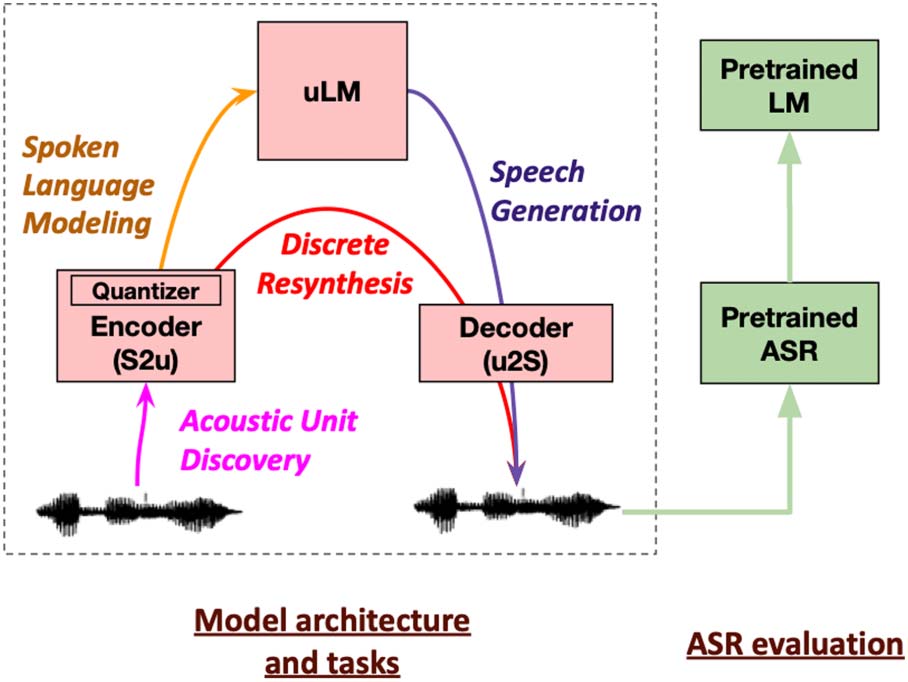
Sobre el modelado generativo del lenguaje hablado a partir de audio sin formato
Kushal Lakhotia∗ , Eugene Kharitonov∗, Wei-Ning Hsu, Yossi Adi, Adam Polyak,
Benjamin Bolte§, Tu-Anh Nguyen†, Jade Copet, Alexei Baevski,
Abdelrahman Mohamed, Emmanuel Dupoux‡
Facebook AI Research
textlessNLP@fb.com
Abstracto
We introduce Generative Spoken Language
Modeling, the task of learning the acoustic and
linguistic characteristics of a language from
raw audio (no text, no labels), and a set of
metrics to automatically evaluate the learned
representations at acoustic and linguistic lev-
els for both encoding and generation. Establecimos
up baseline systems consisting of a discrete
speech encoder (returning pseudo-text units), a
generative language model (trained on pseudo-
texto), and a speech decoder (generating a wave-
form from pseudo-text) all trained without
supervision and validate the proposed metrics
with human evaluation. Across 3 speech en-
codificadores (CPC, wav2vec 2.0, HuBERT), we find
that the number of discrete units (50, 100, o
200) matters in a task-dependent and encoder-
dependent way, and that some combinations
approach text-based systems.1
1
Introducción
An open question for AI research is creating sys-
tems that learn from natural interactions as infants
learn their first language(s): from raw uncurated
datos, and without access to text or expert labels
(Dupoux, 2018). Natural Language Processing
(NLP) systems are currently far from this re-
quirement. Even though great progress has been
made in reducing or eliminating the need for ex-
pert labels through self-supervised training obj-
ectives (Brown y cols., 2020; Peters et al., 2018;
Radford et al., 2019; Devlin et al., 2019; Liu et al.,
2019b; Dong et al., 2019; Lewis et al., 2020), el
basic units on which these systems are trained are
still textual. Young children learn to speak several
∗Equal contribution. ‡ Also at EHESS. † Also at INRIA.
§Work done while at FAIR.
1Evaluation code and trained models are here: https://
github.com/pytorch/fairseq/tree/master/examples
/textless nlp/gslm. Sample examples are here: https://
speechbot.github.io/gslm.
years before they can read and write, providing
a proof of principle that language can be learned
without any text. Being able to achieve ‘textless
NLP’ would be good news for the majority of the
world’s languages, which do not have large textual
resources or even a widely used standardized or-
thography (Swiss German, dialectal Arabic, Igbo,
etc.), y cual, despite being used by millions of
users, have little chance of being served by cur-
rent text-based technology. It would also be good
for ‘high-resource’ languages, where the oral and
written forms often mismatch in terms of lexicon
and syntax, and where some linguistically rele-
vant signals carried by prosody and intonation are
basically absent from text. While text is still the
dominant form of language present on the web,
a growing amount of audio resources like pod-
casts, local radios, social audio apps, online video
games provide the necessary input data to push
NLP to an audio-based future and thereby expand
the inclusiveness and expressivity of AI systems.
Is it possible to build an entire dialogue sys-
tem from audio inputs only? This is a difficult
challenge, but breakthroughs in unsupervised
representation learning may address part of it. Y-
supervised learning techniques applied to speech
were shown to learn continuous or discrete repre-
sentations that capture speaker invariant phonetic
contenido (Versteegh et al., 2016; Dunbar et al.,
2020), despite themselves not being phonemic
(Schatz et al., 2021). Recent developments in
self-supervised learning have shown impressive
results as a pretraining technique (van den Oord
et al., 2017; Chung et al., 2019; Hsu et al., 2021),
to the extent that Automatic Speech Recognition
(ASR) on par with the state of the art from two
years back can be built with 5000 times less la-
belled speech (Baevski et al., 2020b), or even
no with no labelled speech at all (Baevski et al.,
2021). Por supuesto, ASR still assumes access to text
to learn a language model (LM) and the mapping
1336
Transacciones de la Asociación de Lingüística Computacional, volumen. 9, páginas. 1336–1354, 2021. https://doi.org/10.1162/tacl a 00430
Editor de acciones: Richard Sproat. Lote de envío: 6/2021; Lote de revisión: 8/2021; Publicado 12/2021.
C(cid:3) 2021 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
to the learning objectives like perplexity or log
likelihood. Aquí, such an approach is not directly
applicable even if we rely on discrete pseudo-text
units, since such metrics would depend in an
unknown fashion on their granularity (number, du-
ration, and distribution), making the comparison
of models that use different units infeasible.
Conceptually, generative spoken language mod-
els can be evaluated at two levels, the acoustic and
the language levels, and through two modes of op-
eration, encoding and generation, resulting in 2×2
tareas (ver tabla 1 y figura 1). Acoustic Unit
Descubrimiento (encoding at the acoustic level) consists
of representing speech in terms of discrete units
discarding non-linguistic factors like speaker and
ruido. Spoken Language Modeling (encoding at
the language level) consists of learning the prob-
abilities of language patterns. Speech Resynthesis
(generation for acoustic modeling) consists of gen-
erating audio from given acoustic units. This boils
down to repeating in a voice of choice an input lin-
guistic content encoded with speech units. Discurso
Generación (generation for language modeling)
consists of generating novel and natural speech
(conditioned on some prompt or not). Compared
to standard text generation, a critical and novel
component of the audio variant is clearly the dis-
covery of units since it conditions all the other
componentes. This is why we devote our analyses
of model architectures to the unit-to-speech com-
ponent specifically, and leave it for further work
to evaluate how the downstream components can
also be optimized for spoken language generation.
The major contributions of this paper are as
follows: (1) We introduce two novel evaluation
metrics for the generation mode of spoken lan-
the acoustic and language
guage modeling at
levels respectively. Our key insight
is to use
a generic pretrained ASR system to establish
model-independent assessments of the intelligibil-
idad (acoustic level) and meaningfulness (idioma
nivel) of the produced outputs. The ASR system
converts the generated waveform back to text,
enabling us to adapt standard text-based metrics
for these two levels. (2) We validate these met-
rics through comparison with human evaluation.
We show a high degree of concordance between
human and machine evaluations of intelligibility
and meaningfulness of generated audio. (3) Nosotros
show that these metrics can be predicted by sim-
pler ones geared to evaluate the encoding mode of
the spoken LM. Zero-shot metrics borrowed from
Cifra 1: Setup of the baseline model architecture,
tareas, and metrics.
to the audio units. Aquí, we study the case where
the LM is directly trained from the audio units
without any recourse to text.
The high level idea (ver figura 1) is that auto-
matically discovered discrete units can be used to
encode speech into «pseudo-text» (speech-to-unit,
S2u), which is used in turn to train a generative lan-
guage model (unit-based language model, uLM)
and to train a speech synthesizer (unit-to-speech,
u2S). This enables learning an LM from scratch
without text, and use it to generate speech condi-
tionally or unconditionally, essentially replicating
what toddlers achieve before learning to read.
Early studies using discrete codes learned from
an autoencoder show the feasibility of such an
acercarse, but remain at a level of a demo (van den
Oord et al., 2017).
en este documento, we address one major conceptual
stumbling block which has, thus far, prevented
such early studies from having the transformative
impact they could have in language technology:
model evaluation. We contend that it will be
impossible to make progress in this area beyond
demos unless proper evaluation methods enabling
system comparison are etablished.
Evaluation for speech generation is difficult due
to the continuous, variable and multi-level nature
of the speech waveform, and the necessity both to
capture fine grained acoustic details to generate in-
telligible audio and to abstract away from them to
learn higher level language concepts. Text-based
models do not have this problem, since the in-
put is already expressed in terms of mid-level
discrete units (characters or words), and are typ-
ically evaluated with unsupervised metrics close
1337
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Nivel
Tarea
Automatic metric
Tarea
Encoding
Generación
Automatic metric
Language Spoken
LM
Spot-the-word,
Syntax-Acc
Discurso
generación.
AUC-of-VERT/PPX, cont-
AZUL, PPX@o-VERT
Acoustic
Acoustic
Unit Disc.
ABX-across,
ABX-within
Resynthesis PER-from-ASR,
CER-from-ASR
Humano
MMOS
CER,
MOS
Mesa 1: Tasks and metrics proposed to evaluate encoding/generation quality of models at the acoustic
or language levels. Bold fonts highlights the main metric used for each category (Sección 3 for details).
previous studies in the Zero Resource Speech
Challenges (Versteegh et al., 2016; Nguyen et al.,
2020) correlate well with their generative counter-
part, offering an easier proxy to rapidly iterate on
model selection. (4) We systematically study the
effect of the type of encoding units by factorially
crossing three recent speech-to-unit encoders—
CPC, Wave2vec 2.0, and HuBERT—with three
codebook sizes for the discrete units: 50, 100, 200.
