Transacciones de la Asociación de Lingüística Computacional, 2 (2014) 207–218. Editor de acciones: Alejandro Clark.
Submitted 10/2013; Revised 3/2014; Publicado 4/2014. C
(cid:13)
2014 Asociación de Lingüística Computacional.
GroundedCompositionalSemanticsforFindingandDescribingImageswithSentencesRichardSocher,AndrejKarpathy,QuocV.Le*,ChristopherD.Manning,AndrewY.NgStanfordUniversity,ComputerScienceDepartment,*GoogleInc.richard@socher.org,karpathy@cs.stanford.edu,qvl@google.com,manning@stanford.edu,ang@cs.stanford.eduAbstractPreviousworkonRecursiveNeuralNetworks(RNNs)showsthatthesemodelscanproducecompositionalfeaturevectorsforaccuratelyrepresentingandclassifyingsentencesorim-ages.However,thesentencevectorsofprevi-ousmodelscannotaccuratelyrepresentvisu-allygroundedmeaning.WeintroducetheDT-RNNmodelwhichusesdependencytreestoembedsentencesintoavectorspaceinordertoretrieveimagesthataredescribedbythosesentences.UnlikepreviousRNN-basedmod-elswhichuseconstituencytrees,DT-RNNsnaturallyfocusontheactionandagentsinasentence.Theyarebetterabletoabstractfromthedetailsofwordorderandsyntacticexpression.DT-RNNsoutperformotherre-cursiveandrecurrentneuralnetworks,kernel-izedCCAandabag-of-wordsbaselineonthetasksoffindinganimagethatfitsasentencedescriptionandviceversa.Theyalsogivemoresimilarrepresentationstosentencesthatdescribethesameimage.1IntroductionSinglewordvectorspacesarewidelyused(TurneyandPantel,2010)andsuccessfulatclassifyingsin-glewordsandcapturingtheirmeaning(collobertandweston,2008;Huangetal.,2012;Mikolovetal.,2013).Sincewordsrarelyappearinisolation,thetaskoflearningcompositionalmeaningrepre-sentationsforlongerphraseshasrecentlyreceivedalotofattention(MitchellandLapata,2010;Socheretal.,2010;Socheretal.,2012;Grefenstetteetal.,2013).Similarmente,classifyingwholeimagesintoafixedsetofclassesalsoachievesveryhighperfor-mance(Leetal.,2012;Krizhevskyetal.,2012).Sin embargo,similartowords,objectsinimagesareof-tenseeninrelationshipswithotherobjectswhicharenotadequatelydescribedbyasinglelabel.Inthiswork,weintroduceamodel,illustratedinFig.1,whichlearnstomapsentencesandimagesintoacommonembeddingspaceinordertobeabletoretrieveonefromtheother.Weassumewordandimagerepresentationsarefirstlearnedintheirre-spectivesinglemodalitiesbutfinallymappedintoajointlylearnedmultimodalembeddingspace.OurmodelformappingsentencesintothisspaceisbasedonideasfromRecursiveNeuralNetworks(RNNs)(Pollack,1990;Costaetal.,2003;Socheretal.,2011b).Sin embargo,unlikeallpreviousRNNmodelswhicharebasedonconstituencytrees(CT-RNNs),ourmodelcomputescompositionalvectorrepresentationsinsidedependencytrees.Thecom-positionalvectorscomputedbythisnewdependencytreeRNN(DT-RNN)capturemoreofthemeaningofsentences,wherewedefinemeaningintermsofsimilaritytoa“visualrepresentation”ofthetextualdescription.DT-RNNinducedvectorrepresenta-tionsofsentencesaremorerobusttochangesinthesyntacticstructureorwordorderthanrelatedmod-elssuchasCT-RNNsorRecurrentNeuralNetworkssincetheynaturallyfocusonasentence’sactionanditsagents.WeevaluateandcompareDT-RNNinducedrep-resentationsontheirabilitytouseasentencesuchas“Amanwearingahelmetjumpsonhisbikenearabeach.”tofindimagesthatshowsuchascene.Thegoalistolearnsentencerepresentationsthatcapture
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
208
A man wearing a helmet jumps on his bike near a beach.Compositional Sentence VectorsTwo airplanes parked in an airport.A man jumping his downhill bike.Image Vector RepresentationA small child sits on a cement wall near white flower.Multi-Modal RepresentationsFigure1:TheDT-RNNlearnsvectorrepresentationsforsentencesbasedontheirdependencytrees.Welearntomaptheoutputsofconvolutionalneuralnetworksappliedtoimagesintothesamespaceandcanthencomparebothsentencesandimages.Thisallowsustoqueryimageswithasentenceandgivesentencedescriptionstoimages.thevisualscenedescribedandtofindappropriateimagesinthelearned,multi-modalsentence-imagespace.Conversely,whengivenaqueryimage,wewouldliketofindadescriptionthatgoesbeyondasinglelabelbyprovidingacorrectsentencedescrib-ingit,ataskthathasrecentlygarneredalotofat-tention(Farhadietal.,2010;Ordonezetal.,2011;Kuznetsovaetal.,2012).Weusethedatasetintro-ducedby(Rashtchianetal.,2010)whichconsistsof1000images,eachwith5descriptions.Onalltasks,ourmodeloutperformsbaselinesandrelatedmod-els.2RelatedWorkThepresentedmodelisconnectedtoseveralareasofNLPandvisionresearch,eachwithalargeamountofrelatedworktowhichwecanonlydosomejusticegivenspaceconstraints.SemanticVectorSpacesandTheirComposition-ality.Thedominantapproachinsemanticvec-torspacesusesdistributionalsimilaritiesofsinglewords.Often,co-occurrencestatisticsofawordanditscontextareusedtodescribeeachword(TurneyandPantel,2010;BaroniandLenci,2010),suchastf-idf.Mostofthecompositionalityalgorithmsandrelateddatasetscapturetwo-wordcompositions.Forinstance,(MitchellandLapata,2010)usetwo-wordphrasesandanalyzesimilaritiescomputedbyvectoraddition,multiplicationandothers.Compo-sitionalityisanactivefieldofresearchwithmanydifferentmodelsandrepresentationsbeingexplored(Grefenstetteetal.,2013),amongmanyothers.Wecomparetosupervisedcompositionalmodelsthatcanlearntask-specificvectorrepresentationssuchasconstituencytreerecursiveneuralnetworks(Socheretal.,2011b;Socheretal.,2011a),chainstructuredrecurrentneuralnetworksandotherbaselines.An-otheralternativewouldbetouseCCGtreesasabackboneforvectorcomposition(K.M.Hermann,2013).MultimodalEmbeddings.Multimodalembed-dingmethodsprojectdatafrommultiplesourcessuchassoundandvideo(Ngiametal.,2011)orim-agesandtext.Socheretal.