Tʼainʼt What You Say, Itʼs the Way That You Say It—Left Insula
and Inferior Frontal Cortex Work in Interaction with
Superior Temporal Regions to Control the
Performance of Vocal Impersonations
Carolyn McGettigan1,2, Frank Eisner3, Zarinah K. Agnew1, Tom Manly4,
Duncan Wisbey1, and Sophie K. Scott1
D
oh
w
norte
yo
oh
a
d
mi
d
F
r
oh
metro
Abstracto
■ Historically, the study of human identity perception has
focused on faces, but the voice is also central to our expressions
and experiences of identity [Belin, PAG., Fecteau, S., & Bedard, C.
Thinking the voice: Neural correlates of voice perception. Trends
in Cognitive Sciences, 8, 129–135, 2004]. Our voices are highly
flexible and dynamic; talkers speak differently, depending on
their health, emotional state, and the social setting, así como
extrinsic factors such as background noise. Sin embargo, hasta la fecha,
there have been no studies of the neural correlates of identity
modulation in speech production. In the current fMRI experi-
mento, we measured the neural activity supporting controlled
voice change in adult participants performing spoken impres-
siones. We reveal that deliberate modulation of vocal identity
recruits the left anterior insula and inferior frontal gyrus, apoyo-
ing the planning of novel articulations. Bilateral sites in posterior
superior temporal/inferior parietal cortex and a region in right
middle/anterior STS showed greater responses during the emula-
tion of specific vocal identities than for impressions of generic
accents. Using functional connectivity analyses, we describe roles
for these three sites in their interactions with the brain regions
supporting speech planning and production. Our findings mark
a significant step toward understanding the neural control of
vocal identity, with wider implications for the cognitive control
of voluntary motor acts. ■
INTRODUCCIÓN
Voices, like faces, express many aspects of our identity
(Belin, Fecteau, & Bedard, 2004). From hearing only a
few words of an utterance, we can estimate the speakerʼs
gender and age, their country or even specific town of
birth, as well as more subtle evaluations on current mood
or state of health (Karpf, 2007). Some of the indexical
cues to speaker identity are clearly expressed in the
voice. The pitch (or fundamental frequency, F0) del
voice of an adult male speaker tends to be lower than
that of adult women or children, because of the thicken-
ing and lengthening of the vocal folds during puberty in
human men. The secondary descent of the larynx in adult
men also increases the spectral range in the voice, reflejar-
ing an increase in vocal tract length.
Sin embargo, the human voice is also highly flexible, y
we continually modulate the way we speak. The Lombard
efecto (Lombard, 1911) describes the way that talkers
automatically raise the volume of their voice when the
1Institute of Cognitive Neuroscience, University College London,
2Department of Psychology, Royal Holloway, Universidad de
Londres, 3Max Planck Institute for Psycholinguistics, Nimega,
Los países bajos, 4MRC Cognition and Brain Sciences Unit,
Cambridge, Reino Unido
© 2013 Massachusetts Institute of Technology Published under a
Creative Commons Attribution-NonCommercial 3.0 no portado
(CC BY-NC 3.0) licencia.
auditory environment is perceived as noisy. In the social
context of conversations, interlocutors start to align their
behaviors, from body movements and breathing patterns
to pronunciations and selection of syntactic structures
(Pardo, 2006; Garrod & Pickering, 2004; McFarland,
2001; Chartrand & Bargh, 1999; Condon & Ogston,
1967). Laboratory tests of speech shadowing, where par-
ticipants repeat speech immediately as they hear it, tener
shown evidence for unconscious imitation of linguistic and
paralinguistic properties of speech (Kappes, Baumgaertner,
Peschke, & Ziegler, 2009; Shockley, Sabadini, & Fowler,
2004; Bailly, 2003). Giles and colleagues (Giles, Coupland,
& Coupland, 1991; Giles, 1973) put forward the Com-
munication Accommodation Theory to account for pro-
cesses of convergence and divergence in spoken language
pronunciation—namely, they suggest that talkers change
their speaking style to modulate the social distance be-
tween them and their interlocutors, with convergence
promoting greater closeness. It has been argued by others
that covert speech imitation is central to facilitating com-
prehension in conversation (Pickering & Garrod, 2007).
Aside from these short-term modulations in speech,
changes in vocal behavior can also be observed over much
longer periods—the speech of Queen Elizabeth II has
shown a gradual progression toward standard southern
Revista de neurociencia cognitiva 25:11, páginas. 1875–1886
doi:10.1162/jocn_a_00427
yo
yo
/
/
/
/
j
t
t
F
/
i
t
.
:
/
/
h
t
t
pag
:
/
D
/
oh
metro
w
i
norte
t
oh
pag
a
r
d
C
mi
.
d
s
F
i
r
oh
yo
metro
v
mi
h
r
C
pag
h
a
d
i
i
r
r
mi
.
C
C
t
.
oh
metro
metro
/
j
mi
oh
d
tu
C
norte
oh
/
C
a
norte
r
a
t
r
i
t
i
C
C
yo
mi
mi
–
pag
–
d
pag
d
2
F
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
oh
9
C
6
norte
8
_
5
a
/
_
j
0
oh
0
C
4
norte
2
7
_
a
pag
_
d
0
0
b
4
y
2
gramo
7
tu
.
mi
pag
s
t
d
oh
F
norte
b
0
y
8
S
METRO
mi
I
pag
t
mi
metro
l
i
b
b
mi
r
r
a
2
r
0
2
i
3
mi
s
/
j
t
.
/
F
tu
s
mi
r
oh
norte
1
7
METRO
a
y
2
0
2
1
British pronunciation (Harrington, Palethorpe, & watson,
2000).
Although modulations of the voice often occur outside
conscious awareness, they can also be deliberate. A re-
cent study showed that student participants could change
their speech to sound more masculine or feminine, por
making controlled alterations that simulated target-
appropriate changes in vocal tract length and voice pitch
(Cartei, Cowles, & Reby, 2012). En efecto, speakers can
readily disguise their vocal identity (sullivan & Schlichting,
1998), which makes forensic voice identification noto-
riously difficult (Eriksson et al., 2010; Ladefoged, 2003).
Notablemente, when control of vocal identity is compromised,
Por ejemplo, in Foreign Accent Syndrome (p.ej., Scott,
Clegg, Rudge, & Burgess, 2006), the change in the patientʼs
vocal expression of identity can be frustrating and debili-
tating. Interrogating the neural systems supporting vocal
modulation is an important step in understanding human
vocal expression, yet this dynamic aspect of the voice is a
missing element in existing models of speech production
(Hickok, 2012; Tourville & Guenther, 2011).
Speaking aloud is an example of a very well practised
voluntary motor act (Jurgens, 2002). Voluntary actions
need to be controlled in a flexible manner to adjust to
changes in environment and the goals of the actor. El
main purpose of speech is to perform the transfer of a
linguistic/conceptual message. Sin embargo, we control our
voices to achieve intended goals on a variety of levels,
from acoustic–phonetic accommodation to the auditory
ambiente (cocinero & Lu, 2010; Lu & cocinero, 2009) a
socially motivated vocal behaviors reflecting how we wish
to be perceived by others (Pardo, Gibbons, Suppes, &
Krauss, 2012; Pardo & Jay, 2010). Investigations of the
cortical control of vocalization have identified two neuro-
logical systems supporting the voluntary initiation of innate
and learned vocal behaviors, where expressions such as
emotional vocalizations are controlled by a medial frontal
system involving the ACC and SMA, whereas speech and
song are under the control of lateral motor cortices
( Jurgens, 2002). De este modo, patients with speech production
deficits following strokes to lateral inferior motor structures
still exhibit spontaneous vocal behaviors such as laughter,
crying, and swearing, despite their severe deficits in volun-
tary speech production (Groswasser, Korn, Groswasser-
Reider, & Solzi, 1988). Electrical stimulation studies
show that vocalizations can be elicited by direct stim-
ulation of the anterior cingulate (p.ej., laughter; descrito
by Sem-Jacobsen & Torkildsen, 1960) and lesion evidence
shows that bilateral damage to anterior cingulate prevents
the expression of emotional inflection in speech ( Jurgens
& por cramon, 1982).
In healthy participants, a detailed investigation of the
lateral motor areas involved in voluntary speech produc-
tion directly compared voluntary inhalation/exhalation
with syllable repetition. The study found that the func-
tional networks associated with laryngeal motor cortex
were strongly left-lateralized for syllable repetition but
bilaterally organized for controlled breathing (Simonyan,
Ostuni, Ludlow, & Horwitz, 2009). Sin embargo, that design
did not permit further exploration of the modulation of
voluntary control within either speech or breathing. Este
aspect has been addressed in a study of speech prosody,
which reported activations in left inferior frontal gyrus
(IFG) and dorsal premotor cortex for the voluntary mod-
ulation of both linguistic and emotional prosody, eso
overlapped with regions sensitive to the perception of
these modulations (Aziz-Zadeh, Sheng, & Gheytanchi,
2010).
Some studies have addressed the neural correlates of
overt and unintended imitation of heard speech (Reiterer
et al., 2011; Peschke, Ziegler, Kappes, & Baumgaertner,
2009). Peschke and colleagues found evidence for un-
conscious imitation of speech duration and F0 in a shad-
owing task in fMRI, in which activation in right inferior
parietal cortex correlated with stronger imitation of dura-
tion across participants. Reiterer and colleagues (2011)
found that participants with poor ability to imitate non-
native speech showed greater activation (and lower gray
matter density) in left premotor, inferior frontal, and in-
ferior parietal cortical regions during a speech imitation
tarea, compared with participants who were highly rated
mimics. The authors interpret this as a possible index of
greater effort in the phonological loop for less skilled imi-
tatores. Sin embargo, en general, the reported functional imag-
ing investigations of voluntary speech control systems
have typically involved comparisons of speech outputs
with varying linguistic content, Por ejemplo, conectado
speech of different linguistic complexities (Dhanjal,
Handunnetthi, patel, & Inteligente, 2008; Blank, Scott, Murphy,
Warburton, & Inteligente, 2002) or pseudowords of varying
length and phonetic complexity (Papoutsi et al., 2009;
Bohland & Guenther, 2006).
