the test labels (a test label may include several concepts) are separated from each other and
are marked as being something visual, something carried, or internal to self; the test results
(yes/no) are provided explicitly; and actions always occur at the end of the sentence.
Once the target is set, the speaker produces for each concept in the target the word it has acquired in
its list of mappings, METRO. If a concept does not occur in this list, then the agent has not yet acquired this
mapping unambiguously through XSL. In such cases, the speaker invents—with a low probability ( pag =
0.01)—a new word and adds the association both to the lexicon with usage frequency one and to the list
of mappings. Words are invented as random strings containing one to three consonant-vowel pairs. El
resulting set of words are transmitted to the hearer. In the case of an SLI, the expression is only trans-
mitted if all concepts can be verbalized. This way, SLIs only tend to occur once the language is learned
to some degree.
2.2.3 Interpretation
When an agent hears an expression, it will try to interpret this expression. Each word is interpreted
according to the acquired mappings in M. If the expression concerns an LLI (es decir., the expression is
accompanied by a pointing gesture), the interpreted meaning is only accepted if it is in the learning
context CL; otherwise the interpretation fails.
2 Although it is possible to have concepts constructed during an agentʼs lifetime by means of discrimination games [48], we have decided
to predefine concepts in order to initiate agents with a DQT controller, as well as to reduce the learning complexity of the model.
Artificial Life Volume 16, Número 4
295
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
In the case of LLIs, the co-occurrence frequencies and the mapping list are updated before inter-
pretation proceeds, as described in Section 2.2.1. Además, the co-occurrence frequency of a word
and its interpreted meaning (if any) from the mapping list M is increased additionally to reduce the
need to incorporate the mutual exclusivity step.3
If the expression concerns an SLI and all words are interpreted with an existing meaning (desde
there is no learning context, these meanings can be any meaning acquired in M ), then—with the
syntactic information attached to the expression—the interpretation is transformed into a DQT-
compatible format that can be used for the social learning of skills as described earlier.
When a word cannot be interpreted in M, the interpretation fails. When it concerns an SLI, the agent
will decide not to incorporate the knowledge. Failed interpretations can also be triggered following atten-
tion dialogues, as we will discuss later.
2.2.4 Perspective Taking
Since we assume full autonomy, (virtual) embodiment, and situatedness of the agents, the problems they
face are similar to those faced by real robots (ver, p.ej., [59, 56] for discussions). In our model, conceptos
relate to properties of objects, such as shape, color, direction, distancia, weight, sexo, or actions (el ultimo
two only apply to agents). Due to our assumptions, it was found in [64] that although developing a
shared lexicon regarding observer invariant properties, such as shape and color, is relatively straight-
forward, agents could not learn mappings of the observer-dependent concepts front-left, frente,
front-right, reachable, cerca, and far. The reason for this is that agents did not take each
otherʼs perspective, so that what was to the left of one agent could have been to the right of another
agent, and what is reachable to one agent could have been far away to another.
To overcome this problem, we allowed the hearer to take the perspective of the speaker when con-
structing its learning context from the object pointed to in LLIs (a method that proved successful in
robotic experiments [52]). Perspective taking is achieved by reconstructing the dialogue partnerʼs visual
view through straightforward triangulation by using the visual information concerning the distance and
direction of both the pointed object and the speaker, as well as the speakerʼs orientation. Taking per-
spective in this way is necessary because the required autonomy and embodiment do not allow agents
to have access to each otherʼs stimuli, nor do the agents have a common absolute frame of reference.
Since the analysis of the model from [64] also revealed that agents were often communicating
about objects that hearers could not see, we also used this perspective-taking mechanism to ensure that
in LLIs speakers only communicated about (and hence pointed to) an object that the hearer could see.
2.2.5 Dialogue Control and Joint Attention
As mentioned, LLIs involve joint attention. Además, LLIs require both agents to see each other
in order to take each otherʼs perspective, and both need to see the object that is the topic of the inter-
acción. When—as in [64]—agents have no control of their actions dedicated to communication, situa-
tions in which these conditions occur tend to be rare. (Imagine communicating and learning language
from each other while walking past each other in different directions without stopping and gesturing.) A
dedicated dialogue controller was designed to implement dialogue-like LLIs that could override actions
decided by the DQT. Since SLIs do not require that agents see each other, the dialogue controller
did not coordinate such interactions. The main purpose of the dialogue controller is to coordinate
the establishment of joint attention as described hereafter, whereby the conditions required to take
perspective will be met implicitly. The dialogue controller is implemented as a behavior-based cognitive archi-
tecture [57], where two finite state automata implement the scripts of speaker and hearer. Transitions
from one state to another are communicated with predefined gestures to the dialogue partner when
turn-taking is required.
3 Children seem to use mutual exclusivity only for a small period. A mechanism like this could simulate this finding.
296
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
Two of the three joint attentional mechanisms proposed in [29] were implemented: checking/sharing
attention and following attention.4 Checking/sharing attention is the most basic one and is initiated by the
agent that becomes the speaker. If an agent is in its default state where it is not involved in any inter-
action and simply executes the actions decided by the DQT controller, then if it sees another agent, con
a certain probability it will initiate a checking attention dialogue by sending a hardwired gesture to the
visible agent. The initiator (or speaker) stops moving and waits for the other agentʼs response. El otro
agent, which becomes the hearer, will override its own DQT action and start turning left until it sees
the speaker. Then it will stop and send the speaker a hardwired gesture indicating that it sees the other
agent. (Note that such a gesture is not required, since the speaker could see this, but for computational
efficiency it is thus implemented.) The speaker then selects an object visible to both agents as the topic
(possibly one of the agents involved in the dialogue), and produces an expression containing a single
word for each concept describing this topic and sends the resulting message accompanied by a pointing
gesture to the hearer. In case the speaker itself is the topic, it will perform the action proposed by the
DQT controller to show this to the hearer. The hearer then constructs the learning context CL as the set
of concepts describing the topic from the speakerʼs perspective. Using this learning context, the hearer
adapts its lexicon and interprets the expression as described in Section 2.2.1.
