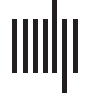ARTÍCULO DE INVESTIGACIÓN
Decoding of Envelope vs. Fundamental Frequency
During Complex Auditory Stream Segregation
un acceso abierto
diario
Keelin M. Greenlaw1,2,3, Sebastian Puschmann4
, and Emily B. j. Coffey1,2,3
1Department of Psychology, Concordia University, Montréal, QC, Canada
2International Laboratory for Brain, Music and Sound Research (BRAMS)
3The Centre for Research on Brain, Language and Music (CRBLM)
4Institute of Psychology, University of Lübeck, Lübeck, Alemania
Palabras clave: auditory stream segregation, hearing-in-noise, pitch representation, reconstruction,
speech-in-noise, neural decoding
ABSTRACTO
Hearing-in-noise perception is a challenging task that is critical to human function, but how
the brain accomplishes it is not well understood. A candidate mechanism proposes
that the neural representation of an attended auditory stream is enhanced relative to
background sound via a combination of bottom-up and top-down mechanisms. Hasta la fecha,
few studies have compared neural representation and its task-related enhancement across
frequency bands that carry different auditory information, such as a sound’s amplitude
envelope (es decir., syllabic rate or rhythm; 1–9 Hz), and the fundamental frequency of periodic
estímulos (es decir., pitch; >40 Hz). Además, hearing-in-noise in the real world is frequently both
messier and richer than the majority of tasks used in its study. En el presente estudio, we use
continuous sound excerpts that simultaneously offer predictive, visual, and spatial cues to help
listeners separate the target from four acoustically similar simultaneously presented sound
streams. We show that while both lower and higher frequency information about the entire
sound stream is represented in the brain’s response, the to-be-attended sound stream is
strongly enhanced only in the slower, lower frequency sound representations. Estos resultados
are consistent with the hypothesis that attended sound representations are strengthened
progressively at higher level, later processing stages, and that the interaction of multiple brain
systems can aid in this process. Our findings contribute to our understanding of auditory
stream separation in difficult, naturalistic listening conditions and demonstrate that pitch and
envelope information can be decoded from single-channel EEG data.
INTRODUCCIÓN
Hearing-in-noise (HIN) is a complex and computationally challenging task that is critical to
human function in social, educational, and vocational contexts. Anecdotally, our HIN skills
can sometimes be strikingly effective, as when we catch a phrase from a familiar song on the radio
and can suddenly perceive its entirety over the din of a crowded supermarket. More frequently,
attending to a target sound stream in the presence of noise is perceived to be effortful and fatiguing
(Enrique, Schneider, & Craik, 2008; McGarrigle et al., 2014). Using compensatory mechanisms
negatively impacts on other cognitive functions (Peelle, 2018; Wu, Stangl, zhang, Perkins, &
Eilers, 2016), with consequences for well-being (Eckert, Teubner-Rhodes, & Vaden, 2016). El
large number of people affected, notably older adults (anderson, Parbery-Clark, White-Schwoch,
& Kraus, 2012; anderson, Parbery-Clark, Hacer, & Kraus, 2011) and some paediatric populations
Citación: Greenlaw, k. METRO., Puschmann,
S., & Coffey, mi. B. j. (2020). Decoding of
envelope vs. fundamental frequency
during complex auditory stream
segregation. Neurobiology of
Idioma, 1(3), 268–287. https://doi.
org/10.1162/nol_a_00013
DOI:
https://doi.org/10.1162/nol_a_00013
Recibió: 26 Noviembre 2019
Aceptado: 25 Abril 2020
Conflicto de intereses: Los autores tienen
declaró que no hay intereses en competencia
existir.
Autor correspondiente:
Emily B. j. Coffey
emily.coffey@concordia.ca
Editor de manejo:
David Poeppel
Derechos de autor: © 2020 Massachusetts
Institute of Technology. Publicado
bajo una atribución Creative Commons
4.0 Internacional (CC POR 4.0) licencia.
La prensa del MIT
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Decoding complex auditory stream segregation
(Ziegler, Pech-Georgel, Jorge, Alario, & Lorenzi, 2005), motivates efforts to clarify the neural
mechanisms underlying this complex behaviour. Además, noninvasive, low-cost, and plea-
surable interventions such as musical training might improve HIN skills (Dubinsky, Wood,
Nespoli, & ruso, 2019), but to realise their potential we require a better understanding of the
degree to which language and musical processing that are critical for HIN perception rely on the
same mechanisms (Särkämö, Altenmüller, Rodríguez-Fornells, & Peretz, 2016).
