BLiMP: The Benchmark of Linguistic Minimal Pairs for English
Alex Warstadt1, Alicia Parrish1, Haokun Liu2, Anhad Mohananey2,
Wei Peng2, Sheng-FuWang1, Samuel R. Bowman1,2,3
1Department of Linguistics
New York University
2Departamento de Ciencias de la Computación
New York University
3Center for Data Science
New York University
{warstadt,alicia.v.parrish,haokunliu,anhad,
weipeng,shengfu.wang,bowman}@nyu.edu
Abstracto
We introduce The Benchmark of Linguistic
Minimal Pairs (BLiMP),1 a challenge set for
evaluating the linguistic knowledge of lan-
guage models (LMs) on major grammatical
phenomena in English. BLiMP consists of
67 individual datasets, each containing 1,000
minimal pairs—that is, pairs of minimally dif-
ferent sentences that contrast in grammatical
acceptability and isolate specific phenomenon
in syntax, morfología, or semantics. We gen-
erate the data according to linguist-crafted
grammar templates, and human aggregate
agreement with the labels is 96.4%. Nosotros
evaluate n-gram, LSTM, and Transformer
(GPT-2 and Transformer-XL) LMs by observ-
ing whether they assign a higher probability to
the acceptable sentence in each minimal pair.
We find that state-of-the-art models identify
morphological contrasts related to agreement
reliably, but they struggle with some subtle
semantic and syntactic phenomena, como
negative polarity items and extraction islands.
1 Introducción
Current neural networks for sentence processing
rely on unsupervised pretraining tasks like lan-
is an open question
él
guage modeling. Still,
how the linguistic knowledge of state-of-the-art
language models (LMs) varies across the lin-
guistic phenomena of English. Recent studies
(p.ej., Linzen et al., 2016; Marvin and Linzen,
2018; Wilcox et al., 2018) have explored this
question by evaluating LMs’ preferences between
minimal pairs of sentences differing in gramma-
tical acceptability, as in Example 1. Sin embargo, cada
1https://github.com/alexwarstadt/blimp.
377
of these studies uses a different set of metrics,
and focuses on a small
linguistic
paradigms, severely limiting any possible big-
picture conclusions.
set of
(1)
a. The cats annoy Tim. (grammatical)
b. *The cats annoys Tim. (ungrammatical)
We introduce the Benchmark of Linguistic
Minimal Pairs (shortened to BLiMP), a linguis-
tically motivated benchmark for assessing the
sensitivity of LMs to acceptability contrasts across
a wide range of English phenomena, covering both
previously studied and novel contrasts. BLiMP
consists of 67 datasets automatically generated
from linguist-crafted grammar templates, cada
containing 1,000 minimal pairs and organized
by phenomenon into 12 categories. Validación
with crowdworkers shows that BLiMP faithfully
represents human preferences.
We use BLiMP to study several pretrained LMs:
Transformer-based LMs GPT-2 (Radford et al.,
2019) and Transformer-XL (Dai et al., 2019), un
LSTM LM trained by Gulordava et al. (2019), y
an n-gram LM. We evaluate whether the LM
assigns a higher probability to the acceptable
sentence in each minimal pair to determine which
grammatical distinctions LMs are sensitive to.
This gives us indirect evidence about each model’s
linguistic knowledge and allows us to compare
models in a fine-grained way. We conclude that
current neural LMs appear to acquire robust
knowledge of morphological agreement and some
syntactic phenomena such as ellipsis and control/
raising. They show weaker evidence of knowledge
about argument structure, negative polarity item
licensing, and the semantic properties of quan-
tifiers. All models perform at or near chance
on extraction islands. En general, every model we
Transacciones de la Asociación de Lingüística Computacional, volumen. 8, páginas. 377–392, 2020. https://doi.org/10.1162/tacl a 00321
Editor de acciones: Marcos Steedman. Lote de envío: 1/2020; Lote de revisión: 3/2020; Publicado 7/2020.
C(cid:13) 2020 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
evaluate falls short of human performance by a
wide margin. GPT-2, which performs the best,
performs 8 points below humans overall, aunque
it does match or exceed human performance on
specific phenomena.
In §6.3 we conduct additional experiments to
investigate the effect of training size on the
LSTM LM and Transformer-XL’s performance
on BLiMP. Although we see steady improvements
in overall performance, we find that LMs learn
phenomenon-specific distinctions at different
tarifas.
In §6.4 we consider alternative well-
motivated evaluation metrics on BLiMP, but find
that they do not differ drastically from our method
of comparing LM probabilities for full sentences.
We conclude that whereas models like GPT-2
appear to have significant linguistic knowledge,
this knowledge is concentrated in some specific
domains of English grammar. We use BLiMP
to uncover several linguistic phenomena where
even state-of-the-art
language models clearly
lack human-like knowledge, and to bring into
focus those areas of grammar that future studies
evaluating LMs should investigate in greater
profundidad.
2 Background and Related Work
2.1 Language Models
The objective of a language model is to give
a probability distribution over the strings of a
idioma. Both neural network and non-neural
network architectures are used to build LMs, y
neural models can be trained in a self-supervised
setting without the need for labeled data. Recientemente,
variants of neural language modeling have been
shown to be a strong pretraining task for natural
language processing tasks (Howard and Ruder,
2018; Peters et al., 2018; Radford et al., 2018;
Devlin et al., 2019).
The last decade has seen two major paradigm
shifts in the state of the art for language modeling.
Primero, there was a movement from models based on
local n-gram statistics (see Chen and Goodman,
1999) to neural sequence models such as LSTMs
(Mikolov et al., 2010), which optimize on the
task of predicting the next token. Después,
Transformer-based architectures employing self-
atención (Vaswani et al., 2017) have outperformed
LSTMs (p.ej., Dai et al., 2019). Although these
shifts have resulted in stronger LMs, perplexity
on large benchmark datasets like WikiText-103
(Merity et al., 2016) has remained the primary
performance metric, which cannot give detailed
insight into these models’ knowledge of grammar.
Evaluation on benchmarks like GLUE (Wang
et al., 2018, 2019a), which heavily adapt language
models to perform downstream tasks, is more
informative, but doesn’t offer broad coverage
of linguistic phenomena, and doesn’t necessary
reflect knowledge that is already present in the
LMs.
2.2 Linguistic Knowledge of NNs
Many recent studies have searched for evidence
that neural networks (NNs) learn representations
that implicitly encode grammatical concepts. Nosotros
refer to the ability to encode these concepts
as linguistic knowledge. Some studies evaluate
NNs’ linguistic knowledge using probing tasks
is trained to directly
in which a classifier
predict grammatical properties of a sentence
(p.ej., syntactic tree depth) or part of a sentence
(p.ej., part-of-speech) using only the NNs’ learned
representation as input (Shi et al., 2016; Adi et al.,
2017; Conneau et al., 2018; Ettinger et al., 2018;
Tenney et al., 2019). We follow a complementary
approach that uses acceptability judgments to
address the same question without the need for
training data labeled with grammatical concepts.
Acceptability judgments are the main form of
behavioral data used in generative linguistics to
measure human linguistic competence (Chomsky,
1965; Sch¨utze, 1996).
One branch of this literature uses minimal pairs
to infer whether LMs detect specific grammatical
contrasts. Mesa 1 summarizes linguistic pheno-
mena studied in this work. Por ejemplo, Linzen
et al. (2016) look closely at minimal pairs contrast-
ing subject-verb agreement. Marvin and Linzen
(2018) expand the investigation to negative
polarity item and reflexive licensing. Sin embargo,
these and related studies cover a limited set of
phenomena,
to the exclusion of well-studied
phenomena in linguistics such as control and
raising, ellipsis, quantification, and countless
otros. This is likely due to the labor-intensive
nature of collecting such targeted minimal pairs.
A related line of work evaluates neural networks
on acceptability judgments in a more domain-
general way. Corpora of sentences and their
grammaticality are collected for this purpose in a
378
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Phenomenon
Relevant work
Marvin and Linzen (2018), Futrell et al. (2018), Warstadt et al. (2019b)
Anaphora/binding
Subj.-verb agreement Linzen et al. (2016), Futrell et al. (2018), Gulordava et al. (2019), Marvin and
Linzen (2018), An et al. (2019), Warstadt et al. (2019b)
Neg. polarity items Marvin and Linzen (2018), Futrell et al. (2018), Jumelet and Hupkes (2018),
Filler-gap/Islands
Argument structure
Wilcox et al. (2019), Warstadt et al. (2019a)
Wilcox et al. (2018), Warstadt et al. (2019b), Chowdhury and Zamparelli
(2018, 2019), Chaves (2020), Da Costa and Chaves (2020)
Kann et al. (2019), Warstadt et al. (2019b), Chowdhury and Zamparelli (2019)
Mesa 1: Summary of related work organized by linguistic phenomena tested. All studies analyze neural
networks using acceptability judgments on minimal pairs mainly in English. Some studies appear
multiple times.
number of studies (Heilman et al., 2014; Lau et al.,
2017; Warstadt et al., 2019b). The most recent
and comprehensive corpus is CoLA (Warstadt
et al., 2019b), containing 10k sentences covering
a wide variety of linguistic phenomena provided as
examples in linguistics papers and books. CoLA,
which is included in the GLUE benchmark (Wang
et al., 2018), has been used to track advances
in the sensitivity of reusable sentence encoding
models to acceptability. Current models like
BERT (Devlin et al., 2019) and T5 (Rafael y col.,
2019) now learn to give acceptability judgments
that approach or even exceed individual human
agreement with CoLA.
predicciones
Although CoLA can provide evidence about
phenomenon-specific knowledge of models, este
method is limited by the need to train a super-
vised classifier on CoLA data prior to evaluation.
This is because CoLA is designed for binary
acceptability classification, and there is no gen-
erally accepted method for obtaining binary
acceptability
from unsupervised
models like LMs.2 Warstadt and Bowman (2019)
measure phenomenon-specific performance on
CoLA for several pretrained sentence encoding
modelos: an LSTM, GPT (Radford et al., 2018),
and BERT. Sin embargo,
the use of supervision
prevents making strong conclusions about the
sentence encoding component, since it
is not
possible to distinguish what the encoder knows
from what is learned through supervised training
on acceptability data.
Evaluating LMs on minimal pairs avoids this
problema, with the caveat that the LM probability
2Though see Lau et al. (2017) for some promising
proposals for normalizing LM probabilities to correlate with
gradient acceptability.
of a sentence can only serve as a proxy for
acceptability if confounding factors impacting
a sentence’s probability such as length and
lexical content are controlled for. It is with these
considerations in mind that we design BLiMP.