Following attention dialogues are initiated by the hearer when—after interpretation—it wishes a clarifica-
tion of one or more words. This can occur after interpreting either an LLI or an SLI for words that
the hearer could not interpret or—with a low probability—for words it could interpret. If a following
attention dialogue is initiated, the hearer sends a gesture to the speaker indicating for which words it
requests clarification. Además, the hearer starts turning to the left until it sees the speaker, cual
stops moving. Since the speaker already initiated the interaction earlier, it is safe to assume that the
speaker sees the hearer.5 When the speaker is visible, the hearer sends a hardwired gesture to indicate
it is ready. The speaker then searches for an object visible to both agents (using perspective taking) y
whose concepts include one or more concepts that were expressed by the words that the hearer requests
clarification for. If the hearerʼs request is a response to an LLI, then a preference is given to a different
object than was pointed to in the first place. (If the speaker could not find a different object, la primera
object is taken.) If the new object does not cover all words that required a clarification, the non-covered
words are discarded. The speaker then produces an expression containing the words it clarifies accom-
panied by a pointing gesture. If the clarification involves an action, the speaker performs that action. El
hearer constructs the learning context as the set of concepts describing the object pointed to or—in case
the following attention dialogue was a response to a previous LLI—as the cross section between that
set and the learning context of the previous interaction. In the latter case, the learning context tends to
be smaller than the original one, thus speeding up learning [29].
3 experimentos
3.1 Environment Specification
In the experiments we describe here, the agents are faced with the well-known poisonous-food problem
[10, 37, 54]. They find themselves in an environment where there are two types of plants, both of which
can be picked up and eaten. One type is nutritious and yields an energy increase; the other type is poi-
sonous, and eating them actually drains energy. Agents can distinguish between the two types, pero ellos
do not know a priori that one kind—let alone which kind—is poisonous.
To measure the efficacy of social learning as a mechanism for the proliferation of knowledge
pieces through a population, we ran a series of experiments where the population consists of two
kinds of agents: knowers and students. The knowers have pre-built controllers that allow them to tackle
4 The three joint attentional mechanisms checking/sharing attention, following attention, and directing attention implemented in [29]
were inspired by the three mechanisms that humans are assumed to use [12].
5 This assumption does not always hold, because the speaker may have moved either when it produced an SLI or when it had to show the
action it was drawing the hearerʼs attention to.
Artificial Life Volume 16, Número 4
297
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
the poisonous-food problem. The students have a partially randomly constructed controller—they
know how to pick up and eat plants (regardless of their being poisonous or not), but the rest of their
DQTs are constructed randomly. A varying proportion of the knowers are teachers, who can initiate,
but not react to, SLIs. The remaining knowers do not engage in SLIs in any way (hence they neither
teach nor learn skills); they are only there to ensure that the environment contains the same number
of agents eating away at the edible plants across the experiments, so that the results are comparable.
Students both initiate and react to SLIs. The teachers, but not the knowers or students, were initialized
with a predefined lexicon where each concept is uniquely associated with a word form. Knowers
hacer, sin embargo, engage in LLIs, so they can contribute to (or frustrate) language development within
la población.
We ran the experiment with varying numbers of teachers to compare the rate at with which the
population of students learns to differentiate between nutritious and poisonous food. In our simula-
ciones, the world was initialized with 5000 edible plants and 5000 poisonous plants distributed randomly
en un 200 × 200 grid. Poisonous plants drain 1.5 times the energy that edible plants yield. Plants re-
grow practically immediately (within two time steps) after they have been picked, similar to food in
SugarScape [18]. De este modo, there is always food (and poison) disponible, and the ratio of poisonous to edible
plants more or less remains at the initial value 0.5. The total number of agents was fixed to N = 250,
of which 125 were knower agents and 125 were students, each of them positioned randomly at the start
of the experiments. We varied the number of teachers, Nt, with the following values: Nt = 0, 1, 25, 50,
75, 100, 125. Agents were given sufficient energy to survive the entire simulations. So the population
size remained constant throughout the simulations. All simulations were run for 50,000 time steps and
were performed 10 times for statistical purposes.
3.2 Measures
We monitored the simulations using the measures of communicative success, communicative accuracy,
and fitness.
3.2.1 Communicative Success
This is the average of the agentsʼ own estimates for communicative success. An agent verifies, after the
interpretation of each word in each LLI as a hearer, whether the interpretation yielded a valid meaning.
If this was the case, the agent assumes the interpretation was successful. Each agent ai keeps a measure
csi, which is the proportion of the thus successful interpretations during the past 50 interactions
where the agent acted as hearer. The communicative success (CS) is then the average csi:
CS ¼ 1
norte
XN
i¼1
csi :
ð1Þ
3.2.2 Communicative Accuracy
This measures the average of the agentsʼ accurate interpretations. After each interpretation of each
word in each utterance, the system verifies whether the interpreted concept is the same as that in-
tended by the speaker. The communicative accuracy (California) gives the proportion of accurate inter-
pretations during a given number of time steps (500 in the experiments reported). Let caij = 1 para
each agent i that interpreted a word wj accurately, and caij = 0 for each word interpreted inaccurately.