The brain appears to rely on both the quality of feed-forward, bottom-up encoding (Coffey,
Chepesiuk, Herholz, Baillet, & Zatorre, 2017; Song, Skoe, Banai, & Kraus, 2011) and active
top-down mechanisms to enhance or “sharpen” task-relevant acoustic features in the presence
of competing sound (Bidet-Caulet et al., 2007; Du & Zatorre, 2017; Forte, Etard, & Reichenbach,
2017; Puschmann et al., 2017). Feed-forward encoding can be observed in the fidelity with
which aspects of sound are encoded in the brain, whereas the contributions of top-down (o
multimodal) factors can be teased out via experimental design (p.ej., selective attention para-
digms). Two frequency bands carry important acoustic information, the neural representations
of which can be measured in time-resolved neuroimaging methods, such as EEG and MEG.
Lower frequency (es decir., ~1–9 Hz) fluctuations convey information concerning the temporal
envelope of sound, which is related to the rate of words, syllables, and phonemes in speech
(Keitel, Bruto, & Kayser, 2018) and also rhythmic elements in music (Harding, Sammler,
Henry, Large, & Kotz, 2019). For continuous auditory input, such as natural speech or music,
the neural response to the sound envelope can be assessed using linear mapping approaches
(Crosse, Di Liberto, Bednar, & Lalor, 2016). Stimulus reconstruction (es decir., backward mapping
from EEG/MEG data to the sound envelope) allows us to quantify the accuracy/robustness of the
cortical envelope response (Ding & Simón, 2011). In the context of speech-in-noise, diferencias
in the speech envelope response have been associated with individual differences in speech
intelligibility (Ding & Simón, 2013). In selective listening paradigms, in which participants must
attend to one of two or more sound streams, the neural representations of to-be-attended audi-
tory streams are sharpened relative to unattended streams (Ding & Simón, 2012) in human non-
primary auditory cortex (Ding & Simón, 2011; Mesgarani & Chang, 2012).
The neural representation of a sound’s fundamental frequency, called the frequency-following
respuesta (FFR; Kraus, anderson, & White-Schwoch, 2017), conveys information related to pitch
Procesando (Gockel, Carlyon, Mehta, & Plack, 2011) and is also measurable with EEG and MEG.
Although the FFR is sometimes referred to as the “brainstem response,” it has multiple origins
including the auditory brainstem, thalamus, and cortex (Coffey, Herholz, Chepesiuk, Baillet, &
Zatorre, 2016; Hartman & Weisz, 2019; Tichko & Skoe, 2017; see Coffey, Nicol et al., 2019
for discussion). Even a single EEG channel placed at the vertex or frontal scalp captures informa-
tion about the fidelity with which the auditory system as a whole preserves useful sound informa-
ción, making single-channel FFR an attractively accessible and widely used technique (Coffey,
Nicol et al., 2019).
The FFR is sensitive to individual differences in HIN perception (anderson, Parbery-Clark,
White-Schwoch, & Kraus, 2013; Marrón & Bacon, 2010; Coffey et al., 2017), suggesting that the
quality of feed-forward pitch encoding is important. While FFRs are typically assessed using
evoked responses obtained from repeated presentation of an acoustic stimulus (es decir., a tone or a
speech syllable; Kraus et al., 2017; Krizman & Kraus, 2019; Skoe & Kraus, 2010), trabajo reciente
shows that high-frequency acoustic information can also be reconstructed from electrophysi-
ological responses to continuous input (Forte et al., 2017; Maddox & Sotavento, 2018). In a selective
listening paradigm using two competing speakers, small enhancements of the attended stream
relative to the unattended stream were reported (Etard, Kegler, Braiman, Forte, & Reichenbach,
2019; Forte et al., 2017). These results agree with findings that the gain of pitch representations
Neurobiology of Language
269
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Decoding complex auditory stream segregation
in the FFR is accessible to top-down attentional mechanisms (Hartman & Weisz, 2019). Pocos
studies have looked at the relationship between neural representations in both frequency
bands, which is relevant to understanding how and when streams of task-relevant acoustic
information are separated from background noise and enhanced.