3 Datos
BLiMP consists of 67 minimal pair paradigms,
each with 1,000 sentence pairs in mainstream
American English grouped into 12 categories.3
We refer to minimal pair types as paradigms
and categories as phenomena. Each paradigm is
annotated for the unique contrast it isolates and the
broader phenomena it is part of. We automatically
generate the data from linguist-crafted grammar
templates, and our automatic labels are validated
with crowd-sourced human judgments.
the fact
Although each minimal pair type corresponds
to exactly one paradigm, a particular fact about
English grammar may be illustrated by multiple
paradigms. Por ejemplo,
that certain
determiners and nouns agree can be illustrated
by keeping the determiner the same and changing
the number marking of the noun as in the example
en mesa 2, or by keeping the noun the same
and changing the determiner (p.ej., Rachelle had
bought those chair.). With completeness in mind,
we include such complementary paradigms in
BLiMP whenever possible.
3We choose English because it is the native language of
the linguists who built the grammar templates, though in the
long run, creating versions of BLiMP in additional languages
would allow for coverage of more phenomena and expand
BLiMP’s range of usefulness. We assume 1,000 pairs is
sufficient to limit random noise resulting from small sample
sizes.
379
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Phenomenon
N Acceptable Example
Unacceptable Example
ANAPHOR AGR.
ARG. STRUCTURE
BINDING
CONTROL/RAISING
DET.-NOUN AGR.
ELLIPSIS
2 Many girls insulted themselves.
9 Rose wasn’t disturbing Mark.
7 Carlos said that Lori helped him.
5 There was bound to be a fish escaping. There was unable to be a fish escaping.
8 Rachelle had bought that chair.
2 Anne’s doctor cleans one important
Many girls insulted herself.
Rose wasn’t boasting Mark.
Carlos said that Lori helped himself.
book and Stacey cleans a few.
FILLER-GAP
IRREGULAR FORMS
ISLAND EFFECTS
NPI LICENSING
QUANTIFIERS
SUBJECT-VERB AGR. 6 These casseroles disgust Kayla.
7 Brett knew what many waiters find.
2 Aaron broke the unicycle.
8 Whose hat should Tonya wear?
7 The truck has clearly tipped over.
4 No boy knew fewer than six guys.
Rachelle had bought that chairs.
Anne’s doctor cleans one book and
Stacey cleans a few important.
Brett knew that many waiters find.
Aaron broken the unicycle.
Whose should Tonya wear hat?
The truck has ever tipped over.
No boy knew at most six guys.
These casseroles disgusts Kayla.
Mesa 2: Minimal pairs from each of the twelve linguistic phenomenon categories covered by BLiMP.
Differences are underlined. N is the number of 1,000-example minimal pair paradigms within each
broad category.
3.1 Data Generation Procedure
To create minimal pairs exemplifying a wide array
of linguistic contrasts, we found it necessary to
artificially generate all datasets. This ensures both
that we have sufficient unacceptable examples,
and that the data is fully controlled, allowing for
repeated isolation of a single linguistic pheno-
menon (Ettinger et al., 2018). For each paradigm,
we use a generation script to sample lexical items
from a vocabulary of over 3,000 items according
to a template specifying linear order of the phrases
in the acceptable and unacceptable sentences in
each minimal pair. Our data generation scripts are
publicly available.4 We annotate these lexical
items with the morphological, syntactic, y
semantic features needed to enforce selectional
restrictions and create grammatical and seman-
tically felicitous sentences.
All examples in a paradigm are structurally
analogous up to the point required for the relevant
contrast but may vary in some ways. Por ejemplo,
illustrated in
the template for NPI LICENSING,
Mesa 2, specifies that an arbitrary verb phrase
needs to be generated. Respectivamente, the generation
script samples from the entire set of verbs and
generates the required arguments on-the-fly. De este modo,
the structure of the sentence then depends on
whether the sampled verb is transitive, cláusula-
incrustar, raising, Etcétera, but that same
4https://github.com/alexwarstadt/data
generación.
verb phrase and its arguments are used in both
pairs in the paradigm.
This generation procedure is not without
limitations, and despite the very detailed voca-
bulary we use, implausible sentences are occa-
sionally generated (p.ej., Sam ran around some
glaciers).
aunque, both the
acceptable and unacceptable sentences will be
equally implausible given world knowledge, entonces
any difference in the probability assigned to them
is still attributable to the intended grammatical
contrast.
In these cases,
3.2 Coverage
The paradigms covered by BLiMP represent
well-established contrasts in English morphology,
syntax, and semantics. Each paradigm is grouped
into one of 12 phenomena, mostrado en la tabla 2.
Examples of all 67 paradigms appear in Table 4
of the Appendix. The paradigms are selected with
the constraints that they can be characterized using
templates as described above and illustrated with
minimal pairs of sentences equal in length5 that
differ in at most one vocabulary item.
Although this dataset has broad coverage, es
not exhaustive. It is not possible to include every
5We define length as the number of entries from our
lexicon. Some sentences in a pair contain different numbers
of words because visit and drop by are each one lexical entry.
Where discrepancies in number of words occur, ellos son
generally randomly distributed across the grammatical and
ungrammatical sentences in a paradigm.
380
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
grammatical phenomenon of English, and there is
no agreed-upon set of core phenomena. Sin embargo,
we consider frequent inclusion of a phenomenon in
a syntax/semantics textbook as an informal proxy
for what linguists consider to be core phenomena.
We survey several syntax textbooks (p.ej., Sag
et al., 2003; Adger, 2003; Sportiche et al., 2013),
and find that nearly all of the phenomena in
BLiMP are discussed in some source. Most of
the topics that repeatedly appear in textbooks
and can be represented with minimal pairs (p.ej.,
agreement, control/raising, wh-extraction/islands,
binding) are present in BLiMP.6
We characterize the 12 phenomena in BLiMP
as follows7:
• ANAPHOR AGREEMENT:
the requirement that
reflexive pronouns like himself
anaphora) agree with their antecedents in
persona, number, género, and animacy.
(a.k.a.
• ARGUMENT STRUCTURE: the ability of different
verbs to appear with different
types of
argumentos. Por ejemplo, different verbs can
appear with a direct object, participate in the
causative alternation, or take an inanimate
argumento.
• BINDING: the structural relationship between
a pronoun and its antecedent. All paradigms
illustrate aspects of Chomsky’s
(1981)
Principle A. Because coindexation cannot
be annotated in BLiMP, Principles B and C
are not illustrated.
• CONTROL/RAISING:
entre
syntactic and semantic
diferencias
de
predicates that embed an infinitival VP.
This includes control, raising, and tough-
movement predicates.
various
types
• DETERMINER-NOUN AGREEMENT: number agree-
ment between demonstrative determiners
(p.ej., this/these) and the associated noun.
• ELLIPSIS:
el
omitting
possibility
expressions from a sentence. Because this is
difficult to illustrate with sentences of equal
de
6In line with these textbooks, we rely on stereotyped
gender-name pairings and contrasts not present in all English
dialects (more detail provided in the Appendix).
7Nuestro
narrower
particular constraints described above.
implementation of
than the linguistic definition because of
these phenomena is often
el
381
length, our paradigms cover only special
cases of noun phrase ellipsis that meet this
constraint.
• FILLER-GAP:
dependencies
phrasal movement
preguntas.
en,
arising
de
Por ejemplo, wh-
• IRREGULAR FORMS: irregular morphology on
English past participles (p.ej., broken). Nosotros
are unable to evaluate models on nonexistent
forms like *breaked because such forms are
out of the vocabulary for some LMs.
• ISLAND EFFECTS:
restrictions on syntactic
environments where the gap in a filler-gap
dependency may occur.
• NPI LICENSING: restrictions on the distribution
of negative polarity items like any and ever
limited to, Por ejemplo, the scope of negation
y solo.
cover
quantifiers. Nosotros
• QUANTIFIERS: restrictions on the distribution
de
semejante
restricciones: superlative quantifiers (p.ej., en
el menos) cannot embed under negation, y
definite quantifiers and determiners cannot
be subjects in existential-there constructions.
two
• SUBJECT-VERB AGREEMENT:
subjects
y
present tense verbs must agree in number.
3.3 Comparison to Related Resources
With a vocabulary of over 3,000 palabras, BLiMP
lexical variation of any
has by far the most
related generated dataset. It includes verbs with
11 different subcategorization frames, incluido
verbs that select for PPs, infinitival VPs, y
embedded clauses. By comparison, datasets by
Ettinger et al. (2018) and Marvin and Linzen
(2018) use vocabularies of under 200 elementos. Otro
datasets of minimal pairs that achieve more lexical
and syntactic variety use data-creation methods
that limit empirical scope and control. Linzen
et al. (2016) construct a dataset of minimal
pairs for subject-verb agreement by changing
verbs’ number marking in a subset of English
Wikipedia, but this approach does not generalize
beyond agreement phenomena. Lau et al. (2017)
construct minimal pairs by taking sentences from
the BNC through round-trip machine translation.
The resulting sentences contain a wider variety of
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
r
mi
v
oh
Modelo
5-gram 61.2
LSTM 69.8
TXL
69.6
GPT-2
81.5
Humano
88.6
a ll
A. A
norte
A
47.9
91.7
94.1
99.6
97.5
R
GRAMO
GRAMO. S
R
A
71.9
73.2
69.5
78.3
90.0
R
t
GRAMO
D I N
I N
B
64.4
73.5
74.7
80.1
87.3
l . R
R
t
C
68.5
67.0
71.5
80.5
83.9
S I S
R
GRAMO
A
A I S.
D – norte
70.0
85.4
83.0
93.3
92.2
L I P
l
mi
36.9
67.6
77.2
86.6
85.0
mi
l
I L
F
60.2
73.9
66.6
81.3
86.9
PAG
A
R . GRAMO
GRAMO
mi
R
I R
79.5
89.1
78.2
84.1
97.0
R
A
l
Ud.
norte
A
l
I S
57.2
46.6
48.4
70.6
84.9
D
P I
norte
45.5
51.7
55.2
78.9
88.1
norte
A
Ud.
q
53.5
64.5
69.3
71.3
86.6
S
R
T I F I E
R
GRAMO
A
S – V
60.3
80.1
76.0
89.0
90.9
Mesa 3: Percentage accuracy of four baseline models and raw human performance on BLiMP using a forced-choice
tarea. A random guessing baseline would achieve an accuracy of 50%.
grammatical violations, but it is not possible to
control the nature or quantity of violations in the
resulting sentences.
3.4 Data Validation
To verify that the generated sentences represent a
real contrast in acceptability, we conduct human
validation via Amazon Mechanical Turk.8 Twenty
separate validators rated five pairs from each of
el 67 paradigms, for a total of 6,700 judgments.
