¿Por qué surge la sorpresa de los modelos de lenguaje más grandes basados en transformadores?
Provide a Poorer Fit to Human Reading Times?
Byung-Doh Oh
Department of Linguistics
The Ohio State University, EE.UU
oh.531@osu.edu
William Schuler
Department of Linguistics
The Ohio State University, EE.UU
schuler.77@osu.edu
Abstracto
This work presents a linguistic analysis into
why larger Transformer-based pre-trained lan-
guage models with more parameters and
lower perplexity nonetheless yield surprisal
estimates that are less predictive of human
reading times. Primero, regression analyses show
a strictly monotonic, positive log-linear rela-
tionship between perplexity and fit to reading
times for the more recently released five
GPT-Neo variants and eight OPT variants
on two separate datasets, replicating earlier
results limited to just GPT-2 (Oh et al.,
2022). Después, analysis of residual er-
rors reveals a systematic deviation of the larger
variants, such as underpredicting reading times
of named entities and making compensatory
overpredictions for reading times of func-
tion words such as modals and conjunctions.
These results suggest that the propensity of
larger Transformer-based models to ‘memo-
rize’ sequences during training makes their
surprisal estimates diverge from humanlike
expectations, which warrants caution in using
pre-trained language models to study human
language processing.
1
Introducción
Expectation-based theories of sentence processing
(Hale, 2001; Exacción, 2008) postulate that process-
ing difficulty is largely driven by how predictable
upcoming linguistic material is given its context.
In cognitive modeling, predictability operational-
ized by information-theoretic surprisal (shannon,
1948) has been shown to be a strong predictor
of behavioral and neural measures of process-
ing difficulty (Demberg and Keller, 2008; Herrero
and Levy, 2013; Hale et al., 2018; Shain et al.,
2020), providing empirical support for this posi-
ción. As language models (LMs) directly define a
conditional probability distribution of a word given
its context required for surprisal calculation, ellos
336
have frequently been evaluated as surprisal-based
cognitive models of sentence processing.
Recientemente, it was observed that surprisal from
larger variants of the pre-trained GPT-2 LM
(Radford et al., 2019) that have more parame-
ters and achieve lower perplexity is less predictive
of self-paced reading times and eye-gaze dura-
tions collected during naturalistic reading (Oh
et al., 2022). As the different variants of the pre-
trained GPT-2 model share the primary architec-
ture and training data, this offers an especially
strong counterexample to previous work that
showed a negative relationship between LM per-
plexity and predictive power of surprisal esti-
compañeros (Goodkind and Bicknell, 2018; Hao y cols.,
2020; Wilcox et al., 2020). More broadly, este
observation also contradicts the recent ‘larger is
better’ trend of the NLP community, leaving open
the question of why larger LMs perform worse.
Sin embargo, the Oh et al. (2022) results were part
of a follow-up analysis in support of a separate
claim about parser surprisal that only examined
four model variants, so the results were not tested
for statistical significance or extensively explored.
The current work fills that gap by conducting
a detailed linguistic analysis of the positive re-
lationship between LM perplexity and predictive
power of surprisal estimates. Primero, the robustness
of the trend observed in Oh et al. (2022) is exam-
ined by reproducing their results and additionally
evaluating surprisal estimates from different fam-
ilies of Transformer-based LMs (GPT-Neo, OPT;
Black et al., 2021, 2022; Wang and Komatsuzaki,
2021; Zhang et al., 2022) on their ability to
predict human reading times. Results from regres-
sion analyses show a strictly monotonic, positivo
log-linear relationship between LM perplexity and
fit to reading times for the five GPT-Neo variants
and eight OPT variants on two separate datasets,
which provides firm empirical support for this
Transacciones de la Asociación de Lingüística Computacional, volumen. 11, páginas. 336–350, 2023. https://doi.org/10.1162/tacl a 00548
Editor de acciones: Marco Baroni. Lote de envío: 10/2022; Lote de revisión: 12/2022; Publicado 3/2023.
C(cid:2) 2023 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
trend. Después, to provide an explanation
for this positive relationship, residual errors from
the regression models are analyzed with a focus
on identifying linguistic phenomena that surprisal
from larger variants accounts for less accurately
compared to surprisal from their smaller coun-
terparts. The results show that regression models
with surprisal predictors from GPT-2, GPT-Neo,
and OPT models generally underpredict reading
times at nouns and adjectives, and that the degree
of underprediction increases along with model
tamaño. This indicates that the poorer fit to human
reading times achieved by surprisal estimates from
larger Transformer-based LMs is primarily driven
by their characteristic of assigning lower surprisal
values to open-class words, which may be accu-
rately predicted by extensive domain knowledge
gleaned from large sets of training examples that
are not available to humans. This suggests that as
Transformer-based LMs get larger, they may be
problematic for cognitive modeling because they
are trained with non-human learning objectives
and different inductive biases on vast quantities of
Internet text.1
2 Trabajo relacionado
(LSTM; Hochreiter
In previous studies, surprisal estimates from
several well-established types of LMs, incluido
n-gram models, Simple Recurrent Networks
(elman, 1991), Gated Recurrent Unit networks
(GRU; Cho et al., 2014), and Long Short-Term
Memory networks
y
Schmidhuber, 1997), have been compared against
behavioral measures of processing difficulty (p.ej.,
Smith and Levy, 2013; Goodkind and Bicknell,
2018; Aurnhammer and Frank, 2019). Recientemente,
as Transformer-based (Vaswani et al., 2017) modificación-
els have dominated many NLP tasks, both large
pre-trained and smaller
‘trained-from-scratch’
Transformer-based LMs have also been evaluated
as models of processing difficulty (Wilcox et al.,
2020; Hao y cols., 2020; Merkx and Frank, 2021;
Schrimpf et al., 2021).
A consistent finding that emerged out of these
studies is that better LMs are also more predictive
models of comprehension difficulty, or in other
palabras, there is a negative correlation between
LM perplexity and fit to human reading times.
Goodkind and Bicknell (2018) compared surprisal
1All code used in this work is available at: https://
github.com/byungdoh/llm surprisal.
estimates from a set of n-gram and LSTM LMs
and observed a negative linear relationship be-
tween perplexity and regression model fit. Wilcox
et al. (2020) evaluated n-gram, LSTM, Trans-
anterior, and RNNG (Dyer et al., 2016) models and
replicated the negative relationship, although they
note a more exponential relationship at certain in-
tervals. Merkx and Frank (2021) provided further
support for this trend using GRU and Transformer
models with different numbers of layers.2
Sin embargo, Oh et al. (2022) observed a di-
rectly contradictory relationship to this using sur-
prisal estimates from pre-trained GPT-2 models
(Radford et al., 2019). Using self-paced reading
times from the Natural Stories Corpus (Futrell
et al., 2021) and go-past durations from the
Dundee corpus (Kennedy et al., 2003), the authors
calculated the increase in log-likelihood (ΔLL) a
a baseline linear-mixed effects (LME) model due
to including a surprisal predictor. Their results
showed that surprisal from the largest XL vari-
ant made the smallest contribution to regression
model fit, followed by the smaller Large, Medium,
and Small variants in that order, revealing a ro-
bust positive correlation between LM perplexity
and predictive power of surprisal estimates. El
same trend was replicated when unigram surprisal
was included in the baseline, as well as when
spillover effects were controlled for through the
use of continuous-time deconvolutional regression
(CDR; Shain and Schuler, 2021).
Además, recent work has shown that surprisal
from neural LMs generally tends to under-
predict human reading times of both targeted
constructions and naturalistic text. Por ejemplo,
van Schijndel and Linzen (2021) and Arehalli
et al. (2022) observed that surprisal from neu-
ral LMs severely underpredicts the magnitude of
garden-path effects demonstrated by human sub-
jects. Además, Hahn et al. (2022) showed that
surprisal from the pre-trained GPT-2 model fails
to accurately predict the increase in reading times
at the main verb of deeply embedded sentences.
Kuribayashi et al. (2022) also demonstrated that
neural LMs yield surprisal estimates that under-
predict naturalistic reading times of English and
Japanese text compared to those from neural LMs
2Although counterexamples to this trend have been noted,
they were based on comparisons of LMs and incremental
parsers that were trained on different data (Oh et al., 2021)
or evaluation on Japanese, which has a different syntactic
head-directionality than English (Kuribayashi et al., 2021).
