Resumen de políticas
APPROPRIATE STANDARDS OF EVIDENCE
FOR EDUCATION POLICY DECISION MAKING
Carrie Conaway
Graduate School of Education
Harvard University
Cambridge, MAMÁ 02138
carrie_conaway@gse.harvard
.edu
Dan Goldhaber
(Autor correspondiente)
Center for Education and Data
& Investigación
University of Washington
seattle, Washington 98103
dgoldhab@uw.edu
Abstracto
Education policy makers must make decisions under uncertainty.
De este modo, how they think about risks has important implications for
resource allocation, intervenciones, innovation, and the informa-
tion that is provided to the public. In this policy brief we illustrate
how the standard of evidence for making decisions can be quite
inconsistently applied, in part because of how research findings
are reported and contextualized. We argue that inconsistencies in
evaluating the probabilities of risks and rewards can lead to sub-
optimal decisions for students. We offer suggestions for how pol-
icy makers might think about the level of confidence they need to
make different types of decisions and how researchers can provide
more useful information so that research might appropriately af-
fect decision making.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
.
F
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
383
https://doi.org/10.1162/edfp_a_00301
© 2019 Asociación para la política y las finanzas educativas
Standards of Evidence for Decision Making
INTRODUCCIÓN
A key job of education policy makers is to make decisions under uncertainty. They must
weigh the risks, recompensas, and costs of different interventions, políticas, and mixes of
resources, and make decisions even when the likely outcome is uncertain. A veces
decisions are informed by an abundance of empirical evidence; in those cases policy
makers might be quite certain about the consequences of the decisions they make.
But often decisions must be made in instances where the evidence is unavailable or
inconclusive, or the evidence may even suggest that an informed decision is likely to
yield uncertain outcomes.
How policy makers think about and deal with uncertainty has important implica-
tions for resource allocation, intervenciones, innovation, and the information that is pro-
vided to the public. We do not presume to judge how much risk policy makers should
feel comfortable with in the face of uncertain educational decisions. Bastante, we worry
that the way uncertainty is described—particularly adherence to the statistician’s stan-
dard for statistical significance—may lead to misunderstandings and inconsistencies
in how uncertainty affects decisions.
In this policy brief we illustrate how the standard of evidence for making decisions
can be quite inconsistently applied, in part because of how research findings are re-
ported and contextualized. Academic papers and (especially) summaries, abstracts, y
policy reports frequently exclude information about uncertainty, let alone the broader
context for the findings. Without this information, it is hard for policy makers to appro-
priately consider uncertainty in their decisions. We also argue that inconsistencies in
evaluating the probabilities of risks and rewards can lead to suboptimal decisions for
students because risks and rewards are often judged by how the adults, rather than the
estudiantes, in the system are affected. Finalmente, we offer some suggestions for how policy
makers might think about the level of confidence they need to make different types of
decisions and how researchers can provide more useful information so that research
might appropriately affect decision making.
T H E U S E A N D N O N U S E O F S TAT I S T I C A L S I G N I F I C A N C E I N P O L I C Y M A K I N G
We are not alone in raising concerns about how policy makers consider uncertainty.
Most prominently, the widely cited 2016 statement by the American Statistical Asso-
ciation (ASA) raises a number of issues with interpretation of, and overreliance on,
p-values, the measure commonly used to assess the level of statistical significance. Él
warns that “Scientific conclusions and business or policy decisions should not be based
only on whether a p-value passes a specific threshold” (Wasserstein and Lazar 2016,
pag. 131), but also notes that “Nothing in the ASA statement is new. Statisticians and others
have been sounding the alarm about these matters for decades, to little avail” (pag. 130).
The fact that sounding the alarm has seemingly yielded little change may itself be
justification for continuing to try to get the message out about how to think about un-
certeza. But we also believe it is helpful to center this challenge within a specific policy
contexto, to make more tangible how these issues apply to the decisions policy makers
rostro. In this case we focus on education policy.
Testing and school accountability provide useful illustrations of how uncertainty
enters the policy-making process. Under the No Child Left Behind Act (NCLB) y
384
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
/
.
F
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Carrie Conaway and Dan Goldhaber
Mesa 1. Examples of Uncertainty in Test Score Use
Test Score Use
Examples of Sources of
Incertidumbre
Is This Source of
Incertidumbre
Quantifiable?
Is it Commonly
Reported?
Reporting individual scores
Random error (p.ej., guessing, misreading)
Sí
Only some domains of knowledge are included
Not easily
Determining proficiency levels
Reporting aggregate school performance
on the test
Above plus . . .
Human judgment on performance levels
Above plus . . .
Sampling error
Making school accountability determinations
Above plus . . .