The paradigms used in HIN studies differ in many ways, including the nature of the target and
ignored sound streams, physiological signal measured, recording equipment used, and the pres-
ence of additional cues in the stimuli. Although the majority of HIN experimental tasks and clin-
ical tasks operationalize HIN perception in simple unimodal auditory terms (p.ej., sentences in
broadband noise, two-talkers reading different stories), it has been well documented that other
cues that are frequently present in real-world HIN conditions contribute to performance. Espacial
information improves stream segregation and HIN performance (Carhart, Tillman, & Johnson,
1968; Divenyi & Oliver, 1989; Yost, Sheft, & Dye, 1994), as does the presence of visual infor-
mation that is congruent with the attended sound source (Crosse, Di Liberto, & Lalor, 2016;
Golumbic, Cogan, Schroeder, & Poeppel, 2013; Puschmann et al., 2019). Visual information
enhances auditory perception, and helps to resolve auditory perceptual ambiguity (Golumbic
et al., 2013), likely by priming the brain to receive relevant input at specific times. HIN skills are
also affected by knowledge of language syntax and semantics (Golestani, rosa, & Scott, 2009;
Pickering & Garrod, 2007), familiarity with the speaker’s vocal timbre (Pregonero & Hombre nuevo, 2004;
Souza, Gehani, Wright, & McCloy, 2013; Yonan & Sommers, 2000), and prior knowledge of the
objetivo (Agus, Thorpe, & Pressnitzer, 2010; Bey & McAdams, 2002), which can be used to predict,
constrain, and evaluate the interpretation of incoming information (Bendixen, 2014).
Recognizing that HIN is a complex skill involving multiple interacting neural systems to de-
grees that depend on the nature of the task and on individuals’ strengths (Jasmin, Dick, Holt, &
Tierney, 2019; Yates, moore, Amitay, & Barry, 2019), some experimental approaches divide HIN
perception into its component skills and compare their relative contributions. Por ejemplo,
Coffey, Arseneau-Bruneau, zhang, and Zatorre (2019) compared the benefits to HIN perfor-
mance of offering spatial, visual, and predictive information (in separate conditions) to otherwise
matched auditory stimuli presented in noise. Each additive cue conferred a benefit to listeners
over unimodal auditory HIN performance; sin embargo, these benefits were also related differently
to individuals’ experiences with musical training, multilingualism, and both measures of top-
abajo (es decir., auditory working memory) and bottom-up (es decir., fine pitch discrimination) habilidades.
While reductionist approaches offer insight into individual differences and specific processes,
a complementary experimental approach in which multiple cues are simultaneously present
could more closely replicate the brain’s integrative approach to naturally occurring HIN situa-
ciones, in which multiple cues are often present. A notable aspect of this design is that it uses simple
musical melodies, which reduces the influence of inter individual differences in linguistic skills,
and enables precise balancing of sensory conditions in a relatively naturalistic framework. Tarea
performance nonetheless correlated with a sentence-based measure of HIN (es decir., the HIN task;
Nilsson, Soli, & sullivan, 1994), suggesting overlap in neural mechanisms, and supporting the use
of musical stimuli in HIN studies.
The Current Study
The main focus of this work is to better understand how acoustic information in the two fre-
quency bands described above is enhanced through processes of selective attention, bajo
difficult but cue-rich listening conditions. Previous work has shown greater stream differences
in later (higher level) cortical brain areas, suggesting that only attended information is carried
forward from early auditory regions (p.ej., Du & Zatorre, 2017; Puschmann, Baillet, & Zatorre, 2018).
Neurobiology of Language
270
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Decoding complex auditory stream segregation
We hypothesized that while both the envelope and the fundamental frequency reconstruction
of the attended stream would be greater than that of the unattended stream (as shown in pre-
vious work), the slower responses that are thought to originate from primary, secondary, y
later auditory cortical regions would show greater stream-specific enhancements than the FFR,
which comes from subcortical regions, and at the level of the auditory cortex, likely only comes
from early regions (Coffey et al., 2016; Hartman & Weisz, 2019). We recorded single-channel
EEG while listeners were asked to follow a target stream of music embedded within four other
sound streams, including one with equivalent but temporally rearranged (es decir., scrambled)
acoustic information and three with scrambled information at different timbres and spectral
ranges. The target sound stream was thus concealed in a rich cacophony of sound, constituting
both energetic and informational masking. Listeners were offered visual, spatial, and predictive
cues simultaneously in addition to auditory information. We decoded the attended, ignored,
and total sound streams within each frequency band from the EEG signals, analyzed their
temporal properties, and compared their relative strengths.