337
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
that have a recency bias implemented as limited
access to the previous context.
3 Main Experiment: Predictive Power of
Language Model Surprisal Estimates
In order to examine whether the positive corre-
lation observed by Oh et al. (2022) y otros
generalizes to larger Transformer-based models,
surprisal predictors from different variants of the
GPT-2, GPT-Neo, and OPT LMs were evalu-
ated on self-paced reading times from the Natural
Stories Corpus (Futrell et al., 2021) and go-past
eye-gaze durations from the Dundee Corpus
(Kennedy et al., 2003).
3.1 Response Data
The Natural Stories Corpus contains data from
181 subjects who read 10 naturalistic English
stories that consist of a total of 10,245 tokens.
The reading times were filtered to remove ob-
servations for sentence-initial and sentence-final
palabras, observations from subjects who answered
three or fewer comprehension questions correctly,
and observations shorter than 100 ms or longer
than 3000 EM, which resulted in a total of 770,102
observaciones. The Dundee Corpus contains data
de 10 subjects who read 67 newspaper edito-
rials that consist a total of 51,501 tokens. El
durations were filtered to remove observations for
unfixated words, words following saccades longer
than four words, and words at sentence-, screen-,
document-, and line-starts and ends. This resulted
in a total of 195,507 observaciones.
Both datasets were subsequently partitioned
into an exploratory set and a held-out set of
roughly equivalent sizes.3 This partitioning allows
regression model selection (p.ej., making decisions
about random effects structure) and exploratory
analyses to be conducted on the exploratory set
and a single statistical significance test to be con-
ducted on the held-out set, thereby obviating the
need for multiple trials correction. This resulted in
an exploratory set of 384,905 observations and a
held-out set of 385,197 observations for the Natu-
ral Stories Corpus and an exploratory set of 98,115
observations and a held-out set of 97,392 obser-
vations for the Dundee Corpus. All observations
were log-transformed prior to model fitting.
3This partitioning was conducted based on the sum of sub-
ject ID and sentence ID, resulting in each subject-by-sentence
combination remaining intact in one partition.
#L #H dmodel
Modelo
GPT-2 Small
GPT-2 Medium
GPT-2 Large
GPT-2 XL
12
24
36
48
GPT-Neo 125M
12
GPT-Neo 1300M 24
GPT-Neo 2700M 32
28
GPT-J 6B
44
GPT-NeoX 20B
OPT 125M
OPT 350M
OPT 1.3B
OPT 2.7B
OPT 6.7B
OPT 13B
OPT 30B
OPT 66B
12
24
24
32
32
40
48
64
12
16
20
25
12
16
20
16
64
12
16
32
32
32
40
56
72
768
1024
1280
1600
Parameters
∼124M
∼355M
∼774M
∼1558M
∼125M
768
∼1300M
2048
∼2700M
2560
∼6000M
4096
6144 ∼20000M
∼125M
768
∼350M
1024
∼1300M
2048
∼2700M
2560
∼6700M
4096
5120 ∼13000M
7168 ∼30000M
9216 ∼66000M
Mesa 1: Model capacities of LM families whose
surprisal estimates were examined in this work.
#l, #h, and dmodel refers to number of layers,
number of attention heads per layer, and embed-
ding size, respectivamente.
3.2 Predictors
Surprisal estimates calculated from four differ-
ent variants of GPT-2 models (Radford et al.,
2019) were used in Oh et al. (2022). In ad-
dition to GPT-2 surprisal, this experiment also
evaluates surprisal estimates from five variants
of GPT-Neo models (Black et al., 2021, 2022;
Wang and Komatsuzaki, 2021)4 and eight vari-
ants of OPT models (Zhang et al., 2022).5 Todo
of these LMs are decoder-only autoregressive
Transformer-based models whose variants mainly
differ in their capacity. The model capacities of
the three LM families are summarized in Table 1.
Each story of the Natural Stories Corpus and
each article of the Dundee Corpus was tokenized
according to the three models’ respective byte-
pair encoding (BPE; Sennrich et al., 2016) tok-
enizer and was provided to each model variant
to calculate surprisal estimates. In cases where
4Technically, the two largest variants are GPT-J and
GPT-NeoX models, respectivamente, both of which have minor
architectural differences from the GPT-Neo models. Cómo-
alguna vez, given that they share the same training data, they were
considered to belong to the same family as the GPT-Neo
modelos.
5The largest variant of the OPT model, which has about
175 billion parameters, was not used in this work due to
constraints in computational resources.
338
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
each story or article did not fit into a single
context window for the LMs, the second half
of the previous context window served as the
first half of a new context window to calculate
surprisal estimates for the remaining tokens. En
práctica, most stories and articles fit completely
within two context windows for the GPT-2 mod-
els that have a context size of 1,024 tokens, y
within one context window for the GPT-Neo and
OPT models that have a context size of 2,048
tokens. Además, when a single word wt was
tokenized into multiple subword tokens, nega-
tive log probabilities of subword tokens corre-
sponding to wt were added together to calculate
S(peso) = − log P(peso | w1..t−1).
3.3 Regression Modeling
Después, following the methods of Oh et al.
(2022), a ‘baseline’ LME model that contains
baseline predictors capturing low-level cognitive
processing and seventeen ‘full’ LME models that
contain the baseline predictors and each LM sur-
prisal predictor were fit to the exploratory set of
self-paced reading times and go-past durations
using lme4 (Bates et al., 2015). The baseline pre-
dictors include word length measured in characters
and index of word position within each sentence
(both self-paced reading and eye-tracking), también
as saccade length and whether or not the previous
word was fixated (eye-tracking only).
All predictors were centered and scaled prior
to model fitting, and the LME models included
by-subject random slopes for all fixed effects as
well as random intercepts for each subject and
each word type. Además, for self-paced read-
ing times collected from 181 subjects, a random
intercept for each subject-sentence interaction was
incluido. For eye-gaze durations collected from
a much smaller number of 10 subjects, a random
intercept for each sentence was included.
After the regression models were fit, the ΔLL
values were first calculated for each regression
model by subtracting the log-likelihood of the
baseline model from that of a full regression
modelo. Además, to examine the trend between
LM perplexity and predictive power of surprisal
estimados, the perplexity of each LM variant was
calcuated on the two corpora.