We restricted validators to individuals currently
located in the US who self-reported as native
speakers of English. To assure that our validators
made a genuine effort on the task, each HIT
included an attention check item and a hidden
field question to catch bot-assisted humans.
Validators were paid $0.25 for completing five
judgments, which we estimate took 1-2 minutos.
For each minimal pair, 20 individuals completed
a forced-choice task mirroring the LMs’ task;
the human-determined acceptable sentence was
calculated via majority vote of annotators. By this
métrico, we estimate aggregate human agreement
with our annotations to be 96.4% en general. Como un
threshold of inclusion in BLiMP, the majority of
validators needed to agree with BLiMP on at least
4/5 examples from each paradigm. De este modo, todo 67
paradigms in the public version of BLiMP passed
this validation; only two additional paradigms
were rejected on this criterion. We also estimate
individual human agreement to be 88.6% en general
using the approximately 100 annotations from
each paradigm.9 Table 3 reports individual human
resultados (and model results) as a conservative
measure of human agreement.
4 Modelos
GPT-2 GPT-2 (Radford et al., 2019) is a large-
scale language model using the Transformer
architecture (Vaswani et al., 2017). Nuestro principal
experiments use GPT-2-large with 36 layers and
774M parameters.10 The model is pretrained on
Radford et al.’s WebText dataset, which contains
40GB of English text extracted from Web pages
and filtered for quality. To our knowledge,
WebText is not publicly available, so assuming
an average of 5–6 bytes/chars per word, nosotros
estimate WebText contains about 8B tokens. Nosotros
use jiant, a codebase for training and evaluating
sentence understanding models (Wang y cols.,
2019b), to implement code for evaluating GPT-2
on BLiMP.11
Transformer-XL Transformer-XL (Dai et al.,
2019) is another multilayer Transformer-based
neural language model. We test the pretrained
Transformer-XL Large model with 18 layers of
Transformer decoders and 16 attention heads for
each layer. The model is trained on WikiText-
103 (Merity et al., 2016), a corpus of 103M
tokens from English Wikipedia. Code for testing
Transformer-XL on BLiMP is also implemented
in jiant.
LSTM We include a long-short term memory
(LSTM, Hochreiter and Schmidhuber, 1997)
LM in our experiments. Específicamente, we test
a pretrained LSTM LM from Gulordava et al.
(2019) on BLiMP. The model is trained on a 83M-
token corpus extracted from English Wikipedia.
To investigate the effect of training size on
model performance (§6.3), we retrain a series
of LSTM and Transformer-XL models with the
same hyperparameters and the following training
8The full set of human judgments and a summary of the
results for all 67 paradigms is in Table 4 in the Appendix.
9A few had to be excluded due to ineligible annotators.
10GPT-2-XL performs slightly worse on BLiMP; see §6.3.
11https://github.com/nyu-mll/jiant/tree/
blimp-and-npi/scripts/blimp.
382
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
sizes: 64METRO, 32METRO, 16METRO, 8METRO, 4METRO, 2METRO, 1METRO, 1/2METRO,
1/4METRO, and 1/8M tokens. For each size, we train
the model on five different random samples of the
original training data, which has a size of 83M
tokens.12
5-gram We build a 5-gram LM on the English
Gigaword corpus (Graff et al., 2003), cual
consists of 3.1B tokens. To efficiently query
n-grams we use an implementation13 based on
Heafield et al. (2013).14
5 Results and Discussion
An LM’s overall accuracy on BLiMP is simply
the proportion of the 67,000 minimal pairs in
which the model assigns a higher probability to
the acceptable sentence. We report the results for
all models and human evaluation in Table 3. GPT-
2 achieves the highest accuracy and the 5-gram
model the lowest. All models perform well below
estimated human accuracy (as described in § 3.4).
The 5-gram model’s poor performance—overall
and on every individual category—indicates
that BLiMP is likely not solvable from local
co-occurrence statistics alone.
Because we evaluate pretrained models that
differ in architecture and training data, podemos
only speculate about what drives these differences
(though see § 6.3 for a controlled ablation study
on the LSTM LM). The results seem to indicate
that access to training data is the main driver of
performance on BLiMP for the neural models we
evaluate. This may explain why Transformer-XL
and the LSTM LM perform similarly in spite of
differences in architecture, as both are trained on
approximately 100M tokens of Wikipedia text.
Relacionado, GPT-2’s advantage may come from
the fact that it is trained on roughly two orders of
magnitude more data. Possibly, LSTMs trained on
larger datasets could perform comparably to GPT-
2, but such experiments are impractical because of
the inefficiency of training LSTMs at this scale.
generally perform best and closest
to human
level on morphological phenomena. Por ejemplo,
GPT-2 performs within 2.1 points of humans
on ANAPHOR AGR., DET.-NOUN AGR., and SUBJ.-VERB
AGR.. The set of challenging phenomena is more
diverse. ISLANDS are the hardest phenomenon by
a wide margin. Only GPT-2 performs well above
chance, and it remains 14 points below humans.
Some semantic phenomena, specifically those
involving NPI LICENSING and QUANTIFIERS, are also
challenging overall. All models perform relatively
poorly on ARG. STRUCTURE.
From these results we conclude that current
SotA LMs robustly encode basic facts of English
agreement. This does not mean that LMs will
come close to human performance for all
agreement phenomena. §6.1 discusses evidence
that increased dependency length and the presence
of agreement attractors of the kind investigated by
Linzen et al. (2016) and Gulordava et al. (2019)
reduce performance on agreement phenomena.
We find,
that LMs do represent
in accordance with Wilcox et al.
(2018),
long-distance
wh-dependencies, but we also conclude that
their representations differ fundamentally from
humans’. Although some models approach human
performance in ordinary filler-gap dependencies,
they are exceptionally poor at identifying island
violations overall. This finding suggests that they
reliably encode long-distance dependencies in
general, but not the syntactic domains in which
these dependencies are blocked, though GPT-2
does perform well above chance on some para-
digms of ISLAND EFFECTS. Sin embargo, strong con-
clusions about how these models
representar
wh-dependencies are not possible using the
forced-choice task compatible with BLiMP, y
a complete assessment of syntactic islands is best
addressed using a factorial design that manipulates
both the presence of an island and an attempt to
extract from it, as in Kush et al. (2018) or Wilcox
et al. (2018).
5.1 Results and Discussion by Phenomenon
into how LM’s
The results also give insight
linguistic knowledge varies by domain. Modelos
12https://github.com/sheng-fu/colorless
greenRNNs.
13https://github.com/kpu/kenlm.
14https://github.com/anhad13/blimp ngram.
In the semantic phenomena where models
struggle (NPIS and QUANTIFIERS), violations are
often attributed in semantic theories to a presup-
position failure or contradiction arising from
semantic composition or pragmatic reasoning
(p.ej., Chierchia, 2013; Ward and Birner, 1995;
Geurts and Nouwen, 2007). These abstract
383
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
semantic and pragmatic factors may be difficult
for LMs to learn. Marvin and Linzen also find
that LSTMs largely fail to recognize NPI licensing
condiciones. Warstadt et al. (2019a) find that BERT
(which is similar in scale to GPT-2) recognizes
these conditions inconsistently in an unsupervised
configuración.
The weak performance on ARG. STRUCTURE is
somewhat surprising, since arguments and heads
are usually—though not always—adjacent (p.ej.,
subjects and direct objects are adjacent to the
verb in default English word order). Sin embargo,
argument structure is closely related to semantic
event structure (see Marantz, 2013), which may
be comparatively difficult for LMs to learn.
judgments about argument structure are
También,
complicated by the possibility of coercing a
frequently transitive verb to be intransitive and
vice versa as well as the existence of secondary
meanings of verbs with different argument
estructuras (p.ej., normally intransitive boast has a
transitive use as in The spa boasts 10 pools), cual
might make this domain somewhat more difficult
for LMs. Though even with these complications,
humans detect the intended contrast 90% del
tiempo. We note that the reported difficulty of these
phenomena contradicts Warstadt and Bowman’s
(2019) conclusion that argument structure is one of
the strongest domains for neural models. Sin embargo,
Warstadt and Bowman evaluate classifiers with
supervision on CoLA, a large proportion of which
is sentences related to argument structure.
elementos,
Finalmente, we caution against interpreting positive
results on a general phenomenon in BLiMP as
proof of human-like knowledge. Although it is
unlikely that GPT-2 could reach human perfor-
mance on the SUBJ.-VERB AGR. paradigms without
acquiring a concept of number marking that
abstracts away from specific lexical
él
is difficult to rule out this possibility without
accumulating different forms of evidence, para
instancia, by testing how it generalizes to nonce
palabras. We take the paradigms in FILLER-GAP as
a cautionary example (ver tabla 4). Hay
four paradigms that assess a model’s sensitivity to
the syntactic requirements of complementizer that
versus a wh-word. We observe that all models
more or less succeed when the unacceptable
sentence lacks a necessary gap, but fail when
it contains an illicit gap. These results suggest the
models’ ability to accurately detect a contrast in
384
Cifra 1: Heatmap showing the correlation between
models’ accuracies in each of the 67 paradigms.
whether a gap is filled following a wh-word is
not clearly based on a generalization about the
relationship between that wh-word and its gap,
as such a generalization should extend to the
cases where the models currently fail to detect
the correct contrast. More generally, conclusions
about a model’s knowledge of a particular
grammatical concept can only be reached by
considering several paradigms.