To address the ubiquitous behavior of voluntary mod-
ulation of vocal expression in speech, while holding the
linguistic content of the utterance constant, we carried
out an fMRI experiment in which we studied the neural
correlates of controlled voice change in adult speakers of
English performing spoken impressions. The participants,
who were not professional voice artists or impressionists,
repeatedly recited the opening lines of a familiar nursery
rhyme under three different speaking conditions: normal
voice (norte), impersonating individuals (I), and impersonat-
ing regional and foreign accents of English (A). The nature
of the task is similar to the kinds of vocal imitation used in
everyday conversation, Por ejemplo, in reporting the
speech of others during storytelling. We aimed to uncover
the neural systems supporting changes in the way speech
is articulated, in the presence of unvarying linguistic con-
tent. We predicted that left-dominant orofacial motor
control centers, including the left IFG, insula, and motor
corteza, as well as auditory processing sites in superior
temporal cortex, would be important in effecting change to
speaking style and monitoring the auditory consequences.
Beyond this, we aimed to measure whether the goal of
1876
Revista de neurociencia cognitiva
Volumen 25, Número 11
D
oh
w
norte
yo
oh
a
d
mi
d
F
r
oh
metro
yo
yo
/
/
/
/
j
F
/
t
t
i
t
.
:
/
/
h
t
t
pag
:
/
D
/
oh
metro
w
i
norte
t
oh
pag
a
r
d
C
mi
.
d
s
F
i
r
oh
yo
metro
v
mi
h
r
C
pag
h
a
d
i
i
r
r
mi
.
C
C
t
.
oh
metro
metro
/
j
mi
oh
d
tu
C
norte
oh
/
C
a
norte
r
a
t
r
i
t
i
C
C
yo
mi
mi
–
pag
–
d
pag
d
2
F
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
oh
9
C
6
norte
8
_
5
a
/
_
j
0
oh
0
C
4
norte
2
7
_
a
pag
_
d
0
0
b
4
y
2
gramo
7
tu
.
mi
pag
s
t
d
oh
F
norte
b
0
y
8
S
METRO
mi
I
pag
t
mi
metro
l
i
b
b
mi
r
r
a
2
r
0
2
i
3
mi
s
/
j
t
F
/
.
tu
s
mi
r
oh
norte
1
7
METRO
a
y
2
0
2
1
the vocal modulation—to imitate a generic speaking style/
accent versus a specific vocal identity—would modulate
the activation of the speech production network and/or
its connectivity with brain regions processing information
relevant to individual identities.
MÉTODOS
Participantes
Twenty-three adult speakers of English (seven women;
edad media = 33 años 11 meses) were recruited who
were willing to attempt spoken impersonations. All had
healthy hearing and no history of neurological incidents
nor any problems with speech or language (self-reported).
Although some had formal training in acting and music,
none had worked professionally as an impressionist or voice
artist. The study was approved by the University College
London Department of Psychology Ethics Committee.
Design and Procedure
Participants were asked to compile in advance lists of 40 indi-
viduals and 40 accents they could feasibly attempt to imper-
sonate. These could include any voice/accent with which
they were personally familiar, from celebrities to family
miembros (p.ej., “Sean Connery,” “Carlyʼs Mum”). Asimismo,
the selected accents could be general or specific (p.ej.,
“French” vs. “Blackburn”).
Functional imaging data were acquired on a Siemens
Avanto 1.5-T scanner (Siemens AG, Erlangen, Alemania)
in a single run of 163 echo-planar whole-brain volumes
(repetition time = 8 segundo, acquisition time = 3 segundo, echo
time = 50 mseg, flip angle = 90°, 35 axial slices, 3 mm ×
3 mm × 3 mm in-plane resolution). A sparse-sampling
rutina (Edmister, Talavage, Ledden, & Weisskoff, 1999;
Hall et al., 1999) was employed, with the task performed
during a 5-sec silence between volumes.
Había 40 trials of each condition: normal voice
(norte), impersonating individuals (I), impressions of re-
gional and foreign accents of English (A), and a rest base-
line (B). The mean list lengths across participants were
36.1 (DE = 5.6) for condition I and 35.0 (DE = 6.9) para
A (a nonsignificant difference; t(1, 22) = .795, pag = .435).
When submitted lists were shorter than 40, some names/
accents were repeated to fill the 40 ensayos. Condition order
was pseudorandomized, with each condition occurring
once in every four trials. Participants wore electrodynamic
headphones fitted with an optical microphone (MR Confon
GmbH, Magdeburg, Alemania). Using MATLAB (Matemáticas,
Cª, Natick, MAMÁ) with the Psychophysics Toolbox exten-
sión (Brainard, 1997) and a video projector (Eiki Inter-
national, Cª, Rancho Santa Margarita, California), visual prompts
(“Normal Voice,” “Break” or the name of a voice/accent,
as well as a “Start speaking” instruction) were delivered
onto a front screen, viewed via a mirror on the head coil.
Each trial began with a condition prompt triggered by
the onset of a whole-brain acquisition. En 0.2 sec after
the start of the silent period, the participant was prompted
to start speaking and to cease when the prompt dis-
appeared (3.8 sec later). In each speech production trial,
participants recited the opening line from a familiar nurs-
ery rhyme, such as “Jack and Jill went up the hill,” and were
reminded that they should not include person-specific
catchphrases or catchwords. This controlled for the
linguistic content of the speech across the conditions.
Spoken responses were recorded using Audacity (audacity.
sourceforge.net). After the functional run, a high-resolution
T1-weighted anatomical image was acquired (HIRes
MP-RAGE, 160 sagittal slices, voxel size = 1 mm3). El
total time in the scanner was around 35 mín..
Acoustic Analysis of Spoken Impressions
Because of technical problems, auditory recordings were
only available for 13 Participantes. El 40 tokens from the
three speech conditions—Normal Voice, Impersonations,
and Accents—was entered into a repeated-measures
ANOVA with Condition as a within-subject factor for each
of the following acoustic parameters: (i) duración (segundo), (ii)
intensidad (dB), (iii) mean F0 (Hz), (iv) minimum F0 (Hz),
(v) maximum F0 (Hz), standard deviation of F0 (Hz), (vi)
spectral center of gravity (Hz), y (vii) spectral standard
desviación (Hz). Three Bonferroni-corrected post hoc
paired t tests compared the individual conditions. Mesa 1
illustrates the results of these analyses, y figura 1 illus-
trates the acoustic properties of example trials from each
speech condition (taken from the same participant).
fMRI Analysis
Data were preprocessed and analyzed using SPM5 (Well-
come Trust Centre for Neuroimaging, Londres, Reino Unido). Func-
tional images were realigned and unwarped, coregistered
with the anatomical image, normalized using parameters
obtained from unified segmentation of the anatomical
imagen, and smoothed using a Gaussian kernel of 8 mm
FWHM. At the first level, the condition onsets were mod-
eled as instantaneous events coincident with the prompt to
speak, using a canonical hemodynamic response function.
Contrast images were calculated to describe each of the
four conditions (norte, I, A and B), each speech condition com-
pared with rest (N > B, I > B, A > B), each impression
condition compared with normal speech (I > N, A > N),
and the comparison of impression conditions (I > A).
These images were entered into second-level, one-sample
t tests for the group analyses.
The results of the conjunction analyses are reported at
a voxel height threshold of p < .05 (corrected for family-
wise error). All other results are reported at an uncor-
rected voxel height threshold of p < .001, with a cluster
extent correction of 20 voxels applied for a whole-brain α
of p < .001 using a Monte Carlo simulation (with 10,000
McGettigan et al.
1877
D
o
w
n
l
o
a
d
e
d
f
r
o
m
l
l
/
/
/
/
j
t
t
f
/
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
f
/
.
t
u
s
e
r
o
n
1
7
M
a
y
2
0
2
1
ANOVA
t Test N vs. V
t Test N vs. A
t Test V vs. A
Table 1. Acoustic Correlates of Voice Change during Spoken Impressions
Acoustic Parameter
Mean
Normal
Mean
Voices
Mean
Accents
Duration (sec)
2.75
3.10
2.98
Intensity (dB)
Mean F0 (Hz)
Min F0 (Hz)
Max F0 (Hz)
SD F0 (Hz)
Spec CoG (Hz)
Spec SD (Hz)
47.4
155.9
94.4
625.0
117.3
2100
1647
51.3
207.2
104.9
667.6
129.9
2140
1579
51.3
186.3
102.1
628.5
114.7
2061
1553
F
9.96
49.25
24.11
3.71
1.28
1.62
0.38
2.24
Sig.
.006
.000
.000
.039
.295
.227
.617
.128
t
3.25
10.15
5.19
2.20
1.31
1.26
Sig.
.021
.000
.001
.144
.646
.694
t
3.18
7.62
4.87
2.18
0.10
Sig.
.024
.000
.001
.149
1.00
.240
1.00
t
Sig.