3.4 Resultados
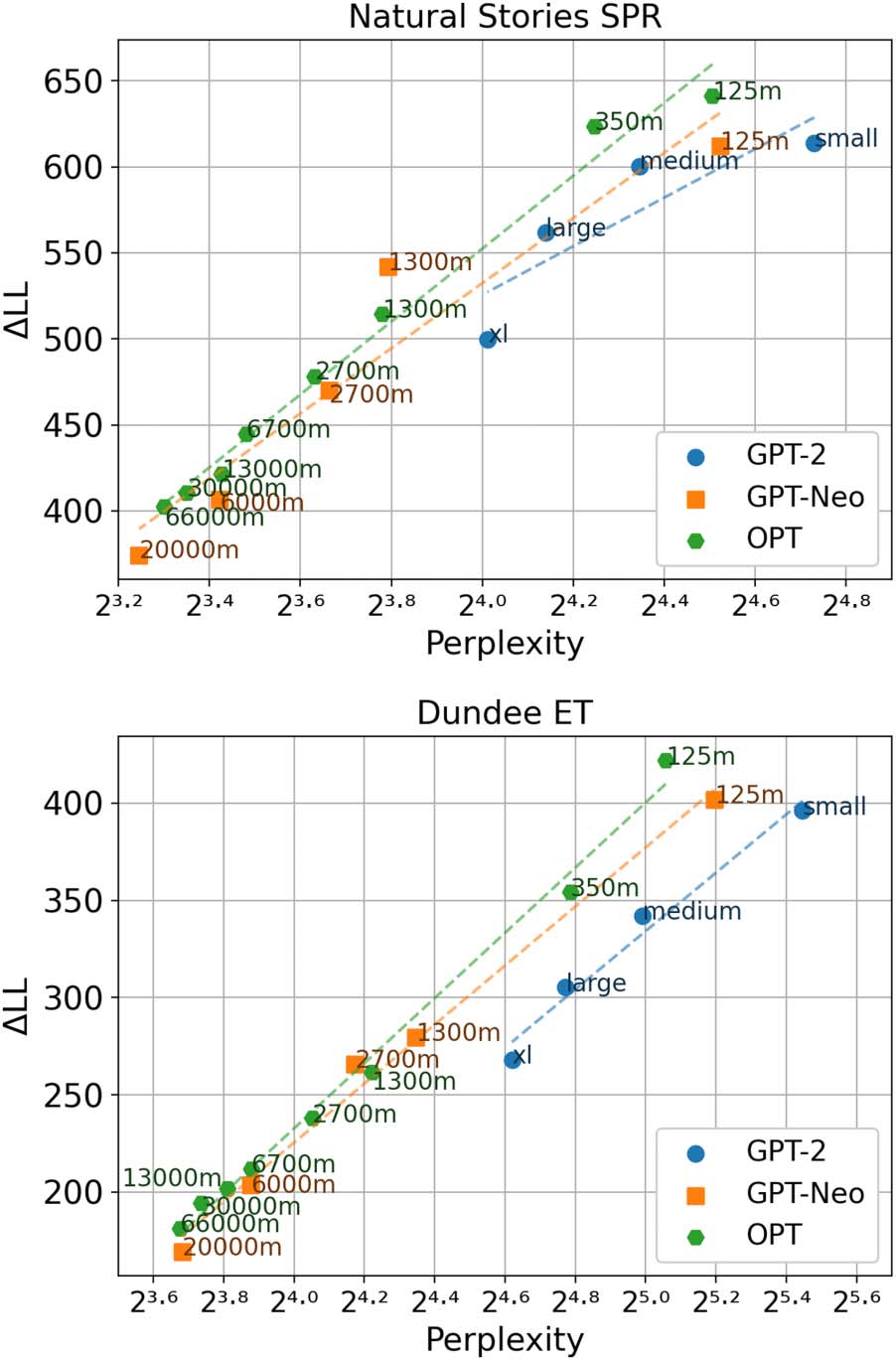
The results in Figure 1 show that surprisal from
the smallest variant (es decir., GPT-2 Small, GPT-Neo
Cifra 1: Perplexity measures from each LM variant,
and improvements in regression model log-likelihood
from including each surprisal estimate on the ex-
ploratory set of Natural Stories (arriba) and Dundee data
(abajo). Dotted lines indicate the least-squares re-
gression line for each LM family.
125METRO, and OPT 125M) made the biggest contri-
bution to regression model fit on both self-paced
reading times and eye-gaze durations for the
three LM families. More notably, surprisal esti-
mates from larger LM variants within each family
yielded strictly poorer fits to reading times, ro-
bustly replicating the trend observed by Oh et al.
(2022). Curiosamente, the three LM families also
seem to demonstrate a strong log-linear relation-
ship between perplexity and ΔLL, as can be seen
by the least-squares regression lines. All regres-
sion lines had a slope significantly greater than 0
at p < 0.05 level according to a one-tailed t-test,
with the exception of the regression line for GPT-2
on Natural Stories (p = 0.07). This trend is highly
significant overall by a binomial test (five results
with p < 0.05 out of six trials), and directly con-
tradicts the findings of recent studies that report a
negative correlation between LM perplexity and
predictive power of surprisal estimates.
339
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
l
a
c
_
a
_
0
0
5
4
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Additionally, comparison of the GPT-2 mod-
els and OPT models of similar model capacities
(i.e., Small-125M, Medium-350M) shows that the
OPT models generally both achieve lower per-
plexity and yield surprisal estimates that are more
predictive of human reading times. Given the high
similarity in model architecture between the two
LMs, this trend seems to be due to the difference
in the training data that were used. The most no-
table difference between the two training datasets
is in their size, with the training set for GPT-2 es-
timated to be about 15B tokens and that for OPT
estimated to be about 180B tokens (Thompson,
2022). However, the GPT-Neo models trained on
about 247B tokens show no improvement over
the OPT models, yielding a mixed picture. These
results suggest that beyond a certain level, the
quantity of training data may play a secondary role
to the number of model parameters in capturing
humanlike expectations.
4 Post-hoc Analysis: Linguistic
Phenomena Underlying the Trend
In order to provide an explanation for the trend
observed in Section 3, the residual errors from the
regression models were analyzed to identify data
points that surprisal from larger LM variants ac-
counted for less accurately compared to surprisal
from their smaller counterparts. For this analy-
sis, a special emphasis was placed on identifying
subsets of data points where surprisal from larger
LM variants deviated more drastically from hu-
manlike processing difficulty.
4.1 Calculation of Residual Errors
The seventeen LME models that contain each
of
the LM surprisal predictors described in
Section 3.3 were used to generate predictions
for all data points in the exploratory set of both
self-paced reading times and go-past durations.6
Subsequently,
the predictions were subtracted
from the target values to calculate the residual
errors for each of the seventeen regression models.
However, a preliminary analysis of the LME
models fitted to the Dundee Corpus revealed a
discrepancy between model likelihood and mean
squared error (MSE), where the regression models
with higher likelihoods achieved similar MSEs to
those with lower likelihoods. This is because the
6The post-hoc analysis focused on the exploratory set, as
the held-out set is reserved for statistical significance testing.
lme4 package (Bates et al., 2015) minimizes the
penalized residual sum-of-squares, which includes
a Euclidean norm penalty on the spherical com-
ponent of the random effects variables. In other
words, an LME model can achieve higher likeli-
hood than another if it can achieve similar MSE
using less expressive random effects variables that
have lower variance.
An inspection of the fitted random effects vari-
ables revealed that the by-word intercept was
mostly responsible for the discrepancy between
likelihood and MSE for the LME models fitted to
the Dundee Corpus. More specifically, the LME
models with surprisal estimates from larger LM
variants had systematically higher variance for the
by-word intercept, which allowed them to achieve
similar MSEs at the cost of an increased penalty
for the random effects variables. In order to control
for this confound and bring model likelihood and
MSE closer together, the seventeen LME models
were fitted again to both corpora with the by-word
random intercepts removed. Since the goal of this
analysis was to identify data points that are re-
sponsible for the positive correlation between LM
perplexity and fit to human reading times, it was
thought that removing the by-word random in-
tercepts would also yield a clearer picture with
regard to words on which the surprisal estimates
from larger LMs fall especially short.