CA is then calculated as follows:
CA ¼ 1
norte
XN
i¼1
1
Wi
XWi
j¼1
!
caij
;
ð2Þ
298
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
where Wi is the number of words that agent i interpreted into some concept within the given time
window. (Words that were not interpreted at all, es decir., those that did not yield a concept, were not
incluido. This way, CA measures the accuracy of interpretations that agents themselves consider
successful, so CA is relative to CS.) To investigate the dynamics of the learning in more detail,
two different forms of CA were measured.
• CAall, the overall communicative accuracy, is the accuracy measured over all interactions of
all agents.
• CAsli measures CA over all studentsʼ interpretations of skill-learning interactions.
3.2.3 Fitness
In order to measure the effectiveness of social learning of skills, we used a fitness function based on
the proportions of the different types of food that the students eat:
F ¼ Ee
Ee þ Ep
(cid:1) Pe
Pe þ Pp
;
where Ee and Ep are the numbers of edible and poisonous plants eaten by the population during a time
frame of 500 time steps, and Pe and Pp are the numbers of edible and poisonous plants available in the
ambiente. The second term is introduced to compensate for the sometimes skewed proportion of
edible plants, which usually is around 0.5, but during the early stages tends to increase to 0.6. En esto
measure, random behavior will yield values around 0.0, whereas proper behavior will yield a fitness of
0.5, which occurs when all students have successfully learned the proper behavior.
Note that communicative success (CS) is calculated by individual agents to estimate their own
language proficiency, which they use as a probabilistic indicator of whether or not to send or accept
a skill-learning message. The number of words exchanged per time step depends on the frequency of
contact and the proficiency in language as measured by CS. Communicative accuracy is processed by an
external monitor that intercepts all received utterances, and it is calculated each 500 time steps.
3.3 Results and Discussion
Before presenting the results regarding the social learning of skills, we present those regarding the lan-
guage development. Cifra 3 shows that for each condition (es decir., number of teachers) communicative
= 125, but CS remains well
success rises toward values between 0.65 for Nt
behind in speed of development and level for both Nt = 0 and Nt = 1. It is important to realize that
CS is based on the agentsʼ own perception and indicates the percentage of received words for which the
agents succeeded in retrieving a concept by interpreting the utterances.
= 25 y 0.95 for Nt
Since the agents themselves evaluate CS, there is no guarantee they do so correctly. We therefore also
measure communicative accuracy, which checks, for each received word that agents interpreted success-
fully according to themselves, whether this interpretation matches the intended meaning. Considering all
agents, the communicative accuracy rose rapidly to well above 0.8 in the cases where Nt ≥ 25, and settled
cerca 0.9 (Figura 4a). The speed with which CA increased, sin embargo, was lower for Nt = 25, and CAall rose
even more slowly in the cases where Nt = 0 and Nt = 1. The lower results when Nt = 0 or Nt = 1 es
understood on realizing that in these conditions, the population had to develop their own language rather
= 1), es
than adopting those the teachers were given. Even in the case where there was one teacher (Nt
language did not spread sufficiently over the population to become influential. Sin embargo, also in these
casos, CAall increased to a value of around 0.8, so the interpretation was quite accurate.
It is important to realize that CAall was measured over LLIs and SLIs for all types of agents, incluido
teachers that knew the language, as well as knowers and students, both of which had to acquire the
Artificial Life Volume 16, Número 4
299
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
Cifra 3. The development of communicative success. Each line relates to a different number of teachers, Nt, as indicated
in the label, and is an average over 10 different runs.
idioma. To assess the adequacy of the acquired language to allow the social learning of skills, nosotros también
measured communicative accuracy only over SLI for students (Figura 4b). Here we see a similar result
when the population contained 25 or more teachers, but when Nt = 0 or Nt = 1, CAsli also increased
early on to a value over 0.8. This high yield when Nt = 0 or Nt = 1 may seem odd, but it is important
to realize that in SLIs an expression is sent or accepted by the agents participating in an interaction only
if all concepts or words (each node in the DQT relates to one or more words) have a unique mapping
for production or interpretation. This takes a while, because the language is (almost) nonexistent at first
= 1 and only happens for one or possibly two branches of the DQT (p.ej., [carry
when Nt
plant] ⇒ eat). Hence the late rise of CAsli after approximately 4000 time steps. Shortly after CAsli
first increased, we see the curve drop again, after which it rises again, similar to the well-studied U curve
observed in language learning (p.ej., [30, 53]). (This also occurs for CS and to a lesser extent CAall.)
= 0 or Nt
To explain the occurrence of this U curve, it is important to stress that SLIs only lead to an actual
utterance in the case where all concepts can be expressed. For teachers this always succeeds, but for
students it only succeeds in the case where the language is sufficiently developed. Sin embargo, estudiantes
can act as teachers and, En realidad, form the majority of teachers when Nt = 0 or Nt = 1. So the first suc-
cessfully expressed SLIs involve rules whose concepts are most straightforwardly learned through XSL,
such as plant or agent. Since these words are by then already successfully established by the students,
CAsli rises sharply. Sin embargo, when more complex rules are being expressed and interpreted, they in-
volve concepts that the recipients may not have adequately disambiguated yet. Por ejemplo, a word in-
tended to mean plant by one agent may be inadequately interpreted as meaning poisonous-plant
by another agent or vice versa. Como consecuencia, CAsli drops. Sin embargo, con el tiempo, these problems are also
solved through language learning, so CAsli rises again. Este, together with the low usage frequency of
words when there are fewer teachers, explains the U curve.