2.51
.081
0.88
1.00
3.89
.006
0.77
1.00
2.15
3.30
1.49
.158
.019
.485
0.37
1.00
1.17
.789
0.39
2.05
1.00
.188
0.89
1.00
F0 = fundamental frequency, SD = standard deviation, Spec = spectral, CoG = center of gravity. Significance levels are Bonferroni-corrected (see
Methods), with significant effects shown in bold.
iterations) implemented in MATLAB (Slotnick, Moo, Segal,
& Hart, 2003).
Conjunction analyses of second-level contrast images
were performed using the null conjunction approach
(Nichols, Brett, Andersson, Wager, & Poline, 2005). Using
the MarsBaR toolbox (Brett, Anton, Valabregue, & Poline,
2002), spherical ROIs (4 mm radius) were built around
the peak voxels—parameter estimates were extracted
from these ROIs to construct plots of activation.
A psychophysiological interaction (PPI) analysis was
used to investigate changes in connectivity between the
conditions I and A. In each participant, the time course of
activation was extracted from spherical volumes of inter-
est (4 mm radius) built around the superior temporal
peaks in the group contrast I > A (right middle/anterior
STS: [54 −3 −15], right posterior STS: [57 −36 12], izquierda
posterior STS: [−45 −60 15]). A PPI regressor described
the interaction between each volume of interest and a
psychological regressor for the contrast of interest (I >
A)—this modeled a change in the correlation between
activity in these STS seed regions and the rest of the
brain across the two conditions. The PPIs from each seed
region were evaluated in a first-level model that included
the individual physiological and psychological time
courses as covariates of no interest. A random-effects,
one-sample t test assessed the significance of each PPI
en el grupo (voxelwise threshold: pag < .001, corrected
cluster threshold: p < .001).
Post hoc pairwise t tests using SPSS (version 18.0; IBM,
Armonk, NY) compared condition-specific parameter esti-
mates (N vs. B and I vs. A) within the peak voxels in the
voice change conjunction ((I > norte) ∩ (A > N)). To maintain
independence and avoid statistical “double-dipping,” an
iterative, hold-one-out approach was used in which the
peak voxels for each participant were defined from a group
statistical map of the conjunction ((I > N) ∩ (A > N))
using the other 22 Participantes. These subject-specific
peak locations were used to extract condition-specific
parameter estimates from 4-mm spherical ROIs built
around the peak voxel (using MarsBaR). Paired t tests
were run using a corrected α level of .025 (to correct
for two tests in each ROI).
The anatomical locations of peak and subpeak voxels
(al menos 8 mm apart) were labeled using the SPM Anatomy
Toolbox (versión 18; Eickhoff et al., 2005).
RESULTS AND DISCUSSION
Brain Regions Supporting Voice Change
Areas of activation common to the three speech output
conditions compared with a rest baseline (B; (N > B) ∩
(I > B) ∩ (A > B)) comprised a speech production net-
work of bilateral motor and somatosensory cortex, SMA,
tu
s
mi
r
oh
norte
1
7
METRO
a
y
2
0
2
1
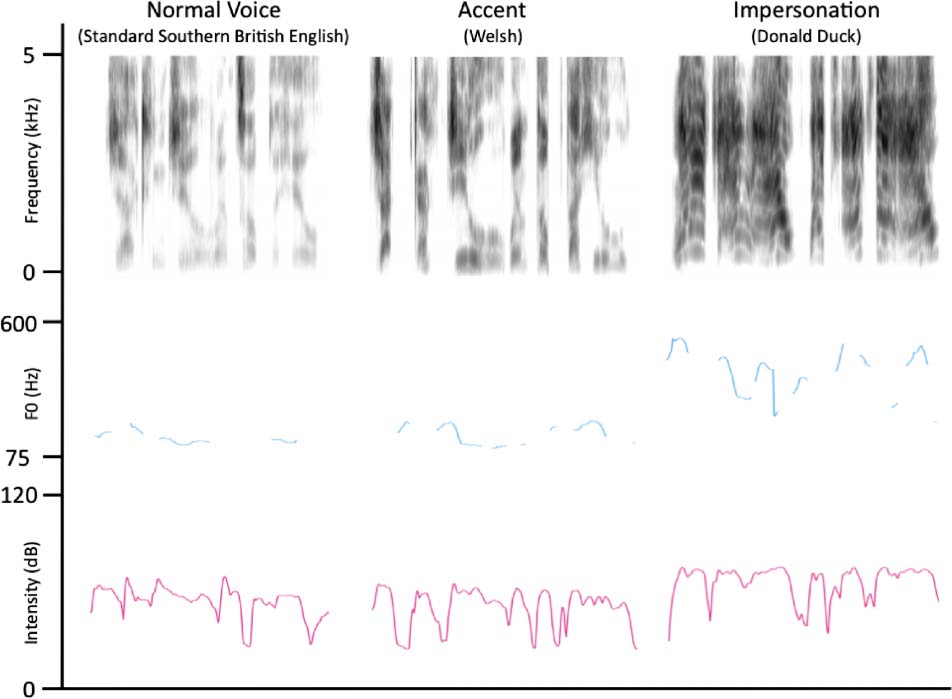
Cifra 1. Examples of the phrase “Jack and Jill went up the hill”
spoken by a single participant in the conditions Normal Voice, Accents,
and Impersonations. Top: A spectrogram of frequency against time
(where darker shading indicates greater intensity). Middle: El
fundamental frequency (F0) profile across each utterance. Bottom:
The intensity contour in decibels.
1878
Revista de neurociencia cognitiva
Volumen 25, Número 11
D
oh
w
norte
yo
oh
a
d
mi
d
F
r
oh
metro
yo
yo
/
/
/
/
j
t
t
F
/
i
t
.
:
/
/
h
t
t
pag
:
/
D
/
oh
metro
w
i
norte
t
oh
pag
a
r
d
C
mi
.
d
s
F
i
r
oh
yo
metro
v
mi
h
r
C
pag
h
a
d
i
i
r
r
mi
.
C
C
t
.
oh
metro
metro
/
j
mi
oh
d
tu
C
norte
oh
/
C
a
norte
r
a
t
r
i
t
i
C
C
yo
mi
mi
–
pag
–
d
pag
d
2
F
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
oh
9
C
6
norte
8
_
5
a
/
_
j
0
oh
0
C
4
norte
2
7
_
a
pag
_
d
0
0
b
4
y
2
gramo
7
tu
.
mi
pag
s
t
d
oh
F
norte
b
0
y
8
S
METRO
mi
I
pag
t
mi
metro
l
i
b
b
mi
r
r
a
2
r
0
2
i
3
mi
s
/
j
/
F
.
t
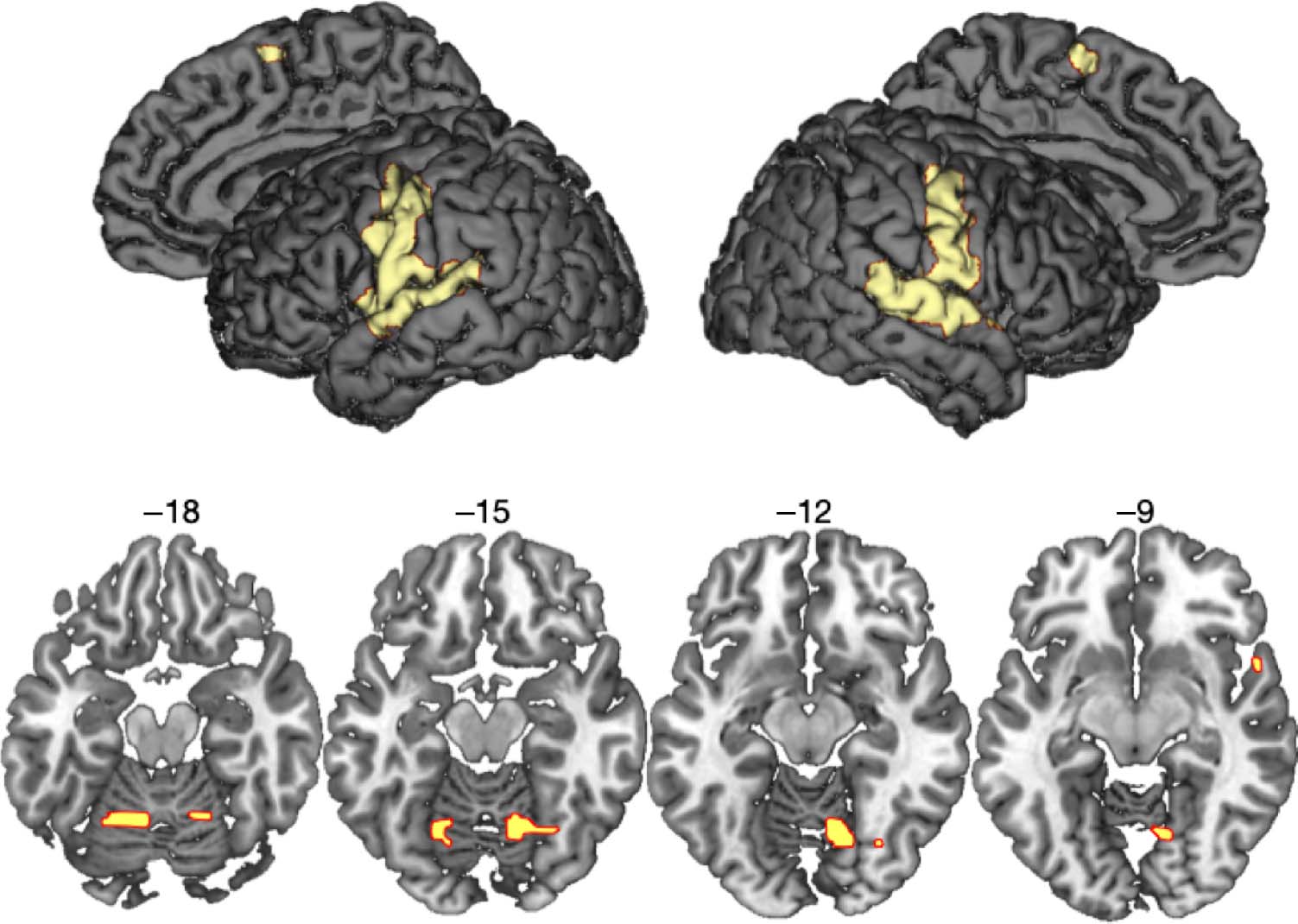
Cifra 2. Activations common
to the three speech conditions
(Normal, Impersonations,
and Accents) comparado con
a rest baseline (voxel height
threshold p < .05, FWE-
corrected). Numbers indicate
the z coordinate in Montreal
Neurological Institute (MNI)
stereotactic space.