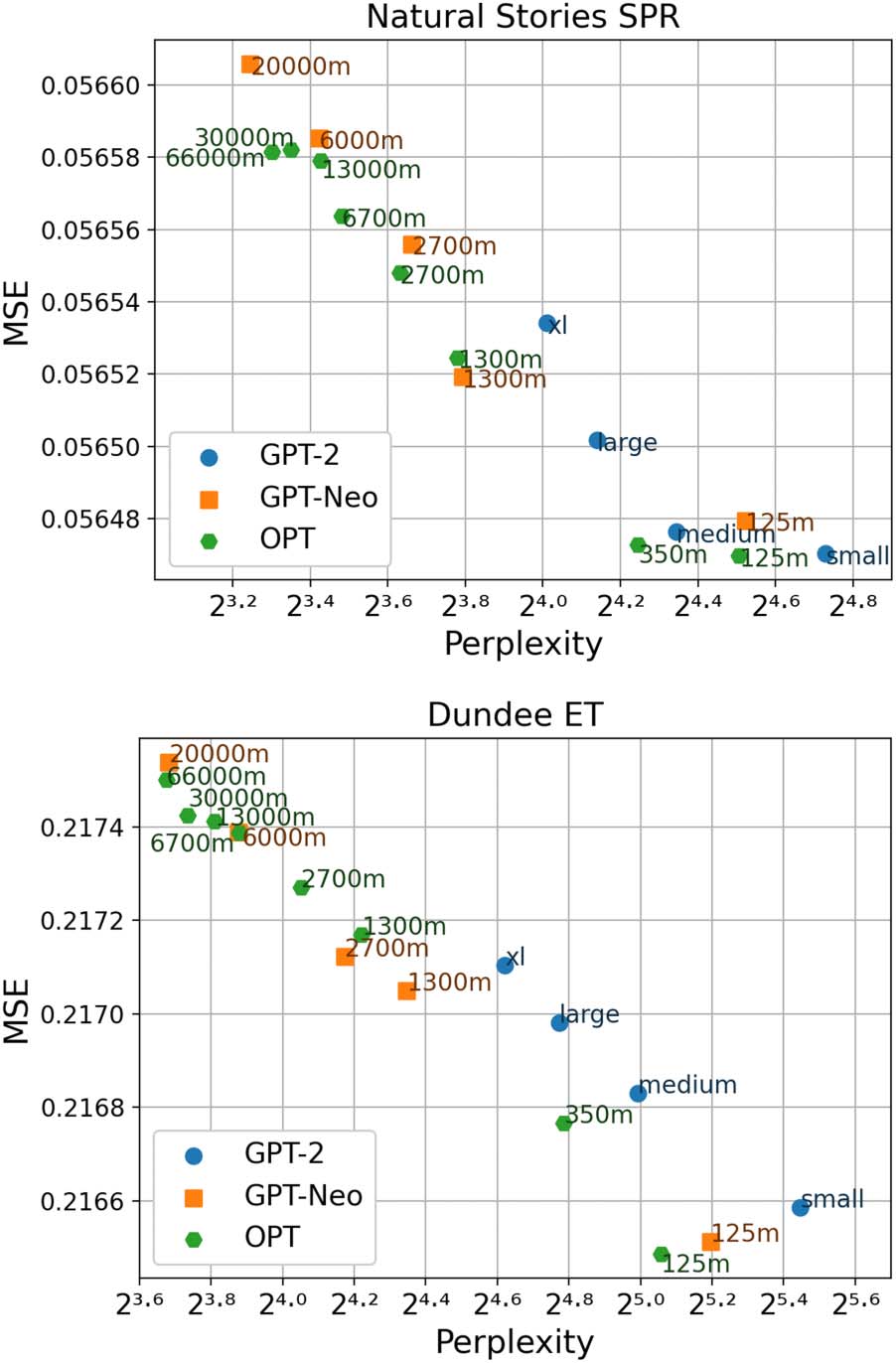
The MSEs plotted in Figure 2, which generally
replicate the inverse trend of ΔLLs in Figure 1,
show that the removal of by-word random in-
tercepts brought model
likelihoods and MSEs
closer. The residual errors from these newly fitted
regression models were subsequently analyzed.
4.2 Annotation of Data Points
In order to guide the identification of linguis-
tic phenomena underlying the trend observed in
Section 3.4, each data point in both corpora was
associated with various word- and sentence-level
properties that are thought to influence real-time
processing. These properties were derived from
the manually annotated syntactic tree structures of
both corpora from Shain et al. (2018).
Word-level properties reflect characteristics of
the word that generally hold regardless of the
surrounding context:
• Part-of-speech: the syntactic category of each
word from a generalized categorial grammar
annotation scheme (Nguyen et al., 2012; Shain
340
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
l
a
c
_
a
_
0
0
5
4
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
• Dependency Locality Theory (DLT; Gibson,
2000) cost: DLT posits that the construction of
backward-looking dependencies between words
(e.g., between a verb and its subject) incurs an
‘integration’ cost driven by memory retrieval
operations. This cost is thought to be propor-
tional to the length of the dependency in terms
of the number of intervening discourse refer-
ents, which are operationalized as any noun or
finite verb in this work.
structures
from a series of
• Left-corner parsing (Johnson-Laird, 1983):
incrementally derives
A left-corner parser
lexi-
phrasal
cal match and grammatical match decisions
at every word.8 These two decisions allow
center-embedded constituents to be distin-
guished from non-embedded constituents. Ad-
ditionally,
the grammatical decision results
in expectations about the upcoming syntactic
category, which allows words before com-
plete constituents (e.g., words before sentential
clauses) to be identified.
Figure 2: Perplexity measures from each LM variant,
and mean squared errors of regression models that
include each surprisal estimate on the exploratory set
of Natural Stories (top) and Dundee data (bottom). Note
that the larger values of MSE correspond to smaller
values of log-likelihood in Figure 1.
et al., 2018). As these categories are defined
in terms of primitive types (e.g., verbs and
nouns) and type-combining operators (e.g., un-
satisfied preceding and succeeding arguments),
they make more fine-grained distinctions in
terms of linguistic subcategorization.
• Named entities: a binary variable for whether
or not the word is part of a proper name. Since
words at the beginning of sentences were ex-
cluded from regression modeling, capitalization
reliably identified such named entities.7
Sentence-level properties capture the syntac-
tic structure of sentences, either in terms of de-
pendencies or hierarchical phrases:
7Words like the pronoun I and names of fictional char-
acters that appeared in the Natural Stories Corpus were
manually excluded afterwards.
341
This annotation allowed the data points in
each corpus to be subsetted, which subsequently
helped identify where surprisal from the larger
LM variants deviated further from humanlike
processing.
4.3 Iterative Slope-Based Analysis of
Residual Errors
Subsequently, based on the properties annotated
in Section 4.2, subsets of data points that strongly
drive the trend in Figure 2 were identified. To this
end, the linear relationship between log perplexity
and MSEs was used; subsets of data points that
drive the general trend should show larger differ-
ences in MSE between regression models, or in
other words, have negative slopes that are steeper
than the corpus-level slope.
Based on this idea, for every corpus-LM combi-
nation (i.e., {Natural Stories, Dundee} × {GPT-2,
GPT-Neo, OPT}), a least-squares regression line
was fitted between corpus-level log perplexity and
MSEs of each subset defined by the properties out-
lined in Section 4.2. Subsequently, the subset with
the steepest negative slope was identified. After
excluding the identified subset, the above proce-
dure was repeated to identify a new subset that
showed the next strongest effect. For this analysis,
8See, e.g., Oh et al. (2022) for a more detailed definition
of left-corner parsing models.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
l
a
c
_
a
_
0
0
5
4
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
l
a
c
_
a
_
0
0
5
4
8
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
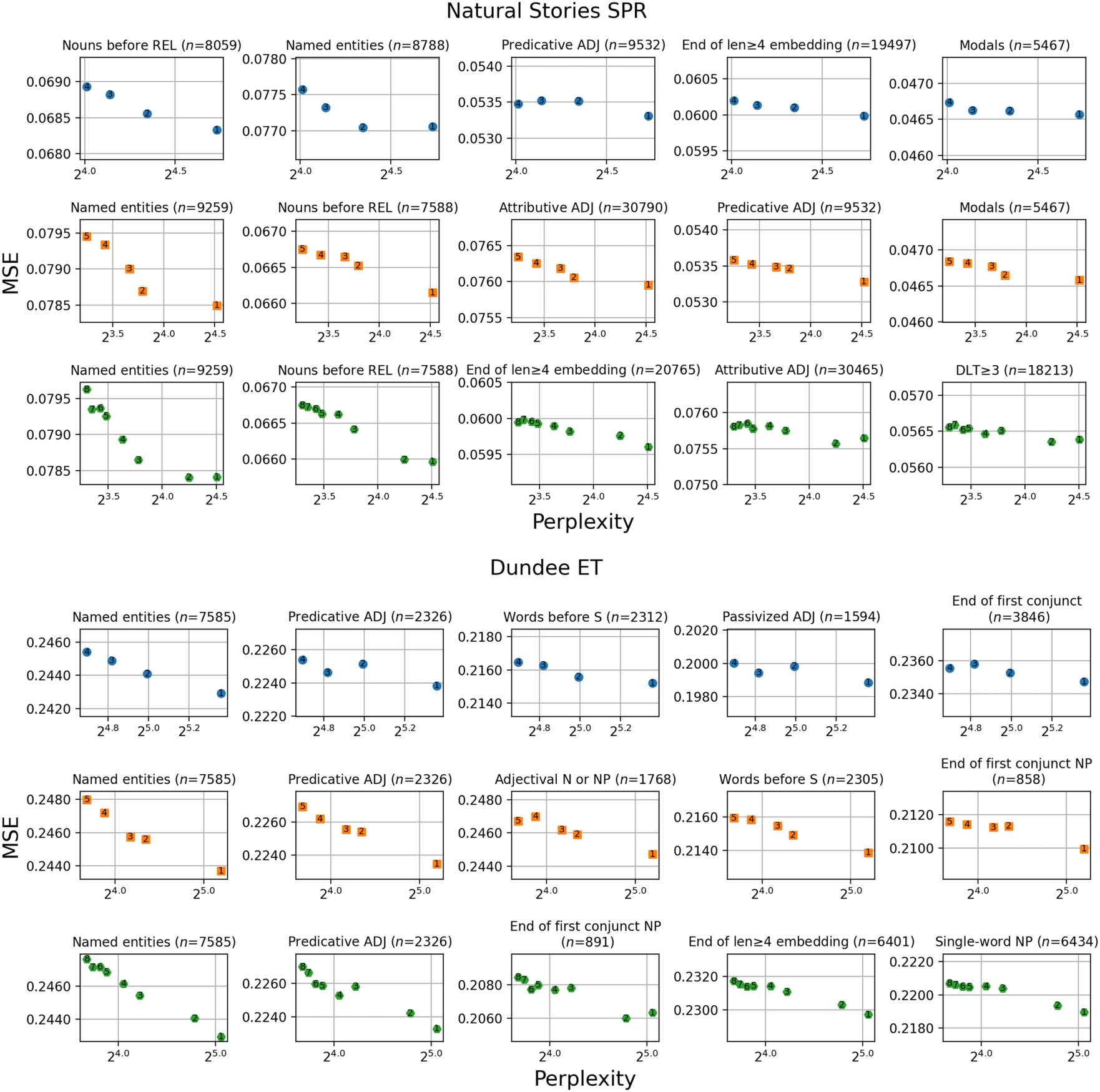
Figure 3: Corpus-level perplexity measures from each GPT-2, GPT-Neo, and OPT model variant (top, middle,
and bottom rows, respectively), and mean squared errors of regression models that include each surprisal estimate
on the top five subsets (columns ordered from left to right) of Natural Stories self-paced reading data (top panel)
and Dundee eye-tracking data (bottom panel). The ordered labels represent LM variants of different sizes, with ‘1’
representing the smallest variant. ADJ: adjective, N: noun, NP: noun phrase, REL: relativizer, S: sentential clause.
