Aceleración diagonal para matriz de covarianza
Adaptation Evolution Strategies
Y. Akimoto
University of Tsukuba, 1-1-1 Tennodai, Tsukuba, Japón
akimoto@cs.tsukuba.ac.jp
norte. Hansen
Inria, RandOpt Team, CMAP, Ecole Polytechnique, Palaiseau, Francia
nikolaus.hansen@inria.fr
https://doi.org/10.1162/evco_a_00260
Abstracto
We introduce an acceleration for covariance matrix adaptation evolution strategies
(CMA-ES) by means of adaptive diagonal decoding (dd-CMA). This diagonal accelera-
tion endows the default CMA-ES with the advantages of separable CMA-ES without
inheriting its drawbacks. Technically, we introduce a diagonal matrix D that expresses
coordinate-wise variances of the sampling distribution in DCD form. The diagonal ma-
trix can learn a rescaling of the problem in the coordinates within a linear number of
function evaluations. Diagonal decoding can also exploit separability of the problem,
pero, crucialmente, does not compromise the performance on nonseparable problems. El
latter is accomplished by modulating the learning rate for the diagonal matrix based on
the condition number of the underlying correlation matrix. dd-CMA-ES not only com-
bines the advantages of default and separable CMA-ES, but may achieve overadditive
speedup: it improves the performance, and even the scaling, of the better of default
and separable CMA-ES on classes of nonseparable test functions that reflect, arguably,
a landscape feature commonly observed in practice.
The article makes two further secondary contributions: we introduce two differ-
ent approaches to guarantee positive definiteness of the covariance matrix with active
CMA, which is valuable in particular with large population size; we revise the default
parameter setting in CMA-ES, proposing accelerated settings in particular for large
dimension.
All our contributions can be viewed as independent improvements of CMA-ES, todavía
they are also complementary and can be seamlessly combined. In numerical experi-
ments with dd-CMA-ES up to dimension 5120, we observe remarkable improvements
over the original covariance matrix adaptation on functions with coordinate-wise ill-
conditioning. The improvement is observed also for large population sizes up to about
dimension squared.
Palabras clave
Evolution strategies, covariance matrix adaptation, adaptive diagonal decoding, active
covariance matrix update, default strategy parameters.
1
Introducción
In real-world applications of continuous optimization involving simulations such as
physics or chemical simulations, the input-output relation between a candidate solu-
tion and its objective function value is barely expressible in explicit mathematical for-
mula. The objective function value is computed through a complex simulation with a
candidate solution as an input. In such scenarios, we gain the information of the prob-
lem only through the evaluation of the objective function value of a given candidate
Manuscrito recibido: 22 Enero 2019; revisado: 12 Abril 2019 y 7 Puede 2019; aceptado: 8 Puede 2019.
© 2019 Instituto de Tecnología de Massachusetts
Computación evolutiva 28(3): 405–435
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
solución. A continuous optimization of f : Rn → R is referred to as black-box continu-
ous optimization if we gain the information of the problem only through the evaluation
X (cid:3)→ f (X) of a given candidate solution x ∈ Rn.
Black-box continuous optimization arises widely in real world applications such
as model parameter calibration and design of robot controller. It often involves com-
putationally expensive simulation to evaluate the quality of candidate solutions. El
search cost of black-box continuous optimization is therefore the number of simula-
ciones, eso es, the number of objective function calls; and a search algorithm is desired
to locate good quality solutions with as few f -calls as possible. Practitioners need to
choose one or a few search algorithms to solve their problems and tune their hyperpa-
rameters based on the prior knowledge into their problems. Sin embargo, prior knowledge
is often limited in the black-box situation due to the black-box relation between x and
F (X). Por eso, algorithm selection, as well as hyperparameter tuning, is a tedious task
for practitioners who are typically not experts in search algorithms.
Covariance matrix adaptation evolution strategy (CMA-ES), developed by Hansen
and Ostermeier (2001), Hansen et al. (2003), Hansen and Kern (2004), and Jastrebski
and Arnold (2006), is recognized as a state-of-the-art derivative-free search algorithm
for difficult continuous optimization problems (Rios and Sahinidis, 2013). CMA-ES is
a stochastic and comparison-based search algorithm that maintains the multivariate
normal distribution as a sampling distribution of candidate solutions. The distribution
parameters such as the mean vector and the covariance matrix are updated at each itera-
tion based on the candidate solutions and their objective value ranking, so that the sam-
pling distribution will produce promising candidate solutions more likely in the next
algorithmic iteration. The update of the distribution parameters is partially found as the
natural gradient ascent on the manifold of the distribution parameter space equipped
with the Fisher metric (Akimoto et al., 2010; Glasmachers et al., 2010; Ollivier et al.,
2017), thereby revealing the connection to natural evolution strategies (Wierstra et al.,
2008; Sun et al., 2009; Glasmachers et al., 2010; Wierstra et al., 2014), whose parameter
update is derived explicitly from the natural gradient principle.
Invariance (Hansen, 2000; Hansen et al., 2011) is one of the governing principles of
the design of CMA-ES and the essence of its success on difficult continuous optimiza-
tion problems consisting of ruggedness, ill-conditioning, and nonseparability. CMA-ES
exhibits several invariance properties such as invariance to order preserving transfor-
mation of the objective function, invariance to translation, rotation, and coordinate-wise
scaling of the search space (Hansen and Auger, 2014). Invariance guarantees the algo-
rithm to work identically on an original problem and its transformed version. Thanks
to its invariance properties, CMA-ES works, after an adaptation phase, equally well on
separable and well-conditioned functions, which are easy for most search algorithms,
and on nonseparable and ill-conditioned functions produced by an affine coordinate
transformation of the former, which are considered difficult for many other search al-
gorithms. This also contributes to allow default hyperparameter values to depend solely
on the search space dimension and the population size, whereas many other search algo-
rithms need tuning depending on problem difficulties to make the algorithms efficient
(Karafotias et al., 2015).
Por otro lado, exploiting problem structure, si es posible, is beneficial for opti-
mization speed. Different variants of CMA-ES have been proposed to exploit problem
structure such as separability and limited variable dependency. They aim to achieve a
better scaling with the dimension (Knight and Lunacek, 2007; Ros and Hansen, 2008;
Akimoto et al., 2014; Akimoto and Hansen, 2016; Loshchilov, 2017). Sin embargo, they lose
406
Volumen de cálculo evolutivo 28, Número 3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
some of the invariance properties that CMA-ES has and compromise the performance
on problems where their specific, more or less restrictive assumptions on the problem
structure do not hold. Por ejemplo, the separable CMA-ES (Ros and Hansen, 2008) re-
duces the degrees of freedom of the covariance matrix from (n2 + norte)/2 to n by adapting
only the diagonal elements of the covariance matrix. It scales better in terms of internal
time and space complexity and in terms of number of function evaluations to adapt the
coordinate-wise variance of the search distribution. Good results are hence observed
on functions with weak variable dependencies. Sin embargo, unsurprisingly, the conver-
gence speed of the separable CMA is significantly deteriorated on nonseparable and
ill-conditioned functions, where the shape of the level sets of the objective function can
not be reasonably well approximated by the equiprobability ellipsoid defined by the
normal distribution with diagonal (co)variance matrix.
In this article, we aim to improve the performance of CMA-ES on a relatively wide
class of problems by exploiting problem structure, however crucially, without compro-
mising the performance on more difficult problems without this structure.1
The first mechanism we are concerned with is the so-called active covariance
matrix update, which was originally proposed for the (μ, λ)-CMA-ES with interme-
diate recombination (Jastrebski and Arnold, 2006), and later incorporated into the
(1 + 1)-CMA-ES (Arnold and Hansen, 2010). It utilizes unpromising solutions to ac-
tively decrease the eigenvalues of the covariance matrix. The active update consistently
improves the adaptation speed of the covariance matrix in particular on functions where
a low dimensional subspace dominates the function value. The positive definiteness of
the covariance matrix is, sin embargo, not guaranteed when the active update is utilized.
Practically, a small enough learning rate of the covariance matrix is sufficient to keep
the covariance matrix positive definite with overwhelming probability; sin embargo, nosotros
would like to increase the learning rate when the population size is large. We propose
two novel schemes that guarantee the positive definiteness of the covariance matrix,
so that we take advantage of the active update even when a large population size is
desired, p.ej., when the objective function evaluations are distributed on many CPUs or
when the objective function is rugged.
The main contribution of this article is the diagonal acceleration of CMA by means
of adaptive diagonal decoding, referred to as dd-CMA. We introduce a coordinate-wise
variance matrix, D2, of the sampling distribution alongside the positive definite sym-
metric matrix C, such that the resulting covariance matrix of the sampling distribution
is represented by DCD. We call D the diagonal decoding matrix. We update C with the
original CMA, whereas D is updated similarly to separable CMA. An important point
is that we want to update D faster than C, by setting higher learning rates for the D
update. Sin embargo, when C contains nonzero covariances, the update of D can result in
a drastic change of the sampling distribution and disturb the adaptation of C. To re-
solve this issue, we introduce an adaptive damping mechanism for the D update, entonces
that the difference (p.ej., Kullback-Leibler divergence) between the distributions before
and after the update remains sufficiently small. With this damping, D is updated as fast
as by separable CMA on a separable function if the correlation matrix of the sampling
distribution is close to the identity, and it suppresses the D update when the correlation
matrix is away from the identity; eso es, variable dependencies have been learned.
1Any covariance matrix, (cid:2), can be uniquely decomposed into (cid:2) = DCD, where D is a diagonal ma-
trix and C is a correlation matrix. The addressed problem class can be characterized in that for the best
problem approximation (cid:2) = DCD both matrices, C and D, have non-negligible condition number, say no less
than 100.
Volumen de cálculo evolutivo 28, Número 3
407
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
The update of D breaks the rotation invariance of the original CMA; hence, we lose
a mathematical guarantee of the original CMA that it performs identical on functions in
an equivalence group defined by this invariance property. The ultimate aim of this work
is to gain significant speed-up in some situations and to preserve the performance of the
original CMA in the worst case. Functions where we expect that the diagonally acceler-
ated CMA outperforms the original one have variables with different sensitivities, eso
es, coordinate-wise ill-conditioning. Such functions may often appear in practice, desde
variables in a black-box continuous optimization problem can have distinct meanings.
Diagonal acceleration however can even be superior to the optimal additive portfolio of
the original CMA and the separable CMA. We demonstrate in numerical experiments
that dd-CMA outperforms the original CMA not only on separable functions but also on
nonseparable ill-conditioned functions with coordinate-wise ill-conditioning that sep-
arable CMA cannot efficiently solve.
The last contribution is a set of improved and simplified default parameter settings
for the covariance matrix adaptation and for the cumulation factor for the so-called evo-
lution path. These learning rates, whose default values have been previously expressed
with independent formulas, are reformulated so that their dependencies are clearer. El
new default learning rates also improve the adaptation speed of the covariance matrix
on high dimensional problems without compromising stability.
