Sobre el papel del precedente negativo en la predicción de resultados jurídicos
Josef Valvoda
Ryan Cotterell
Simone Teufel
University of Cambridge, Reino Unido
ETH Z¨urich, Suiza
{jv406,sht25}@cam.ac.uk
ryan.cotterell@inf.ethz.ch
Abstracto
Every legal case sets a precedent by develop-
ing the law in one of the following two ways.
It either expands its scope, in which case it sets
positive precedent, or it narrows it, en el cual
case it sets negative precedent. Legal outcome
predicción, the prediction of positive outcome,
is an increasingly popular task in AI. en contra-
contraste, we turn our focus to negative outcomes
aquí, and introduce a new task of negative
outcome prediction. We discover an asym-
metry in existing models’ ability to predict
positive and negative outcomes. Where the
state-of-the-art outcome prediction model we
used predicts positive outcomes at 75.06 F1, él
predicts negative outcomes at only 10.09 F1,
worse than a random baseline. To address this
performance gap, we develop two new models
inspired by the dynamics of a court process.
Our first model significantly improves posi-
tive outcome prediction score to 77.15 F1 and
our second model more than doubles the nega-
tive outcome prediction performance to 24.01
F1. Despite this improvement, shifting focus
to negative outcomes reveals that there is still
much room for improvement for outcome pre-
diction models.
https://github.com/valvoda
/Negative-Precedent-in
-Legal-Outcome-Prediction
1
Introducción
The legal system is inherently adversarial. Ev-
ery case pitches two parties against each other:
the claimant, who alleges their rights have been
breached, and the defendant, who denies breach-
ing those rights. For each claim of the claimant,
their lawyer will produce an argument, para cual
the defendant’s lawyer will produce a counter-
argumento. In precedential legal systems (Negro,
2019), the decisions in the past judgements are
34
binding on the judges in deciding new cases.1
Por lo tanto, both sides of the dispute will rely on
the outcomes of previous cases to support their
posición (Duxbury, 2008; Lamond, 2016; Negro,
2019). The claimant will assert that her circum-
stances are alike those of previous claimants
whose rights have been breached. The defendant,
por otro lado, will allege that the circum-
stances are in fact more alike those of unsuccess-
ful claimants. The judge decides who is right, y
by doing so establishes a new precedent. If it is the
claimant who is successful in a particular claim,
the precedent expands the law by including the
new facts in its scope. If it is the defendant who
is successful, the law is contracted by rejection
of the new facts from its scope. The expansion
or contraction is encoded in the case outcome;
we will refer to them as positive outcome and
negative outcome, respectivamente.
Positive and negative outcomes are equally
binding, which means that the same reasons that
motivate the research of the positive outcome also
apply to the negative outcome. Both are important
for computational legal analysis, a fact that has
been known at least since Lawlor (1963).2 Cómo-
alguna vez, the de facto interpretation of precedent in
today’s legal NLP landscape focuses only on pos-
itive outcomes. Several researchers have shown
that a simple model can achieve very high perfor-
mance for such formulation of the outcome pre-
diction task (Aletras et al., 2016; Chalkidis et al.,
2019; Clavi´e and Alphonsus, 2021; Chalkidis
et al., 2021b), a finding that has been replicated
for a number of jurisdictions (Zhong et al., 2018;
Xu et al., 2020).
1This is in contrast to the civil law jurisdictions, dónde
judges do not create new law and predominantly rely on
applying rules found in the Legal Code. Our paper mainly
concerns precedential legal systems, such as the US, Reino Unido,
Australia, and India.
2He describes them as pro-precedent and con-precedent.
Transacciones de la Asociación de Lingüística Computacional, volumen. 11, páginas. 34–48, 2023. https://doi.org/10.1162/tacl a 00532
Editor de acciones: Sebastián Padó. Lote de envío: 5/2022; Lote de revisión: 7/2022; Publicado 1/2023.
C(cid:2) 2023 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
yo
a
C
_
a
_
0
0
5
3
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
En este trabajo, we reformulate outcome predic-
tion as the task of predicting both the positive and
negative outcome given the facts of the case. Nuestro
results indicate that while a simple BERT-based
classification model can predict positive out-
comes at an F1 of 75.06, it predicts negative out-
comes at an F1 of 10.09, falling short of a random
baseline which achieves 11.12 F1. This naturally
raises the question: What causes such asymme-
intentar? In §8, we argue that this disparity is caused
by the fact that most legal NLP tasks are formu-
lated without a deep understanding of how the
law works.
Searching for a way to better predict negative
resultados, we hypothesize that building a prob-
abilistic model that is more faithful to the legal
process will improve both negative and positive
outcome prediction. To test this hypothesis we
develop two such models. Our first model, cual
we call the joint model, is trained to jointly pre-
dict positive and negative outcome. Nuestro segundo
modelo, which we call the claim-outcome model,
enforces the relationship between the claims and
resultados. While the joint model significantly3
outperforms state-of-the-art models on positive
outcome prediction with 77.15 F1, the claim-
outcome model doubles the F1 on negative out-
come prediction at 24.01 F1. We take this result
as strong evidence that building neural models
of the legal process should incorporate domain-
specific knowledge of how the legal process works.
2 The Judicial Process
In order to motivate our two models of outcome,
it is necessary to first understand the process of
how law is formed. Broadly speaking, the legal
process can be understood as a task of narrowing
down the legal space where the breach of law
might have taken place. Initially, before the legal
process begins, the space includes all the law there
es, eso es, every legal Article.4 It is the job of the
lawyer to narrow it down to only a small number
of Articles, a subset of all law. Finalmente, the judge
determines which of the claimed Articles, if any,
has been violated. We can therefore observe two
distinct interactions between the real world and
la ley: (i) when a lawyer connects the real world
3Throughout the paper we report significance using the
two-tailed paired permutation test with p < 0.05.
4Legal Article is a codification of a particular law. For
example Article 3 of the European Convention of Human
Rights (ECHR) prohibits torture.
and law via a claim, and (ii) when a judge connects
them via an outcome.
In practice, this means that judges are con-
strained in their decision. They cannot decide that
a law has been breached unless a lawyer has
claimed it has. A corollary of the above is that
lawyers actively shape the outcome by forcing a
judge to consider a particular subset of law. In do-
ing so a lawyer defines the set of laws from which
the judge decides on the outcome.5 The power of
a lawyer is also constrained. On one hand, lawyers
want to claim as many legal Articles as possible,
on the other there are only so many legal Articles
that are relevant to their client’s needs. Thus, there
are two principles that arise from the interaction
of a lawyer and a judge. First, positive outcome
is a subset of claims. Second, negative outcome
consists of the unsuccessful claims, namely, the
claims the judge rejected.
There is a close relationship between claims
and negative outcomes: If we knew the claims
the lawyer had made, we could define negative
outcome as exactly those Articles that have been
claimed, but that the judge found not to be violated.
Much like how outcomes are a product of judges,
claims are a product of lawyers. And, unlike facts,
they are not known before human legal experts
interact with the case. Therefore, to study the rela-
tionship of outcomes and facts, one can not rely
on claims as an additional input to the model. The
only input which is available and known before a
case is processed by the court, are the facts.
Outcome Prediction Task. Legal facts are the
transcript of the judge’s description of what has
happened between the claimant and the defen-
dant. Under the current formulation of the out-
come prediction task, models are trained to predict
whether case facts correspond to a violation of
each Article, that is, the models are trained to pre-
dict a vector in {0, 1}K where 1 indicates a posi-
tive outcome and K is the number of legal Articles
under consideration.
What is Wrong with Current Work? In the
above formulation, 0 is ambiguous—it can indi-
cate either that the Article not claimed or that
the judge ruled that that specific Article was not
breached. Existing models, which don’t take any
5In some jurisdictions and certain type of trials, the
decision is made by a jury instead of a judge.