Frequency is also an important factor regarding the effectiveness of language development. Higo-
=
ura 5 shows the number of words exchanged during a window of 500 time steps for the conditions Nt
= 125. The lower lines show the number of words exchanged as part of language-learning
0 and Nt
interactions, which rises to about 3000 words per 500 time steps in both extreme cases. This means that
each time step about six words are being expressed, which is slightly more than one LLI each time
step (an LLI typically contains five words describing the object). The number of words exchanged in
skill-learning interactions during each 500 time steps starts to rise later, but then rapidly exceeds the
number of words expressed in LLIs. The main reasons for this difference are that the number of
300
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
SLIs is positively related to CS and that no dedicated physical coordination is required to carry out an
SLI. Since the number of SLIs depends on the level of CS, it also depends on the number of teachers
in the population, as they have a CS of 1. When there are no teachers, the number of words exchanged
rises to about 18,000 (Figure 5a), whereas this number rises to around 76,000 when there are 125 enseñar-
ers (Figura 5b). With more teachers in the population, the number of SLIs also exceeds the number
of LLIs earlier in the simulations, because CS rises more rapidly.
The fitness measure F shows that the language needs to be shared among the population to a
sufficient degree for skill learning to become successful (ver figura 6). F only increases when Nt ≥
= 50 and even more so than
25, but when Nt
= 25, it remains substantially lower than when Nt
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4. The results on average communicative accuracy for (a) all agents and all interactions, y (b) studentsʼ SLIs. Cada
line in CAall and CAsli shows averages over 10 different runs and relates to a different number of teachers, Nt, as indicated
in the legends.
Artificial Life Volume 16, Número 4
301
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 5. The number of LLIs (solid lines) and SLIs (dashed lines) played during 500 time steps for (a) Nt = 0 y (b) Nt =
125. All lines are averages over 10 different runs.
when Nt ≥ 75. When Nt = 0 or Nt = 1, F remains practically 0. In these cases, the curve fluctuates
greatly toward the end, because the students tend to eat less often. De término medio, when Nt = 125, el
= 0, in which case about one
students ended up eating 35 times more often than the students when Nt
eating action is performed each 500 time steps. The reason for this low number of eating actions is
that other (aleatorio) skills are being learned from other students, because the knowers do not engage in
SLIs. Además, in the case that Nt = 1, the only teacherʼs language fails to invade the population, entonces
it cannot communicate its skills. This was despite the fact that the word creation probability (es decir., el
chance an agent would invent a new word when it failed to produce an utterance) was kept low at 0.01,
302
Artificial Life Volume 16, Número 4
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
so that existing words would have had enough time to propagate in the population. (In most language-
game studies, this word creation probability is set to 1; p.ej., [45, 51, 62].) Since learning from unskilled
students is not beneficial, F remains low.
Basically, the above means that the mechanisms for the social learning of skills work well and
also that the language appears to develop to a sufficient degree when Nt = 0 or Nt = 1, but then the
agents learn skills from agents who are still students and have not (todavía) mastered the proper behavior.
A potential solution to this problem would be to use reputation (p.ej., based on fitness) as a trigger to
adopt socially transmitted skills, so students would tend to learn only from those agents who use the
= 1 when the language was predefined [23], but during
appropriate skills [40]. This worked well for Nt
the modelʼs development we discovered that this did not work when the language had to be acquired
from scratch. Further studies are required to understand why reputation does not work well in the cur-
rent model.
4 General Discussion
In this article we have related our model to what Gergely and Csibra have called pedagogy learning [20], eso
es, the learning of opaque knowledge through dedicated social transfer of skills. Both the rules represent-
ing the relevant skills and the meanings of words are opaque, because they are not directly accessible
to other agents. In our model, the rules are transmitted through language, whose meanings—in turn—
are transmitted by means of joint attention. Por eso, one medium for communication (idioma) is ac-
quired using another medium of communication (joint attention). So joint attention acts as a scaffold
for learning language, which then forms a scaffold for learning rule-like skills. This shows that pedagogy
learning can act at different levels of knowledge using different means of communication.
Our model goes beyond previous simulations in that the environment is more complex and demand-
ing than most simulations in the combination of, among others, skill learning, language learning, the num-
ber of observable features, population size, embodiment, and situatedness. Various models have gone
beyond the complexity of individual aspects of the model. Por ejemplo, the population size in [4] era
much larger than in the current model, but the number of meanings was low and no embodiment was
assumed. Asimismo, the language and embodiment in Steelsʼ robots implementing fluid construction
grammars (p.ej., [50]) exceeds the complexity of the current model, but there the population size was
Cifra 6. The development of the fitness F for the experiment with different numbers of teachers. Again the lines are
averages over 10 different runs.
Artificial Life Volume 16, Número 4
303
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
low and these robots did not use the language to transmit opaque rule-based skills. es la combinacion
of the various aspects we have implemented that makes the difference with other models.