The rest of this article is organized as follows. We introduce the original and sep-
arable CMA-ES in Section 2. The active update of the covariance matrix with positive
definiteness guarantee is proposed in Section 3. The adaptive diagonal decoding mech-
anism is introduced in Section 4. Sección 5 is devoted to explain the renewed default
hyperparameter values for the covariance matrix adaptation and provides an algorithm
summary of dd-CMA-ES and a link to publicly available Python code. Numerical ex-
periments are conducted in Section 6 to see how effective each component of CMA with
diagonal acceleration works in different situations. We conclude the article in Section 7.
2
Evolution Strategy with Covariance Matrix Adaptation
We summon up the (μw, λ)-CMA-ES consisting of weighted recombination, cumulative
step-size adaptation, and rank-one and rank-μ covariance matrix adaptation.
The CMA-ES maintains the multivariate normal distribution, norte (metro, σ 2DCD), dónde
m ∈ Rn is the mean vector that represents the center of the search distribution, σ ∈ R+ is
the so-called step-size that represents the scaling factor of the distribution spread, y
C ∈ Rn×n is a positive definite symmetric matrix that represents the shape of the distri-
bution ellipsoid. Though the covariance matrix of the sampling distribution is σ 2DCD,
we often call C the covariance matrix in the context of CMA-ES. In this article, we ap-
ply this terminology, and we will call σ 2DCD the covariance matrix of the sampling
distribution to distinguish them when necessary. The positive definite diagonal matrix
D ∈ Rn×n is regarded as a diagonal decoding matrix, which represents the scaling factor
of each design variable. It is fixed during the optimization, usually D = I, and does not
appear in the standard terminology. Sin embargo, it plays an important role in this article,
and we define the CMA-ES with D for the later modification.
2.1 Original CMA-ES
The CMA-ES repeats the following steps until it meets one or more termination criteria:
1. Sample λ candidate solutions, xi, independently from N (metro, σ 2DCD);
408
Volumen de cálculo evolutivo 28, Número 3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
2. Evaluate candidate solutions on the objective, F (xi ), and sort them in ascending
orden,2 F (x1:λ) ≤ · · · ≤ f (xλ:λ), where i : λ is the index of the i-th best candidate
solution among x1, . . . , xλ;
3. Update the distribution parameters, metro, pag , and C.
Sampling and Recombination
2.1.1
To generate candidate solutions, we compute the (unique, symmetric) square root of
(cid:2)√
the covariance matrix
. The candidate solutions are the affine
transformation of independent and standard normally distributed random vectors,
C obeying C(t ) =
(cid:3)
2
C
√
Czi ∼ N (0, C),
zi ∼ N (0, I),
√
yi =
xi = m(t ) + pag (t )D yi ∼ N (metro(t ), (pag (t ))2DCD).
(1)
The default population size is λ = 4 + (cid:8)3 ln n(cid:9). To reduce the time complexity per f –
call without compromising the performance, we compute the matrix decomposition
C(t ) =
iteration, where c1 and cμ are the
(βeig(c1
= 10n. Si
learning rates for the covariance matrix adaptation that appear later, and βeig
−1), the covariance matrix is re-
the learning rates are small enough (c1
garded as insignificantly changing in each iteration and we stall the decomposition.
+ cμ (cid:2) (2βeig)
+ cμ))−1
every teig
= max
(cid:3)
C
(cid:2)√
(cid:5)(cid:3)
1,
(cid:4)
(cid:2)
2
The mean vector m is updated by taking the weighted average of the promising
candidate directions,
metro(t+1) = m(t ) + cm
μ(cid:6)
Wisconsin (xi:λ − m),
(2)
where cm is the learning rate for the mean vector update, usually cm = 1. The number of
μ
promising candidate solutions are denoted by μ, y
i=1 are recombination weights
satisfying wi > 0 for i (cid:2) μ. A standard choice is wi ∝ ln λ+1
− ln i for i = 1, . . . , μ and
μ = (cid:8)λ/2(cid:9) y
(cid:2)
Wisconsin
(cid:7)
μ
(cid:3)
2
i=1 wi = 1.
yo=1
Step-Size Adaptation
2.1.2
The cumulative step-size adaptation (CSA) updates the step-size σ based on the length
of the evolution path that accumulates the mean shift normalized by the current distri-
bution covariance, eso es,3
pag(t+1)
pag
= (1 − cσ ) pag(t )
pag
+
(cid:8)
cσ (2 − cσ )μw
γσ
(t+1) = (1 − cσ )2γσ
(t ) + cσ (2 − cσ ),
μ(cid:6)
wi zi:λ,
yo=1
(3)
(4)
√
(cid:7)
C)
−1(xi:λ − m)/σ in this article whereas originally zi:λ =
2Ties, F (xi:λ) = · · · = f (xi+k−1:λ), are treated by redistributing the averaged recombination weights
k−1
l=0 wi+l/k to tied solutions xi:λ, . . . , xi+k−1:λ.
3When D is not the identity, (3) is not exactly equivalent to the original CSA (Hansen and Ostermeier,
2001): zi:λ = (D
(xi:λ − m)/pag . Este
difference results in rotating the second term of the RHS of (3) at each iteration with a different orthog-
onal matrix, and ends up in a different (cid:11) pσ (cid:11). Krause et al. (2016) have theoretically studied the effect
of this difference and argued that this systematic difference becomes small if the parameterization of
the covariance matrix of the sampling distribution is unique and it converges up to scale. If D is fixed,
the parameterization is unique. Later in this article, we update both D and C but we force the param-
eterization to be unique by Eqs. (34) y (35). Por eso, the systematic difference is expected to be small.
See Krause et al. (2016) for details.
DCD
√
−1
Volumen de cálculo evolutivo 28, Número 3
409
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
(cid:7)
μ
i=1 w2
where μw = 1/
i is the so-called variance effective selection mass, and cσ is the
inverse time horizon for the pσ update, also known as cumulation factor. The scalar
pag (cid:11)2/norte = 0.4
γσ
The log step-size is updated as
(t+1) is a correction factor for small t and converges to 1, where γσ
(0) = (cid:11) pag(0)
ln σ (t+1) = ln σ (t ) + cσ
dσ
(cid:9)
(cid:11)
(cid:11) pag(t+1)
pag
χn
(cid:10)
(cid:11)
−
(t+1)
γσ
,
(5)
where dσ is the damping factor for the σ update and χn =
is an ap-
proximation of the expected value of the norm of an n-dimensional standard normally
√
(cid:3)
. The default values for cσ and dσ are
distributed random vector,
+ 1
21n2
(cid:2)
(cid:2)
√
(cid:2)
1 − 1
norte
4norte
(cid:3)
n+1
2
(cid:3)
/(cid:2)
2(cid:2)
cσ = μw + 2
norte + μw + 5
norte
2
dσ = 1 + cσ + 2 máximo
0,
(cid:9)
(cid:12)
(cid:11)
− 1
.
μw − 1
norte + 1
(6)
(7)
The damping parameter dσ is introduced to stabilize the step-size adaptation when the
population size is large (Hansen and Kern, 2004). When the step-size becomes too small
(cid:3)
by accident or is initialized so, the norm of the evolution path will become O
,
which results in a quick increase of σ if dσ = 1 (Akimoto et al., 2008). For large μw,
the chosen damping factor dσ prevents an unreasonable increase of σ at the price of a
reduced convergence speed. In case of μw (cid:12) norte, the covariance matrix adaptation is the
main component decreasing the overall variance of the sampling distribution, mientras que la
CSA is still effective to increase σ when necessary.
μw/n
(cid:2)√
2.1.3 Covariance Matrix Adaptation
The covariance matrix C is updated by the following formula that combines rank-one
and rank-μ update
(cid:9)
C(t+1) =
1 − c1γc
(t+1) − cμ
Wisconsin
C(t )
(cid:11)
μ(cid:6)
yo=1
(cid:13)
D
−1 p(t+1)
C
+ c1
(cid:14) (cid:13)
D
−1 p(t+1)
C
(cid:14)
t
+ cμ
μ(cid:6)
yo=1
wi yi:λ yT
i:λ,
(8)
where c1 and cμ are the learning rates for the rank-one update (2nd term) and the rank-μ
update (3rd term), respectivamente, pc is the evolution path that accumulates the successive
mean movements, and γc is the correction factor for the rank-one update, cuales son
updated as
pag(t+1)
C
= (1 − cc ) pag(t )
C
+ hσ
(t+1)
(cid:8)
cc(2 − cc )μw
μ(cid:6)
yo=1
wiD yi:λ,
(t+1) = (1 − cc )2γc
γc
(t ) + hσ
(t+1)cc(2 − cc ),
(9)
(10)
4An elegant alternative to introducing γσ is to use cσ
(t ) = max(cσ , 1/t ) in place of cσ in Eq. (3), como-
suming the first t = 1. This resembles a simple average while t ≤ 1/cσ and only afterwards discounts
older information by the original decay of 1 − cσ .
410
Volumen de cálculo evolutivo 28, Número 3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
(t+1)
where cc is the inverse time horizon for the pc update. The Heaviside function hσ
is introduced to stall the update of pc if (cid:11) pσ (cid:11) is large, es decir., when the step-size is rapidly
increasing. It is defined as
⎧
⎪⎨
⎪⎩
(t+1) =
hσ
1 si (cid:11) pag(t+1)
pag
(cid:11)2/γσ
(t+1) <
0 otherwise.
(cid:19)
2 + 4
n + 1
(cid:20)
n
(11)
The default parameters for c1, cμ, and cc are smaller than one and presented later.
2.2
Separable Covariance Matrix Adaptation
The separable covariance matrix adaptation (sep-CMA; Ros and Hansen, 2008) adapts
only the coordinate-wise variance of the sampling distribution, that is, the diagonal
elements of the covariance matrix in the same way as Eq. (8), but with larger learning
rates. In our notation scheme, we keep C to be the identity and describe sep-CMA by
updating D. The update of coordinate k follows
(cid:9)
[D(t+1)]2
k,k
= [D(t )]2
k,k
1 − c1γc
(t+1) − cμ
+ c1[ p(t+1)
c
k/[D(t )]2
]2
k,k
+ cμ
μ(cid:6)
i=1
μ(cid:6)
i=1
wi
(cid:11)
wi [zi:λ]2
k
.
(12)
The learning rates c1 and cμ are set differently from those used for the C update.
One advantage of the separable CMA is that all operations can be done in linear
time per f -call. Therefore, it is promising if f -calls are cheap. The other advantage is
that one can set the learning rate greater than those used for the C update, since the de-
grees of freedom of the covariance matrix of the sampling distribution is n, rather than
n(n + 1)/2. The adaptation speed of the covariance matrix is faster than for the original
CMA. However, if the problem is nonseparable and has strong variable dependencies,
adapting the coordinate-wise scaling is not enough to make the search efficient. More
−1, is not well approx-
concisely, if the inverse Hessian of the objective function, Hess(f )
imated by a diagonal matrix, the convergence speed will be O(1/Cond(D2Hess(f ))),
which is empirically observed on convex quadratic functions as well as theoretically
deduced in Akimoto et al. (2018). In practice, it is rarely known in advance whether
the separable CMA is appropriate or not. Ros and Hansen (2008) propose to use the
separable CMA for hundred times dimension function evaluations and then switch to
the original CMA afterwards. Such an algorithm has been benchmarked in Ros (2009),
where the first 1 + 100n/
λ iterations are used for the separable CMA.
