ARTÍCULO DE INVESTIGACIÓN
Towards automated analysis of research methods
in library and information science
Ziqi Zhang1
, Winnie Tam2
, and Andrew Cox1
1Information School, The University of Sheffield
2University of Manchester Library, The University of Manchester
Palabras clave: bibliometría, content analysis, data mining, library and information science, investigación
methods, text mining
ABSTRACTO
Previous studies of research methods in Library and Information Science (LIS) lack consensus
in how to define or classify research methods, and there have been no studies on automated
recognition of research methods in the scientific literature of this field. This work begins to
fill these gaps by studying how the scope of “research methods” in LIS has evolved, y el
challenges in automatically identifying the usage of research methods in LIS literature. Nosotros
collected 2,599 research articles from three LIS journals. Using a combination of content analysis
and text mining methods, a sample of this collection is coded into 29 different concepts of research
methods and is then used to test a rule-based automated method for identifying research methods
reported in the scientific literature. We show that the LIS field is characterized by the use of
an increasingly diverse range of methods, many of which originate outside the conventional
boundaries of LIS. This implies increasing complexity in research methodology and suggests the
need for a new approach towards classifying LIS research methods to capture the complex
structure and relationships between different aspects of methods. Our automated method is the
first of its kind in LIS, and sets an important reference for future research.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
1.
INTRODUCCIÓN
Research methods are one of the defining intellectual characteristics of an academic discipline
(Whitley, 2000). Paradigmatic fields use a settled range of methods. Softer disciplines are
marked by greater variation, more interdisciplinary borrowing, and novelty. In trying to under-
stand our own field of Library and Information Science (LIS) mejor, a grasp of the changing
pattern of methods can tell us much about the character and directions of the subject. LIS em-
ploys an increasingly diverse range of research methods as the discipline becomes increasingly
entwined with other subjects, such as health informatics (p.ej., Lustria, Kazmer et al., 2010), y
computer science (p.ej., Chen, Liu, & A, 2013). As a result of a wish to understand these
patrones, a number of studies have been conducted to investigate the usage and evolution of
research methods in LIS. Many of these (Bernhard, 1993; Blake, 1994; Chu, 2015; Järvelin &
Vakkari, 1990) aim to develop a classification scheme of commonly used research methods
in LIS, whereas some (Hider & Pymm, 2008; VanScoy & Fontana, 2016) focus on comparing
the usage of certain methods (p.ej., qualitative vs. quantitative), or recent trends in the usage
of certain methods (Fidel, 2008; Grankikov, Hong et al., 2020).
un acceso abierto
diario
Citación: zhang, Z., Tam, w., & Cox, A.
(2021). Towards automated analysis of
research methods in library and
information science. Quantitative
Science Studies, 2(2), 698–732. https://
doi.org/10.1162/qss_a_00123
DOI:
https://doi.org/10.1162/qss_a_00123
Recibió: 25 Junio 2020
Aceptado: 23 Enero 2021
Autor correspondiente:
Ziqi Zhang
ziqi.zhang@sheffield.ac.uk
Editor de manejo:
Juego Waltman
Derechos de autor: © 2021 Ziqi Zhang, Winnie
Tam, and Andrew Cox. Published under
a Creative Commons Attribution 4.0
Internacional (CC POR 4.0) licencia.
La prensa del MIT
Automated analysis of research methods in library and information science
Sin embargo, we identify several gaps in the literature on research methods in LIS. Primero, hay
an increasing need for an updated view of how the scope of “research methods” in LIS has
evolved. Por un lado, as we shall learn from the literature review, despite continuous
interest in this research area, there remains a lack of consensus in the terminology and the
classification of research methods (Ferran-Ferrer, Guallar et al., 2017; Risso, 2016). Alguno
(Hider & Pymm, 2008; Järvelin & Vakkari, 1990) classify methods from different angles that
form a hierarchy, y otros (Chu, 2015; Parque, 2004) define a flat structure of methods. En
reporting their methods, scholars also undertake different approaches, such as some that de-
fine their work in terms of data collection methods, and others that define themselves through
modes of analysis. Por lo tanto, this “lack of consensus” is difficult to resolve, but reflects that LIS
is not a paradigmatic discipline where it is agreed how knowledge is built. Bastante, the field
sustains a number of incommensurable viewpoints about the definition of method.
Por otro lado, as our results will show, the growth of artificial intelligence (AI) and Big
Data research in the last decade has led to a significant increase of data-driven research pub-
lished in LIS that extends to these fast-growing disciplines. As a result of this, lo convencional
scope and definitions of LIS research methods have difficulty in accommodating these new
disciplines. Por ejemplo, many of the articles published around the AI and Big Data topics
are difficult to fit into the categories of methods defined in Chu (2015).
The implication of the above situation is that it becomes extremely challenging for re-
searchers (particularly new to LIS) to develop and maintain an informed view of the research
methods used in the field. Segundo, there is an increasing need for automated methods that can
help the analysis of research methods in LIS, as the number of publications and research
methods both increase rapidly. Sin embargo, we find no work in this direction in LIS to date.
Although such work has already been attempted in other disciplines, such as Computer
Ciencia (Augenstein, Das et al., 2017) and Biomedicine (Hirohata, Okazaki et al., 2008) allá
is nothing comparable in LIS. Studies in those other fields have focused on automatically iden-
tifying the use of research methods and their parameters (p.ej., data collected, experiment set-
tings) from scientific literature, and have proved to be an important means for the effective
archiving and timely summarizing of research. The need for providing structured access to
the content of scientific literature is also articulated in Knoth and Herrmannova (2014)’s con-
cept of “semantometics.” We see a pressing need for conducting similar research in LIS.
Sin embargo, due to the complexity of defining and agreeing with a classification of LIS research
methods, we anticipate the task of automated analysis will face many challenges. Por lo tanto, a
first step in this direction would be to gain an in-depth understanding of such technical
challenges.
To address these limitations in previous literature, this work combines both content analysis
and text mining methods to conduct an analysis of research methods reported in the LIS liter-
ature, to answer the following questions:
(cid:129) How has the scope of “research methods” in LIS evolved, compared to previous defini-
tions of this subject?
(cid:129) To what extent can we automatically identify the usage of research methods in LIS
literature, and what are the challenges?
We review existing definitions and the scope of “research methods” in LIS, and discuss their
limitations in the context of the increasingly multidisciplinary nature and diversification of
research methods used in this domain. Following on from this, we propose an updated
Estudios de ciencias cuantitativas
699
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
classification of LIS research methods based on an analysis of the past 10 years’ publications
from three primary journals in this field. Although this does not address many of the limitations
in the status quo of the definition and classification of LIS research methods, it reflects the
significant changes that deviate from the previous findings and highlights issues that need to
be addressed in future research in this direction. Segundo, we conduct the first study of auto-
mated methods for identifying research methods from LIS literature. To achieve this, we de-
velop a data set containing human-labeled scientific publications according to our new
classification scheme, and a text mining method that automatically recognizes these labels.
Our experiments revealed that, compared to other disciplines where automated classification
of this kind is well established, the task in LIS is extremely challenging and there remains a
significant amount of work to be done and coordinated by different parties to improve the
performance of the automated method. We discuss these challenges and potential ways to
address them to inform future research taking this direction.
The remainder of this paper is structured as follows. We discuss related work in the next
sección, followed by a description of our method. We then present and discuss our results and
the limitations of this study, with concluding remarks in the final section.
2. RELATED WORK
We discuss related work in two areas. Primero, we review studies of research methods in LIS. Nosotros
do not cover research in similar directions within other disciplines, as research methods can
differ significantly across different subject fields. Segundo, we discuss studies of automated
methods for information extraction (IE) from scholarly data. We will review work conducted
in other disciplines, particularly from Computer Science and Biomedicine, because significant
progress has been made in these subject fields and we expect to learn from and generalize
methods developed in these areas to LIS.
2.1. Studies of Research Methods in LIS
Chu (2015) surveyed pre-2013 studies of research methods in LIS and these have been sum-
marized in Table 1. To avoid repetition, we only present an overview of this survey and refer
readers to her work for details. Järvelin and Vakkari (1990) conducted the first study on this
topic and proposed a framework that contains “research strategies” (p.ej., historical research,
survey, qualitative strategy, evaluación, case or action research, and experiment) and “data
collection methods” (p.ej., cuestionario, interview, observación, thinking aloud, content anal-
ysis, and historical source analysis). This framework was widely adopted and revised in later
estudios. Por ejemplo, Kumpulainen (1991) showed that 51% of studies belonged to “empirical
research” where “interview and questionnaire” (combined) was the most popular data collec-
tion method, y 48% were nonempirical research and contained no identifiable methods of
data collection. Bernhard (1993) defined 13 research methods in a flat structure. Some of these
have a connection to the five research strategies by Järvelin and Vakkari (1990) (p.ej., “exper-
imental research” to “empirical research”), and others would have been categorized as “data
collection methods” by Järvelin and Vakkari (p.ej., “content analysis,” “bibliometrics,” and
“historical research”). Other studies that proposed flat structures of method classification in-
clude Blake (1994), who introduced a classification of 13 research methods largely resembling
those in Bernhard (1993), and Park (2004), who identified 17 research methods when com-
paring research methods curricula in Korean and U.S. universidades. The author identified new
methods such as “focus group,” and “field study,” possibly indicating the changing scene in
Estudios de ciencias cuantitativas
700
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 1.
A summary of literature on the studies of research methods in LIS
Estudiar
Järvelin and Vakkari
(1990)
Data sample
Key findings w.r.t. research methods
833 articles from 37 journals
en 1985
A classification scheme consisting of five “research strategies”
and seven “data collection methods”
Kumpulainen (1991)
632 articles from 30 LIS journals
Bernhard (1993)
en 1975
Including journals, tesis,
textbooks, and reference
sources in LIS
51% “empirical research," 48% “nonapplicable," 13%
“historical method," 11% “questionnaire and interview”
13 research methods; some relate to the “research strategies”
whereas others relate to the “data collection methods”
in Järvelin and Vakkari (1990)
Blake (1994)
LIS dissertations between 1975
13 research methods, most of which are similar
y 1989
to Bernhard (1993)
Parque (2004)
Fidel (2008)
71 syllabus of Korean and U.S.
universities between 2001
y 2003
17 research methods, some not reported before
(p.ej., field study, focus group)
465 articles from LIS journals
entre 2005 y 2006
Solo 5% used “mixed methods,” whereas many that claimed to
do so actually used “multiple methods” or “two approaches”
Hider and Pymm (2008)
834 articles from 20 LIS journals
en 2005
Chu (2015)
1,162 articles from LIS journals
entre 2001 y 2010
VanScoy and Fontana
1,362 journal articles published
(2016)
entre 2000 y 2009
Ferran-Ferrer
et al. (2017)
580 Spanish LIS journal articles
entre 2012 y 2014
Based on the Järvelin and Vakkari (1990) clasificación, “survey”
remained as the predominant “research strategy”
and “experiment” had increased significantly
A classification that extends earlier work in this area; “survey”
no long dominating; en cambio, “content analysis,” “experiment,"
and “theoretical approach” become more popular
A classification scheme similar to the previous work;
majority of research was “quantitative”, con
“descriptive studies” based on “surveys” most common
Proposed nine “research methods” and 13 “techniques.”
“Descriptive research” was the most used “research method,"
and “content analysis” was the most used “technique”
Togia and Malliari
440 LIS journal articles between
(2017)
2011 y 2016
A similar classification of 12 “research methods” similar to
that in Chu (2015). “Survey” remained the dominant method
Grankikov et al. (2020)
386 LIS journal articles between
Showed an increase in the use of “mixed methods”
2015 y 2018
in this field
LIS. Hider and Pymm (2008) conducted an analysis that categorized articles from 20 LIS jour-
nals into the classification scheme defined by Järvelin and Vakkari (1990). They showed that
“survey” remained the predominant research strategy but there had been a notable increase of
“experiment.” Fidel (2008) examined the use of “mixed methods” in LIS. She proposed a def-
inition of “mixed method” and distinguished it with other concepts that are often misused as
“mixed methods” in this field. En general, only a very small percentage of LIS literature (5%) usado
“mixed methods” defined in this way. She also highlighted that in LIS, researchers often do not
use the term mixed methods to describe their work.
Drawing conclusions from the literature, Chu (2015) highlighted several patterns from the
studies of research methods in LIS. Primero, researchers in LIS are increasingly using more
Estudios de ciencias cuantitativas
701
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
sophisticated methods and techniques instead of the commonly used survey or historical
method of the past. Methods such as experiments and modeling were on the rise. Segundo,
there has been an increase in the use of qualitative approaches compared with the past, semejante
as in the field of Information Retrieval. Building on this, Chu (2015) conducted a study of
1,162 research articles published from 2001 a 2010 in three major LIS journals—the largest
collection spanning the longest time period in previous studies. She proposed a classification of
17 methods that largely echo those suggested before. Sin embargo, some new methods included
were “research journal/diary” and “webometrics” (p.ej., link analysis, altmetrics). The study also
showed that “content analysis,” “experiment,” and “theoretical approach” overtook “survey”
and “historical method” to secure the dominant position among popular research methods
used in LIS.
Since Chu (2015), a number of studies have been conducted on the topic of research
methods in LIS, generally using a similar approach. Research articles published from some
major LIS journals are sampled and manually coded into a classification scheme that is typi-
cally based on those proposed earlier. We summarize a number of studies below. VanScoy
and Fontana (2016) focused on reference and information service (RIS) literature, a subfield of
LIS. Encima 1,300 journal articles were first separated into research articles (es decir., empirical stud-
es) and those that were not research. Research articles were then coded into 13 investigación
methods that can be broadly divided into “qualitative,” “quantitative,” and “mixed” methods.
De nuevo, these are similar to the previous literature, but add new categories such as “narrative
analysis” and “phenomenology.” Authors showed that most of the RIS research was quantita-
tivo, with “descriptive methods” based on survey questionnaires being the most common.