Choices on which measures to include and how
much to weight them
Not easily
Sí
Sí
Sí
No
No
No
No
now Every Student Succeeds Act (ESSA), all states are required to administer annual
academic achievement tests to students to measure their proficiency. The data from
these tests are used for multiple purposes, among them to measure individual stu-
dent achievement and assign students to interventions, and to measure and report on
teacher and school performance (ver tabla 1). As we argue in this brief, uncertainty is
inherent in the testing process—yet it is not consistently considered or reported across
all these uses.
Standard psychometric practice for reporting test data (or any other statistical es-
timate) is to provide both an individual test score and a range of scores within which
statisticians are highly confident (more on this later) that a student would receive a sim-
ilar score were she to retake the test (AERA et al. 2014). This range is meant to reflect
the fact that a student’s test score on any given day is just an estimate of her true ability,
in part because of random errors such as guessing or misreading questions (Koretz
2009). This type of error is easily quantified and thus typically included in describing
test findings. But error at the individual level can also arise because tests themselves
only measure a sample of a domain of knowledge; depending on the domains sam-
pled, students may perform better or worse on the test (Koretz 2009). This is harder to
quantify so is typically not represented statistically.
Criterion-referenced tests—whose purpose is to measure whether students are pro-
ficient, and not just how they perform relative to one another—also involve uncertainty
in another, less obvious way. To determine which students are and are not proficient
in a given subject, states must make decisions about what level of test performance
is sufficiently high to meet that standard. States typically establish these thresholds by
convening teams of educators to review test items and results, and to set cut points—
eso es, the minimum level of performance needed to attain each performance level on
the test (p.ej., “needs improvement,” “proficient,” “advanced”). Como resultado, the percent
of students identified as proficient varies in part as a function of the differing judg-
ments of different groups of educators, as opposed to meaningful differences in the
challenge level of the content for that grade or students’ preparation for learning that
contenido. This type of uncertainty goes unnoticed because, unlike the uncertainty in
student-level scores, it is not easy to quantify—yet it is critically important to how the
results are interpreted and used downstream.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
F
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
.
/
F
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
385
Standards of Evidence for Decision Making
Similar issues arise when assessment data are aggregated to the teacher or school
level to describe performance (ver tabla 1). Every state, por ejemplo, publishes extensive
data on school-level assessment results, often along with other information, como
high school graduation rates. The provision of this information, required under both
NCLB and ESSA, is a form of public accountability that is intended to inform school-
ing choices (Shober 2016), yet it ignores uncertainty in at least two critical ways. Primero,
once a minimum school size threshold is met,1 the information is typically reported
publicly without any indication of a confidence interval around the results. Stated dif-
ferently, sampling error is often not discussed. And second, these reports typically dis-
play the percentage of students scoring in each performance level, so rely heavily on the
inherently uncertain performance-level categorizations described above. These public
reports rarely, if ever, explicitly describe how uncertainty might matter for the results.
These same data are also used to rate school performance through accountability de-
terminations. Standard practice is to assign weights to test scores, graduation rates, y
other quantitative measures of school performance, to rank schools on those measures,
to classify them into groups based on the rankings, and to report those classifications
publicly. The designations schools receive lead to substantial rewards, sanciones, y
prioritization in resource allocation. Todavía, once again, this process pays little attention
to whether the reported differences between schools are meaningful or how much the
weighting of factors—a subjective choice—matters for the determinations.
The aggregation of test results across multiple students helps to ensure that ob-
served differences in achievement reflect real differences in students’ learning, si arriba-
posed to sampling or random errors.2 Still, small differences between schools in test
scores are almost surely not indicative of true underlying differences in school quality
(Kane and Staiger 2002). De hecho, the issues with uncertainty around small differences
are so well established among researchers that a common research design for causal
inference is to compare outcomes for schools just above and below an arbitrarily set
cut point, on the argument that they are essentially equivalent, except for the random
chance of which side of the cut they ended up on (p.ej., Rockoff and Turner 2010; Rouse
et al. 2013; Holden 2016). Yet the categorizations of schools affect how literally billions
of dollars of education funding are allocated.
Some states do attempt to address uncertainty in some parts of the accountability
proceso. Por ejemplo, in Massachusetts’s accountability system under the NCLB waiver
(in place from 2012 a 2016), schools received credit for reaching their performance
target if they came within half of a standard deviation. But accounting for uncertainty
is not required, and thus states vary in whether and how they choose to address this
issue. This leaves parents and the public with access to arbitrarily different information
about school performance.
1. Here we have simplified the actual requirement that schools report the aggregate test performance of various
student subgroups that exceed minimum threshold sizes. Curiosamente, states vary in the thresholds they set for
the minimum number of students in each subgroup for reporting requirements. De este modo, the level of confidence in
the differences in student achievement across subgroups varies from state to state according to the differences
in their reporting thresholds.