only subsets that contained more than 1% of the
data points in each corpus were considered at each
iteration.9
Additionally, once the subsets of interest were
identified, the data points in each subset were
further separated according to whether the regres-
sion model underpredicted or overpredicted the
target reading times. In order to identify whether
the trend of MSEs is driven primarily by system-
atic underprediction or overprediction of reading
times, the average surprisal from each LM variant
and the sum of squared errors (SSE) were calcu-
lated for each subset. SSEs instead of MSEs were
analyzed because different regression models had
different numbers of underpredicted vs. overpre-
dicted data points, and because points close to 0
can distort the MSEs and obscure the overall trend
of mispredictions.
9This criterion amounts to >3,849 data points for Natural
Stories and >981 data points for Dundee at the first iteration.
Although this may seem like a lenient criterion, this was
necessary to examine phenomena that lie at the long tail of
the Zipfian distribution of word frequencies.
4.4 Resultados
The results in Figure 3 show that on each cor-
pus, similar subsets were identified as driving the
trend of MSEs across different LM families. On
342
the Natural Stories Corpus, these subsets were
primarily determined by the word’s syntactic cat-
egoría, such as named entity nouns, nouns before
relativizers, attributive and predicative adjectives,
and modals. The top subsets of the Dundee Corpus
were similarly determined by syntactic category,
such as named entity nouns, predicative and pas-
sivized adjectives, and single-word noun phrases
(p.ej., pronouns). Subsets defined by the syntac-
tic structure of sentences were less commonly
identified from the Natural Stories Corpus, con
ends of center-embedded constituents spanning
four or more words and words with high DLT
costs emerging. From the Dundee Corpus, ends of
center-embedded constituents, ends of first con-
junct constituents (both overall and noun phrases
específicamente), and beginnings of adjectival noun
phrases (p.ej., family in a family size pack) eran
identificado. Además, words preceding a sen-
tential clause were identified, which corresponded
to conjunctions and ends of adjuncts. On most of
these subsets, the MSEs of each regression model
were higher than those on the entire corpus, cual
indicates that the misprediction of reading times
that pre-trained LM surprisal already has diffi-
culty modeling is exacerbated as the models get
más grande. Subsets such as modals of Natural Sto-
ries and first conjunct NP endings of Dundee are
counterexamples to this general trend.
The average surprisal values10 and SSEs from
underpredicted and overpredicted data points in
Cifra 4 shed more light on the direction and
magnitude of mispredictions from each regres-
sion model. Por ejemplo, on the subset of named
entidades, which emerged as the top two subsets
across all corpus-by-LM combinations, the larger
LM variants show systematically higher SSEs
due to underprediction. This strong discrepancy
highlights a mismatch between human sentence
processing and language modeling; named entity
terms (p.ej., Elvis Presley) have been shown to in-
cur increased processing times compared to their
common noun counterparts (p.ej., a singer) pendiente
to various semantic associations that are retrieved
(Proverbio et al., 2001; Wang y cols., 2013). En
contrast, for language models, named entity terms
that typically consist of multiple tokens have high
10Since perplexity is equivalent to exponentiated average
surprisal, the average surprisal values for each subset are
roughly comparable to LM perplexity of, p.ej., Cifra 2.
Sin embargo, caution is warranted as these values are calculated
over data points of reading times instead of tokens.
mutual information, making it easy for them to ac-
curately predict subsequent tokens given the first
(p.ej., Presley given Elvis), resulting in especially
lower surprisal estimates for larger LM variants.
Similarmente, across the two corpora and three
LM families, the trend of MSEs for other nouns as
well as adjectives appears to be consistently driven
by more severe underpredictions from regression
models containing surprisal estimates from larger
LM variants. On these subsets, the difference in
average surprisal values between the smallest and
largest LM variants was typically above 2 bits,
which is larger than the difference in log perplex-
idad (es decir., corpus-level average surprisal, Cifra 2)
between these variants. This indicates that these
subsets represent words that the larger LM vari-
ants predict especially accurately, which results in
low surprisal estimates that deviate from human
reading times.
A diferencia de, the subset of modals on the Natu-
ral Stories Corpus identified for the GPT-2 and
GPT-Neo models shows a completely opposite
trend in which more severe overpredictions drive
the overall trend of MSEs. This seems to be
more due to the difference in the estimated re-
gression coefficients rather than the difference in
the LM surprisal estimates themselves. The av-
erage surprisal values on this subset show that
the difference between their smallest and largest
variants is less than 1 bit, lo que indica que
the LM variants are making more similar pre-
dictions about modals. Sin embargo, since surprisal
predictors from larger LM variants are gener-
ally smaller in magnitude, the regression models
assign them higher coefficients in order to predict
reading times, resulting in a systematic over-
prediction given surprisal predictors of similar
valores. This also explains the trend observed for
words preceding a sentential clause on the Dundee
Cuerpo, which mainly consisted of conjunctions.
Finalmente, while they were less common, subsets
based on syntactic complexity were also iden-
tified as driving the differential fit to reading
veces. On the Natural Stories Corpus, a systematic
underprediction of regression models with OPT
surprisal was observed on words with a DLT cost
of greater than or equal to three. These words
mainly consist of nouns and finite verbs that com-
plete long-distance dependencies. While finite
verbs in general were not identified as subsets
that showed a strong effect, it is likely that the in-
creased reading times caused by the construction
343
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4: Average surprisal from each GPT-2, GPT-Neo, and OPT model variant, and sum of squared errors of
regression models that include each surprisal estimate on the top five subsets of Natural Stories self-paced reading
data and Dundee eye-tracking data. The top and bottom subplots of each row represent values from underpredicted
and overpredicted data points, respectivamente.
of long-distance dependencies made the underpre-
dictions more salient. Ends of center-embedded
constituents of length greater than or equal to four
were also identified, which typically corresponded
to nouns and adjectives. On the Natural Stories
Cuerpo, the trend of more severe underpredictions
driving the effect is consistent with other noun
and adjective subsets. Sin embargo, on the Dundee
Cuerpo, overpredictions seem to be responsible
for the overall trend in this subset, which may hint
at subtle differences in how syntactic complex-
ity is manifested in self-paced reading times and
eye-gaze durations.