D
o
w
n
l
o
a
d
e
d
f
r
o
m
l
l
/
/
/
/
j
f
/
t
t
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
/
.
t
f
u
s
e
r
o
n
1
7
M
a
y
2
0
2
1
superior temporal gyrus (STG), and cerebellum (Figure 2
and Table 2; Simmonds, Wise, Dhanjal, & Leech, 2011;
Tourville & Guenther, 2011; Tourville, Reilly, &
Guenther, 2008; Bohland & Guenther, 2006; Riecker
et al., 2005; Blank et al., 2002; Wise, Greene, Buchel, &
Scott, 1999). Activation common to the voice change
conditions (I and A) compared with normal speech ((I >
norte) ∩ (A > N)) was found in left anterior insula, extending
laterally onto the IFG (orbital and opercular parts) and on
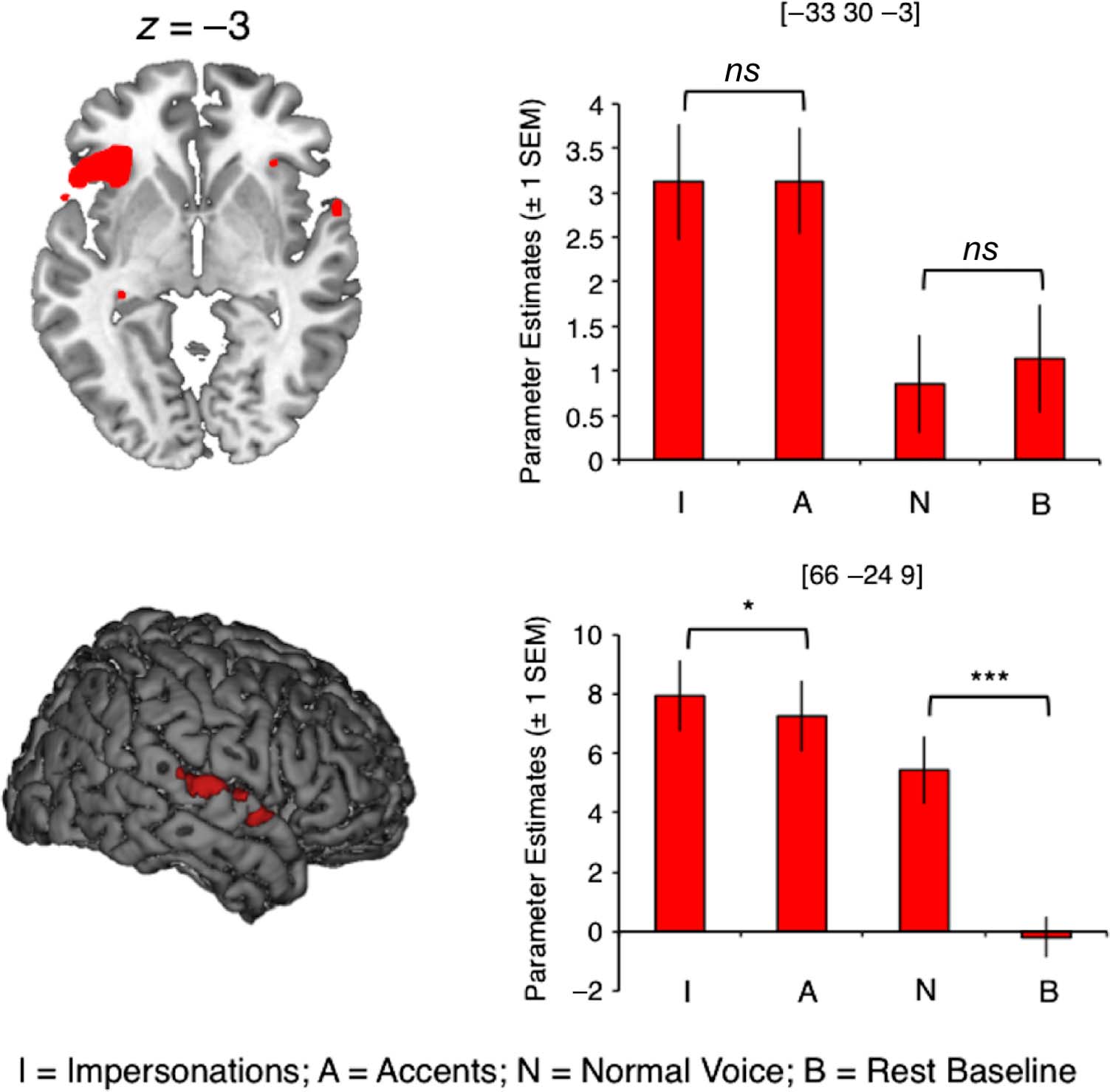
the right STG (Cifra 3 and Table 3). Planned post hoc
comparisons showed that responses in the left frontal sites
were equivalent for impersonations and accents (two-
cola, paired t test; t(22) = −0.068, corrected p = 1.00) y
during normal speech and rest (t(22) = 0.278, corregido
Mesa 2. Activation Common to the Three Speech Output Conditions
Contrast
No. of Voxels
Region
X
y
z
t
z
All Speech > Rest ((N > B) ∩
(I > B) ∩ (A > B))
963
Left postcentral gyrus/STG/precentral gyrus
−48 −15
39 14.15 7.07
Coordinate
852
Right STG/precentral gyrus/postcentral gyrus
Left cerebellum (lobule VI)
Left SMA
63 −15
3 13.60 6.96
−24 −60 −18
7.88 5.38
−3 −3
63
7.77 5.34
Right cerebellum (lobule VI), right fusiform gyrus
12 −60 −15
7.44 5.21
Right/left calcarine gyrus
Left calcarine gyrus
Right lingual gyrus
Right area V4
Left calcarine gyrus
Left thalamus
Right calcarine gyrus
3 −93
6
7.41 5.19
−15 −93 −3
6.98 5.02
15 −84 −3
6.73 4.91
30 −69 −12
6.58 4.84
−9 −81
0
6.17 4.65
−12 −24 −3
6.15 4.64
15 −69
12
6.13 4.63
21
20
34
35
5
7
1
3
2
2
Conjunction null analysis of all speech conditions (Normal, Impersonations, and Accents) compared with rest. Voxel height threshold p < .05 (FWE- corrected). Coordinates indicate the position of the peak voxel from each significant cluster, in MNI stereotactic space. McGettigan et al. 1879 p = 1.00). The right STG, in contrast, was significantly more active during impersonations than accents (two- tailed, paired t test; t(22) = 2.69, Bonferroni-corrected p = .027) and during normal speech compared with rest (t(22) = 6.64, corrected p < .0001). Thus, we demon- strate a partial dissociation of the inferior frontal/insular and sensory cortices, where both respond more during impressions than in normal speech, but where the STG shows an additional sensitivity to the nature of the voice change task—that is, whether the voice target is asso- ciated with a unique identity. Acoustic analyses of the impressions from a subset of participants (n = 13) indicated that the conditions in- volving voice change resulted in acoustic speech signals that were significantly longer, more intense, and higher in fundamental frequency (roughly equivalent to pitch) than normal speech. This may relate to the right-lateralized temporal response during voice change, as previous work has shown that the right STG is engaged during judg- ments of sound intensity (Belin et al., 1998). The right temporal lobe has also been associated with processing nonlinguistic information in the voice, such as speaker identity (von Kriegstein, Kleinschmidt, Sterzer, & Giraud, 2005; Kriegstein & Giraud, 2004; von Kriegstein, Eger, Kleinschmidt, & Giraud, 2003; Belin, Zatorre, & Ahad, 2002; Belin, Zatorre, Lafaille, Ahad, & Pike, 2000) and emotion (Schirmer & Kotz, 2006; Meyer, Zysset, von Cramon, & Alter, 2005; Wildgruber et al., 2005), although these re- sults tend to implicate higher-order regions such as the STS. The neuropsychology literature has described the im- portance of the left IFG and anterior insula in voluntary speech production (Kurth, Zilles, Fox, Laird, & Eickhoff, 2010; Dronkers, 1996; Broca, 1861). Studies of speech production have identified that the left posterior IFG and insula are sensitive to increasing articulatory complex- ity of spoken syllables (Riecker, Brendel, Ziegler, Erb, & Ackermann, 2008; Bohland & Guenther, 2006), but not to the frequency