35
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
information about claims into accounts, implic-
itly assume that all Articles have been claimed,
which is almost never the case in practice. Under
this assumption, the role of the legal claim and of
negative outcomes is therefore effectively ignored.
Reformulating the Task. How should negative
outcome then be modeled? Given the domain
the interaction of a
specific knowledge about
judge and a lawyer, our position is that models
that predict outcomes should model the claims
and outcomes together. To this end, we first need
information about which laws have been claimed.
In §6, we discuss the creation of a new corpus,
which contains the necessary annotation for this
task. In the next section we develop two mod-
els that jointly predict outcomes and claims using
two basic assumptions about how the law oper-
ates. We believe that our reformulation of the task
has two advantages. First, considering positive
and negative outcomes together is a step towards
better evaluation of legal outcome prediction
models. Second, incorporating the roles of a judge
and a lawyer within the models of outcome is a
step towards better models of law.
3 Law-Abiding Models
In this section we formulate our two probabilistic
models of law. Our law-abiding models are built
on top of the two assumptions described below.
Ck = ck, to refer to the random variable
associated with the kth Article. Bolded C is
a random variable ranging over CK. The
values of C are denoted as c ∈ CK.
• The random variable F ranges over tex-
tual descriptions of facts, that is, Σ∗ for a
vocabulary Σ. Values of F are denoted as f .
3.1 Joint Model
We begin with a simple assumption that, given the
facts of a case, legal Articles are independent.
Assumption 1 (Conditional Independence). Con-
ditioned on the facts F = f , the random var-
iables (Ok, Ck) for the kth Article are jointly
conditionally independent of the random variables
(O(cid:2), C(cid:2)) for the (cid:2)th Article when (cid:2) (cid:6)= k.
This assumption is based in the origin of each
Article as an independent Human Right, related
by the spirit of ECHR, but otherwise orthogonal
in nature. This is indeed how the law operates in
general. A law, whether codified in an Article or
a product of precedent, encodes a unique right or
obligation. In practice this means that a breach
of one law does not determine a breach of another.
For example, a breach of Article 3 of ECHR (the
prohibition of torture) does not entail a breach of
Article 6 (right to a fair trial). Even breaches of
law that are closely related, for example, libel and
slander, do not entail each other, and allegation
of each must be considered independently.
Notation. We define a probability distribution
over three random variables.
By Assumption 1, the joint distribution over
outcomes and claims decomposes over Articles as
• O is a random variable ranging over the set
O = {+, −, ∅}, whose elements correspond
to positive, negative, and null outcome, re-
spectively. The null outcome refers to all
those Articles that the lawyer did not claim.
The values of O are denoted o ∈ O. We use
a subscript, Ok = ok, to refer to the ran-
dom variable associated with the kth Article.
Bolded O is a random variable ranging over
OK, where K is the number of Articles we
consider. The values of O are denoted as
o ∈ OK.
• The random variable C ranges over the set
C = {Y, N}, whose elements encode whether
or not an Article has claimed. The values of
C are denoted c ∈ C. We use a subscript,
p(O = o, C = c | F = f )
(1)
=
K(cid:2)
k=1
p(Ok = ok, Ck = ck | F = f )
In the remainder of the text we write f in lieu of
F = f to save space. We also write ok instead of
Ok = ok and ck instead of Ck = ck, respectively,
when it is clear from context.
3.2 Claim–Outcome Model
Our second model builds on the first assumption
with a second simple assumption:
Assumption 2 (Claims and Outcomes). For an
Article to be breached, that is, for it to become
an outcome, it first needs to be claimed. The
36
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
judge provides an outcome if and only if a claim
is made:
p(Ok = ∅ | Ck = Y, f ) = 0
p(Ok = ∅ | Ck = N, f ) = 1
(2a)
(2b)
By Assumption 2, we have that each distribu-
tion over outcome–claim pairs simplifies into the
following equation:
p(Ok = ok, Ck = ck | f ) =
⎧
⎪⎨
p(ok | Y, f ) p(Y | f )
p(N | f )
0
⎪⎩
if ck = Y ∧ ok (cid:6)= ∅
if ck = N ∧ ok = ∅
otherwise
(3)
Crucially, Assumption 2 allows us to reduce the
problem to two independent binary classifica-
tion problems. First, we train a claim predictor
p(ck | f ) that predicts whether a lawyer would
claim that the kth Article is relevant to the facts f .
Second, we train an outcome predictor that pre-
dicts whether the outcome is + or −, given that
the lawyer has claimed a violation of Article k.
3.3 Neural Parameterization
We consider neural parametrizations for all the
distributions discussed above. At the heart of all
of our models is a high-dimensional representa-
tion enc(f ) ∈ Rd1 of the facts f . We obtain this
representation from a pre-trained language model
fine-tuned for our task (see §5). All our language
models rely on f as their sole input. Except
where we indicate otherwise, both the language
model weights and classifier weights are learned
separately for every model presented below.6
Joint Model. First we parameterize the joint
model, which gives us a joint distribution over all
configurations of ok and ck for a specific Arti-
cle k. In principle, there are six such config-
urations {+, −, ∅} × {Y, N}. However, after we
enforce Assumption 2, we are left with only three
. This re-
configurations
duces the problem to a 3-way classification, which
we parameterise as follows:
(cid:8)+, Y(cid:9), (cid:8)−, Y(cid:9), (cid:8)∅, N(cid:9)
(cid:7)
(cid:8)
p(Ok = ok,Ck = ck | f ) =
(4)
softmax(Uk ρ(Vk enc(f )))(cid:8)ok,ck(cid:9)
6For
the language models,
the weights are fine-
tuned from a pre-trained model that we initialize from the
HuggingFace library.
(cid:2)
I
i(cid:10) exp xi(cid:10)
, ρ is a ReLU
where softmax(x)i = exp xi
activation function defined as ρ(x) = max(0, x);
Uk ∈ R3×d2 and Vk ∈ Rd2×d1 are per-Article
learnable parameters. In total, the classifier has
K(3d2 + d2d1) parameters, excluding those from
the encoder enc.
Claim–Outcome Model. We parameterize the
claim–outcome model as two binary classifica-
tion tasks: One that is predicting the claims, the
other that is predicting positive outcomes. For the
latter binary classification task, one class corre-
sponds to +, while the other to both − and ∅. This
leads to the following pair of binary classifiers:
p(Ck = Y | f ) = σ(uk · ρ(Vk enc(f )))
p(Ok = + | Ck = Y, f ) = σ(u(cid:10)
k
· ρ(V(cid:10)
(5)
k enc(cid:10)(f )))
1
where uk ∈ Rd2, Vk ∈ Rd2×d1, u(cid:10)
∈ Rd3,
k
∈ Rd3×d1 are learnable parameters,
and V(cid:10)
k
σ(x) =
1+exp(−x) is the sigmoid function, and enc
and enc(cid:10) are two separate encoders. In total, we
have K(d2 + d1d2 + d3 + d1d3) parameters, ex-
cluding those from the encoder enc. We use
primed symbols to denote separately learned pa-
rameters. Given these probabilities, we can mar-
ginalize out the claims to obtain the probability
of a positive outcome:
p(Ok = + | f )
(6)
= p(Ok = + | Ck = Y, f ) p(Ck = Y | f )
+ p(Ok = + | Ck = N, f ) p(Ck = N | f )
(1)
= p(Ok = + | Ck = Y, f ) p(Ck = Y | f )
where (1) is true because p(Ok = + | Ck = N, f )
is always zero (since by Assumption 2 no positive
outcome can be set on an unclaimed case).
