Traducción automática neuronal semántica mediante AMR
Linfeng Song,1 Daniel Gildea,1 Yue Zhang,2 Zhiguo Wang,3 and Jinsong Su4
1Departamento de Ciencias de la Computación, University of Rochester, Rochester, Nueva York 14627
2School of Engineering, Westlake University, Porcelana
3IBM T.J. Watson Research Center, Yorktown Heights, Nueva York 10598
4Xiamen University, Xiamen, Porcelana
1{lsong10,gildea}@cs.rochester.edu 2yue.zhang@wias.org.cn
3zgw.tomorrow@gmail.com 4jssu@xmu.edu.cn
Abstracto
It is intuitive that semantic representations can
be useful for machine translation, mainly be-
cause they can help in enforcing meaning pre-
servation and handling data sparsity (muchos
sentences correspond to one meaning) of ma-
chine translation models. Por otro lado,
little work has been done on leveraging se-
mantics for neural machine translation (NMT).
En este trabajo, we study the usefulness of
AMR (abstract meaning representation) en
NMT. Experiments on a standard English-to-
German dataset show that incorporating AMR
as additional knowledge can significantly
improve a strong attention-based sequence-
to-sequence neural translation model.
1
Introducción
It is intuitive that semantic representations ought
to be relevant to machine translation, given that
the task is to produce a target language sentence
with the same meaning as the source language
aporte. Semantic representations formed the core of
the earliest symbolic machine translation systems,
and have been applied to statistical but non-neural
systems as well.
Leveraging syntax for neural machine trans-
lación (NMT) has been an active research topic
(Stahlberg et al., 2016; Aharoni and Goldberg,
2017; Le et al., 2017; Chen et al., 2017; Bastings
et al., 2017; Wu et al., 2017; Chen et al.,
2018). Por otro lado, exploring semantics
for NMT has so far received relatively little
atención. Recientemente, Marcheggiani et al. (2018)
exploited semantic role labeling (srl) for NMT,
showing that the predicate–argument information
from SRL can improve the performance of an
attention-based sequence-to-sequence model by
alleviating the ‘‘argument switching’’ problem,1
one frequent and severe issue faced by NMT
sistemas (Isabelle et al., 2017). Cifra 1(a) muestra
one example of semantic role information, cual
only captures the relations between a predicate
(gave) and its arguments (John, esposa, and present).
Other important information, such as the relation
between John and wife, cannot be incorporated.
en este documento, we explore the usefulness of
abstract meaning representation (AMR) (Banarescu
et al., 2013) as a semantic representation for
NMT. AMR is a semantic formalism that encodes
the meaning of a sentence as a rooted, directed
graph. Cifra 1(b) shows an AMR graph,
en
which the nodes (such as give-01 y juan) rep-
resent the concepts and edges (como :ARG0 and
:ARG1) represent the relations between concepts
they connect. Comparing with semantic roles,
AMRs capture more relations, such as the rela-
tion between John and wife (represented by the
subgraph within dotted lines). Además, AMRs
directly capture entity relations and abstract away
inflections and function words. Como resultado, ellos
can serve as a source of knowledge for machine
translation that is orthogonal to the textual input.
Además, structural information from AMR
graphs can help reduce data sparsity when training
data is not sufficient for large-scale training.
Recent advances in AMR parsing keep push-
ing the boundary of state-of-the-art performance
(Flanigan et al., 2014; Artzi et al., 2015; Pust
et al., 2015; Peng et al., 2015; Flanigan et al.,
2016; Buys and Blunsom, 2017; Konstas et al.,
2017; Wang and Xue, 2017; Lyu and Titov, 2018;
1Eso es, flipping arguments corresponding to different
roles.
19
Transacciones de la Asociación de Lingüística Computacional, volumen. 7, páginas. 19–31, 2019. Editor de acciones: Philipp Koehn.
Lote de envío: 6/2018; Lote de revisión: 10/2018; Publicado 3/2019.
C(cid:13) 2019 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
yo
a
C
_
a
_
0
0
2
5
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
cantly improves a strong attention-based sequence-
to-sequence baseline (25.5 vs 23.7 AZUL). Cuando
trained with small-scale (226k) datos,
the im-
provement increases (19.2 vs 16.0 AZUL), cual
shows that the structural information from AMR
can alleviate data sparsity when training data are
not sufficient. To our knowledge, we are the first
to investigate AMR for NMT.
Our code and parallel data (training/dev/test)
with automatically parsed AMRs are available at
https://github.com/freesunshine0316/semantic-nmt.
2 Trabajo relacionado
Most previous work on exploring semantics
for statistical machine translation (SMT) estudios
the usefulness of predicate–argument structure
from semantic role labeling (Wong and Mooney,
2006; Wu and Fung, 2009; Liu and Gildea,
2010; Baker et al., 2012). Jones et al. (2012)
first convert Prolog expressions into graphical
meaning representations, leveraging synchronous
hyperedge replacement grammar to parse the
input graphs while generating the outputs. Su
graphical meaning representation is different
from AMR under a strict definition, and their
experimental data are limited to 880 oraciones.
We are the first to investigate AMR on a large-
scale machine translation task.
Recientemente, Marcheggiani et al. (2018) investi-
gated SRL on NMT. The predicate–argument
structures are encoded via graph convolutional
network (GCN) capas (Kipf and Welling, 2017),
which are laid on top of regular BiRNN or CNN
capas. Our work is in line with exploring seman-
tic information, but different in exploiting AMR
rather than SRL for NMT. Además, we lever-
age a GRN (Song et al., 2018; Zhang et al., 2018)
for modeling AMRs rather than GCN, cual
is formally consistent with the RNN sentence
encoder. Since there is no one-to-one correspon-
dence between AMR nodes and source words,
we adopt a doubly attentive LSTM decoder, cual
is another major difference from Marcheggiani
et al. (2018).
GRNs have recently been used to model graph
structures in NLP tasks. En particular, zhang
et al. (2018) use a GRN model
to represent
raw sentences by building a graph structure of
neighboring words and a sentence-level node,
showing that the encoder outperforms BiLSTMs
Cifra 1:
(a) A sentence with semantic roles
anotaciones; (b) the corresponding AMR graph of that
oración.
Peng et al., 2018; Groschwitz et al., 2018; guo
and Lu, 2018), and have made it possible for
automatically generated AMRs to benefit down-
stream tasks, such as question answering (Mitra
and Baral, 2015), summarization (Takase et al.,
2016), and event detection (Le et al., 2015a).
Sin embargo, a nuestro conocimiento, no existing work has
exploited AMR for enhancing NMT.
We fill in this gap, taking an attention-based
sequence-to-sequence system as our baseline, cual
is similar to Bahdanau et al. (2015). To leverage
knowledge within an AMR graph, we adopt a
graph recurrent network (GRN) (Song et al.,
2018; Zhang et al., 2018) as the AMR encoder.