Ferran-Ferrer et al. (2017) studied a collection of Spanish LIS journal articles and showed that
68% were empirical research. They developed a classification scheme that defines nine “re-
search methods” and 13 “techniques.” Different categories to the previous studies include “log
análisis,” “text interpretation,” etc. Sin embargo, the exact difference between these concepts
was not clearly explained. Togia and Malliari (2017) coded 440 LIS journal articles into a sim-
ilar classification of 12 “research methods” to that in Chu (2015). Sin embargo, in contrast to Chu,
they showed that “survey” remained in the dominant position. Grankikov et al. (2020) studied
the use of “mixed methods” in LIS literature. Different from Fidel (2008), they concluded that
the use of “mixed methods” in LIS has been on the rise.
In addition to work within LIS there has been work more widely in the social sciences to
produce typologies for methodology (p.ej., Luff, Byatt, & Martín, 2015). This update to an ear-
lier seminal work by Durrant (2004) introduces a rather comprehensive typology of method-
ology, differentiating research design, data collection, data quality, and data analysis, entre
other categories. While offering a detailed approach for the gamut of social science methods, él
does not represent the full range of methods of use in LIS which draws on approaches beyond
the social sciences. De este modo, while contributing to the development of our own taxonomy, este
work could only offer a useful input.
En resumen, the literature shows a continued interest in the studies of research methods in
LIS in the last two decades. Sin embargo, there remains significant inconsistency in the interpre-
tation of terminologies used to describe the research methods, and in the different categoriza-
tions of research methods. This “lack of consensus” was discussed in Risso (2016) y
VanScoy and Fontana (2016). Risso (2016) highlighted that first, studies of LIS research
methods take different perspectives that can reflect research subareas within this field, object
of study delimitation, or different ways of considering and approaching it. Segundo, a severe
problem is the lack of category definitions in the different research method taxonomies pro-
posed in the literature, and as a result, some were difficult to distinguish from each other.
Estudios de ciencias cuantitativas
702
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
VanScoy and Fontana (2016) pointed out that existing methodology categorizations in LIS are
difficult to use, due to “conflation of research design, data collection, and data analysis
methods,” “ill-defined categories,” and “extremely broad ‘other’ categories.” As examples,
whereas Chu (2015) proposed a classification primarily based on data collection techniques,
methods such as “bibliometrics” and “webometrics” are arguably not for data collection,
and were seen to be classified as “techniques” or “methods” in Ferran-Ferrer et al. (2017).
On the contrary, “survey,” “interview,” and “observation” are mixed with “content analysis”
and “experiment” and all considered as “techniques” by Ferran-Ferrer et al. (2017). In terms of
the disagreement on the use of hierarchy, many authors have adopted a simple flat structure
(p.ej., Bernhard, 1993; Chu, 2015; Hider & Pymm, 2008; Parque, 2004), whereas some introduced
simple but inconsistent hierarchies (p.ej., “research strategies” vs. “data collection methods” in
Järvelin and Vakkari (1990) and “qualitative” vs. “quantitative” in VanScoy and Fontana
(2016)). While intuitively we may argue that a sensible approach is to split methods primarily
into data collection and analysis methods, apparently the examples shown above suggest that
this is not a view that warrants consensus.
We argue that this issue reflects the ambiguity and complexity in research methods used in
LIS. As a result of this, the same data can be analyzed in different ways that reflect different
conceptual stances. Adding to this is the lack of consistency among authors in reporting their
methods. Researchers sometimes define their work in terms of data collection methods, otros
through modes of analysis. Por esta razón, we argue that it is intrinsically difficult, if not im-
posible, to fully address these issues with a single universally agreed LIS research method
definition and classification. Sin embargo, it remains imperative for researchers to gain an up-
dated view of the evolution and diversification of research methods in this field, and to appre-
ciate the different viewpoints from which they can be structured.
2.2. Automated Information Extraction from Scholarly Data
IE is the task of automatically extracting structured information from unstructured or semi-
structured documents. There has been increasing research in IE from scientific literature (o
“scholarly data”) in the last decades, due to the rapid growth of literature and the pressing
need to effectively index, retrieve, and analyze such data (Nasar, Jaffry, & Malik, 2018). Nasar
et al. (2018) reviewed recent studies in this area and classified them into two groups: those
that extract metadata about an article, and those that extract key insights from the content.
Research in this area has been predominantly conducted in the computer science, medical,
and biology domains. We present an overview of these studies below.
Metadata extraction may target “descriptive” metadata that are often used for discovery and
indexing, such as title, author, keywords, and references; “structural” metadata that describe
how an article is organized, such as the section structures; and “administrative” metadata for
resource management, such as file type and size. A significant number of studies in this area
focus on extracting information from citations (Alam, Kumar et al., 2017), or header level
metadata extraction from articles (Wang & Chai, 2018). The first targets information in indi-
vidual bibliographic entries, such as the author names (first name, last name, initial), title of the
artículo, journal name, and publisher. The second targets information usually on the title page
of an article, such as title, autores, affiliations, emails, publication venue, keywords, y
abstract. Thanks to the continuous interest in the computer science, medical, and biology do-
mains, several gold-standard data sets have been curated over the years to be used to bench-
mark IE methods developed for such tasks. Por ejemplo, the CORA data set (Seymore,
McCallum, & Rosenfeld, 1999) was developed based on a collection of computer science
Estudios de ciencias cuantitativas
703
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
research articles, and consists of both a set for header metadata extraction (935 records) y un
set for citation extraction (500 records). The FLUX-CiM data set (Cortez, da Silva et al., 2007) es
a data set for citation extraction, containing over 2,000 bibliography entries for computer sci-
ence and health science. Th UMASS data set consists of bibliographic information from 5,000
research papers in four major domains that include physics, matemáticas, computer science,
and quantitative biology.
According to Nasar et al. (2018), key-insights extraction refers to the extraction of informa-
tion within an article’s text content. The types of such information vary significantly. Ellos son
often ad hoc and there is no consensus on what should be extracted. Sin embargo, típicamente, este
can include mentions of objectives, hypothesis, método, related work, gaps in research, resultado,
experimento, evaluation criteria, conclusion, limitations of the study, and future work.
Augenstein et al. (2017) and QasemiZadeh and Schumann (2016) proposed more fine-grained
information units for extraction, such as task (p.ej., “machine learning,” “data mining”), proceso
(es decir., solutions of a problem, such as algorithms, methods and tools), materiales (es decir., resources
studied in a paper or used to solve the problem, such as “data set,” “corpora”), tecnología,
sistema, tool, language resources (specific to computational linguistics), modelo, and data item
metadata. The sources of such information are generally considered to be either sentence- o
phrase-level, where the first aims to identify sentences that may convey the information either
explicitly or implicitly, and the second aims to identify phrases or words that explicitly de-
scribe the information (p.ej., “CNN model” in “The paper proposes a novel CNN model that
works effectively for text classification”).
Studies of key-insight extraction are also limited to computer science and medical domains.
Due to the lack of consensus over the task definition, which is discussed above, different data
sets have been created focusing on different tasks. Hirohata et al. (2008) created a data set of
51,000 abstracts of published biomedical research articles, and classified individual sentences
into objective, método, resultado, conclusion, and none. Teufel and Moens (2002) coded 80 com-
putational linguistics research articles into different textual zones that describe, Por ejemplo,
fondo, objetivo, método, and related work. Liakata, Saha et al. (2012) developed a cor-
pus of 256 full biochemistry/chemistry articles which are coded at sentence-level for 11 cat-
egories, such as hypothesis, motivación, meta, and method. Dayrell, Candido et al. (2012)
created a data set containing abstracts from Physical Sciences and Engineering and Life and
Health Sciences (LH). Sentences were classified into categories such as background, método,
and purpose. Ronzano and Saggion (2015) coded 40 articles of the computer imaging domain
and classified sentences into similar categories. Gupta and Manning (2011) pioneered the
study of phrase-level key-insight extraction. They created a data set of 474 abstracts of com-
putational linguistics research papers, and annotated phrases that describe three general levels
of concepts: “focus,” which describes an article’s main contribution; “technique,” which men-
tions a method or a tool used in an article; and “domain,” which explains the application do-
main of a paper, such as speech recognition. Augenstein et al. (2017) created a data set of
computational linguistics research articles that focus on phrase-level insights. Phrases indicat-
ing a concept of task, proceso, and material are annotated within 500 article abstracts.
QasemiZadeh and Schumann (2016) annotated “terms” in 300 abstracts of computational
linguistics papers. The categories of these terms are more fine grained, but some are generic,
such as spatial regions, temporal entities, and numbers. Tateisi, Ohta et al. (2016) annotated a
corpus of 400 computer science paper abstracts for relations, such as “apply-to” (p.ej., a method
applied to achieve certain purpose) and “compare” (p.ej., a method is compared to a baseline).
In terms of techniques, the state of the art has mostly used either rule-based methods or
aprendizaje automático. With rule-based methods, rules are coded into programs to capture
Estudios de ciencias cuantitativas
704
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
recurring patterns in the data. Por ejemplo, words such as “results,” “experiments,” and “eval-
uation” are often used to represent results in a research article, and phrases such as “we use,"
and “our method” are often used to describe methods (Hanyurwimfura, Bo et al., 2012;
Houngb & Mercer, 2012). With machine learning methods, a human annotated data set con-
taining a large number of examples is first created, and is used subsequently to “train” and
“evaluate” machine learning algorithms (Hirohata et al., 2008; Ronzano & Saggion, 2015).
Such algorithms will consume low-level features (p.ej., palabras, word sequences (n-grams), part
of speech, word-shape (capitalized, lower case, etc.), and word position, which are usually
designed by domain experts) to discover patterns that may help capture the type of information
that is to be extracted.
En resumen, although there have been a plethora of studies on IE in the scientific literature,
these have been limited to only a handful of disciplines and none has studied the problem in
LIS. Existing methods will not be directly applicable to our problems for a number of reasons.
Primero, previous work that extracts “research methods” only aims to identify the sentence or
phrase that mentions a method (es decir., oración- or phrase-level of extraction), but not recognize
the actual method used. This is different, because the same research method may be referred
to in different ways (p.ej., “questionnaire” and “survey” may indicate the same method).
Previous work also expects the research methods to be explicitly mentioned, which is not
always true in LIS. Studies that use, Por ejemplo, “content analysis,” “ethnography,” or
“webometrics” may not even use these terms in their work to explain their methods. Para
ejemplo, instead of stating “a content analysis approach is used,” many papers may only state
“we analyzed and coded the transcripts….” For these reasons, a different approach needs to
be taken and a deeper understanding of these challenges as well as to what extent they can be
dealt with will add significant value for future research in this area.
3. METODOLOGÍA
We describe our method in four parts. Primero, we explain our approach to data collection.
Segundo, we describe an exploratory study of the data set, with the goal of developing a pre-
liminary view of the possible research methods mentioned in our data set. Tercero, guided by the
literature and informed by the exploratory analysis, we propose an updated research method
classification scheme. Instead of attempting to address the intrinsically difficult problem of de-
fining a classification hierarchy, our proposed scheme will adopt a flat structure. Our focus
will be the change in the scope of research methods (p.ej., where previous classification
schemes need a revision). Finalmente, we describe how we develop the first automated method
for the identification of research methods used in LIS studies.
3.1. Recopilación de datos
Our data collection methods are subject to the following criteria. Primero, we select scientific
publications from popular journals that are representative of LIS. Segundo, we use data that
are machine readable, such as those in an XML format that preserves all the structural infor-
mation of an article, instead of PDFs. This is because we would like to be able to process the
text content of each, and OCR from PDFs is known to create noise in converted text (Nasar
et al., 2018). Finalmente, we select data from the same or similar sources reported from the pre-
vious literature such that our findings can be directly compared to early studies. This may al-
low us to discover trends in LIS research methods.
De este modo, building on Chu (2015), we selected research articles published between January 1,
2008 and December 31, 2018 and from Journal of Documentation ( JDoc), Journal of the
Estudios de ciencias cuantitativas
705
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
American Society for Information Science & Tecnología ( JASIS&T; now Journal of the
Association for Information Science and Technology), and Library & Information Science
Investigación (LISR). These are among the core journals in LIS and were also used in Chu
(2015), thus allowing us to make a direct comparison against earlier findings. We used the
CrossRef API1 to fetch the XML copies of these articles, and only kept articles that describe
empirical research. This is identified with a category label assigned to each article by a journal.
Sin embargo, we notice a significant degree of inter- and intrajournal inconsistency in terms of
how their articles are labeled. Brevemente, each journal used between 14 y 19 categories to label
their articles. There appear to be repetitions in these categories within each journal, and a lack
of consensus on how each journal categorizes its articles. We show details of this later in
our results section. For JDoc, we included 381 (out of 508 articles published in this period)
articles labeled as “research article” and “case study.” For JASIS&t, we included 1,837
“research articles” (out of 2,150). For LISR, we included 382 “research articles” and “full
length articles (FLA).” This created a data set of 2,599 research articles, twice more than that in
Chu (2015).
The XML versions of research articles allow programmatic access to the structured content
of the articles, such as the title, autores, abstract, sections of main text, subsections, and par-
agraphs. We extract this structured content from each article for automated analysis later.
Sin embargo, it is worth noting that different publishers have adopted different XML templates
to encode their data, which created obstacles during data processing.
3.2. Exploratory Analysis
To support our development of the classification scheme, we begin by undertaking an explor-
atory analysis of our data set to gain a preliminary understanding of the scope of methods
potentially in use. Para esto, we use a combination of clustering and terminology extraction
methods. VOSviewer (Van Eck & waltman, 2010), a bibliometric software tool, is used to
identify keywords from the publication data sets and their co-occurrence network within
the three journals. Our approach consisted of three steps detailed below.