We keep constant the rest of the system built from
out-of-the-box components (standard Transformer
for the uLM, Tacotron 2 for u2S). Nosotros mostramos que
both the encoder type and the number of units mat-
ter, and that they matter differently depending on
the evaluation task. (5) We open source our evalu-
ation tools and models to help reproducibility and
comparability with future work.
En la sección 3, we introduce the ASR, zero-shot
and human evaluation metrics, en la sección 4 we pre-
sent the models, en la sección 5, we analyze the re-
sults and discuss them in Section 6.
2 Trabajo relacionado
Unsupervised Speech Representation Learning
aims to distill features useful for downstream
tareas, such as phone discrimination (Kharitonov
et al., 2021; Schneider et al., 2019) and semantic
predicción (Lai et al., 2021; Wu et al., 2020), por
constructing pretext tasks that can exploit large
quantities of unlabeled speech. Pretext tasks in
the literature can be roughly divided into two
categories: reconstruction and prediction. reconocimiento-
struction is often implemented in the form of
auto-encoding (Hsu et al., 2017a), where speech
is first encoded into a low-dimensional space, y
then decoded back to speech. Various constraints
can be imposed on the encoded space, como
temporal smoothness (Ebbers et al., 2017; Glarner
et al., 2018; Khurana et al., 2019, 2020), discreto-
ness (Ondel et al., 2016; van den Oord et al.,
2017), and presence of hierarchy (Lee and Glass,
2012; Hsu et al., 2017b).
Prediction-based approaches which task a mod-
el to predict information of unseen speech based
on its context, have gained increasing interest re-
cently. Examples of information include spectro-
gramos (Chung et al., 2019; Wang y cols., 2020; Chi
et al., 2021; Liu et al., 2020; Chung and Glass,
2020; Liu et al., 2020; Ling et al., 2020; Abadejo
and Liu, 2020), cluster indices (Baevski et al.,
2019; Hsu et al., 2021), derived signal processing
características (Pascual et al., 2019; Ravanelli et al.,
2020), and binary labels of whether a candidate
is the target unseen spectrogram (van den Oord
et al., 2018; Schneider et al., 2019; Baevski et al.,
2020a; Kharitonov et al., 2021; Baevski et al.,
2020b).
Speech Resynthesis. Recent advancements in
neural vocoders enabled generating natural sound-
ing speech and music (Oord et al., 2016; Kumar
et al., 2019; Kong et al., 2020). These are often
conditioned on the log mel-spectrogram for the
generation process. Learning low bitrate speech
representations in an unsupervised manner has
attracted attention from both the machine learn-
ing and the speech communities (Liu et al., 2019a;
Feng et al., 2019; Nayak et al., 2019; Tjandra et al.,
2019; Schneider et al., 2019; Baevski et al., 2020a;
Chen and Hain, 2020; Morita and Koda, 2020;
Tobing et al., 2020). These representations can
later be used for generation without text, cual es
particularly important for low-resource languages
(Dunbar et al., 2019, 2020). van den Oord et al.
(2017) proposed a Vector-Quantized Variational
Auto-Encoder (VQ-VAE) model to learn discrete
speech units, which will be later used for speech
synthesis using a WaveNet model. Eloff et al.
(2019) suggested a VQ-VAE model followed
by a FFTNet vocoder model (Jin et al., 2018).
Tjandra et al. (2020) suggested using transformer
1338
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(Vaswani et al., 2017) together with a VQ-VAE
model for unsupervised unit discovery, and van
Niekerk et al. (2020) combines vector quanti-
zation together with contrastive predictive coding
for acoustic unit discovery. Another line of work
uses representations from an ASR acoustic model
that are combined with identity and prosodic
information for voice conversion (Polyak et al.,
2020b,a, 2021b). In terms of evaluation, the Zero-
Resource challenge (Dunbar et al., 2019, 2020;
Nguyen et al., 2020) used bitrate together with
human evaluation. In this paper we additionally
introduce an ASR based evaluation metric.
3 Evaluation Methods
We present two sets of automatic evaluation met-
rics; the first one assesses the output of generative
speech models (ASR metrics, Sección 3.1); the sec-
ond one, the encoded representations (zero-shot
probe metrics, Sección 3.2). Finalmente, we present
the human evaluations (Sección 3.3).
3.1 Generación: ASR Metrics
We present our new evaluation metrics for gen-
eration tasks. The first task, speech resynthesis,
involves S2u, which encodes input speech into
units and u2S, which decodes it back to speech. En
this task, we wish to evaluate intelligibility of the
resulting speech. The second task, speech genera-
ción, involves the full S2u→uLM→u2S pipeline,
and we wish to evaluate meaningfulness of the
generated speech. Our overall idea is to use ASR
to convert the generated speech back to text and
then use text-based metrics.
Speech Resynthesis Intelligibility: ASR-PER.
The ideal metric for intelligibility would be to use
humans to transcribe the resynthesized speech and
compare the text to the original input. An auto-
matic proxy can be obtained by using a state-of-
the-art ASR system pretrained on a large corpus
of real speech.2 Our main metric is Phone Error
Rate (PER), which only uses an acoustic-model
ASR, without fusing with an additional language
modelo (Chorowski and Jaitly, 2016). In prelim-
inary experiments we also experimented with a
full ASR with an LM and computed Word Error
Rate (WER) and Character Error Rate (CER) a
give partial credit. The latter is probably closer
to human intelligibility metrics, as humans cannot
turn off their lexicon or language model. Nosotros también
computed such metrics by training a fitted ASR
model for each resynthesis model on a specific
training corpus. The logic of this last test is that it
provides a more direct measure of the information
lost in the S2u→u2S pipeline, because it could
adapt to systematic errors introduced by the u2S
modelo. Since the scores between these different
approaches correlated highly, we only report here
the results on the PER for a pretrained ASR model
that is the simplest to deploy.
Speech Generation Quality and Diversity: AUC
on Perplexity and VERT. Text generation eval-
uation typically involves two axes: the quality of
el texto generado (with automatic metrics like
mean perplexity or negative log likelihood com-
puted on a reference large language model) y el
diversity (with metrics like self-BLEU;3 Zhu et al.,
2018). Typically, there is a trade-off between these
two dimensions based on the temperature hyper-
parameter used for sampling from the language
modelo, whereby at low temperature, the system
outputs good sentences but not varied, and at
high temperatures, it outputs varied sentences, pero
not very good. This results in model compari-
son being either based on 2D plots with lines
representing the trade-off between quality and di-
versity, or on aggregate metrics like the area under
the curve. Preliminary explorations (see Appendix
Sección 7.2) with our models revealed two prob-
lems preventing a straightforward application of
such a scoring strategy.
Primero, we found that for some models, at a low
enough temperature, self-BLEU score stopped in-
creasing, but the systems started to repeat more and
more words within a sentence (p.ej., ‘‘the property
the property the property’’). We therefore intro-
duce a new metric, auto-BLEU, that measures
within-sentence diversity. For a single utterance
tu, auto-BLEU is calculated as the ratio of k-grams
s ∈ N Gk(tu) that are repeated at least once:
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(cid:2)
auto-BLEU(tu, k) =
s 11 [s ∈ (N Gk(tu)\s)]
|N Gk(norte)|
As with BLEU score,
(1)
to obtain n-gram
auto-BLEU we calculate the geometric mean of
auto-BLEU(tu, k) obtained for k ∈ [1, norte] y
average over the set of generated utterances. Por
2We use a BASE wav2vec 2.0 phoneme detection model
3Higher self-BLEU scores indicate lower diversity of the
trained on LibriSpeech-960h with CTC loss from scratch.
produced text.
1339
We entirely draw on evaluations from the Zero
Resource challenge series (Versteegh et al., 2016;
Dunbar et al., 2019; Nguyen et al., 2020)6 for com-
parability with published work and refer to these
challenges for details. These metrics are ‘‘zero-
shot’’ because they do not require training any
classifier, and are either based on distances over
embeddings, or on computing probabilities over
entire utterances. When they have hyperparam-
eters, these are selected using a validation set.
For acoustic-level evaluation, we use the
between-speaker ABX score to quantify how
well-separated phonetic categories are. Brevemente,
it consists of estimating the probability that two
tokens of the same category A (x and a) are closer
to one another than a token of A (X) and of B (b).
The categories are triphones that only differ in the
middle phoneme (like bit and bet) and the score
is averaged over all possible such pairs. Para el
across-speaker ABX, a and b are spoken by the
same speaker and x by a different one, requiring
feature invariance over a speaker change. Nosotros también
include the bitrate, which has been used in the
TTS-without-T challenges (Dunbar et al., 2019)
to quantify the efficiency of the discrete units used
to resynthetize speech. It is simply the entropy of
the sequence of units divided by the total duration.
For language-level evaluation, we use spot-
the-word accuracy from the Zero Resource 2021
Benchmark (Nguyen et al., 2020). It consists of
detecting the real word from a pair of short utter-
ances like ‘brick’ vs. ‘blick’, matched for unigram
and bigram phoneme frequency to ensure that
low-level cues do not make the task trivial. Este
task can be done by computing the probability
(or pseudo-probability) of the utterances from the
uLM. The test set (sWUGGY) consists of 5,000
word-pseudoword pairs generated by the Google
TTS API, filtered for the word being present
in the LibriSpeech 960h training set (Panayotov
et al., 2015). The ZR21 benchmark also uses
higher level metrics, notably, syntactic (based
on the sBLIMP dataset), which we did not use
because the baselines were too close to chance.
3.3 Human Evaluation Metrics
As above, we asked humans to evaluate two
aspects of speech generation: intelligibility and
meaningfulness. Intelligibility was assessed using
two metrics: i) Mean Opinion Scores (MOS) en
6www.zerospeech.com.