5.2 Shallow Predictors of Performance
We also ask what
factors besides linguistic
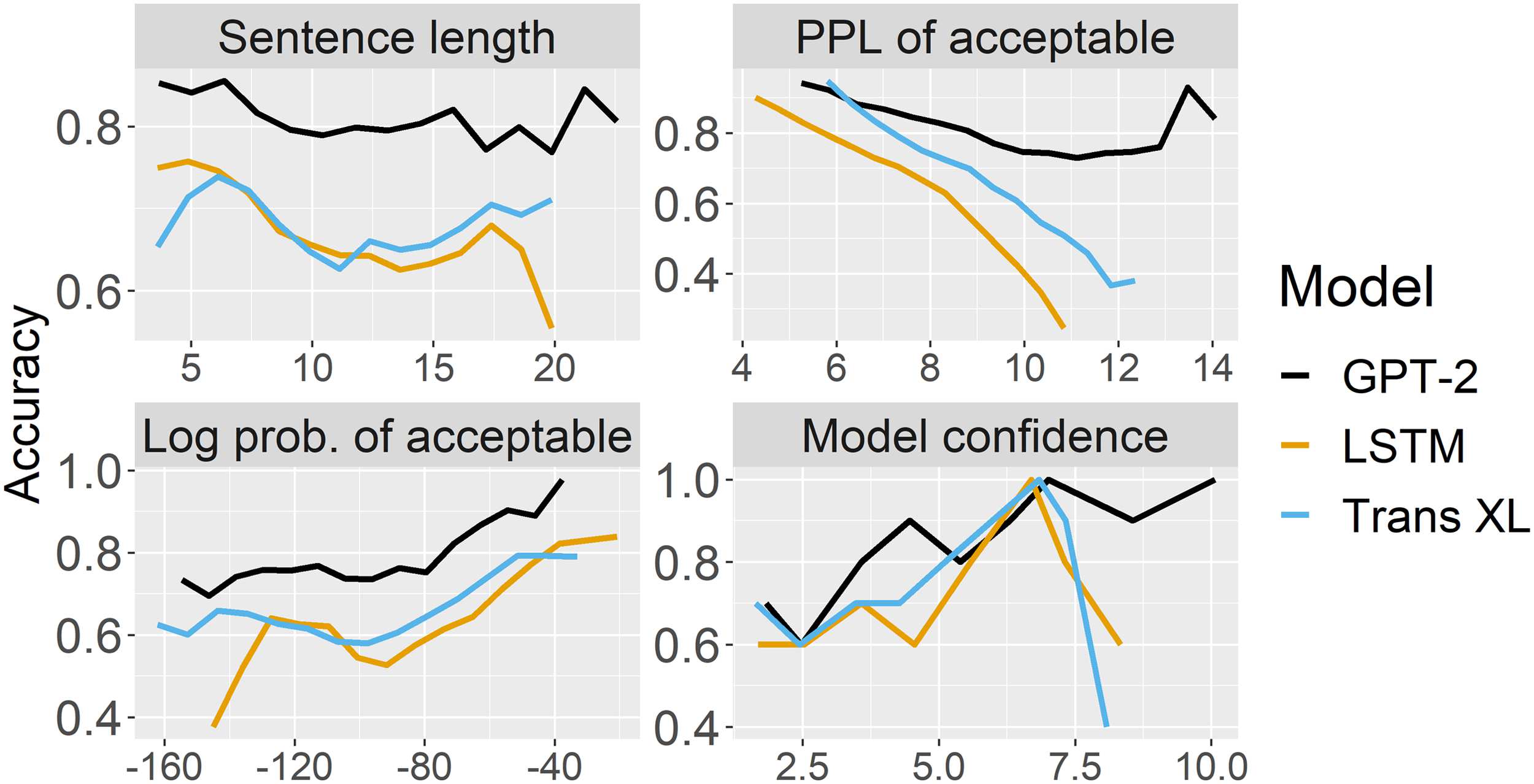
phenomena affect model accuracy. Cifra 2 muestra
how sentence length, perplexity (which does not
depend on length), the probability of the good
oración (which does depend on length), y
confidence affect model performance. El efecto
of perplexity is much weaker for GPT-2 than
for other models, which indicates that it is probably
more robust to sentences with non-stereotypical
syntax or describing unlikely scenarios. GPT-2
is the only model where accuracy increases
largely monotonically with confidence. A similar
relationship holds between confidence
y
agreement in human acceptability judgments.
5.3 Correlation of Model and Human
Actuación
We examine the extent to which models and
humans succeed at detecting contrasts for the same
linguistic phenomena. Cifra 1 shows the Pearson
correlation between the four LMs and humans
of their accuracies on the 67 paradigms. El
neural models correlate moderately with humans,
with GPT-2 correlating most strongly. The n-gram
model’s performance correlates with humans rela-
tively weakly. Neural models correlate with each
other more strongly, suggesting neural networks
share some biases that are not human-like.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2: Models’ performance on BLiMP as a function
of sentence length, perplexity, log probability of the
acceptable sentence, and model confidence (calculated
como |registro P (S1) − log P (S2)|).
Transformer-XL and LSTM’s high correlation of
0.9 possibly reflects their similar training data.
6 Análisis
6.1 Long-Distance Dependencies
The presence of intervening material can lower the
ability of humans to detect agreement depen-
dencies (Bock and Miller, 1991). We study how
intervening material affects the LMs’ sensitivity
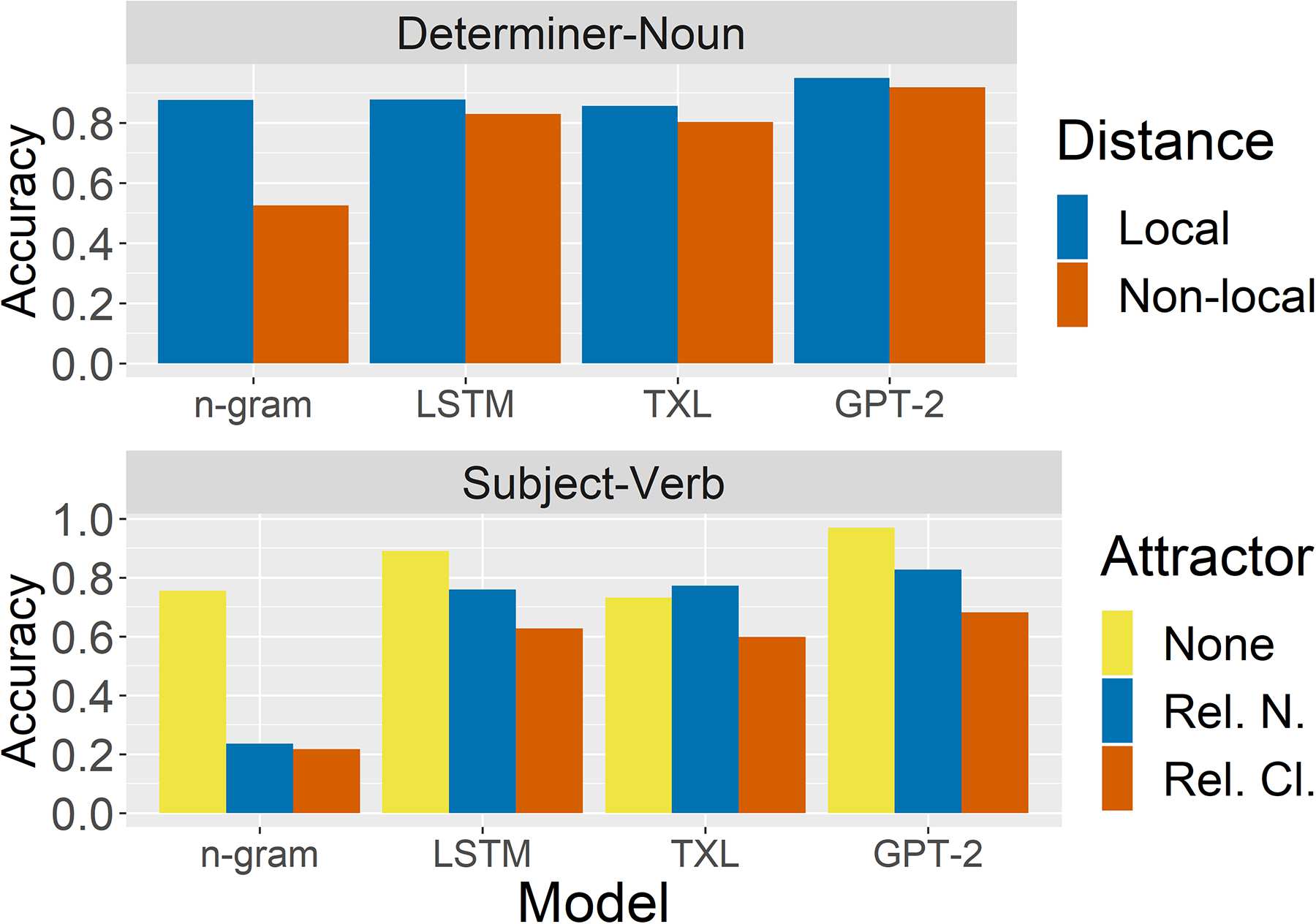
to mismatches in agreement in BLiMP. Primero, nosotros
test for sensitivity to determiner-noun agreement
with and without an intervening adjective, as in
Ejemplo (2). The results are plotted in Figure 3.
The n-gram model is the most heavily impacted,
performing on average 35 points worse. Esto es
unsurprising, since the bigram consisting of a
determiner and noun is far more likely to be
observed than the trigram of determiner, adjective,
and noun. For the neural models, we find a weak
but consistent effect, with all models performing
on average between 5 y 3 points worse when
there is an intervening adjective.
(2)
a. Ron saw that man/*men.
b. Ron saw that nice man/*men.
Segundo, we test for sensitivity to mismatches
in subject-verb agreement when an attractor noun
of the opposite number intervenes. comparamos
attractors in relative clauses (3-b) and as part of
a relational noun (3-C), following experiments
by Linzen et al. (2016) y otros. De nuevo, nosotros
the n-gram model’s performance is
find that
reduced significantly by this intervening material,
suggesting the model is consistently misled by the
presence of an attractor. All the neural models
perform above chance with an attractor present,
but GPT-2 and the LSTM perform 22 y 20 puntos
Cifra 3: The effect of the locality of determiner-noun
agreement (upper panel) and the type of agreement
attractor (lower panel) on model performance.
worse when an attractor is present than when
there is no attractor, while Transformer-XL’s
performance is reduced by only 5 puntos. De este modo,
we reproduce Linzen et al.’s finding that attractors
significantly reduce LSTM LMs’ sensitivity to
mismatches in agreement and find evidence that
this holds true of some Transformer LMs as well.
(3)
a. The sisters bake/*bakes.
b. The sisters who met Cheryl bake/*bakes.