While decoding accuracy is most effective using multiple EEG channels, it is not known whether
the single-channel technique can be used to decode FFR information (Mirkovic, Debener, Jaeger, &
De Vos, 2015). A secondary aim was to test whether single-channel decoding is possible in both
frequency ranges, cual, due to its experimental simplicity, opens many possibilities for mea-
suring larger samples and more sensitive populations.
MATERIALES Y MÉTODOS
Participantes
Data were collected from 18 subjects who were participating in an undergraduate-level course
on experimental methods for musical neurocognition (average age = 22.1 años, DE = 1.6,
range = 21–26). Three subjects were left-handed, y 15 subjects were female. Subjects par-
ticipated on a voluntary basis as part of their training, after providing written informed consent
in accordance with protocols reviewed by the ethics committee of the University of Montreal.
All subjects had pure tone hearing thresholds better than 20 dB SPL (sound pressure level) en
both ears at octave frequencies between 125 Hz and 8 kHz (with one exception who had a
marginally elevated threshold of 25 dB SPL in the right ear at 6,000 Hz only). All subjects
reported having no neurological conditions nor other difficulties with hearing or vision.
Information regarding the subjects’ musical experience was collected via the Montreal
Music History Questionnaire (Coffey, Herholz, Scala, & Zatorre, 2011) and is reported for
completeness; because our convenience sample is of modest size and is highly musically
and linguistically heterogeneous, we do not attempt statistical analyses of finer grained rela-
tionships between pitch representation and experience in sound herein. Sixteen subjects re-
ported being native French speakers, one was a native Russian speaker, and one was a native
Arabic speaker. Eight subjects were monolingual French speakers and 10 were bi- or trilingual.
Only one spoke a tonal language, and two believed themselves to have absolute pitch. On
promedio, subjects had 1,969 cumulative musical practice and training hours (DE = 3,621,
range = 0–15,023) and started training at age 7.57 (DE = 3.25, range = 3–16).
Stimulation
Attended, ignored, and background streams
As in previous work (Disbergen, Valente, Formisano, & Zatorre, 2018; Pressnitzer, Suied, &
Shamma, 2011), we take advantage of music as a excellent platform to study complex stream
segregation and the integration processes that appear to be common to both music and
Neurobiology of Language
271
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Decoding complex auditory stream segregation
idioma. To ensure that the results would be relevant across both domains, we created mu-
sical stimuli with temporal properties that have been strongly related to language processing.
The target stream consisted of a musical excerpt of an instrumental work by Georg Philipp
Telemann (1681–1767), Sonata for Flute in F(TMV 41:F2, mvmt 1). Only the first 10 measures
of the melodic line were used (21 s). The rate of tone onsets was 120 quarter notes or 240 eighth
notes per min, correspondiente a 2 y 4 Hz. The strongest frequency was 4 Hz, confirmed by
analyzing the frequency content of the spectral amplitude envelope (Ding et al., 2017; ver
Cifra 1). Cortical response in the 1–4 Hz range reliably predicts speech recognition in the
presence of background noise (Ding, Chatterjee, & Simón, 2014). In recordings of naturally
occurring speech and musical recordings, there are small differences in the average peak
frequency of amplitude envelope modulations (es decir., 5 Hz for speech and 2 Hz for music;
Ding et al., 2017). Our tone rate falls close to the peak of the speech range, to which the human
auditory system is highly sensitive (Teng & Poeppel, 2019), maximizing the likelihood of
engaging mechanisms that are also active in speech-in-noise processing.