The primary objective of this study has been to investigate what sociocognitive mechanisms are
required for a population of agents to achieve this social learning at different levels in a model that
assumes—insofar as is possible in a simulation—strict autonomy, embodiment, and situatedness. En
particular, we have been interested in those mechanisms that become important when integrating various
basic mechanisms, such as cross-situational learning of word-meaning mappings with skill-learning
mechanisms, while being constrained by physical aspects of the real world (por ejemplo, no explicit
meaning transfer, different perspectives, etc.). As argued in [64], we believe that building such a model
is highly instructive for understanding (algunos de) the sociocognitive mechanisms that our ancestors
(protohumans) should and/or might have evolved as a prerequisite for the evolution of language and/
or a complex culture.
Here we summarize the most crucial mechanisms we had to implement in order to deal with the
problems agents in our environment face (mostly relating to language learning):
• We have distinguished between language-learning interactions and skill-learning interactions.
As the SLIs involve agents communicating parts of their internal controllers, estos
communication acts could not be used directly to learn language. (Indirectly they could,
by having agents request for clarifications of unknown words, after which the agents could
engage in LLIs.) This is because agents need to construct a context of concrete objects in order
to learn mappings between words and their meanings (concepts derived from visible objects or
agentsʼ own states and actions). So we expect that humans evolved different ways to interact
with each other, depending on whether the interactions are aimed at learning language or other
internal rules.
• On a related note, the language performance of agents has to be at a sufficient level
to achieve an efficient transfer of skills. We devised heuristics for agents to evaluate
their own competence, such as having agents measure their own communicative success,
and transmit or incorporate skill knowledge only when the construction or interpretation
of entire messages succeeds (whether correctly or not). We demonstrated that using
these heuristics, communicative accuracy during SLIs tends to exceed 90%. We expect
that humans have evolved (or otherwise acquired) the ability to self-assess language
actuación.
• The LLIs require coordinated interactions involving turn-taking and joint attention. Learning a
referential language from each other in a complex world requires rather sophisticated
and coordinated interactions, mostly in order to establish joint attention and perspective
tomando. Such interactions may be triggered by seeing another agent, but also by requesting
clarifications for words that are not well understood. In order to show another agent a
particular action, point to an object, or take perspective, both agents have to be able to see
each other as well as the third object, and they have to stand still for an instant so that both
agents can observe the situation well. To facilitate the turn-taking involved, agents have to
signal to each other that they want to communicate, in what stage of an interaction they are,
and what role they are taking. So, turn-taking and coordinated joint activity aimed to establish
common ground [14] through joint attention appears to be a crucial prerequisite for human
languages to have evolved.
• Although not surprising, perspective taking is pivotal to learning words relating to observer-
dependent features such as directions and distances of objects with respect to agents. Este
requires agents to imagine what other agents see. To achieve this, an agent needs to see both
the other agent and the target object. The dialogues are crucial in that respect. Perspective
taking is not only crucial to learning observer-dependent word-meaning mappings, but can
304
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
also aid in preventing an agent from talking about something that is outside the visual field of
another agent.
• The usefulness of mutual exclusivity is also not completely surprising, as it is a constraint
that children appear to use [31] and has been incorporated successfully in previous models
of cross-situational learning [45]. Sin embargo, in the current model it has become clear why
it could be a necessary constraint. Como, por ejemplo, the concept female always co-occurs
with the concept agent, the word for female could not be learned through statistical
cross-situational learning alone, unless we have allowed words to be associated with
combinations of concepts such as [female agent ]. For reasons of learning complexity
(the search space would face a combinatorial explosion), sin embargo, we decided to opt for
implementing the computationally cheap mutual exclusivity constraint. Es posible que
mutual exclusivity arose to deal with exactly these types of problems.
• Syntax is required for covert complex rules to be transmitted such that agents can reconstruct
the tree (regla) structure of the transmitted knowledge social learning. en este estudio, tenemos
decided to predefine the syntax, as well as negation, but syntax is a prerequisite for social
learning of complex opaque rules, and humans unquestionably have evolved it. The lack
of syntax may be a reason why other species do not display the social learning of covert skills
by means of pedagogy. It is also interesting to note that the structure of rules may be reflected
in the syntax that humans have evolved; at least some components of rule-like knowledge
occur in the grammar of natural languages (p.ej., if…then… constructions).
We realize that the current analysis is far from complete and much more work needs to be done. Para
instancia, additional research is required into the prerequisites required for syntax to evolve. A pesar de
various studies have already looked into that problem (p.ej., [5, 27, 50]), we believe it is also important
to investigate it in relatively complex platforms such as these. Además, it is equally important to verify
such formal models by comparing them with empirical findings on human behavior [63]. También, más
research is required into the sociocognitive mechanisms that underlie the social learning of rule-like
habilidades. Quite a bit of research has already been done regarding, por ejemplo, reputation-based social
aprendiendo, but usually using explicit knowledge transfer [40]. Sin embargo, the mechanisms developed in
such models do not necessarily hold when transmitting covert rules using a language that needs to de-
velop first. The reputation-based learning mechanism we implemented in our previous model that used
explicit knowledge transfer [23], Por ejemplo, did not work well in the current model when the language
had to develop first.
5 Conclusions
We have investigated what sociocognitive mechanisms are required to design a model of social learning
of both language and survival skills through pedagogy learning. Our design was constrained by our
assumption of strict autonomy, virtual embodiment, and situatedness. We have demonstrated that the
following sociocognitive mechanisms are crucial in our design, and we hypothesize that protohumans
had to evolve (or otherwise learn) a ellos:
1. Agents need to separate language learning from learning other skills (es decir., they cannot do both
simultaneously).