(SocherandFei-Fei,2010)projectwordsandimageregionsintoacom-monspaceusingkernelizedcanonicalcorrelationanalysistoobtainstateoftheartperformanceinan-notationandsegmentation.Similartoourwork,theyuseunsupervisedlargetextcorporatolearnseman-ticwordrepresentations.AmongotherrecentworkisthatbySrivastavaandSalakhutdinov(2012)whodevelopedmultimodalDeepBoltzmannMachines.Similartotheirwork,weusetechniquesfromthebroadfieldofdeeplearningtorepresentimagesandwords.Recently,singlewordvectorembeddingshavebeenusedforzeroshotlearning(Socheretal.,2013c).Mappingimagestowordvectorsenabledtheirsystemtoclassifyimagesasdepictingobjectssuchas”cat”withoutseeinganyexamplesofthisclass.RelatedworkhasalsobeenpresentedatNIPS(Socheretal.,2013b;Fromeetal.,2013).Thisworkmoveszero-shotlearningbeyondsinglecategoriesperimageandextendsittounseenphrasesandfulllengthsentences,makinguseofsimilarideasofse-manticspacesgroundedinvisualknowledge.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
209
DetailedImageAnnotation.Interactionsbe-tweenimagesandtextsisagrowingresearchfield.Earlyworkinthisareaincludesgeneratingsinglewordsorfixedphrasesfromimages(Duyguluetal.,2002;Barnardetal.,2003)orusingcontextualin-formationtoimproverecognition(GuptaandDavis,2008;Torralbaetal.,2010).Apartfromalargebodyofworkonsingleobjectimageclassification(Leetal.,2012),thereisalsoworkonattributeclassificationandothermid-levelelements(Kumaretal.,2009),someofwhichwehopetocapturewithourapproachaswell.Ourworkiscloseinspiritwithrecentworkinde-scribingimageswithmoredetailed,longertextualdescriptions.Inparticular,Yaoetal.(2010)describeimagesusinghierarchicalknowledgeandhumansintheloop.Incontrast,ourworkdoesnotrequirehu-maninteractions.Farhadietal.(2010)andKulkarnietal.(2011),por otro lado,useamoreautomaticmethodtoparseimages.Forinstance,theformerap-proachusesasingletripleofobjectsestimatedforanimagetoretrievesentencesfromacollectionwrittentodescribesimilarimages.Itformsrepresentationstodescribe1object,1acción,and1scene.Kulkarnietal.(2011)extendstheirmethodtodescribeanim-agewithmultipleobjects.Noneoftheseapproacheshaveusedacompositionalsentencevectorrepre-sentationandtheyrequirespecificlanguagegener-ationtechniquesandsophisticatedinferencemeth-ods.Sinceourmodelisbasedonneuralnetworksin-ferenceisfastandsimple.Kuznetsovaetal.(2012)useaverylargeparallelcorpustoconnectimagesandsentences.FengandLapata(2013)usealargedatasetofcaptionedimagesandexperimentswithbothextractive(buscar)andabstractive(generación)models.MostrelatedistheveryrecentworkofHodoshetal.(2013).Theytooevaluateusingarankingmea-sure.Inourexperiments,wecomparetokernelizedCanonicalCorrelationAnalysiswhichisthemaintechniqueintheirexperiments.3Dependency-TreeRecursiveNeuralNetworksInthissectionwefirstfocusontheDT-RNNmodelthatcomputescompositionalvectorrepresentationsforphrasesandsentencesofvariablelengthandsyn-tactictype.Insection5theresultingvectorswillthenbecomemultimodalfeaturesbymappingim-agesthatshowwhatthesentencedescribestothesamespaceandlearningboththeimageandsen-tencemappingjointly.Themostcommonwayofbuildingrepresenta-tionsforlongerphrasesfromsinglewordvectorsistosimplylinearlyaveragethewordvectors.Whilethisbag-of-wordsapproachcanyieldreasonableperformanceinsometasks,itgivesallthewordsthesameweightandcannotdistinguishimportantdif-ferencesinsimplevisualdescriptionssuchasThebikecrashedintothestandingcar.vs.Thecarcrashedintothestandingbike..RNNmodels(Pollack,1990;GollerandK¨uchler,1996;Socheretal.,2011b;Socheretal.,2011a)pro-videdanovelwayofcombiningwordvectorsforlongerphrasesthatmovedbeyondsimpleaverag-ing.TheycombinevectorswithanRNNinbinaryconstituencytreeswhichhavepotentiallymanyhid-denlayers.Whiletheinducedvectorrepresentationsworkverywellonmanytasks,theyalsoinevitablycapturealotofsyntacticstructureofthesentence.However,thetaskoffindingimagesfromsentencedescriptionsrequiresustobemoreinvarianttosyn-tacticdifferences.Onesuchexampleareactive-passiveconstructionswhichcancollapsewordssuchas“by”insomeformalisms(deMarneffeetal.,2006),relyinginsteadonthesemanticrelationshipof“agent”.Forinstance,Themotherhuggedherchild.andThechildwashuggedbyitsmother.shouldmaptoroughlythesamevisualspace.Cur-rentRecursiveandRecurrentNeuralNetworksdonotexhibitthisbehaviorandevenbagofwordsrep-resentationswouldbeinfluencedbythewordswasandby.Themodelwedescribebelowfocusesmoreonrecognizingactionsandagentsandhasthepo-tentialtolearnrepresentationsthatareinvarianttoactive-passivedifferences.3.1DT-RNNInputs:WordVectorsandDependencyTreesInorderfortheDT-RNNtocomputeavectorrepre-sentationforanorderedlistofmwords(aphraseorsentence),wemapthesinglewordstoavectorspaceandthenparsethesentence.First,wemapeachwordtoad-dimensionalvec-tor.Weinitializethesewordvectorswiththeun-