En particular, a full AMR graph is considered as
a single state, with nodes in the graph being its
substates. State transitions are performed on the
graph recurrently, allowing substates to exchange
information through edges. At each recurrent step,
each node advances its current state by receiving
information from the current states of its adjacent
nodos. De este modo, with increasing numbers of recurrent
steps, each word receives information from a
larger context. Cifra 3 shows the recurrent tran-
posición, where each node works simultaneously.
Compared with other methods for encoding AMRs
(Konstas et al., 2017), GRN keeps the original graph
estructura, and thus no information is lost (Song
et al., 2018). For the decoding stage, two separate
attention mechanisms are adopted in the AMR
encoder and sequential encoder, respectivamente.
Experiments on WMT16 English-to-German
datos (4.17METRO) show that adopting AMR signifi-
20
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
yo
a
C
_
a
_
0
0
2
5
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
and Transformer
(Vaswani et al., 2017) en
classification and sequence labeling tasks; Song
et al. (2018) build a GRN for encoding AMR
graphs for text generation, mostrando que
el
representation is superior compared to BiLSTM
on serialized AMR. We extend Song et al. (2018)
by investigating the usefulness of AMR for neu-
ral machine translation. To our knowledge, nosotros
are the first to use GRN for machine translation.
In addition to GRNs and GCNs, there have
been other graph neural networks, such as graph
gated neural network (GGNN) (Le et al., 2015b;
Beck et al., 2018). Because our main concern is to
empirically investigate the effectiveness of AMR
for NMT, we leave it to future work to compare
GCN, GGNN, and GRN for our task.
3 Base: Attention-Based BiLSTM
We take the attention-based sequence-to-sequence
model of Bahdanau et al. (2015) as the baseline,
but use LSTM cells (Hochreiter and Schmidhuber,
1997) instead of GRU cells (Cho et al., 2014).
3.1 BiLSTM Encoder
←−
h 1,
−→
h 1,
−→
h 2, . . .
←−
h 2, . . . ,
←−
h N ] y [
The encoder is a bidirectional LSTM on the
source side. Given a sentence, two sequences of
−→
estados [
h N ]
are generated for representing the input word
sequence x1, x2, . . . , xN in the right-to-left and
left-to-right directions, respectivamente, where for
each word xi,
←−
h i = LSTM(
−→
h i = LSTM(
←−
h i+1, exi)
−→
h i−1, exi)
exi is the embedding of word xi.
3.2 Attention-Based Decoder
The decoder yields a word sequence in the target
language y1, y2, . . . , yM by calculating a sequence
of hidden states s1, s2 . . . , sM recurrently. Nosotros
use an attention-based LSTM decoder (Bahdanau
et al., 2015), where the attention memory (h) es
the concatenation of the attention vectors among
all source words. Each attention vector hi is the
concatenation of the encoder states of an input
token in both directions (
←−
h i and
−→
h i):
←−
h i;
−→
h i]
hi = [
H = [h1; h2; . . . ; hN ].
N is the number of source words.
21
While generating the m-th word, the decoder
considers four factors: (1) the attention memory
h; (2) the previous hidden state of the LSTM
model sm−1; (3) the embedding of the current
aporte (previously generated word) eym; y (4)
the previous context vector ζm−1 from attention
memory H. When m = 1, we initialize ζ0 as a
zero vector, set ey1 to the embedding of sentence
start token ‘‘'', and calculate s0 from the last
step of the encoder states via a dense layer:
s0 = W 1[
←−
h 0;
−→
h N ] + b1,
where W 1 and b1 are model parameters.
For each decoding step m, the decoder feeds
the concatenation of the embedding of the current
input eym and the previous context vector ζm−1
into the LSTM model to update its hidden state:
sm = LSTM(sm−1, [eym; ζm−1]).
Then the attention probability αm,i on the attention
vector hi ∈ H for the current decode step is
calculated as:
(cid:15)metro,i = v
(cid:124)
2 tanh(W hhi + W ssm + b2)
αm,i =
exp.((cid:15)metro,i)
j=1 exp((cid:15)metro,j)
(cid:80)norte
.
W h, W s, v2, and b2 are model parameters. El
new context vector ζm is calculated via
ζm =
norte
(cid:88)
yo=1
αm,ihi.
The output probability distribution over the target
vocabulary at the current state is calculated by
P vocab = softmax(V 3[sm, ζm] + b3),
(1)
where V 3 and b3 are learnable parameters.
4
Incorporating AMR
Cifra 2 shows the overall architecture of our
modelo, which adopts a BiLSTM (abajo a la izquierda)
and our graph recurrent network (GRN)2 (abajo
bien) for encoding the source sentence and AMR,
respectivamente. An attention-based LSTM decoder
is used to generate the output sequence in the
target language, with attention models over both
the sequential encoder and the graph encoder. El
2We show the advantage of our graph encoder by com-
paring with another popular method for encoding AMRs in
Sección 6.3.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
yo
a
C
_
a
_
0
0
2
5
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
yo
a
C
_
a
_
0
0
2
5
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2: Overall architecture of our model.
Cifra 3: Architecture of the graph recurrent network.
attention memory for the graph encoder is from
the last step of the graph state transition process,
which is shown in Figure 3.
4.1 Encoding AMR with GRN
Cifra 3 shows the overall structure of our graph
recurrent network for encoding AMR graphs,
which follows Song et al. (2018). Formalmente, given
an AMR graph G = (V , mi), we use a hidden
state vector aj to represent each node vj ∈ V .
The state of the graph can thus be represented as:
g = {aj}|vj ∈V .
In order to capture non-local interaction between
nodos, information exchange between nodes is
executed through a sequence of state transitions,
leading to a sequence of states g0, g1, . . . , gT ,
where gt = {aj
t }|vj ∈V , and T is the number of
state transitions, which is a hyperparameter. El
initial state g0 consists of a set of initial node
states aj
0 = a0, where a0 is a vector of all zeros.
A recurrent neural network is used to model the
state transition process. En particular, the transi-
tion from gt−1 to gt consists of a hidden state tran-
sition for each node (such as from aj
t−1 to aj
t ),
as shown in Figure 3. At each state transition
step t, our model conducts direct communication
between a node and all nodes that are directly con-
nected to the node. To avoid gradient diminishing
or bursting, LSTM (Hochreiter and Schmidhuber,
1997) is adopted, where a cell cj
t is taken to re-
cord memory for aj
t , un
output gate oj
t , and a forget gate f j
t to control in-
formation flow from the inputs and to the output aj
t .
The inputs include representations of edges
that are connected to vj, where vj can be either
t . We use an input gate ij
22
the source or the target of the edge. Definimos
each edge as a triple (i, j, yo), where i and j are
indices of the source and target nodes, respetar-
activamente, and l is the edge label. SG
i,j is the repre-
sentation of edge (i, j, yo), detailed in Section 4.1.1.