2. Agentsʼ ability to assess their own language performance aids the successful transmission of
skill knowledge.
3. Learning word-meaning mappings requires agents to coordinate their interactions using
turn-taking and joint attention.
Artificial Life Volume 16, Número 4
305
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
4. Agents require taking each otherʼs perspective when learning language.
5. Mutual exclusivity is advantageous for learning word meanings when words always coincide
with multiple meanings.
6. Syntax is required to structure the rules so that they can be reconstructed by the recipient.
We have shown how pedagogy learning can work for different types of knowledge. Based on our
findings, we hypothesize that—in general—“lower,” more primitive means of communication are re-
quired to facilitate the social (“pedagogy”) learning of the higher-level knowledge. In our model,
the social learning of skills is facilitated by language, whose learning in turn is facilitated by joint atten-
ción. En un sentido, one means of communication forms a scaffold for learning the next level. How this is
generalizable across different levels of social learning is subject to further investigation. Research could
be done to investigate what lower-level communication is required to facilitate the learning of joint at-
tention, which—following our model—could be the communication that manages the turn-taking dia-
logues. One could also proceed in the other direction by investigating what the social learning of skills
can contribute to advance social learning at the next levels. Perhaps the answer lies somewhere in the
advancement of social learning among artificial agents. In any case, scaffolding social learning thus re-
duces the cost of learning opaque knowledge substantially and, following [7], could therefore contribute
immensely to cumulative cultural evolution.
Expresiones de gratitud
The NEW TIES project, of which this work has been part, was supported by a European Commission
FET grant under contract FP6-502386. Information provided in this manuscript is entirely the authorsʼ
responsibility; it does not necessarily reflect the views of the Commission or even those of other
NEW TIES members. We thank all project members for their invaluable contributions and sugges-
ciones. Paul Vogt is supported by the Netherlands Organisation for Scientific Research (NOW) a través de
a Vidi grant.
Referencias
1. Acerbi, A., Marocco, D., & Vogt, PAG. (2008). Social learning in embodied agents. Connection Science, 20, 69–72.
2. Acerbi, A., & Nolfi, S. (2007). Social learning and cultural evolution in embodied and situated agents. En
Proceedings of the First IEEE Symposium on Artificial Life. Piscataway, Nueva Jersey: IEEE Press.
3. Annunziato, METRO., & Pierucci, PAG. (2003). The emergence of social learning in artificial societies. In Applications
of evolutionary computing (páginas. 467–478). Berlina: Saltador.
4. Baronchelli, A., Felici, METRO., Caglioti, MI., Loreto, v., & Steels, l. (2006). Sharp transition towards shared
lexicon in multi-agent systems. Revista de mecánica estadística, P06014.
5. Batali, j. (2002). The negotiation and acquisition of recursive grammars as a result of competition among
exemplars. In T. Briscoe (Ed.), Linguistic evolution through language acquisition: Formal and computational models.
Cambridge, Reino Unido: Prensa de la Universidad de Cambridge.
6. Belpaeme, T., & Bleys, j. (2005). Explaining universal colour categories through a constrained acquisition
proceso. Adaptive Behavior, 13, 293–310.
7. chico, r., & Richerson, PAG. j. (1985). Culture and the evolutionary process. chicago: University of Chicago Press.
8. Bull, l., Studley, METRO., Bagnall, A., & Whitley, I. (2007). Learning classifier system ensembles with rule-sharing.
IEEE Transactions on Evolutionary Computation, 11(4), 496–502.
9. Cangelosi, A., Greco, A., & Harnad, S. (2000). From robotic toil to symbolic theft: Grounding transfer from
entry-level to higher-level categories. Connection Science, 12, 143–162.
10. Cangelosi, A., & Parisi, D. (1998). The emergence of “language” in an evolving population of neural networks.
Connection Science, 10, 83–93.
306
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
11. Cangelosi, A., & Parisi, D. (Editores.). (2002). Simulating the evolution of language. Berlina: Saltador.
12. Carpintero, METRO., Nagell, K., Tomasello, METRO., Butterworth, GRAMO., & moore, C. (1998). Social cognition, articulación
atención, and communicative competence from 9 a 15 months of age. Monographs of the Society for Research
in Child Development, 63(4).
13. clark, mi. V. (1993). The lexicon in acquisition. Cambridge, Reino Unido: Prensa de la Universidad de Cambridge.
14. clark, h. h. (1996). Using language. Cambridge, Reino Unido: Prensa de la Universidad de Cambridge.
15. Conte, r., & Paolucci, METRO. (2001). Intelligent social learning. Journal of Artificial Societies and Social Simulation, 4(1),
U61–U82.
16. de Boer, B. (2001). The origins of vowel systems. Oxford, Reino Unido: prensa de la Universidad de Oxford.
17. Eiben, A. MI., Griffioen, A. r., & Haasdijk, mi. (2007). Population-based adaptive systems: An implementation
in NEW TIES. Presented at ECCS 2007, European Conference on Complex Systems 2007.
18. Epstein, j. METRO., & Axtell, R. (1996). Growing artificial societies: Social science from the bottom up. Cambridge, MAMÁ:
CON prensa.
19. Galef, B., Jr. (1995). Why behaviour patterns that animals learn socially are locally adaptive. Animal Behaviour,
49(5), 1325–1334.