The melodic excerpt was converted to midi electric piano timbre using Musescore (www.
musescore.com) to provide strong attacks (sudden sound onsets), which produce robust re-
sponses from the auditory system. The excerpt was then transposed such that all tones had
fundamental frequencies below ~500 Hz, so as to be centred on the human vocal pitch range
and maximize the auditory system’s response (Tichko & Skoe, 2017). The final range of fun-
damental frequencies was 104–277 Hz. We split measures in half, Resultando en 20 new mea-
sures, each containing 2 beats and between 1 y 8 notas. Measures were exported as
separate files (WAV, sampling frequency 44,100 Hz). Because the decay of the rendered piano
tones exceeds the measure and would have resulted in mixed acoustic information between
measures, measures were trimmed to 1 s and windowed using a 10 ms raised cosine ramp,
using custom scripts (MATLAB; www.mathworks.com). The right channel was copied over the
left channel to ensure identical frequency information was presented to each ear. The acoustic
properties of each ear and for the attended (in which measures were presented sequentially, en
their original order) and ignored sound stream (in which measures were presented in a scram-
bled order) were therefore acoustically comparable, except at longer timescales (>1 s).
Cifra 1. Spectrograms of 10 s excerpts of the stimulus presented in silence (arriba) and embedded in the background streams (abajo). Spectral
amplitude summed over frequencies, which represents how sound intensity fluctuates over time, is superimposed as black curves, the mod-
ulation spectra of which are shown at right. The stimulus presented in silence has a clear modulation peak in the amplitude envelope at 4 Hz
(top right), whereas it is obscured by the addition of background noise (bottom right).
Neurobiology of Language
272
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Decoding complex auditory stream segregation
This experimental design strongly challenges the auditory system with high levels of infor-
mational and energetic masking yet offers multiple additional cues. By using musical stimuli
that have frequency information within the ranges of interest for speech, while removing the
complications of multiple layers of linguistic processing, we are able to emphasize enhance-
ments via top-down processing and multimodal integration on acoustic representation.
Attentional control
En cada prueba, one of the six quarter notes in the musical excerpt was randomly replaced by a
triplet in which the first and last notes were the same pitch, and the central note was raised by
a tone. These targets occurred in the attended stream for 50% of trials and in the unattended
stream for the other 50% of trials; subjects were asked to indicate (on a score sheet) after each
trial if they had heard a triplet in the attended stream, and an accuracy score of correct hits and
correct misses was calculated as an attentional control (Disbergen et al., 2018). Triplets
occurred only in the auditory modality; the visual representation was that of the original
excerpt, such that the task could not be accomplished using only visual information. The first
three subjects received an earlier version of the triplet manipulation in which each of the triplets
had the same pitch—the subjects expressed frustration with the task (although they performed
above chance levels). The central note was raised by a tone for the remainder of the subjects
(norte = 15) to make the variation more salient.
Spatial cues, visual cues, and predictive information
To simulate spatial separation between different sound sources, the attended and unattended
streams were presented at a higher sound level in one ear than the other (L > R by *0.8 or R > L
por *0.8, corresponding to a perceptual experience of the sound originating approximately 45
degrees to one side or the other of a straight-ahead position). A visualization was prepared
using a Python clone of a freely available musical animation software (www.musanim.com;
ver figura 2). Two versions of the video were then created (using Kdenlive; https://kdenlive.
org/en/) in which the animation was reduced in size and moved either to the left or right side of
the screen to provide a spatial cue as to whether the attended sound would be at a higher level
in the left or right ear.
Prior to the EEG recording, subjects were familiarized with five demonstration versions of
the stimuli and encouraged to practice listening for triplets both with no background noise and
in noise. At the beginning of each block, subjects heard the original musical excerpt presented
in silence three times binaurally, with the visual representation, to refresh their memory and
facilitate use of top-down predictive cues.
Background noise
Three background streams were included to provide a consistent level of “multi-music” back-
ground noise, and to reduce the perception of salient or disturbing coincidences created by the
offset between to-be-attended and to-be-ignored streams (p.ej., if the unattended stream was
jittered by half a beat on a given trial, it might have been perceived as a new “fused” melody
at double the original tempo). The background streams also served to reduce temporal glimps-
En g (es decir., when a target stimulus is momentarily unmasked; see Vestergaard, Fyson, &
Patterson, 2011), in an analogous fashion to multitalker speech used in some speech-in-noise
tareas (p.ej., wilson, 2003).