Tomados juntos, these results indicate that the
poorer fit to human reading times achieved by sur-
prisal estimates from larger Transformer-based
language models is primarily driven by their
characteristic of assigning lower surprisal values
to open-class words like nouns and adjectives,
which may be accurately predicted by extensive
domain knowledge gleaned from large sets of
training examples that are not available to hu-
mans. En otras palabras, the extra parameters of the
larger LM variants may be improving predictions
of such words in a way that is beyond human
capacidad.
344
5 Discusión y conclusión
This work presents results using multiple large
pre-trained LMs showing that larger variants with
more parameters and better next-word prediction
actuación (es decir., lower perplexity) nonetheless
yield surprisal estimates that are less predictive of
human reading times (es decir., smaller contribution to
regression model fit), corroborating and expand-
ing upon earlier results based on the GPT-2 LM
(Oh et al., 2022).
Primero, in order to examine the generalizability
of this trend, surprisal estimates from five vari-
ants of the GPT-Neo LM and eight variants of
the OPT LM were evaluated in terms of their
ability to predict self-paced reading times and
eye-gaze durations. The regression analysis re-
vealed a strictly monotonic, positive log-linear
relationship between perplexity and fit to read-
ing times for five GPT-Neo variants and eight
OPT variants, providing robust empirical sup-
port for this trend. Además, the different data
used to train each LM family seem to influence
the quality of surprisal estimates, although more
pre-training data did not necessarily result in sur-
prisal estimates that are more predictive of reading
veces.
Después, to identify the data points that
are responsible for the positive relationship, a
post-hoc analysis of the residual errors from
each regression model was conducted. The re-
sults showed that the difference in MSEs between
regression models containing surprisal predictors
from different LM variants was especially large
on nouns and adjectives, such as named entity
terms and predicative adjectives. A further in-
spection of their predictions showed that the trend
of MSEs on these words was driven mainly by
underpredictions of reading time delays, cual
were exacerbated as the larger LM variants pre-
dicted the words more accurately and assigned
lower surprisal values. This tendency also led to
higher regression coefficients for surprisal esti-
mates from larger LM variants, which resulted in
a systematic overprediction at function words like
conjunctions and modals that had similar surprisal
estimates across LM variants.
The ‘more and more superhuman’ predictions
of larger LM variants observed in this work are
consistent with findings from recent analyses of
Transformer-based LMs. Por ejemplo, a mathe-
matical analysis of Transformers (Elhage et al.,
2021) showed that a layer of self-attention essen-
tially functions as a lookup table that keeps track
of bigram statistics of the input data. Given this
observación, it may be the case that the larger
LM variants with more attention heads at their
disposal have the capability to learn stronger lo-
cal associations between tokens. This possibility
was empirically supported from the perspective
of memorization by Carlini et al. (2022), OMS
found that larger variants of the GPT-Neo model
returned more sequences verbatim from the
pre-training data during greedy decoding. Este
behavior may explain why nouns and adjectives
showed the strongest effect in the post-hoc anal-
ysis; since adjectives and nouns typically have
higher type-frequency than verbs or function
palabras, it may be the case that nouns and adjectives
that are rarely seen during training are predicted
much more faithfully by the larger LM variants
with higher model capacity. Además, this also
suggests that as these pre-trained LMs continue
to get bigger, they will continue to degrade as
models of humanlike language comprehension.
The ‘trained-from-scratch’ LMs studied in
earlier psycholinguistic modeling work (p.ej.,
Goodkind and Bicknell, 2018; Wilcox et al., 2020)
show a negative relationship between perplexity
and fit to reading times. Sin embargo, based on re-
gression results following the same protocols as
Sección 3, surprisal estimates from LMs trained in
Wilcox et al. (2020) generally seem to be less pre-
dictive of human reading times than those from
pre-trained LMs examined in this work. Given
the especially large discrepancy in model size be-
tween newly trained LMs and pre-trained LMs,
it may be the case that they capture two distinct
regimes in terms of the relationship between LM
performance and predictive power of surprisal es-
timates. While the results of the current study
clearly show that surprisal estimates from smaller
pre-trained LM variants are more predictive of
reading times, it remains to be seen how much
smaller LMs can become before the predictive
power of surprisal estimates starts to decrease.
With recently increasing effort in developing ef-
ficient NLP models, future work could explore
the extent to which, Por ejemplo, knowledge dis-
tillation techniques (Sanh et al., 2019) can result
in LMs that are more predictive of humanlike
processing difficulty.
Además, the importance of being ‘ade-
quately surprised’ at nouns like named entity
345
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
terms that was identified in the current study may
also explain similar recent counterexamples to
the trend observed between model perplexity and
fit to reading times (Oh et al., 2021; Kuribayashi
et al., 2021). Oh et al. (2021) showed that in-
corporating a character model to estimate word
generation probabilities within an incremental
left-corner parser resulted in more predictive sur-
prisal estimates compared to those from a base-
line parser that treats words as symbols, a pesar de
at a cost of higher test perplexity. The character
model may be effectively assigning higher sur-
prisal values to these rare words, thereby achieving
better fit to human reading times. The reading
times of Japanese text studied in Kuribayashi
et al. (2021) were measured in larger units (es decir.,
bunsetsu; roughly equivalent to phrases) than typ-
ical English words. Por lo tanto, the Japanese LMs
analyzed in that study are likely to have been
trained on and have made predictions on text that
has been tokenized into ‘sub-bunsetsu’ tokens,
which may have made a different picture emerge
from results based on purely word-based LMs of
earlier work.
En general, the tendency of pre-trained LM
surprisal to underpredict reading times observed
in this work is consistent with recent empiri-
cal shortcomings of neural LM surprisal. Para
ejemplo, van Schijndel and Linzen (2021) y
Arehalli et al. (2022) found that surprisal from
neural LMs severely underpredicts the magnitude
of garden-path effects demonstrated by human
subjects. Similarmente, Hahn et al. (2022) presentado
that surprisal from GPT-2 fails to accurately pre-
dict the increase in reading times at the main
verb of deeply embedded sentences. Kuribayashi
et al. (2022) also demonstrated that implement-
ing a recency bias by deterministically truncat-
ing the context window of neural LMs leads to
surprisal estimates that alleviate the underpredic-
tions of full neural LM surprisal on naturalistic
reading times of English and Japanese text. Taken
together, these results suggest that neural LMs
do not make abstract, linguistic generalizations
like people do.
Además, there are also efforts to evaluate other
memory- and attention-based predictors calcu-
lated from Transformer-based LM representations
on their ability to predict human behavior. Para
instancia, Ryu and Lewis (2021) drew connec-
tions between the self-attention mechanism of
Transformers and cue-based retrieval models of
sentence comprehension (p.ej., Lewis et al., 2006).
Their proposed attention entropy, which quan-
tifies the diffuseness of attention weights over
previous tokens, was found to show profiles that
are consistent with similarity-based interference
observed during the processing of subject-verb
agreement. Oh and Schuler (2022) expanded upon
this idea and showed that the entropy of attention
weights at a given timestep as well as the shift in
attention weights across consecutive timesteps are
robust predictors of naturalistic reading times over
GPT-2 surprisal. Hollenstein and Beinborn (2021)
calculated the norm of the gradient of each input
token on two eye-tracking corpora using BERT
(Devlin et al., 2019) as a metric of saliency, cual
showed higher correlations to fixation durations
compared to raw attention weights.
Finalmente, it is becoming more common in psy-
cholinguistic modeling to use surprisal
de
pre-trained LMs as a baseline predictor to study
various effects in naturalistic sentence processing
(p.ej., Ryu and Lewis, 2022; Clark and Schuler,
2022). The broader implication of the current study
is that researchers should not select the largest
pre-trained LM available based on the widely held
‘larger is better’ assumption of the NLP com-
munity. As a general practice, surprisal estimates
from smaller pre-trained LM variants should be
incorporated to form a more rigorous baseline,
which will guard against drawing unwarranted
scientific conclusions.