We then predict the probability of negative
outcome as the complement of the probability of
a positive outcome multiplied by the probability
of a claim:
p(Ok = − | f ) =
(cid:9)
(cid:10)
(7)
1 − p(Ok = + | Y, f )
p(Ck = Y | f )
This step enforces that the negative outcome prob-
ability is always both lower than that of claims
and sums up to 1 with the probability of positive
outcome. Finally, we have that
p(Ok = ∅ | f ) = p(Ck = N | f )
(8)
37
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
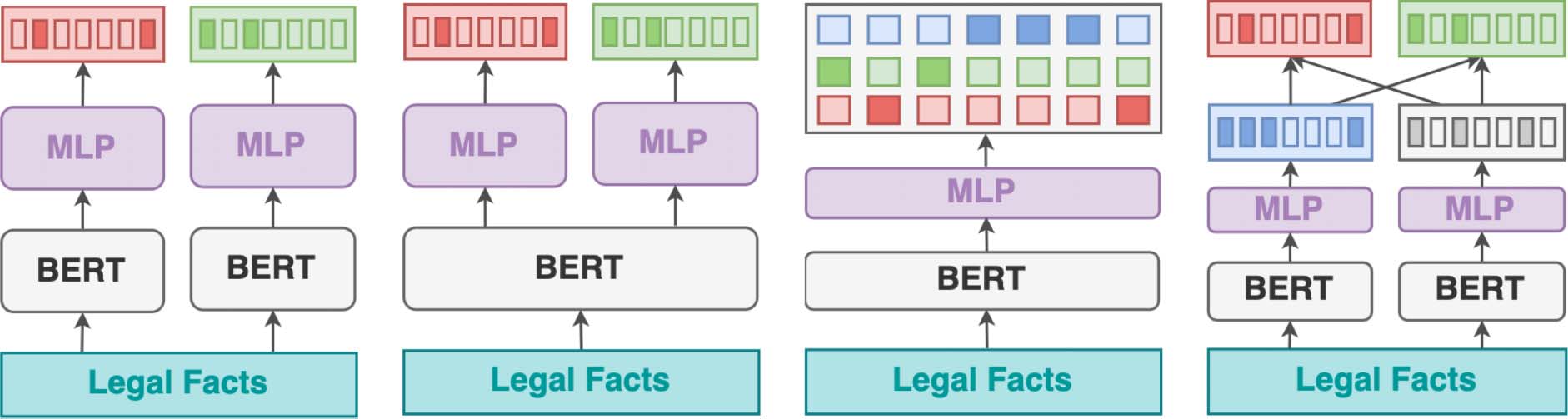
Figure 1: The models under consideration. Green and red boxes represent positive and negative outcomes,
respectively. Blue boxes represent claims.
To make a decision, we compute the following
argmax that marginalizes over claims:
o(cid:3)
k = argmax
ok∈O
p(Ok = ok | f )
(cid:11)
= argmax
ok∈O
ck∈C
p(Ok = ok, Ck = ck | f )
(9)
Training and Fine-tuning. All models in § 3.3
are trained by maximizing the log of the joint
distribution p(o, c | f ). We are given a dataset of
triples D =
o(n), c(n), f (n)
Due to the
(cid:10) (cid:8)
(cid:7) (cid:9)
N
n=1
independence assumption made, this additively
|
factorizes over Articles
N
K
| f (n)). We
f (n)) =
n=1
fine-tune enc jointly for all p(ok, ck | f ).
N
n=1 log p(o(n), c(n)
k , c(n)
k=1 log p(o(n)
(cid:12)
(cid:12)
(cid:12)
k
4 Baselines
We contextualize the performance of the joint
and claim–outcome model with a number of
baselines. As a starting point we build a simple
classification model trained to predict positive or
negative outcome separately, see Figure 1a. We
further want to test whether the advantage of our
joint model stems from encoding the relation-
ship between positive and negative outcome, or
whether it is down to simply training on more
data. We test this by formulating the task as a
multi-task learning objective, see Figure 1b. While
this model is trained on the same amount of
data as our joint model, it does not explicitly en-
code the relationship between positive and nega-
tive outcomes.
A Simple Baseline. For our simple baseline
model we formulate the positive and negative
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
outcome prediction as a multi-label classification
task. Despite its conceptual simplicity, this model
achieves state-of-the-art performance on the task
of positive outcome prediction. Given the facts
of a case f , we directly model the probability
that the outcome is positive, as a binary classifi-
cation problem where the first class is the positive
+ and the second is the union of negative and
unclaimed {−, ∅}. Likewise, we separately model
the probability that the outcome is negative, as a
binary classification problem where the first class
is the negative − and the second is the union
of positive and unclaimed {+, ∅}. To this end,
we define a pair of binary classifiers:
p(Ok = + | f ) = σ(u1
k
p(Ok = − | f ) = σ(u2
k
· ρ(V1
· ρ(V2
k enc1(f ))) (10a)
k enc2(f ))) (10b)
∈ Rd2, V1
k
∈ Rd2×d1, u2
k
∈ Rd3, and
where u1
k
∈ Rd3×d1 are the per-Article learnable pa-
V2
k
rameters. Thus, in total, we have K(d3 + d3d1 +
d2 + d2d1) parameters excluding those from the
fine-tuned encoders enc1 and enc2. The encoders
enc1 and enc2 represent two different fine-tuned
parameters of the encoder. Note that this ap-
proach does not model whether or not an Article
is claimed, which stands in contrast to the main
models proposed by this work.
MTL Baseline. We also consider a version of
the simple baseline where we jointly fine-tune a
single encoder. Symbolically, this is written as:
p(Ok = + | f ) = σ(u1
k
p(Ok = − | f ) = σ(u2
k
· ρ(V1
· ρ(V2
k enc(f ))) (11a)
k enc(f ))) (11b)
38
where enc is shared between the classifiers. Apart
from the sharing, the MTL baseline is identical
to the simple baseline.
Random Baseline. Finally, we provide a simple
random baseline by sampling the outcome vectors
from discrete uniform distribution. The random
baseline is an average performance over 100 in-
stantiations of this baseline.
5 Experimental Setup
Pre-trained Language Models. We obtain
high-dimensional representations enc(f ) by fine-
tuning one of the following pre-trained language
models with f as an input:
• We first consider BERT because it
is a
widely used model in legal AI (Chalkidis
et al., 2021b).
• Second, we consider LEGAL-BERT, be-
cause it is trained on legal text, which should
give it an advantage in our setting.
• Finally, we use the Longformer model.
Longformer is built on the same Transformer
(Vaswani et al., 2017) architecture as BERT
(Devlin et al., 2019) and LEGAL-BERT
(Chalkidis et al., 2020), but it can process
up to 4,096 tokens. We select this architec-
ture because the facts of legal documents
often exceed 512 tokens; a model that can
process longer documents could therefore be
better suited to our needs.
Training Details. All our models are trained
with a batch size of 16. We conduct hyperpa-
rameter optimization across learning rate {3e−4,
3e−5, 3e−6}, dropout {0.2, 0.3, 0.4}, and hidden
size {50, 100, 200, 300}. We truncate individual
case facts to 512 tokens for BERT and LEGAL-
BERT or 4,096 tokens for
the Longformer.
Our models are implemented using the PyTorch
(Paszke et al., 2019) and HuggingFace (Wolf et al.,
2020) libraries. We use Adam for optimization
(Kingma and Ba, 2015) and train all our models
on 1 Tesla V100 32GiB GPUs for a maxi-
mum of 1 hour. We train for a maximum of
10 epochs.7 The models are trained on the training
set, see Table 1. We report the results on the test
Chalkidis et al. Corpus
Outcome
Train
Validation
Test
Positive
Negative
Claims
8046
2259
8836
835
279
985
Outcome Corpus
Outcome
Train
Validation
Positive
Negative
Claims
7542
4413
8372
844
498
931
851
289
991
Test
925
560
1034
Table 1: Number of cases with at least one pos-
itive or negative outcome label in the dataset.
set for the models that have achieved the lowest
loss on the validation set.