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
210
AmanwearingahelmetjumpsonhisbikenearabeachdetnsubjpartmoddetdobjrootprepposspobjprepdetpobjFigure2:Exampleofafulldependencytreeforalongersentence.TheDT-RNNwillcomputevectorrepresentationsateverywordthatrepresentsthatwordandanarbitrarynumberofchildnodes.Thefinalrepresentationiscomputedattherootnode,hereattheverbjumps.Notethatmoreimportantactivityandobjectwordsarehigherupinthistreestructure.supervisedmodelofHuangetal.(2012)whichcanlearnsinglewordvectorrepresentationsfrombothlocalandglobalcontexts.Theideaistoconstructaneuralnetworkthatoutputshighscoresforwindowsanddocumentsthatoccurinalargeunlabeledcorpusandlowscoresforwindow-documentpairswhereonewordisreplacedbyarandomword.WhensuchanetworkisoptimizedviagradientdescentthederivativesbackpropagateintoawordembeddingmatrixAwhichstoreswordvectorsascolumns.Inordertopredictcorrectscoresthevectorsinthema-trixcaptureco-occurrencestatistics.Weused=50inallourexperiments.TheembeddingmatrixXisthenusedbyfindingthecolumnindexiofeachword:[w]=iandretrievingthecorrespondingcol-umnxwfromX.Henceforth,werepresentaninputsentencesasanorderedlistof(palabra,vector)pares:s=((w1,xw1),…,(wm,xwm)).Próximo,thesequenceofwords(w1,…,wm)isparsedbythedependencyparserofdeMarneffeetal.(2006).Fig.2showsanexample.Wecanrepresentadependencytreedofasentencesasanorderedlistof(niño,parent)indices:d(s)={(i,j)},whereeverychildwordinthesequencei=1,…,mispresentandhasanywordj∈{1,…,metro}∪{0}asitsparent.Therootwordhasasitsparent0andwenoticethatthesamewordcanbeaparentbetweenzeroandmnumberoftimes.Withoutlossofgenerality,weassumethatthesein-dicesformatreestructure.Tosummarize,theinputtotheDT-RNNforeachsentenceisthepair(s,d):thewordsandtheirvectorsandthedependencytree.3.2ForwardPropagationinDT-RNNsGiventhesetwoinputs,wenowillustratehowtheDT-RNNcomputesparentvectors.Wewillusethefollowingsentenceasarunningexample:Students1ride2bikes3at4night5.Fig.3showsitstreeandcomputedvectorrepresentations.Thedepen-Students bikes nightride at x1x2x3x4x5h1h2h3h4h5Figure3:ExampleofaDT-RNNtreestructureforcom-putingasentencerepresentationinabottomupfashion.dencytreeforthissentencecanbesummarizedbythefollowingsetof(niño,parent)bordes:d={(1,2),(2,0),(3,2),(4,2),(5,4)}.TheDT-RNNmodelwillcomputeparentvectorsateachwordthatincludeallthedependent(chil-dren)nodesinabottomupfashionusingacom-positionalityfunctiongθwhichisparameterizedbyallthemodelparametersθ.Tothisend,thealgo-rithmsearchesfornodesinatreethathaveeither(i)nochildrenor(ii)whosechildrenhavealreadybeencomputedandthencomputesthecorrespond-ingvector.Inourexample,thewordsx1,x3,x5areleafnodesandhence,wecancomputetheircorrespond-inghiddennodesvia:hc=gθ(xc)=f(Wvxc)forc=1,3,5,(1)wherewecomputethehiddenvectoratpositioncviaourgeneralcompositionfunctiongθ.Inthecaseofleafnodes,thiscompositionfunctionbecomessimplyalinearlayer,parameterizedbyWv∈Rn×d,followedbyanonlinearity.Wecross-validateoverusingnononlinearity(f=id),tanh,sigmoidorrectifiedlinearunits(f=max(0,X),butgenerallyfindtanhtoperformbest.Thefinalsentencerepresentationwewanttocom-puteisath2,however,sincewestilldonothaveh4,
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
211
wecomputethatonenext:h4=gθ(x4,h5)=f(Wvx4+Wr1h5),(2)whereweusethesameWvasbeforetomapthewordvectorintohiddenspacebutwenowalsohavealinearlayerthattakesasinputh5,theonlychildofthefourthnode.ThematrixWr1∈Rn×nisusedbecausenode5isthefirstchildnodeontherightsideofnode4.Generally,wehavemultiplematri-cesforcomposingwithhiddenchildvectorsfromtherightandleftsides:Wr·=(Wr1,…,Wrkr)andWl·=(Wl1,…,Wlkl).Thenumberofneededma-tricesisdeterminedbythedatabysimplyfindingthemaximumnumbersofleftklandrightkrchil-drenanynodehas.Ifattesttimeachildappearedatanevenlargedistance(thisdoesnothappeninourtestset),thecorrespondingmatrixwouldbetheidentitymatrix.Nowthatallchildrenofh2havetheirhiddenvec-tors,wecancomputethefinalsentencerepresenta-tionvia:h2=gθ(x2,h1,h3,h4)=(3)F(Wvx2+Wl1h1+Wr1h3+Wr2h4).Noticethatthechildrenaremultipliedbymatricesthatdependontheirlocationrelativetothecurrentnode.Anothermodificationthatimprovesthemeanrankbyapproximately6inimagesearchonthedevsetistoweightnodesbythenumberofwordsunder-neaththemandnormalizebythesumofwordsunderallchildren.Thisencouragestheintuitivedesidera-tumthatnodesdescribinglongerphrasesaremoreimportant.Let‘(i)bethenumberofleafnodes(palabras)undernodeiandC(i,y)bethesetofchildnodesofnodeiindependencytreey.Thefinalcom-positionfunctionforanodevectorhibecomes:hi=f1‘(i)Wvxi+Xj∈C(i)'(j)Wpos(i,j)hj,(4)wherebydefinition‘(i)=1+Pj∈C(i)'(j)andpos(i,j)istherelativepositionofchildjwithre-specttonodei,e.g.l1orr2inEq.3.3.3SemanticDependencyTreeRNNsAnalternativeistoconditiontheweightmatricesonthesemanticrelationsgivenbythedependencyparser.WeusethecollapsedtreeformalismoftheStanforddependencyparser(deMarneffeetal.,2006).Withsuchasemanticuntyingoftheweights,theDT-RNNmakesbetteruseofthedependencyformalismandcouldgiveactive-passivereversalssimilarsemanticvectorrepresentation.TheequationforthissemanticDT-RNN(SDT-RNN)isthesameastheoneaboveexceptthatthematricesWpos(i,j)arereplacedwithmatricesbasedonthedependencyrelationship.Thereareatotalof141uniquesuchrelationshipsinthedataset.However,mostareveryrare.Forexamplesofsemanticrelationships,seeFig.2andthemodelanalysissection6.7.Thisforwardpropagationcanbeusedforcom-putingcompositionalvectorsandinSec.5wewillexplaintheobjectivefunctioninwhichthesearetrained.3.4ComparisontoPreviousRNNModelsTheDT-RNNhasseveralimportantdifferencestopreviousRNNmodelsofSocheretal.