√
3 Active Covariance Matrix Update with Guarantee of Positive
Definiteness
Active covariance matrix adaptation (referred to as Active-CMA; Jastrebski and Arnold,
2006) utilizes the information of unpromising solutions, xi:λ for i > μ, to update the co-
variance matrix. The modification is rather simple. We prepare λ recombination weights
(Wisconsin )λ
i=1 for the active covariance matrix update, where wi are no longer restricted to be
positivo. Por ejemplo, the recombination weights used in Jastrebski and Arnold (2006)
Volumen de cálculo evolutivo 28, Número 3
411
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
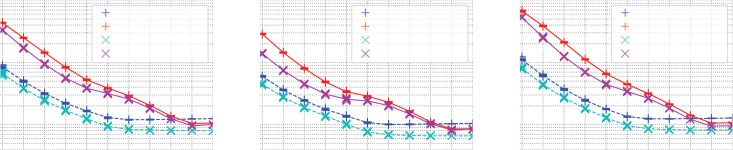
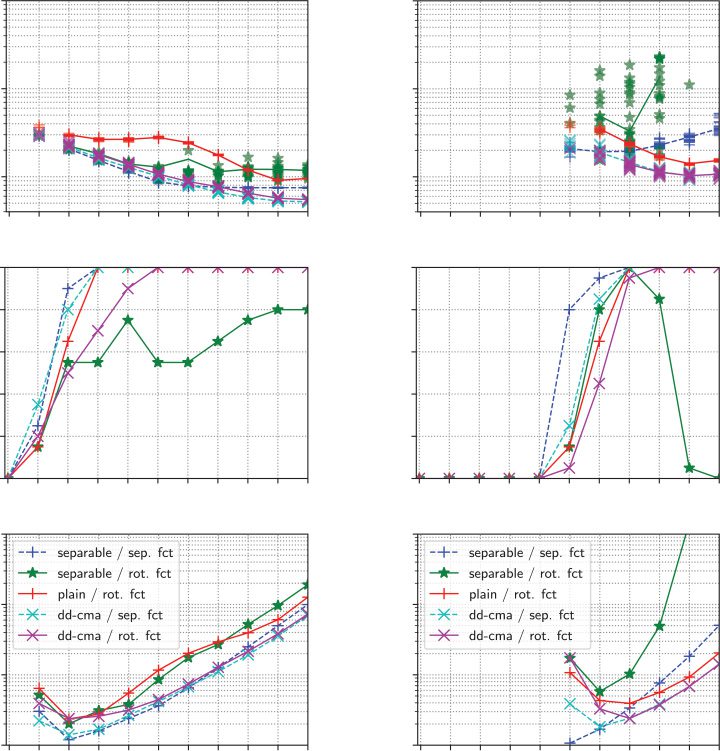
Cifra 1: Levelset of three convex quadratic functions xTHx with Hessian H of condi-
tion number 30. Cigar type: H = diag(30, 30, 1), Ellipsoid type: H = diag(1,
30, 30),
Discus type: H = diag(1, 1, 30).
√
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
(13)
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
son
⎧
⎪⎨
⎪⎩
wi =
1/μ
(i (cid:2) μ)
(μ < i (cid:2) λ − μ)
0
−1/μ (λ − μ < i).
The update formula (8) is then replaced with
λ(cid:6)
⎛
C(t+1) =
⎜
⎝1 − c1γc
(t+1) − cμ
⎞
⎟
⎠ C(t )
wi
(cid:13)
D
−1 p(t+1)
c
+ c1
i=1
(cid:14) (cid:13)
D
−1 p(t+1)
c
(cid:14)
T
+ cμ
λ(cid:6)
i=1
wi yi:λ yT
i:λ,
(14)
where shaded areas depict the difference to (8). The only difference is that we use all λ
candidate solutions to update the covariance matrix with positive and negative recom-
bination weights.5
Each component of the covariance matrix adaptation, rank-one update, rank-μ up-
date, and active update, produces complementary effects. The rank-one update of the
covariance matrix (the second term on the RHS of Eq. (14); Hansen and Ostermeier,
2001) accumulates the successive steps of the distribution mean and increases the eigen-
values of the covariance matrix in the direction of the successive movements. It excels
at learning one long axis of the covariance matrix, and is effective on functions with a
subspace of a relatively small dimension where the function value is less sensitive than
in its orthogonal subspace. Figure 1a visualizes an example of such function. See also
Figure 7 in Hansen and Auger (2014) for numerical results. On the other hand, since the
update is always of rank one, the learning rate c1 needs to be sufficiently small to keep
the covariance matrix regular and stable.
5As of 2018, many implementations of CMA-ES feature the active update of C and it should be con-
sidered as default.
412
Evolutionary Computation Volume 28, Number 3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
The rank-μ update (the third term on the RHS of Eq. (14) with positive wi; Hansen
et al., 2003) utilizes the information of μ successful candidate solutions in a different way
than the rank-one update. It computes the empirical covariance matrix of successful
mutation steps yi. The update matrix is with probability one of rank min(n, μ), allowing
to set a relatively large learning rate cμ. It reduces the number of iterations to adapt the
covariance matrix when λ (cid:12) 1.
Both rank-one and rank-μ update try to increase the variances in the subspace of
successful mutation steps. The eigenvalues corresponding to unsuccessful mutation
steps only passively fade out. The active update actively decreases such eigenvalues.
It consistently accelerates covariance matrix adaptation, and the improvement is par-
ticularly pronounced on functions with a small number of dominating eigenvalues of
the Hessian of the objective function. Figure 1c is an example of such function.
(cid:7)
− cμ
A disadvantage of the active update with negative recombination weights such as
Eq. (13) is to have no guarantee of the positive definiteness of the covariance matrix
anymore. It is easy to see that the rank-one and rank-μ update of CMA in Eq. (8) guar-
antee that the minimal eigenvalue of C(t+1) is no smaller than the minimal eigenvalue of
μ
C(t ) times 1 − c1
i=1 wi, since the second and third terms only increase the eigen-
values. However, the introduction of negative recombination weights can violate the
positive definiteness because the third term may decrease the minimum eigenvalue ar-
bitrarily. Jastrebski and Arnold (2006) set a sufficiently small learning rate for the active
update; that is, the absolute values of the negative recombination weights sum up to a
smaller value than one. It will prevent the covariance matrix from being non-positive
with high probability, but it does not guarantee positive definiteness. Moreover, it be-
comes ineffective when the population size is relatively large and a greater learning
rate is desired.
Krause and Glasmachers (2015) apply the active update with positive definiteness
guarantee by introducing the exponential covariance matrix update, called xCMA. In-
stead of updating the covariance matrix in an additive way as in Eq. (14), the covariance
matrix is updated as
C(t+1) =
C(t ) exp ((cid:3))
C(t ),
(15)
where (cid:3) is a symmetric matrix. Since the eigenvalues of the matrix exponential are
eδi where δi are the eigenvalues of (cid:3), the positive definiteness is naturally guaranteed.
Arnold and Hansen (2010) achieve the positive definiteness guarantee in the (1 + 1)-
CMA-ES by rescaling the negative recombination weights depending on the norm of
unsuccessful mutation steps (cid:11)z(cid:11). In this article, we introduce two strategies that are
both considered as generalization of this idea to the (μw, λ)-CMA-ES.6
(cid:8)
(cid:8)
3.1 Method 1: Scaling Down the Update Factor
To guarantee the positive definiteness of the covariance matrix, we rescale the update
factor of the covariance matrix so that the changes of the minimum eigenvalue of the
6There are variants of CMA-ES that update a factored matrix A satisfying C = AAT (e.g., eNES by
Sun et al., 2009). No matter how A is updated, the positive semidefiniteness of C is guaranteed since
AAT is always positive semidefinite. However this approach has a potential drawback that a nega-
tive update may end up increasing a variance. To see this, consider the case A ← A(I − ηeeT ), where
e is some vector and η > 0 represents the learning rate times the recombination weight. Entonces, the co-
variance matrix follows C ← A(I − ηeeT )2AT. This update shrinks a variance if η is sufficiently small
(η < 1/(cid:11)e(cid:11)2); however, it increases the variance if η is large (η > 1/(cid:11)mi(cid:11)2). Por eso, a negative update with
a long vector e and/or a large η will cause an opposite effect. Por lo tanto, the factored matrix update is
not a conclusive solution to the positive definiteness issue.