6 Legal Corpora
We work with the ECtHR corpus,8 which con-
tains thousands of instances of case law pertain-
ing to the European Convention of Human rights
(ECHR). ECtHR cases contain a written descrip-
tion of case facts, which is our f , and informa-
tion about claims and outcomes. Since positive
outcomes are a subset of all claims, the exclusion
set of claims and positive outcomes constitutes
the set of negative outcomes.
Chalkidis et al. Corpus. To obtain the golden
labels for outcomes and claims we first rely on the
Chalkidis et al. (2021a) scrape of the ECHR corpus
that contains alleged violations and violations la-
bels. The violations are case outcomes, while the
alleged violations are the main claims of the case.
Outcome Corpus. Since violations are only the
main claims of the case, to investigate the full
set of claims (and negative outcomes) we process
the Chalkidis et al. (2019) scrape of the online
HUDOC9 database and extract the full set of
claims using regular expressions.
We conduct all our experiments on both cor-
pora. However, not all of the Articles of ECHR
are interesting from the perspective of a legal out-
come, since not all of them can be claimed by a
8While ECtHR interacts with civil law jurisdictions, its
judges rely on precedent (Valvoda et al., 2021).
9See Appendix B for examples from our dataset or
7All our code is available on Github.
HUDOC for all the ECHR caselaw.
39
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Outcome Corpus
Chalkidis et al. Corpus
Model
LLM
Pos
Neg
Null
All
Pos
Neg
Null
All
Claim-Outcome
Joint
MTL
Baseline
Simple Baseline
BERT
74.80
LEGAL-BERT 74.90
74.23
Longformer
BERT
76.24
LEGAL-BERT 76.96
77.15
Longformer
BERT
75.75
LEGAL-BERT 76.73
75.83
Longformer
BERT
75.06
LEGAL-BERT 74.85
74.12
Longformer
24.01
21.83
20.55
17.43
21.93
16.24
12.90
9.44
12.34
6.62
10.09
6.72
95.53
95.49
95.17
95.46
95.71
95.49
64.78
64.07
63.32
63.04
64.87
62.96
–
–
–
–
–
–
–
–
–
–
–
–
63.85
64.47
63.53
65.15
67.08
65.94
63.21
65.00
63.36
65.04
65.51
63.92
14.65
13.05
14.84
1.87
0.94
0.95
0.95
0.95
0.47
0.00
0.00
1.81
97.15
97.14
97.21
97.07
97.19
97.11
58.55
58.22
58.53
54.70
55.07
54.67
–
–
–
–
–
–
–
–
–
–
–
–
Table 2: F1-micro averaged scores for all the models considered over the two datasets.
lawyer. Out of the 51 Articles of the convention,
only Articles 2 to 18 contain the rights and free-
doms, whereas the remaining Articles pertain to
the court and its operation. The rights and free-
doms are what a lawyer can claim, the focus of
our work. We therefore restrict our study to pre-
dicting the outcome of these core rights. Further-
more, we remove any Articles that do not appear
in the validation and test sets. This leaves us with
K = 17 and K = 14 for the Chalkidis et al. Cor-
pus and Outcome Corpus, respectively. Table 1
shows the number of cases containing negative
outcome vs. positive outcome across the train-
ing/validation/test splits. The full distribution of
Articles over cases in both corpora can be found
in Appendix C.
7 Results
Following Chalkidis et al. (2019), we report all
results as F1 micro-averaged. We report signif-
icance using the two tailed paired permutation
tests with p < 0.05. The bulk of our results is
contained in Table 2. We report individual con-
clusions in the following paragraphs.
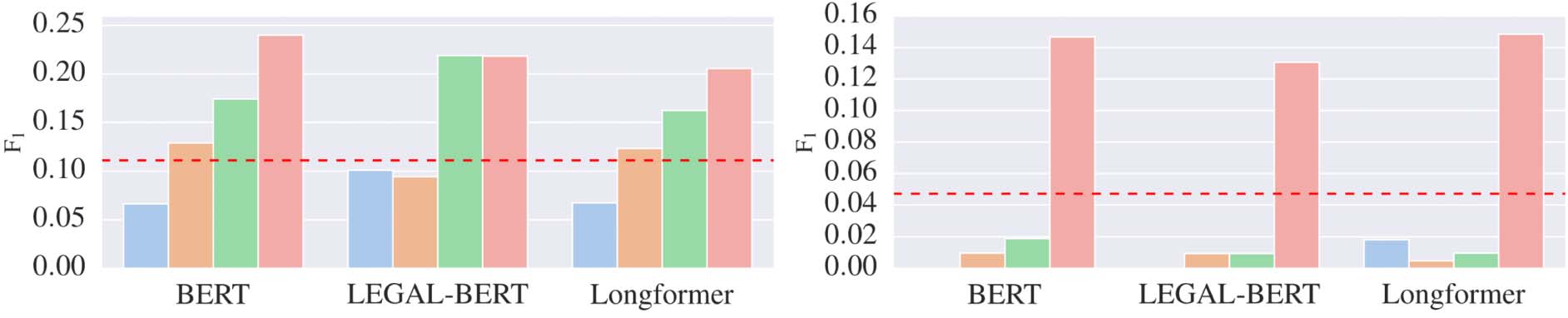
Negative Outcome Prediction is Challenging.
First, we compare the positive and negative out-
come prediction performance on our outcome
corpus and find that while the best simple baseline
model achieves 75.06 F1 on positive outcomes, the
same model achieves only 10.09 F1 on negative
outcomes. In fact, the model fails to beat our ran-
dom baseline of 11.12 F1 on negative outcomes.
The same trend holds over all our model architec-
tures, all the underlying language models and both
datasets under consideration. Every time, the neg-
ative outcome performance is significantly lower
than that of positive outcomes. Therefore, our
first conclusion is that negative outcome is simply
harder to predict than its positive counterpart.
Claim-outcome Model Improves Negative Out-
come Prediction. We observe a large and sig-
nificant improvements using our claim–outcome
model on the task of negative outcome prediction;
see Figure 2a and Figure 2b. Our claim–outcome
model is better than every baseline model under
consideration, a finding that holds over three un-
derlying language models and both datasets. A
single exception to this rule is the joint model,
which insignificantly beats our claim–outcome
model (by 0.1) on the outcome corpus using
the LEGAL-BERT LLM. Overall, where the best
claim–outcome model achieves 24.01 F1 on the
outcome corpus and 14.84 F1 on the Chalkidis
et al. corpus, the best simple baseline model only
achieves 10.09 and 1.81 F1, respectively. There-
fore, our second conclusion is that enforcing the
relationship between claims and outcomes im-
proves negative outcome prediction. We expand
our discussion on this in Appendix A.
40
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 2: Results for Simple, MTL, Joint, and Claim-Outcome models. Dashed line is our random baseline.
Joint-model Improves Positive Outcome Pre-
diction. Turning to the positive outcome pre-
diction task, we see that the simple baseline and
our claim–outcome model have a comparable F1.
The joint model, on the other hand, improves over
either baseline and achieves the best F1 on both
the outcome corpus and the Chalkidis et al. cor-
pus (77.15 and 67.08 F1, respectively). Since the
simple baseline model using pre-trained BERT
is the state-of-the-art model for positive outcome
prediction (Chalkidis et al., 2021b), our third con-
clusion is that jointly training on positive and
negative outcomes is a better way of learning how
to predict a positive outcome of a case.
Impact of Pre-training.
In line with the stan-
dard results on LexGLUE task A (Chalkidis et al.,
2021b), we find that LEGAL-BERT and Long-
former fail
to consistently outperform BERT.
Nonetheless, LEGAL-BERT has a significant pos-
itive effect on negative outcome prediction for
the joint model. It improves over BERT (17.43
F1) and Longformer (16.24 F1) based models and
achieves 21.93 F1. It is also the underlying lan-
guage model for the highest performing model
for the outcome corpus (achieving 64.87 F1 over-
all). Meanwhile, Longformer sets the highest pos-
itive outcome performance on the same corpus
(77.15 F1). We therefore find both longer doc-
ument encoding and legal language pre-training
useful in certain narrow settings, although it seems
that the choice of model architecture has a larger
effect on the performance than the choice of the
language model size or pre-training material.