Primero, for each article, we extract the text content that most likely contains descriptions of its
methodology (es decir., the “methodology text”). Para esto, we combine text content from title, key-
palabras, abstracts, and also the methodology section (si está disponible) of each article. To extract the
methodology section from an article, we use a rule-based method to automatically identify the
section that describes the research methods (es decir., the “methodology section”). This is done by
extracting all level 1 sections in an article together with their section titles, and then using a list
of keywords to match against these section titles. If a section title contains any one of these
keywords, we consider that section to be the methodology section. The keywords include2
“methodology, desarrollo, método, procedimiento, diseño, study description, data analysis/
estudiar, the model.” Note that although these keywords are frequently seen in methodology
section titles, we do not expect them to identify all variations of such section titles, nor can
we expect every article to have a methodology section. Sin embargo, we did not need to fully
recover them as long as we have a sufficiently large sample that can inform our development
of the classification scheme later on. This method identified methodology sections from 290
(out of 381), 1,283 (out of 1,837), y 346 (out of 383) of JDoc, JASIS&t, and LISR articles
1 https://www.crossref.org/services/metadata-delivery/, last retrieved in March 2020.
2 Their plural forms are also considered.
Estudios de ciencias cuantitativas
706
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
respectivamente. Still, there remains significant variation in terms of how researchers name their
methodology section. We show this later in the results section. When the methodology section
cannot be identified by our method, we use the title, keywords, and abstract of the article only.
We apply this process to each article in each journal, creating three corpora.
Segundo, we import each corpus to VOSviewer3 (versión 1.614) and use its text-mining func-
tion to extract important terms and create clusters based on co-occurrences of the terms.
VOSviewer uses natural language processing algorithms in the process of identifying terms.
It involves steps such as copyright statement removal, sentence detection, part-of-speech tag-
ging, noun phrase identification, and noun phrase unification. The extracted noun phrases are
then treated as term candidates. Próximo, the number of articles in which a term occurs is counted
(es decir., document frequency, or DF). Binary counting is chosen to avoid the analysis being
skewed by terms that are very frequent within single articles. Then we select the top 60% rel-
evant terms ranked by document frequency, and exclude those with a DF less than 10. Estos
terms are used to support the development of the classification scheme.
To facilitate our coders in their task, the terms are further clustered into groups using the
clustering function in VOSviewer. Brevemente, the algorithm starts by creating a keyword network
based on the co-occurrence frequencies within the title, abstract, keyword list, and method-
ology section. It then uses a technique that is a variant of the modularity function by Newman
and Girvan (2004) and Newman (2004) for clustering the nodes in a network. Details of this
algorithm can be found in Van Eck and Waltman (2014). We expect terms related to the same
or similar research methods to form distinct clusters. De este modo, by creating these clusters, we seek
to gain some insight into the methods they may represent.
The term lists and their cluster memberships for the three journals are presented to the
codificadores, who are asked to manually inspect them and consider them in their development of
the classification scheme below.
3.3. Classification Scheme
Our development of the classification of research methods is based on a deductive approach
informed by the previous literature and our exploratory analysis. A sample of around 110 ar-
ticles (“shared sample”) were randomly selected from each of the three journals to be coded by
three domain experts. To define “research methods,” we asked all coders to create a flat clas-
sification of methods primarily following the flat scheme proposed by Chu (2015) for refer-
ence. They could identify multiple methods for an article, and when this was the case, ellos
were asked to identify the “main” (es decir., “first” as in Chu) method and other “secondary”
methods (es decir., segundo, tercero, etc.. in Chu). While Chu (2015) took a view focusing on data col-
lection methods, we asked coders to consider both modes of analysis and data collection
methods as valid candidates, as in Kim (1996). We did not ask coders to explicitly separate
analysis from data collection, porque (as reflected in our literature review) there is disagree-
ment in how different methods are classified from these angles.
Coders were asked to reuse the methods in Chu’s classification where possible. They were
also asked to refer to the term lists extracted before, to look for terms that may support existing
theory, or terms that may indicate new methods that were not present in Chu’s classification.
When no codes from Chu’s model could be used, they were asked to discuss and create new
codes that are appropriate, particularly informed by the term lists. Once the codes were final-
ized, the coders split the remaining data equally for coding. An Inter-Annotator-Agreement
3 https://www.vosviewer.com/. Last accessed May 2020.
Estudios de ciencias cuantitativas
707
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
(Kappa statistics) de 86.7 was obtained on the shared sample when only considering the main
method identified.
One issue at the beginning of the coding process is the notable duplicative and overlapping
nature in the methods reported in the existing literature, as well as those proposed by the
codificadores. Using Chu’s scheme as an example, ethnography often involves participant observa-
ción, whereas bibliometrics may use methods such as link analysis (as part of webometrics).
Another issue is the confusion of “topic” and “method.” For example, an article could clearly
discuss a bibliometrics study, but it was debatable whether it uses a “bibliometrics” method.
To resolve these issues, coders were asked to follow the following principles. The first was to
distinguish the goal of an article and the means implemented to achieve it. The second was to
treat the main method as the one that generally takes the larger part of the text. Examples will
be provided later in the results section.
During the coding process, coders were also asked to document the keywords that they
found to be often indicative of each research method. Por ejemplo, “content analysis” and
“inter coder/rater reliability” are often seen in articles that use the “content analysis” method,
whereas “survey,” “Likert,” “sampling,” and “response rate” are often seen in articles that use
“questionnaire.” Note however, that it is not possible to create an exhaustive vocabulary for all
research methods. Many keywords could also be ambiguous, and some research methods may
only have a very limited set of keywords. Sin embargo, these keywords form an important
resource for our automated methods to be proposed below. Our proposed method classifica-
tion contains 29 methods. Estos, together with their associated keywords, are shown and
discussed later in the results section.
3.4.
Information Extraction of Research Methods
En esta sección, our goal is to develop automated IE methods that are able to determine the type
of research method(s) that are used by a research article. As discussed before, this is different
from the large number of studies on key-insights extraction that are already conducted in other
disciplines. Primero, previous studies aim to classify text segments (p.ej., oraciones, phrases) dentro
a research article into broad categories including “methods,” without identifying what the
methods are. As we have argued, these are two different tasks. Segundo, compared to the types
of key insights for extraction, our study tackles a significantly larger number of fine-grained
tasks—29 research methods. This implies that our task is much more challenging and that pre-
vious methods will not be directly transferable.
As our study is the first to tackle this task in LIS, we opt for a rule-based method for two
razones. Primero, compared to machine learning methods, rule-based methods were found to
have better interpretability and flexibility when requirements are unclear (Chiticariu, li, &
Reiss, 2013). This is particularly important for studies in new domains. Segundo, despite in-
creasing interest in machine learning-based methods, Nasar et al. (2018) showed that they
do not have a clear advantage over rule-based methods. Además, we also focus on a rather
narrow target: identifying a single main method used. Note that this does not imply an assump-
tion that each article will use only one method. It is rather a built-in limitation of our IE method.
The reasons, as we shall discuss in more detail later, are twofold. Por un lado, almost
every article will mention multiple methods, but it is extremely difficult to determine automat-
ically which are actually used for conducting the research and which are not. En el otro
mano, as per Chu (2015), articles that report using multiple methods remain a small fraction
(p.ej., 23% for JDoc, 13% for JASIS&t, y 18% for LISR in 2009–2010). With these in mind, él
is extremely easy for automated methods to make false positive extractions of multiple
Estudios de ciencias cuantitativas
708
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
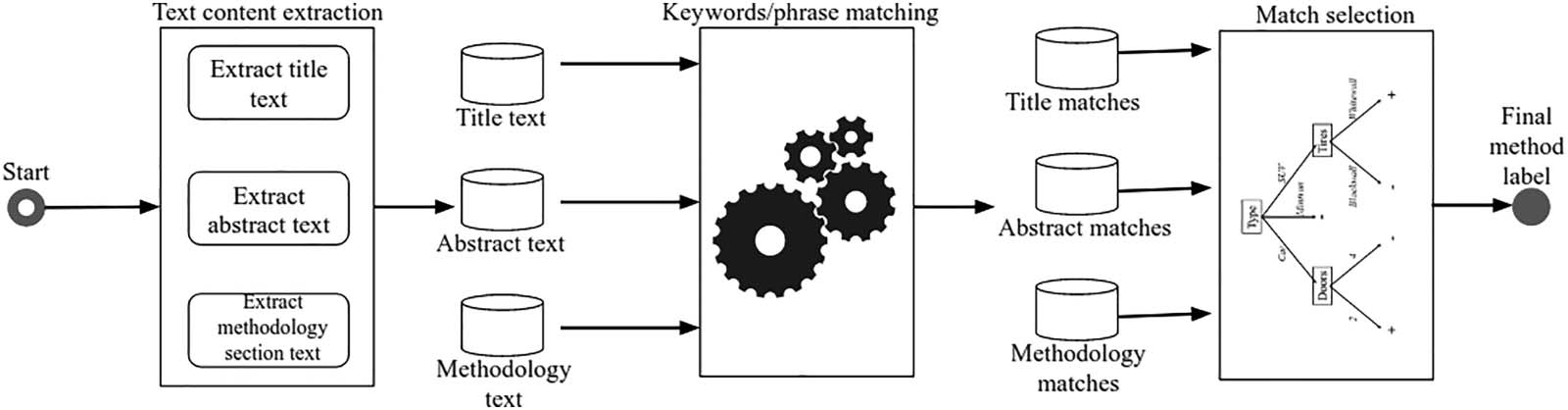
Cifra 1. Overview of the IE method for research method extraction.
methods. Por lo tanto, our aim here is exploring the feasibility and understanding the challenges
in achieving our goal, rather than maximizing the potential performance of the automated
methods.
We used a smaller sample of 30 coded articles to develop the rule-based method, con el
remaining 300 for evaluation later on. Generally, our method searches the keywords (como
explained before) associated with each research method within the restricted sections of an
artículo. The method receiving the highest frequency will be considered to be the main research
method used in that study. As we have discussed previously, many of these keywords can be
ambiguous, but we hypothesize that by restricting our search within specific contexts, como
the abstract or the methodology section, there will be a higher possibility of recovering true
positives. Cifra 1 shows the overall workflow of our method, which will be explained in
detail below.
3.4.1. Text content extraction
In this step, we aim to extract the text content from the parts of an article that are most likely to
mention the research methods used. We focus on three parts: the title of an article, its abstract,
and the methodology section, si está disponible. Titles and abstracts can be directly extracted from
our data set following the XML structures. For methodology sections, we use the same method
introduced before for identifying them.
3.4.2. Keywords/keyphrase matching
In this step, we aim to look up the keywords/keyphrases (to be referred to uniformly as “key-
words” below) associated with each research method within the text elements identified
arriba. For each research method, and for each associated keyword, we count its frequency
within each of the identified text elements. Note that the inflectional forms of these keywords
(p.ej., plural forms) are also searched. Then we sum the frequencies of all matched keywords
for each research method within each text element to obtain a score for that research method
within that text element. We denote this as freq(metro, texti), where m denotes one of the research
methods, texti denotes the text extracted from the part i of the article, with i 2 {título, abstract,
methodsection}.
3.4.3. Match selection
In this step, we aim to determine the main research method used in an article based on the
matches found before. Given the set of matched research methods for a particular type of text
element, eso es, for a set of {freq(m1, texti), freq(m2, texti)…, freq(mk, texti)}, where i is fixed, nosotros
simply choose the method with the highest frequency. Como ejemplo, if “content analysis”
and “interview” have frequencies of 5 y 3, respectivamente, in the abstract of an article, nosotros
Estudios de ciencias cuantitativas
709
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
select “content analysis” to be the method detected from the abstract of that paper. Próximo, nosotros
select the research method based on the following priority: title > abstract > methodology sec-
ción. En otras palabras, if a research method is found in the title, abstract, and methodology sec-
tion of an article, we choose only the one found in the title. Following the example above, si
“content analysis” is the most frequent method based on the abstract of an article, and “ques-
tionnaire” is the one selected for its methodology section, we choose “content analysis” to be
the research method used by the study. If none of the research methods are found in any of the
three text elements, we consider the article to be “theoretical.” If multiple methods are found
to tie based on our method, then the one appearing earlier in the text will be chosen to be the
main method.
3.4.4. Evaluation
Typically, automated methods cannot obtain perfect results as judged by humans and their per-
formance needs to be formally evaluated. De este modo, to understand to what extent we can correctly
identify the research method used by a study, we propose to use the standard Precision, Recordar,
and F1 measures used for classification tasks. Específicamente, these are defined in Eqs. 1, 2, y 3.
Precision ¼
#true positives
#total predicted positives
Recall ¼
#true positives
#total actual positives
F1 ¼ 2 (cid:2)
precisión (cid:2) recordar
precision þ recall
(1)
(2)
(3)
Given a particular type of research method in the data set, the number of research articles
that reported using that method is “total actual positives,” and the number predicted by the IE
method is “total predicted positives.” The intersection of the two is “true positives.” Because the
problem is cast as a classification task, and in line with the work in this direction but in other
disciplines, we treat Precision and Recall with equal weights in computing F1. También, we compute
the “micro” average of Precision, Recordar, and F1 over the entire data set across all research
methods, where the “true positives,” “total predicted positives,” and “total actual positives” will
simply be the sum of the corresponding values for each research method in the data set.
4. FINDINGS
4.1. Recopilación de datos
As mentioned previously, we notice a significant degree of inter- and intrajournal inconsis-
tency in how different journals categorize their articles. We show the details in Table 2.
Primero, there is a lack of definition of these categorization labels from the official sources, y
many of the labels are not self-explanatory. Por ejemplo, it is unclear why fine-grained JASIS&t
labels such as “advances in information science” and “AIS review” deserve to be separate catego-
ries, or what “technical paper” and “secondary article” entail in JDoc. For LISR, which uses
mostly acronym codes to label its articles, we were unable to find a definition of these codes4.