with which those syllables occur in every- day language (Riecker et al., 2008), suggesting involvement in the phonetic aspects of speech output rather than higher- order linguistic representations. Ackermann and Riecker (2010) suggest that insula cortex may actually be associated with more generalized control of breathing, which could be voluntarily modulated to maintain the sustained and finely controlled hyperventilation required to produce con- nected speech. In finding that the left IFG and insula can influence the way we speak, as well as what we say, we have also shown that they are not just coding abstract linguistic Figure 3. Brain regions supporting voice change. Bar plots show parameter estimates extracted from spherical ROIs centered on peak voxels. Annotations show the results of planned paired-sample t tests (two-tailed, with Bonferroni correction; *p < .05, ***p < .0001, ns = nonsignificant). Coordinates are in MNI space. D o w n l o a d e d f r o m l l / / / / j f / t t i t . : / / h t t p : / D / o m w i n t o p a r d c e . d s f i r o l m v e h r c p h a d i i r r e . c c t . o m m / j e o d u c n o / c a n r a t r i t i c c l e e - p - d p d 2 f 5 / 1 2 1 5 / 1 1 8 1 7 / 5 1 1 8 9 7 4 5 6 / 0 1 7 4 7 7 o 9 c 6 n 8 _ 5 a / _ j 0 o 0 c 4 n 2 7 _ a p _ d 0 0 b 4 y 2 g 7 u . e p s t d o f n b 0 y 8 S M e I p T e m L i b b e r r a 2 r 0 2 i 3 e s / j . f / t u s e r o n 1 7 M a y 2 0 2 1 1880 Journal of Cognitive Neuroscience Volume 25, Number 11 Table 3. Neural Regions Recruited during Voice Change (Null Conjunction of Impersonations > Normal and Accents > Normal)
Contrast
No. de
Voxels
Region
Impressions > Normal Speech
180
LIFG (pars orb., pars operc.)/insula
((I > N) ∩ (A > N))
1
19
17
16
4
9
3
6
1
1
2
4
1
4
2
Left temporal pole
Right thalamus
Right STG
Right hippocampus
Left thalamus
Left thalamus
Left hippocampus
Right insula
Right STG
Left hippocampus
Right STG
Right temporal pole
Left hippocampus
Right caudate nucleus
Left cerebellum (lobule VI)
Coordinate
X
−33
−54
3
66
33
−12
−27
−15
33
63
−24
66
60
−15
21
−24
y
30
15
−6
−24
−45
−6
−21
−21
27
−3
−39
−9
6
−42
12
−60
z
−3
−9
9
9
3
12
−9
−15
0
3
9
6
−6
12
18
−18
t
z
8.39
5.56
7.48
7.44
7.30
7.17
7.11
6.80
6.65
6.59
6.45
6.44
6.44
6.42
6.30
6.20
6.10
5.22
5.21
5.15
5.10
5.07
4.94
4.87
4.85
4.78
4.78
4.78
4.77
4.71
4.66
4.62
Voxel height threshold p < .05 (FWE-error corrected). Coordinates indicate the position of the peak voxel from each significant cluster, in MNI
stereotactic space. LIFG = left IFG; pars orb. = pars orbitalis; pars operc. = pars opercularis.
elements of the speech act. In agreement with Ackermann
and Riecker (2010), we suggest that these regions may also
play a role in more general aspects of voluntary vocal con-
trol during speech, such as breathing and modulation of
pitch. In line with this, our acoustic analysis shows that
both accents and impressions were produced with longer
durations, higher pitches, and greater intensity, all of
which are strongly dependent on the way that breathing
is controlled (MacLarnon & Hewitt, 1999, 2004).
Effects of Target Specificity: Impersonations
versus Accents
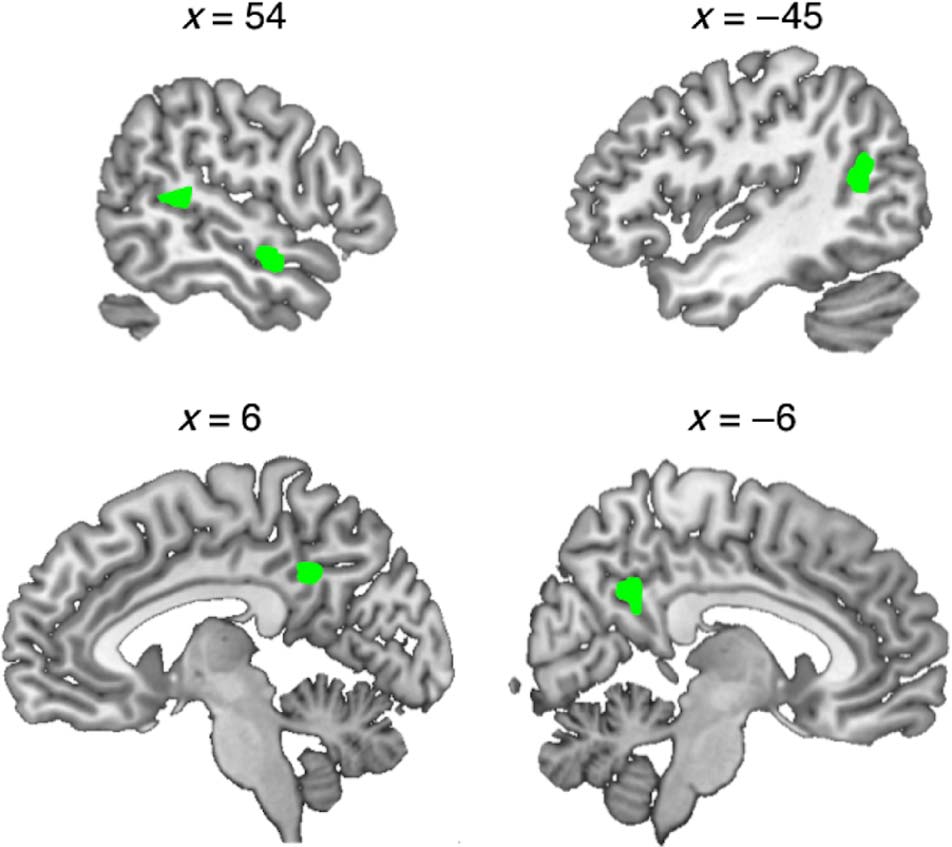
A direct comparison of the two voice change conditions
(I > A) showed increased activation for specific imper-
sonations in right middle/anterior STS, bilateral posterior
STS extending to angular gyrus (AG) on the left, and pos-
terior midline sites on cingulate cortex and precuneus
(Cifra 4 and Table 4; the contrast A > I gave no signifi-
cant activations). Whole-brain analyses of functional con-
nectivity revealed areas that correlated more positively
with the three sites on STS during impersonations than
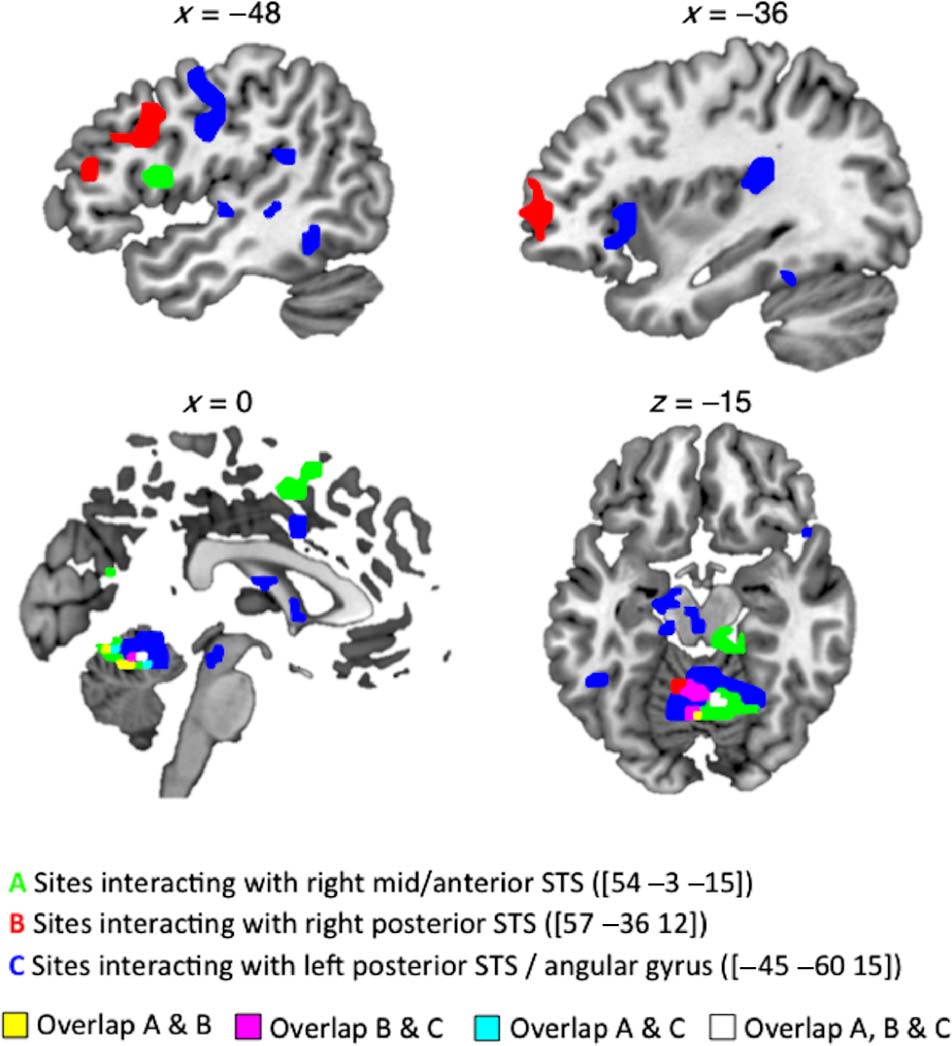
during accents (Cifra 5 and Table 5). Strikingly, all three
temporal seed regions showed significant interactions
with areas typically active during speech perception and
tu
s
mi
r
oh
norte
1
7
METRO
a
y
2
0
2
1
Cifra 4. Greater activation for the production of specific
impersonations (I) than for accents (A). Coordinates are in MNI space.