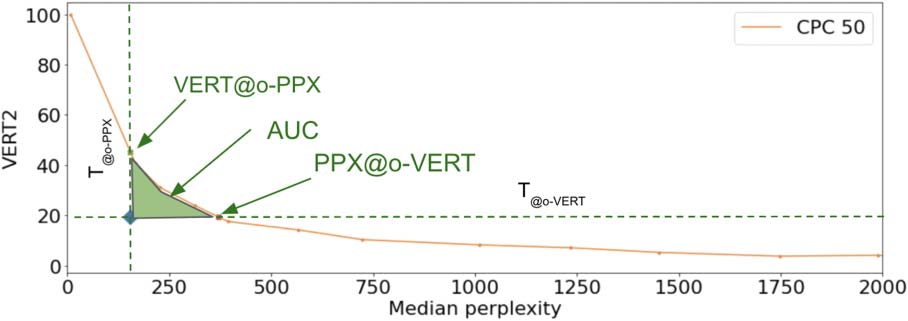
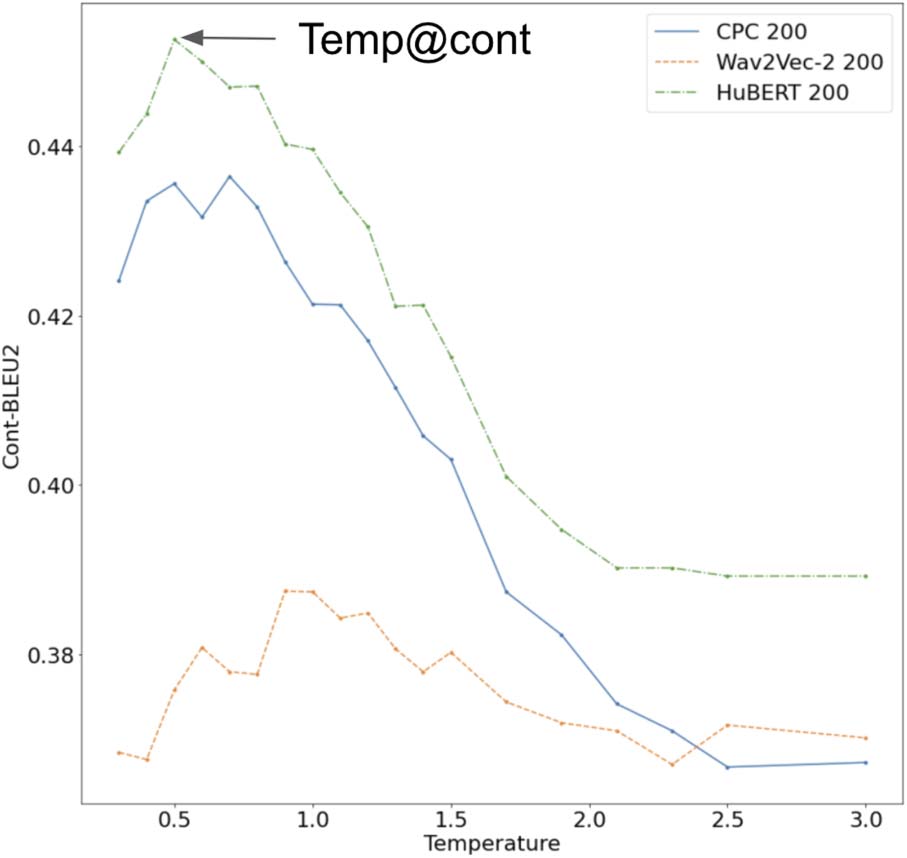
Cifra 2: Comparison of diversity and perplexity
of the generated speech. We plot VERT vs. Median
perplexity. The blue diamond corresponds to the oracle
reference point. It defines two cut-offs on the curve:
VERT @oracle-PPX and PPX @oracle-VERT. El
green area corresponds to the AUC metric.
calculating the geometric mean of self- and auto-
AZUL, we obtain an aggregate metric which we
call VERT (for diVERsiTy). We used a bigram
version of self- and auto-BLEU.
Segundo, we found that critical temperatures for
which the output was reasonable were not con-
stant across models. This makes sense, porque
temperature controls the probability of sampling
individual units, and the probabilistic distribution
and duration of these units depend on the models.
Aquí, we chose to use the oracle text as an anchor
to compute reference temperatures, eso es, el
temperatures at which the perplexity or the VERT
score reach the values of the oracle text.
This gives us boundary conditions at which we
can compare (the perplexity at oracle diversity
and the diversity at oracle perplexity), así como
a method to compute the area under curve (AUC)
between these two boundaries (ver figura 2). Como
AUC decreases, the system gets closer to the ora-
cle point. Thus with AUC, lower is better.
To calculate perplexity of the generated ut-
terances, we use a pre-trained ASR4 to convert
speech to text, and an off-the-shelf Transformer
model trained on the English NewsCrawl dataset.5
3.2 Encoding: Zero-shot Probe Metrics
The purpose of the encoding metrics is to eval-
uate the quality of the learned representations at
each linguistic level along the pipeline linking the
S2u and the uLM. They are inspired by human
psycholinguistics and can be be thought of as
unit tests providing interpretation and diagnosis.
4We use a LARGE wav2vec 2.0 modelo,
trained on
LibriSpeech-960h with CTC loss from scratch. Its decoder
uses the standard KenLM 4-gram language model.
5https://github.com/pytorch/fairseq/tree
/master/examples/language model.
1340
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
which raters were asked to evaluate subjectively
how intelligible a given audio sample is; y
ii) Character Error Rate (CER) computed from
written transcriptions providing an objective in-
telligibility test. As for meaningfulness, we set up
a meaningfulness-MOS (MMOS) in which raters
were asked to evaluate how natural (considering
both grammar and meaning) a given sample is. Para
both subjective tests, raters evaluate the samples
on a scale of 1–5 with an increment of 1.
For the MMOS, we had to select a temperature
to sample from. Preliminary experiments showed
that humans preferred lower temperatures (producir-
ing also less diverse outputs). Aquí, we settled on
selecting the temperature on a model-by-model
basis by constructing a continuation task: We take
el 1,000 shortest utterances from LibriSpeech
test-clean that are at least 6 seconds long, y
use the first 3 seconds as prompts for the uLM
(after transcribing them into pseudo-texts). Para
each prompt, we generated 10 candidate continua-
tions of the same length (in seconds) as the utter-
ance which we took the prompt from. We varied
. . . , 1.4, 1.5, 1.7, 1.9,
temperatura (0.3, 0.4,
2.1, 2.3, 2.5, 3.0), and selected the one yielding
the maximal BLEU-2 score with the reference
oración (after ASR). These temperatures were
typically between the two boundary temperatures
described above.
We evaluated 100 samples from each of the
evaluated methods while we enforced at least 15
raters for each sample. The CrowdMOS package
(Ribeiro et al., 2011) was used for all subjective
experiments using the recommended recipes for
detecting and discarding inaccurate scores. El
recordings for the naturalness test were generated
by the LM unconditionally and conditionally from
a 3 seconds prompt. Participants were recruited
using a crowd-sourcing platform.
4 Proposed Systems
Aquí, we present our S2u (Sección 4.1), uLM
(Sección 4.2), and u2S (Sección 4.3) componentes.
4.1 Speech-to-Unit Models
We selected 3 recent state-of-the-art unsupervised
Encoders, which we used ‘out of the box’: we did
not retrain them nor change their hyperparameters.
We also included a log Mel filter-bank baseline
(80 filters, computed every 10 EM). We then dis-
cretized the embeddings using k-means. We only
give a high level description of these models, y
refer to the original publications for details.
CPC. Contrastive Predictive Coding (van den Oord
et al., 2017) as applied to speech consists of
two components: an encoder and a predictor. El
encoder produces an embedding z from speech
aporte. The predictor predicts the future states
of the encoder based on the past, and the system
is trained with a contrastive loss. We use the CPC
model from Rivi`ere and Dupoux (2020), cual
was trained on a ‘‘clean’’ 6k hour sub-sample
of the LibriLight dataset (Kahn et al., 2020;
Rivi`ere and Dupoux, 2020). We extract a represen-
tation from an intermediate layer of the predictor,
which provides a 256-dimensional embedding
(one per 10ms), as in the original paper.
wav2vec 2.0. Similar to CPC, this model uses
an encoder and a predictor, which is trained con-
trastively to distinguish positive and negative
samples from discretized and masked segments
of the encoder’s output. We use the LARGE vari-
ant of pretrained wav2vec 2.0 (Baevski et al.,
2020b) trained on 60k hours of LibriLight dataset
(Kahn et al., 2020). This model encodes raw au-
dio into frames of 1024-dimensional vectors (uno
per 20ms). To choose the best layer, we extracted
frozen representations of the 10-hour LibriLight
subset from every layer of the model and trained
a linear classifier with the CTC loss to predict the
phonetic version of the text labels. Layer 14 transmisión exterior-
tained the lowest PER on LS dev-other (a similar
approach was done in Baevski et al. [2021], cual
in this case selected Layer 15).
HuBERT. Unlike CPC and wav2vec 2.0 eso
use a contrastive loss, HuBERT is trained with a
masked prediction task similar to BERT (Devlin
et al., 2019) but with masked continuous audio
signals as inputs. The targets are obtained through
unsupervised clustering of raw speech features or
learned features from earlier iterations, motivated
by DeepCluster (Caron et al., 2018). We use the
BASE 12 transformer-layer model trained for two
iterations (Hsu et al., 2021) en 960 hours of
LibriSpeech (Panayotov et al., 2015). This model
encodes raw audio into frames of 768-dimensional
vectores (one per 20 EM) at each layer and we extract
those from the 6th layer as in the original paper.
LogMel. As a baseline, we consider a Log Mel
Filterbank encoder using 80 frequency bands.
1341
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Quantization. We use k-means to convert con-
tinuous frame representations into discrete repre-
sentation by training on LibriSpeech clean-100h
(Panayotov et al., 2015). We experiment with
codebooks that have 50, 100, y 200 units.
4.2 Unit-Language Model
We use the Transformer model as implemented
in fairseq (Ott et al., 2019). We use the trans-
former lm big architecture: Tiene 12 capas, 16
attention heads, embedding size of 1024, FFN size
de 4096, and dropout probability of 0.1, and we
train it as a causal LM on sequences of pseudo-text
units. Each sample contains up to 3,072 units. Nosotros
use sampling with temperature for generation.
All language models are trained on a ‘‘clean’’
6k hours sub-sample of LibriLight used in
(Rivi`ere and Dupoux, 2020),
transcribed with
corresponding discrete units. In preliminary ex-
perimentos, we found that removing sequential rep-
etitions of units improves performance, hence we
apply it universally.7 We hypothesize that this sim-
ple modification allows us to use Transformer’s
limited attention span more efficiently, as in Hsu
et al., 2020.