4 All available codes are defined at: https://www.elsevier.com/__data/assets/text_file/0005/275666
/ja5_art550_dtd.txt. Sin embargo, no explanation of these codes can be found. A search on certain Q&A plat-
forms found “FLA” to be “Full Length Article.”
Estudios de ciencias cuantitativas
710
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 2. Different categorizations of published articles by the three different journals
JASIS&t
Research article
JDoc
1837 Research paper
LISR
370
FLA
350
ciencia
Errata
In this issue
Opinion
AIS review
Revisar
Opinion piece
Depth review
Guest editorial
Brief communication
115 Conceptual paper
121
EDI
Letter to the editor
65 Revisar
Editorial
Advances in information
31
31
Secondary article
Revisión de literatura
16 ANN
75
52
research-article
e-review
17 Viewpoint
14 BRV
13
Editorial
Perspectives on design:
12 Case study
information technologies
and creative practice
Opinion paper
10 Article
11
11
8
8
5
3
1
e-non-article
IND
e-conceptual-paper
SCO
EDB
review-article
E-literature review
7 General view
7 Book review
2
Technical paper
1 Guest editorial
1
1
List of referees 2013
1 REV
ERR
PRP
COR
DIS
PUB
40
32
23
12
11
11
7
5
5
3
2
2
2
2
1
1
1
1
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segundo, different journals have used a different set of labels to categorize their articles.
While the three journals appear to include some types that are the same, some of these are
named in different ways (p.ej., “opinion paper” in JASIS&T and “viewpoint” in JDoc). Más
noticeable is the lack of consensus in their categorization labels. Por ejemplo, solo
JASIS&T has “brief communication,” only JDoc has “secondary article,” and only LISR has
“non-article.”
A more troubling issue is the intrajournal inconsistency. Each journal has used a large set of
labels, many of which appear to be redundant. Por ejemplo, in JASIS&t, “opinion paper,"
“opinion,” and “opinion piece” seem to refer to the same type. “Depth review” and “AIS
review” seem to be a part of “review.” In JDoc, “general review” and “book review” seem to
be a part of “review.” And “article” seems to be too broad a category. In LISR, it is unclear
why “e-review” is needed in addition to “review-article.” Also, note that for many categories,
there are only a handful of articles, an indication that those labels may be no longer used, o
were even created in error.
Estudios de ciencias cuantitativas
711
Automated analysis of research methods in library and information science
4.2. Exploratory Analysis
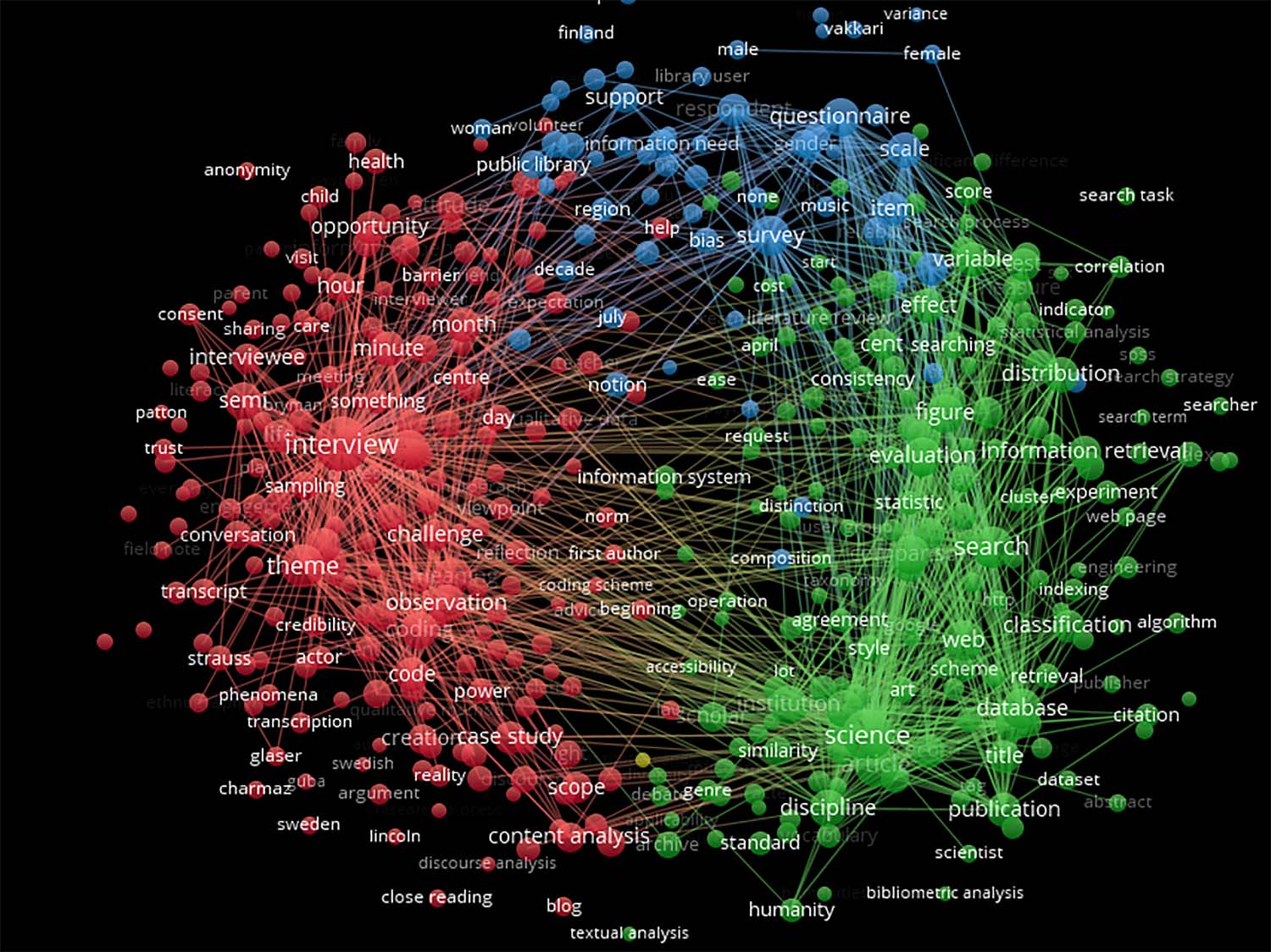
Figures 2–4 visualize the clusters of methodologyrelated keywords found in the articles from
each of the three journals. All three journals show a clear pattern of three separated large clus-
ters. For LISR, three clusters emerge as follows: Uno (verde) centers on “interview,” with key-
words such as “interviewee,” “theme,” and “transcript”; uno (rojo) centers on “questionnaire,"
with keywords such as “survey,” “respondent,” and “scale”; y uno (azul) with miscella-
neous keywords, many of which seem to correlate weakly with studies of scientific literature
(p.ej., keywords such as “author,” “discipline,” and “article”) or bibliometrics generally.
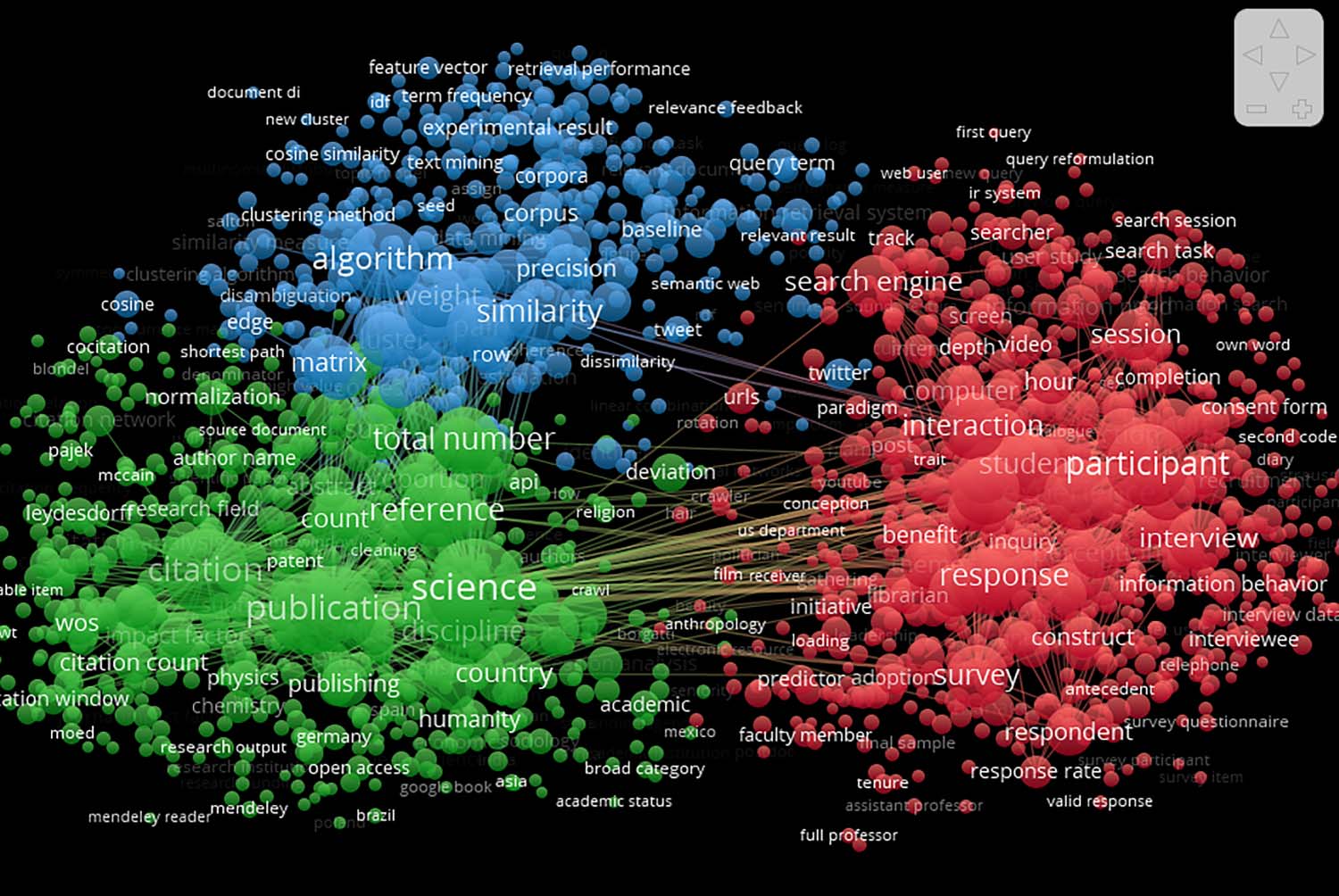
For JDoc, the two clusters around “interview” (verde) and “questionnaire” (azul) are clearly
visible. In contrast to LISR, the third cluster (rojo) features keywords that are often indicative of
statistical methods, algoritmos, and use of experiments. En general, the split of the clusters seems
to indicate the separation of methods that are typically qualitative (green and blue) and quan-
titative (rojo).
The clusters from JASIS&T appear to be more different from LISR and JDoc and also have
clearer boundaries. One cluster (rojo) appears to represent methods based on “interview” and
“survey”; uno (verde) features keywords indicative of bibliometrics studies; y uno (azul) tiene
keywords often seen in studies using statistical methods, experimentos, or algorithms.
Comparing the three journals, we see a similar focus of methodologies between LISR and
JDoc, but quite different patterns in JASIS&t. The latter appears to be more open to quantita-
tive and data science research.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2. Cluster of terms extracted from the LISR corpus (arriba 454 terms ranked by frequency
extracted from the entire corpus of 382 artículos). Size of font indicates frequency of the
keyword.
Estudios de ciencias cuantitativas
712
Automated analysis of research methods in library and information science
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
Cifra 3. Cluster of terms extracted from the JDoc corpus (arriba 451 terms ranked by frequency
extracted from the entire corpus of 381 artículos). Size of font indicates frequency of the keyword.
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4. Cluster of terms extracted from the JASIS&T corpus (arriba 2,027 terms ranked by frequency
extracted from the entire corpus of 1,837 artículos). Font size indicates frequency of the keyword.