Volumen de cálculo evolutivo 28, Número 3
413
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
covariance matrix is bounded. We start by introducing the rescaling of unpromising
soluciones,
⎧
⎪⎪⎨
⎪⎪⎩
and analogously,
⎧
⎪⎪⎨
⎪⎪⎩
Wisconsin (cid:3) 0
Wisconsin (cid:3) 0
zi:λ
√
yi:λ
√
˜zi:λ =
(16)
˜yi:λ
=
norte
(cid:11)zi:λ(cid:11)
yi:λ wi < 0, n (cid:11)zi:λ(cid:11) zi:λ wi < 0. This rescaling results in projecting unpromising solutions onto the surface of the hyper- ellipsoid defined by yTC−1 y = n. By this projection we achieve three desired effects. First, the update becomes bounded which makes it easier to control positive definite- ness. Second, short steps are elongated, enhancing their effect in the update. Third, long steps are shortened, reducing their effect in the update. The two latter effects counter the correlation between rank and length of steps in unfavorable directions. For any given unfavorable direction, longer steps in this direction are most likely ranked worse than shorter steps. With these scaled solutions, the covariance matrix is updated as (cid:27)(cid:13) (cid:14) (cid:13) (cid:9) (cid:14) C(t+1) = C(t ) + α(t ) D −1 p(t+1) c D −1 p(t+1) c T − γc (t+1)C(t ) c1 (cid:27) wi ˜yi:λ ˜yT i:λ − C(t ) (cid:28)(cid:11) , + cμ λ(cid:6) i=1 (cid:28) (17) where shaded areas highlight the difference to (14) and α(t ) (cid:2) 1 is the scaling factor to guarantee the positive definiteness of the covariance matrix. Note that if α(t ) = 1, it is equivalent to Eq. (14) except for the rescaling of the unpromising samples. Importantly, the rescaling of unpromising solutions does not affect the stationarity of the parameter update; that is, E[C(t+1) | C(t )] = C(t ) under a random function such as f (x) ∼ U (0, 1). This is shown as follows. First, given p(t ) c ∼ N (0, γc (t )DC(t )D), it is easy to see that p(t+1) (t+1)DC(t )D). Second, using E[zzT/(cid:11)z(cid:11)2] = I/n (Lemma 1 of Heijmans, (cid:29) (cid:7) (cid:3) (cid:2) (cid:7) 1999) we have E C(t ). Finally, combining them, we obtain E[C(t+1) | C(t )] = C(t ). i=1 wi ˜yi:λ ˜yT i:λ ∼ N (0, γc λ i=1 wi | C(t ) = (cid:30) λ c The main idea is to scale down, if necessary, the update of the covariance matrix by setting α(t ) < 1 in (17). To provide a better intuition, we start by considering the case teig for every iteration t. Equation (17) can be written as (cid:30)√ = 1; that is, C(t ) = 2 C √ √ C(t+1) = (cid:29) I + α(t )Z(t ) C with Z(t ) = c1 (cid:27)(cid:13)√ −1 C D −1 p(t+1) c (cid:14) (cid:13)√ −1 C D −1 p(t+1) c (cid:14)T − γc (t+1)I + cμ C, (cid:28) (18) (cid:29) wi λ(cid:6) i=1 ˜zi:λ ˜zT i:λ − I (cid:30) . (19) Then, the scaling down parameter α(t ) in Eq. (18) is taken so that I + α(t )Z(t ) is positive definite. Then, with maximum and minimum eigenvalue of a matrix A denoted by d1(A) and dn(A), respectively, we have that (cid:29) I + α(t )Z(t ) C (cid:4) dn(I + α(t )Z(t ))C, d1(I + α(t )Z(t ))C (cid:4) (20) (cid:30)√ √ C 414 Evolutionary Computation Volume 28, Number 3 l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . / / e d u e v c o a r t i c e - p d l f / / / / 2 8 3 4 0 5 1 8 5 8 9 7 3 e v c o _ a _ 0 0 2 6 0 p d / . f b y g u e s t t o n 0 7 S e p e m b e r 2 0 2 3 Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies where A (cid:4) B mean that A − B is positive semidefinite (i.e., all eigenvalues are non- negative)7 for any two square matrices A and B. Moreover, dn(I + α(t )Z(t )) = 1 + α(t )dn(Z(t )). Therefore, if α(t ) < 1/(cid:11)dn(Z(t ))(cid:11), the resulting covariance matrix is guaran- teed to be positive definite. (cid:3) 1), let t be the iteration at which the last eigen decom- For the general case (teig position was performed, i.e., C(t ) = . For iterations k ∈ [t, t + teig), we store the in- termediate update matrix Z(k). The covariance matrix is updated only when the eigen decomposition is required, i.e., at iteration t + teig, as √ C 2 (cid:31) I + α(t+teig ) √ C t+teig −1(cid:6) √ C. Z(k) C(t+teig ) = k=t (21) Analogously to the above argument, the resulting covariance matrix is positive definite if the inside of the brackets is positive definite. We set the scaling down parameter as (cid:9) (cid:11) α(t+teig ) = min 0.75 (cid:2) (cid:7)t+teig k=t −1 ! !dn , 1 (cid:3)! ! . Z(k) (22) The first argument guarantees that the minimum eigenvalue of C(t+teig ) is greater than or equal to 1/4th of the minimum eigenvalue of C(t ). More concisely, we have C(t+teig ) (cid:4) 4 C(t ). The last argument, which is the most frequent case in practice, implies that the 1 covariance matrix update does not need to be scaled down. 3.2 Method 2: Scaling Down Negative Weights An alternative way to guarantee the positive definiteness of the covariance matrix is to scale down the sum of the absolute values of the negative weights, combined with the projection of unpromising solutions introduced above. We use the same update formula (21), but α(t+teig ) = 1. 1/teig > c1
(cid:7)
λ
+ cμ
The positive definiteness of the covariance matrix is guaranteed under the condition
|Wisconsin|. Más precisamente, we have the following claim.
|Wisconsin|, then C(t+teig ) (cid:4)
i=1 wi + ncμ
(cid:2)
1 − teig
i: Wisconsin <0
(cid:7)
i=1 wi + ncμ
(cid:2)
c1
i: <0
(cid:7)
(cid:7)
+
λ
+ cμ
(cid:3)(cid:3)
(cid:7)
Theorem 3.1: If 1> c1
cμ
i=1 wi + ncμ
i: Wisconsin <0 (cid:7) λ |wi| C(t ). = 1. Using the fact that self Proof of Theorem 3.1: First, we consider case teig outer product vvT a vector v is matrix rank 1 with only nonzero eigenvalue of (cid:11)v(cid:11)2, have (cid:9) (cid:11) C(t+1) (cid:4) 1 − c1 − cμ wi C(t ) cμ λ(cid:6) i =1 (cid:6) i: wi <0 |wi| n yi:λ yT i:λ (cid:11)zi:λ(cid:11)2 ⎡ (cid:9) √ C =⎣ 1 cμ (cid:11) wi I <0 n|wi| zi:λ zT i:λ (cid:11)zi:λ(cid:11)2 ⎤ ⎦ √ C 7Some references (e.g., Harville (2008)) use term “positive semidefinite matrix” for matrix with positive and zero eigenvalues “non-negative definite used matrices non- negative eigenvalues, whereas in other these terms are non-negative eigenvalues. In this article, apply latter terminology. Evolutionary Computation Volume 28, Number 3 415 l D o w n o a d e d f r o m h t t p : > 1 también. This completes the proof.
(cid:5)
i )λ
We show how to construct the recombination weights so that they satisfy the suffi-
cient condition of Theorem 3.1 como sigue. Dejar (w(cid:14)
i=1 be the predefined weights that are
nonincreasing. Without loss of generality, we assume that the first μ weights are posi-
tive and sum to one. The recombination weights are wi = w(cid:14)
(cid:3) 0 and wi = αw(cid:14)
i
for w(cid:14)
i < 0, where α ∈ (0, 1]. Then, the sufficient condition in Theorem 3.1 reads 1/teig >
−1, as sat-
|w(cid:14)
|. It holds if we set for example teig < (c1
c1
(cid:2)
i
= max
(βeig(c1
1,
isfied by the default choice teig
− (c1
α = 1/teig
(cid:7)
ncμ
+ cμ + (n − 1)cμα
i for w(cid:14)
+ cμ))
+ cμ)
, and
i: wi <0
(23)
(cid:7)
(cid:5)(cid:3)
+ cμ)
|w(cid:14)
|
i
−1
(cid:4)
.
i: wi <0
i
Then, it is guaranteed that C(t+teig ) (cid:4) 1
n C(t ).
This method simpler than the described in Section 3.1 since does not
require an additional eigenvalue computation. However, to guarantee positive def-
initeness this way, we bound unrealistic worst case where all unpromising can-
didate solutions are sampled on a line. Therefore, scaling down factor set much
smaller value actually needed practice. Figure 2 visualizes correc-
tion α under our choice of default pre-weights and learning rates described
in 5. The sum negative recombination weights needs decrease as the
population size increases. For n (cid:3) 320, less 0.1 for λ n1.5. Unless the
internal computational time becomes critical bottleneck, prefer de-
scribed over 3.2.
3.3 Choice Recombination Weights
We first review rationale weights. The
default weights, ln λ+1
− i (cid:2)>0
(cid:7)
i:w(cid:14)
i >0
|w(cid:14)
i
|w(cid:14)
i
|)2
|2
y
μ−
w
=
(
i:w(cid:14)
i <0
(cid:7)
i:w(cid:14)
i <0
|w(cid:14)
i
|w(cid:14)
i
|)2
|2
.
(26)
The learning rates c1 and cμ may be computed depending on the above quantities.
The default values for are discussed in Section 5. The recombination
weights wi set as follows
⎧
wi =⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
w(cid:14)
i(cid:7)
j :w(cid:14)
j>0
w(cid:14)
i(cid:7)
j :w(cid:14)
j <0
|w(cid:14)
j
|
|w(cid:14)
j
|
× min
(cid:19)
1 + c1
cμ
, 1 + 2μ−
w
μw + 2
(cid:20)
for i with w(cid:14)
i
(cid:3) 0,
for i with w(cid:14)
i < 0.
(27)
The positive recombination weights are unchanged from the default settings
without active CMA. They are approximately proportional to the positive half of the
optimal recombination weights. However, this is not the case for the negative recom-
bination weights. The optimal recombination weights are symmetric about zero; that
is, wi = −wλ−i+1, whereas our negative weights tend to level out for the following rea-
sons. The above-mentioned quality gain results consider only the mean update. The
obtained optimal values are not necessarily optimal for the covariance matrix adapta-
tion. Since we use only positive recombination weights for the mean vector update, the
negative weights do not need to correspond to these optimal recombination weights.
Furthermore, the optimal negative weights—greater absolute values for worse steps—
counteract our motivation for rescaling of unpromising steps discussed in Section 3.1.
Our choice of the negative recombination weights is a natural extension of the default
positive recombination weights. The shape of our recombination weights is somewhat
similar to the one in xCMA-ES (Krause and Glasmachers, 2015), where the first half is
wi − 1/λ and the last half is −1/λ. A minor difference is that xCMA-ES assigns negative
values even for some of the better half of the candidate solutions, whereas our setting
8Interesting results are derived from the quality gain (and progress rate) analysis; see, for example,
Section 4.2 of Hansen et al. (2015). Comparing the (1 + 1)-ES and (μ, λ)-ES with intermediate recom-
bination, we realize that they reach the same quality gain in the limit for n to infinity when μ is the
optimal value, μ ≈ 0.27λ (Beyer, 1995). That is, a nonelitist strategy with optimal μ/λ for intermediate
recombination can reach the same speed as the elitist strategy. With the optimal recombination weights
above, the weighted recombination ES is 2.475 times faster than those algorithms. If we employ only
the positive half of the optimal recombination weights, the speed will be halved, yet it is faster by the
factor of 1.237.
Evolutionary Computation Volume 28, Number 3
417
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
/
e
d
u
e
v
c
o
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
e
v
c
o
_
a
_
0
0
2
6
0
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Y. Akimoto and N. Hansen
assigns positive values only for the better half and negative values only for the worse
half.
Positive and negative recombination weights are scaled differently. Positive weights
are scaled to sum to one, whereas negative weights are scaled so that the sum of their ab-
and 1 + 2μ−
solute values is the minimum of 1 + c1
μw+2 . The latter corrects for unbalanced
cμ
positive and negative weights, but is usually greater than the former with our default
λ
values. The former makes the decay factor 1 − c1
i=1 wi of the covariance matrix
update (see Eq. (14)) to 1. That is, the covariance matrix does not passively shrink, and
only the negative update can shrink the covariance matrix. Krause and Glasmachers
(2015) mention to have no passive shrinkage by setting the sum of the weights to zero,
but the effect of the rank-one update was not taken into account and thus in xCMA the
passive decay factor of 1 − c1 remains.
− cμ
(cid:7)
w
4 Adaptive Diagonal Decoding (dd-CMA)
The separable CMA-ES (Ros and Hansen, 2008) enables an adaptation to a diagonal co-
variance matrix faster than the standard CMA-ES because the learning rates are O(n)
times greater than in standard CMA-ES. This works well on separable objective func-
tions, where separable CMA-ES adapts the (co)variance matrix by a factor of O(n) faster
than CMA-ES. To accelerate standard CMA, we combine separable CMA and standard
CMA. We adapt both D and C at the same time,9 where D is updated with adaptive
learning rates which can be much greater than those used to update C.