(2011a)y(Socheretal.,2011b;Socheretal.,2011c).TheseconstituencytreeRNNs(CT-RNNs)usethefollow-ingcompositionfunctiontocomputeahiddenpar-entvectorhfromexactlytwochildvectors(c1,c2)inabinarytree:h=f(cid:18)W.(cid:20)c1c2(cid:21)(cid:19),whereW∈Rd×2disthemainparametertolearn.ThiscanberewrittentoshowthesimilaritytotheDT-RNNash=f(Wl1c1+Wr1c2).Sin embargo,thereareseveralimportantdifferences.NotefirstthatinpreviousRNNmodelsthepar-entvectorswereofthesamedimensionalitytoberecursivelycompatibleandbeusedasinputtothenextcomposition.Incontrast,ournewmodelfirstmapssinglewordsintoahiddenspaceandthenpar-entnodesarecomposedfromthesehiddenvectors.Thisallowsahighercapacityrepresentationwhichisespeciallyhelpfulfornodesthathavemanychil-dren.Secondly,theDT-RNNallowsforn-arynodesinthetree.ThisisanimprovementthatispossibleevenforconstituencytreeCT-RNNsbutithasnotbeenexploredinpreviousmodels.Third,duetocomputingparentnodesincon-stituencytrees,previousmodelshadtheproblemthatwordsthataremergedlastinthetreehavealargerweightorimportanceinthefinalsentencerep-
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
212
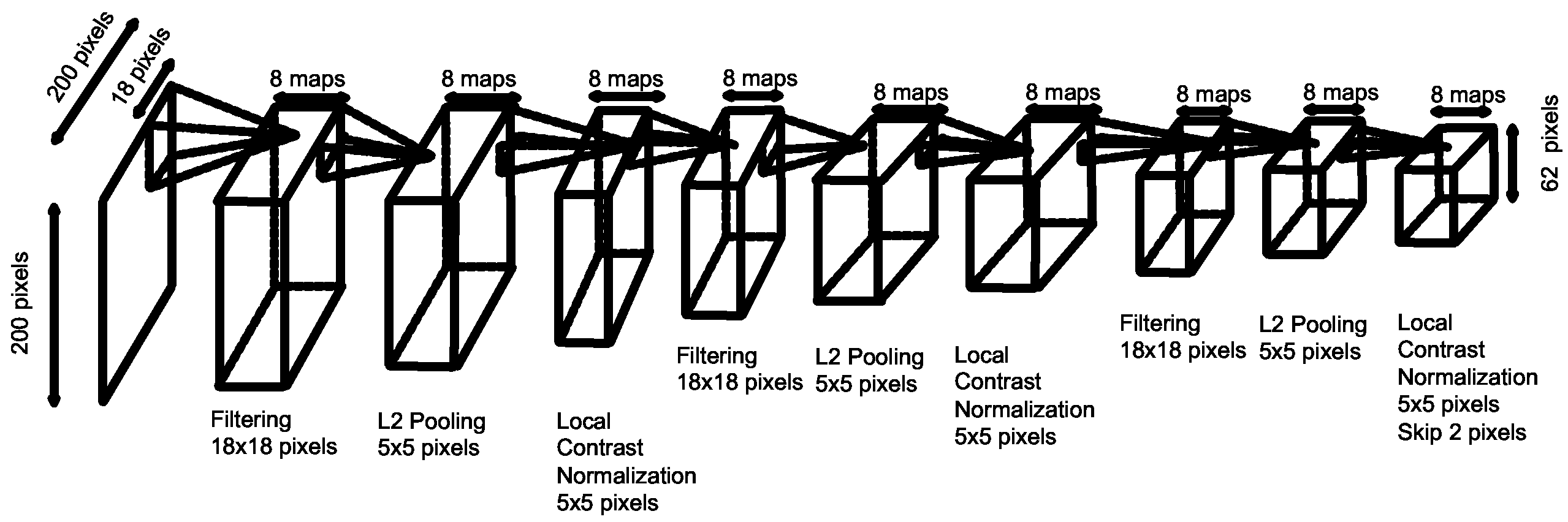
Figure4:Thearchitectureofthevisualmodel.Thismodelhas3sequencesoffiltering,poolingandlocalcontrastnormalizationlayers.Thelearnableparametersarethefilteringlayer.Thefiltersarenotshared,i.e.,thenetworkisnonconvolutional.resentation.Thiscanbeproblematicsincetheseareoftensimplenon-contentwords,suchasaleading‘But,’.Whilesuchsinglewordscanbeimportantfortaskssuchassentimentanalysis,wearguethatfordescribingvisualscenestheDT-RNNcapturesthemoreimportanteffects:Thedependencytreestruc-turespushthecentralcontentwordssuchasthemainactionorverbanditssubjectandobjecttobemergedlastandhence,byconstruction,thefinalsentencerepresentationismorerobusttolessimportantad-jectivalmodifiers,wordorderchanges,etc.Fourth,weallowsomeuntyingofweightsde-pendingoneitherhowfarawayaconstituentisfromthecurrentwordorwhatitssemanticrelationshipis.Nowthatwecancomputecompositionalvectorrepresentationsforsentences,thenextsectionde-scribeshowwerepresentimages.4LearningImageRepresentationswithNeuralNetworksTheimagefeaturesthatweuseinourexperimentsareextractedfromadeepneuralnetwork,replicatedfromtheonedescribedin(Leetal.,2012).Thenet-workwastrainedusingbothunlabeleddata(randomwebimages)andlabeleddatatoclassify22,000cat-egoriesinImageNet(Dengetal.,2009).Wethenusedthefeaturesatthelastlayer,beforetheclassi-fier,asthefeaturerepresentationinourexperiments.Thedimensionofthefeaturevectorofthelastlayeris4,096.Thedetailsofthemodelanditstrainingproceduresareasfollows.ThearchitectureofthenetworkcanbeseeninFigure4.Thenetworktakes200x200pixelimagesasinputsandhas9layers.Thelayersconsistofthreesequencesoffiltering,poolingandlocalcon-trastnormalization(Jarrettetal.,2009).ThepoolingfunctionisL2poolingofthepreviouslayer(takingthesquareofthefilteringunits,summingthemupinasmallareaintheimage,andtakingthesquare-root).Thelocalcontrastnormalizationtakesinputsinasmallareaofthelowerlayer,subtractsthemeananddividesbythestandarddeviation.Thenetworkwasfirsttrainedusinganunsuper-visedobjective:tryingtoreconstructtheinputwhilekeepingtheneuronssparse.Inthisphase,thenet-workwastrainedon20millionimagesrandomlysampledfromtheweb.Weresizedagivenimagesothatitsshortdimensionhas200pixels.Wethencroppedafixedsize200x200pixelimagerightatthecenteroftheresizedimage.Thismeanswemaydis-cardafractionofthelongdimensionoftheimage.Afterunsupervisedtraining,weusedIma-geNet(Dengetal.,2009)toadjustthefeaturesintheentirenetwork.TheImageNetdatasethas22,000categoriesand14millionimages.Thenumberofimagesineachcategoryisequalacrosscategories.The22,000categoriesareextractedfromWordNet.Tospeedupthesupervisedtrainingofthisnet-work,wemadeasimplemodificationtothealgo-rithmdescribedinLeetal.(2012):addinga“bottle-neck”layerinbetweenthelastlayerandtheclassi-fier.toreducethenumberofconnections.Weaddedone“bottleneck”layerwhichhas4,096unitsinbe-tweenthelastlayerofthenetworkandthesoftmaxlayer.Thisnewly-addedlayerisfullyconnectedtothepreviouslayerandhasalinearactivationfunc-tion.Thetotalnumberofconnectionsofthisnet-workisapproximately1.36billion.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
213