Estudios de ciencias cuantitativas
713
Automated analysis of research methods in library and information science
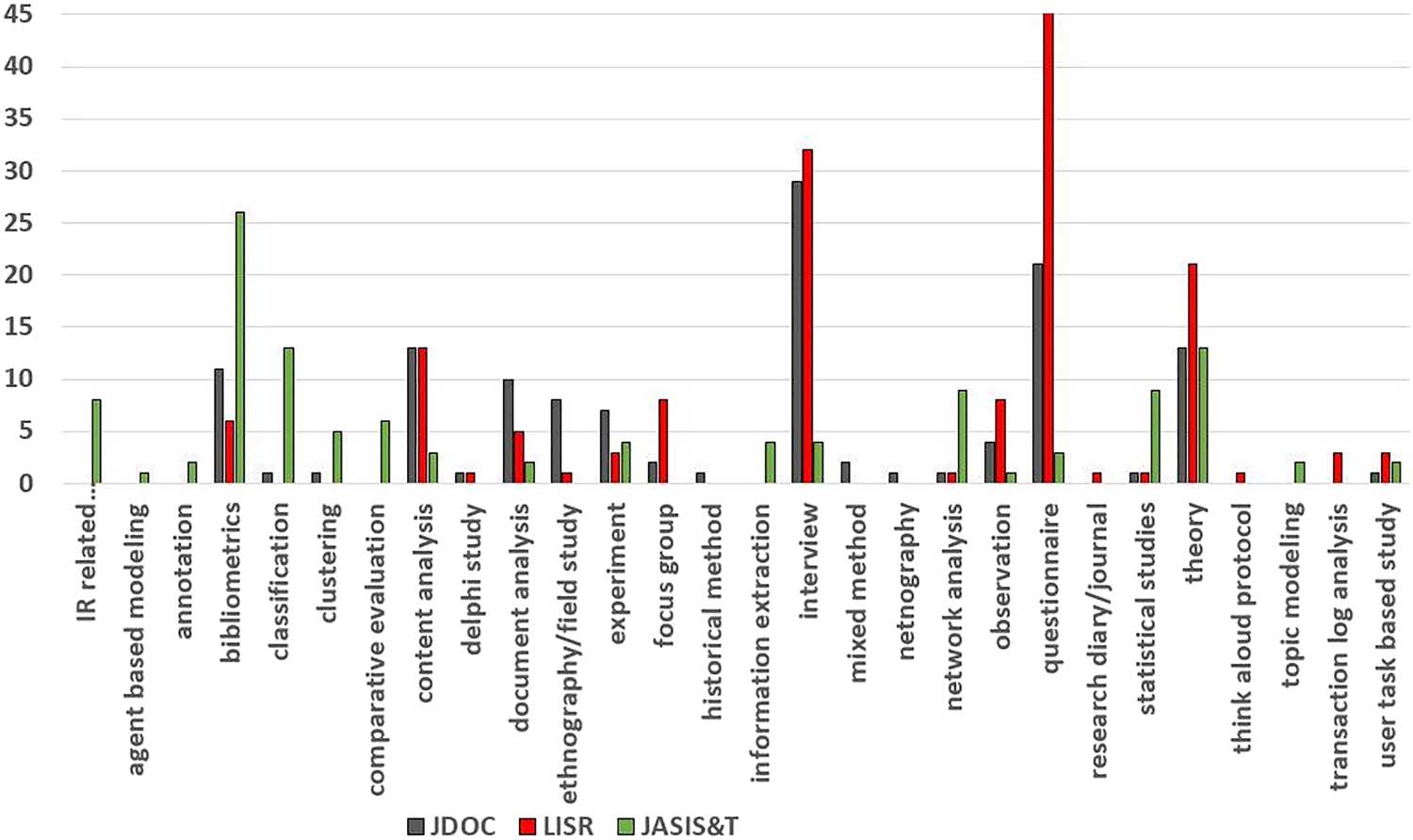
4.3. Classification Scheme
Mesa 3 displays our proposed method classification scheme, together with references to pre-
vious work where appropriate, and keywords that were indicative of the methods. Notice that
some of the keywords are selected based on the clusters derived from the exploratory studies.
También, the keywords are by no means a comprehensive representation of the methods, but only
serve as a starting point for this type of study. In the following we define some of the methods
in detail and explain their connection to the literature.
Our study was able to reuse most of the codes from Chu (2015). We revised Chu’s
“ethnography/field study” to two categories: “ethnography/field study,” which refers to tradi-
tional ethnographic research (p.ej. using participant observation in real world settings), y
“digital ethnography,” referring to the use of ethnographic methods in the digital world, en-
cluding work following Kozinets’ (2010) suggestions for “netnography” as an influential
branch of this work.
The major change we have introduced concerns the “experiment” category. Chu (2015)
argued for a renewed perspective on “experiment,” in the sense that this refers to a broad
range of studies where “new procedures (p.ej., key-phrase extraction), algoritmos (p.ej., buscar
result ranking), or systems (p.ej., digital libraries)” are created and subsequently evaluated. Este
differs from the classic “experimental design” as per Campbell and Stanley (1966). Sin embargo,
we argue that this is an “overgeneralization,” as Chu showed that more than half of the arti-
cles from JASIS&T have used this method. Such a broad category is less useful as it hides the
complex multidisciplinary nature in LIS. Por lo tanto, in our classification, we use “experiment”
to refer to the classic “experimental design” method and introduce a more fine-grained list of
methods that would have been classified as “experiment” by Chu. These include “agent based
modeling/simulation,” “classification,” “clustering,” “information extraction,” “IR related in-
dexing/ranking/query methods,” and “topic modeling,” all of which focus on developing pro-
cedures or algorithms (rather than simple application of such techniques for a different
purpose) that are often subject to systematic evaluation; and “comparative evaluation,” which
focuses on following scientific experimental protocols to systematically compare and evaluate
a set of methods.
Más, we added methods that do not necessarily overlap with Chu’s classification. Para
ejemplo, “annotation” refers to studies that involve users annotating or coding certain content,
with the coding frame or the coded content being the primary output of a study. “Document
analysis” refers to studies that analyze a collection of documents (p.ej., government policy pa-
pers) or media items (p.ej., audio or video data) to discover patterns and insights. “Mixed
methods” is added, as studies such as Grankikov et al. (2020) revealed an upward trend in
the usage of this research method in LIS. Note that in this context, “mixed methods” refers
to Fidel’s (2008) definition, which refers to research that combines data collection in a partic-
ular sequence for some reason, rather than any research that happens to involve multiple
forms of data. “Statistical methods” has a narrow scope encompassing studies of correlation
between variables or hypothesis testing, as well as those that propose metrics to quantify cer-
tain problems. This excludes metrics specifically targeting the bibliometrics domain (p.ej.,
h-index), as the level of complexity and the extent of effort devoted to that area justifies it being
an independent umbrella term that encompasses various statistical metrics. Statistical methods
also exclude generic comparison based on descriptive statistics, which is very common (y
thus can be overgeneralizing) in quantitative research; también, the majority of computational
methods for classification, clustering, or regression are statistical-based in a more general sense.
Finalmente, “user task based studies” refers to systematic methods that involve human users undertaking
Estudios de ciencias cuantitativas
714
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 3.
The proposed research method classification scheme
Método
From Chu (2015)
Relation to previous work
Indicative key-words/phrases5
bibliometría
Same as Chu
content analysis
Same as Chu
impact factor, scientometric,
bibliometric, citation
análisis, h-index…
content analysis, inter coder
fiabilidad, inter annotator
agreement, krippendorff
delphi study
Same as Chu
delphi study
ethnography/
field study
Traditional ethnographic studies
excluding those done in a
digital context (see “digital
ethnography” below).
Hammersley, partícipe
observación, ethnography,
ethnographic, ethnographer…
experimento
Classic experimental studies,
dependent variable,
not the generalized
concept as per Chu.
independent variable,
experimento
focus group
Same as Chu
historical method
Same as Chu
interview
Same as Chu
focus group
historical method
interview, interviewed,
interviewer, interviewee,
interviewing
observación
Same as Chu
observación
cuestionario
Same as Chu
respondent, cuestionario,
survey, Likert, surveyed…
research diary/
Same as Chu
diary study, cultural probe
journal
think aloud protocol
Same as Chu
think aloud
transaction log
Same as Chu
log analysis/technique
análisis
theoretical studies
Same as Chu
webometrics
Same as Chu
Studies that cannot be
classified into any of the
other method categories
webometrics, cybermetrics,
link analysis
Nuevo
agent based
modeling/
simulation
Studies that use computational
modeling methods for the
purpose of simulation
agent model/modeling,
multi-agents
Estudios de ciencias cuantitativas
715
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 3.
(continued )
Método
annotation
Relation to previous work
Studies that focus on using
human users to create
coded data
Indicative key-words/phrases5
annotation, tagging
clasificación
Studies that focus on
clasificación, classify
developing computational
classification techniques
clustering
Studies that focus on
grupo, clustering
comparative
evaluación
developing computational
clustering techniques
Studies that follow systematic
evaluation procedures
to compare different methods
comparative evaluation,
evaluative studies
document analysis
Studies that analyze secondary
document/textual analysis,
información
extraction
document collections
(p.ej., historical policy
documentos, transcripts)
with a critical close reading
Studies that develop
computational methods for the
purpose of extracting structured
information from texts
IR related indexing/
ranking/query
methods
Studies that develop methods
with a goal to improve
search results
mixed method
Fidel (2008)
document review
named entity recognition,
NER, relation extraction
Learning to rank, term
weighting, indexing
método, query expansion,
question answering
cresswell and plano clark,
mixed method
digital ethnography
Studies applying ethnography
digital ethnography,
to the digital context
netnography, netnographic
network analysis
statistical methods
Studies that apply network
theories with a focus to
understand the properties
of social networks
Studies of correlations between
variables, hypothesis testing;
proposing new statistical
metrics that quantify
certain problems other than
bibliometría. This category
excludes comparisons based
on simple descriptive statistics
network analysis/study
correlation, logistic test, prueba t,
chi-square, hypothesis test…
topic modeling
Studies that develop
computational topic
modeling methods
topic model, topic
modelado, LDA
Estudios de ciencias cuantitativas
716
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 3.
(continued )
Método
user task based study
Relation to previous work
Studies that require human
users to carry out certain
tareas (sometimes using a
sistema) to produce data
for further analysis
Indicative key-words/phrases5
user study, user analysis
certain tasks following certain (often different) procesos, with a goal to compare their behaviors
or evaluate the processes.
Revisiting the issue of duplication and overlap often seen in the scope of LIS research
methods discussed before, we use examples to illustrate how our classification should be used
to avoid such an issue. En mesa 4, articles by Zuccala, van Someren, and van Bellen (2014),
Wallace, Gingras, and Duhon (2008), Denning, Soledad, and Ng (2015), and Solomon and
Björk (2012) all study bibliometrics problems, but their main research method is classified dif-
ferently under our scheme. Zuccala et al. (2014) focuses on developing a classifier to automat-
ically categorize sentences in reviews by their scholarly credibility and writing style. El
article studied a problem of bibliometrics nature, and used human coders to annotate training
datos. Sin embargo, its ultimate goal is to develop and evaluate a classifier, as is the focus of the
majority of the text. Por lo tanto, the main research method is considered to be “classification,"
and “annotation” may be considered a secondary research method and “bibliometrics” is
more appropriate as a topic of the study. Wallace et al. (2008) has a similar pattern, dónde
the content is dominated by technical details of how the “network analysis” method is con-
structed and applied to bibliometrics problems. Denning et al. (2015) describes a tool whose
core method is formulating a statistical indicator, which the authors propose to measure book
readability. Thus its main method qualifies under “statistical methods.” Solomon and Björk
(2012) uses descriptive statistics to compare open access journals. By definition, we do not
classify such an approach as “statistical methods.” But it can be argued that the authors used
certain metrics to quantify a specific bibliometrics problem and therefore, we label its main
method as “bibliometrics.” In terms of our very own article, arguably, we consider both “con-
tent analysis” and “classification” as our main methods, and “annotation” as a secondary
method because it serves a purpose for content analysis and creating training data for classi-
fication. “Bibliometrics” is more appropriate as the topic rather than the method we use, ser-
cause our work actually adapts generic methods to bibliometric problems.
Cifra 5 compares the distribution of different research methods found in the samples of the
three journals. We notice several patterns. Primero, compared to JDoc and LISR, work published
at JASIS&T has a clear emphasis on using a wider range of computational methods. Esto es
consistent with findings from Chu (2015). Segundo, JASIS&T also has a substantial focus on
bibliometrics research, which lacks representation in JDoc or LISR. En cambio (the third pattern)
for JDoc and LISR, questionnaire and interview remain the most dominant research methods.
These findings resonate with those from our exploratory analysis. Cuatro, for all three journals,
a noticeable fraction of published work (entre 10% y 18%) is of a theoretical nature,
where no data collection or analysis methods are documented. Finalmente, we could not identify
studies using “webometrics” as methods, but many may qualify under such a topic. Sin embargo,
5 Only up to five examples are shown. For the full list of keywords, see supplementary material in the
appendix.
Estudios de ciencias cuantitativas
717
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 4.
Example articles and how their main research method will be coded under our scheme
Article
A machine-learning approach to coding book reviews
as quality indicators: Toward a theory of megacitation
Reference
Zuccala et al. (2014)
Main method
Classification
A new approach for detecting scientific specialties
Wallace et al. (2008)
Network analysis
from raw cocitation networks
A readability level prediction tool for K-12 books
Denning et al. (2015)
Statistical methods
A study of open access journals using article
Solomon and Björk (2012)
Bibliometrics
processing charges
they often use other methods (p.ej., content analysis of web collections, annotation of web
contenido) to study a webometrics problem.
4.4.
Information Extraction of Research Methods
We evaluate our IE method using 300 articles from the coded sample data6 (disjoint with the
smaller set for developing the method), and present the Precision, Recall and F1 scores below.
As mentioned before, we only evaluate the main method extracted by the IE process using
Eqs. 1–3. We then show the common errors made by our method.
4.4.1. Overview of Precision, Recordar, and F1
Mesa 5 shows the Precision, Recall and F1 of our IE method obtained on the annotated sam-
ples from the three journals. En general, the results show that the task is a very challenging one, como
our method has obtained rather poor results on most of the research methods. Across the dif-
ferent journals and considering the size of the sample, our method has generally performed
consistently on “interview,” “questionnaire,” and “bibliometrics.” Based on the nature of our
método (es decir., keywords lookup), this suggests that terminologies related to these research
methods may be used more often in nonambiguous contexts. The average performance of
our IE method achieves a microaverage F1 of 0.783 on JDoc, 0.811 on LISR, y 0.61 en
JASIS&t. State-of-the-art methods on key-insights extraction generally achieve an F1 of be-
entre 0.03 (lin, Ng et al., 2010) y 0.53 (Kovac(cid:1)evic(cid:3), Konjovic(cid:3) et al., 2012) on tasks related
to “research methods” at either sentence or phrase levels. Notice that the figures should not be
compared directly as-is, because the task we deal with is different: We aim to identify specific
methods, whereas all the previous studies only aim to determine whether a specific piece of text
describes a research method or not.
4.4.2.
Impact of the article of abstract
We conducted further analysis to investigate the quality of abstracts and its impact on our IE
método. This includes three types of analysis. To begin with, we disabled the “methodology
section” extraction component in our method, and retested our method on the same data set,
but excluded articles where methods can only be identified from the methodology section.