4.1 Algorithm
The update of D is similar to separable CMA, but is done in local exponential coordi-
nates. The update of D is as follows
[(cid:3)D]k,k = c1,D
(cid:2)(cid:29)√
−1
C
(D(t ))
−1 pc,D
(cid:30)
2
k
(cid:3)
− γc,D
+ cμ,D
(cid:19)
D(t+1) ← D(t ) · exp
(cid:20)
,
(cid:3)D
2β (t )
(cid:2)(cid:29)
wi,D
˜zi:λ
(cid:30)
2
k
(cid:3)
− 1
λ(cid:6)
i=0
(28)
(29)
where [(cid:3)D]k,k is the k-th diagonal element of the diagonal matrix (cid:3)D, the evolution path
pc,D feeds the rank-one D update, c1,D and cμ,D are the learning rates for the rank-one
and rank-μ D updates, respectively, the recombination weights wi,D are computed by
Eq. (27) using c1,D/cμ,D instead of c1/cμ, ˜zi:λ is defined in (16), and β (t ) is the damping
factor for the diagonal matrix update given in Eq. (31) below. The evolution path pc,D
and its normalization factor γc,D are updated in the same way as Eqs. (9) and (10) with
the cumulation factor cc,D rather than cc. The matrix exponential of a diagonal matrix
is exp(diag(d1, . . . , dn)) = diag(exp(d1), . . . , exp(dn)).
Using the correlation matrix of the covariance matrix C of the last time the matrix
was decomposed,
corr(C) :=
(cid:10)
(cid:10)
−1
diag(C)
C
diag(C)
−1
,
(30)
9Considering the eigen decomposition of the covariance matrix, E(cid:3)ET, instead of the decomposition
DCD, our attempts to additionally adapt (cid:3) were unsuccessful. We attribute the failure to the strong in-
terdependency between (cid:3) and E. Compared to the eigen decomposition, the diagonal decoding model
DCD also has the advantage to be interpretable as a rescaling of variables. We never considered the
C as proposed by one of the reviewers of this article; however, at first sight, we
decomposition
do not see any particular advantage in favor of this decomposition.
CD2
√
√
418
Evolutionary Computation Volume 28, Number 3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
/
e
d
u
e
v
c
o
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
e
v
c
o
_
a
_
0
0
2
6
0
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
Figure 3: Equiprobability ellipse defined by C, DCD, and DβCDβ. Green ellipses repre-
sent N (0, C) with axis ratio of 1, 10, 100, and inclination angle π/4. Blue dashed ellipses
represent N (0, DCD) with D = [1.2, 1/1.2]. Red ellipses represent N (0, Dβ CDβ ) with
Dβ damped by using β in Eq. (31).
where diag(C) is the diagonal matrix whose diagonal elements are the diagonal ele-
ments of C, the damping factor is based on the square root of the condition number of
this correlation matrix as
(cid:13)
(cid:8)
β (t ) = max
1,
Cond (corr(C)) − βthresh
,
(31)
(cid:14)
+ 1
where βthresh := 2 is the threshold parameter at which β (t ) becomes larger than one. We
remark that β (t ) changes only every teig iterations.
The D-update is multiplicative as in Ostermeier et al. (1994) or Krause and Glas-
machers (2015) to be unbiased on the log-scale and to simply guarantee the posi-
tive definiteness of D. Note that the first order approximation of the update formula
D(t ) exp((2β )
−1(cid:3)D ) gives
(cid:13)
(cid:14)
2
(cid:14)
2
(cid:13)
D(t )
≈
D(t+1)
+ 1
β (t )
D(t )(cid:3)DD(t ),
which is the update in separable CMA.
Importantly, we set the learning rates for the D update, c1,D and cμ,D, to be about
n times greater than the learning rates for the C update, c1 and cμ. Moreover, we main-
tain an additional evolution path, pc,D, for the rank-one update of D since an adequate
cumulation factor, cc,D, may be different from the one for pc.
4.2 Damping Factor
The dynamic damping factor β (t ) is the crucial novelty that prevents diagonal decoding,
to disrupt the adaptation of the covariance matrix C in CMA-ES. The damping factor
is introduced to prevent the sampling distributions from drastically changing due to
the diagonal matrix update. Figure 3 visualizes three example cases with different C.
When the diagonal decoding matrix changes from the identity matrix to D, the change
of the distribution from N (0, C) to N (0, DCD) is minimal when C is diagonal, and is
comparatively large if C is nondiagonal. It will be greater as the condition number of
the correlation matrix corr(C) increases. In the worst case in Figure 3, we see that two
distributions are overlapping only at the center of distribution.
The damping factor β (t ) computed in Eq. (31) is motivated from the KL divergence
between the sampling distributions before and after the D update. The KL divergence
Evolutionary Computation Volume 28, Number 3
419
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
/
e
d
u
e
v
c
o
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
e
v
c
o
_
a
_
0
0
2
6
0
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Y. Akimoto and N. Hansen
between two multivariate normal distributions that have the same mean vectors is
equivalent to the half of the Log-Determinant divergence between the covariance ma-
trices, defined as
Dld (A, B) = Tr(AB
−1) − log det(AB
−1) − n,
(32)
where A and B are two positive definite symmetric matrices. Let A = D(cid:14)CD(cid:14)
and
B = DCD, that is, A and B are the covariance matrices after and before the D update,
respectively. The divergence Dld is asymmetric, and the value changes if we exchange A
and B, but we will obtain a symmetric approximation in the end. To analyze the diver-
gence between A and B due to the difference in shape and put aside the effect of a global
scaling, we scale both to be of determinant one. We denote the resulting divergence by
¯Dld (A, B) = Dld (A/ det(A), B/ det(B)). Then, we obtain
1
2β
¯Dld (A, B) = Tr
1
2β
C exp
¯(cid:3)D
¯(cid:3)D
exp
−1
(cid:19)
(cid:20)
(cid:20)
(cid:19)
(cid:19)
(cid:20)
C
(cid:13)
− n,
(cid:14)
(cid:13)
(cid:14)
(cid:13)
where ¯(cid:3)D = (cid:3)D − (Tr((cid:3)D )/n)I. With the approximation exp
1
2β
D and neglecting ((cid:3)D/β )3 and higher terms, we have10
(cid:14)
2
¯(cid:3)2
1
2
1
2β
¯(cid:3)D
≈ I +
1
2β
¯(cid:3)D +
(cid:19)
(cid:20)
2
(cid:19)
(cid:20)
2
(cid:2)
¯(cid:3)DC ¯(cid:3)DC
(cid:3)
+
−1
Tr
¯Dld (A, B) ≈
1
2β
(cid:2) (β + βthresh
4β2
(cid:2)
Note that ¯Dld ((D(t+1))2, (D(t ))2) ≈ 2
if C is diagonal and β = 1. Therefore, with
¯(cid:3)2
D
β computed in Eq. (31), we bound the realized divergence approximately by the diver-
gence of D like
1
2β
(cid:3)
− 1)2 + 1
(cid:2)
¯(cid:3)2
D
−1Tr
Tr
Tr
(cid:3)
.
(cid:3)
(cid:2)
¯(cid:3)2
D
¯Dld (D(t+1)CD(t+1), D(t )CD(t )) (cid:2) ¯Dld ((D(t+1))2, (D(t ))2),
(33)
for large β.
In a nutshell, we have quantified the distribution change from changing D by mea-
suring its KL-divergence. We derive that β in Eq. (31) upper bounds the KL-divergence
due to changes of D approximately by the KL-divergence from the same change of D
when C = I. The latter is directly determined by the learning rates c1,D and cμ,D.
4.3
Implementation Remark
To avoid unnecessary numerical errors and additional computational effort for eigen
decompositions in the adaptive diagonal decoding mechanism Eqs. (28), (29), and (31),
we force the diagonal elements of C to be all one by assigning
D(t ) ← D(t )diag(C(t ))
(34)
1
2
C(t ) ← corr(C(t )) = diag(C(t ))
− 1
2 C(t )diag(C(t ))
− 1
2 .
(35)
10Let A and B be an arbitrary positive definite symmetric matrix and an arbitrary symmetric ma-
trix, respectively. Let ⊗ and vec denote the Kronecker product of two matrices and the matrix-vector
rearrangement operator that successively stacks the columns of a matrix. From Theorem 16.2.2 of
Harville (2008), we have Tr(ABA−1B) = vec(B)T(A ⊗ A−1)vec(B). The eigenvalues of the Kronecker
product A ⊗ A−1 are the products of the eigenvalues of A and A−1 (Theorem 21.11.1 of Harville,
2008). They are all positive and upper bounded by the condition number of A. Therefore, we have
vec(B)T(A ⊗ A−1)vec(B) (cid:2) Cond(A)(cid:11)vec(B)(cid:11)2 = Cond(A)Tr(B2). Letting A = corr(C) and B = ¯(cid:3)D,
we have Tr
= Tr(ABA−1B) (cid:2) (β + βthresh
(cid:2)
¯(cid:3)DC ¯(cid:3)DC−1
− 1)2Tr( ¯(cid:3)2
(cid:3)
D ).
420
Evolutionary Computation Volume 28, Number 3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
/
e
d
u
e
v
c
o
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
e
v
c
o
_
a
_
0
0
2
6
0
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
√
C
These lines are performed just before the eigen decomposition. It means that D and C
are the variance matrix and the correlation matrix of the sampling distribution, respec-
tively. This reparametrization does not change the algorithm itself, it only improves the
numerical stability of the implementation. Note that if C is constrained to be a correla-
tion matrix, then DCD is a unique parametrization for the covariance matrix.
−1
The eigen decomposition of C(t ) is performed every teig iterations. We keep
√
C
√
2 ET and
C = E(cid:4) 1
and
until the next matrix decomposition is performed. Suppose that the eigen
decomposition C(t ) = E(cid:4)ET is performed at iteration t. Then, the above matrices are
√
−1 = E(cid:4)− 1
2 ET. Then, we can compute β in Eq. (31) as β =
max(1, (maxi ([(cid:4)]i,i )/ mini ([(cid:4)]i,i ))
+ 1). This β is kept until the next eigen de-
2 − βthresh
composition is performed. Then, the additional computational cost for adaptive diag-
+ λn), which is smaller than the computational cost for the
onal decoding is O(n2/teig
other parts of the CMA-ES, O(n3/teig
+ λn2) per iteration.
C
1
One might think that maintaining D is not necessary and C could be updated by pre-
and post-multiplying by a diagonal matrix absorbing the effect of the D update. How-
ever, because diagonal decoding may lead to a fast change of the distribution shape, the
decomposition of C then needs to be done every iteration. The chosen parametrization
circumvents frequent matrix decompositions despite changing the sampling distribu-
tion rapidly.
5 Algorithm Summary and Strategy Parameters
The dd-CMA-ES combines weighted recombination, active covariance matrix update
with positive definiteness guarantee (described in Section 3.1), adaptive diagonal de-
coding (described in Section 4), and CSA, and is summarized in Algorithm 1.11
Providing good default values for the strategy parameters (aka hyperparameters)
is, needless to say, essential for the success of a novel algorithm. Especially in a black-
box optimization scenario, parameter tuning for an application relies on trial-and-error
and is usually prohibitively time consuming. The computation of the default parameter
values is summarized in Algorithm 2. Since we have c1/cμ = c1,D/cμ,D as long as c1
+
cμ < 1 (see below), the recombination weights for the update of C and of D are the same,
wi = wi,D.