Which Model Is the Best? Finally, we turn to
the question of what is the best model of outcome
prediction, the joint model or the claim–outcome
model? Towards answering this question we take
an average F1 over all three random variables
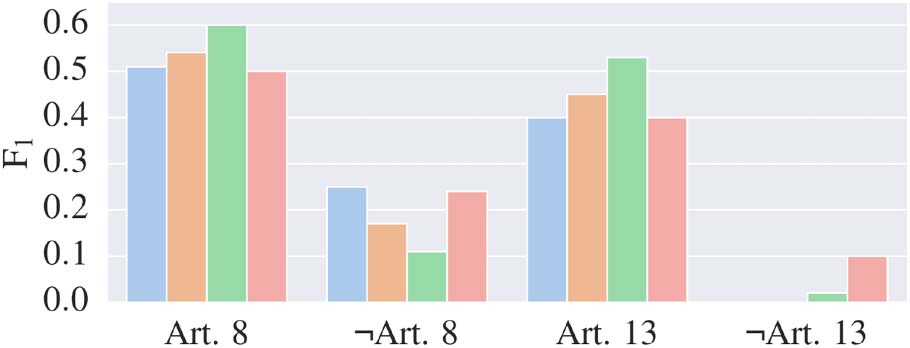
Figure 3: Article 8 and 13 results for Simple, MTL,
Joint, and Precedent models.
under consideration; the best model of outcome
should do well at distinguishing between positive,
negative and null outcome. We find that while
the joint model has an insignificant edge over the
claim–outcome model on the outcome corpus (by
0.1), on the Chalkidis et al. corpus the claim–out-
come model significantly improves over the joint
model (by 3.48 F1). This leads us to believe that
claim–outcome model is overall the better model
for legal outcome prediction. However, both mod-
els are valuable in their own right. Where the
joint model improves over state-of-the-art positive
outcome prediction models, the claim–outcome
model doubles their performance on the negative
outcome task.
8 Discussion
The results reported above raise the question of
why models severely underperform on negative
outcome prediction. The simplest answer could
be the amount of training data that is available for
each task. We test this hypothesis by comparing
the performance on Articles 8 (796 negative vs.
654 positive examples) and 13 (1197 negative vs.
1031 positive examples) of ECHR in our outcome
corpus, where there is more training data avail-
able for the negative outcome than for the positive
outcome. The results, given in Figure 3, show that
41
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
even when the model has more training data for
negative outcome than the positive outcome, pre-
dicting negative outcome is still harder. In par-
ticular for Article 13,
the amount of training
data is higher than for Article 8, yet the drop in
performance between positive and negative out-
come prediction is still dramatic. In fact, while
the scores achieved by the claim–outcome model
are still low, the other models (except our joint
model) fail to predict a single negative outcome
correctly for Article 13. We therefore believe
that the performance drop is likely to be more re-
lated with the complexity of the underlying task,
than with the imbalance of the underlying datasets.
To find a better explanation of the performance
asymmetry, we now turn in our discussion to the
legal perspective. In precedential jurisdictions, of
which ECtHR is one (Zupancic, 2016; Lupu and
Voeten, 2010; Valvoda et al., 2021), the decisions
of a case are binding on future decisions of the
court. Two cases with the same facts should there-
fore arrive at the same outcome. Of course, in
reality, the facts are never the same. Rather, cases
with similar circumstances will, broadly speak-
ing, lead to similar outcomes. This is achieved by
applying the precedent. In such cases, the judge
will in effect say that the new case is not substan-
tially different from an already existing case and
therefore the same outcome will be propagated.
On the other hand, if the previous precedent is
not to be followed, the judge needs to distinguish
the case at hand from the precedent. Distinguish-
ing the case from the precedent is a more involved
task than applying the precedent. It requires iden-
tifying what exactly about the new facts sets the
new case apart from the previous one. This can of
course be done for both cases with positive and
negative outcome. Both can be applied or distin-
guished.10 Since judges deal with claims, each of
which comes with an argument built around the
precedent that favours the claimant’s viewpoint,
we believe that negative outcomes overwhelm-
ingly rely on distinguishing the case from the
precedent. This is evidenced in the yearly reports
of the ECtHR (2020), which list cases where the
judges decided to distinguish the facts of the case
at hand. Distinguishing almost always leads to a
negative outcome. We observe the same trend in
our ECtHR corpus.
10Overruling is another option, though it is exceptionally
rare at the ECtHR (Dzehtsiarou, 2017).
It might therefore be the case that while there
is such a thing as a prototypical positive prece-
dent, there is no prototypical negative precedent.
This could explain why the simpler architectures
struggle to learn to predict it. While a simpler
model is ill-suited for the task since it is trained
to find a similarity between the negative outcome
cases, our claim-outcome model does not assume
that negative outcome cases are similar in the
first place. Instead, our model assumes similarity
between claims. Since claim prediction can be
modeled with a high accuracy (Chalkidis et al.,
2021a), we can reveal the negative outcome as a
disagreement between a judge and a lawyer (i.e.,
claims and the outcomes).
By investigating individual cases
in the
Chalkidis et al. Corpus, we can identify a further
possible explanation for the baseline model per-
formance. For instance, the case of Wetjen and
Others v. Germany (Wetjen) is concerned with
Article 8: Right to respect for private and family
life. In this case, religious parents used caning
(among other methods) as a punishment for their
children. The German State intervened and placed
the children in foster care. The parents claim in-
terference with their right to family life. On a su-
perficial level, the case is similar to two Article 8
cases both cited in Wetjen: that of Shuruk v.
Switzerland (Shuruk), and Suss v. Germany (Suss).
In Shuruk, religious parents fight for an extra-
dition of a child. The mother of the child argues
that it would be an interference with her right
to a family life if the child was to be extradited
to the husband, who has joined an ultra-orthodox
Jewish movement. A component of the case is an
allegation of domestic violence the husband was
supposed to have perpetrated against his wife. In
Suss, the German State has denied a divorced
father access to his daughter due to the frequent
quarrels between the parents during the visits.
The father alleges breach of Article 8. In Wetjen
and Suss, the judges have decided a violation of
Article 8 has not occurred, they have ruled the
opposite in Shuruk.
On the surface, the facts are alike, especially
between Shuruk and Wetjen—both cases contain
elements of abuse, religion, and state intervention.
However, to a human lawyer, the distinction be-
tween the cases is fairly trivial. In Wetjen, the
State is allowed to intervene to protect a child
from an abusive ultra-religious parents, which is
very similar situation to Suss, where a State is
42
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
allowed to intervene to protect the child from
quarrels between divorced parents.
All our models are exposed to both Shuruk
and Suss in the training set. However, for the
positive outcome baseline, the information about
Suss being related to Article 8 is lost. Conversely,
for the negative outcome baseline, the information
about Shuruk being related to Article 8 is lost. It
is therefore not surprising that the best perform-
ing negative11 and positive12 outcome baseline
models both get the Wetjen outcome prediction
wrong. On the other hand, the best claim–outcome
model, which is trained to learn that both Shuruk
and Suss are related to Article 8 via the claim
prediction objective, makes the correct outcome
prediction in the Wetjen case.
In conclusion, our claim-outcome model is in-
deed a better way of modeling negative outcome,
but its superiority is not due to the fact that it
is learning anything about the law itself. It sim-
ply leverages the fact that positive outcomes and
claims are easy to predict and enforces the rela-
tionship between them. To identify the negative
outcome with high F1 will require deeper under-
standing of law than our models are currently
capable of.
9 Related Work
Juris-informatics can trace its origins all the way
to the late 1950s (Kort, 1957; Nagel, 1963). The
pioneers used rule-based systems to successfully
capture aspects of legal reasoning, using thou-
sands of hand-crafted rules (Ashley, 1988). Yet
due to the ever-changing rules of law, these sys-
tems were too brittle to be employed in practice.