Los resultados se muestran en la tabla. 6. De término medio, we obtained noticeable improvement on the
6 Data can be downloaded at https://doi.org/10.5281/zenodo.4486156.
Estudios de ciencias cuantitativas
718
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Cifra 5. Distribution of research methods found in the samples of the three journals. The y-axis
indicates percentages represented by a method within a specific journal collection.
JDoc data set, but not on LISR or JASIS&t. Among the three journals, JDoc is the only one that
enforces a structured abstract. Arguably, this ensures consistency and quality in writing the
abstracts, from which our IE methods may have potentially benefited.
To verify this, we conducted the second type of analysis. We asked coders to revisit the
articles they coded and identify the percentage of articles for which they were unable to iden-
tify its main method confidently without going to the full texts. This provides an alternative but
more direct view of the quality of abstracts from the three journals, without the bias from the IE
método. The figures are 5%, 6%, y 12% for JASIS&t, JDoc, and LISR respectively. Este
shows that to a human reader, relativamente, both JDoc and JASIS&T abstracts are more
explicit than LISR when it comes to explaining their methods. This may be an indication of
better quality abstracts. To some extent, this is consistent with the pattern we observed from
the previous analysis. The quality in JASIS&T abstracts does not translate to better performance
of our IE method when focusing on only the abstracts. This could be partially attributed to the
wider diversity of methods noted in JASIS&T articles (Cifra 5) as well as the implicitness in the
description of many of those methods that deviate from LISR and JDoc. Por ejemplo, none of
the articles using “comparative evaluation” used the keywords shown in Table 3. En cambio, ellos
used generic words that, if included, could have significantly increased false positives (p.ej.,
“compare” and “evaluate” are typically used but will be nondiscriminative to identify studies
that solely focus on comparative evaluations). Similarmente, only one article using “user based task
studies” used our proposed keywords. We will cover this issue again in the later sections.
Our third type of analysis involves studying the association between the length of an ab-
stract and its quality, and subsequently (and potentially) its impact on our IE method. We no-
tice that the three journals have different requirements on the length of abstract: 150 for LISR,
250 for JDoc, y 200 for JASIS&t. We do not make hypothesis a correlation between an
abstract’s length and its clarity (hence affecting its quality), as this can be argued from contra-
dictory angles. Por un lado, one may argue that a shorter length can force authors to be
Estudios de ciencias cuantitativas
719
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 5.
does our method predict that method for any articles. For the absolute number of instances for each method, ver figura 5
Precision (PAG), Recordar (R) and F1 on the three journals. “–” indicates that no articles are classified under method by the coders; neither
F1
PAG
F1
PAG
JASIS&t
R
Método
Methods from Chu (2015)
bibliometría
content analysis
delphi study
ethnography/field study
experimento
focus group
historical method
interview
observación
cuestionario
research diary/journal
think aloud protocol
transaction log analysis
webometric
PAG
0.917
0.857
0
0.875
1.00
0.500
1.00
0.793
0.375
0.600
–
–
–
–
JDoc
R
1.00
0.462
0
0.875
0.714
0.500
1.00
0.821
1.00
0.750
–
–
–
–
LISR
R
0.833
0.462
1.00
1.00
0.667
0.750
––
0.781
0.500
0.915
0
1.00
0.462
1.00
0.250
0.400
0.667
––
0.735
0.444
0.827
0
0.909
0.462
1.00
0.400
0.500
0.706
––
0.758
0.471
0.869
0
0.250
1.00
0.400
0
–
0
–
0
–
0.957
0.600
0
0.875
0.833
0.500
1.00
0.807
0.545
0.667
–
–
–
–
F1
0.846
0.571
––
––
0.846
0.500
––
––
0.846
0.667
––
––
0.071
0.250
0.111
––
––
––
––
––
––
1.00
0.500
0.667
0
0
0
0.333
0.667
0.444
–
–
–
–
–
–
–
–
–
–
–
–
theoretical studies
0.310
0.923
0.462
0.474
0.857
0.610
0.476
0.769
0.588
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
Nuevo
agent based modeling
annotation
clasificación
clustering
comparative evaluation
–
–
–
–
–
–
0.143
1.00
0.250
0
–
0
–
0
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
document analysis
1.00
0.200
0.333
1.00
0.600
0.750
information extraction
IR related indexing/ranking/
query methods
–
–
–
–
–
–
mixed method
0.667
1.000
0.800
digital ethnography
1.00
1.00
1.00
–
–
–
–
–
–
–
–
–
–
–
–
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
1.00
1.00
1.00
0
0.467
0.833
0
0
1.00
0.67
–
–
0
0.583
1.00
0
0
0
0.519
0.909
0
0
0.250
0.25
0.400
0.363
–
–
–
–
network analysis
0
0
0
1.00
1.00
1.00
0.750
0.333
0.462
Estudios de ciencias cuantitativas
720
Automated analysis of research methods in library and information science
Mesa 5.
(continued )
Método
statistical methods
topic modeling
user task based study
AVERAGE7
PAG
–
0
0
JDoc
R
–
0
0
F1
–
0
0
PAG
0.167
–
0
LISR
R
1.00
–
0
F1
0.286
–
0
PAG
0.500
1.00
1.00
0.783
0.783
0.783
0.811
0.811
0.811
0.610
JASIS&t
R
0.444
0.500
0.500
0.610
F1
0.471
0.667
0.667
0.610
more explicit about their methodology; Por un lado, one could also argue that a shorter
length may result in more ambiguity, as authors have little space to explain their approach
clearly. En cambio, we started with analyzing the distribution of abstract length in our data sets
across the three journals. We wrote a program that counts the number of words in each ab-
stract, where words are delimited by white space characters only. We made surprising find-
ings, as shown in Figure 6: a very large proportion of articles did not comply with the limit of
the abstract length.
Cifra 6 suggests that at least 50% of articles in our JASIS&T and LISR data sets have ex-
ceeded the abstract word limits. The situation of JDoc is not very much better. Across all three
journals, there are also very long abstracts that almost doubled the word limit8; and there are
noticeable articles with very short abstracts, such as those containing fewer than 100 palabras: 1
for JDoc, 34 for LISR, y 14 for JASIS&t. En general, we do not see significantly different patterns
in the distributions across the three journals. We further manually inspected a sample of 20
articles from each journal to investigate whether there were any patterns in terms of the pub-
lication year of those articles that exceeded the word limit. This is because we were uncertain
whether during the abstract word limit changed during the history of each journal. De nuevo, nosotros
could not find any consistent patterns. For JDoc, the distributions are 2010 (3), 2011 (3), 2013
(4), 2014 (1), 2015 (2), 2016 (2), 2017 (2), y 2018 (3). For LISR, the distributions are 2010
(5), 2011 (1), 2012 (4), 2013 (2), 2014 (1), 2015 (4), 2016 (2), y 2018 (1). For JASIS&t, el
distributions are 2010 (3), 2011 (4), 2012 (2), 2013 (1), 2014 (4), 2015 (2), 2016 (1), 2017 (2),
y 2018 (1). Articles exceeding the abstract length limit can be found in any year in all three
journals. For these reasons, we argue that there is no strong evidence indicating any associa-
tion between the abstract length and its impact on our IE method. Sin embargo, the lack of com-
pliance with the journal requirement is rather concerning. While the quality of abstracts may
be a factor that affects our method, it is worth noting that our method for detecting the meth-
odology section has its limitations. Some articles do not have an explicit “methodology” sec-
ción. En cambio, they may describe different parts of their method in several top-level sections
(p.ej., see Saarikoski, Laurikkala et al., 2009). Some may have a “methodology” section that
is a subsection of the top-level sections (p.ej., the method section is within the “Case Study”
section in Freeburg, 2017). A manual inspection of 50 annotated samples revealed that there
eran 10% of articles on which this method failed to identify the methodology section. En otra
palabras, the method has a 10% error rate. Thus arguably, with a more reliable method for
7 Average P, R, and F1 are identical because we are evaluating micro-average over all classes. Also the method
predicts only one class for each article; therefore in Eqs. 1 y 2, #total predicted positives = #total actual
positives = #articles in the collection.
8 Examples: 10.1108/JD-10-2012-0138, 10.1108/00220410810912415, 10.1002/asi.21694.
Estudios de ciencias cuantitativas
721
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Precision (PAG), Recordar (R) and F1 on the three journals when the text from the methodology section (si está disponible) is ignored. “–”
Mesa 6.
indicates that no articles are classified under method by the coders, and neither does our method predict that method for any articles. Bold
indicates better results whereas underline indicates worse results compared to Table 4. For the absolute number of instances for each method,
ver figura 5
Método
Methods from Chu (2015)
PAG
JDoc
R
F1
PAG
F1
PAG
JASIS&t
R
bibliometría
0.917
1.00
content analysis
1.00
0.462
delphi study
ethnography/field study
experimento
focus group
historical method
interview
observación
cuestionario
research diary/journal
think aloud protocol
transaction log analysis
webometric
0
0.875
1.00
0.500
1.00
0.821
0.429
0.600
–
–
–
–
0
0.875
0.714
0.500
1.00
0.821
1.00
0.750
–
–
–
–
0.957
0.632
0
0.875
0.833
0.500
1.00
0.821
0.600
0.667
–
–
–
–
LISR
R
0.833
0.363
1.00
1.00
0.500
0.833
–
0.766
0.429
0.891
0
1.00
0.444
1.00
0.250
1.00
0.833
–
0.885
0.600
0.891
0
0.909
0.400
1.00
0.400
0.667
0.833
–
0.821
0.500
0.891
0
0.500
1.00
0.667
0
–
0
–
0
–
F1
0.846
0.571
–
–
0.846
0.500
0.846
0.667
–
–
–
–
0.071
0.250
0.111
–
–
–
–
–
–
1.00
0.500
0.667
0
0
0
0.333
0.667
0.444
–
–
–
–
–
–
–
–
–
–
–
–
theoretical studies
0.324
0.923
0.480
0.457
0.889
0.604
0.476
0.769
0.588
Nuevo
agent based modeling
annotation
clasificación
clustering
comparative evaluation
–
–
–
–
–
–
0.167
1.00
0.286
0
–
0
–
0
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
document analysis
1.00
0.286
0.444
1.00
0.500
0.667
information extraction
IR related indexing/ranking
/query methods
–
–
–
–
–
–
mixed method
0.667
1.000
0.800
digital ethnography
1.00
1.00
1.00
–
–
–
–
–
–
–
–
–
–
–
–
1.00
1.00
1.00
0
0.467
0.833
0
0
1.00
0.67
–
–
0
0.583
1.00
0
0
0
0.519
0.909
0
0
0.250
0.25
0.400
0.363
–
–
–
–
Estudios de ciencias cuantitativas
722
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Mesa 6.
(continued )
Método
network analysis
statistical methods
topic modeling
user task based study
PAG
1.00
0
–
0
JDoc
R
1.00
0
–
0
F1
1.00
0
–
0
PAG
1.00
0.167
–
0
LISR
R
1.00
1.00
–
0
F1
1.00
0.286
–
0
PAG
0.750
0.500
1.00
1.00
AVERAGE
0.804
0.804
0.804
0.812
0.812
0.812
0.610
JASIS&t
R
0.333
0.444
0.500
0.500
0.610
F1
0.462
0.471
0.667
0.667
0.610
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 6. Distribution of abstract length across the three different journals.
finding methodology sections or generally content sections that describe methodology, our IE
method could perform better.
4.4.3. Error analysis
To further understand the challenges of this task, we analyzed all errors made by our IE method
and explain these below. Of the errors, 67%9 are due to keywords used in different contexts
than expected. Por ejemplo, we define “classification” to be methods that use computational
approaches for classifying data. Sin embargo, the keywords “classify” or “classification” are also
used frequently in work that may use, Por ejemplo, content analysis or document analysis, a
study library classification systems. A frequent error of this type is when a method is mentioned
as future or previous work, such as in “In future studies, p.ej., families’ focus-group interviews
could bring new insights.” Some 10% of errors are due to ambiguity of the keywords them-
selves. Por ejemplo, “bibliometrics” was identified as the wrong research method from the
sentence “This paper combines practices emerging in the arts and humanities with research
evaluation from a scientometric perspective…”. Otro 33% of errors are due to the lack of
keywords, or when a method is mentioned implicitly and can only be inferred from reading the
contexto. As examples, we discussed “comparative evaluation” and “user based task studies”
antes. More examples include “information extraction,” which is a very broad topic and can
be difficult to include all possible keywords; and “document analysis,” which is particularly
9 More than one error category can be associated with each article.
Estudios de ciencias cuantitativas
723
Automated analysis of research methods in library and information science
difficult to capture because researchers rarely use distinctive keywords to describe their study.
In all these cases, a lot of inference with background knowledge is required.
5. DISCUSIÓN
We discuss the lessons learned from this work with respect to our research questions, también
as limitations of our work.
5.1. Research Method Classification
Our first research question concerns the evolution of “research methods” in LIS. We summa-
rize three key points below.
Primero, following a deductive coding process informed by literature as well as our data anal-
ysis, we developed a classification scheme that largely extends that of Chu (2015). In partic-
ular, we refined Chu’s “experiment” category to include a range of methods that are based on
computational approaches, used in the creation of procedures, algoritmos, or systems. Estos
are often found in work belonging to the “new frontier” of LIS (es decir., those that often cross
boundaries with other disciplines, such as information retrieval, data mining, human computer
interacción, and information systems). We also added new categories that were not included in
the existing classification schemes by earlier studies. En general, we believe that our significantly
wider classification scheme indicates the increasing trend of diversification and interdisciplin-
ary research in LIS. This could be seen as a strength in terms of LIS drawing fruitfully on a wide
range of fields and influences, from humanities, social science, and science. It does not suggest
a field moving towards the mature position of paradigmatic consensus, but it could be seen to
reflect a healthy dynamism. More troubling might be considered the extent to which novelty
comes largely from computational methods, suggesting a discipline without a long history of
development and whose direction is subordinate to that of another.