Expresiones de gratitud
We thank our TACL action editor and the review-
ers for their helpful comments. This work was
supported by the National Science Foundation
grant #1816891. All views expressed are those
of the authors and do not necessarily reflect the
views of the National Science Foundation.
Referencias
Suhas Arehalli, Brian Dillon, and Tal Linzen.
2022. Syntactic surprisal from neural models
predicts, but underestimates, human process-
ing difficulty from syntactic ambiguities.
En procedimientos de
the 26th Conference on
Computational Natural Language Learning,
pages 301–313.
Christoph Aurnhammer and Stefan L. Franco.
2019. Comparing gated and simple recurrent
346
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
neural network architectures as models of hu-
man sentence processing. En procedimientos de
the 41st Annual Meeting of
the Cognitive
Science Society, pages 112–118.
Douglas Bates, Martin M¨achler, Ben Bolker,
and Steve Walker. 2015. Fitting linear mixed-
effects models using lme4. Journal of Sta-
tistical Software, 67(1):1–48. https://doi
.org/10.18637/jss.v067.i01
Sid Black, Stella Biderman, Eric Hallahan,
Quentin Anthony, Leo Gao, Laurence Golding,
Horace He, Connor Leahy, Kyle McDonell,
Jason Phang, Michael Pieler, Usvsn Sai
Prashanth, Shivanshu Purohit, Laria Reynolds,
Jonathan Tow, Ben Wang,
and Samuel
Weinbach. 2022. GPT-NeoX-20B: An open-
source autoregressive language model. En profesional-
ceedings of BigScience Episode #5 – Workshop
on Challenges & Perspectives in Creating
Large Language Models, pages 95–136.
https://doi.org/10.18653/v1/2022
.bigscience-1.9
Sid Black, Leo Gao, Phil Wang, Connor
Leahy, and Stella Biderman. 2021. GPT-Neo:
Large scale autoregressive language modeling
with Mesh-Tensorflow. Zenodo. https://
doi.org/10.5281/zenodo.5297715
Nicholas Carlini, Daphne Ippolito, Matthew
Jagielski, Katherine Lee, Florian Tramer, y
Chiyuan Zhang. 2022. Quantifying memori-
zation across neural language models. arXiv
preprint, arXiv:2202.07646v2. https://doi
.org/10.48550/arXiv.2202.07646
Kyunghyun Cho, Bart van Merri¨enboer, Caglar
Gulcehre, Dzmitry Bahdanau, Fethi Bougares,
Holger Schwenk, and Yoshua Bengio. 2014.
Learning phrase representations using RNN
encoder–decoder for statistical machine trans-
lación. En Actas de la 2014 Conferencia
sobre métodos empíricos en lenguaje natural
Procesando, pages 1724–1734. https://doi
.org/10.3115/v1/D14-1179
Christian Clark and William Schuler. 2022. Ev-
idence for composition operations in broad-
coverage sentence processing. In 35th Annual
Conference on Human Sentence Processing.
Vera Demberg and Frank Keller. 2008. Datos
from eye-tracking corpora as evidence for the-
ories of syntactic processing complexity. Cog-
nition, 109(2):193–210. https://doi.org/10
.1016/j.cognition.2008.07.008, PubMed:
18930455
Jacob Devlin, Ming-Wei Chang, Kenton Lee, y
Kristina Toutanova. 2019. BERT: Pre-entrenamiento
of deep bidirectional Transformers for lan-
guage understanding. En Actas de la
2019 Conference of the North American Chap-
the Association for Computational
ter of
Lingüística: Tecnologías del lenguaje humano,
páginas 4171–4186. https://doi.org/10
.18653/v1/N19-1423
Chris Dyer, Adhiguna Kuncoro, Miguel
Ballesteros, y Noé A.. Herrero. 2016. Recur-
rent neural network grammars. En procedimientos
del 2016 Conference of the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
pages 199–209. https://doi.org/10.18653
/v1/N16-1024
Nelson Elhage, Neel Nanda, Catherine Olsson,
Tom Henighan, Nicolás José, hombre ben,
Amanda Askell, Yuntao Bai, Anna Chen,
Tom Conerly, Nova Das Sarma, Drenaje del amanecer,
Gangul profundo, Zac Hatfield-Dodds, danny
Hernández, Andy Jones, Jackson Kernion,
Liane Lovitt, Kamal Ndousse, Dario Amodei,
Tom Brown, Jack Clark, Jared Kaplan, Sam
McCandlish, y Chris Olah. 2021. A mathe-
matical framework for Transformer circuits.
Jeffrey L. elman. 1991. Distributed representa-
ciones, simple recurrent networks, and grammat-
ical structure. Machine Learning, 7:195–225.
https://doi.org/10.1007/978-1-4615
-4008-3 5
Richard Futrell, Edward Gibson, Harry J. Teja,
Idan Blank, Anastasia Vishnevetsky, Steven
Piantadosi, and Evelina Fedorenko. 2021. El
Natural Stories corpus: A reading-time cor-
pus of English texts containing rare syntactic
constructions. Language Resources and Evalu-
ación, 55(1):63–77. https://doi.org/10
.1007/s10579-020-09503-7, PubMed:
34720781
Edward Gibson. 2000. The Dependency Locality
Teoría: A distance-based theory of linguistic
complejidad. In Image, Idioma, Cerebro: Pa-
pers from the First Mind Articulation Project
Symposium, pages 95–126, Cambridge, MAMÁ.
CON prensa.
347
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Adam Goodkind and Klinton Bicknell. 2018. Pre-
dictive power of word surprisal for reading
times is a linear function of language model
quality. In Proceedings of the 8th Workshop
on Cognitive Modeling and Computational
Lingüística, pages 10–18. https://doi.org
/10.18653/v1/W18-0102
Michael Hahn, Richard Futrell, Edward Gibson,
and Roger P. Exacción. 2022. A resource-rational
model of human processing of recursive lin-
guistic structure. Actas del Nacional
Academia de Ciencias, 119(43):e2122602119.
https://doi.org/10.1073/pnas.2122602119,
PubMed: 36260742
John Hale. 2001. A probabilistic Earley parser
as a psycholinguistic model. En procedimientos de
the Second Meeting of the North American
Chapter of
la Asociación de Computación-
tional Linguistics on Language Technologies,
pages 1–8. https://doi.org/10.3115
/1073336.1073357
John Hale, Chris Dyer, Adhiguna Kuncoro, y
Jonathan Brennan. 2018. Finding syntax in hu-
man encephalography with beam search. En
Proceedings of the 56th Annual Meeting of
la Asociación de Lingüística Computacional,
pages 2727–2736. https://doi.org/10
.18653/v1/P18-1254
Yiding Hao,
Simon Mendelsohn, Rachel
Sterneck, Randi Martinez, y robert frank.
2020. Probabilistic predictions of people pe-
rusing: Evaluating metrics of language model
performance for psycholinguistic modeling. En
Actas de
the Workshop on Cogni-
tive Modeling and Computational Linguistics,
pages 75–86. https://doi.org/10.18653
/v1/2020.cmcl-1.10
Sepp Hochreiter y Jürgen Schmidhuber. 1997.
Memoria larga a corto plazo. Neural Compu-
tation, 9(8):1735–1780. https://doi.org
/10.1162/neco.1997.9.8.1735, PubMed:
9377276
141–150. https://doi.org/10
paginas
.18653/v1/2021.acl-short.19
Philip N. Johnson-Laird. 1983. Mental Models:
Towards a Cognitive Science of Language,
Inference, and Consciousness. Harvard Uni-
versity Press, Cambridge, MAMÁ.
Alan Kennedy, Robin Hill, and Jo¨el Pynte. 2003.
The Dundee Corpus. En Actas de la
12th European Conference on Eye Movement.
Tatsuki Kuribayashi, Yohei Oseki, Ana Brassard,
and Kentaro Inui. 2022. Context limitations
make neural language models more human-
como. En Actas de la 2022 Conferencia
sobre métodos empíricos en lenguaje natural
Procesando.