Thenetworkwastrainedagainusingthesuper-visedobjectiveofclassifyingthe22,000classesinImageNet.Mostfeaturesinthenetworksarelocal,whichallowsmodelparallelism.DataparallelismbyasynchronousSGDwasalsoemployedasinLeetal.(2012).Theentiretraining,bothunsupervisedandsupervised,took8daysonalargeclusterofma-chines.Thisnetworkachieves18.3%precision@1onthefullImageNetdataset(ReleaseFall2011).Wewillusethefeaturesatthebottlenecklayerasthefeaturevectorzofanimage.Eachscaledandcroppedimageispresentedtoournetwork.Thenet-workthenperformsafeedforwardcomputationtocomputethevaluesofthebottlenecklayer.Thismeansthateveryimageisrepresentedbyafixedlengthvectorof4,096dimensions.Notethatduringtraining,noalignedsentence-imagedatawasusedandtheImageNetclassesdonotfullyintersectwiththewordsusedinourdataset.5MultimodalMappingsTheprevioustwosectionsdescribedhowwecanmapsentencesintoad=50-dimensionalspaceandhowtoextracthighqualityimagefeaturevectorsof4096dimensions.Wenowdefineourfinalmulti-modalobjectivefunctionforlearningjointimage-sentencerepresentationswiththesemodels.OurtrainingsetconsistsofNimagesandtheirfeaturevectorsziandeachimagehas5sentencedescrip-tionssi1,…,si5forwhichweusetheDT-RNNtocomputevectorrepresentations.SeeFig.5forex-amplesfromthedataset.Fortraining,weuseamax-marginobjectivefunctionwhichintuitivelytrainspairsofcorrectimageandsentencevectorstohavehighinnerproductsandincorrectpairstohavelowinnerproducts.Letvi=WIzibethemappedimagevectorandyij=DTRNNθ(sij)thecomposedsen-tencevector.WedefineStobethesetofallsentenceindicesandS(i)thesetofsentenceindicescorre-spondingtoimagei.Similarly,Iisthesetofallim-ageindicesandI(j)istheimageindexofsentencej.ThesetPisthesetofallcorrectimage-sentencetrainingpairs(i,j).Therankingcostfunctiontominimizeisthen:j(Wisconsin,i)=X(i,j)∈PXc∈S\S(i)máximo(0,∆−vTiyj+vTiyc)+X(i,j)∈PXc∈I\I(j)máximo(0,∆−vTiyj+vTcyj),(5)whereθarethelanguagecompositionmatrices,andbothsecondsumsareoverothersentencescom-ingfromdifferentimagesandviceversa.Thehyper-parameter∆isthemargin.Themarginisfoundviacrossvalidationonthedevsetandusuallyaround1.Thefinalobjectivealsoincludestheregulariza-tiontermλ/left(kθk22+kWIkF).Boththevisualmodelandthewordvectorlearningrequireaverylargeamountoftrainingdataandbothhaveahugenumberofparameters.Hence,topreventoverfitting,weassumetheirweightsarefixedandonlytraintheDT-RNNparametersWI.Iflargertrainingcorporabecomeavailableinthefuture,trainingbothjointlybecomesfeasibleandwouldpresentaverypromis-ingdirection.WeuseamodifiedversionofAda-Grad(Duchietal.,2011)foroptimizationofbothWIandtheDT-RNNaswellastheotherbaselines(exceptkCCA).Adagradhasachievedgoodperfor-mancepreviouslyinneuralnetworksmodels(Deanetal.,2012;Socheretal.,2013a).Wemodifyitbyresettingallsquaredgradientsumsto1every5epochs.Withbothimagesandsentencesinthesamemultimodalspace,wecaneasilyquerythemodelforsimilarimagesorsentencesbyfindingthenearestneighborsintermsofnegativeinnerproducts.AnalternativeobjectivefunctionisbasedonthesquaredlossJ(Wisconsin,i)=P(i,j)∈Pkvi−yjk22.ThisrequiresanalternatingminimizationschemethatfirsttrainsonlyWI,thenfixesWIandtrainstheDT-RNNweightsθandthenrepeatsthisseveraltimes.Wefindthattheperformancewiththisob-jectivefunction(pairedwithfindingsimilarimagesusingEuclideandistances)isworseforallmodelsthanthemarginlossofEq.5.InadditionkCCAalsoperformsmuchbetterusinginnerproductsinthemultimodalspace.6ExperimentsWeusethedatasetofRashtchianetal.(2010)whichconsistsof1000images,eachwith5sentences.SeeFig.5forexamples.WeevaluateandcomparetheDT-RNNinthreedifferentexperiments.First,weanalyzehowwellthesentencevectorscapturesimilarityinvisualmeaning.ThenweanalyzeImageSearchwithQuerySentences:toqueryeachmodelwithasen-tenceinordertofindanimageshowingthatsen-
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
214
1. A woman and her dog watch the cameraman in their living with wooden floors.2. A woman sitting on the couch while a black faced dog runs across the floor.3. A woman wearing a backpack sits on a couch while a small dog runs on the hardwood floor next to her.4. A women sitting on a sofa while a small Jack Russell walks towards the camera.5. White and black small dog walks toward the camera while woman sits on couch, desk and computer seen in the background as well as a pillow, teddy bear and moggie toy on the wood floor.1. A man in a cowboy hat check approaches a small red sports car.2. The back and left side of a red Ferrari and two men admiring it.3. The sporty car is admired by passer by.4. Two men next to a red sports car in a parking lot.5. Two men stand beside a red sports car.Figure5:Examplesfromthedatasetofimagesandtheirsentencedescriptions(Rashtchianetal.,2010).Sentencelengthvariesgreatlyanddifferentobjectscanbementionedfirst.Hence,modelshavetobeinvarianttowordordering.tence’svisual‘meaning.’ThelastexperimentDe-scribingImagesbyFindingSuitableSentencesdoesthereversesearchwherewequerythemodelwithanimageandtrytofindtheclosesttextualdescriptionintheembeddingspace.Inourcomparisontoothermethodswefocusonthosemodelsthatcanalsocomputefixed,continu-ousvectorsforsentences.Inparticular,wecomparetotheRNNmodelonconstituencytreesofSocheretal.