Voxel height threshold p < .001, cluster threshold p < .001 (corrected).
McGettigan et al.
1881
D
o
w
n
l
o
a
d
e
d
f
r
o
m
l
l
/
/
/
/
j
t
t
f
/
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
t
.
f
/
Table 4. Brain Regions Showing Greater Activation during Specific Impersonations
Contrast
No. of Voxels
Region
Impersonation > Accents
29
24
66
32
Right STS
Left STS
Left middle cingulate cortex
Right STG
Coordinate
X
54
−45
−6
57
y
−3
−60
−48
−36
z
−15
15
36
12
t
5.79
4.62
4.48
4.35
z
4.46
3.82
3.73
3.66
Voxel height threshold p < .001 (uncorrected), cluster threshold p < .001 (corrected). Coordinates indicate the position of the peak voxel from each
significant cluster, in MNI stereotactic space.
D
o
w
n
l
o
a
d
e
d
f
r
o
m
production, with notable sites of overlap in sensorimotor
lobules V and VI of the cerebellum and left STG. How-
ever, there were also indications of differentiation of
the three connectivity profiles. The left posterior STS
seed region interacted with a speech production network
including bilateral pre/postcentral gyrus, bilateral STG,
and cerebellum (Price, 2010; Bohland & Guenther,
2006; Blank et al., 2002), as well as left-lateralized areas
of anterior insula and posterior medial planum tempor-
ale. In contrast, the right anterior STS seed interacted
with the left opercular part of the IFG and left SMA,
and the right posterior STS showed a positive interaction
with the left inferior frontal gyrus/sulcus, extending to the
left frontal pole. Figure 5 illustrates the more anterior dis-
tribution of activations from the right-lateralized seed
regions and the region of overlap from all seed regions
in cerebellar targets.
Our results suggest that different emphases can be
distinguished between the roles performed by these
superior temporal and inferior parietal areas in spoken
impressions. In a meta-analysis of the semantic system,
Binder, Desai, Graves, and Conant (2009) identified the
AG as a high-order processing site performing the re-
trieval and integration of concepts (Binder et al., 2009).
The posterior left STS/AG activation has been implicated
in the production of complex narrative speech and writing
(Brownsett & Wise, 2010; Awad, Warren, Scott, Turkheimer,
& Wise, 2007; Spitsyna, Warren, Scott, Turkheimer, & Wise,
2006) and, along with the precuneus, in the perceptual pro-
cessing of familiar names, faces, and voices (von Kriegstein
et al., 2005; Gorno-Tempini et al., 1998) and person-related
semantic information (Tsukiura, Mochizuki-Kawai, & Fujii,
2006). We propose a role for the left STS/AG in accessing
and integrating conceptual information related to target
voices, in close communication with the regions planning
and executing articulations. The increased performance
demands encountered during the emulation of specific
voice identities, which requires accessing the semantic
knowledge of individuals, results in greater engagement
of this left posterior temporo-parietal region and its en-
hanced involvement with the speech production network.
The interaction of right-lateralized sites on STS with
left, middle, and inferior frontal gyrus and pre-SMA suggests
higher-order roles in planning specific impersonations.
Blank et al. (2002) found that the left pars opercularis of
the IFG and left pre-SMA exhibited increased activation
during production of speech of greater phonetic and lin-
guistic complexity and variability and linked the pre-SMA
to the selection and planning of articulations. In studies of
voice perception, the typically right-dominant temporal
voice areas in STS show stronger activation in response to
vocal sounds of human men, women, and children com-
pared with nonvocal sounds (Belin & Grosbras, 2010; Belin
et al., 2000, 2002; Giraud et al., 2004), and right-hemisphere
lesions are clinically associated with specific impair-
ments in familiar voice recognition (Hailstone, Crutch,
Vestergaard, Patterson, & Warren, 2010; Lang, Kneidl,
l
l
/
/
/
/
j
t
t
f
/
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
f
.
/
t
u
s
e
r
o
n
1
7
M
a
y
2
0
2
1
Figure 5. Regions of the brain showing stronger positive correlations
during the production of impersonations compared with accents. The
seed regions were defined using from the contrast Impersonations >
Accents. Voxel height threshold p < .001 (uncorrected), cluster
threshold p < .001 (corrected).
1882
Journal of Cognitive Neuroscience
Volume 25, Number 11
Table 5. Brain Regions Showing an Enhanced Positive Correlation with Temporo-parietal Cortex during Impersonations, Compared
with Accents
Seed Region
Right anterior STS
Left posterior STS
No. of
Voxels
Target Region
66
98
77
21
65
48
37
346
287
306
163
35
33
138
26
21
23
37
Left STG
Right/left cerebellum
Right cerebellum
Left IFG (pars operc.)
Right calcarine gyrus
Left/right pre-SMA
Right STG
Left rolandic operculum/left STG/STS
Left/right cerebellum
Right STG/IFG
Right/left caudate nucleus and right thalamus
Left thalamus/hippocampus
Left hippocampus
Left pre/postcentral gyrus
Left/right mid cingulate cortex
Left IFG/STG
Right postcentral gyrus
Left insula/IFG
Right posterior STS
225
Left middle/IFG
40
41
20
57
29
31
Left STS
Right postcentral gyrus/precuneus
Right IFG
Left/right cerebellum
Left lingual gyrus
Left STG
Coordinate
x
−60
9
15
−48
15
−3
63
−33
0
66
15
−12
−15
−51
−9
−57
54
−36
−39
−66
27
42
−24
−18
−63
y
−12
−63
−36
9
−72
3
−33
−30
−48
−6
21
−27
−15
−6
9
12
−12
21
54
−36
−45
18
−48
−69
−6
z
6
−12
−18
12
18
51
9
18
−15
−3
3
−6
−21
30
39
3
36
3
0
6
57
27
−24
3
0
t
6.16
5.86
5.84
5.23
5.03
4.84
4.73
6.23
6.15
5.88
5.72
5.22
4.97
4.79
4.37
4.27
4.23
4.14
5.90
5.63
5.05
4.79
4.73
4.64
4.35
z
4.65
4.50
4.49
4.17
4.06
3.95
3.88
4.68
4.64
4.51
4.43
4.17
4.03
3.92
3.67
3.61
3.58
3.52
4.52
4.38
4.07
3.92
3.89
3.83
3.66
Voxel height threshold p < .001 (uncorrected), cluster threshold p < .001 (corrected). Coordinates indicate the position of the peak voxel from each
significant cluster, in MNI stereotactic space. pars operc. = pars opercularis.
Hielscher-Fastabend, & Heckmann, 2009; Neuner &
Schweinberger, 2000). Investigations of familiarity and
identity in voice perception have implicated both poste-
rior and anterior portions of the right superior temporal
lobe, including the temporal pole, in humans and ma-
caques (von Kriegstein et al., 2005; Kriegstein & Giraud,
2004; Belin & Zatorre, 2003; Nakamura et al., 2001). We
propose that the right STS performs acoustic imagery of
target voice identities in the Impersonations condition, and
that these representations are used on-line to guide the
modified articulatory plans necessary to effect voice change
via left-lateralized sites on the inferior and middle frontal
gyri. Although there were some acoustic differences be-
tween the speech produced under these two conditions—
the Impersonations had a higher mean and standard
deviation of pitch than the Accents (see Table 1)—we
would expect to see sensitivity to these physical properties
in earlier parts of the auditory processing stream, that is,
STG rather than STS. Therefore, the current results offer
the first demonstration that right temporal regions pre-
viously implicated in the perceptual processing and rec-
ognition of voices may play a direct role in modulating
vocal identity in speech.
The flexible control of the voice is a crucial element of
the expression of identity. Here, we show that changing the
characteristics of vocal expression, without changing the
linguistic content of speech, primarily recruits left anterior
insula and inferior frontal cortex. We propose that therapeutic
McGettigan et al.
1883
D
o
w
n
l
o
a
d
e
d
f
r
o
m
l
l
/
/
/
/
j
t
t
f
/
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
t
/
f
.
u
s
e
r
o
n
1
7
M
a
y
2
0
2
1
approaches targeting metalinguistic aspects of speech pro-
duction, such as melodic intonation therapy (Belin et al.,
1996) and respiratory training, could be beneficial in cases
of speech production deficits after injury to left frontal sites.
Our finding that superior temporal regions previously
identified with the perception of voices showed increased
activation and greater positive connectivity with frontal
speech planning sites during the emulation of specific
vocal identities offers a novel demonstration of a selective
role for these voice-processing sites in modulating the
expression of vocal identity. Existing models of speech
production focus on the execution of linguistic output
and monitoring for errors in this process (Hickok, 2012;
Price, Crinion, & Macsweeney, 2011; Tourville & Guenther,
2011). We suggest that noncanonical speech output need
not always form an error—for example, the convergence
on pronunciations observed in conversation facilitates
comprehension, interaction, and social cohesion (Garrod
& Pickering, 2004; Chartrand & Bargh, 1999). However,
there likely exists some form of task-related error monitor-
ing and correction when speakers attempt to modulate
how they sound, possibly along a predictive coding
mechanism that attempts to reduce the disparity between
predicted and actual behavior (Price et al., 2011; Friston,
2010; Friston & Price, 2001)—this could take place in the
right superior temporal cortex (although we note that
previous studies directly investigating the detection of
and compensation for pitch/time-shifted speech have
located this to bilateral posterior STG; Takaso, Eisner, Wise,
& Scott, 2010; Tourville et al., 2008). We propose to repeat
the current experiment with professional voice artists who
are expert at producing convincing impressions and pre-
sumably also skilled in self-report on, for example, perfor-
mance difficulty and accuracy. These trial-by-trial ratings
could be used to interrogate the brain regions engaged
when the task is more challenging to potentially uncover
a more detailed mechanistic explanation for the networks
identified for the first time in the current experiment.