The learning rates for D and C are modified to improve the adaptation speed espe-
cially in high dimension. Let m be the degrees of freedom of the matrix to be adapted;
that is, m = (n + 1)n/2 for the C-update and m = n for the D-update. The learning rate
parameters and the cumulation factors are set to the following values
c1, c1,D =
1
2(m/n + 1)(n + 1)3/4 + μw/2
cμ, cμ,D = min(μ(cid:14)c1, 1 − c1), min(μ(cid:14)c1,D, 1 − c1,D )
with μ(cid:14) = μw + 1
μw
√
√
μwc1
2
,
μwc1,D
2
.
cc, cc,D =
− 2 +
λ
2(λ + 5)
(36)
(37)
(38)
11Its python code is available at https://gist.github.com/youheiakimoto/1180b67b5a0b1265c204
cba991fa8518
Evolutionary Computation Volume 28, Number 3
421
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
/
e
d
u
e
v
c
o
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
e
v
c
o
_
a
_
0
0
2
6
0
p
d
/
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Y. Akimoto and N. Hansen
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
/
e
d
u
e
v
c
o
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
e
v
c
o
_
a
_
0
0
2
6
0
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
The first important change is the scaling of the learning rate with the dimension n. In
previous works (Ros and Hansen, 2008; Hansen and Auger, 2014; Akimoto and Hansen,
2016), the default learning rates were set inversely proportional to m; that is, (cid:5)(n−2) for
the original CMA and (cid:5)(n−1) for the separable CMA. Our choice is based on empirical
observations that (cid:5)(n−2) is exceedingly conservative for higher dimensional problems,
422
Evolutionary Computation Volume 28, Number 3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
/
e
d
u
e
v
c
o
a
r
t
i
c
e
-
p
d
l
f
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
e
v
c
o
_
a
_
0
0
2
6
0
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
say n > 100: in experiments to identify cμ for the original CMA-ES, we vary cμ and
investigate the number of evaluations to reach a given target. We find that the location
of the minimum and the shape of the dependency remains for a wide range of different
dimensions roughly the same when the evaluations are taken against cμm/n0.35 (ver
also Figure 5). The observation suggests in particular that cμ = (cid:5)(
n/m) is likely to
fail with increasing dimension, whereas cμ = (cid:5)(n0.35/m) is a stable setting such that the
new setting of (cid:5)(n0.25/m) (replacing (cid:5)(n0/m)) is still sufficiently conservative. Cifra 4
depicts the difference between the default learning rate values in Hansen and Auger
(2014) and the above formulas.12
√
Another important change in the default parameter values from previous stud-
es (Ros and Hansen, 2008; Hansen and Auger, 2014) is in the cumulation factor cc.
Previously, the typical choices were cc = 4
n+4+2μw/n . The new and simpler
n+4 or cc = 4+μw/n
12The learning rate for the rank-μ update is usually μ(cid:14)
times greater than the learning rate for the
rank-one update, where μ(cid:14) ∈ (μw − 2, μw − 1/2) is monotonous in μw and approaches μw − 3/2 para
λ → ∞. Using μ(cid:14)
instead of μw is a correction for small μw. When μw = 1, we have μ(cid:14) < 1/2 (the first
three terms cancel out). In this case, because μ = 1, the rank-one update contains more information
than the rank-μ update as the evolution path accumulates information over time. Using μw instead of
μ(cid:14)
would result in the same learning rates for both updates, whereas the learning rate for the rank-μ
update should be smaller in this case.
Evolutionary Computation Volume 28, Number 3
423
Y. Akimoto and N. Hansen
+ cμ with the dimension n for different population sizes.
Figure 4: Left: Scaling of c1
Solid lines are for the new setting from Table 2, (cid:5)(n1/4λ/m) and dashed lines are for
the original setting, (cid:5)(λ/m). For n < 10, the new learning rates are slightly more con-
servative, for n > 20 they are more ambitious. Shown are six population sizes equally
log-spaced between λ = 4 + (cid:8)3 registro(norte)(cid:9) (abajo) and λ = 64n2 (arriba). Right: Function
evaluations on the ellipsoid function for plain and separable CMA with original and
new parameter settings. Three independent trials have been conducted for each set-
ting, and the median of each setting is indicated by a line (solid: plain CMA, dashed:
separable CMA). See Section 6 for details.
default value for the cumulation factor13 is motivated by an experiment on the Cigar
función, investigating the dependency of cc on c1. The effect of the rank-one update
of the covariance matrix C is most pronounced when the covariance matrix needs to
increase a single eigenvalue. To skip over the usual initial phase where sigma decreases
without changing the covariance matrix and emphasize on the effect of cc, the mean
−6. The rank-μ update is off; eso
vector is initialized at m(0) = (1, 0, . . . , 0) and σ (0) = 10
es, cμ = cμ,re = 0. We compared the number of f -calls until the target function value
−2 is reached. Note that σ (0) is chosen to avoid σ adaptation at the beginning and
de 10
the target value is chosen so that we stop the optimization once the covariance matrix
learned the right scaling. Cifra 5 compares the number of f -calls spent by the orig-
inal CMA and the separable CMA on the 20 dimensional Cigar function. Because the
x-axis is normalized with the new default value for cc, the shape of the graph and the
location of the minimum remains roughly the same for different values of c1 and λ. El
adaptation speed of the covariance matrix tends to be the best around cc =
μwc1/2
μwc1,D/2. The minimum is more pronounced for smaller c1 (or c1,D). Sin embargo,
o
we observe little improvement with the new setting in practice since more f -calls are
usually spent to adapt the overall covariance matrix and even to adapt the step-size to
converge. We have done the same experiments in dimension 80 and observe the same
trend.
√
√
√
13The appearance of
μw in the cumulation factor is motivated as follows. Hansen and Ostermeier
(cid:7)
μ
i=1 wi zi:λ alternates between two vectors
(2001) analyzed the situation where the selection vector
v and w over iterations and showed the squared Euclidean norm of the evolution path; that is the
eigenvalue of pc pT
C , remains in O((cid:11)v + w(cid:11)2/cc ) si (cid:11)v + w(cid:11) > 0. Por otro lado, Akimoto et al. (2008)
μw when σ is (también) pequeño.
showed that the above selection vector can potentially be proportional to
2/2 as μw → ∞. Por lo tanto, el
Altogether, we have c1
eigenvalue added by the rank-one update is bounded by a constant with overwhelming probability.
(cid:11) pc(cid:11)2 ∈ O(c1μw/cc ), where c1μw → 2 and cc →
μw
√
√
√
424
Volumen de cálculo evolutivo 28, Número 3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 5: Function evaluations on the 20-D cigar function until the target f -value of 10−2
is achieved for different c1 (or c1,D) and different cc (or cc,D). Three independent trials
have been conducted for each setting, and the median of each setting is indicated by
a line. The label def is the default value computed in Eq. (36). Missing points indicate
más que 5000 iterations or invalid c-values; Por ejemplo, c1 > 1 or cc > 1.
None of the strategy parameters are meant to be tuned by users, except the popula-
tion size λ. A larger population size typically results in finding a better local minimum
on rugged functions such as multimodal or noisy functions (Hansen and Kern, 2004).
It is also advantageous when the objective function values are evaluated in parallel
(Hansen et al., 2003). Restart strategies that perform independent restarts with increas-
ing population size such as IPOP strategy (Harik and Lobo, 1999; Auger and Hansen,
2005b) or BIPOP strategy (Hansen, 2009) or NIPOP strategy (Loshchilov et al., 2017) son
useful policies that automate the parameter tuning. They can be applied to the CMA-
ES with diagonal acceleration in a straightforward way. We leave research in this line
as future work.
6
experimentos
We conduct numerical simulations to see the effect of the algorithmic components of
CMA-ES with diagonal acceleration, dd-CMA-ES—namely the active update with pos-
itive definiteness guarantee and the adaptive diagonal decoding. Since the effect of the
active covariance matrix update with default population size has been investigated by
Jastrebski and Arnold (2006) and our contribution is a positive definiteness guaran-
tee for the covariance matrix especially for large population size, we investigate how
Volumen de cálculo evolutivo 28, Número 3
425
Y. Akimoto and N. Hansen
Mesa 1: Test function definitions and initial conditions. The unit vector u is either
= (1, 0, . . . , 0) for separable scenarios, or random vectors drawn uniformly on the
e1
unit sphere for nonseparable scenarios or for Ell-Cig and Ell-Dis. A vector z represents
an orthogonal transformation Rx of the input vector x, where the orthogonal matrix
R is the identity matrix for separable scenarios, or is constructed by generating nor-
mal random elements and applying the Gram-Schmidt procedure. The diagonal matrix
i−1
n−1 , . . . , 10) represents a coordinate-wise scaling and the vector y
Dell
is a coordinate-wisely transformed input vector y = D2
= diag(1, . . . , 10
ellx.
Sphere
Cigar
Discus
Ellipsoid
TwoAxes
Ell-Cig
Ell-Dis
Rosenbrock
Bohachevsky
Rastrigin
F (X)
(cid:11)X(cid:11)2
(cid:19)tu, X(cid:20)2 + 106((cid:11)X(cid:11)2 − (cid:19)tu, X(cid:20)2)
106(cid:19)tu, X(cid:20)2 + ((cid:11)X(cid:11)2 − (cid:19)tu, X(cid:20)2)
(cid:11)D3
ell z(cid:11)2
(cid:7)
norte
+
106
i=n/2+1[z]2
i
10−4(cid:19)tu, y(cid:20)2 + ((cid:11) y(cid:11)2 − (cid:19)tu, y(cid:20)2)
104(cid:19)tu, y(cid:20)2 + ((cid:11) y(cid:11)2 − (cid:19)tu, y(cid:20)2)
n/2
yo=1[z]2
i
(cid:7)
(cid:7)
(cid:7)
n−1
yo=1 100([z]2
i
+ 2[z]2
n−1
yo=1 ([z]2
i
i+1
− [z]i+1)2 + ([z]i − 1)2
− 0.3 porque(3Pi [z]i ) . . . norte (0, 82I)
− 0.4 porque(4Pi [z]i+1) + 0.7)
+ 10(1 − cos(2Pi [z]i ))
(cid:7)
norte
yo=1[z]2
i
norte (0, 32I)
metro(0)
3 · 1
3 · 1
3 · 1
3 · 1
3 · 1
3 · 1
3 · 1
0
pag (0)
1
1
1
1
1
1
1
0.1
7
2
the effect of the active update scales as the population size increases. Our main focus
es, sin embargo, on the effect of adaptive diagonal decoding. Particularly, we investigate
(i) how much better dd-CMA scales on separable functions than the CMA without di-
agonal decoding (plain CMA), (ii) how closely dd-CMA matches the performance of
separable CMA on separable functions, y (iii) how the scaling of dd-CMA compares
to the plain CMA on various nonseparable functions. Además, we investigated how
effective dd-CMA is when the population size is increased.