C. The sisters of Cheryl bake/*bakes.
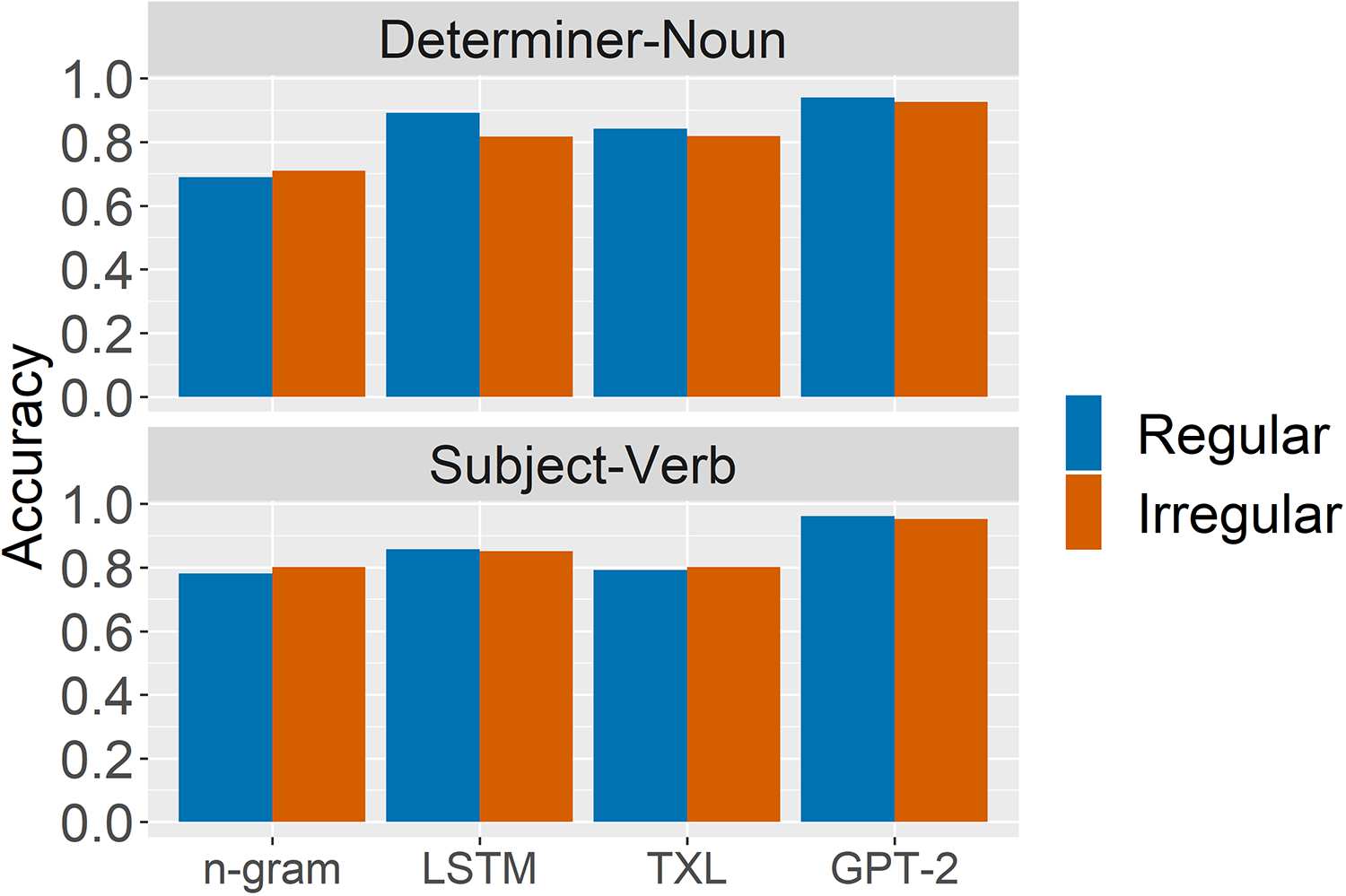
6.2 Regular vs. Irregular Agreement
In DET.-NOUN AGR. and SUBJ.-VERB AGR., we generate
separate datasets for nouns with regular and
irregular number marking, as in Example (4). Todo
else being equal, only models with access
information should make
to sub-word-level
any distinction between regular and irregular
morfología.
(4)
(regular)
a. Ron saw that nice kid/*kids.
b. Ron saw that nice man/*men. (irregular)
De hecho, Cifra 4 shows that the two sub-word-
level models GPT-2 and Transformer-XL show
little effect of irregular morphology: They perform
less than 1.3 points worse on irregulars than
regulars. Their high overall performance suggests
that they robustly encode number features without
relying on segmental cues.15
15The LSTM LM, which has word-level tokens, averages
5.2 points worse on the irregular paradigms. This effect is
not due to morphology, but rather to the higher proportion
of out-of-vocabulary items among the irregular nouns, cual
include many loanwords such as theses and alumni.
385
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4: Models’ performance on agreement phe-
nomena between a determiner and noun and between
a subject and verb, broken down by whether the
noun/subject has a regular or irregular plural form
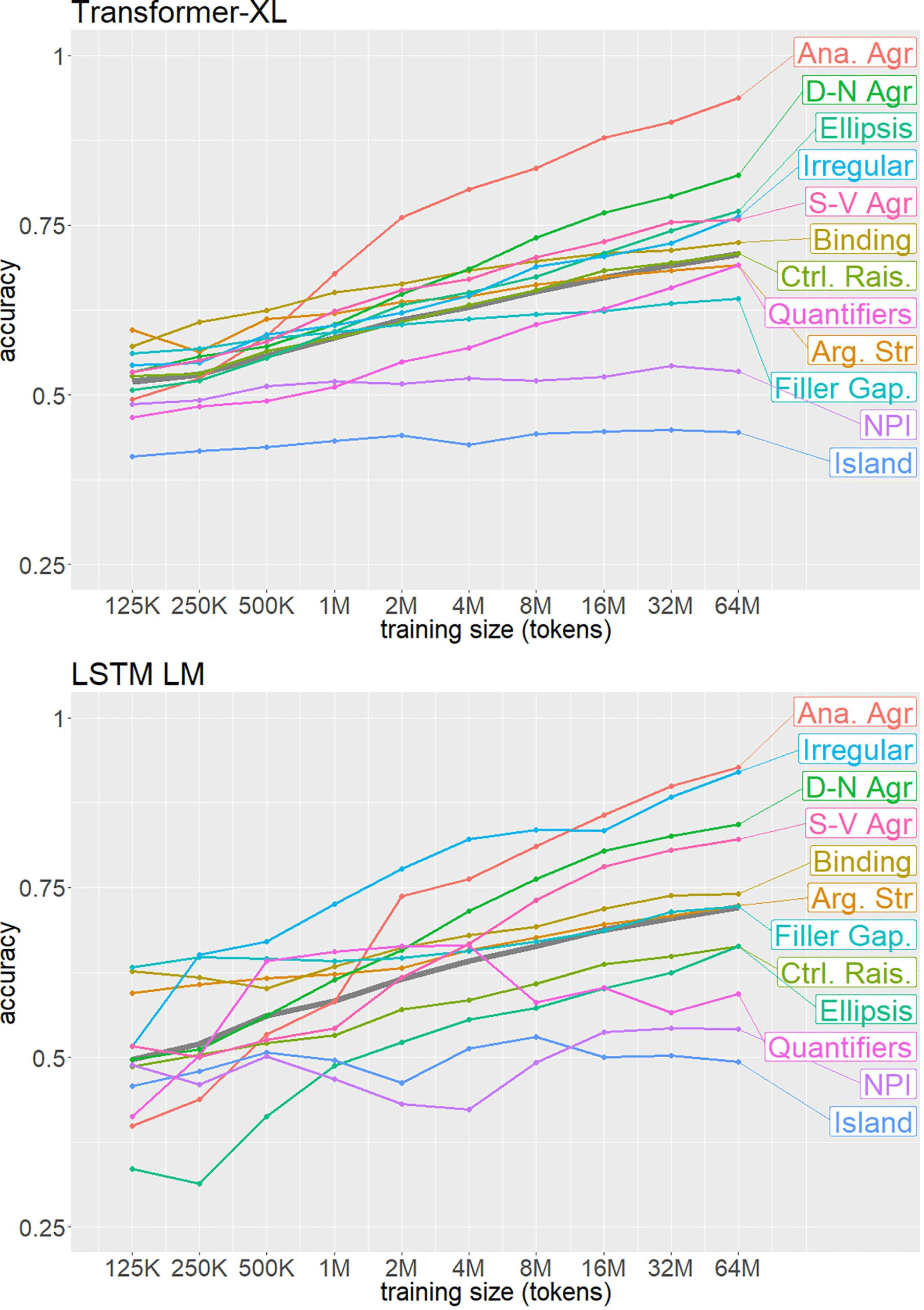
6.3 Training size and BLiMP performance
We use BLiMP to track how a model’s rep-
resentation of particular phenomena varies with
the quantity of training data. Using different
sized subsets of Gulordava et al.’s (2019) training
datos, we retrain the LSTM and Transformer-XL
models and evaluate their performance on BLiMP.
Cifra 5 shows that different phenomena have
notably different learning curves across different
training sizes even if the full model trained on 83M
tokens achieved equivalent accuracy scores. Para
ejemplo, the LSTM model ultimately performs
well on both IRREGULAR and ANAPHOR AGR., pero
requires more training to reach this level of
performance for ANAPHOR AGR. These learning
curve differences show how BLiMP performance
dissociates from perplexity on Wikipedia data, a
standard measure of LM performance: A pesar de
perplexity decreases with more training data,16
performance on different phenomena grows at
varying rates.
a
es
Nosotros
eso
allá
conjecture
sigmoid
relationship between the logarithm of training
set size and BLiMP performance that appears
to be roughly linear at this scale. We conduct
linear regression analyses to estimate the rate
of increase in performance in relation to the
logarithm (base 2) of dataset size. For the LSTM
LM, best-fit
lines for phenomena on which
the model had the highest accuracy have the
steepest slopes: ANAPHOR AGR. (0.0623), DET.-NOUN
16Average perplexity on the Gulordava et al. (2019) prueba
colocar: 595 at 0.125M, 212 at 1M, 92.8 at 8M, y 53 at 64M.
386
Cifra 5: Transformer-XL (arriba) and LSTM LM
(abajo) performance as a function of training size
and phenomena in BLiMP. The gray line shows the
average across all phenomena.
AGR. (0.0426), and IRREGULAR (0.039). We see
the shallowest slopes on phenomena with the
worst performance: NPIS (0.0078) and ISLANDS
(0.0036). For Transformer-XL, we observe a
similar pattern: The steepest
learning curves
again belong to ANAPHOR AGR. (0.0545) and DET.-
NOUN AGR. (0.0405), and the shallowest to NPIS
(0.0055) and ISLANDS (0.0039). Based on these
valores, we estimate that if log-linear improvement
continues, the LSTM LM and Transformer-XL
should require well over 1020 tokens of training
data to achieve human-like performance on these
hardest phenomena.
We also find that increasing model size (number
of parameters) is unlikely to improve performance:
We evaluate four pretrained versions of GPT-
2 con 117 M to 1,558 M parameters trained
on WebText. All models have overall BLiMP
accuracy of 0.84 ± .01%, and standard deviation
among the models on each of the 12 phenomena
does not exceed 0.03. This finding bolsters
our earlier conclusion in §5 that amount of
training data has the biggest impact on BLiMP
actuación.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
6.4 Alternate Evaluation Methods
There are several other methods one can
use to measure an LM’s preference between
two minimally different sentences. Hasta ahora, nosotros
have considered only the full-sentence method,
advocated for by Marvin and Linzen (2018), cual
compares LM likelihoods of full sentences. en un
followup experiment, we use two prefix methods,
each of which has appeared in related prior work,
that evaluate a model’s preferences by comparing
its prediction at a key point of divergence between
the sentences. Subsets of BLiMP data are designed
to be compatible with multiple methods, permitiendo
us to conduct the first direct comparison. We find
that all methods give broadly similar results when
aggregating over a set of paradigms. We see no
strong argument against evaluating solely using
the full-sentence method, though some results
diverge for specific paradigms.