(2011a),astandardrecurrentneuralnetwork;asimplebag-of-wordsbaselinewhichaveragesthewords.AllmodelsusethewordvectorsprovidedbyHuangetal.(2012)anddonotupdatethemasdis-cussedabove.Modelsaretrainedwiththeircorre-spondinggradientsandbackpropagationtechniques.Astandardrecurrentmodelisusedwherethehiddenvectoratwordindextiscomputedfromthehiddenvectorattheprevioustimestepandthecurrentwordvector:ht=f(Whht−1+Wxxt).Duringtraining,wetakethelasthiddenvectorofthesentencechainandpropagatetheerrorintothat.Itisalsothisvectorthatisusedtorepresentthesentence.Otherpossiblecomparisonsaretotheverydiffer-entmodelsmentionedintherelatedworksection.Thesemodelsusealotmoretask-specificengineer-ing,suchasrunningobjectdetectorswithboundingboxes,attributeclassifiers,sceneclassifiers,CRFsforcomposingthesentences,etc.Anotherlineofworkuseslargesentence-imagealignedresources(Kuznetsovaetal.,2012),whereaswefocusoneas-ilyobtainabletrainingdataofeachmodalitysepa-ratelyandarathersmallmultimodalcorpus.Inourexperimentswesplitthedatainto800train-ing,100developmentand100testimages.Sincethereare5sentencesdescribingeachimage,wehave4000trainingsentencesand500testingsen-tences.Thedatasethas3020uniquewords,halfofwhichonlyappearonce.Hence,theunsupervised,pre-trainedsemanticwordvectorrepresentationsarecrucial.Wordvectorsarenotfinetunedduringtrain-ing.Hence,themainparametersaretheDT-RNN’sWl·,Wr·orthesemanticmatricesofwhichthereare141andtheimagemappingWI.ForbothDT-RNNstheweightmatricesareinitializedtoblockidentitymatricesplusGaussiannoise.Wordvectorsandhid-denvectorsaresetolength50.Usingthedevelop-mentsplit,wefoundλ=0.08andthelearningrateofAdaGradto0.0001.Thebestmodelusesamar-ginof∆=3.InspiredbySocherandFei-Fei(2010)andHo-doshetal.(2013)wealsocomparetokernelizedCanonicalCorrelationAnalysis(kCCA).Weusetheaverageofwordvectorsfordescribingsentencesandthesamepowerfulimagevectorsasbefore.WeusethecodeofSocherandFei-Fei(2010).Tech-nically,onecouldcombinetherecentlyintroduceddeepCCAAndrewetal.(2013)andtrainthere-cursiveneuralnetworkarchitectureswiththeCCAobjective.Weleavethistofuturework.Withlin-earkernels,kCCAdoeswellforimagesearchbutisworseforsentenceselfsimilarityanddescribingimageswithsentencesclose-byinembeddingspace.AllothermodelsaretrainedbyreplacingtheDT-RNNfunctioninEq.5.6.1SimilarityofSentencesDescribingtheSameImageInthisexperiment,wefirstmapall500sentencesfromthetestsetintothemulti-modalspace.Thenforeachsentence,wefindthenearestneighborsen-
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
215
SentencesSimilarityforImageModelMeanRankRandom101.1BoW11.8CT-RNN15.8RecurrentNN18.5kCCA10.7DT-RNN11.1SDT-RNN10.5ImageSearchModelMeanRankRandom52.1BoW14.6CT-RNN16.1RecurrentNN19.2kCCA15.9DT-RNN13.6SDT-RNN12.5DescribingImagesModelMeanRankRandom92.1BoW21.1CT-RNN23.9RecurrentNN27.1kCCA18.0DT-RNN19.2SDT-RNN16.9Table1:Left:Comparisonofmethodsforsentencesimilarityjudgments.Lowernumbersarebettersincetheyindicatethatsentencesdescribingthesameimagerankmorehighly(arecloser).Theranksareoutofthe500sentencesinthetestset.Center:Comparisonofmethodsforimagesearchwithquerysentences.Shownistheaveragerankofthesinglecorrectimagethatisbeingdescribed.Right:Averagerankofacorrectsentencedescriptionforaqueryimage.tencesintermsofinnerproducts.Wethensorttheseneighborsandrecordtherankorpositionofthenearestsentencethatdescribesthesameim-age.Ifalltheimageswereveryuniqueandthevi-sualdescriptionsclose-paraphrasesandconsistent,wewouldexpectaverylowrank.However,usuallyahandfulofimagesarequitesimilar(por ejemplo,therearevariousimagesofairplanesflying,parking,taxiingorwaitingontherunway)andsentencede-scriptionscanvarygreatlyindetailandspecificityforthesameimage.Table1(izquierda)showstheresults.Wecanseethataveragingthehighqualitywordvectorsalreadycap-turesalotofsimilarity.Thechainstructureofastandardrecurrentneuralnetperformsworstsinceitsrepresentationisdominatedbythelastwordsinthesequencewhichmaynotbeasimportantasear-lierwords.6.2ImageSearchwithQuerySentencesThisexperimentevaluateshowwellwecanfindim-agesthatdisplaythevisualmeaningofagivensen-tence.Wefirstmapaquerysentenceintothevectorspaceandthenfindimagesinthesamespaceusingsimpleinnerproducts.AsshowninTable1(center),thenewDT-RNNoutperformsallothermodels.6.3DescribingImagesbyFindingSuitableSentencesLastly,werepeattheaboveexperimentsbutwithrolesreversed.Foranimage,wesearchforsuitabletextualdescriptionsagainsimplybyfindingclose-bysentencevectorsinthemulti-modalembeddingspace.Table1(bien)showsthattheDT-RNNagainoutperformsrelatedmodels.Fig.2assignedtoim-ImageSearchModelmRankBoW24.7CT-RNN22.2RecurrentNN28.4kCCA13.7DT-RNN13.3SDT-RNN15.8DescribingImagesModelmRankBoW30.7CT-RNN29.4RecurrentNN31.4kCCA38.0DT-RNN26.8SDT-RNN37.5Table2:ResultsofmultimodalrankingwhenmodelsaretrainedwithasquarederrorlossandusingEuclideandis-tanceinthemultimodalspace.Betterperformanceisreachedforallmodelswhentrainedinamax-marginlossandusinginnerproductsasintheprevioustable.ages.Theaveragerankingof25.3foracorrectsen-tencedescriptionisoutof500possiblesentences.Arandomassignmentwouldgiveanaveragerankingof100.6.4Analysis:SquaredErrorLossvs.MarginLossWeanalyzetheinfluenceofthemultimodallossfunctionontheperformance.Inaddition,wecom-pareusingEuclideandistancesinsteadofinnerprod-ucts.Table2showsthatperformanceisworseforallmodelsinthissetting.6.5Analysis:RecallatnvsMeanRankHodoshetal.(2013)andotherrelatedworkusere-callatnasanevaluationmeasure.Recallatncap-tureshowoftenoneofthetopnclosestvectorswereacorrectimageorsentenceandgivesagoodintu-itionofhowamodelwouldperforminarankingtaskthatpresentsnsuchresultstoauser.Below,wecomparethreecommonlyusedandhighperformingmodels:bagofwords,kCCAandourSDT-RNNon