6.1 Common Setting
Mesa 1 summarizes the test functions used in the following experiments together with
the initial m(0) and σ (0). The initial covariance matrix C(0) and the diagonal decoding
matrix D(0) are always set to the identity matrix. The random vectors and the random
matrix appearing in Table 1 are initialized randomly for each problem instance, pero el
same values are used for different algorithms for fair comparison. A trial is considered
−8 is reached before the algorithm spends
as success if the target function value of 10
5 × 104n function evaluations, otherwise regarded as failure. For n (cid:2) 40 we conducted
20 independent trials for each setting, 10 para 80 (cid:2) norte (cid:2) 320, y 3 for n (cid:3) 640. Cuando el
computational effort of evaluating the test function scales worse than linear with the
dimension (es decir., on rotated functions) we may omit dimensions larger than 320.
We compare the following CMA variants:
Plain CMA updates C while D is kept the identity matrix, with or without active
update described in Section 3 (Algoritmo 1 without D-update);
426
Volumen de cálculo evolutivo 28, Número 3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
Cifra 6: Number of iterations spent by plain and separable CMA with and without
−8 on the 40 dimensional separable El-
active update to reach the target f -value of 10
lipsoid, Discus, and TwoAxes functions. Each line indicates the median of each setting
(solid: plain CMA, dashed: separable CMA).
Separable CMA updates D as described in Section 4 while C is kept the identity ma-
trix, with active update or without active update, where negative recombination
weights are set to zero (Algoritmo 1 without C-update);
dd-CMA as summarized in Algorithm 1, updates C as described in Section 2.1 con
active update described in Section 4, and updates D as described in Section 4.
All strategy parameters such as the learning rates are set to their default value presented
en la sección 5. Note that the separable CMA is different from the original publication (Ros
and Hansen, 2008) in that the matrix is updated in multiplicative form which however
barely affects the performance.
6.2 Active CMA
Primero, the effect of the active update is investigated. The plain and separable CMA with
and without active update are compared.
Cifra 6 shows the number of iterations spent by each algorithm plotted against
population size λ. The number of iterations to reach the target function value decreases
as λ increases and tends to level out. The plain CMA is consistently faster with active
update than without. As expected from the results of Jastrebski and Arnold (2006), el
effect of active covariance matrix update is most pronounced on functions with a small
number of sensitive variables such as the Discus function. The advantage of the ac-
tive update diminishes as λ increases in plain CMA, whereas the speed-up in separable
CMA becomes even slightly more pronounced.
6.3 Adaptive Diagonal Decoding
Próximo, we compare dd-CMA with the plain and the separable CMA with active update.
Cifra 7 compares dd-CMA with the plain CMA on the rotated Cigar, Ellipsoid, y
Discus functions, and with the separable CMA on the separable Cigar, Ellipsoid, y
Discus functions. Note that the plain CMA scales equally well on separable functions
and rotated functions, while the separable CMA will not find the target function value
on rotated functions before the maximum budget is exhausted (Ros and Hansen, 2008).
Displayed are the number of function evaluations to reach the target function value
Volumen de cálculo evolutivo 28, Número 3
427
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
Cifra 7: Function evaluations (divided by n) spent by each algorithm until it reaches
−8 and their median values (solid line: rotated function; dashed
the target f -value of 10
line: non-rotated, separable function). Data for dd-CMA on the separable Ellipsoid in
dimension 5120 are missing since they did not finish in a limited CPU time.
on each problem instance. The results of dd-, plain and separable CMA on the Sphere
function are displayed for reference.
On the Sphere function, no covariance matrix adaptation is required, and all algo-
rithms perform quite similarly. On the Cigar function, the rank-one covariance matrix
update is known to be rather effective, and even the plain CMA scales linearly on the
rotated Cigar function. On both, separable and rotated Cigar functions, dd-CMA is com-
petitive with separable and plain CMA thereby combining the better performance of the
two.
The discrepancy between plain and separable CMA is much more pronounced on
Ellipsoid and Discus functions, where the plain CMA scales superlinearly, mientras que el
separable CMA exhibits linear or slightly worse than linear scaling on separable in-
stances and fails to find the optimum within the given budget on rotated instances. On
the rotated functions, dd-CMA is competitive with the plain CMA, whereas it signifi-
cantly reduces the number of function evaluations on the separable functions compared
to plain CMA; Por ejemplo, ten times fewer f -calls are required on the 160 dimensional
separable Ellipsoid function.
The dd-CMA is competitive with separable CMA on the separable Discus func-
tion up to 5120 dimension, which is the ideal situation since we cannot expect faster
adaptation of the distribution shape on separable functions. On the separable Ellipsoid
función, the performance curve of dd-CMA starts deviating from that of the separable
CMA around n = 320, and scales more or less the same as the plain CMA afterwards,
yet it requires ten times fewer f -calls. To improve the scaling of dd-CMA on the sep-
arable Ellipsoid function, we might need to set βthresh depending on n, or use another
monotone transformation of the condition number of the correlation matrix in Eq. (31).
Performing the eigen decomposition of C less frequently (es decir., setting βeig smaller) is an-
other possible way to improve the performance of dd-CMA on the separable Ellipsoid
función, while compromising the performance on the rotated Ellipsoid function.14
14If we set βeig
= 10n, dd-CMA spends about 1.5 times more FEs on the 5120-
dimensional separable Ellipsoid function than separable CMA as displayed in Figure 7d, whereas it
= 10 instead of βeig
428
Volumen de cálculo evolutivo 28, Número 3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
Cifra 8: Examples where dd-CMA not only performs on par with the better of plain
and separable CMA, but outperforms both at least in some dimension up to n = 320
(up to n = 1280 only for separable CMA on the nonrotated Rosenbrock function). Func-
−8 divided by n. Each line indicates the
tion evaluations to reach the target f -value of 10
median of each setting (solid: rotated function, dashed: non-rotated function). The line
for dd-CMA is extrapolated up to n = 1280 with the least square log-log-linear regres-
sion on the median values.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Figures 8a and 8b show the results on Ell-Cig and Ell-Dis functions, which are non-
separable ill-conditioned functions with additional coordinate-wise scaling, Figure 8c
shows the results on nonrotated and rotated Rosenbrock functions. The separable CMA
locates the target f -value within the given budget only on the nonrotated Rosenbrock
function in smaller dimension. The experiment on the Ell-Cig function reveals that diag-
onal decoding can improve the scaling of the plain CMA even on nonseparable functions.
The improvement on the Ell-Dis function is much less pronounced. The reason why,
compared to the plain CMA, dd-CMA is more suitable for Ell-Cig than for Ell-Dis is
discussed in relation with Figure 9. On the nonrotated Rosenbrock function, dd-CMA
becomes advantageous as the dimension increases, just as the separable CMA is faster
than the plain CMA when n > 80.
Cifra 9 visualizes insights in the typical behavior of dd-CMA on different func-
ciones. On the separable Ellipsoid, the correlation matrix deviates from the identity
matrix due to stochastics and the initial parameter setting, and the inverse damping de-
creases marginally. This effect is more pronounced for n > 320 and is the reason for the
impaired scaling of dd-CMA on the separable Ellipsoid in Figure 7d. The diagonal de-
coding matrix, eso es, variance matrix, adapts the coordinate-wise scaling efficiently as
long as the condition number of the correlation matrix C is not too high. On the rotated
Ellipsoid function, where the diagonal elements of the inverse Hessian of the objective
−6
función, 1
ell R, likely have similar values, the diagonal decoding matrix remains
close to the identity and the correlation matrix learns the ill-conditioning. The inverse
damping parameter decreases so that the adaptation of the diagonal decoding matrix
does not disturb the adaptation of the distribution shape. Figure 9b shows that adaptive
diagonal decoding without the dynamic damping factor Eq. (31) severely disturbs the
adaptation of C on the rotated Ellipsoid.
2 RTD
Idealmente, the diagonal decoding matrix D adapts the coordinate-wise standard devi-
ation and C adapts the correlation matrix of the sampling distribution. If the correlation
spends about 15% more FEs on the 320-dimensional rotated Ellipsoid function than plain CMA as
displayed in Figure 7d. This might be a more practical choice, but further investigation is required.
Volumen de cálculo evolutivo 28, Número 3
429
Y. Akimoto and N. Hansen
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 9: Typical runs of dd-CMA-ES on 80 dimensional test problems (x-axis: función
evaluations). Note that the change of D partially comes from the update of C.
matrix C is easier to adapt than the full covariance matrix DCD, we expect a speed-up of
the adaptation of the distribution shape. The functions Ell-Cig and Ell-Dis in Figures 9c
and 9d are such examples. Once D becomes inversely proportional to D2
ell, the problems
become rotated Cigar and rotated Discus functions, respectivamente. The run on the Ell-Cig
function in 9c depicts the ideal case. The coordinate-wise scaling is first adapted by D
and then the correlation matrix learns a long Cigar axis. The inverse damping factor is
430
Volumen de cálculo evolutivo 28, Número 3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
−8 and its median (solid
Cifra 10: Number of iterations to reach the target f -value of 10
line: rotated function, dashed line: non-rotated function) versus population size on the
40 dimensional Ellipsoid, Discus, and TwoAxes functions.
kept at a high value similar to the one observed on the separable Ellipsoid and it starts
decreasing only after D is adapted. On the Ell-Dis function (9d) sin embargo, the short non-
coordinate axis is learned (también) quickly by the correlation matrix. Por lo tanto, the inverse
damping factor decreases before D has adapted the full coordinate-wise scaling. Desde
the function value is more sensitive in the subspace corresponding to great eigenvalues
of the Hessian of the objective, and the ranking of candidate solutions is mostly deter-
mined by this subspace, the CMA-ES first shrinks the distribution in this subspace. Este
is the main reason why dd-CMA is more efficient on Ell-Cig than on Ell-Dis.
Cifra 10 muestra, similar to Figure 6, the number of iterations versus the population
size λ on three functions in dimension 40. For all larger populations sizes up to 13312,
dd-CMA performs on par with the better of plain and separable CMA, as ideally to be
esperado.
We remark that dd-CMA with default λ = 13 has a relatively large variance in per-
formance on the separable TwoAxes function. Increasing λ from its default value re-
duces this variance and even reduces the number of f -calls to reach the target. Este
defect of dd-CMA is even more pronounced for higher dimensions. It may suggest to
increase the default λ for dd-CMA. We leave this to be addressed in future work.
Cifra 11 shows the number of iterations in successful runs, the success rate and
the average number of evaluations in successful runs divided by the success rate (Precio,
1997; Auger and Hansen, 2005a) on two multimodal 40-dimensional functions. El
maximum numbers of f -calls are 5n × 104 on Bohachevsky and 2n × 105 on Rastrigin.
Comparing separable to dd-CMA on separable functions and plain to dd-CMA on ro-
tated functions, dd-CMA tends to spend less iterations but to require greater λ to reach
the same success rate. The latter is attributed to doubly shrinking the overall variance
by updating C and D. For λ (cid:12) norte, we have cμ ≈ 1 and cμ,D ≈ 1 and the effect of shrinking
the overall variance due to C and D updates is not negligible. Entonces, the overall variance
is smaller than in plain and separable CMA, which also leads to faster convergence. Este
effect disappears if we force the D update to keep its determinant unchanged, cual
can be realized by replacing (cid:3)D in Eq. (29) con (cid:3)D − (Tr((cid:3)D )/norte)I.