We offer the first delineation of how speech produc-
tion and voice perception systems interact to effect con-
trolled changes of identity expression during voluntary
speech. This provides an essential step in understanding
the neural bases for the ubiquitous behavioral phenome-
non of vocal modulation in spoken communication.
Acknowledgments
This work was supported by a Wellcome Trust Senior Research
Fellowship (WT090961MA) awarded to S.K.S.
Reprint requests should be sent to Carolyn McGettigan, Royal
Holloway University of London, Egham Hill, Egham, Surrey
TW20 0EX, United Kingdom, or via e-mail: Carolyn.McGettigan@
rhul.ac.uk.
REFERENCES
Ackermann, H., & Riecker, A. (2010). The contribution of
the insula to motor aspects of speech production:
A review and a hypothesis. Brain and Language, 89,
320–328.
Awad, M., Warren, J. E., Scott, S. K., Turkheimer, F. E., & Wise,
R. J. S. (2007). A common system for the comprehension
and production of narrative speech. Journal of Neuroscience,
27, 11455–11464.
Aziz-Zadeh, L., Sheng, T., & Gheytanchi, A. (2010). Common
premotor regions for the perception and production of
prosody and correlations with empathy and prosodic ability.
Plos One, 5, e8759.
Bailly, G. (2003). Close shadowing natural versus synthetic
speech. International Journal of Speech Technology, 6, 11–19.
Belin, P., Fecteau, S., & Bedard, C. (2004). Thinking the voice:
Neural correlates of voice perception. Trends in Cognitive
Sciences, 8, 129–135.
Belin, P., & Grosbras, M.-H. (2010). Before speech: Cerebral
voice processing in infants. Neuron, 65, 733–735.
Belin, P., McAdams, S., Smith, B., Savel, S., Thivard, L., Samson, S.,
et al. (1998). The functional anatomy of sound intensity
discrimination. Journal of Neuroscience, 18, 6388–6394.
Belin, P., VanEeckhout, P., Zilbovicius, M., Remy, P., Francois, C.,
Guillaume, S., et al. (1996). Recovery from nonfluent aphasia
after melodic intonation therapy: A PET study. Neurology, 47,
1504–1511.
Belin, P., & Zatorre, R. J. (2003). Adaptation to speakerʼs voice
in right anterior temporal lobe. NeuroReport, 14, 2105–2109.
Belin, P., Zatorre, R. J., & Ahad, P. (2002). Human temporal-lobe
response to vocal sounds. Brain Research. Cognitive Brain
Research, 13, 17–26.
Belin, P., Zatorre, R. J., Lafaille, P., Ahad, P., & Pike, B. (2000).
Voice-selective areas in human auditory cortex. Nature, 403,
309–312.
Binder, J. R., Desai, R. H., Graves, W. W., & Conant, L. L. (2009).
Where is the semantic system? A critical review and meta-
analysis of 120 functional neuroimaging studies. Cerebral
Cortex, 19, 2767–2796.
Blank, S. C., Scott, S. K., Murphy, K., Warburton, E., & Wise, R. J.
(2002). Speech production: Wernicke, Broca and beyond.
Brain, 125, 1829–1838.
Bohland, J. W., & Guenther, F. H. (2006). An fMRI investigation
of syllable sequence production. Neuroimage, 32, 821–841.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial
Vision, 10, 433–436.
Brett, M., Anton, J. L., Valabregue, R., & Poline, J. B. (2002).
Region of interest analysis using an SPM toolbox. Paper
presented at the International Conference on Functional
Mapping of the Human Brain, Sendai, Japan.
Broca, P. (1861). Perte de la parole, ramollissement chronique,
et destruction partielle du lobe antérieur gauche du cerveau.
Bulletin de la Société Anthropologique, 2, 235–238.
Brownsett, S. L. E., & Wise, R. J. S. (2010). The contribution of
the parietal lobes to speaking and writing. Cerebral Cortex,
20, 517–523.
Cartei, V., Cowles, H. W., & Reby, D. (2012). Spontaneous
voice gender imitation abilities in adult speakers. Plos One, 7,
e31353.
Chartrand, T. L., & Bargh, J. A. (1999). The chameleon effect:
The perception-behavior link and social interaction. Journal
of Personality and Social Psychology, 76, 893–910.
Condon, W. S., & Ogston, W. D. (1967). A segmentation of
behavior. Journal of Psychiatric Research, 5, 221–235.
Cooke, M., & Lu, Y. (2010). Spectral and temporal changes
to speech produced in the presence of energetic and
informational maskers. Journal of the Acoustical Society
of America, 128, 2059–2069.
Dhanjal, N. S., Handunnetthi, L., Patel, M. C., & Wise, R. J.
(2008). Perceptual systems controlling speech production.
Journal of Neuroscience, 28, 9969–9975.
1884
Journal of Cognitive Neuroscience
Volume 25, Number 11
D
o
w
n
l
o
a
d
e
d
f
r
o
m
l
l
/
/
/
/
j
t
t
f
/
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
/
.
t
f
u
s
e
r
o
n
1
7
M
a
y
2
0
2
1
Dronkers, N. F. (1996). A new brain region for coordinating
speech articulation. Nature, 384, 159–161.
Edmister, W. B., Talavage, T. M., Ledden, P. J., & Weisskoff, R. M.
(1999). Improved auditory cortex imaging using clustered
volume acquisitions. Human Brain Mapping, 7, 89–97.
Eickhoff, S. B., Stephan, K. E., Mohlberg, H., Grefkes, C.,
Fink, G. R., Amunts, K., et al. (2005). A new SPM toolbox
for combining probabilistic cytoarchitectonic maps and
functional imaging data. Neuroimage, 25, 1325–1335.
Eriksson, E., Sullivan, K., Zetterholm, E., Czigler, P., Green, J.,
Skagerstrand, A., et al. (2010). Detection of imitated voices:
Who are reliable earwitnesses? International Journal of
Speech Language and the Law, 17, 25–44.
Friston, K. (2010). The free-energy principle: A unified brain
theory? Nature Reviews Neuroscience, 11, 127–138.
Friston, K. J., & Price, C. J. (2001). Dynamic representations
and generative models of brain function. Brain Research
Bulletin, 54, 275–285.
Garrod, S., & Pickering, M. J. (2004). Why is conversation so
easy? Trends in Cognitive Sciences, 8, 8–11.
Giles, H. (1973). Accent mobility: A model and some data.
Anthropological Linguistics, 15, 87–105.
Giles, H., Coupland, N., & Coupland, J. (1991). Accommodation
theory: Communication, context, and consequence. In
H. Giles, J. Coupland, & N. Coupland (Eds.), The contexts
of accommodation (pp. 1–68). New York: Cambridge
University Press.
Giraud, A. L., Kell, C., Thierfelder, C., Sterzer, P., Russ, M. O.,
Preibisch, C., et al. (2004). Contributions of sensory input,
auditory search and verbal comprehension to cortical
activity during speech processing. Cerebral Cortex, 14,
247–255.
Gorno-Tempini, M. L., Price, C. J., Josephs, O., Vandenberghe,
R., Cappa, S. F., Kapur, N., et al. (1998). The neural systems
sustaining face and proper-name processing. Brain: A
Journal of Neurology, 121, 2103–2118.
Groswasser, Z., Korn, C., Groswasser-Reider, I., & Solzi, P.
(1988). Mutism associated with buccofacial apraxia and
bihemispheric lesions. Brain and Language, 34, 157–168.
Hailstone, J. C., Crutch, S. J., Vestergaard, M. D., Patterson,
R. D., & Warren, J. D. (2010). Progressive associative
phonagnosia: A neuropsychological analysis. Neuropsychologia,
48, 1104–1114.
Hall, D. A., Haggard, M. P., Akeroyd, M. A., Palmer, A. R.,
Summerfield, A. Q., Elliott, M. R., et al. (1999). “Sparse”
temporal sampling in auditory fMRI. Human Brain Mapping,
7, 213–223.
Harrington, J., Palethorpe, S., & Watson, C. I. (2000). Does the
Queen speak the Queenʼs English? Elizabeth IIʼs traditional
pronunciation has been influenced by modern trends.
Nature, 408, 927–928.
Hickok, G. (2012). Computational neuroanatomy of speech
production. Nature Reviews Neuroscience, 13, 135–145.
Jurgens, U. (2002). Neural pathways underlying vocal control.
Neuroscience and Biobehavioral Reviews, 26, 235–258.
Jurgens, U., & von Cramon, D. (1982). On the role of the
anterior cingulate cortex in phonation: A case report.
Brain and Language, 15, 234–248.
Kappes, J., Baumgaertner, A., Peschke, C., & Ziegler, W. (2009).
Unintended imitation in nonword repetition. Brain and
Language, 111, 140–151.
Karpf, A. (2007). The human voice: The story of a remarkable
talent. London: Bloomsbury Publishing PLC.
Kriegstein, K. V., & Giraud, A. L. (2004). Distinct functional
substrates along the right superior temporal sulcus for the
processing of voices. Neuroimage, 22, 948–955.