4.3 Unit-To-Speech Model
We adapt the Tacotron-2 model (Shen et al., 2018)
such that it takes pseudo-text units as input and
outputs a log Mel spectrogram. To enable the
model to synthesize arbitrary unit sequences, en-
cluding those representing incomplete sentences,
we introduce two modifications. Primero, we append
a special ‘‘end-of-input’’ (EOI) token to the in-
put sequence, hinting the decoder to predict the
‘‘end-of-output’’ token when attending to this new
simbólico. Sin embargo, this modification alone may not
be sufficient, as the decoder could still learn to
ignore the EOI token and correlate end-of-output
prediction with the learned discrete token that
represents silence as most of the speech contains
trailing silence. To address this, we train the model
using random chunks of aligned unit sequence and
spectrogram, and append the EOI token to unit se-
quence chunks, such that the audio does not always
end with silence. We implement chunking in the
curriculum learning fashion, where the chunk size
gradually grows (starting with 50 frames with an
incremento de 5 per epoch) to increase the diffi-
7Por ejemplo, a pseudo-text 10 11 11 11 21 32
32 32 21 becomes 10 11 21 32 21.
culty of the task. For waveform generation, we use
the pre-trained flow-based neural vocoder Wave-
Glow (Prenger et al., 2019). This model outputs
the time-domain signal given the log Mel spectro-
gram as input. All u2S models were trained on LJ
Discurso (LJ) (Ito and Johnson, 2017).
5 Resultados
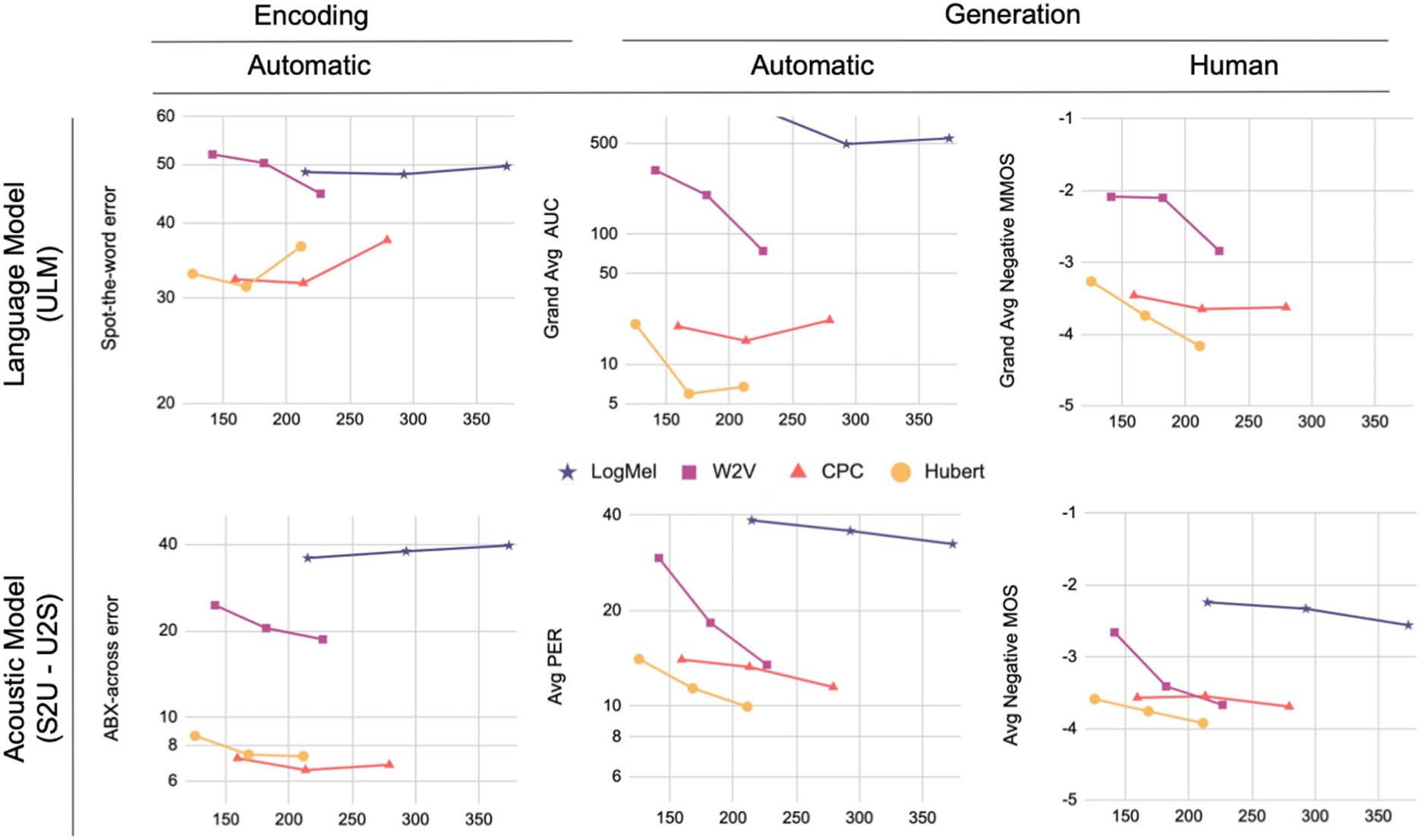
En figura 3, we report the overall results of our
models and our LogMel baseline as a function of
the number of quantized units on our main auto-
mated and human metrics. More detailed results
follow in the following sections, including two
character-based toplines: one uses the oracle tran-
scripts for training the LM, the other uses tran-
scripts produced by the pre-trained ASR model.
5.1 Results on the Resynthesis Task
Overall resynthesis results are shown in the bot-
tom middle and right cells of Figure 3 for our
main automatic (PER) and human scores (MOS),
respectivamente, averaged across the LS and LJ eval-
uation sets. We observe that across all models,
increasing the number of units uniformly leads
to better scores suggesting that the u2S compo-
nent can take benefit from extra details of the
input to produce a more realistic output. HuBERT
and CPC seem to be giving the best results, para
both humans and models better capturing pho-
netic information than other models at equival-
ent bitrates.
More detailed results are in Table 2, separat-
ing the scores for the LJ and LS resynthesis, y
adding extra automatic metrics (CER) and human
métrica (human CER). On PER, we found a do-
main effect: Resynthesizing input from LJ Speech
yields lower PER than from LibriSpeech on all
unsupervised models. From the viewpoint of the
encoder, LJ Speech is out-of-domain; por lo tanto,
one would expect that the units are making more
errors than for the trained LibriSpeech. Sobre el
other hand, the u2S component has learned from
LJ Speech encoded with these units, and might
have learned to compensate for these lower qual-
ity units. When LibriSpeech is offered as input,
the u2S component cannot adapt to this nominally
better input and ends up yielding lower quality
1342
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 3: Overall results with automatic and human metrics. The results are presented in terms of bitrate for 4
encoders (LogMel, CPC, HuBERT, and wav2vec 2.0) varying in number of units (50, 100, 200). For definition of
the tasks and metrics, ver tabla 1 y figura 1. Negative human opinion scores are shown for ease of comparison
with automatic metrics (lower is better). The generation metrics have been averaged across LS and LJ (PER and
MOS; resynthesis task) and across prompted and unprompted conditions (AUC and MMOS; speech generation
tarea). The Log Mel Fbank based systems were not evaluated by humans in the speech generation task.
outputs. This observation is worth further explo-
ration, as other metrics like CER (using an LM)
and human evaluations only replicated this for the
models with the lowest score (like LogMel and
wav2vec). The automatic PER and CER scores
and the human MOS and CER scores all correlate
well with one another across the 4 × 3 models and
baselines. Within the LJ or LS domain, the Pear-
son r ranged from .95 a .99; across domains it was
less good (de .79 a .96), illustrating again the
existence of a domain effect. Not shown here, nosotros
reached similar conclusions with our fitted-ASR
métrica, but with less good score and correlations.
Mesa 2 also shows the results of the two toplines
(original text+TTS and ASR+TTS). Curiosamente,
our best models come within 3% absolute in PER
or CER compared to these toplines, are quite close
to them in terms of MOS and even beat them in
terms of human CER.
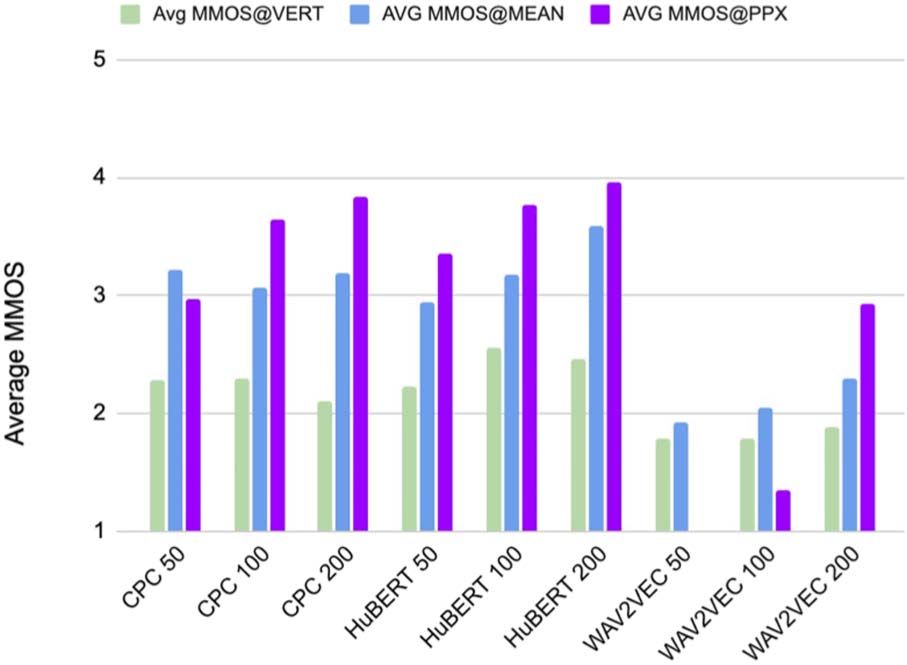
5.2 Results on the Generation Task
The upper mid and right cells of Figure 3 espectáculo
generation results averaging across the uncondi-
tional and conditional conditions, on automatic
and human evaluations, respectivamente. The main
result is that there is both an effect of number of
units and of system. As for resynthesis, 50 units is
always worst, but contrary to resynthesis, 200 units
is not always better. En general, the results on gen-
eration are congruent with the idea that speech
generation both requires good scores on language
modeling and on speech synthesis. The best re-
sults for a particular model are then a compromise
between the number of units that give both scores
to either of these tasks. In terms of systems, el
best one here is HuBERT. Regarding human eval-
uations, they show similar patterns with a clear
dispreference for 50 units, and either 100 o 200
being better.
Detailed results are shown in Table 3 con
separate statistics for conditional and uncon-
ditional generation and additional results with
PPX@o-VERT and VERT@o-PPX. As expected,
the perplexity metric improved with prompts, pero
not the diversity score. The human results are
congruent with the automatic scores, a pesar de
they tend to prefer more units, perhaps showing
that they cannot fully dissociate their judgment
1343
Sistemas
S2u
architect.