Particularly in common law countries, the major-
ity of law is contained in case law, where cases are
transcripts of the judicial decisions. This allows
the law to constantly change in reaction to each
new decision. The advances of natural language
processing (NLP) in the past two decades have
rejuvinated the interest in developing applica-
tions for the legal domain. Areas explored include
question answering (Monroy et al., 2009), legal
entity recognition (Cardellino et al., 2017), text
summarization (Hachey and Grover, 2006), judg-
ment prediction (Xu et al., 2020), majority opin-
ion prediction (Valvoda et al., 2018), and ratio
decidendi extraction (Valvoda and Ray, 2018).
11Simple Baseline Longformer.
12Simple Baseline LEGAL-BERT.
Our work is similar to the recent study of
Chinese law judgement prediction by Zhong et al.
(2018) and Xu et al. (2020), who break down court
judgements into the applicable law, charges, and
terms of penalty. Operating in the civil law system
(which outside of China is also used in Germany,
and France, inter alia), they argue that predicting
applicable law is a fundamental subtask, which
will guide the prediction for other subtasks. In the
context of ECHR law, we argue that legal claims
are one such guiding element for outcome predic-
tion. While similar, applicable law and claims are
different. In the work above, the judge selects the
applicable law from the facts as part of reaching
the outcome. This is not the case for ECHR law,
or any other precedential legal system known to
the authors, where the breach of law is claimed
by a lawyer, not a judge.
Finally, the ECtHR dataset has been collected
by Chalkidis et al. (2019), who have predicted
outcomes of the ECHR law and the correspond-
ing Articles using neural architectures. Our work
builds on their research by reinstantiating the
outcome prediction task on this dataset to in-
clude negative precedent. Similar datasets, which
one could apply our method to, include Caselaw
Access Project and US Supreme Court caselaw.13
10 Conclusion
While positive and negative outcomes are equally
important from the legal perspective, the current
legal AI research has neglected the latter. Our
findings suggest that negative outcome is much
harder to predict than positive outcome, at least
for current deep learning models. This has severe
implications for how well the current legal mod-
els can model judicial outcome. The same models
that predict positive outcome with 75.06 F1 fall
short of a random baseline of 10.09 F1 on the
negative outcome prediction task.
We discuss possible reasons why negative out-
come prediction is so much harder to learn.
Specifically, we suspect that negative outcomes
are mostly caused by a judge distinguishing the
case from its precedent. This lead us to believe
that learning to predict negative outcomes requires
more legal understanding than the current models
are capable of. We believe that negative outcome
13See US Supreme Court corpus and Caselaw Access
Project.
43
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
prediction is therefore a particularly attractive
task for evaluating progress in legal AI.
Our work improves over the existing models
by inducing the relationship between the judge
and the lawyer in our claim–outcome model ar-
chitecture. However, the best negative outcome
prediction model achieves only a third of the
performance of the positive outcome one. In fu-
ture work we hope to study the phenomenon of
precedent more closely, with the aim of building
models capable of narrowing this performance
gap. One possible avenue would be to relax our
Assumption 1 to study the potential relationships
between the individual legal Articles. We leave
this direction for future work.
11 Ethical Considerations
Legal models similar to the ones we study above
have been deployed in the real world. Known
applications include risk assessment of detainees
in the United States (Kehl and Kessler, 2017)
and sentencing of criminals in China (Xiao et al.,
2018). We believe these are not ethical use cases
for legal AI. One must not be tempted to think of
outcome prediction as equivalent to some medical
task, such as cancer detection, with a breach of
law seen as a ‘tumor’ that is either there or not.
This is a naive viewpoint that ignores the fact that
the legal system is a human construct in which the
decision makers, the judges, play a role that can
shift the truth, something that is impossible when
it comes to natural laws.
Herein lies the ethical dubiousness of any at-
tempt at modeling judges using AI. Unlike in the
domain of medicine, where identifying the under-
lying truth is essential for treatment, and thus a
successful machine diagnostician is in theory a
competition for the human one, in the domain of
law the validity of the decision is poised solely on
the best intentions of the judge. For some judges
this pursuit of the ‘right’ outcome can go as far
as defiance of legal precedent. We therefore ar-
gue a judge should not be replaced by a machine
and caution against the use of our, or any other
legal AI model currently available, towards auto-
mating the judicial system.
A Note on the Baselines
Comparing the MTL baseline and the joint model,
one might come to the conclusion that there is no
substantial difference between the models when
it comes to predicting positive outcomes. While
the joint model outperforms the MTL baseline on
eleven out of the twelve experiments we test our
models on, the improvement in performance on
the positive outcome prediction over the outcome
corpus is very narrow. However, there is an impor-
tant difference between them. The MTL baseline,
much like the simple baseline, can predict positive
and negative outcome simultaneously for the same
Article. This means that in our evaluation, the
baseline models can cheat by predicting an Article
to be simultaneously violated and not-violated.
This is another reason that the outcome prediction
task needs to consider the legal relationship be-
tween positive and negative outcomes. Ignoring
the relationship of claims and outcomes makes
both of our baselines fundamentally ill-suited for
the task of outcome prediction. Hence, they are
only useful for a comparison in our study.
44
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
B Glossary and Dataset Examples
Legal Terms
Claim
Positive Outcome
The allegation of a breach of law usually put forth by their legal counsel
on behalf of the claimant.
Claims are assessed by judges in courts of law. If they think a claim is
valid, they rule it as successful. The outcome of the case is a victory for
the claimant; which we call the positive outcome in this paper.
Negative Outcome On the other hand, the claimant can be unsuccessful in the court. The
judge has decided against them in the court, in favor of the defendant,
and we call this the negative outcome in this paper.
The description of what happened to the claimant. This includes more
general descriptions of who they are, circumstances of the perceived
violation of their rights, and the proceedings in domestic courts before
their appeal to ECtHR.
Cases that have been cited by the judges as part of their arguments.
Judges are expected to adhere to the binding rules of law and decide
future access accordingly.
New cases with the same facts to the already decided case should lead to
the same outcome. This is the doctrine of precedent by which judges can
create law.
Transcripts of the court proceedings.
European Convention of Human Rights, comprises the Convention and
the Protocols to the convention. The Protocols are the additions and
amendments to the Convention introduced after the signing of the
original Convention.
European Court of Human Rights, adjudicates ECHR cases.
A judge applies the precedent when she decides on the outcome of a case
via an analogy to an already existing case.
Conversely, a judge distinguishes the case from the already existing
cases when she believes they are not analogous.
Facts
Precedent
Binding
Stare Decisis
Caselaw
ECHR
ECtHR
Apply
Distinguish
ECtHR Example
Facts
Claims
Articles:
2, 6, 8,
14
Positive
Outcomes
Negative
Outcomes
Articles: 2,
6
Articles: 8,
14
‘‘Ms Ivana Dvoˇr´aˇckov´a was born in 1981 with Down
Syndrome (trisomy 21) and a damaged heart and lungs.