One-Prefix Method In the one-prefix method,
used by Linzen et al. (2016), a pair of sentences
share the same initial portion of a sentence, pero
differ in a critical word that make them differ in
grammaticality (p.ej., The cat eats mice vs. El
cat eat mice). The model’s prediction is correct if
it assigns a higher probability to the grammatical
token given the shared prefix.
Two-Prefix Method In the two-prefix method,
used by Wilcox et al. (2019), a pair of sentences
differ in their initial string, and the grammaticality
difference is only revealed when a shared critical
word is included (p.ej., The cat eats mice vs. El
cats eats mice). For these paradigms, we evaluate
whether the model assigns a higher probability to
the critical word conditioned on the grammatical
prefix than on the ungrammatical prefix.
The prefix methods differ
from the full-
sentence method in two key ways: (i)
ellos
require that the acceptability of the sentence be
unambiguously predictable from the critical word,
but not sooner, y (ii) they are not affected
by predictions made by the LM following the
critical word. These values do affect the full
sentence method. Por ejemplo, assuming that
PAG (are numerous) ≫ P (is numerous), a model
could predict that The cats are numerous is more
likely than The cats is numerous without correctly
predicting that P (son|the cats) > P (es|the cats).
Using prefix probabilities allows us to exclude
models’ use of this additional information and
387
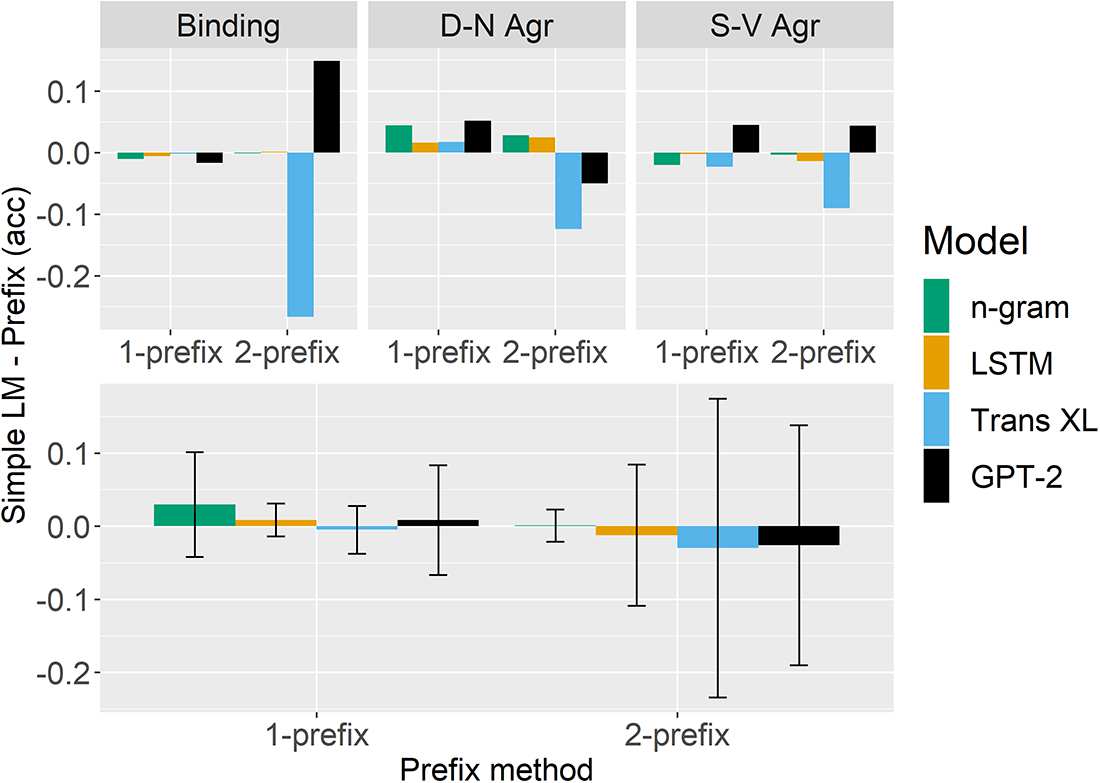
Cifra 6: Comparison of models’ performance on the
simple LM method and the 1- and 2-prefix methods.
The upper panels show results from three phenomena
that are compatible with both 1-prefix and 2-prefix
methods. The lower panel shows the averages and
standard deviations across all phenomena.
evaluate how the models perform when they have
just enough information to judge grammaticality.
Cifra 6 shows that models have generally
comparable accuracies across all three methods.
Sin embargo, there are some cases where we observe
differences between these methods. Por ejemplo,
Transformer-XL performs much worse at BINDING,
DET.-NOUN AGR., and SUBJ.-VERB AGR. in the simple
the probabilities
LM method, suggesting that
Transformer-XL assigns to the irrelevant part
at the end of the sentence very often overturn
the observed preference based on probability up
to the critical word. Por otro lado, GPT-2
benefits from reading the whole sentence for
BINDING phenomena, as its performance is better in
the simple LM method than in the prefix method.
We conclude that with a sufficiently diverse
set of paradigms,
the various metrics under
consideration will give similar results. De este modo, él
is not problematic that BLiMP relies only on the
full-sentence method, and doing so allows BLiMP
to include many paradigms not compatible with
either prefix method. Sin embargo, prefix methods
are still valuable for detailed analysis or for studies
making direct comparison to psycholinguistic
teorías (p.ej., Wilcox et al., 2018).
7 Conclusion and Future Work
We have shown ways in which BLiMP can be used
as tool to gain evidence about both the overall
and fine-grained linguistic knowledge of language
modelos. Like the GLUE benchmark (Wang y cols.,
2018), BLiMP assigns a single overall score
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
to an LM that summarizes its general sensitivity to
minimal pair contrasts. It also provides a break-
down of LM performance by linguistic phenom-
enon, which can be used to draw more concrete
conclusions about
the kinds of grammatical
features learned acquired by a given model. Este
kind of information is a linguistically motivated
evaluation of LMs that can complement common
metrics like perplexity.
the extent
Además,
to which humans
resemble data-driven learners
like language
models is debated in linguistics and cognitive
ciencia (see e.g., Chomsky, 1965; Reali and
Christiansen, 2005). In some domains, we may
require the aid of innate knowledge to acquire
phenomenon-specific knowledge resembling that
tested in BLiMP. By evaluating whether self-
supervised learners like LMs acquire human-like
grammatical acuity in a particular domain, nosotros
este
indirect evidence as to whether
gather
phenomenon is a necessary component of humans’
innate knowledge.
Another aim of BLiMP is to serve as a guide for
future work on the linguistic evaluation of LMs.
It is particularly interesting to better understand
those empirical domains where current LMs
to acquire some relevant knowledge,
appear
but still fall short of human performance. El
results from BLiMP suggest that—in addition
to relatively well-studied phenomena like filler-
gap dependencies, NPIs, and binding—argument
structure remains one area where there is much to
uncover about what LMs learn. More generally,
as language modeling techniques continue to
improve, it will be useful to have large-scale tools
like BLiMP to efficiently track changes in what
these models do and do not know about grammar.
Expresiones de gratitud
This material is based upon work supported by
the National Science Foundation under grant no.
1850208. Any opinions, findings, and conclusions
or recommendations expressed in this material are
those of the author(s) and do not necessarily reflect
the views of the National Science Foundation.
This project has also benefited from support to
SB by Eric and Wendy Schmidt (made by rec-
ommendation of the Schmidt Futures program), por
Samsung Research (under the project Improving
Deep Learning using Latent Structure), by Intuit,
388
Cª, and by NVIDIA Corporation (con el
donation of a Titan V GPU).
Apéndice
The following contains examples from each of the
67 paradigms in BLiMP.
Caveats Some paradigms include non-transparent
factors that may influence interpretation. We list
here those factors that we are aware of:
• Several paradigms within ANAPHOR AGREE-
MENT and BINDING rely on stereotyped gender
assignment associated with names (p.ej.,
Mary). A model has to have at least a weak
gender-name association in order to succeed
on some paradigms in BLiMP. Por ejemplo,
like Mary hugged
we mark sentences
themselves and Mary hugged himself as un-
acceptable, and we never include possibilities
like Mary hugged themself.
• To isolate certain phenomena, we had to rely
on acceptability contrasts present in main-
stream US and UK English but absent in
many other dialects. Por ejemplo, alguno
the sentence Suzy
speakers would accept
lie, but we would mark this un-
don’t
acceptable based on mainstream US English
judgments. BLiMP assesses models’ know-
ledge of this specific dialect of English; en
some cases it could penalize models that
conform to a different dialect.
How to read this table:
• Phenomenon refers to the linguistic phenom-
enon as noted in Table 2. UID refers to the
unique identifier used in the released dataset.
• Model and human performance are reported
as percent accuracy.
‘Human’ uses the
more conservative individual judgments (como
opposed to majority vote, for which each
paradigm would be either 100% o 80%).
• Each pair is marked for whether it is usable
with a prefix method. All sentences are valid
for the simple LM method.