Segundo, coming with this widening scope is the increasing complexity in defining “research
methods.” While our proposed classification scheme remains a flat structure, as is the case for
the majority of studies in this area, we acknowledge that the LIS community may benefit from a
hierarchical classification that reflects different perspectives of research methodology.
Sin embargo, as we have discussed in extended depth earlier on, it has been difficult to achieve
consensus, simply because researchers in different traditions view methodology differently and
use terminology differently. Although it was not an aim of this study, we anticipate that this can
be partially addressed by developing a framework for defining and classifying LIS research
methods from multiple, complementary perspectives. Por ejemplo, a study should have a
topic (p.ej., “bibliometrics” could be both a method and topic), could use certain modes of
analysis and data collection methods (resonating with the “research strategy” and “data collection
method” model by Järvelin and Vakkari (1990)), and adopt a certain methodological stance (p.ej.,
mixedmethods, multimethods, quantitative) based on the mode of analysis (resonating with that
by Hider and Pymm (2008)).
Sin embargo, there exist significant hurdles to achieve this goal. As suggested by Risso (2016),
LIS needs to disambiguate and clearly define different categories of “methods” (p.ej., to address
issues such as “citation analysis” being treated as both research strategy and data collection
method in Järvelin and Vakkari (1990)). Más, there is a need to regularly update the
framework to accommodate the evolution of the LIS discipline (Ferran-Ferrer et al., 2017).
Para esto, automated IE methods may be useful in coping with the growing amount of literature.
También, significant effort needs to be devoted to encourage the adoption of such standards. Last,
but not least, researchers should be encouraged to share their coding frame and the data
Estudios de ciencias cuantitativas
724
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
they coded as examples for future reference. Data sharing has been an obvious gap in LIS
research on research methods, compared to other disciplines such as Computer Science and
Biomedicine.
Tercero, there is a clear pattern of different methodological emphasis in the articles published
by the three different journals. While JDoc and LISR appear to publish more work that uses
“conventional” LIS research methods, JASIS&T appears to be more open to accepting work
that uses a diverse range of methods that have an experimental nature and seen more common
in other disciplines. This pattern may reflect the different scope of focus of these journals. Para
ejemplo, LISR explicitly states that it “does not normally publish technical information science
studies … or most bibliometric studies,” whereas JASIS&T “focuses on the production, …,
usar, and evaluation of information and on the tools and techniques associated with these pro-
cesses.” However, JDoc’s scope description is less indicative of the methodological emphasis,
as it states “… welcome submissions exploring topics where concepts and models in the library
and information sciences overlap with those in cognate disciplines.” This difference in terms of
their scope and aims had an impact on our exploratory analysis and, por lo tanto, our resulting clas-
sification scheme. Sin embargo, this should not be considered a limitation of our approach. If an LIS
journal expands its scope to cover such a diverse range of fields, then we argue there is a need to
develop a more fine-grained classification that better reflects this trend.
5.2. Automated Extraction of Research Methods
Our IE method for detecting the research methods used in a study is the first in LIS. Similar to
earlier studies on key-insight extraction from scientific literature, we found this task particularly
challenging. Although our method is based on simple rules, we believe it is still representative
of the state of the art. This is because, Por un lado, its average performance over all
methods is comparable to figures previously reported in similar tasks, even if our task is argu-
ably more difficult. Por otro lado, research so far cannot show a clear advantage of more
complex methods such as machine learning over rule-based ones. The typical errors we found
from our method will be equally challenging for typical machine learning-based methods.
En general, our method achieved reasonable performance on only a few methods (es decir., “inter-
vista,” “questionnaire,” and “bibliometrics”), whereas its performance on most methods is rather
unsatisfactory. Compared to work in a similar direction from other disciplines, we argue that
research on IE of research methods from the LIS literature will need to consider unique chal-
lentes. The first is the unique requirement of the task. As we discussed before, existing IE
methods in this area only aim to identify the sentence or phrase that mentions a method
(es decir., oración- or phrase-level of extraction), but not to recognize the actual method used.
This is not very useful when our goal is to understand the actual method adopted by a study,
which may mention other methods for the purposes of comparison, discussion, and references.
This implies a formulation of the task beyond the “syntactic” level to the “semantic” level,
where the automated IE method needs not only to identify mentions of methods in text, pero
also to understand the context in which they appear to derive their meanings (p.ej., recall the
examples we have shown in the error analysis section).
Adding to the above (es decir., the second challenge) is the complexity in defining and classifying
LIS “research methods,” as we have discussed in the previous section. The need for taking a
multiperspective view and identifying not only the main but also secondary methods only escalates
the level of difficulty for IE. También, there is the lack of standard terminology to describe LIS methods.
Por ejemplo, from our own process of eliciting research methods, we discovered methods that
are difficult to identify by keywords, such as “mixed methods” and “document analysis.”
Estudios de ciencias cuantitativas
725
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
Finalmente, researchers may need to cope with varying degrees of quality in research article
abstracts. This is particularly important because, as we have shown, our method can benefit
from well-structured abstracts. In Computer Science for example, IE of research methods has
mostly focused on abstracts (Augenstein et al., 2017) because they are generally deemed to be
of high quality and information rich. In the LIS domain, sin embargo, we have noticed issues such
as how journal publishers differ in terms of enforcing structured abstracts, and that not every
study would clearly describe their method in the abstracts (Ferran-Ferrer et al., 2017).
All these challenges mean that feature engineering—a crucial step for IE of research
methods from texts—will be very challenging in the LIS discipline. We discuss some possibil-
ities that may partially address this in the following section.
5.3. Other Issues
During our data collection and analysis, we discovered issues with how journal publishers
categorize their articles. We have shown an extensive degree of intra- and interjournal incon-
sistency, as well as a lack of guidance on how to interpret these categories. This undoubtedly
created difficulties for our data collection process and potential uncertainties in the quality of
our data set, and will remain an obstacle for future research in this area. We therefore urge the
journal publishers to be more transparent about their article categorization system, y para
work on improving the quality of their categorization. It might also be useful for publishers
to offer common guidelines on describing methods in abstracts and to prompt peer reviewers
to examine keywords and abstracts with this in mind.
Our further analysis of the abstract lengths showed a significant extent of noncompliance,
as many articles (alrededor, or even exceeding, 50%) are published with an abstract exceeding
the word limit, and a small number of articles had a very short abstract. While we were unable
to confirm the association between the length of the abstracts and the performance of our IE
método, such inconsistency could arguably be considered as a quality issue for the journal.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
5.4. Limitations of This Study
Primero, our proposed classification scheme remains a flat structure, and as we discussed above, él
may need to be further developed into a hierarchy to better reflect different perspectives on
research methods. Some may also argue that our classification diverges from the core research
methods used in LIS. Due to the multidisciplinary nature of LIS, do we really need to integrate
method classifications that conventionally belong to other disciplines? Would it be better to
simply use the classification schemes from those disciplines when a study crosses those dis-
ciplines? These are the questions that we do not have answers to but deserve a debate given
the multidisciplinary trend in LIS.
Segundo, our automated IE method for extracting research methods has large room for improve-
mento. Similar to the previous work on key-insight extraction, we have taken a classification-
based approach. Our method is based on keyword lookup, which is prone to ambiguity due
to both context and terminology, as we have discussed. Como resultado, its performance is still
unsatisfactory. We envisage an alternative approach to be sentence- or paragraph-level classifi-
cation that focuses on sentences or paragraphs from certain areas of a paper only, como
abstracts or the methodology section, when available. The idea is that sentences or paragraphs
from such content may describe the method used and, compared to simple keywords lookup,
provide additional context for interpretation. Sin embargo, this creates a significant challenge for
data annotation, because machine learning methods require a large amount of examples
Estudios de ciencias cuantitativas
726
Automated analysis of research methods in library and information science
(training data) to learn from, and for this particular task there will be a very large number of
categories that need examples. We therefore urge researchers in LIS to make a collective effort
towards data annotation, sharing, and reuse.
También, our IE method only targets a single, main research method from each article.
Detecting multiple research methods may be necessary but will be even more challenging,
as features that are usually effective for detecting single methods (p.ej., frequency) will be un-
confiable, and it requires a more advanced level of “comprehension” by the automated method.
Además, existing IE methods only identify the research methods themselves but overlook
other parameters of the methods that may also be very interesting. Por ejemplo, new re-
searchers to LIS may want to know what a reasonable sample size is when a questionnaire
se utiliza, whether the sample size has an impact on citation statistics, or what methods are often
“mixed” in a mixed method research. Addressing these issues will be beneficial to the LIS re-
search community, but remains a significant challenge to be tackled in the future.
Finalmente, our work has focused on the LIS discipline. Although this offers unique value com-
pared to the existing work on IE of research methods predominantly covering Computer
Science and Biomedicine, the question remains as to how the method can generalize to other
social science disciplines or humanities. Por ejemplo, our study shows that among the three
journals, entre 13% y 21% of articles are theoretical studies (Cifra 5). Sin embargo,
methods commonly used in the humanities (p.ej., hermeneutics) would not be described in
a manner like empirical studies in LIS. This means that our IE method, if applied to this disci-
pline, can misclassify some studies that use traditional humanities methods as nonempirical,
even though their authors might consider them to be empirical. Sin embargo, LIS is marked by
considerable innovation in methods. This reflects wider pressures for more interdisciplinary
studies to address complex social problems as well as individual researchers’ motives to inno-
vate in methods to achieve novelty. These factors are by no means confined to LIS. We can
anticipate that these factors will make the classification of methods in soft and applied disci-
plines equally challenging. Por lo tanto, something may be learned from this study by those
working in other fields.
6. CONCLUSIÓN
The field of LIS is becoming increasingly interdisciplinary as we see a growing number of
publications that draw on theory and methods from other subject areas. This leads to
increasingly diverse research methods reported in this field. A deep understanding of these
methods would be of crucial interest to researchers, especially those who are new to this
campo. While there have been studies of research methods in LIS in the past, there is a lack of
consensus in the classification and definition of research methods in LIS, and nonexistence
of studies of automated analysis of research methods reported in the literature. The latter has
been recognized as of paramount importance and has attracted significant effort in fields that
have witnessed significant growth of scientific literature, a situation that LIS is also undergoing.
Set in this context, this work analyzed a large collection of LIS literature published in three
representative journals to develop a renewed perspective of research method classification in
LIS, and to carry out an exploratory study into automated methods—to the best of our knowl-
borde, the first of this nature in LIS—for analyzing the research methods reported in scientific
publicaciones. We discovered critical insights that are likely to impact the future studies of re-
search methods in this field.
In terms of research method classification, we showed a widening scope of research meth-
odology in LIS, as we see a substantial number of studies that cross disciplines such as
Estudios de ciencias cuantitativas
727
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
information retrieval, data mining, human computer interaction, and information systems. El
implications are twofold. Primero, conventional methodology classifications defined by the pre-
vious work can be too broad, as certain methodological categories (p.ej., “experiment”) would
include a significant number of studies and are too generic to differentiate them. Segundo, allá
is the increasing complexity of defining “research method,” which necessitates a hierarchically
structured classification scheme that reflects different perspectives of research methodology
(p.ej., data collection method, analysis method, and methodological stance). Además,
we also showed that different journals appear to have a different methodological focus, con
JASIS&T being the most open to studies that are more quantitative, or algorithm and experi-
ment based.
In terms of the automated method for method analysis, we tackled the task of identifying
specific research methods used in a study, one that is novel compared to the previous work in
other fields. Our method is based on simple rule-based keyword lookup, and worked well for a
small number of research methods. Sin embargo, en general, the task remains extremely challenging
for recognizing the majority of research methods. The reasons are mainly due to language
ambiguity, which results in challenges in feature engineering. Our data are publicly available
and will encourage further studies in this direction.
Más, our data collection process revealed data quality issues reflecting an extensive de-
gree of intra- and interjournal inconsistency with regards to how journal publishers organize
their articles when making their data available for research. This data quality issue can dis-
courage interest and effort in studies of research methods in the LIS field. We therefore urge
journal publishers to address these issues by making their article categorization system more
transparent and consistent among themselves.
Our future work will focus on a number of directions. Primero, we aim to progress towards
developing a hierarchical, structured method classification scheme reflecting different per-
spectives in LIS. This will address the limitations of our current, flat method classification
scheme proposed in this work. Segundo, as discussed before, we aim to further develop our
automated method by incorporating more complex features that may improve its accuracy
and enabling it to capture other aspects of research methods, such as the data sets involved
and their quantity.
CONTRIBUCIONES DE AUTOR
Ziqi Zhang: Conceptualización, Curación de datos, Análisis formal, Investigación, Metodología,
Administración de proyecto, Software, Visualización, Escritura: borrador original. Winnie Tam:
Conceptualización, Curación de datos, Análisis formal, Investigación, Metodología, Software,
Visualización, Escritura: revisión & edición. Andrew Cox: Conceptualización, Curación de datos,
Análisis formal, Investigación, Metodología, Supervisión, Escritura: revisión & edición.
CONFLICTO DE INTERESES
Los autores no tienen intereses en competencia.
INFORMACIÓN DE FINANCIACIÓN
No funding was received for this research.
Estudios de ciencias cuantitativas
728
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
DISPONIBILIDAD DE DATOS
The data are available at Zenodo (https://doi.org/10.5281/zenodo.4486156).
REFERENCIAS
Alam, h., Kumar, A., Werner, T., & Vyas, METRO. (2017). Are cited ref-
erences meaningful? Measuring semantic relatedness in citation
análisis. In BIRNDL@SIGIR (volumen. 1888, páginas. 113–118).
Augenstein, I., El, METRO., Riedel, S., Vikraman, l., & McCallum, A.
(2017). SemEval 2017 Tarea 10: ScienceIE—Extracting
Keyphrases and Relations from Scientific Publications. En
Proceedings of the 11th International Workshop on Semantic
Evaluation (SemEval-2017) (páginas. 546–555). DOI: https://doi.org
/10.18653/v1/S17-2091
Bernhard, PAG. (1993). In search of research methods used in informa-
tion science. Canadian Journal of Information and Library
Ciencia, 18(3), 1–35.