20. Gergely, GRAMO., & Csibra, GRAMO. (2006). Sylvia’s recipe: The role of imitation and pedagogy in the transmission of
cultural knowledge. Posada. j. Enfield & S. C. levinson (Editores.), Roots of human sociality: Cultura, cognition, y
interacción (páginas. 229–255). Oxford, Reino Unido: Iceberg.
21. Gergely, GRAMO., Nadasdy, Z., Csibra, GRAMO., & Bíró, S. (1995). Taking the intentional stance at 12 months of age.
Cognición, 56(2), 165–193.
22. Gilbert, NORTE., den Besten, METRO., Bontovics, A., Craenen, B., Divina, F., Eiben, A., Griffioen, A. r., Hévézi, GRAMO.,
Lörincz, A., Paechter, B., Schuster, S., Schut, METRO., Tzolov, C., Vogt, PAG., & Cual, l. (2006). Emerging artificial
societies through learning. Journal of Artificial Societies and Social Simulation, 9(2).
23. Haasdijk, MI., Vogt, PAG., & Eiben, A. (2008). Social learning in population-based adaptive systems. In IEEE
Congress on Evolutionary Computation, 2008. CEC 2008. (IEEE World Congress on Computational Intelligence)
(páginas. 1386–1392).
24. Hayes, GRAMO., & Demiris, j. (1994). A robot controller using learning by imitation. In A. Borkowski & j. l.
Crowley (Editores.), Proceedings of the 2nd International Symposium on Intelligent Robotic Systems (páginas. 198–204).
Grenoble, Francia: LIFTA-IMAG.
25. Heyes, C. METRO. (1994). Social learning in animals: Categories and mechanisms. Biological Reviews, 69, 207–231.
26. Horner, v., & Whiten, A. (2005). Causal knowledge and imitation/emulation switching in chimpanzees (Cacerola
troglodytes) and children (Homo sapiens). Animal cognition, 8(3), 164–181.
27. kirby, S. (2001). Spontaneous evolution of linguistic structure: An iterated learning model of the emergence
of regularity and irregularity. IEEE Transactions on Evolutionary Computation, 5(2), 102–110.
28. kirby, S. (2002). Natural language from artificial life. Artificial Life, 8(3), 185–215.
29. Kwisthout, J., Vogt, PAG., Haselager, PAG., & Dijkstra, t. (2008). Joint attention and language evolution. Connection
Ciencia, 20, 155–171.
30. marco, GRAMO., Pinker, S., Ullman, METRO., Hollander, METRO., rosa, T., & Xu, F. (1992). Overgeneralization in
language acquisition. Monographs of the Society for Research in Child Development, 57(4).
31. Markman, mi. (1989). Categorization and naming in children. Cambridge, MAMÁ: CON prensa.
32. Marocco, D., & Nolfi, S. (2006). Origins of communication in evolving robots. In Lecture notes in computer science
(LNAI) 4095 (páginas. 789–803). Berlina: Saltador.
33. Nehaniv, C. l., & Dautenhahn, k. (Editores.) (2007). Imitation and social learning in robots, humans and animals.
Cambridge, Reino Unido: Prensa de la Universidad de Cambridge.
34. Noble, J., & Franks, D. W.. (2004). Social learning in a multi-agent system. Computing and Informatics, 22(6),
561–574.
35. Noble, J., & Todd, PAG. METRO. (2002). Imitation or something simpler? Modelling simple mechanisms for social
procesamiento de información. In K. Dautenhahn & C. Nehaniv (Editores.), Imitation in animals and artifacts. Cambridge,
MAMÁ: CON prensa.
Artificial Life Volume 16, Número 4
307
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
36. Noble, J., Todd, PAG. METRO., & Tuci, mi. (2001). Explaining social learning of food preferences without aversions:
An evolutionary simulation model of Norway rats. Proceedings of the Royal Society B: Ciencias Biologicas, 268(1463),
141–149.
37. Nolfi, S., & Parisi, D. (1996). Learning to adapt to changing environments in evolving neural networks.
Adaptive Behavior, 5(1), 75.
38. Oliphant, METRO. (1998). Rethinking the language bottleneck: Why donʼt animals learn to communicate?
In C. Caballero & j. R. Hurford (Editores.), The evolution of language (selected papers from the 2nd International Conference
on the Evolution of Language, Londres, April 6–9, 1998).
39. Oudeyer, P.-Y. (2005). How phonological structures can be culturally selected for learnability. Adaptado
Comportamiento, 13, 269–280.
40. Paolucci, METRO., & Conte, R. (2009). Reputation: Social transmission for partner selection. In G. PAG. Trajkovski
(Ed.), Agent-based societies: Social and cultural interactions. Hershey, Pensilvania: IGI Publishing.
41. Schaal, S. (1999). Is imitation learning the route to humanoid robots? Tendencias en Ciencias Cognitivas, 3(6),
233–242.
42. Siskind, j. METRO. (1996). A computational study of cross-situational techniques for learning word-to-meaning
mappings. Cognición, 61, 39–91.
43. Herrero, A. D. METRO. (2001). Establishing communication systems without explicit meaning transmission.
In J. Kelemen & PAG. Sosík (Editores.), Proceedings of the 6th European Conference on Artificial Life, ECAL 2001,
LNAI 2159 (páginas. 381–390). Berlina: Editorial Springer.
44. Herrero, A. D. METRO. (2003). Intelligent meaning creation in a clumpy world helps communication. Artificial Life,
9(2), 559–574.