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
216
A gray convertible sports car is parked in front of the trees.A close-up view of the headlights of a blue old-fashioned car.Black shiny sports car parked on concrete driveway.Five cows grazing on a patch of grass between two roadways.A jockey rides a brown and white horse in a dirt corral.A young woman is riding a Bay hose in a dirt riding-ring.A white bird pushes a miniature teal shopping cart.A person rides a brown horse.A motocross bike with rider flying through the air.White propeller plane parked in middle of grassy field.The white jet with its landing gear down flies in the blue sky.An elderly woman catches a ride on the back of the bicycle.A green steam train running down the tracks.Steamy locomotive speeding thou the forest.A steam engine comes down a train track near trees.A double decker bus is driving by Big Ben in London.People in an outrigger canoe sail on emerald green water.Two people sailing a small white sail boat.behind a cliff, a boat sails awayTourist move in on Big Ben on a typical overcast London day.A group of people sitting around a table on a porch.A group of four people walking past a giant mushroom.A man and women smiling for the camera in a kitchen.A group of men sitting around a table drinking while a man behind stands pointing.Figure6:ImagesandtheirsentencedescriptionsassignedbytheDT-RNN.ImageSearchModelmRank4R@15R@55R@105BoW14.615.842.260.0kCCA15.916.441.458.0SDT-RNN12.516.446.665.6DescribingImagesBoW21.119.038.057.0kCCA18.021.047.061.0SDT-RNN16.923.045.063.0Table3:Evaluationcomparisonbetweenmeanrankoftheclosestcorrectimageorsentence(lowerisbetter4)withrecallatdifferentthresholds(higherisbetter,5).Withoneexception(R@5,bottomtable),theSDT-RNNoutperformstheothertwomodelsandallothermodelswedidnotincludehere.thisdifferentmetric.Table3showsthatthemea-suresdocorrelatewellandtheSDT-RNNalsoper-formsbestonthemultimodalrankingtaskswhenevaluatedwiththismeasure.6.6ErrorAnalysisInordertounderstandthemainproblemswiththecomposedsentencevectors,weanalyzethesen-tencesthathavetheworstnearestneighborrankbe-tweeneachother.WefindthatthemainfailuremodeoftheSDT-RNNoccurswhenasentencethatshoulddescribethesameimagedoesnotuseaverbbuttheothersentencesofthatimagedoincludeaverb.Forexample,thefollowingsentencepairhasvectorsthatareveryfarapartfromeachothereventhoughtheyaresupposedtodescribethesameimage:1.Ablueandyellowairplaneflyingstraightdownwhileemittingwhitesmoke2.AirplaneindivepositionGenerally,aslongasbothsentenceseitherhaveaverbordonot,theSDT-RNNismorerobusttodif-ferentsentencelengthsthanbagofwordsrepresen-tations.6.7ModelAnalysis:SemanticCompositionMatricesThebestmodelusescompositionmatricesbasedonsemanticrelationshipsfromthedependencyparser.WegivesomeinsightsintowhatthemodellearnsbylistingthecompositionmatriceswiththelargestFrobeniusnorms.Intuitively,thesematriceshavelearnedlargerweightsthatarebeingmultipliedwiththechildvectorinthetreeandhencethatchildwillhavemoreweightinthefinalcomposedparentvec-tor.IndecreasingorderofFrobeniusnorm,there-lationshipmatricesare:nominalsubject,possessionmodifier(e.g.their),passiveauxiliary,prepositionat,prepositioninfrontof,passiveauxiliary,passivenominalsubject,objectofpreposition,prepositioninandprepositionon.Themodellearnsthatnounsareveryimportantaswellastheirspatialprepositionsandadjectives.7ConclusionWeintroducedanewrecursiveneuralnetworkmodelthatisbasedondependencytrees.Foreval-uation,weusethechallengingtaskofmappingsen-tencesandimagesintoacommonspaceforfindingonefromtheother.Ournewmodeloutperformsbaselinesandothercommonlyusedmodelsthatcancomputecontinuousvectorrepresentationsforsen-tences.Incomparisontorelatedmodels,theDT-RNNismoreinvariantandrobusttosurfacechangessuchaswordorder.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
217