• If a sentence has a checkmark (X) bajo
the 1pfx column, the sentence can be used
with the 1-prefix method in addition to the
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
T M
l
X
t
t – 2
PAG
GRAMO
norte
a
metro
tu
h
Acceptable Example
Phenomenon
UID
ANAPHOR
AGREEMENT
anaphor gender agreement
anaphor number agreement
ARGUMENT
STRUCTURE
BINDING
CONTROL/
RAISING
DETER-
MINER-
NOUN
AGR.
animate subject passive
animate subject trans
causative
drop argument
inchoative
intransitive
passive 1
passive 2
transitive
principle A c command
principle A case 1
principle A case 2
principle A domain 1
principle A domain 2
principle A domain 3
principle A reconstruction
existential there object raising
existential there subject raising
expletive it object raising
tough vs raising 1
tough vs raising 2
determiner noun agreement 1
determiner noun agreement 2
determiner noun agreement irregular 1
determiner noun agreement irregular 2
determiner noun agreement with adj 1
determiner noun agreement with adj 2
determiner noun agreement with adj irregular 1
determiner noun agreement with adj irregular 2
ELLIPSIS
ellipsis n bar 1
ellipsis n bar 2
FILLER
GAP
wh questions object gap
wh questions subject gap
wh questions subject gap long distance
wh vs that no gap
wh vs that no gap long distance
wh vs that with gap
wh vs that with gap long distance
IRREGULAR
FORMS
irregular past participle adjectives
irregular past participle verbs
ISLAND
EFECTOS
NPI
LICENSING
QUANTIFIERS
SUBJECT-
VERB
AGR.
adjunct island
complex NP island
coordinate structure constraint complex left branch
coordinate structure constraint object extraction
left branch island echo question
left branch island simple question
sentential subject island
wh island
matrix question npi licensor present
npi present 1
npi present 2
only npi licensor present
only npi scope
sentential negation npi licensor present
sentential negation npi scope
existential there quantifiers 1
existential there quantifiers 2
superlative quantifiers 1
superlative quantifiers 2
distractor agreement relational noun
distractor agreement relative clause
irregular plural subject verb agreement 1
irregular plural subject verb agreement 2
regular plural subject verb agreement 1
regular plural subject verb agreement 2
metro
5 – g r a
44
52
54
72
51
68
89
82
71
70
91
58
100
49
95
56
52
40
84
77
72
33
77
88
86
85
90
50
53
55
52
23
50
53
82
86
83
81
18
20
79
80
48
50
32
59
96
57
61
56
1
47
47
57
30
93
45
91
62
45
17
24
22
73
88
76
81
S
l
88
95
68
79
65
79
72
73
65
72
87
59
100
87
98
68
55
46
66
80
63
34
93
92
92
82
86
86
76
83
87
68
67
79
92
96
97
97
43
14
93
85
67
47
30
71
32
36
43
47
2
54
54
93
36
100
23
96
16
63
83
76
63
81
89
89
83
91
97
58
70
54
67
81
81
76
74
89
61
100
95
99
70
60
38
76
79
72
45
86
92
81
88
82
78
81
77
86
65
89
61
83
86
86
91
42
17
91
66
65
58
36
74
63
36
37
20
1
61
48
80
45
99
53
94
14
84
85
77
60
78
83
73
85
99
100
77
80
68
84
90
90
89
79
49
100
96
73
99
73
82
37
92
89
58
72
92
100
93
94
93
90
96
88
93
88
86
84
95
88
97
94
56
56
78
90
91
72
42
88
77
82
35
77
67
55
62
100
85
89
95
99
24
84
78
83
68
95
96
97
96
96
99
98
87
82
90
95
86
99
86
87
86
98
96
95
75
83
78
90
88
86
75
81
96
95
92
85
96
94
85
95
92
78
85
98
85
97
92
77
75
99
95
94
80
90
91
91
99
61
73
98
83
98
92
72
93
81
94
76
91
85
81
86
95
94
95
95
Katherine can’t help herself.
Many teenagers were helping themselves.
Amanda was respected by some waitresses.
Danielle visited Irene.
Aaron breaks the glass.
The Lutherans couldn’t skate around.
A screen was fading.
Some glaciers are vaporizing.
Jeffrey’s sons are insulted by Tina’s supervisor.
Most cashiers are disliked.
A lot of actresses’ nieces have toured that art gallery.
A lot of actresses that thought about Alice healed themselves.
Tara thinks that she sounded like Wayne.
Stacy imagines herself praising this actress.
Carlos said that Lori helped him.
Mark imagines Erin might admire herself.
Nancy could say every guy hides himself.
It’s herself who Karen criticized.
William has declared there to be no guests getting fired.
There was bound to be a fish escaping.
Regina wanted it to be obvious that Maria thought about Anna.
Julia wasn’t fun to talk to.
Rachel was apt to talk to Alicia.
Craig explored that grocery store.
Carl cures those horses.
Phillip was lifting this mouse.
Those ladies walk through those oases.
Tracy praises those lucky guys.
Some actors buy these gray books.
This person shouldn’t criticize this upset child.
That adult has brought that purple octopus.
Unacceptable Example
Katherine can’t help himself.
Many teenagers were helping herself.
Amanda was respected by some picture.
The eye visited Irene.
Aaron appeared the glass.
The Lutherans couldn’t disagree with.
A screen was cleaning.
Some glaciers are scaring.
Jeffrey’s sons are smiled by Tina’s supervisor.
Most cashiers are flirted.
A lot of actresses’ nieces have coped that art gallery.
A lot of actresses that thought about Alice healed herself.
Tara thinks that herself sounded like Wayne.
Stacy imagines herself praises this actress.
Carlos said that Lori helped himself.
Mark imagines Erin might admire himself.
Every guy could say Nancy hides himself.
It’s herself who criticized Karen.
William has obliged there to be no guests getting fired.
There was unable to be a fish escaping.
Regina forced it to be obvious that Maria thought about Anna.
Julia wasn’t unlikely to talk to.
Rachel was exciting to talk to Alicia.
Craig explored that grocery stores.
Carl cures that horses.
Phillip was lifting this mice.
Those ladies walk through that oases.
Tracy praises those lucky guys.
Some actors buy this gray books.
This person shouldn’t criticize this upset children.
That adult has brought those purple octopus.
Brad passed one big museum and Eva passed several.
Curtis’s boss discussed four sons and Andrew discussed five sick sons.
Brad passed one museum and Eva passed several big.
Curtis’s boss discussed four happy sons and Andrew discussed five sick.
Joel discovered the vase that Patricia might take.
Cheryl thought about some dog that upset Sandra.
Bruce knows that person that Dawn likes that argued about a lot of guys.
Danielle finds out that many organizations have alarmed Chad.
Christina forgot that all plays that win worry Dana.
Nina has learned who most men sound like.
Martin did find out what every cashier that shouldn’t drink wore.
Joel discovered what Patricia might take the vase.
Cheryl thought about who some dog upset Sandra.
Bruce knows who that person that Dawn likes argued about a lot of guys.
Danielle finds out who many organizations have alarmed Chad.
Christina forgot who all plays that win worry Dana.
Nina has learned that most men sound like.
Martin did find out that every cashier that shouldn’t drink wore.
The forgotten newspaper article was bad.
Edward hid the cats.
The forgot newspaper article was bad.
Edward hidden the cats.
Who has Colleen aggravated before kissing Judy?
Who hadn’t some driver who would fire Jennifer’s colleague embarrassed?
What lights could Spain sell and Andrea discover?
Who will Elizabeth and Gregory cure?
David would cure what snake?
Whose hat should Tonya wear?
Who have many women’s touring Spain embarrassed.
What could Alan discover he has run around?
Who has Colleen aggravated Judy before kissing?
Who hadn’t Jennifer’s colleague embarrassed some driver who would fire?
What could Spain sell lights and Andrea discover?
Who will Elizabeth cure and Gregory?
What would David cure snake?
Whose should Tonya wear hat?
Who have many women’s touring embarrassed Spain.
What could Alan discover who has run around?
Should Monica ever grin?
Even these trucks have often slowed.
Many skateboards also roll.
Only Bill would ever complain.
Only those doctors who Karla respects ever conceal many snakes.
Those banks had not ever lied.
Those turtles that are boring April could not ever break those couches.
Monica should ever grin.
Even these trucks have ever slowed.
Many skateboards ever roll.
Even Bill would ever complain.
Those doctors who only Karla respects ever conceal many snakes.
Those banks had really ever lied.
Those turtles that are not boring April could ever break those couches.
There aren’t many lights darkening.
Each book is there disturbing Margaret.
No man has revealed more than five forks.
An actor arrived at at most six lakes.
A sketch of lights doesn’t appear.
Boys that aren’t disturbing Natalie suffer.
This goose isn’t bothering Edward.
The woman cleans every public park.
Jeffrey hasn’t criticized Donald.
The dress crumples.
There aren’t all lights darkening.
There is each book disturbing Margaret.
No man has revealed at least five forks.
No actor arrived at at most six lakes.
A sketch of lights don’t appear.
Boys that aren’t disturbing Natalie suffers.
This goose weren’t bothering Edward.
The women cleans every public park.
Jeffrey haven’t criticized Donald.
The dresses crumples.
1pfx 2pfx
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
Mesa 4: Examples of all 67 paradigms in BLiMP along with model performance and estimated human agreement.
simple LM method. The bolded word is the
critical word—the probability of the two
different critical words for the acceptable
and unacceptable sentences can be compared
based on the same ‘prefix’.
Yossi Adi, Einat Kermany, Yonatan Belinkov,
Ofer Lavi, and Yoav Goldberg. 2017. Fine-
grained analysis of sentence embeddings using
auxiliary prediction tasks. En procedimientos de
ICLR Conference Track. Toulon, Francia.
• If a sentence has a checkmark (X) under the
2pfx column, the sentence can be used with
the 2-prefix method in addition to the simple
LM method. The bolded word is the critical
word—the probability of that particular word
can be compared based on the two different
acceptable and unacceptable ‘prefixes’.
Aixiu An, Peng Qian, Ethan Wilcox, and Roger
Exacción. 2019. Representation of constituents in
neural language models: Coordination phrase as
a case study. arXiv preimpresión arXiv:1909.04625.
Kathryn Bock and Carol A. Molinero. 1991. Broken
agreement. Psicología cognitiva, 23(1):45–93.
Referencias
Marantz, Alec. 2013. Verbal argument structure:
Events and participants. Lingua, 30:152–168.
Elsevier.
David Adger. 2003. Core Syntax: A Minimalist
Acercarse. Oxford University Press Oxford.
Rui P. Chaves. 2020. What don’t RNN language
models learn about filler-gap dependencies? En
Proceedings of the Third Meeting of the Society
for Computation in Linguistics (SCiL).
Stanley F. Chen and Joshua Goodman. 1999.
An empirical study of smoothing techniques
for language modeling. Computer Speech &
Idioma, 13(4):359–394.
389
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Gennaro Chierchia. 2013. Logic in Grammar.
prensa de la Universidad de Oxford.
Noam Chomsky. 1965. Aspects of the Theory of
Syntax. CON prensa.
Noam Chomsky. 1981. Lectures on Government
and Binding.
Shammur Absar Chowdhury
2018. RNN simulations
and Roberto
de
Zamparelli.
grammaticality judgments on long-distance
the 27th
dependencies.
International Conference on Computational
Lingüística, pages 133–144.
En procedimientos de
Shammur Absar Chowdhury
and Roberto
Zamparelli. 2019. An LSTM adaptation study
de (y) grammaticality. En Actas de la
2019 ACL Workshop BlackboxNLP: Analyzing
and Interpreting Neural Networks for NLP,
pages 204–212.
Alexis Conneau, German Kruszewski, Guillaume
Lample, Lo¨ıc Barrault, and Marco Baroni.