7
Summary and Conclusion
In this article, we have put forward several techniques to improve multirecombinative
nonelitistic covariance matrix adaptation evolution strategies without changing their
internal computation effort.
Volumen de cálculo evolutivo 28, Número 3
431
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 11: Number of iterations (arriba) spent by each algorithm until it reaches the target
−8 on the 40 dimensional Bohachevsky and Rastrigin functions; and its me-
f -value of 10
dián (line), success rates (middle), and the average number of evaluations in successful
runs divided by the success rate (SP1, abajo).
The first component is concerned with the active covariance matrix update, cual
utilizes unsuccessful candidate solutions to actively shrink the sampling distribution in
unpromising directions. We propose two ways to guarantee the positive definiteness of
the covariance matrix by rescaling unsuccessful candidate solutions.
The second and main component is a diagonal acceleration of CMA by adaptive
diagonal decoding, dd-CMA. The covariance matrix adaptation is accelerated by adapt-
ing a coordinate-wise scaling separately from the positive definite symmetric covari-
ance matrix. This drastically accelerates the adaptation speed on high-dimensional
functions with coordinate-wise ill-conditioning, whereas it does not significantly
432
Volumen de cálculo evolutivo 28, Número 3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
influence the adaptation of the covariance matrix on highly ill-conditioned non-
separable functions without coordinate-wise scaling component.
The last component is a set of improved default parameters for CMA. The scaling
of the learning rates are relaxed from (cid:5)(1/n2) a (cid:5)(1/n1.75) for default CMA and from
(cid:5)(1/norte) a (cid:5)(1/n0.75) for separable CMA. This contributes to accelerate the learning in
all investigated CMA variants on high dimensional problems, say n (cid:3) 100.
Algorithm selection as well as hyperparameter tuning of an algorithm is a trou-
blesome issue in black-box optimization. For CMA-ES, we needed to make a decision
whether we use the plain CMA or the separable CMA, based on the limited knowl-
edge on a problem of interest. If we select the separable CMA but the objective function
is non-separable and highly ill-conditioned, we will not obtain a reasonable solution
within most given function evaluation budgets. Por lo tanto, plain CMA is a safer choice,
though it may be slower on nearly separable functions. The dd-CMA automizes this
decision and achieves faster adaptation speed on functions with ill-conditioned vari-
ables usually without compromising the performance on nonseparable and highly ill-
conditioned functions. Además, the advantage of dd-CMA is not limited to separable
problemas. We found a class of nonseparable problems with variables of different sen-
sitivity on which dd-CMA-ES decidedly outperforms CMA-ES and separable CMA-ES
(see Figure 8a). As dd-CMA-ES improves the performance on a relatively wide range
of problems with mis-scaling of variables, it is a prime candidate to become the default
CMA-ES variant.
Expresiones de gratitud
The authors thank the associate editor and the anonymous reviewers for their valuable
comments and suggestions. This work is partly supported by JSPS KAKENHI grant
number 19H04179.
Referencias
Akimoto, y., Auger, A., and Hansen, norte. (2014). Comparison-based natural gradient optimization
in high dimension. In Proceedings of Genetic and Evolutionary Computation Conference, páginas. 373–
380.
Akimoto, y., Auger, A., and Hansen, norte. (2018). Quality gain analysis of the weighted recombina-
tion evolution strategy on general convex quadratic functions. Informática Teórica.
doi:10.1010/j.tcs.2018.05.015
Akimoto, y., and Hansen, norte. (2016). Projection-based restricted covariance matrix adaptation for
high dimension. In Genetic and Evolutionary Computation Conference (GECCO), páginas. 197–204.
Akimoto, y., Nagata, y., Ono, I., and Kobayashi, S. (2010). Bidirectional relation between CMA
evolution strategies and natural evolution strategies. In Parallel Problem Solving from Nature,
páginas. 154–163. Lecture Notes in Computer Science, volumen. 6238.
Akimoto, y., Sakuma, J., Ono, I., and Kobayashi, S. (2008). Functionally specialized CMA-ES: A
modification of CMA-ES based on the specialization of the functions of covariance matrix
adaptation and step size adaptation. In Proceedings of the 10th Annual Conference on Genetic
and Evolutionary Computation (GECCO). doi:10.1145/13895.1389188
arnold, D. V. (2006). Weighted multirecombination evolution strategies. Theoretical Computer Sci-
ence, 361:18–37.
arnold, D. v., and Hansen, norte. (2010). Active covariance matrix adaptation for the (1 + 1)-CMA-
ES. In Proceedings of Genetic and Evolutionary Computation Conference, páginas. 385–392.
Volumen de cálculo evolutivo 28, Número 3
433
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Y. Akimoto and N. Hansen
Auger, A., and Hansen, norte. (2005a). Performance evaluation of an advanced local search evolu-
tionary algorithm. En 2005 IEEE Congress on Evolutionary Computation, páginas. 1777–1784.
Auger, A., and Hansen, norte. (2005b). A restart CMA evolution strategy with increasing population
tamaño. En 2005 IEEE Congress on Evolutionary Computation, páginas. 1769–1776.
Beyer, H.-G. (1995). Toward a theory of evolution strategies: On the benefits of sex—The (μ/μ,
λ) theory. Computación evolutiva, 3(1):81–111.
Glasmachers, T., Schaul, T., Hacer, S., Wierstra, D., and Schmidhuber, j. (2010). Exponential natural
evolution strategies. In Proceedings of Genetic and Evolutionary Computation Conference, páginas.
393–400.
Hansen, norte. (2000). Invariance, self-adaptation and correlated mutations in evolution strategies.
In Parallel Problem Solving from Nature, páginas. 355–364.
Hansen, norte. (2009). Benchmarking a bi-population CMA-ES on the BBOB-2009 function testbed.
In Workshop Proceedings of the GECCO Genetic and Evolutionary Computation Conference, páginas.
2389–2395.
Hansen, NORTE., arnold, D. v., and Auger, A. (2015). Evolution strategies. In J. Kacprzyk and W.
Pedrycz (Editores.), Handbook of computational intelligence, páginas. 871–898. Berlina: Saltador.
Hansen, NORTE., and Auger, A. (2014). Principled design of continuous stochastic search: From theory
to practice. In Y. Borenstein and A. Moraglio (Editores.), Theory and principled methods for the design
of metaheuristics. Berlina: Saltador.
Hansen, NORTE., and Kern, S. (2004). Evaluating the CMA evolution strategy on multimodal test func-
ciones. In Parallel Problem Solving from Nature, páginas. 282–291.
Hansen, NORTE., Muller, S. D., and Koumoutsakos, PAG. (2003). Reducing the time complexity of the de-
randomized evolution strategy with covariance matrix adaptation (CMA-ES). Evolutionary
Cálculo, 11(1):1–18.
Hansen, NORTE., and Ostermeier, A. (2001). Completely derandomized self-adaptation in evolution
estrategias. Computación evolutiva, 9(2):159–195.
Hansen, NORTE., Ros, r., Mauny, NORTE., Schoenauer, METRO., and Auger, A. (2011). Impacts of invariance in
buscar: When CMA-ES and PSO face ill-conditioned and non-separable problems. Applied
Soft Computing, 11(8):5755–5769.
Harik, GRAMO. r., and Lobo, F. GRAMO. (1999). A parameter-less genetic algorithm. En Actas de la
1st Annual Conference on Genetic and Evolutionary Computation—Volume 1 (GECCO), páginas. 258–
265.
Harville, D. A. (2008). Matrix algebra from a statistician’s perspective. Berlina: Editorial Springer.
Heijmans, R. (1999). When does the expectation of a ratio equal the ratio of expectations? Statistical
Documentos, 40:107–115.
Jastrebski, GRAMO., and Arnold, D. V. (2006). Improving evolution strategies through active covariance
matrix adaptation. En 2006 IEEE Congress on Evolutionary Computation, páginas. 9719–9726.
Karafotias, GRAMO., Hoogendoorn, METRO., and Eiben, A. mi. (2015). Parameter control in evolutionary algo-
rithms: Trends and challenges. IEEE Transactions on Evolutionary Computation, 19(2):167–187.
Caballero, j. NORTE., and Lunacek, METRO. (2007). Reducing the space-time complexity of the CMA-ES. En
Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation (GECCO),
páginas. 658–665.
Krause, o., Arbonès, D. r., and Igel, C. (2016). CMA-ES with optimal covariance update and
storage complexity. In Advances in Neural Information Processing Systems, páginas. 370–378.
434
Volumen de cálculo evolutivo 28, Número 3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies
Krause, o., and Glasmachers, t. (2015). A CMA-ES with multiplicative covariance matrix up-
fechas. En Actas de la 2015 Annual Conference on Genetic and Evolutionary Computation
(GECCO), páginas. 281–288.
Loshchilov, I. (2017). LM-CMA: An alternative to L-BFGS for large-scale black box optimization.
Computación evolutiva, 25(1):143–171.
Loshchilov, I., Schoenauer, METRO., and Sebag, METRO. (2012). Alternative restart strategies for CMA-ES.
In International Conference on Parallel Problem Solving from Nature, páginas. 296–305.
Ollivier, y., arnold, l., Auger, A., and Hansen, norte. (2017). Information-geometric optimization
algoritmos: A unifying picture via invariance principles. Journal of Machine Learning Research,
18(18):1–65.
Ostermeier, A., Gawelczyk, A., and Hansen, norte. (1994). A derandomized approach to self-
adaptation of evolution strategies. Computación evolutiva, 2(4):369–380.
Precio, k. V. (1997). Differential evolution vs. the functions of the 2nd ICEO. In IEEE International
Conference on Evolutionary Computation, 1997, páginas. 153–157.
Rios, l. METRO., and Sahinidis, norte. V. (2013). Derivative-free optimization: A review of algorithms and
comparison of software implementations. Journal of Global Optimization, 56(3):1247–1293.
Ros, R. (2009). Benchmarking sep-CMA-ES on the BBOB-2009 function testbed. En procedimientos de
the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late
Breaking Papers (GECCO), páginas. 2435–2440.
Ros, r., and Hansen, norte. (2008). A simple modification in CMA-ES achieving linear time and space
complejidad. In Parallel Problem Solving from Nature, páginas. 296–305.
Sol, y., Wierstra, D., Schaul, T., and Schmidhuber, j. (2009). Efficient natural evolution strategies.
In Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation (GECCO),
páginas. 539–545.
Wierstra, D., Schaul, T., Glasmachers, T., Sol, y., Peters, J., and Schmidhuber, j. (2014). Natural
evolution strategies. Journal of Machine Learning Research, 15:949–980.
Wierstra, D., Schaul, T., Peters, J., and Schmidhuber, j. (2008). Natural evolution strategies. En
IEEE Congress on Evolutionary Computation, páginas. 3381–3387.
Volumen de cálculo evolutivo 28, Número 3
435
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
mi
d
tu
mi
v
C
oh
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
8
3
4
0
5
1
8
5
8
9
7
3
mi
v
C
oh
_
a
_
0
0
2
6
0
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3