45. Herrero, A. D. METRO. (2005). Mutual exclusivity: Communicative success despite conceptual divergence. En m.
Tallerman (Ed.), Language origins: Perspectives on evolution (páginas. 372–388). Oxford, Reino Unido: prensa de la Universidad de Oxford.
46. Herrero, r., Bonacina, C., Kearney, PAG., & Merlat, W.. (2000). Embodiment of evolutionary computation in general
agents. Computación evolutiva, 8(4), 475–493.
47. Steels, l. (1996). Emergent adaptive lexicons. In P. Maes, METRO. Mataric, J.-A. Meyer, j. Pollack, & S. wilson
(Editores.), From Animals to Animats 4: Proceedings of the Fourth International Conference on Simulating Adaptive Behavior
(páginas. 562–567). Cambridge, MAMÁ: CON prensa.
48. Steels, l. (1996). Perceptually grounded meaning creation. En m. Tokoro (Ed.), Proceedings of the International
Conference on Multi-Agent Systems. Menlo Park, California: AAAI Press.
49. Steels, l. (2003). Evolving grounded communication for robots. Tendencias en Ciencias Cognitivas, 7(7), 308–312.
50. Steels, l., & Beule, j. D. (2006). Unify and merge in fluid construction grammar. In P. Vogt, Y. Sugita, mi.
Tuci, & C. Nehaniv (Editores.), Symbol grounding and beyond: Proceedings of the Third International Workshop on the
Emergence and Evolution of Linguistic Communication (páginas. 197–223). Berlina: Saltador.
51. Steels, l., Kaplan, F., McIntyre, A., & Van Looveren, j. (2002). Crucial factors in the origins of word-meaning.
In A. Wray (Ed.), The transition to language (páginas. 252–271). Oxford, Reino Unido: prensa de la Universidad de Oxford.
52. Steels, l., & Loetzsch, METRO. (2007). Perspective alignment in spatial language. In K. R. Coventry, t. Tenbrink, &
j. A. bateman (Editores.), Spatial language and dialogue. Oxford, Reino Unido: prensa de la Universidad de Oxford.
53. Taatgen, NORTE., & anderson, j. (2002). Why do children learn to say broke? A model of learning the past tense
without feedback. Cognición, 86(2), 123–155.
54. Todd, PAG. METRO., & Molinero, GRAMO. F. (1990). Exploring adaptive agency II: Simulating the evolution of associative
aprendiendo. In Proceedings of the First International Conference on Simulation of Adaptive Behavior: From Animals to
Animats (páginas. 306–315). Cambridge, MAMÁ: CON prensa.
55. Tomasello, METRO., & Call, j. (1997). Primate cognition. Oxford, Reino Unido: prensa de la Universidad de Oxford.
56. Vogt, PAG. (2000). Bootstrapping grounded symbols by minimal autonomous robots. Evolution of Communication,
4(1), 89–118.
57. Vogt, PAG. (2000). Lexicon grounding on mobile robots. Doctor. tesis, Vrije Universiteit Brussel.
58. Vogt, PAG. (2005). The emergence of compositional structures in perceptually grounded language games.
Artificial Intelligence, 167(1–2), 206–242.
308
Artificial Life Volume 16, Número 4
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
PAG. Vogt and E. Haasdijk
Modeling Social Learning of Language and Skills
59. Vogt, PAG. (2006). Language evolution and robotics: Issues in symbol grounding and language acquisition.
In A. Loula, R. Gudwin, & j. Queiroz (Editores.), Artificial cognition systems (páginas. 176–209). Hershey, Pensilvania: Idea Group
Publishing.
60. Vogt, PAG. (2007). Group size effects on the evolution of compositional languages. In F. Almeida e Costa, l.
Rocha, mi. Costa, I. harvey, & A. Coutinho (Editores.), Advances in Artificial Life: Proceedings of ECAL-2007
(LNAI 4684) (páginas. 405–414). Berlina: Saltador.
61. Vogt, PAG. (2007). Variation, competition and selection in the self-organisation of compositionality. In B.
Wallace, A. ross, j. B. Davies, & t. anderson (Editores.), The mind, the body and the world: Psychology after cognitivism?
(páginas. 233–256). Exeter: Imprint Academic.
62. Vogt, PAG., & Coumans, h. (2003). Investigating social interaction strategies for bootstrapping lexicon
desarrollo. Journal for Artificial Societies and Social Simulation, 6(1). http://jasss.soc.surrey.ac.uk.
63. Vogt, PAG., & de Boer, B. (2010). Language evolution: Computer models for empirical data. Adaptive Behavior,
18(1), 5–11.
64. Vogt, PAG., & Divina, F. (2007). Social symbol grounding and language evolution. Interaction Studies, 8(1), 31–52.
65. Werner, GRAMO. METRO., & Dyer, METRO. GRAMO. (1991). Evolution and communication in artificial organisms. In C. GRAMO.
Langton, C. taylor, & j. D. Farmer (Editores.), Artificial life II, volumen. X of SFI studies in the sciences of complexity.
Reading, MAMÁ: Addison-Wesley.
66. Ziemke, T., & Sharkey, norte. mi. (2001). A stroll through the worlds of robots and animals: Applying Jakob
von Uexküllʼs theory of meaning to adaptive robots and artificial life. Semiotica, 134(1–4), 701–746.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Artificial Life Volume 16, Número 4
309
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
a
r
t
yo
/
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
6
4
2
8
9
1
6
6
2
7
4
6
a
r
t
yo
/
_
a
_
0
0
0
0
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3