Blake, V. (1994). Since Shaughnessy: Research methods in library
and information science dissertation, 1975–1989. Collection
Desarrollo, 19(1/2), 1–42. DOI: https://doi.org/10.1300
/J105v19n01_01
Campbell, D., & Stanley, j. (1966). Experimental and quasi-experimental
designs for research. chicago, IL: Rand McNally.
Chen, y., Liu, y., & A, W.. (2013). A text mining approach to
assist the general public in the retrieval of legal documents.
Journal of the American Society for Information Science and
Tecnología, 64(2), 280–290. DOI: https://doi.org/10.1002/asi
.22767
Chiticariu, l., li, y., & Reiss, F. (2013). Rule-based information ex-
traction is dead! Long live rule-based information extraction sys-
tems! En Actas de la 2013 Conferencia sobre Empirismo
Métodos en el procesamiento del lenguaje natural (páginas. 827–832).
Asociación de Lingüística Computacional.
Chu, h. (2015). Research methods in library and information science:
A content analysis. Library and Information Science Research, 37,
36–41. DOI: https://doi.org/10.1016/j.lisr.2014.09.003
Cortez, MI., da Silva, A., Goncalves, METRO., Mesquita, F., & de Moura,
mi. (2007). FLUX-CiM: Fexible unsupervised extraction of citation
metadata. In Proceedings of the 7th ACM/IEEE Joint Conference
on Digital Libraries (páginas. 215–224). DOI: https://doi.org/10.1145
/1255175.1255219
Dayrell, C., Candido, A., Lima, GRAMO., Machado, D., Copestake, A.,
Feltrim, v., & Aluísio, S. (2012). Rhetorical move detection in
English abstracts: Multi-label sentence classifiers and their annotated
corpus. In Proceedings of the Eighth International Conference on
Language Resources and Evaluation (páginas. 1604–1609).
Denning, J., Soledad, METRO., & Ng, PAG. (2015). A readability level pre-
diction tool for K–12 books. Journal of the American Society for
Information Science and Technology, 67(3), 550–565. DOI:
https://doi.org/10.1002/asi.23417
Durrant, GRAMO. (2004): A typology of research methods within the so-
cial sciences. NCRM Working Paper Series, páginas. 1–22.
Ferran-Ferrer, NORTE., Guallar, J., Abadal, MI., & Server, A. (2017).
Research methods and techniques in Spanish library and infor-
mation science journals (2012–2014). Information Research,
22(1), 741.
Fidel, R. (2008). Are we there yet?: Mixed methods research in
library and information science. Library & Information Science
Investigación, 30, 265–272. DOI: https://doi.org/10.1016/j.lisr
.2008.04.001
Freeburg, D. (2017). A knowledge lens for information literacy:
Conceptual framework and case study. Journal of Documentation,
73(5), 974–991. DOI: https://doi.org/10.1108/JD-04-2017-0058
Grankikov, v., hong, P., Crist, MI., & Pluye, PAG. (2020). Mixed methods
research in library and information science: A methodological re-
vista. Library & Information Science Research, 42(1), 101003.
DOI: https://doi.org/10.1016/j.lisr.2020.101003
Gupta, S., & Manning, C. (2011). Analyzing the dynamics of research
by extracting key aspects of scientific papers. En procedimientos de
the 5th International Joint Conference on Natural Language
Procesando (páginas. 1–9). Asian Federation of Natural Language
Procesando.
Hanyurwimfura, D., Bo, l., Njogu, h., & Ndatinya, mi. (2012). Un
automated cue word based text extraction. Diario de
Convergence Information Technology, 7(10), 421–429. DOI:
https://doi.org/10.4156/jcit.vol7.issue10.50
Hider, PAG., & Pymm, B. (2008). Empirical research methods reported
in high-profile LIS journal literature. Library & Información
Science Research, 30, 108–114. DOI: https://doi.org/10.1016/j
.lisr.2007.11.007
Hirohata, K., Okazaki, NORTE., Ananiadou, S., & Ishizuka, METRO. (2008).
Identifying sections in scientific abstracts using conditional ran-
dom fields. In Proceedings of the Third International Joint
Conferencia sobre procesamiento del lenguaje natural (páginas. 381–388).
Houngb, h., & Mercer, R. (2012). Method mention extraction from
scientific research paper. In Proceedings of COLING: Técnico
paper, 1211–1222.
Järvelin, K., & Vakkari, PAG. (1990). Content analysis of research arti-
cles in library and information science. Library & Información
Science Research, 12, 395–421.
kim, METRO. (1996). Research record. Journal of Education for Library
and Information Science, 37(4), 376–383. DOI: https://doi.org
/10.2307/40324247
Knoth, PAG., & Herrmannova, D. (2014). Towards semantometrics: A
new semantic similarity based measure for assessing a research
publications contribution. D-Lib Magazine, 20(11), 8. DOI:
https://doi.org/10.1045/november2014-knoth
Kovac(cid:1)evic(cid:3), A., Konjovic(cid:3), Z., Milosavljevic(cid:3), B., & Nenadic, GRAMO.
(2012). Mining methodologies from NLP publications: A case
study in automatic terminology recognition. Computer Speech
& Idioma, 26(2), 105–126. DOI: https://doi.org/10.1016/j
.csl.2011.09.001
Kozinets, R. (2010). Netnography: Doing ethnographic research
en línea. Newbury Park, California: Sage.
Kumpulainen, k. (1991). Library and information science research
en 1975. Libri, 41(1), 59–76. DOI: https://doi.org/10.1515/libr
.1991.41.1.59
Liakata, METRO., saha, S., Dobnik, S., Batchelor, C., & Rebholz-
Schuhmann, D. (2012). Automatic recognition of conceptualiza-
tion zones in scientific articles and two life science applications.
Bioinformatics, 28(7), 991–1000. DOI: https://doi.org/10.1093
/bioinformatics/bts071, PMID: 22321698, PMCID: PMC3315721
lin, S., Ng, J., Pradhan, S., Shah, J., Pietrobon, r., & Kan, METRO. (2010).
Extracting formulaic and free text clinical research articles meta-
data using conditional random fields. En Actas de la
Estudios de ciencias cuantitativas
729
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
NAACL HLT 2010 Second Louhi Workshop on Text and Data
Mining of Health Documents (páginas. 90–95). Asociación para
Ligüística computacional.
Luff, r., Byatt, D., & Martín, D. (2015). Review of the typology of
research methods within the social sciences. National Centre For
Research Methods Report.
Lustria, METRO., Kazmer. METRO., Glueckauf, r., Hawkins, r., Randeree, MI.,
Rosario, I., McLaughlin, C., & Redmond, S. (2010). Participatory
design of a health informatics system for rural health practitioners
and disadvantaged women. Journal of the American Society for
Information Science and Technology, 61(11), 2243–2255. DOI:
https://doi.org/10.1002/asi.21390
Nasar, Z., Jaffry, S., & Malik, METRO. (2018). Information extraction from
scientific articles: A survey. cienciometria, 117, 1931–1990.
DOI: https://doi.org/10.1007/s11192-018-2921-5
Hombre nuevo, METRO. (2004). Fast algorithm for detecting community struc-
ture in networks. Physical Review E, 69(6), 066133. DOI: https://
doi.org/10.1103/PhysRevE.69.066133, PMID: 15244693
Hombre nuevo, METRO., & girvan, METRO. (2004). Finding and evaluating com-
munity structure in networks. Physical Review E, 69(2), 026113.
DOI: https://doi.org/10.1103/PhysRevE.69.026113, PMID:
14995526
Parque, S. (2004). The study of research methods in LIS education:
Issues in Korean and U.S. universidades. Library & Información
Science Research, 26, 501–510. DOI: https://doi.org/10.1016/j
.lisr.2004.04.009
QasemiZadeh, B., & Schumann, A. (2016). The ACL RD-TEC 2.0: A
language resource for evaluating term extraction and entity recogni-
tion methods. In Proceedings of the Tenth International Conference
on Language Resources and Evaluation (páginas. 1862–1868).
Risso, V. (2016). Research methods used in library and information
science during the 1970–2010, New Library World, 117(1/2),
74–93. DOI: https://doi.org/10.1108/NLW-08-2015-0055
Ronzano, F., & Saggion, h. (2015). Dr. Inventor framework:
Extracting structured information from scientific publications. En
norte. Japkowicz & S. matwin (Editores.), Discovery Science (páginas. 209–220).
cham: Saltador. DOI: https://doi.org/10.1007/978-3-319-24282
-8_18
Saarikoski, J., Laurikkala, J., Järvelin, K., & Juhola, METRO. (2009). A
study of the use of self-organising maps in information retrieval.
Journal of Documentation, 65(2), 304–322. DOI: https://doi.org
/10.1108/00220410910937633
Seymore, K., McCallum, A., & Rosenfeld, R. (1999). Aprendiendo
hidden Markov model structure for information extraction. En
Proceedings of the AAAI’99 Workshop Machine Learning for
Information Extraction (páginas. 37–42).
Solomon, D., & Björk, B. (2012). A study of open access journals
using article processing charges. Journal of the American Society
for Information Science and Technology, 63(8), 1485–1495.
DOI: https://doi.org/10.1002/asi.22673
Tateisi, y., Ohta, T., Pyysalo, S., Miyao, y., & Aizawa, A. (2016).
Typed entity and relation annotation computer science papers. En
Proceedings of the Tenth International Conference on Language
Resources and Evaluation (páginas. 3836–3843).
Teufel, S., & Moens, METRO. (2002). Summarizing scientific articles:
Experiments with relevance and rhetorical status. computacional
Lingüística, 28(4), 409–445. DOI: https://doi.org/10.1162
/089120102762671936
Togia, A., & Malliari, A. (2017). Research methods in library and
information science. In S. Oflazoglu (Ed.) Qualitative versus
Quantitative Research (páginas. 43–64). Londres: IntechOpen. DOI:
https://doi.org/10.5772/intechopen.68749
Van Eck, NORTE., & waltman, l. (2010). Software survey: VOSviewer, a
computer program for bibliometric mapping. cienciometria,
84(2), 523–538. DOI: https://doi.org/10.1007/s11192-009
-0146-3, PMID: 20585380, PMCID: PMC2883932
Van Eck, NORTE., & waltman, l. (2014). Visualizing bibliometric networks.
In Y. Ding, R. Rousseau, & D. Wolfram (Editores.), Measuring scholarly
impacto: Methods and practice (páginas. 285–320). cham: Saltador.
VanScoy, A., & Fontana, oh. (2016). How reference and information
service is studied: Research approaches and methods. Library &
Information Science Research, 38, 94–100. DOI: https://doi.org
/10.1016/j.lisr.2016.04.002
Wallace, METRO., Gingras, y., & Duhon, R. (2008). A new approach for
detecting scientific specialties from raw cocitation networks.
Journal of the American Society for Information Science and
Tecnología, 60(2), 240–246. DOI: https://doi.org/10.1002
/asi.20987
Wang, METRO., & Chai, l. (2018). Three new bibliometric indicators
/approaches derived from keyword analysis. cienciometria, 116(2),
721–750. DOI: https://doi.org/10.1007/s11192-018-2768-9
Whitley, R. (2000). The intellectual and social organization of the
sciences. Nueva York: prensa de la Universidad de Oxford.
Zuccala, A., van Someren, METRO., & van Bellen, METRO. (2014). A
machine-learning approach to coding book reviews as quality
indicators: Toward a theory of megacitation. Journal of the
American Society for Information Science and Technology, 65(11),
2248–2260. DOI: https://doi.org/10.1002/asi.23104
Estudios de ciencias cuantitativas
730
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
APPENDIX A
Método
From Chu (2015)
bibliometría
Keywords associated with each research method
Indicative keywords/phrases
impact factor, scientometric, bibliometric, citation
analysis/impact/importance/counts/index/report/
window/rate/pattern/distributions/score/network,
citation-based index, h-index, hindex, citers,
citees, bibliometric indicator, leydesdorff, altmetrics
content analysis
content analysis, inter coder reliability,
inter annotator agreement, krippendorff
delphi study
delphi study
ethnography/field study
Hammersley, participant observation, ethnography,
experimento
focus group
historical method
interview
observación
cuestionario
ethnographic, ethnographer, field note,
rich description
dependent variable, independent variable,
experimento, experimental
focus group
historical method
interview, interviewed, interviewer, interviewee,
interviewing, transcript
observación
respondent, cuestionario, survey, Likert, surveyed,
sampling, response rate
research diary/journal
diary study, cultural probe
think aloud protocol
think aloud
transaction log analysis
log analysis/technique
webometrics
webometrics, cybermetrics, link analysis
Nuevo
agent based modeling/
agent model/modeling, multi-agents
simulation
annotation
clasificación
clustering
annotation, tagging
clasificación, classify, classifier
grupo, clustering
comparative evaluation
comparative evaluation, evaluative studies
document analysis
document/textual analysis, document review
Estudios de ciencias cuantitativas
731
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Automated analysis of research methods in library and information science
(continued )
Método
information extraction
Indicative keywords/phrases
named entity recognition, NER, relation extraction
IR related indexing/
ranking/query methods
Learning to rank, term weighting, indexing method,
query expansion, question answering
mixed method
cresswell and plano clark, mixed method
digital ethnography
digital ethnography, netnography, netnographic
network analysis
statistical methods
network analysis/study
correlation, logistic test, prueba t, chi-square,
hypothesis test, null hypothesis, dependence test
topic modeling
topic model, topic modeling, LDA
user task based study
user study, user analysis
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
2
6
9
8
1
9
3
0
7
9
2
q
s
s
_
a
_
0
0
1
2
3
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Estudios de ciencias cuantitativas
732