The inputs for vj are grouped into incoming and
outgoing edges before being summed up:
φj =
ˆφj =
(cid:88)
SG
i,j
(i,j,yo)∈Ein(j)
(cid:88)
(j,k,yo)∈Eout(j)
SG
j,k
where Ein(j) and Eout(j) are the sets of incoming
and outgoing edges of vj, respectivamente.
In addition to edge inputs, our model also takes
the hidden states of the incoming and outgoing
neighbors of each node during a state transition.
Taking vj as an example, the states of its incoming
and outgoing neighbors are summed up before
being passed to the cell and gate nodes:
ψj =
ˆψj =
(cid:88)
ai
t−1
(i,j,yo)∈Ein(j)
(cid:88)
ak
t−1.
(j,k,yo)∈Eout(j)
Based on the above definitions of φj, ˆφj, ψj,
and ˆψj, the state transition from gt−1 to gt, como
represented by aj
t , can be defined as:
ˆφj + U iψj + ˆU i
ˆφj + U oψj + ˆU o
ˆφj + U f ψj + ˆU f
ˆφj + U uψj + ˆU u
ˆψj + bi)
ˆψj + bo)
ˆψj + bf )
ˆψj + bu)
t = σ(W iφj + ˆW i
ij
t = σ(W oφj + ˆW o
oj
t = σ(W f φj + ˆW f
f j
t = σ(W uφj + ˆW u
uj
cj
t = f j
t−1 + ij
t (cid:12) cj
t (cid:12) uj
t (cid:12) tanh(cj
t = oj
aj
t ),
t
John wants to go……möchtegehenmöchte
t , oj
t , and f j
where ij
t are the input, producción, and for-
get gates mentioned earlier. W x, ˆW x, U x, ˆU x,
bx, where x ∈ {i, oh, F, tu}, are model parameters.
With this state transition mechanism, infor-
mation of each node is propagated to all
es
neighboring nodes after each step. So after several
transition steps, each node state contains the in-
formation of a large context, including its an-
cestors, descendants, and siblings. For the worst
case where the input graph is a chain of nodes,
the maximum number of steps necessary for
information from one arbitrary node to reach
another is equal to the size of the graph. Nosotros
experiment with different numbers of transition
steps to study the effectiveness of global encoding.
4.1.1
Input Representation
The edges of an AMR graph contain labels,
which represent relations between the nodes they
connect, and are thus important for modeling the
graphs. The representation for each edge (i, j, yo)
is defined as:
SG
i,j = W 4
(cid:16)
[el; evi]
(cid:17)
+ b4,
where el and ei are the embeddings of edge label
l and source node vi, and W 4 and b4 are model
parámetros.
4.2
Incorporating AMR Information with a
Doubly Attentive Decoder
There is no one-to-one correspondence between
AMR nodes and source words. To incorporate
additional knowledge from an AMR graph, un
external attention model is adopted over the base-
the attention mem-
line model. En particular,
ory from the AMR graph is the last graph state
gT = {aj
the contextual
vector based on the graph state is calculated as:
t }|vj ∈V . Además,
˜(cid:15)metro,i = ˜v
˜αm,i =
(cid:124)
2 tanh(W aai
exp.(˜(cid:15)metro,i)
j=1 exp(˜(cid:15)metro,j)
(cid:80)norte
.
t + ˜W ssm + ˜b2)
i=1 ˜αm,iai
W a, ˜W s, ˜v2, and ˜b2 are model parameters.
The new context vector ˜ζm is calculated via
(cid:80)norte
t . Finalmente, ˜ζm is incorporated into the
calculation of the output probability distribution
over the target vocabulary (previously defined in
Ecuación 1):
P vocab = softmax(V 3[sm, ζm, ˜ζm] + b3).
(2)
23
5 Capacitación
Given a set of training instances {(X (1), Y (1)),
(X (2), Y (2)), . . . }, we train our models using the
cross-entropy loss over each gold-standard target
sequence Y (j) = y(j)
2 , . . . , y(j)
METRO :
1 , y(j)
l = −
METRO
(cid:88)
m=1
iniciar sesión p(y(j)
metro |y(j)
m−1, . . . , y(j)
1 , X (j); i).
X (j) represents the inputs for the jth instance,
which is a source sentence for our baseline, o
a source sentence paired with an automatically
parsed AMR graph for our model. θ represents
the model parameters.
6 experimentos
We empirically investigate the effectiveness of
AMR for English-to-German translation.
6.1 Setup
Data We use the WMT163 English-to-German
conjunto de datos, which contains around 4.5 million sen-
tence pairs for training. Además, we use a sub-
set of the full dataset (News Commentary v11
[NC-v11], containing around 243,000 oración
pares) for development and additional experi-
mentos. For all experiments, we use newstest2013
and newstest2016 as the development and test
conjuntos, respectivamente.
To preprocess the data,
the tokenizer from
Moses4 is used to tokenize both the English
and German sides. The training sentence pairs
where either side is longer than 50 words are
filtered out after tokenization. To deal with rare
and compound words, byte-pair encoding (BPE)5
(Sennrich et al., 2016) is applied to both sides.
En particular, 8,000 y 16,000 BPE merges are
used on the News Commentary v11 subset and
the full training set, respectivamente. En el otro
mano, JAMR6 (Flanigan et al., 2016) is adopted
to parse the English sentences into AMRs before
BPE is applied. The statistics of the training data
and vocabularies after preprocessing are shown in
Tables 1 y 2, respectivamente. For the experiments
with the full training set, we used the top 40K
3http://www.statmt.org/wmt16/translation-task.html.
4http://www.statmt.org/moses/.
5https://github.com/rsennrich/subword-nmt.
6https://github.com/jflanigan/jamr.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
yo
a
C
_
a
_
0
0
2
5
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Dataset
NC-v11
Lleno
News2013
News2016
#Sent.
226k
4.17METRO
3000
2999
#Tok. (EN)
6.4METRO
109METRO
84.7k
88.1k
#Tok. (DE)
7.3METRO
118METRO
95.6k
98.8k
Mesa 1: Statistics of the dataset. Numbers of tokens
are after BPE processing.
Dataset
NC-v11
Lleno
DE
AMR
EN
EN-ori
79.8k
8.4K 36.6K 8.3K
874K 19.3K 403K 19.1K
Mesa 2: Sizes of vocabularies. EN-ori represents
original English sentences without BPE.
of the AMR vocabulary, which covers more than
99.6% of the training set.