She was in the care of a specialised health institution
in Bratislava. In 1986 she was examined in the Cen-
tre of Paediatric Cardiology in Prague-Motole where it
was established that, due to post-natal pathological de-
velopments, her heart chamber defect could no longer
be remedied...’’ for more see Case of Dvoracek and
Dvorackova v. Slovakia
45
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
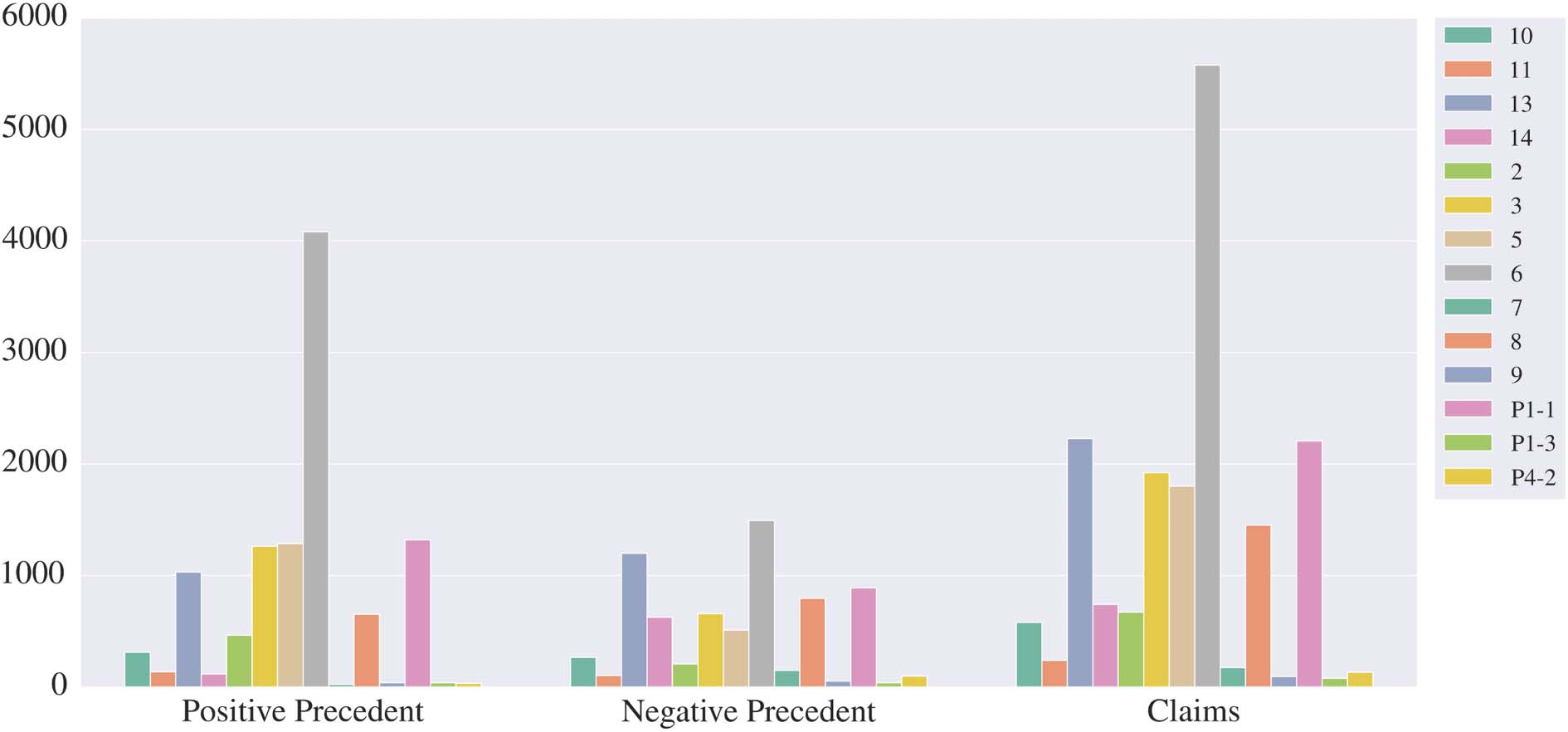
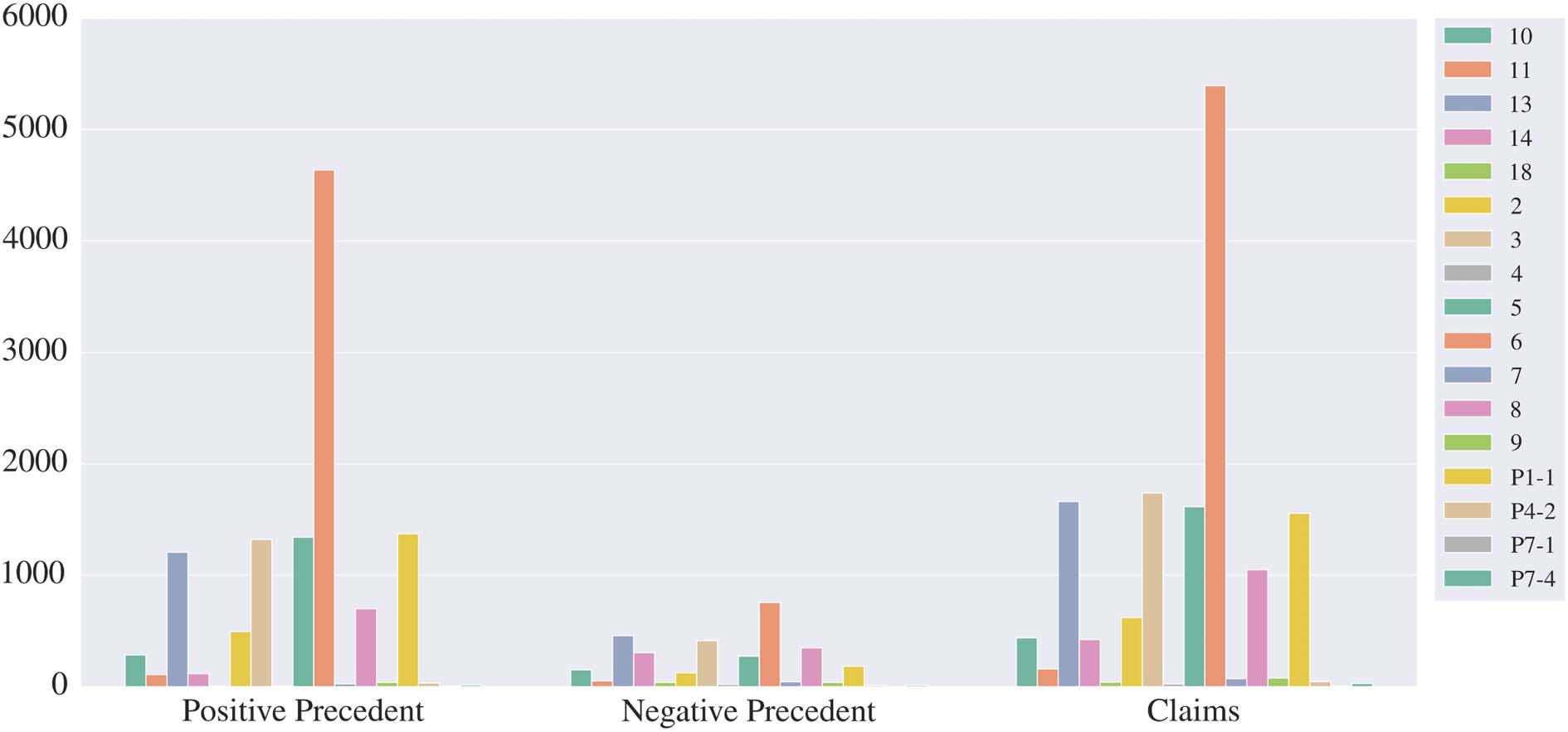
C Corpora Statistics
Figure 4: Distribution of Articles over training data in our outcome corpus.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
Figure 5: Distribution of Articles over training data in Chalkidis et al. corpus.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
46
References
Nikolaos Aletras, Dimitrios Tsarapatsanis, Daniel
Preot¸iuc-Pietro, and Vasileios Lampos. 2016.
Predicting judicial decisions of the European
Court of Human Rights: A natural language pro-
cessing perspective. PeerJ Computer Science,
2:e93. https://doi.org/10.7717/peerj
-cs.93
Kevin D. Ashley. 1988. Modelling Legal Argu-
ment: Reasoning with Cases and Hypotheticals.
Ph.D. thesis, USA. Order No: GAX88-13198.
Henry Black. 2019. Black’s Law Dictionary,
11th edition. Thomson Reuters.