Neurobiology of Language
273
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Decoding complex auditory stream segregation
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
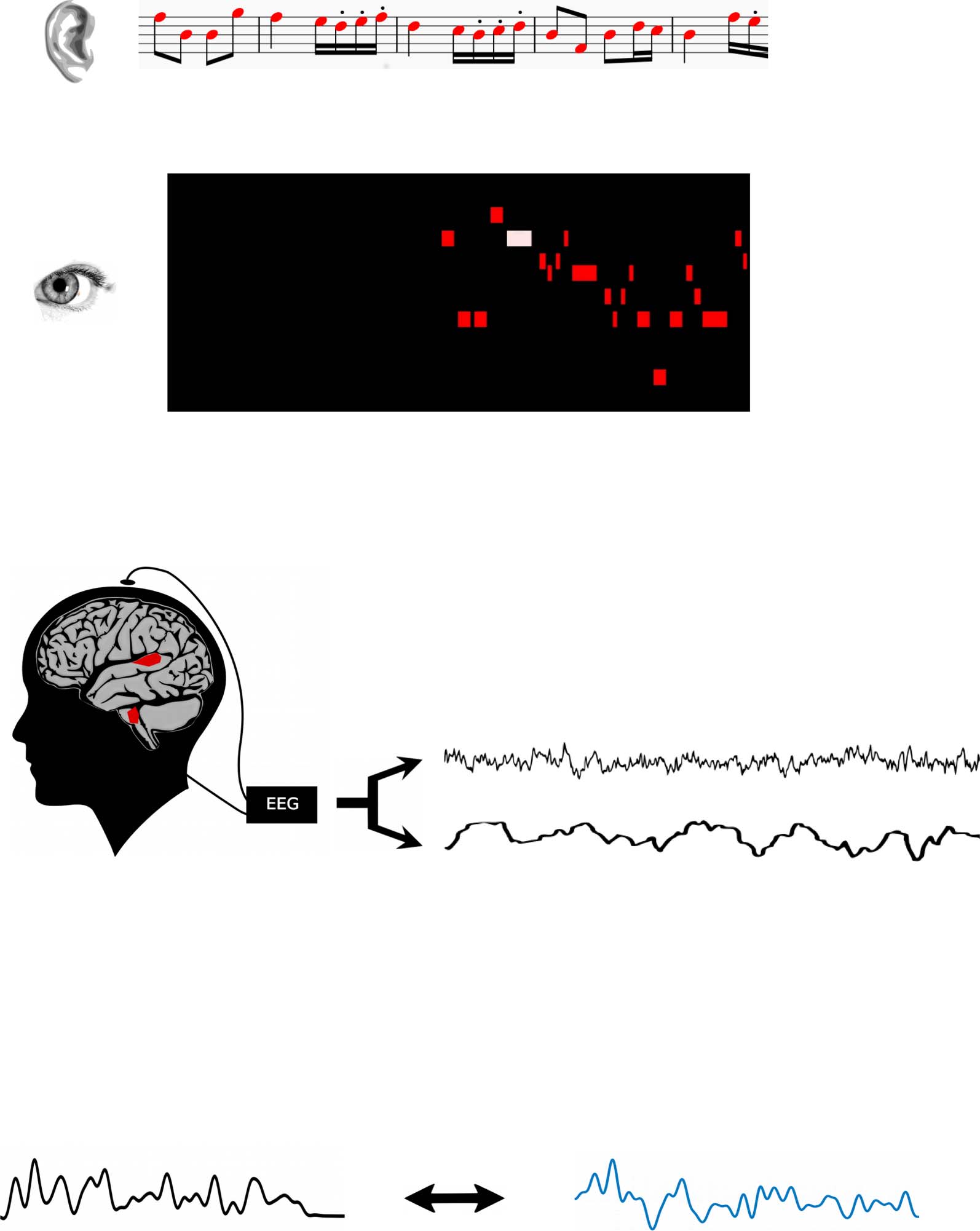
Cifra 2. A) Auditory stimulation consisted of a mixture of a to-be-attended stream, an acoustically similar but scrambled to-be-ignored
stream, and three streams of additional background noise. Predictive, spatial, and visual cues were provided simultaneously. B)
Electroencephalography (EEG) was collected and filtered in two information-bearing frequency bands. C) Reconstruction of sound enve-
lope and frequency-following response was performed using ridge regression to establish a linear backward mapping between EEG neural
responses and the sound streams. The measure of successful reconstruction is an average correlation between the EEG-based reconstruc-
tion and the auditory information.