Tatsuki Kuribayashi, Yohei Oseki, Takumi Ito,
Ryo Yoshida, Masayuki Asahara, and Kentaro
Inui. 2021. Lower perplexity is not always
human-like. In Proceedings of the 59th Annual
Meeting of the Association for Computational
Linguistics and the 11th International Joint
Conferencia sobre procesamiento del lenguaje natural,
pages 5203–5217. https://doi.org/10
.18653/v1/2021.acl-long.405
Roger Levy. 2008. Expectation-based syntactic
comprensión. Cognición, 106(3):1126–1177.
https://doi.org/10.1016/j.cognition
.2007.05.006, PubMed: 17662975
Richard L.. Luis, Shravan Vasishth,
y
Julie A. Van Dyke. 2006. computacional
principles of working memory in sentence
comprensión. Trends in Cognitive Science,
10(10):447–454. https://doi.org/10.1016
/j.tics.2006.08.007, PubMed: 16949330
Danny Merkx and Stefan L. Franco. 2021.
Human sentence processing: Recurrence or at-
tention? In Proceedings of the Workshop on
Cognitive Modeling and Computational Lin-
guísticos, pages 12–22. https://doi.org
/10.18653/v1/2021.cmcl-1.2
Nora Hollenstein and Lisa Beinborn. 2021.
Relative importance in sentence processing.
En procedimientos de
the 59th Annual Meet-
the Association for Computational
ing of
Linguistics and the 11th International Joint
Conferencia sobre procesamiento del lenguaje natural,
Luan Nguyen, Marten van Schijndel,
y
William Schuler. 2012. Accurate unbounded
dependency recovery using generalized cate-
gorial grammars. In Proceedings of the 24th
International Conference on Computational
Lingüística, pages 2125–2140.
348
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Byung-Doh Oh, Christian Clark, and William
Schuler. 2021. Surprisal estimators for human
reading times need character models. En profesional-
ceedings of the 59th Annual Meeting of the
Association for Computational Linguistics and
the 11th International Joint Conference on Nat-
ural Language Processing, pages 3746–3757.
Byung-Doh Oh, Christian Clark, and William
Schuler. 2022. Comparison of structural pars-
ers and neural language models as surprisal
estimators. Fronteras de la inteligencia artificial,
5:777963. https://doi.org/10.3389/frai
.2022.777963, PubMed: 35310956
Byung-Doh Oh and William Schuler. 2022.
Entropy- and distance-based predictors from
GPT-2 attention patterns predict reading times
over and above GPT-2 surprisal. En curso-
cosas de
el 2022 Conferencia sobre Empirismo
Métodos en el procesamiento del lenguaje natural,
pages 9324–9334.
Alice Mado Proverbio, Stefania Lilli, carlo
Semenza, and Alberto Zani. 2001. ERP indexes
of functional differences in brain activation
during proper and common names retrieval.
Neuropsicología, 39(8):815–827. https://
doi.org/10.1016/S0028-3932(01)00003-3,
PubMed: 11369405
Alec Radford, Jeff Wu, niño rewon, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI Technical Report.
Soo Hyun Ryu and Richard L. Luis. 2021. C.A-
counting for agreement phenomena in sentence
comprehension with Transformer
idioma
modelos: Effects of similarity-based interfer-
ence on surprisal and attention. En curso-
ings of the Workshop on Cognitive Modeling
and Computational Linguistics, pages 61–71.
https://doi.org/10.18653/v1/2021
.cmcl-1.6
Soo Hyun Ryu and Richard L. Luis. 2022. Usando
Transformer language model to integrate sur-
prisal, entropy, and working memory retrieval
accounts of sentence processing. In 35th Annual
Conference on Human Sentence Processing.
version of BERT: Menor, faster, cheaper and
lighter. In NeurIPS EMCˆ2 Workshop.
Marten van Schijndel and Tal Linzen. 2021.
Single-stage prediction models do not explain
the magnitude of syntactic disambiguation
difficulty. Ciencia cognitiva, 45(6):e12988.
https://doi.org/10.1111/cogs.12988,
PubMed: 34170031
Martin Schrimpf,
Idan Asher Blank, Greta
Tuckute, Carina Kauf, Eghbal A. Hosseini,
Nancy Kanwisher, Joshua B. Tenenbaum,
and Evelina Fedorenko. 2021. The neural ar-
chitecture of language: Integrative modeling
converges on predictive processing. Proceed-
cosas de
the National Academy of Sciences,
118(45). https://doi.org/10.1073/pnas
.2105646118, PubMed: 34737231
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of rare
words with subword units. En procedimientos de
the 54th Annual Meeting of the Association for
Ligüística computacional, pages 1715–1725.
https://doi.org/10.18653/v1/P16
-1162
Cory Shain,
Idan Asher Blank, Marten van
and Evelina
Schijndel, William Schuler,
Fedorenko. 2020.
reveals language-
resonancia magnética funcional
specific predictive coding during naturalis-
tic sentence comprehension. Neuropsicología,
138:107307. https://doi.org/10.1016/j
.neuropsychologia.2019.107307, PubMed:
31874149
Cory Shain
and William Schuler.
2021.
Continuous-time deconvolutional
regression
for psycholinguistic modeling. Cognición,
215:104735. https://doi.org/10.1016/j
.cognition.2021.104735, PubMed: 34303182
Cory Shain, Marten van Schijndel, and William
Schuler. 2018. Deep syntactic annotations for
broad-coverage psycholinguistic modeling. En
Workshop on Linguistic and Neuro-Cognitive
Recursos.
Claude Elwood Shannon. 1948. A mathematical
theory of communication. Bell System Tech-
nical Journal, 27:379–423. https://doi.org
/10.1002/j.1538-7305.1948.tb01338.x
Víctor Sanh, Debut de Lysandre, Julien Chaumond,
and Thomas Wolf. 2019. DistilBERT, a distilled
Nathaniel J. Smith and Roger Levy. 2013.
The effect of word predictability on reading
349
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
time is logarithmic. Cognición, 128:302–319.
https://doi.org/10.1016/j.cognition
.2013.02.013, PubMed: 23747651
Alan D. Thompson. 2022. What’s in my AI?
A comprehensive analysis of datasets used to
train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B,
Megatron-11B, MT-NLG, and Gopher. Life-
Architect.ai Report.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Leon Jones, Aidan N.. Gómez,
lucas káiser, y Illia Polosukhin. 2017. En-
La atención es todo lo que necesitas.. En avances en neurología
Sistemas de procesamiento de información, volumen 30.
Ben Wang and Aran Komatsuzaki. 2021.
GPT-J-6B: A 6 billion parameter autoregres-
sive language model. https://github.com
/kingoflolz/mesh-transformer-jax
Lin Wang, Zude Zhu, Marcel Bastiaansen, Peter
Hagoort, and Yufang Yang. 2013. Recognizing
the emotional valence of names: An ERP
estudiar. Brain and Language, 125(1):118–127.
https://doi.org/10.1016/j.bandl
.2013.01.006, PubMed: 23467262
Ethan Gotlieb Wilcox, Jon Gauthier, Jennifer Hu,
Peng Qian, and Roger P. Exacción. 2020. Sobre el
predictive power of neural language models for
human real-time comprehension behavior. En
Proceedings of the 42nd Annual Meeting of the
Sociedad de ciencia cognitiva, pages 1707–1713.
Susan Zhang, Stephen Roller, Naman Goyal,
Mikel Artetxe, Moya Chen, Shuohui Chen,
Christopher Dewan, Mona Diab, Xian Li, Xi
Victoria Lin, Todor Mihaylov, Myle Ott, Sam
Schleifer, Kurt Shuster, Daniel Simig, Punit
Singh Koura, Anjali Sridhar, Tianlu Wang,
and Luke Zettlemoyer. 2022. OPT: Open pre-
trained Transformer language models. arXiv
preprint, arXiv:2205.01068v4. https://doi
.org/10.48550/arXiv.2205.01068
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
4
8
2
0
7
5
9
4
0
/
/
t
yo
a
C
_
a
_
0
0
5
4
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
350