Toplines
original wav
orig text+TTS
ASR + TTS
Líneas de base
LogMel
LogMel
LogMel
Unsupervised
CPC
CPC
CPC
HuBERT-L6
HuBERT-L6
HuBERT-L6
wav2vec-L14
wav2vec-L14
wav2vec-L14
Nb
units
Bit-
tasa
27
50
100
200
50
100
200
50
100
200
50
100
200
214.8
292.7
373.8
159.4
213.1
279.4
125.7
168.1
211.3
141.3
182.1
226.8
End-to-end ASR-based metrics
PER↓ PER↓ CER↓ CER↓ MOS↑ MOS↑ CER↓ CER↓
(LS)
(LJ)
Human Opinion
(LS)
(LS)
(LS)
(LJ)
(LJ)
(LJ)
–
7.78
9.45
27.72
25.83
19.78
10.87
10.75
8.74
11.45
9.53
8.87
24.95
14.58
10.65
–
7.92
8.18
49.38
45.58
45.16
17.16
15.82
14.23
16.68
13.24
11.06
33.69
22.07
16.34
–
8.87
9.48
27.73
24.88
17.86
10.68
9.84
9.20
11.02
9.31
8.88
25.42
13.72
10.21
–
5.14
5.30
52.05
48.71
46.12
12.06
9.46
8.29
11.85
7.19
5.35
32.91
17.22
10.50
4.83
4.02
4.04
2.41
2.65
2.96
3.63
3.42
3.85
3.69
3.84
4.00
2.45
3.50
3.83
4.30
4.03
4.06
2.07
2.01
2.16
3.51
3.68
3.54
3.49
3.68
3.85
2.87
3.32
3.51
8.88
13.25
15.98
43.78
37.39
23.33
13.97
13.53
9.36
14.54
13.02
11.67
46.82
23.76
13.14
6.73
10.73
11.56
66.75
62.72
62.6
19.92
14.73
14.33
13.14
11.43
10.84
54.9
28.1
15.27
Mesa 2: Results on the resynthesis task for 3 unsupervised models plus one LogMel baseline and 3
unit sizes. Bitrates are in bit/sec, PER are for a pretrained phone recognition model without lexicon and
LM, CER are derived from a full ASR model (lower is better). Human MOS (upper is better) and CER
(computed from transcription, lower is better) are provided (el 95% confidence interval was on average
.32 for MOS and 1.8 for human CER).
of meaning from their judgment of intelligibility.
The three metrics correlate well with one another
(r between .86 y .99) and correlate with their
counterpart across task (prompted vs. unprompted:
r between .82 y .99). Human evaluations cor-
related well with the automatic metrics (AUC:
r= .87; PPX: r= .92; VERT: r= 0.75).
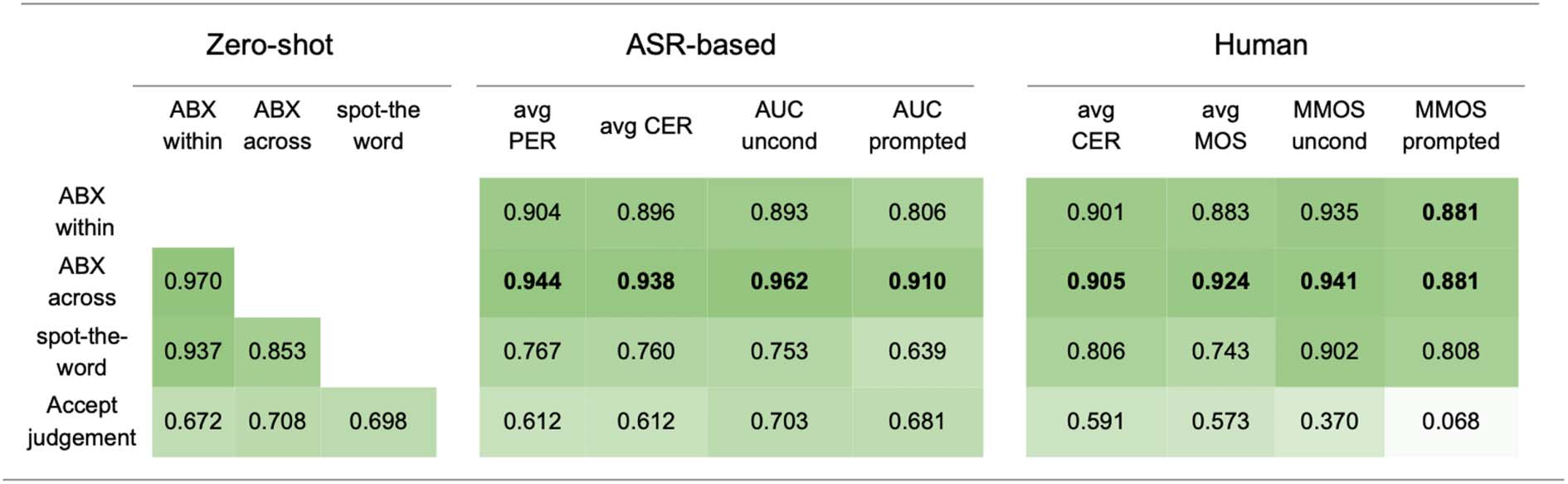
5.3 Results for Zero-shot Probe Metrics
En mesa 4, we show the results for zero-shot
metrics across the different models and baselines.
En general, the performance depends on the linguistic
levels while remaining above chance. While per-
formance is excellent at the acoustic level (6.5%
error for the best model on ABX-across), es
intermediate at the lexical level (31.3% error for
the best model on spot-the-word). Not shown,
the syntactic test is close to chance (42% error
for the best model on the sBLIMP test). Estos
values are worse than the ASR-topline (3.1% y
29%, for lexicon and syntax, resp.), showing room
for improvement.
The metrics correlate well: The ABX score
predicts the lexical score (r= 0.85) y el
syntax score (r= 0.71). Across the different
modelos, CPC gets the best units (ABX score) y
HuBERT gets the best LM scores. Además, nosotros
see a clear effect of number of units (Cifra 3). Para
wav2vec, the performances on all metrics increase
with more units, mientras, for CPC and HuBERT
a U-shaped pattern emerges on most metrics, con
best scores for units of intermediate sizes. Es
interesting that the models with the highest bitrate
do not always have the best results. This means
that encoding too much acoustic information can
be detrimental to linguistic encoding in the uLM.
See Appendix Section 7.1 showing that ABX
has good correlations with automatic and human
métrica (r > .88).
6 Discusión y conclusión
We introduced Generative Spoken Language Mod-
eling as a new unsupervised task bridging the gap
between speech and natural language processing
1344
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Sistemas
Encoder
architect.
Control S
oracle text
ASR + LM
Base
LogMel
LogMel
LogMel
Unsupervised
CPC
CPC
CPC
HuBERT-L6
HuBERT-L6
HuBERT-L6
wav2vec-L14
wav2vec-L14
wav2vec-L14
Generation based metrics
Human Opinion
Nb
units
unconditional
VERT↓
AUC↓
PPX↓
prompt
PPX↓ VERT↓
prompt
uncond.
AUC↓ MMOS↑ MMOS↑
154.5
178.4
1588.97
1500.11
1539.00
374.26
349.56
362.84
376.33
273.86
289.36
936.97
948.96
538.56
19.43
21.31
–
95.50
–
46.26
41.797
40.28
43.06
31.36
33.04
–
79.51
61.06
50
100
200
50
100
200
50
100
200
50
100
200
–
0.18
154.5
162.8
19.43
20.49
–
0.04
4.02
3.91
4.26
4.38
1083.76
510.26
584.16
–
–
–
19.68
15.74
16.46
19.27
5.54
7.49
307.91
208.38
61.48
323.9
294.7
303.5
339.8
251.2
262.4
1106.3
775.1
585.8
–
–
–
39.92
42.93
43.42
45.85
33.67
34.30
–
–
–
–
–
–
18.44
14.06
26.67
21.03
5.88
6.13
330.8
205.7
91.07
–
–
–
3.31
3.65
3.58
3.53
3.95
4.01
2.26
2.28
2.64
–
–
–
3.61
3.65
3.67
3.00
3.53
4.32
1.91
1.92
3.04
Mesa 3: Results on the generation task for three unsupervised models plus the LogMel baseline and
3 unit sizes. PPX@-o-VERT and VERT@o-PPX are reported as PPX and VERT. ‘-’ : missing or non
calculable results. Human MMOS are also provided (el 95% confidence interval was on average .29
for uncond. y .61 for cond.).
S2u
Métrica
Nb
units with.↓
ABX ABX spot-the-
word↓
acr.↓
accept.
judg.↓
uLM
–
–
3.12
29.02
50
100
200
50
100
200
50
100
200
50
100
200
23.95
24.33
25.71
5.50
5.09
5.18
7.37
6.00
5.99
22.30
18.16
16.59
35.86
37.86
39.65
7.20
6.55
6.83
8.61
7.41
7.31
24.56
20.44
18.69
48.52
48.12
49.62
32.18
31.72
37.40
32.88
31.30
36.52
51.92
50.24
44.68
46.78
46.83
47.76
45.43
44.35
45.19
44.06
42.94
47.03
45.75
45.97
45.70
Sistema
Toplines
ASR+LM
Líneas de base
LogMel
LogMel
LogMel
Unsupervised
CPC
CPC
CPC
HuBERT-L6
HuBERT-L6
HuBERT-L6
wav2vec-L14
wav2vec-L14
wav2vec-L14
Mesa 4: Results for zero-shot probe metrics for
3 unsupervised models plus one LogMel baseline
y 3 unit sizes. ABX within and across speakers,
spot-the-word, and acceptability judgments are
error rates (lower is better); chance is 50%.
and related it conceptually to previously studied
unsupervised tasks: Acoustic Unit Discovery, Spo-
ken Language Modeling, Discrete Speech Re-
synthesis, and Text Generation. We introduced a
suite of metrics, baselines, and first results on Lib-
rilight that sets the playing field for future work.
For comparability, we open source our evaluation
stack and the best of our baseline models.