Kurth, F., Zilles, K., Fox, P. T., Laird, A. R., & Eickhoff, S. B.
and integration within the human insula revealed by meta-
analysis. Brain Structure & Function, 214, 519–534.
Ladefoged, P. (2003). Validity of voice identification. Journal
of the Acoustical Society of America, 114, 2403.
Lang, C. J. G., Kneidl, O., Hielscher-Fastabend, M., &
Heckmann, J. G. (2009). Voice recognition in aphasic and
non-aphasic stroke patients. Journal of Neurology, 256,
1303–1306.
Lombard, É. (1911). Le signe de lʼélévation de la voix. Annales
des Maladies de LʼOreille et du Larynx, XXXVII, 101–109.
Lu, Y., & Cooke, M. (2009). Speech production modifications
produced in the presence of low-pass and high-pass filtered
noise. Journal of the Acoustical Society of America, 126,
1495–1499.
MacLarnon, A. M., & Hewitt, G. P. (1999). The evolution of
human speech: The role of enhanced breathing control.
American Journal of Physical Anthropology, 109, 341–363.
MacLarnon, A. M., & Hewitt, G. P. (2004). Increased breathing
control: Another factor in the evolution of human language.
Evolutionary Anthropology, 13, 181–197.
McFarland, D. H. (2001). Respiratory markers of conversational
interaction. Journal of Speech Language and Hearing
Research, 44, 128–143.
Meyer, M., Zysset, S., von Cramon, D. Y., & Alter, K. (2005).
Distinct fMRI responses to laughter, speech, and sounds
along the human peri-sylvian cortex. Brain Research.
Cognitive Brain Research, 24, 291–306.
Nakamura, K., Kawashima, R., Sugiura, M., Kato, T., Nakamura, A.,
Hatano, K., et al. (2001). Neural substrates for recognition of
familiar voices: A PET study. Neuropsychologia, 39, 1047–1054.
Neuner, F., & Schweinberger, S. R. (2000). Neuropsychological
impairments in the recognition of faces, voices, and personal
names. Brain and Cognition, 44, 342–366.
Nichols, T., Brett, M., Andersson, J., Wager, T., & Poline, J. B.
(2005). Valid conjunction inference with the minimum
statistic. Neuroimage, 25, 653–660.
Papoutsi, M., de Zwart, J. A., Jansma, J. M., Pickering, M. J.,
Bednar, J. A., & Horwitz, B. (2009). From phonemes to
articulatory codes: An fMRI study of the role of Brocaʼs area
in speech production. Cerebral Cortex, 19, 2156–2165.
Pardo, J. S. (2006). On phonetic convergence during conversational
interaction. Journal of the Acoustical Society of America, 119,
2382–2393.
Pardo, J. S., Gibbons, R., Suppes, A., & Krauss, R. M. (2012).
Phonetic convergence in college roommates. Journal of
Phonetics, 40, 190–197.
Pardo, J. S., & Jay, I. C. (2010). Conversational role influences
speech imitation. Attention Perception & Psychophysics, 72,
2254–2264.
Peschke, C., Ziegler, W., Kappes, J., & Baumgaertner, A.
(2009). Auditory-motor integration during fast repetition:
The neuronal correlates of shadowing. Neuroimage, 47,
392–402.
Pickering, M. J., & Garrod, S. (2007). Do people use language
production to make predictions during comprehension?
Trends in Cognitive Sciences, 11, 105–110.
Price, C. J. (2010). The anatomy of language: A review of 100
fMRI studies published in 2009. Annals of the New York
Academy of Sciences, 1191, 62–88.
Price, C. J., Crinion, J. T., & Macsweeney, M. (2011). A generative
model of speech production in Brocaʼs and Wernickeʼs areas.
Front Psychol, 2, 237.
Reiterer, S. M., Hu, X., Erb, M., Rota, G., Nardo, D., Grodd, W.,
et al. (2011). Individual differences in audio-vocal speech
imitation aptitude in late bilinguals: Functional neuro-imaging
and brain morphology. Frontiers in Psychology, 2, 271.
Riecker, A., Brendel, B., Ziegler, W., Erb, M., & Ackermann, H.
(2010). A link between the systems: Functional differentiation
(2008). The influence of syllable onset complexity and
McGettigan et al.
1885
D
o
w
n
l
o
a
d
e
d
f
r
o
m
l
l
/
/
/
/
j
f
/
t
t
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
f
/
.
t
u
s
e
r
o
n
1
7
M
a
y
2
0
2
1
syllable frequency on speech motor control. Brain and
Language, 107, 102–113.
Riecker, A., Mathiak, K., Wildgruber, D., Erb, M., Hertrich, I.,
Grodd, W., et al. (2005). fMRI reveals two distinct cerebral
networks subserving speech motor control. Neurology, 64,
700–706.
Schirmer, A., & Kotz, S. A. (2006). Beyond the right hemisphere:
Brain mechanisms mediating vocal emotional processing.
Trends in Cognitive Sciences, 10, 24–30.
Scott, S. K., Clegg, F., Rudge, P., & Burgess, P. (2006). Foreign
accent syndrome, speech rhythm and the functional
neuronatomy of speech production. Journal of
Neurolinguistics, 19, 370–384.
Sem-Jacobsen, C., & Torkildsen, A. (1960). Depth recording
and electrical stimulation in the human brain. In Estelle R.
Ramey and Desmond OʼDoherty (Eds.), Electrical studies
on the unanesthetized brain. New York.
Shockley, K., Sabadini, L., & Fowler, C. A. (2004). Imitation in
shadowing words. Perception & Psychophysics, 66, 422–429.
Simmonds, A. J., Wise, R. J. S., Dhanjal, N. S., & Leech, R.
(2011). A comparison of sensory-motor activity during speech
in first and second languages. Journal of Neurophysiology,
106, 470–478.
Simonyan, K., Ostuni, J., Ludlow, C. L., & Horwitz, B. (2009).
Functional but not structural networks of the human
laryngeal motor cortex show left hemispheric lateralization
during syllable but not breathing production. Journal of
Neuroscience, 29, 14912–14923.
Slotnick, S. D., Moo, L. R., Segal, J. B., & Hart, J. (2003). Distinct
prefrontal cortex activity associated with item memory and
source memory for visual shapes. Cognitive Brain Research,
17, 75–82.
Spitsyna, G., Warren, J. E., Scott, S. K., Turkheimer, F. E., &
Wise, R. J. S. (2006). Converging language streams in the
human temporal lobe. Journal of Neuroscience, 26,
7328–7336.
Sullivan, K. P. H., & Schlichting, F. (1998). A perceptual and
acoustic study of the imitated voice. Journal of the Acoustical
Society of America, 103, 2894.
Takaso, H., Eisner, F., Wise, R. J., & Scott, S. K. (2010).
The effect of delayed auditory feedback on activity in the
temporal lobe while speaking: A positron emission
tomography study. Journal of Speech Language and
Hearing Research, 53, 226–236.
Tourville, J. A., & Guenther, F. H. (2011). The DIVA model:
A neural theory of speech acquisition and production.
Language and Cognitive Processes, 26, 952–981.
Tourville, J. A., Reilly, K. J., & Guenther, F. H. (2008). Neural
mechanisms underlying auditory feedback control of speech.
Neuroimage, 39, 1429–1443.
Tsukiura, T., Mochizuki-Kawai, H., & Fujii, T. (2006).
Dissociable roles of the bilateral anterior temporal lobe in
face-name associations: An event-related fMRI study.
Neuroimage, 30, 617–626.
von Kriegstein, K., Eger, E., Kleinschmidt, A., & Giraud, A. L.
(2003). Modulation of neural responses to speech by
directing attention to voices or verbal content. Cognitive
Brain Research, 17, 48–55.
von Kriegstein, K., Kleinschmidt, A., Sterzer, P., & Giraud, A. L.
(2005). Interaction of face and voice areas during speaker
recognition. Journal of Cognitive Neuroscience, 17,
367–376.
Wildgruber, D., Riecker, A., Hertrich, I., Erb, M., Grodd, W.,
Ethofer, T., et al. (2005). Identification of emotional
intonation evaluated by fMRI. Neuroimage, 24, 1233–1241.
Wise, R. J., Greene, J., Buchel, C., & Scott, S. K. (1999).
Brain regions involved in articulation. Lancet, 353,
1057–1061.
D
o
w
n
l
o
a
d
e
d
f
r
o
m
l
l
/
/
/
/
j
t
t
f
/
i
t
.
:
/
/
h
t
t
p
:
/
D
/
o
m
w
i
n
t
o
p
a
r
d
c
e
.
d
s
f
i
r
o
l
m
v
e
h
r
c
p
h
a
d
i
i
r
r
e
.
c
c
t
.
o
m
m
/
j
e
o
d
u
c
n
o
/
c
a
n
r
a
t
r
i
t
i
c
c
l
e
e
-
p
-
d
p
d
2
f
5
/
1
2
1
5
/
1
1
8
1
7
/
5
1
1
8
9
7
4
5
6
/
0
1
7
4
7
7
o
9
c
6
n
8
_
5
a
/
_
j
0
o
0
c
4
n
2
7
_
a
p
_
d
0
0
b
4
y
2
g
7
u
.
e
p
s
t
d
o
f
n
b
0
y
8
S
M
e
I
p
T
e
m
L
i
b
b
e
r
r
a
2
r
0
2
i
3
e
s
/
j
.
/
t
f
u
s
e
r
o
n
1
7
M
a
y
2
0
2
1
1886
Journal of Cognitive Neuroscience
Volume 25, Number 11