For our dependency-based and SRL-based base-
líneas (which will be introduced in Baseline Sys-
tems), we choose Stanford CoreNLP Manning
et al. (2014) and IBM SIRE to generate depen-
dency trees and semantic roles, respectivamente. Desde
both dependency trees and semantic roles are
based on the original English sentences without
BPE, we used the top 100K frequent English words,
which cover roughly 99.0% of the training set.
Hyperparameters We use the Adam optimizer
(Kingma and Ba, 2014) with a learning rate of
0.0005. The batch size is set to 128. Between
capas, we apply dropout with a probability of
0.2. The best model
is picked based on the
cross-entropy loss on the development set. Para
model hyperparameters, we set the graph state
transition number to 10 according to development
experimentos. Each node takes information from
at most six neighbors. AZUL (Papineni et al.,
2002), TER (Snover et al., 2006), and Meteor
(Denkowski and Lavie, 2014) are used as the
metrics on cased and tokenized results.
For experiments with the NC-v11 subset, ambos
word embedding and hidden vector sizes are set
a 500, and the models are trained for at most
30 epochs. For experiments with full training set,
the word embedding and hidden state sizes are set
a 800, and our models are trained for at most
10 epochs. For all systems, the word embeddings are
randomly initialized and updated during training.
Baseline Systems We compare our model with
the following systems. Seq2seq represents our
attention-based LSTM baseline (Sección 3), y
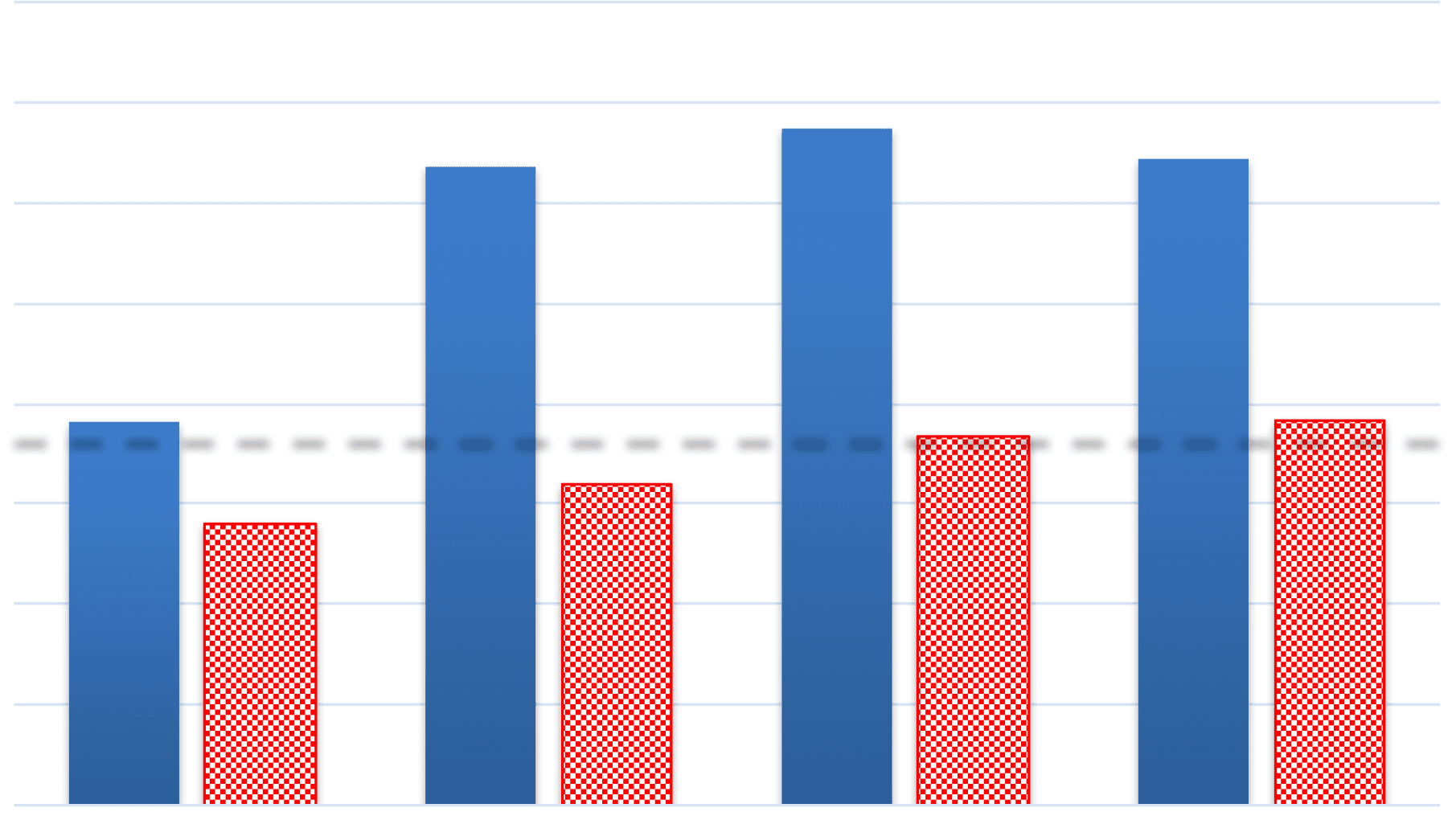
Cifra 4: DEV BLEU scores against transition steps for
the graph encoders. The state transition is not applicable
to Seq2seq, so we draw a dashed line to represent its
actuación.
Dual2seq is our model, which takes both a se-
quential and a graph encoder and adopts a
doubly attentive decoder (Sección 4). To show the
merit of AMR, we further contrast our model with
the following baselines, all of which adopt the
same doubly attentive framework with a BiLSTM
for encoding BPE-segmented source sentences:
Dual2seq-LinAMR uses another BiLSTM for
encoding linearized AMRs. Dual2seq-Dep and
Dual2seq-SRL adopt our graph recurrent net-
work to encode original source sentences with
dependency and semantic role annotations, re-
spectively. The three baselines are useful for
contrasting different methods of encoding AMRs
and for comparing AMRs with other popular
structural information for NMT.
We also compare with Transformer (Vaswani
et al., 2017) and OpenNMT (Klein et al.,
2017), trained on the same dataset and with the
same set of hyperparameters as our systems. En
particular, we compare with Transformer-tf, uno
popular implementation7 of Transformer based
on TensorFlow, and we choose OpenNMT-tf, un
official release8 of OpenNMT implemented with
TensorFlow. For a fair comparison, OpenNMT-tf
has one layer for both the encoder and the decoder,
and Transformer-tf has the default configuration
(norte = 6), but with parameters being shared among
different blocks.
6.2 Development Experiments
Cifra 4 shows the system performances as a
function of the number of graph state transitions
7https://github.com/Kyubyong/transformer.
8https://github.com/OpenNMT/OpenNMT-tf.