Our main contributions are as follows. (1) Nosotros
established a set of easy to use automatic ASR-
based metrics for model comparison at two criti-
cal levels for this task: intelligibility of the speech
output and meaningfulness in terms of higher
linguistic content. We assessed the first through
ASR-based PER and CER metrics; and the sec-
ond using text-generation-based metrics (AUC for
PPX/VERT). (2) We found that these two sets
of metrics correlated well with human judgment
y (3) that they can be approximated with their
inference-mode counterparts, which are faster to
compute using zero-shot probe tasks. (4) Applying
these metrics to pipeline models based on current
speech representation learning models and out-
of-the-box LM and TTS components, we found
that our basic premise is fulfilled: It is possible
to train a language model from quantized units de
rived from audio and using it to generate new
speech. The generated speech is English-sounding,
with recognizable phonemes and words and lo-
cally acceptable syntax (see transcribed examples
in the Appendix and audio snippets here: https://
speechbot.github.io/gslm). Our automatic
metrics confirm the quality of the representations
1345
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
and outputs at the acoustic/phonetic level, pero
show that improvements are needed at the lan-
guage level. It is to be expected that performance
will increase with larger training sets beyond our
6k hours, as has been noted in the case of text.
(5) We also uncovered specific issues regard-
ing the number of quantized units. For speech
resynthesis, the optimum number of units was al-
maneras 200 by a large margin, reflecting the well
known bitrate/intelligibility trade-off
(Dunbar
et al., 2019). Sin embargo, for language modeling,
this was not necessarily the case, as the more
detailed acoustic information may introduce too
numerous phonetic details that have no impact at
the level of lexical and syntactic representations.
(6) Finalmente, we found that the choice of units also
affected the temperature parameter which is used
to control the trade-off between quality and di-
versity in text-based language model. To address
este efecto, we proposed a method to normalize
the temperature by using an oracle text to build
perplexity and diversity anchor points.
Obviamente, this is only a first step towards
building textless NLP applications that could be
applied to any language, even low resource ones.
To reach this long term goal, three important
challenges need to be addressed.
Primero, even though we did compare three dif-
ferent encoders and obtained different results, nosotros
cannot conclude that one encoder is definitely su-
perior to the others. Our point here was merely
to use previously published pretrained encoders,
and study systematically the effect of number of
units on these encoders. A fuller study including
a wider set of encoders and a proper hyperparam-
eter search (including the selection of the embed-
ding layer and the clustering algorithm) would be
needed in order to determine which of them is
most appropriate for speech generation.
Segundo, it is to be expected that to further
improve generation results, more needs to be done
than applying this pipeline to larger training sets.
Contrary to text, speech unfolds through time and
varies continuously in phonetic space. Speech also
contains multilayered representations (phonetic,
prosodic, speaker identity, emotions, fondo
ruido, etc.). Sin embargo, both our TTS and our LM
were out-of-the-box systems typically used for text
applications. More work is needed to adapt these
architectures to the richness and variability of the
speech signal (see Polyak et al., 2021a, for first
steps towards integrating prosody into discrete
units). The metrics and baselines we introduced
here provide landmarks against which we will
measure future progress.
Tercero, the automatic metrics that we defined
here depend on textual resources to build the
evaluation ASR and LM models, and on lin-
guistic resources to build the zero-shot metrics.
How could this ever be applied to low-resource
idiomas? Note that the linguistic resources we
require are used only for model selection, no
model training. Our metrics allow for fast itera-
tions in architecture and hyperparameter search,
but the overall algorithm is totally unsupervised.
Por lo tanto, an important next step is to extend this
work to other languages, in order to find a com-
mon architecture/hyperparameter set that gives
good results in held-out languages (high or low
resource). The hope is that once good learning
models are tuned using a diverse sample of high
resource languages, the same models could be
deployed in languages where no such resources
are available, and work in a purely unsupervised
moda.
Expresiones de gratitud
We thank Michael Auli and Alexis Conneau for
their useful input on wav2vec, and Lior Wolf,
Pierre Emmanuel Mazar´e, and Gargi Gosh for
their support for this project. We would also like to
thank the reviewers and editors for their thorough
revisar, and constructive feedback.
Referencias
Alexei Baevski, Michael Auli, and Abdelrahman
mohamed. 2019. Effectiveness of self-supervised
pre-training for speech recognition. CORR, abs
/1911.03912.
Alexei Baevski, Wei-Ning Hsu, and Alexis
Conneau. 2021. Unsupervised speech recog-
nition. arXiv preimpresión arXiv:2012.15454.
Alexei Baevski, Steffen Schneider, y miguel
Auli. 2020a. vq-wav2vec: Self-supervised
learning of discrete speech representations.
Conferencia Internacional sobre Aprendizaje Repre-
sentaciones (ICLR).
Alexei Baevski, Henry Zhou, Abdelrahman
mohamed, and Michael Auli. 2020b. wav2vec
1346
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2.0: A framework for self-supervised learning
of speech representations. En procedimientos de
the 34th International Conference on Neural
Sistemas de procesamiento de información, volumen 33,
pages 12449–12460.
Steven Bird, Edward Loper, and Ewan Klein.
2009. Natural Language Processing with
Python.
Tom B. Marrón, Benjamín Mann, Nick Ryder,
Melanie Subbiah,
Jared Kaplan, Prafulla
Dhariwal, Arvind Neelakantan, Pranav Shyam,
Girish Sastry, Amanda Askell, Sandhini Agarwal,
Ariel Herbert-Voss, Gretchen Krueger, Tom
Henighan, niño rewon, Aditya Ramesh,
Daniel M. Ziegler, Jeffrey Wu, Clemens Winter,
Christopher Hesse, Marcos Chen, Eric Sigler,
Mateusz Litwin, Scott Gris, Benjamin Chess,
Jack Clark, Christopher Berner,
Sam
McCandlish, Alec Radford, Ilya Sutsk. 2020.
Language models are few-shot learners. En profesional-
ceedings of the 34th International Conference
on Neural Information Processing Systems.
Mathilde Caron, Piotr Bojanowski, Armand
Joulin, and Matthijs Douze. 2018. Deep cluster-
ing for unsupervised learning of visual features.
In Proceedings of the European Conference on
Computer Vision (ECCV), pages 132–149.
Mingjie Chen and Thomas Hain. 2020. Unsu-
pervised acoustic unit representation learning
for voice conversion using WaveNet auto-
encoders. In Proceedings of INTERSPEECH,
pages 4866–4870. https://doi.org/10
.21437/Interspeech.2020-1785
Po-Han Chi, Pei-Hung Chung, Tsung-Han Wu,
y
Chun-Cheng Hsieh, Shang-Wen Li,
Hung-yi Lee. 2021. Audio ALBERT: A lite
BERT for self-supervised learning of audio
In IEEE Spoken Language
representación.
Technology Workshop (SLT), pages 344–350.
https://doi.org/10.1109/SLT48900
.2021.9383575
Jan Chorowski and Navdeep Jaitly. 2016. Towards
better decoding and language model integra-
tion in sequence to sequence models. En profesional-
ceedings of INTERSPEECH, pages 523–527.
https://doi.org/10.21437/Interspeech
.2017-343
Yu-An Chung and James Glass. 2020. Improved
speech representations with multi-target auto-
regressive predictive coding. En procedimientos de
la 58ª Reunión Anual de la Asociación de
Ligüística computacional, pages 2353–2358.
Asociación de Lingüística Computacional.
https://doi.org/10.18653/v1/2020
.acl-main.213
Yu-An Chung, Wei-Ning Hsu, Hao Tang, y
James Glass. 2019. An unsupervised au-
toregressive model for speech representation
aprendiendo. In Proceedings of INTERSPEECH,
pages 146–150. https://doi.org/10.21437
/Interspeech.2019-1473
Jacob Devlin, Ming-Wei Chang, Kenton Lee, y
Kristina Toutanova. 2019. BERT: Pre-entrenamiento
de transformadores bidireccionales profundos para el lenguaje
comprensión. En Actas de la 2019 Estafa-
ference of the North American Chapter of the
Asociación de Lingüística Computacional: Hu-
man Language Technologies, Volumen 1 (Largo
and Short Papers), páginas 4171–4186. asociación-
ción para la Lingüística Computacional. https://
doi.org/10.18653/v1/N19-1423
Li Dong, Nan Yang, Wenhui Wang, Furu Wei,
Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming
zhou, and Hsiao-Wuen Hon. 2019. Unified lan-
guage model pre-training for natural language
comprensión y generación. In Advances
en sistemas de procesamiento de información neuronal,
volumen 32, pages 13063–13075. Curran Asso-
ciates, Cª.
Ewan Dunbar, Robin Algayres, Julien Karadayi,
Mathieu Bernard, Juan Benjumea, Xuan-Nga
Cao, Lucie Miskic, Charlotte Dugrain, lucas
Ondel, Alan W. Negro, Laurent Besacier,
Sakriani Sakti, and Emmanuel Dupoux. 2019.
The Zero Resource Speech Challenge 2019:
TTS without T. In Proceedings of INTER-
SPEECH, pages 1088–1092. https://doi
.org/10.21437/Interspeech.2019-2904
Ewan Dunbar, Julien Karadayi, Mathieu Bernard,
Xuan-Nga Cao, Robin Algayres, lucas
Ondel, Laurent Besacier, Sakriani Sakti, y
Emmanuel Dupoux. 2020. The Zero Resource
Speech Challenge 2020: Discovering discrete
subword and word units. En procedimientos de
INTERSPEECH, pages 4831–4835. https://
1347
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
doi.org/10.21437/Interspeech.2020
-2743
Emmanuel Dupoux. 2018. Cognitive science in
the era of artificial intelligence: A roadmap
idioma-
for reverse-engineering the infant
learner. Cognición, 173:43–59. https://
doi.org/10.1016/j.cognition.2017
.11.008
Janek Ebbers, Jahn Heymann, Lukas Drude,
Thomas Glarner, Reinhold Haeb-Umbach,
and Bhiksha Raj. 2017. Hidden Markov
Model variational autoencoder for acoustic unit
discovery. In Proceedings of INTERSPEECH,
pages 488–492. https://doi.org/10.21437
/Interspeech.2017-1160
Ryan Eloff, Andr´e Nortje, Benjamin van Niekerk,
Avashna Govender, Leanne Nortje, Arnu
Pretorius, Elan van Biljon, Ewald van der
Westhuizen, Lisa van Staden, and Herman
Kamper. 2019. Unsupervised acoustic unit
discovery for speech synthesis using discrete
latent-variable neural networks. En curso-
ings of INTERSPEECH, pages 1103–1107.
https://doi.org/10.21437/Interspeech
.2019-1518
Siyuan Feng, Tan Lee, and Zhiyuan Peng. 2019.