The three background streams were created by transposing the original melody either up or
down by a major or minor second and changing their timbre, which produced background
tones with fundamental frequencies in the frequency range of 87–294 Hz. This manipulation
Neurobiology of Language
274
Decoding complex auditory stream segregation
ensured that the attended and unattended streams were well buried in the noise and could not
be separated solely by paying attention to high or low pitch ranges; these background streams
were played at a reduced volume (*0.6 amplitude with respect to the attended and ignored
streams) and equally in both ears, such that it would theoretically be possible to separate the
to-be-ignored stream from the rest of the background noise based on sound level, timbre, y
spatial separation. The timbral manipulation was intended to simulate the observation from
speech-in-noise research that familiarity with the speaker’s voice improves HIN perception
(Pregonero & Hombre nuevo, 2004; Souza et al., 2013; Yonan & Sommers, 2000). The attended stream
began very slightly ahead of the other streams in order to facilitate stream following. Each ad-
ditional stream started within the duration of the first beat (0.025–0.475 s in steps of 0.005 s,
randomized). The attended, ignored, and background streams were combined using custom
scripts to create 78 unique stimuli (ver tabla 1).
Diseño
The experiment was divided into 3 bloques (8.5 min each). In each block, subjects listened to
el 3 in-silence trials and 78 task trials. During a 3–4 s break after each trial, subjects indicated
on a form whether they had heard a triplet in the attended stream. Subject comfort, compli-
ance, and motivation were informally assessed for each subject and between each run; todo
subjects remained motivated and alert for the duration of the experiment.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 1. Stimulus design
Streams
Attended
Order of
measures
In order
Timbre
Electric
piano
Key: nota
range (Hz)
D♭: A♭2–D♭4
(104–277 Hz)
L-R level balance
L > R by *0.8 o
R > L by *0.8;
randomized
Jitter
Starts first
Visual
representación
Sí, posición
reflects ear
of greater
volumen
(spatial cue)
Ignored
Scrambled
Electric
piano
D♭: A♭2–D♭4
(104–277 Hz)
Opposite to target No
Fondo 1
Scrambled Acoustic
bass
Fondo 2
Scrambled
Recorder
B♭: F2–B♭3
(87–233 Hz)
(transposed
down by minor
segundo)
D: A2–D4
(110–294 Hz)
(transposed
up by minor
segundo)
Fondo 3
Scrambled Vibraphone C♭: G♭2–C♭3
(93–247 Hz)
(transposed
down by minor
segundo)
Equal, *0.6 con
respect to
1 y 2
Equal, *0.6 con
respect to
1 y 2
Equal, *0.6 con
respect to
1 y 2
No
No
No
Jittered by
25–500 ms in
steps of 5 EM,
randomized
Jittered by
25–500 ms in
steps of 5 EM,
randomized
Jittered by
25–500 ms in
steps of 5 EM,
randomized
Jittered by
25–500 ms in
steps of 5 EM,
randomized
Neurobiology of Language
Oddball
objetivos
Sí, 50%
of trials
Sí,
opposite
50%
No
No
No
275
Decoding complex auditory stream segregation
EEG Data Collection and Preprocessing
EEG data were recorded in a magnetically shielded audiometric booth from monopolar active
Ag/AcCl electrodes placed at Cz (10–20 International System), and both mastoids, using an
averaged reference (BioSemi; www.biosemi.com). Two ground electrodes were placed above
the right eyebrow. Because active electrodes reduce nuisance voltages caused by interference
currents by performing impedance transformation on the electrode, we confirmed that direct-
current offset was close to zero during electrode placement instead of measuring impedance.
Electrode signals were amplified with a BioSemi ActiveTwo amplifier, recorded using open
filters with a sampling frequency of 2,048 Hz, and stored for offline analysis using BioSemi
ActiView software. The auditory signal was simultaneously recorded into the EEG data in order
to facilitate precise alignment of auditory stimulation with neural responses.
Data were preprocessed in EEGLAB (Delorme & Makeig, 2004) and then with custom MATLAB
scripts (Matemáticas; www.mathworks.com). EEG data were band-pass filtered both from 1–9 Hz for
sound envelope reconstruction and from 80–300 Hz for fundamental response (default order); ambos
outputs were down-sampled to 1,000 Hz, and re-referenced to the average of the right and left
mastoid channels. Trials were cut into 22 s epochs for reconstruction analysis. Amplitude envelopes
of the musical streams were obtained using a Hilbert transform, followed by 1–9 Hz band-pass
filtering. Filtering was performed using a third order Butterworth filter and the filtfilt function in
MATLAB for zero-phase digital filtering of the data, as in Puschmann et al. (2018).