Cristian Cardellino, Milagro Teruel, Laura
Alonso Alemany, and Serena Villata. 2017.
Legal NERC with ontologies, Wikipedia and
curriculum learning. In Proceedings of
the
15th Conference of the European Chapter of
the Association for Computational Linguis-
tics: Volume 2, Short Papers, pages 254–259,
Valencia, Spain. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/E17-2041
Ilias Chalkidis,
Ion Androutsopoulos,
and
Nikolaos Aletras. 2019. Neural legal judgment
prediction in English. In Proceedings of the
57th Annual Meeting of the Association for
Computational Linguistics, pages 4317–4323,
Florence, Italy. Association for Computational
Linguistics. https://doi.org/10.18653
/v1/P19-1424
Ilias Chalkidis, Manos Fergadiotis, Prodromos
and Ion
Malakasiotis, Nikolaos Aletras,
Androutsopoulos. 2020. LEGAL-BERT: The
muppets straight out of law school. In Find-
the Association for Computational
ings of
Linguistics: EMNLP 2020, pages 2898–2904,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2020.findings-emnlp.261
Aletras,
Ilias Chalkidis, Manos Fergadiotis, Dimitrios
Tsarapatsanis,
Ion
Nikolaos
Androutsopoulos, and Prodromos Malakasiotis.
2021a. Paragraph-level
rationale extraction
through regularization: A case study on Euro-
pean court of human rights cases. In Pro-
ceedings of the 2021 Conference of the North
American Chapter of the Association for Com-
putational Linguistics: Human Language Tech-
47
nologies, pages 226–241, Online. Association
for Computational Linguistics. https://doi
.org/10.18653/v1/2021.naacl-main.22
Ilias Chalkidis, Abhik Jana, Dirk Hartung,
Ion Androutsopoulos,
Michael Bommarito,
Daniel Martin Katz, and Nikolaos Aletras.
2021b. LexGLUE: A benchmark dataset for
legal language understanding in English. arXiv.
https://doi.org/10.2139/ssrn.3936759
Benjamin Clavi´e and Marc Alphonsus. 2021.
The unreasonable effectiveness of the base-
line: Discussing SVMs in legal text classifica-
tion. arXiv. https://doi.org/10.3233
/FAIA210317
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
understanding. In Proceedings of
the 2019
Conference of the North American Chapter
of the Association for Computational Linguis-
tics: Human Language Technologies, Volume 1
(Long and Short Papers), pages 4171–4186,
for
Minneapolis, Minnesota. Association
Computational Linguistics.
Neil Duxbury. 2008. The Nature and Author-
ity of Precedent, chapter 4. Cambridge Uni-
versity Press. https://doi.org/10.1017
/CBO9780511818684
Kanstantsin Dzehtsiarou. 2017. What is law for
the European court of human rights. George-
town Journal of International Law, 49:89.
ECtHR. 2020. Overview of the case-law of the
ECHR. Annual Report 2020 of the European
Court of Human Rights, Council of Europe.
Ben Hachey and Claire Grover. 2006. Extractive
summarisation of legal texts. Artificial Intelli-
gence and Law, 14(4):305–345. https://doi
.org/10.1007/s10506-007-9039-z
D. Kehl and Samuel Ari Kessler. 2017. Algorithms
in the criminal justice system: Assessing the
use of risk assessments in sentencing. Espon-
sive Communities Initiative, Berkman Klein
Center for Internet & Society, Harvard Law
School.
Diederik P. Kingma and Jimmy Ba. 2015. Adam:
A method for stochastic optimization. In Pro-
ceedings of the 3rd International Conference
on Learning Representations (ICLR).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Fred Kort. 1957. Predicting supreme court deci-
sions mathematically: A quantitative analysis
of the ‘‘right to counsel’’ cases. American Po-
litical Science Review, 51(1):1–12. https://
doi.org/10.2307/1951767
Josef Valvoda, Oliver Ray, and Ken Satoh. 2018.
Using agreement statements to identify major-
ity opinion in UKHL case law. In Legal Knowl-
edge and Information Systems, pages 141–150.
IOS Press.
Grant Lamond. 2016. Precedent and analogy in
legal reasoning. In Edward N. Zalta, editor,
The Stanford Encyclopedia of Philosophy,
Spring 2016 edition. Metaphysics Research
Lab, Stanford University.
Reed C. Lawlor. 1963. What computers can
do: Analysis and prediction of judicial de-
cisions. American Bar Association Journal,
49(4):337–344.
Yonatan Lupu and Erik Voeten. 2010. The role
of precedent at the European court of human
rights: A network analysis of case citations.
OpenSIUC.
Alfredo Monroy, Hiram Calvo, and Alexander
Gelbukh. 2009. NLP for Shallow Question
Answering of Legal Documents Using Graphs.
volume 5449, pages 498–508. https://doi
.org/10.1007/978-3-642-00382-0 40
Stuart S. Nagel. 1963. Applying correlation anal-
ysis to case prediction. Texas Law Review,
42:1006.
Adam Paszke, Sam Gross, Francisco Massa,
Adam Lerer, James Bradbury, Gregory Chanan,
Trevor Killeen, Zeming Lin, Natalia Gimelshein,
Luca Antiga, et al. 2019. PyTorch: An imperative
style, high-performance deep learning library.
In Advances in Neural Information Processing
Systems, pages 8026–8037.
Josef Valvoda, Tiago Pimentel, Niklas Stoehr,
Ryan Cotterell, and Simone Teufel. 2021. What
about the precedent: An information-theoretic
analysis of common law. In Proceedings of
the 2021 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
pages 2275–2288, Online. Association for
Computational Linguistics. https://doi.org
/10.18653/v1/2021.naacl-main.181
Josef Valvoda and Oliver Ray. 2018. From case
law to ratio decidendi. In New Frontiers in
Artificial Intelligence, pages 20–34, Cham:
Springer International Publishing. https://
doi.org/10.1007/978-3-319-93794-6 2
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N.
Gomez, Łukasz Kaiser, and Illia Polosukhin.
2017. Attention is all you need. In Advances
in Neural Information Processing Systems,
pages 5998–6008.
Thomas Wolf, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue, Anthony
Moi, Pierric Cistac, Tim Rault, Remi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao,
Sylvain Gugger, Mariama Drame, Quentin
Lhoest, and Alexander Rush. 2020. Transform-
ers: State-of-the-art natural language process-
ing. In Proceedings of the 2020 Conference on
Empirical Methods in Natural Language Pro-
cessing: System Demonstrations, pages 38–45,
Online. Association for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2020.emnlp-demos.6
Chaojun Xiao, Haoxi Zhong, Z. Guo, Cunchao
Tu, Zhiyuan Liu, M. Sun, Yansong Feng,
Xianpei Han, Z. Hu, Heng Wang, and J. Xu.
2018. CAIL2018: A large-scale legal dataset for
judgment prediction. ArXiv, abs/1807.02478.
Nuo Xu, Pinghui Wang, Long Chen, Li Pan,
Xiaoyan Wang, and Junzhou Zhao. 2020. Dis-
tinguish confusing law articles for legal judg-
ment prediction. arXiv preprint arXiv:2004
.02557. https://doi.org/10.18653/v1
/2020.acl-main.280
Haoxi Zhong, Zhipeng Guo, Cunchao Tu,
Chaojun Xiao, Zhiyuan Liu, and Maosong Sun.
2018. Legal
judgment prediction via topo-
logical learning. In Proceedings of the 2018
Conference on Empirical Methods in Natu-
ral Language Processing, pages 3540–3549,
Brussels, Belgium. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D18-1390
Bostjan Zupancic. 2016. In the context of the
common law: The European court of human
rights in Strasbourg transcript. Transcript of a
lecture given at Gresham College.
48
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
2
2
0
6
7
8
3
8
/
/
t
l
a
c
_
a
_
0
0
5
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3