Combining adversarial training and disentan-
gled speech representation for robust zero-
resource subword modeling. En procedimientos de
INTERSPEECH, pages 1093–1097. https://
doi.org/10.21437/Interspeech.2019
-1337
Thomas Glarner, Patrick Hanebrink,
Janek
Ebbers, and Reinhold Haeb-Umbach. 2018. Lleno
Bayesian Hidden Markov Model variational au-
toencoder for acoustic unit discovery. En profesional-
ceedings of INTERSPEECH, pages 2688–2692.
https://doi.org/10.21437/Interspeech
.2018-2148
Wei-Ning Hsu, David Harwath, Christopher Song,
and James Glass. 2020. Text-free image-
to-speech synthesis using learned segmental
units. arXiv preimpresión arXiv:2012.15454.
Wei-Ning Hsu, Yao-Hung Hubert Tsai, Benjamín
Bolte, Ruslan Salakhutdinov, and Abdelrahman
mohamed. 2021. HuBERT: How much can a
bad teacher benefit ASR pre-training? In Neu-
ral Information Processing Systems Workshop
on Self-Supervised Learning for Speech and
Audio Processing Workshop, pages 6533–6537.
https://doi.org/10.1109/ICASSP39728
.2021.9414460
Wei-Ning Hsu, Yu Zhang, and James Glass.
2017a. Learning latent
representations for
speech generation and transformation. En profesional-
ceedings of INTERSPEECH, pages 1273–1277.
https://doi.org/10.21437/Interspeech
.2017-349
Wei-Ning Hsu, Yu Zhang, and James Glass.
2017b. Unsupervised learning of disentan-
gled and interpretable representations from
sequential data. In Advances in Neural In-
formation Processing Systems, volumen 30,
pages 1878–1889. Asociados Curran, Cª.
Keith Ito and Linda Johnson. 2017. The lj
speech dataset. https://keithito.com
/LJ-Speech-Dataset/
z. Jin, A. Finkelstein, GRAMO. j. Mysore, y j. Lu.
2018. FFTNet: A real-time speaker-dependent
neural vocoder. In IEEE International Confer-
ence on Acoustics, Speech and Signal Process-
En g (ICASSP), pages 2251–2255. https://
doi.org/10.1109/ICASSP.2018.8462431
j. Kahn, METRO. Rivi`ere, W.. Zheng, mi. Kharitonov,
q. Xu, PAG. mi. Mazar´e, j. Karadayi, V. Liptchinsky,
R. Collobert, C. Fuegen, t. Likhomanenko,
GRAMO. Synnaeve, A. Joulin, A. mohamed, y
mi. Dupoux. 2020. Libri-light: A benchmark
for ASR with limited or no supervision. En
IEEE International Conference on Acous-
tics, Speech and Signal Processing (ICASSP),
pages 7669–7673. https://doi.org/10
.1109/ICASSP40776.2020.9052942
Eugene Kharitonov, Morgane Rivi`ere, Gabriel
Pierre-Emmanuel
Synnaeve, Lior Wolf,
Mazar´e, Matthijs Douze,
and Emmanuel
Dupoux. 2021. Data augmenting contrastive
learning of speech representations in the time
domain. arXiv preimpresión arXiv:2007.00991,
215–222. https://doi.org/10
paginas
.1109/SLT48900.2021.9383605
Sameer Khurana, Shafiq Rayhan Joty, ahmed
Alí, and James Glass. 2019. A factorial
1348
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
deep Markov Model for unsupervised disen-
tangled representation learning from speech.
In IEEE International Conference on Acous-
tics, Speech and Signal Processing (ICASSP),
pages 6540–6544. IEEE.
Sameer Khurana, Antoine Laurent, Wei-Ning
hsu, Jan Chorowski, Adrian Lancucki, Ricard
Marxer, and James Glass. 2020. A convolu-
tional deep Markov model for unsupervised
speech representation learning. En procedimientos
INTERSPEECH, pages 3790–3794. https://
doi.org/10.21437/Interspeech.2020
-3084
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae.
2020. HiFi-GAN: Generative adversarial net-
works for efficient and high fidelity speech syn-
tesis. In Proceedings of the 34th International
Conference on Neural Information Process-
ing Systems, volumen 33, pages 17022–17033.
https://arxiv.org/abs/2010.05646.
Kundan Kumar, Rithesh Kumar, Thibault
de Boissiere, Lucas Gestin, Wei Zhen Teoh,
Jose Sotelo, Alexandre de Br´ebisson, Yoshua
bengio, and Aaron C. Courville. 2019. Mel-
GAN: Generative adversarial networks for
conditional waveform synthesis. In Advances
en sistemas de procesamiento de información neuronal,
volumen 32, pages 14910–14921. Curran Asso-
ciates, Cª.
Cheng-I Lai, Yung-Sung Chuang, Hung-Yi Lee,
Shang-Wen Li, and James Glass. 2021. Semi-
supervised spoken language understanding via
self-supervised speech and language model pre-
training. In IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP),
pages 7468–7472. https://doi.org/10
.1109/ICASSP39728.2021.9414922
Chia-ying Lee and James Glass. 2012. A nonpara-
metric Bayesian approach to acoustic model
discovery. In Proceedings of the 50th Annual
reunión de
la Asociación de Computación-
lingüística nacional (Volumen 1: Artículos largos),
pages 40–49.
mike lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Exacción, Veselin Stoyanov, and Luke Zettlemoyer.
2020. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
the 58th Annual Meeting of
traducción, and comprehension. En curso-
el
cosas de
Asociación de Lingüística Computacional,
pages 7871–7880. Asociación de Computación-
lingüística nacional. En línea. https://doi
.org/10.18653/v1/2020.acl-main.703
Shaoshi Ling and Yuzong Liu. 2020. DeCoAR
2.0: Deep contextualized acoustic representa-
tions with vector quantization. arXiv preprint
arXiv:2012.06659.
Shaoshi Ling, Yuzong Liu, Julian Salazar, y
Katrin Kirchhoff. 2020. Deep contextualized
acoustic representations for semi-supervised
In IEEE International
speech recognition.
Conference on Acoustics, Speech and Signal
Procesando (ICASSP), pages 6429–6433. IEEE.
A. t. Liu, S. Cual, PAG. Chi, PAG. hsu, and H. Sotavento.
2020. Mockingjay: Unsupervised speech rep-
resentation learning with deep bidirectional
transformer encoders. In IEEE International
Conference on Acoustics, Speech and Signal Pro-
cesando (ICASSP), pages 6419–6423. https://
doi.org/10.1109/ICASSP40776.2020
.9054458
Alexander H. Liu, Yu-An Chung, and James
Glass. 2020. Non-autoregressive predictive
coding for
learning speech representations
from local dependencies. arXiv preprint
arXiv:2011.00406.
Andy T. Liu, Po chun Hsu, and Hung-Yi
Sotavento. 2019a. Unsupervised end-to-end learning
of discrete linguistic units for voice con-
versión. In Proceedings of INTERSPEECH,
pages 1108–1112. https://doi.org/10
.21437/Interspeech.2019-2048
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
mike lewis, Lucas Zettlemoyer, and Veselin
Stoyanov. 2019b. RoBERTa: A robustly op-
timized BERT pretraining approach. arXiv
preprint arXiv:1907.11692.
Takashi Morita and Hiroki Koda. 2020. Explor-
ing TTS without T using biologically/psycho-
logically motivated neural network modules
(ZeroSpeech 2020). In Proceedings of INTER-
SPEECH, pages 4856–4860. https://doi
.org/10.21437/Interspeech.2020-3127
1349
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Shekhar Nayak, C. Shiva Kumar, GRAMO. Ramesh,
Saurabhchand Bhati, and K. Sri Rama Murty.
2019. Virtual phone discovery for speech
synthesis without text. In IEEE Global Con-
ference on Signal and Information Processing
(GlobalSIP). https://doi.org/10.1109
/GlobalSIP45357.2019.8969412
Vassil Panayotov, Guoguo Chen, Daniel Povey,
and Sanjeev Khudanpur. 2015. LibriSpeech: Un
ASR corpus based on public domain audio
books. In IEEE International Conference on
Acoustics, Speech and Signal Processing
(ICASSP), pages 5206–5210. IEEE. https://
doi.org/10.1109/ICASSP.2015.7178964
Tu Anh Nguyen, Maureen de Seyssel, patricia
Roz´e, Morgane Rivi`ere, Evgeny Kharitonov,
Alexei Baevski, Ewan Dunbar, and Emmanuel
Dupoux. 2020. The Zero Resource Speech
Benchmark 2021: Metrics and baselines for
unsupervised spoken language modeling. En
Avances en el procesamiento de información neuronal
Sistemas (NeurIPS) – Self-Supervised Learning
for Speech and Audio Processing Workshop.
Benjamin van Niekerk, Leanne Nortje, y
Herman Kamper. 2020. Vector-quantized neu-
ral networks for acoustic unit discovery in the
ZeroSpeech 2020 Challenge. En procedimientos de
INTERSPEECH, pages 4836–4840. https://
doi.org/10.21437/Interspeech.2020
-1693
Lucas Ondel, Luk´aˇs Burget, and Jan ˇCernock`y.
acoustic
2016. Variational
unit discovery. Procedia Computer Science,
81:80–86.
inferencia
para
Aaron van den Oord, Yazhe Li, and Oriol
Viñales. 2018. Representation learning with
contrastive predictive coding. arXiv preprint
arXiv:1807.03748.
Aaron van den Oord, Oriol Vinyals, and Koray
Kavukcuoglu. 2017. Neural discrete represen-
tation learning. In Advances in Neural Informa-
tion Processing Systems, pages 6306–6315.
Aaron van den Oord, Sander Dieleman, Heiga
Zen, Karen Simonyan, Oriol Vinyals, Alex
Tumbas, Nal Kalchbrenner, Andrew Senior, y
Koray Kavukcuoglu. 2016. WaveNet: A gen-
erative model for raw audio. arXiv preprint
arXiv:1609.03499.
Myle Ott, Sergey Edunov, Alexei Baevski, Angela
Admirador, Sam Gross, Nathan Ng, David Grangier,
and Michael Auli. 2019. Fairseq: A fast, ex-
tensible toolkit for sequence modeling. En profesional-
ceedings of NAACL-HLT, pages 48–53.
Santiago Pascual, Mirco Ravanelli, Joan Serra,
Antonio Bonafonte, and Yoshua Bengio. 2019.