Reconstruction Method
Reconstruction of the sound envelope and FFR was performed using the multivariate temporal re-
sponse function toolbox for MATLAB (Crosse, Di Liberto, Bednar, & Lalor, 2016). Ridge regression
was used to fit a linear backward mapping between EEG neural responses of the Cz channel and the
sound stream. This model allows for stimulus reconstruction that incorporates a window of relative
time lags between sound input and EEG response (p.ej., 0–200 ms) or a reconstruction that is based on
a single relative time lag (p.ej., neural response at 10 EM). We employed both of these strategies to
explore the magnitude and temporal evolution of reconstruction accuracy of different sound streams
within the sound envelope and FFR bandwidths.
−2, 10
The regularization parameter, λ, was optimized for each sound stream and each subject with
−1,
leave-one-out cross-validation across trials. This procedure uses grid values of λ (λ = 10
…, 108) and selects the optimal value based on mean squared error. Using the selected λ value,
the model was trained on each of the trials to obtain regression weights. Model fitting for each
sound stream was then performed with data from the selected trial and the mean regression
weights obtained for this stream in all other trials. This leave-one-out parameter estimation pro-
cedure ensured that reconstruction did not depend on trial-specific properties of the recorded
EEG data but was rather related to trial-independent mapping between the sound streams and
neural response as measured by EEG (Puschmann et al., 2018). Pearson’s correlation, r, entre
the reconstructed and original sound stream was computed and averaged across trials to quan-
tify the accuracy of the reconstruction. This process was repeated for each of the sound streams
de interés (es decir., objetivo, ignored, and entire sound stream), with audio and EEG data filtered within
the 1–9 Hz and 80–300 Hz bandwidths. Given that the model may find spurious patterns in data,
chance correlations between reconstructions and sound streams are likely to be above zero. Nosotros
therefore computed chance r values by averaging values obtained by correlating the reconstruc-
tion of the target stream with the ignored sound stream, and the reconstruction of the ignored
stream with the target sound stream. De este modo, we computed chance values by attempting the re-
construction correlation with the wrong training data (O'Sullivan et al., 2014).
Neurobiology of Language
276
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
1
3
2
6
8
1
8
6
7
7
6
0
norte
oh
_
a
_
0
0
0
1
3
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Decoding complex auditory stream segregation
Calculation of reconstruction accuracy
The models for sound envelope (1–9 Hz) reconstruction included time lags between 0 y
200 EM, a range selected based on previous work to encompass the strongest response, pensamiento
to originate in Heschl’s gyrus and the planum temporale (see Puschmann et al., 2018, Cifra
3B; see also Ding & Simón, 2012; Steinschneider, Liégeois-Chauvel, & Brugge, 2011). Modelos
for FFR (80–300 Hz) included time lags between 0 y 35 EM. We performed a series of
Wilcoxon signed-rank tests to compare the overall mean reconstruction of each of the target,
ignored, and entire sound streams with chance values, as well as between attended and ignored
streams, and each of attended and ignored streams with the entire sound stream. Nosotros informamos
uncorrected p values, as well as p values corrected for false discovery rate (FDR) of multiple
testing under dependency (Benjamini & Yekutieli, 2001).
Temporal evolution
We explored the temporal evolution of reconstruction accuracy (es decir., timing of the neural con-
tributions to reconstruction) in each of the sound envelope and FFR frequency bands. Para el
anterior, we fit single lag models ranging from 0 a 200 ms for the attended, ignored, and entire
sound stream, as well as for chance reconstruction values, as previously described. For the fun-
damental response, we fit single lag models ranging from 0 a 75 EM. Although the majority of the
signal is expected to be <35 ms, reflecting the shorter expected time course of this signal (Etard
et al., 2019), cortical FFR response does not peak until ~60 ms (Coffey et 2016), for which
reason we explored a longer window. In these models each point in represents how well
sound can be reconstructed from EEG neural with contributions re-
sponse only single lag. We smoothed reconstruction accuracy across lags models
by using ±3 ms.
In frequency domains and lags, attended, ignored, entire
sound streams were compared to chance paired Wilcoxon signed-rank
tests, p values corrected multiple comparisons lags.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
>