24
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
yo
a
C
_
a
_
0
0
2
5
2
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Sistema
OpenNMT-tf
Transformer-tf
Seq2seq
Dual2seq-LinAMR
Duel2seq-SRL
Dual2seq-Dep
Dual2seq
NC-V11
BLEU TER↓ Meteor
0.3040
0.6902
15.1
0.3578
0.6647
17.1
0.3379
0.6695
16.0
0.3612
0.6530
17.3
0.3644
0.6591
17.2
0.3673
0.6516
17.8
0.3840
0.6305
19.2*
FULL
BLEU TER↓ Meteor
0.4225
0.5567
24.3
0.4344
0.5537
25.1
0.4258
0.5590
23.7
0.4246
0.5643
24.0
0.4223
0.5626
23.8
0.4328
0.5538
25.0
0.4376
0.5480
25.5*
Mesa 3: TEST performance. NC-v11 represents training only with the NC-v11 data, while Full means using the
full training data. * represents significant (Koehn, 2004) resultado (pag < 0.01) over Seq2seq. ↓ indicates the lower
the better.
on the development set. Dual2seq (self) represents
our dual-attentive model, but its graph encoder
encodes the source sentence, which is treated
as a chain graph instead of an AMR graph.
Compared with Dual2seq, Dual2seq (self) has
the same number of parameters, but without
semantic information from AMR. Due to hardware
limitations, we do not perform an exhaustive
search by evaluating every possible state transition
number, but only transition numbers of 1, 5, 10,
and 12.
Our Dual2seq shows consistent performance
improvement by increasing the transition number
both from 1 to 5 (roughly +1.3 BLEU points)
and from 5 to 10 (roughly 0.2 BLEU points).
The former shows greater improvement
than
the latter, showing that the performance starts
to converge after five transition steps. Further
increasing transition steps from 10 to 12 gives
a slight performance drop. We set the number
of state transition steps to 10 for all experiments
according to these observations.
On the other hand, Dual2seq (self) shows
only small improvements by increasing the state
transition number, and it does not perform
better than Seq2seq. Both results show that the
performance gains of Dual2seq are not due to an
increased number of parameters.
6.3 Main Results
Table 3 shows the TEST BLEU, TER, and Meteor
scores of all systems trained on the small-scale
News Commentary v11 subset or the large-scale
full set. Dual2seq is consistently better than the
other systems under all three metrics, showing
the effectiveness of the semantic information pro-
vided by AMR. Especially, Dual2seq is better
than both OpenNMT-tf and Transformer-tf. The
it
in that
to Transformer
recurrent graph state transition of Dual2seq is
similar
iteratively
incorporates global information. The improve-
ment of Dual2seq over Transformer-tf undoubt-
edly comes from the use of AMRs, which provide
complementary information to the textual inputs
of the source language.
In terms of BLEU score, Dual2seq is signif-
icantly better than Seq2seq in both settings, which
shows the effectiveness of incorporating AMR
information. In particular, the improvement is
much larger under the small-scale setting (+3.2
BLEU) than that under the large-scale setting
(+1.7 BLEU). This is an evidence that structural
and coarse-grained semantic information encoded
in AMRs can be more helpful when training data
are limited.
When trained on the NC-v11 subset, the gap
between Seq2seq and Dual2seq under Meteor
(around 5 points) is greater than that under BLEU
(around 3 points). Since Meteor gives partial credit
to outputs that are synonyms to the reference or
share identical stems, one possible explanation is
that the structural information within AMRs helps
to better translate the concepts from the source
language, which may be synonyms or paronyms
of reference words.
As shown in the second group of Table 3,
we further compare our model with other meth-
ods of leveraging syntactic or semantic infor-
mation. Dual2seq-LinAMR shows much worse
performance than our model and only slightly
outperforms the Seq2seq baseline. Both results
show that simply taking advantage of the AMR
concepts without their relations does not help very
much. One reason may be that AMR concepts,
such as John and Mary, also appear in the textual
input, and thus are also encoded by the other
25
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
AMR Anno. BLEU
16.8
Automatic
17.5*
Gold
Table 4: BLEU scores of Dual2seq on The Little Prince
data, when gold or automatic AMRs are available.
(sequential) encoder.9 The gap between Dual2seq
and Dual2seq-LinAMR comes from modeling the
relations between concepts, which can be helpful
for deciding target word order by enhancing the
relations in source sentences. We conclude that
properly encoding AMRs is necessary to make
them useful.
Encoding dependency trees instead of AMRs,
Dual2seq-Dep shows a larger performance gap
with our model (17.8 vs 19.2) on small-scale
training data than on large-scale training data
(25.0 vs 25.5). It is likely because AMRs are more
useful on alleviating data sparsity than dependency
trees, since words are lemmatized into unified
concepts when parsing sentences into AMRs. For
modeling long-range dependencies, AMRs have
one crucial advantage over dependency trees by
modeling concept-concept relations more directly.
It is because AMRs drop function words; thus
the distances between concepts are generally
closer in AMRs than in dependency trees. Finally,
Dual2seq-SRL is less effective than our model,
because the annotations labeled by SRL are a
subset of AMRs.
We outperform Marcheggiani et al. (2018) on
the same datasets, although our systems vary
in a number of respects. When trained on the
NC-v11 data, they show BLEU scores of 14.9
only with their BiLSTM baseline, 16.1 using
additional dependency information, 15.6 using
additional semantic roles, and 15.8 taking both
as additional knowledge. Using Full as the training
data, the scores become 23.3, 23.9, 24.5, and 24.9,
respectively. In addition to the different seman-
tic representation being used (AMR vs SRL),
Marcheggiani et al. (2018) laid GCN (Kipf and
Welling, 2017) layers on top of a bidirectional
LSTM (BiLSTM) layer, and then concatenated
layer outputs as the attention memory. GCN
layers encode the semantic role information, while
BiLSTM layers encode the input sentence in the
source language, and the concatenated hidden
Figure 5: Test BLEU score of various sentence lengths.
states of both layers contain information from
both semantic role and source sentence. For
incorporating AMR, because there is no one-
to-one word-to-node correspondence between a
sentence and the corresponding AMR graph, we
adopt separate attention models. Our BLEU scores
are higher than theirs, but we cannot conclude that
the advantage primarily comes from AMR.
6.4 Analysis
Influence of AMR Parsing Accuracy To ana-
lyze the influence of AMR parsing on our model
performance, we further evaluate on a test set
where the gold AMRs for the English side are
available. In particular, we choose The Little
Prince corpus, which contains 1,562 sentences
with gold AMR annotations.10 Since there are no
parallel German sentences, we take a German-
version The Little Prince novel, and then perform
manual sentence alignment. Taking the whole The
Little Prince corpus as the test set, we measure the
influence of AMR parsing accuracy by evaluating
on the test set when gold or automatically parsed
AMRs are available. The automatic AMRs are
generated by parsing the English sentences with
JAMR.