Learning problem-agnostic speech representa-
tions from multiple self-supervised tasks. En
Proceedings of INTERSPEECH, pages 161–165.
https://doi.org/10.21437/Interspeech
.2019-2605
Matthew Peters, Mark Neumann, Mohit Iyyer,
Matt Gardner, Christopher Clark, Kenton Lee,
and Luke Zettlemoyer. 2018. Deep contextu-
alized word representations. En procedimientos de
el 2018 Conference of the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
Volumen 1 (Artículos largos), pages 2227–2237,
Nueva Orleans, Luisiana. Asociación para Com-
Lingüística putacional. https://doi.org
/10.18653/v1/N18-1202
Adam Polyak, Yossi Adi, Jade Copet, Eugene
Kharitonov, Kushal Lakhotia, Wei-Ning Hsu,
Abdelrahman Mohamed,
and Emmanuel
Dupoux. 2021a. Speech resynthesis from dis-
crete disentangled self-supervised representa-
ciones. In Proceedings of INTERSPEECH.
Adam Polyak, Lior Wolf, Yossi Adi, Ori Kabeli,
and Yaniv Taigman. 2021b. High fidelity
speech regeneration with application to speech
enhancement. In IEEE International Confer-
ence on Acoustics, Speech and Signal Process-
En g (ICASSP), pages 7143–7147. https://
doi.org/10.1109/ICASSP39728.2021
.9414853
Adam Polyak, Lior Wolf, Yossi Adi, and Yaniv
Taigman. 2020a. Unsupervised cross-domain
singing voice conversion. En procedimientos de
INTERSPEECH, pages 801–805. https://
doi.org/10.21437/Interspeech.2020
-1862
Adam Polyak, Lior Wolf, and Yaniv Taigman.
2020b. TTS skins: Speaker conversion via
INTERSPEECH,
ASR.
En procedimientos de
1350
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
786–790. https://doi.org/10
paginas
.21437/Interspeech.2020-1416
R. Prenger, R. Valle, y B. Catanzaro. 2019.
Waveglow: A flow-based generative network
for speech synthesis. In IEEE International
Conference on Acoustics, Speech and Signal
Procesando
3617–3621.
https://doi.org/10.1109/ICASSP.2019
.8683143
(ICASSP),
paginas
Alec Radford, Jeffrey Wu, niño rewon, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI blog, 1(8):9.
j. Zhong, S. Pascual, PAG.
METRO. Ravanelli,
j. Trmal, y
j. Monteiro,
Swietojanski,
Y. bengio. 2020. Multi-task self-supervised
learning for
En
IEEE International Conference on Acous-
tics, Speech and Signal Processing (ICASSP),
pages 6989–6993. https://doi.org/10
.1109/ICASSP40776.2020.9053569
robust speech recognition.
F. Ribeiro, D. Florˆencio, C. zhang, y M. Seltzer.
2011. CROWDMOS: An approach for crowd-
sourcing mean opinion score studies.
En
IEEE International Conference on Acous-
tics, Speech and Signal Processing (ICASSP),
pages 2416–2419. https://doi.org/10
.1109/ICASSP.2011.5946971
Morgane Rivi`ere and Emmanuel Dupoux. 2020.
Towards unsupervised learning of speech fea-
tures in the wild. In IEEE Spoken Language
Technology Workshop (SLT), pages 156–163.
https://doi.org/10.1109/SLT48900
.2021.9383461
Thomas Schatz, Naomi H. Feldman, Sharon
Goldwater, Xuan-Nga Cao, and Emmanuel
Dupoux. 2021. Early phonetic learning without
phonetic categories: Insights from large-scale
simulations on realistic input. En procedimientos
of the National Academy of Sciences, 118(7).
https://doi.org/10.1073/pnas
.2001844118
Steffen Schneider, Alexei Baevski, Ronan
Collobert, and Michael Auli. 2019. wav2vec:
Unsupervised pre-training for speech recog-
INTERSPEECH,
nition.
pages 3465–3469. http://doi.org/10
.21437/Interspeech.2019-1873
En procedimientos de
j. shen, R. Angustia, R. j. Weiss, METRO. Schuster,
norte. Jaitly, z. Cual, z. Chen, Y. zhang, Y.
Wang, R. Skerrv-Ryan, R. A. Saurous, Y.
Agiomvrgiannakis, and Y. Wu. 2018. Natural
TTS synthesis by conditioning WaveNet on
MEL spectrogram predictions. In IEEE Inter-
ational Conference on Acoustics, Speech and
Signal Processing (ICASSP), pages 4779–4783.
https://doi.org/10.1109/ICASSP
.2018.8461368
Andros Tjandra, Sakriani Sakti, and Satoshi
Nakamura. 2020. Transformer VQ-VAE for
unsupervised unit discovery and speech synthe-
hermana: ZeroSpeech 2020 Challenge. En curso-
ings of INTERSPEECH, pages 4851–4855.
https://doi.org/10.21437/Interspeech
.2020-3033
Andros Tjandra, Berrak Sisman, Mingyang
zhang, Sakriani Sakti, Haizhou Li, and Satoshi
Nakamura. 2019. VQVAE unsupervised unit
discovery and multi-scale Code2Spec inverter
for Zerospeech Challenge 2019. En procedimientos
of INTERSPEECH, pages 1118–1122. https://
doi.org/10.21437/Interspeech.2019
-3232
Patrick Lumban Tobing, Tomoki Hayashi,
Yi-Chiao Wu, Kazuhiro Kobayashi,
y
Tomoki Toda. 2020. Cyclic spectral mod-
eling for unsupervised unit discovery into
voice conversion with excitation and waveform
modelado. In Proceedings of INTERSPEECH,
pages 4861–4865. https://doi.org/10
.21437/Interspeech.2020-2559
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Leon Jones, Aidan N Gomez,
lucas káiser, y Illia Polosukhin. 2017.
Attention is all you need. In Advances in Neu-
ral Information Processing Systems, volumen 30,
pages 5998–6008. Asociados Curran, Cª.
Maarten Versteegh, Xavier Anguera, Aren Jansen,
and Emmanuel Dupoux. 2016. The Zero
Resource Speech Challenge 2015: Proposed
approaches and results. Procedia Computer
Ciencia, 81:67–72. https://10.1016/j
.procs.2016.04.031
W.. Wang, q. Espiga, and K. Livescu. 2020. Y-
supervised pre-training of bidirectional speech
encoders via masked reconstruction.
1351
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
In IEEE International Conference on Acous-
tics, Speech and Signal Processing (ICASSP),
pages 6889–6893. https://doi.org/10
.1109/ICASSP40776.2020.9053541
Anne Wu, Changhan Wang, Juan Pino, y
Jiatao Gu. 2020. Self-supervised represen-
improve end-to-end speech trans-
taciones
INTERSPEECH,
En procedimientos de
lación.
pages 1491–1495. https://doi.org/10
.21437/Interspeech.2020-3094
Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian
guo, Weinan Zhang, Jun Wang, and Yong
Yu. 2018. Texygen: A benchmarking plat-
form for text generation models. In SIGIR,
pages 1097–1100. https://doi.org/10
.1145/3209978.3210080
7 Apéndice
7.1 Zero-shot Metrics Correlation Results
In Figure A1, we present the Pearson correlations
between the zero-shot metrics and the human
and automatic metrics on downstream tasks. El
fact that the ABX metric correlates well with these
downstream metrics makes it a useful proxy metric
for preliminary model and unit size selection, como
it is much less costly than generating TTS output
and running human or ASR evaluations.
7.2 Effect of Temperature on Outputs
En esta sección, we describe preliminary ex-
periments we conducted to test the effects of
temperature on the generated outputs. As shown
in Table A1, the temperature defined qualitatively
4 operating zones. With the lowest temperature,
we get repetitive outputs, where the system keeps
repeating the same few words. At a slightly higher
temperatura, the system outputs complete sen-
tenencias, but they are sampled from a narrow set
of topics. At the highest temperature, the sys-
tem utters an unstructured bag of words. En el
mid-temperature range, we observe relatively co-
herent and varied outputs. This is the range we
want to select for our systems. As described in
Cifra 2, the lowest bound was set by using
the oracle PPX (temperature range between 0.2
y 0.65. across unsupervised models) y el
highest bound by using the oracle VERT (tema-
perature range between 1.1 a 1.4). In Figure A2
we present human opinion results for samples
from these two temperatures, plus an extra mean
temperature falling in between. Humans typically
preferred the lower temperature.
single
judgments
selecting a
In Figure A3, we illustrate the continuation
temperatura
method for
en un
for human meaningfulness
model-neutral way, as explained in Section 3.3.
It consists of generating possible continuations of
each prompt and computing the BLEU-2 score8
with oracle continuation. The temp@cont tem-
perature is defined as the temperature maximizing
this score. Computing these estimates with 10
continuations gave continuation temperatures
varying between 0.5 y 0.9 across models and
unit sizes. These are the temperatures we used for
the MMOS results reported in the main paper.
8We used NLTK to compute BLEU (Bird et al., 2009).
1352
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Figure A1: Patterns of correlations between the zero-shot metrics and the automatic and human metrics.
Color scale indicates strength of the Pearson correlation coeficient (we used negative MOS and MMOS to enforce
less is better for all metrics).
Temp Example
Very low temperature samples (stuttering zone)
0.3
the property by james resell red for liberata or by jason downy the property
by jason downy the property the property the property the property
and to take in another path and to take in another path and to take in an-
other path and to take in another path and to take in another path and to
take in another path and take in a
Low temperature samples (obsessive zone)
0.7
chapter nineteen of the life of the upper part of the ocean this is ali
bravos recording only bravos recordings are in the public domain i for more
information or to volunteer
this is a lipper vox are courting oliver vox or courting are in the public
domain for afraid art to volunteer pleases it lipper vox dot or this
Mid temperature samples
1.0
but it is attendant from the people to defend himself from this information
pride of the potential in criminal activity a curiosity and impetuosity of
the world a war soon acquired
finally we ought to have a strong plan a without positively the best type of
the public with which we ascend it or extend it our business and as we are a
persons of the most strong designs and other affairs of the case we
High temperature samples (babble zone)
1.5
ation of pure blue he said at once a licking streamy at her warm spot of half
performed note was a raging oath let it as bir of amole in mood strolling er
crass
at the swing here as to motions out of the events not time and abe he was any
stump headed and flow any he’s the kiln are tama why do ye take the floor
0.3
0.7
1.0
1.5
Table A1: Unconditional uLM (trained on CPC-100 units) muestras, transcribed by ASR, at different
temperaturas.
1353
Figure A2: MMOS for unconditional (no prompt)
and conditional generated speech sampled at the three
reference temperatures (oracle VERT, oracle PPX, y
average temperature) (preliminary experiments).
Figure A3: Method for selecting the continuation
temperature for MMOS judgments.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
3
0
1
9
7
6
7
8
4
/
/
t
yo
a
C
_
a
_
0
0
4
3
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
1354