ReferencesG.Andrew,R.Arora,K.Livescu,andJ.Bilmes.2013.Deepcanonicalcorrelationanalysis.InICML,At-lanta,Georgia.K.Barnard,P.Duygulu,N.deFreitas,D.Forsyth,D.Blei,andM.Jordan.2003.Matchingwordsandpictures.JMLR.M.BaroniandA.Lenci.2010.Distributionalmem-ory:Un marco general para la semántica basada en corpus. Lingüística computacional,36(4):673–721.R.CollobertandJ.Weston.2008.Aunifiedarchi-tecturefornaturallanguageprocessing:deepneuralnetworkswithmultitasklearning.InProceedingsofICML,pages160–167.F.Costa,P.Frasconi,V.Lombardo,andG.Soda.2003.Towardsincrementalparsingofnaturallanguageusingrecursiveneuralnetworks.AppliedIntelligence.M.deMarneffe,B.MacCartney,andC.D.Manning.2006.Generatingtypeddependencyparsesfromphrasestructureparses.InLREC.J.Dean,G.S.Corrado,R.Monga,K.Chen,M.Devin,Q.V.Le,M.Z.Mao,M.Ranzato,A.Senior,P.Tucker,K.Yang,andA.Y.Ng.2012.Largescaledistributeddeepnetworks.InNIPS.J.Deng,W.Dong,R.Socher,L.-J.Li,K.Li,andL.Fei-Fei.2009.ImageNet:ALarge-ScaleHierarchicalIm-ageDatabase.InCVPR.J.Duchi,E.Hazan,andY.Singer.2011.Adaptivesub-gradientmethodsforonlinelearningandstochasticop-timization.JMLR,12,July.P.Duygulu,K.Barnard,N.deFreitas,andD.Forsyth.2002.Objectrecognitionasmachinetranslation.InECCV.A.Farhadi,M.Hejrati,M.A.Sadeghi,P.Young,C.Rashtchian,J.Hockenmaier,andD.Forsyth.2010.Everypicturetellsastory:Generatingsentencesfromimages.InECCV.Y.FengandM.Lapata.2013.Automaticcaptiongen-erationfornewsimages.IEEETrans.PatternAnal.Mach.Intell.,35.A.Frome,G.Corrado,J.Shlens,S.Bengio,J.Dean,M.Ranzato,andT.Mikolov.2013.Devise:Adeepvisual-semanticembeddingmodel.InNIPS.C.GollerandA.K¨uchler.1996.Learningtask-dependentdistributedrepresentationsbybackpropaga-tionthroughstructure.InProceedingsoftheInterna-tionalConferenceonNeuralNetworks.E.Grefenstette,G.Dinu,Y.-Z.Zhang,M.Sadrzadeh,andM.Baroni.2013.Multi-stepregressionlearningforcompositionaldistributionalsemantics.InIWCS.A.GuptaandL.S.Davis.2008.Beyondnouns:Exploit-ingprepositionsandcomparativeadjectivesforlearn-ingvisualclassifiers.InECCV.M.Hodosh,P.Young,andJ.Hockenmaier.2013.Fram-ingimagedescriptionasarankingtask:Datos,mod-elsandevaluationmetrics.J.Artif.Intell.Res.(JAIR),47:853–899.E.H.Huang,R.Socher,C.D.Manning,andA.Y.Ng.2012.ImprovingWordRepresentationsviaGlobalContextandMultipleWordPrototypes.InACL.K.Jarrett,K.Kavukcuoglu,M.A.Ranzato,andY.Le-Cun.2009.Whatisthebestmulti-stagearchitectureforobjectrecognition?InICCV.P.Blunsom.K.M.Hermann.2013.Theroleofsyntaxinvectorspacemodelsofcompositionalsemantics.InACL.A.Krizhevsky,I.Sutskever,andG.E.Hinton.2012.Imagenetclassificationwithdeepconvolutionalneuralnetworks.InNIPS.G.Kulkarni,V.Premraj,S.Dhar,S.Li,Y.Choi,A.C.Berg,andT.L.Berg.2011.Babytalk:Understandingandgeneratingimagedescriptions.InCVPR.N.Kumar,A.C.Berg,P.N.Belhumeur,,andS.K.Na-yar.2009.Attributeandsimileclassifiersforfacever-ification.InICCV.P.Kuznetsova,V.Ordonez,A.C.Berg,T.L.Berg,andYejinChoi.2012.Collectivegenerationofnaturalimagedescriptions.InACL.Q.V.Le,M.A.Ranzato,R.Monga,M.Devin,K.Chen,G.S.Corrado,J.Dean,andA.Y.Ng.2012.Build-inghigh-levelfeaturesusinglargescaleunsupervisedlearning.InICML.T.Mikolov,W.Yih,andG.Zweig.2013.Linguisticregularitiesincontinuousspacewordrepresentations.InHLT-NAACL.J.MitchellandM.Lapata.2010.Compositionindis-tributionalmodelsofsemantics.CognitiveScience,34(8):1388–1429.J.Ngiam,A.Khosla,M.Kim,J.Nam,H.Lee,andA.Y.Ng.2011.Multimodaldeeplearning.InICML.V.Ordonez,G.Kulkarni,andT.L.Berg.2011.Im2text:Describingimagesusing1millioncaptionedpho-tographs.InNIPS.J.B.Pollack.1990.Recursivedistributedrepresenta-tions.ArtificialIntelligence,46,November.C.Rashtchian,P.Young,M.Hodosh,andJ.Hocken-maier.2010.CollectingimageannotationsusingAmazon’sMechanicalTurk.InWorkshoponCreat-ingSpeechandLanguageDatawithAmazon’sMTurk.R.SocherandL.Fei-Fei.2010.Connectingmodalities:Semi-supervisedsegmentationandannotationofim-agesusingunalignedtextcorpora.InCVPR.R.Socher,C.D.Manning,andA.Y.Ng.2010.Learningcontinuousphraserepresentationsandsyntacticpars-ingwithrecursiveneuralnetworks.InProceedingsoftheNIPS-2010DeepLearningandUnsupervisedFea-tureLearningWorkshop.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
1
7
7
1
5
6
6
8
2
6
/
/
t
yo
a
C
_
a
_
0
0
1
7
7
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
218
R.Socher,E.H.Huang,J.Pennington,A.Y.Ng,andC.D.Manning.2011a.DynamicPoolingandUnfold-ingRecursiveAutoencodersforParaphraseDetection.InNIPS.R.Socher,C.Lin,A.Y.Ng,andC.D.Manning.2011b.ParsingNaturalScenesandNaturalLanguagewithRecursiveNeuralNetworks.InICML.R.Socher,J.Pennington,E.H.Huang,A.Y.Ng,andC.D.Manning.2011c.Semi-SupervisedRecursiveAutoencodersforPredictingSentimentDistributions.InEMNLP.R.Socher,B.Huval,C.D.Manning,andA.Y.Ng.2012.SemanticCompositionalityThroughRecursiveMatrix-VectorSpaces.InEMNLP.R.Socher,J.Bauer,C.D.Manning,andA.Y.Ng.2013a.ParsingWithCompositionalVectorGrammars.InACL.R.Socher,M.Ganjoo,C.D.Manning,andA.Y.Ng.2013b.Zero-ShotLearningThroughCross-ModalTransfer.InNIPS.R.Socher,M.Ganjoo,H.Sridhar,O.Bastani,andA.Y.Ng.C.D.Manningand.2013c.Zero-shotlearn-ingthroughcross-modaltransfer.InProceedingsoftheInternationalConferenceonLearningRepresenta-tions(ICLR,WorkshopTrack).N.SrivastavaandR.Salakhutdinov.2012.Multimodallearningwithdeepboltzmannmachines.InNIPS.A.Torralba,K.P.Murphy,andW.T.Freeman.2010.Usingtheforesttoseethetrees:exploitingcontextforvisualobjectdetectionandlocalization.Communica-tionsoftheACM.P.D.TurneyandP.Pantel.2010.Fromfrequencytomeaning:Modelos espaciales vectoriales de semántica. Revista de investigación de inteligencia artificial,37:141–188.B.Yao,X.Yang,L.Lin,M.W.Lee,andS.-C.Zhu.2010.I2t:imageparsingtotextdescription.IEEEXplore.