Table 4 shows the BLEU scores of our
Dual2seq model taking gold or automatic AMRs
as inputs. Not listed in Table 4, Seq2seq achieves
a BLEU score of 15.6, which is 1.2 BLEU points
lower than using automatic AMR information.
The improvement from automatic AMR to gold
AMR (+0.7 BLEU) is significant, which shows
the translation quality of our model can
that
be further improved with an increase of AMR
parsing accuracy. However, the BLEU score with
gold AMR does not indicate the potentially best
9AMRs can contain multi-word concepts, such as New
York City, but they are in the textual input.
10https://amr.isi.edu/download.html.
26
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
lokalen Medien treffen seitdem im kroatischen Tovarnik st¨andig Polizeifahrzeuge mit neuen
AMR: (s2 / say-01 :ARG0 (p3 / person :ARG1-of (h / have-rel-role-91 :ARG0 (p / person :ARG1-of (m2 /
meet-03 :ARG0 (t / they) :ARG2 15) :mod (m / mutual)) :ARG2 (f / friend)) :name (n2 / name :op1 ‘‘Carla’’ :op2
‘‘Hairston’’)) :ARG1 (a / and :op1 (p2 / person :name (n / name :op1 ‘‘Lamb’’))) :ARG2 (s / she) :time 20)
Src: Carla Hairston said she was 15 and Lamb was 20 when they met through mutual friends .
Ref: Carla Hairston sagte , sie war 15 und Lamm war 20 , als sie sich durch gemeinsame Freunde trafen .
Dual2seq: Carla Hairston sagte , sie war 15 und Lamm war 20 , als sie sich durch gegenseitige Freunde trafen .
Seq2seq: Carla Hirston sagte , sie sei 15 und Lamb 20 , als sie durch gegenseitige Freunde trafen .
AMR: (s / say-01 :ARG0 (m / media :ARG1-of (l / local-02)) :ARG1 (c2 / come-01 :ARG1 (v / vehicle :mod (p
/ police)) :manner (c3 / constant) :path (a / across :op1 (r / refugee :mod (n2 / new))) :time (s2 / since :op1 (t3 /
then)) :topic (t / thing :name (n / name :op1 (c / Croatian) :op2 (t2 / Tavarnik)))))
Src: Since then , according to local media , police vehicles are constantly coming across new refugees in Croatian
Tavarnik .
Ref: Laut
Fl¨uchtlingen ein .
Dual2seq: Seither kommen die Polizeifahrzeuge nach den ¨ortlichen Medien st¨andig ¨uber neue Fl¨uchtlinge in
Kroatische Tavarnik .
Seq2seq: Seitdem sind die Polizeiautos nach den lokalen Medien st¨andig neue Fl¨uchtlinge in Kroatien
Tavarnik .
AMR: (b2 / breed-01 :ARG0 (p2 / person :ARG0-of (h / have-org-role-91 :ARG2 (s3 / scientist))) :ARG1 (w2 /
worm) :ARG2 (s2 / system :ARG1-of (c / control-01 :ARG0 (b / burst-01 :ARG1 (w / wave :mod (s / sound)))
:ARG1-of (p / possible-01)) :ARG1-of (n / nervous-01) :mod (m / modify-01 :ARG1 (g / genetics))))
Src: Scientists have bred worms with genetically modified nervous systems that can be controlled by bursts of
sound waves .
Ref: Wissenschaftler haben W¨urmer mit genetisch ver¨anderten Nervensystemen gez¨uchtet
Ausbr¨uchen von Schallwellen gesteuert werden k¨onnen .
Dual2seq: Die Wissenschaftler haben die W¨urmer mit genetisch ver¨anderten Nervensystemen gez¨uchtet,
die durch Verbrennungen von Schallwellen kontrolliert werden k¨onnen .
Seq2seq: Wissenschaftler haben sich mit genetisch modifiziertem Nervensystem gez¨uchtet
Verbrennungen von Klangwellen gesteuert werden k¨onnen .
, die durch
, die von
Figure 6: Sample system outputs.
performance that our model can achieve. The
primary reason is that even though the test set
is coupled with gold AMRs, the training set is
not. Trained with automatic AMRs, our model
can learn to selectively trust the AMR structure.
An additional reason is the domain difference:
The Little Prince data are in the literary domain
while our training data are in the news domain.
There can be a further performance gain if the
accuracy of the automatic AMRs on the training
set is improved.
Performance Based on Sentence Length We
hypothesize that AMRs should be more beneficial
for longer sentences: Those are likely to contain
long-distance dependencies (such as discourse
information and predicate–argument structures),
which may not be adequately captured by linear
chain RNNs but are directly encoded in AMRs.
To test this, we partition the test data into four
buckets by length and calculate BLEU for each
of them. Figure 5 shows the performances of our
model along with Dual2seq-Dep and Seq2seq. Our
model outperforms the Seq2seq baseline rather
uniformly across all buckets, except for the first
one, where they are roughly equal. This may be
surprising. On the one hand, Seq2seq fails to
capture some dependencies for medium-length
instances; on the other hand, AMR parses are
more noisy for longer sentences, which prevents us
from obtaining extra improvements with AMRs.
Dependency trees have been proved useful
in capturing long-range dependencies. Figure 5
shows that AMRs are comparatively better than
dependency trees, especially on medium-length
(21–30) sentences. The reason may be that the
AMRs of medium-length sentences are much
more accurate than longer sentences, and thus are
better at capturing the relations between concepts.
On the other hand, even though dependency trees
are more accurate than AMRs, they still fail to
represent relations for long sentences. It is likely
because relations for longer sentences are more
difficult to detect. Another possible reason is that
dependency trees do not incorporate coreferences,
which AMRs consider.
27
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Human Evaluation We further study the trans-
lation quality of predicate–argument structures by
conducting a human evaluation on 100 instances
from the test set. In the evaluation, translations
of both Dual2seq and Seq2seq, together with the
source English sentence, the German reference,
and an AMR are provided to a German-speaking
annotator
to decide which translation better
captures the predicate–argument structures in
the source sentence. To avoid annotation bias,
translation results of both models are swapped for
some instances, and the German annotator does
not know which model each translation belongs
to. The annotator either selects a ‘‘winner’’ or
makes a ‘‘tie’’ decision, meaning that both results
are equally good.
Out of the 100 instances, Dual2seq wins on
46, Seq2seq wins on 23, and there is a tie on
the remaining 31. Dual2seq wins on almost half
of the instances, about twice as often as Seq2seq
wins, indicating that AMRs help in translating
the predicate–argument structures on the source
side.
Case Study The outputs of the baseline system
(Seq2seq) and our final system (Dual2seq) are
shown in Figure 6. In the first sentence, the AMR-
based Dual2seq system correctly produces the
reflexive pronoun sich as an argument of the
verb trafen (meet), despite the distance between
the words in the system output, and despite the
fact that the equivalent English words each other
do not appear in the system output. This is
facilitated by the argument structure in the AMR
analysis.