2018. What you can cram into a single
&!#* vector: Probing sentence embeddings for
linguistic properties. In ACL 2018-56th Annual
Meeting of the Association for Computational
Lingüística, volumen 1, pages 2126–2136.
Jillian K. Da Costa and Rui P. Chaves.
2020. Assessing the ability of transformer-
based neural models to represent structurally
unbounded dependencies. En Actas de la
Third Meeting of the Society for Computation
in Linguistics (SCiL).
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime
Carbonell, Quoc Le, and Ruslan Salakhutdinov.
2019. Transformer-XL: Attentive language
En
models beyond a fixed-length context.
Actas de la 57ª Reunión Anual de
la Asociación de Lingüística Computacional,
pages 2978–2988. Florencia, Italia. Asociación
para Lingüística Computacional.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, y
Kristina Toutanova. 2019. BERT: Pre-entrenamiento
de transformadores bidireccionales profundos para el lenguaje
comprensión. En procedimientos de
el 2019
Conference of the North American Chapter of
la Asociación de Lingüística Computacional:
Tecnologías del lenguaje humano, Volumen 1
(Artículos largos y cortos), páginas 4171–4186.
390
Allyson Ettinger, Ahmed Elgohary, Colin Phillips,
and Philip Resnik. 2018. Assessing composition
in sentence vector representations. En curso-
ings of the 27th International Conference on
Ligüística computacional, pages 1790–1801.
Asociación de Lingüística Computacional.
Ricardo
Futrell,
Takashi
Ethan Wilcox,
Morita,
and Roger Levy. 2018. RNNs
as psycholinguistic subjects: Syntactic state
and grammatical dependency. arXiv preprint
arXiv:1809.01329.
Bart Geurts and Rick Nouwen. 2007. ‘At least’
et al.: The semantics of scalar modifiers.
Idioma, pages 533–559.
David Graff, Junbo Kong, Ke Chen, and Kazuaki
maeda. 2003. English gigaword. Lingüístico
Data Consortium, Filadelfia, 4(1):34.
Kristina Gulordava, Piotr Bojanowski, Edouard
Grave, Tal Linzen, and Marco Baroni. 2019.
Colorless green recurrent networks dream
hierarchically. Proceedings of the Society for
Computation in Linguistics, 2(1):363–364.
Kenneth Heafield, Ivan Pouzyrevsky, Jonathan H.
clark, and Philipp Koehn. 2013. Scalable mod-
ified Kneser-Ney language model estimation.
In Proceedings of the 51st Annual Meeting of
la Asociación de Lingüística Computacional
(Volumen 2: Artículos breves), pages 690–696.
Michael Heilman, Aoife Cahill, Nitin Madnani,
Melissa Lopez, Matthew Mulholland, y
Joel Tetreault. 2014. Predicting grammaticality
on an ordinal scale. En procedimientos de
el
52nd Annual Meeting of the Association for
Ligüística computacional (Volumen 2: Short
Documentos), volumen 2, pages 174–180.
Sepp Hochreiter y Jürgen Schmidhuber. 1997.
Memoria larga a corto plazo. Computación neuronal,
9(8):1735–1780.
Jeremy Howard and Sebastian Ruder. 2018.
Universal language model fine-tuning for text
the 56th
clasificación.
Annual Meeting of
la Asociación para
Ligüística computacional (Volumen 1: Largo
Documentos), pages 328–339.
En procedimientos de
Jaap Jumelet and Dieuwke Hupkes. 2018. Do
language models understand anything? On
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
the ability of LSTMs to understand negative
el 2018
polarity items. En procedimientos de
EMNLP Workshop BlackboxNLP: Analyzing
and Interpreting Neural Networks for NLP,
pages 222–231.
Katharina Kann, Alex Warstadt, Adina Williams,
and Samuel R. Bowman. 2019. Verb argument
structure alternations in word and sentence
embeddings. Proceedings of the Society for
Computation in Linguistics, 2(1):287–297.
Dave Kush, Terje Lohndal, and Jon Sprouse. 2018.
Investigating variation in island effects. Natural
Idioma & Linguistic Theory, 36(3):743–779.
Jey Han Lau, Alejandro Clark, and Shalom Lappin.
2017. Grammaticality, acceptability, y probablemente-
habilidad: A probabilistic view of linguistic knowl-
borde. Ciencia cognitiva, 41(5):1202–1241.
Tal Linzen, Emmanuel Dupoux, and Yoav
Goldberg. 2016. Assessing the ability of LSTMs
to learn syntax-sensitive dependencies. Trans-
acciones de la Asociación de Computación
Lingüística, 4:521–535.
Rebecca Marvin and Tal Linzen. 2018. Targeted
syntactic evaluation of language models. En
el 2018 Conferencia sobre
Actas de
Empirical Methods
in Natural Language
Procesando, pages 1192–1202.
Stephen Merity, Caiming Xiong, James Bradbury,
and Richard Socher. 2016. Pointer sentinel
mixture models. CORR, abs/1609.07843.
Tom´aˇs Mikolov, Martin Karafi´at, Luk´aˇs Burget,
Jan ˇCernock`y, and Sanjeev Khudanpur. 2010.
Recurrent neural network based language
In Eleventh Annual Conference of
modelo.
el
Speech Communication
Asociación.
Internacional
Matthew E. Peters, Mark Neumann, Mohit Iyyer,
Matt Gardner, Christopher Clark, Kenton Lee,
and Luke Zettlemoyer. 2018. Deep contex-
tualized word representations. arXiv preprint
arXiv:1802.05365.
Alec Radford, Karthik Narasimhan, Tim
Salimans, and Ilya Sutskever. 2018. Improving
language understanding with unsupervised
aprendiendo, Technical report, OpenAI.
Alec Radford, Jeffrey Wu, niño rewon, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI Blog, 1(8).
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Miguel
mañana, Yanqi Zhou, wei li, y Pedro J.. Liu.
2019. Explorando los límites del aprendizaje por transferencia
con un transformador unificado de texto a texto. arXiv
e-prints.
Florencia Reali and Morten H. Christiansen.
2005. Uncovering the richness of the stimulus:
Structure dependence and indirect statistical
evidencia. Ciencia cognitiva, 29(6):1007–1028.
Ivan A. Sag, Thomas Wasow, and Emily M.
Bender. 2003. Syntactic Theory: A Formal
Introducción, 2nd edition. CSLI Publications.
Carson T. Sch¨utze. 1996. The Empirical Base
of Linguistics: Grammaticality Judgments and
Linguistic Methodology. University of Chicago
Prensa.
Xing Shi, Inkit Padhi, and Kevin Knight. 2016.
Does string-based neural MT learn source
syntax? En Actas de la 2016 Conferencia
sobre métodos empíricos en lenguaje natural
Procesando, pages 1526–1534.
Dominique Sportiche, Hilda Koopman, y
Edward Stabler. 2013. Una introducción a
Syntactic Analysis and Theory, John Wiley &
Sons.
Ian Tenney, Patrick Xia, Berlin Chen, Alex
Wang, Adam Poliak, R. Thomas McCoy,
Najoung Kim, Benjamin Van Durme, Samuel R
Bowman, Dipanjan Das, et al. 2019. Qué
do you learn from context? Probing for
sentence structure in contextualized word
representaciones. In Proceedings of ICLR.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Leon Jones, Aidan N..
Gómez, lucas káiser, y Illia Polosukhin.
2017. Attention is all you need, I. Guyon,
Ud.. V. Luxburg, S. bengio, h. Wallach,
R. Fergus, S. Vishwanathan, y r. Garnett,
Información
editores, Avances
Sistemas de procesamiento 30, pages 5998–6008.
Asociados Curran, Cª.
in Neural
391
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alex Wang, Yada Pruksachatkun, Nikita Nangia,
Amanpreet Singh, Julian Michael, Felix Hill,
Omer Levy, and Samuel R. Bowman. 2019a.
SuperGLUE: A stickier benchmark for general-
purpose language understanding systems. En
Información
33rd Conference on Neural
Sistemas de procesamiento.
Alex Wang, Amanpreet Singh, Julian Michael,
Felix Hill, Omer Levy, and Samuel R. Bowman.
benchmark
2018. GLUE: A multi-task
and analysis platform for natural
idioma
el 2018
comprensión. En procedimientos de
EMNLP Workshop BlackboxNLP: Analyzing
and Interpreting Neural Networks for NLP,
pages 353–355.
Alex Wang, Ian F. Tenney, Yada Pruksachatkun,
Katherin Yu, Jan Hula, Patrick Xia, Raghu
Pappagari, Shuning Jin, R. Thomas McCoy,
Roma Patel, Yinghui Huang, Jason Phang,
Edouard Grave, Haokun Liu, Najoung Kim,
Phu Mon Htut, Thibault F’evry, Berlin Chen,
Nikita Nangia, Anhad Mohananey, Katharina
Kann, Shikha Bordia, Nicolas Patry, David
bentón, Ellie Pavlick, and Samuel R. Bowman.
2019b. jiant 1.2: A software toolkit for
research on general-purpose text understanding
modelos. http://jiant.info/.
Gregory Ward and Betty Birner. 1995. Definite-
ness and the English existential. Idioma,
pages 722–742.
Alex Warstadt and Samuel R. Bowman. 2019. lin-
guistic analysis of pretrained sentence encoders
with acceptability judgments. arXiv preprint
arXiv:1901.03438.
Alex Warstadt, Yu Cao, Ioana Grosu, Wei Peng,
Hagen Blix, Yining Nie, Anna Alsop, Shikha
Bordia, Haokun Liu, Alicia Parrish, Sheng-
Fu Wang, Jason Phang, Anhad Mohananey,
Phu Mon Htut, Paloma Jeretiˇc, and Samuel
R. Bowman. 2019a.
Investigating BERT’s
knowledge of language: Five analysis methods
with NPIs. In Proceedings of EMNLP-IJCNLP,
pages 2870–2880.
Alex Warstadt, Amanpreet Singh, and Samuel R.
Bowman. 2019b. Neural network acceptability
judgments. Transactions of the Association for
Ligüística computacional, 7:625–641.
Ethan Wilcox, Roger Levy, Takashi Morita, y
Richard Futrell. 2018. What do RNN language
models learn about filler–gap dependencies? En
Actas de la 2018 EMNLP Workshop
BlackboxNLP: Analyzing and Interpreting
Neural Networks for NLP, pages 211–221.
Ethan Wilcox, Peng Qian, Richard Futrell, Miguel
Ballesteros, and Roger Levy. 2019. Structural
supervision improves learning of non-local
grammatical dependencies. En procedimientos de
el 2019 Conference of the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
pages 3302–3312.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
3
2
1
1
9
2
3
6
9
7
/
/
t
yo
a
C
_
a
_
0
0
3
2
1
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
392