In the second sentence,
the AMR-based
Dual2seq system produces an overly literal trans-
lation for the English phrasal verb come across.
incorrectly
The Seq2seq translation, however,
states that the police vehicles are refugees. The
difficulty for the Seq2seq probably derives in part
from the fact that are and coming are separated by
the word constantly in the input, while the main
predicate is clear in the AMR representation.
In the third sentence,
the Dual2seq system
correctly translates the object of breed as worms,
while the Seq2seq translation incorrectly states
the scientists breed themselves. Here the
that
difficulty is likely the distance between the object
and the verb in the German output, which causes
the Seq2seq system to lose track of the correct
input position to translate.
7 Conclusion
We showed that AMRs can improve neural
machine translation. In particular, the structural
semantic information from AMRs can be com-
plementary to the source textual input by intro-
ducing a higher level of information abstraction.
A graph recurrent network (GRN) is leveraged
to encode AMR graphs without breaking the
original graph structure, and a sequential LSTM
is used to encode the source input. The decoder
is a doubly attentive LSTM, taking the encoding
results of both the graph encoder and the sequential
encoder as attention memories. Experiments on
a standard benchmark showed that AMRs are
helpful regardless of the sentence length and are
more effective than other more popular choices,
such as dependency trees and semantic roles.
Acknowledgments
We would like to thank the action editor and
the anonymous reviewers for their insightful
comments. We also thank Kai Song from Alibaba
for suggestions on large-scale training, Parker
Riley for comments on the draft, and Rochester’s
CIRC for computational resources.
References
Roee Aharoni and Yoav Goldberg. 2017. Towards
string-to-tree neural machine translation. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(ACL-17), pages 132–140.
Yoav Artzi, Kenton Lee, and Luke Zettlemoyer.
2015. Broad-coverage CCG semantic pars-
ing with AMR. In Conference on Empirical
Methods in Natural Language Processing
(EMNLP-15), pages 1699–1710.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
Bengio. 2015. Neural machine translation by
In
jointly learning to align and translate.
International Conference on Learning Repre-
sentations (ICLR).
Kathryn Baker, Michael Bloodgood, Bonnie J
Dorr, Chris Callison-Burch, Nathaniel W
Filardo, Christine Piatko, Lori Levin, and
Scott Miller. 2012. Modality and negation
in SIMT use of modality and negation in
semantically-informed syntactic MT. Compu-
tational Linguistics, 38(2):411–438.
28
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Laura Banarescu, Claire Bonial, Shu Cai,
Madalina Georgescu, Kira Griffitt, Ulf
Hermjakob, Kevin Knight, Philipp Koehn,
Martha Palmer, and Nathan Schneider. 2013.
Abstract meaning representation for sembank-
the 7th Linguistic
ing.
Annotation Workshop and Interoperability with
Discourse, pages 178–186.
In Proceedings of
Joost Bastings, Ivan Titov, Wilker Aziz, Diego
Marcheggiani, and Khalil Simaan. 2017. Graph
convolutional encoders for syntax-aware neu-
In Conference on
ral machine translation.
Empirical Methods
in Natural Language
Processing (EMNLP-17), pages 1957–1967.
Daniel Beck, Gholamreza Haffari, and Trevor
Cohn. 2018. Graph-to-sequence learning using
gated graph neural networks. In Proceedings
of the 56th Annual Meeting of the Associa-
tion for Computational Linguistics (ACL-18),
pages 273–283.
Jan Buys and Phil Blunsom. 2017. Robust
incremental neural semantic graph parsing. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(ACL-17), pages 1215–1226.
Huadong Chen, Shujian Huang, David Chiang,
and Jiajun Chen. 2017. Improved neural ma-
chine translation with a syntax-aware encoder
and decoder. In Proceedings of the 55th Annual
Meeting of the Association for Computational
Linguistics (ACL-17), pages 1936–1945.
Kehai Chen, Rui Wang, Masao Utiyama, Eiichiro
Sumita, and Tiejun Zhao. 2018. Syntax-directed
attention for neural machine translation. In
Proceedings of the National Conference on
Artificial Intelligence (AAAI-18).
Kyunghyun Cho, Bart van Merrienboer, Caglar
Gulcehre, Dzmitry Bahdanau, Fethi Bougares,
Holger Schwenk, and Yoshua Bengio. 2014.
Learning phrase representations using RNN
encoder–decoder for statistical machine trans-
lation. In Conference on Empirical Methods
in Natural Language Processing (EMNLP-14),
pages 1724–1734.
of the Ninth Workshop on Statistical Machine
Translation, pages 376–380.
Jeffrey Flanigan, Chris Dyer, Noah A. Smith,
and Jaime Carbonell. 2016. CMU at SemEval-
2016 Task 8: Graph-based AMR parsing
with infinite ramp loss. In Proceedings of
the 10th International Workshop on Semantic
Evaluation (SemEval-2016), pages 1202–1206.
Jeffrey Flanigan, Sam Thomson, Jaime Carbonell,
Chris Dyer, and Noah A. Smith. 2014. A
discriminative graph-based parser for the ab-
stract meaning representation. In Proceedings
of the 52nd Annual Meeting of the Associ-
ation for Computational Linguistics (ACL-14),
pages 1426–1436.
Jonas Groschwitz, Matthias Lindemann, Meaghan
Fowlie, Mark Johnson, and Alexander Koller.
2018. AMR dependency parsing with a typed
semantic algebra. In Proceedings of the 56th
Annual Meeting of the Association for Computa-
tional Linguistics (ACL-18), pages 1831–1841.
Zhijiang Guo and Wei Lu. 2018. Better transition-
based AMR parsing with a refined search space.
In Proceedings of the 56th Annual Meeting of
the Association for Computational Linguistics
(ACL-18), pages 1712–1722.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. Neural Computation,
9(8):1735–1780.
Pierre
Isabelle, Colin Cherry,
and George
Foster. 2017. A challenge set approach to
evaluating machine translation. In Conference
on Empirical Methods in Natural Language
Processing (EMNLP-17), pages 2486–2496.
Bevan Jones, Jacob Andreas, Daniel Bauer,
Karl Moritz Hermann, and Kevin Knight.
2012. Semantics-based machine translation
with hyperedge replacement grammars.
In
Proceedings of the International Conference
on Computational Linguistics (COLING-12),
pages 1359–1376.
Michael Denkowski and Alon Lavie. 2014. Meteor
universal: Language specific translation evalu-
ation for any target language. In Proceedings
Diederik Kingma and Jimmy Ba. 2014. Adam:
A method for stochastic optimization. arXiv
preprint arXiv:1412.6980.
29
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Thomas N. Kipf and Max Welling. 2017. Semi-
supervised classification with graph convolu-
tional networks. In International Conference
on Learning Representations (ICLR).
Guillaume Klein, Yoon Kim, Yuntian Deng,
Jean Senellart, and Alexander M. Rush.
2017. OpenNMT: Open-Source Toolkit for
Neural Machine Translation. arXiv preprint
arXiv:1701.02810.
Philipp Koehn. 2004. Statistical significance tests
for machine translation evaluation. In Confer-
ence on Empirical Methods in Natural Lan-
guage Processing (EMNLP-04), pages 388–395.
Ioannis Konstas, Srinivasan Iyer, Mark Yatskar,
Yejin Choi, and Luke Zettlemoyer. 2017.
Neural AMR: Sequence-to-sequence models
for parsing and generation. In Proceedings
of the 55th Annual Meeting of the Associa-
tion for Computational Linguistics (ACL-17),
pages 146–157.
Junhui Li, Deyi Xiong, Zhaopeng Tu, Muhua
Zhu, Min Zhang, and Guodong Zhou. 2017.
Modeling source syntax for neural machine
translation. In Proceedings of the 55th Annual
Meeting of the Association for Computational
Linguistics (ACL-17), pages 688–697.
Xiang Li, Thien Huu Nguyen, Kai Cao, and
Ralph Grishman. 2015a.
Improving event
detection with abstract meaning representa-
tion. In Proceedings of the First Workshop
on Computing News Storylines, pages 11–15.
Yujia Li, Daniel Tarlow, Marc Brockschmidt,
and Richard Zemel. 2015b. Gated graph
sequence neural networks. arXiv preprint
arXiv:1511.05493.
Ding Liu and Daniel Gildea. 2010. Semantic role
features for machine translation. In Proceed-
ings of
the 23rd International Conference
on Computational Linguistics (COLING-10),
pages 716–724.
Chunchuan Lyu and Ivan Titov. 2018. AMR
parsing as graph prediction with latent
alignment. In Proceedings of the 56th Annual
Meeting of the Association for Computational
Linguistics (ACL-18), pages 397–407.
Christopher D. Manning, Mihai Surdeanu, John
Bauer, Jenny Finkel, Steven J. Bethard, and
David McClosky. 2014. The Stanford CoreNLP
natural language processing toolkit. In Asso-
ciation for Computational Linguistics (ACL)
System Demonstrations, pages 55–60.
Diego Marcheggiani, Joost Bastings, and Ivan
Titov. 2018. Exploiting semantics in neural
machine translation with graph convolutional
networks. In Proceedings of the 2018 Meeting
of the North American Chapter of the Associa-
tion for Computational Linguistics (NAACL-
18), pages 486–492.
Arindam Mitra and Chitta Baral. 2015. Loca-
tioning a question answering challenge by
combining statistical methods with inductive
rule learning and reasoning. In Proceedings
of the National Conference on Artificial Intel-
ligence (AAAI-16).
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu. 2002. BLEU: A method for
automatic evaluation of machine translation.
In Proceedings of the 40th Annual Meeting of
the Association for Computational Linguistics
(ACL-02), pages 311–318.
Xiaochang Peng, Linfeng Song, and Daniel
Gildea. 2015. A synchronous hyperedge re-
placement grammar based approach for AMR
parsing. In Proceedings of the Nineteenth Con-
ference on Computational Natural Language
Learning, pages 32–41.
Xiaochang Peng, Linfeng Song, Daniel Gildea,
and Giorgio Satta. 2018. Sequence-to-sequence
models for cache transition systems. In Pro-
ceedings of the 56th Annual Meeting of the
Association for Computational Linguistics
(ACL-18), pages 1842–1852.
Michael Pust, Ulf Hermjakob, Kevin Knight,
Daniel Marcu, and Jonathan May. 2015. Pars-
ing english into abstract meaning represen-
tation using syntax-based machine translation.
in
In Conference on Empirical Methods
Natural Language Processing (EMNLP-15),
pages 1143–1154.
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of
rare words with subword units. In Proceedings
30
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
of the 54th Annual Meeting of the Associa-
tion for Computational Linguistics (ACL-16),
pages 1715–1725.
2017. Attention is all you need. In Advances
in Neural Information Processing Systems, 30,
pages 5998–6008.
Matthew Snover, Bonnie Dorr, Richard Schwartz,
Linnea Micciulla, and John Makhoul. 2006.
A study of
rate with tar-
translation edit
geted human annotation. In Proceedings of
Association for Machine Translation in the
Americas, pages 223–231.
Linfeng Song, Yue Zhang, Zhiguo Wang, and
Daniel Gildea. 2018. A graph-to-sequence
model for AMR-to-text generation. In Pro-
ceedings of the 56th Annual Meeting of the
Association for Computational Linguistics
(ACL-18), pages 1842–1852.
Felix Stahlberg, Eva Hasler, Aurelien Waite,
and Bill Byrne. 2016. Syntactically guided
neural machine translation. In Proceedings of
the 54th Annual Meeting of the Association
for Computational Linguistics
(ACL-16),
pages 299–305.
Sho Takase,
Jun Suzuki, Naoaki Okazaki,
Tsutomu Hirao, and Masaaki Nagata. 2016.
Neural headline generation on abstract meaning
representation. In Conference on Empirical
Methods in Natural Language Processing
(EMNLP-16), pages 1054–1059.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N
Gomez, Łukasz Kaiser, and Illia Polosukhin.
Chuan Wang and Nianwen Xue. 2017. Getting
the most out of AMR parsing. In Conference
on Empirical Methods in Natural Language
Processing (EMNLP-17), pages 1257–1268.
Yuk Wah Wong and Raymond Mooney. 2006.
Learning for semantic parsing with statistical
machine translation. In Proceedings of the 2006
Meeting of the North American Chapter of
the Association for Computational Linguistics
(NAACL-06), pages 439–446.
Dekai Wu and Pascale Fung. 2009. Semantic
roles for SMT: A hybrid two-pass model.
In Proceedings of the 2009 Meeting of the
North American Chapter of the Association
for Computational Linguistics (NAACL-09),
pages 13–16.
Shuangzhi Wu, Ming Zhou, and Dongdong
Zhang. 2017. Improved neural machine trans-
In Proceedings
lation with source syntax.
of the Twenty-Sixth International Joint Con-
ference on Artificial Intelligence (IJCAI-17),
pages 4179–4185.
Yue Zhang, Qi Liu, and Linfeng Song. 2018.
Sentence-state LSTM for text representation.
In Proceedings of the 56th Annual Meeting of
the Association for Computational Linguistics
(ACL-18), pages 317–327.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
31
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
5
2
1
9
2
3
2
6
8
/
/
t
l
a
c
_
a
_
0
0
2
5
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3