2. Nota, sin embargo, this does not alleviate concerns about whether tests are measuring the right domains, or the
potential that testing itself negatively affects schools or students (Koretz 2017; Goldhaber and Özek 2019).
386
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
F
/
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
/
.
F
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Carrie Conaway and Dan Goldhaber
De este modo, uncertainty is an integral part of generating, interpreting, and using assess-
ment data, but its role and implications are inconsistently considered throughout that
proceso. Where the uncertainty is easily quantified, it is more commonly reported—but
this is only a small subset of the places where uncertainty matters for policy making.
The inconsistency is troubling, considering the implications of making incorrect de-
cisions based on test scores are arguably more profound when they are used to set
proficiency levels or to drive resources and trigger interventions (precisely the cases
where uncertainty is not considered).
TOW A R D A P P RO P R I AT E R E S E A R C H F R A M I N G A N D S TA N DA R D S O F E V I D E N C E
Decades of academic research speaks to how managers make decisions under uncer-
tainty (p.ej., Arrow and Lind 1978; Bradley and Drechsler 2013; Goodwin and Wright
2014). But this work does not address how the typical reporting of research findings
helps to frame the ways in which policy makers seek to account for uncertainty, or how
the context for a decision might influence how much certainty a decision maker should
buscar. En particular, as we describe below, the statistician’s standard for significance may
serve to obscure effects to which policy makers should attend. Y, the context for de-
cision making—the policy goal, the weight of the evidence on an issue, the cost and
reversibility of policy choices, and what is known about relevant policy alternatives—
clearly matters for policy makers when interpreting and applying new evidence.
Standard Statistical Practice Often Doesn’t Reflect Policy Makers’ Needs
In academia, studies are often judged by their reliability and their internal and external
validity, eso es, the degree to which the study produces consistent measures, measures
that it intended to measure, and generalizes to other contexts. Where a study’s reliability
and validity are strong, its implications for decision making are more certain. Pero esto
overlooks the fact that in the abstracts, briefs, and media reporting most accessible to
policy makers,3 findings are generally described not in terms of their reliability and
validity but rather their statistical significance—and the statistician’s standard for what
constitutes a “significant finding” can steer policy makers in the wrong direction.
Specficially, in testing for differences between samples, the norm is to set a high
standard for what constitutes a “real” difference, typically a probability (known as a p-
valor) de 5 percent or less, of stating that a difference exists when it does not. This then
translates to a 95 percent confidence interval that defines the range in which the true
population difference would lie with 95 percent certainty. This high standard limits the
chance of finding a false positive (Type I error).
El 95 percent certainty standard is often uncritically adopted in the context of
making education policy decisions. De hecho, it is likely that many decision makers are
unaware of the specific standards at all; they simply hear whether an initiative has a
statistically significant effect or not.4 Yet, some policy makers’ decisions suggest that
3. Evidence suggests policy makers access research primarily through their professional networks (Penuel et al.
2017).
4. The standard practice when designing an experiment is to seek at least 80 percent confidence in avoiding falsely
claiming that a difference doesn’t exist when it really does. This in effect suggests that false positives are four
times as problematic as false negatives, a standard that is certainly debatable. But we would also argue that
researchers often fail to pay attention to false negatives (es decir., Type II error). This is particularly true in research
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
F
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
.
/
F
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
387
Standards of Evidence for Decision Making
they also value avoiding false negatives. Por ejemplo, states devote substantial resources
to collecting and publishing data about schools, even when the differences between
them may not be meaningful.
Teacher preparation policy provides a helpful example of how policy makers might
weight the risks of false positives and negatives differently from standard statistical
práctica. The quality of newly prepared teachers and the role of teacher preparation
programs in developing teachers are issues receiving increased attention of late (Gold-
haber 2019). One natural question is whether programs vary meaningfully in the ef-
fectiveness of their graduates. De hecho, a number of states have begun to hold them
accountable for teacher value added,5 one measure of teacher effectiveness (von Hippel
and Bellows 2018).
No es sorprendente, ranking teacher preparation programs is controversial, especially
when it comes to rankings based on value-added measures and using these rankings for
program accountability. The American Educational Research Association (AERA), para
instancia, released a statement raising substantial cautions about the use of value-added
models to evaluate programs (AERA 2015). One of the concerns raised is that value
added should “always be accompanied by estimates of uncertainty to guard against
overinterpretation of differences [between programs]" (pag. 50).
So, how many, y cual, programs produce especially strong or weak teachers?
The answer depends in large part on the statistical standards used to determine whether
the differences are meaningful. In an analysis of studies from six states, von Hipple
and Bellows (2018) note that few programs are different from the average in a state and
conclude that “It is not meaningful to rank all the [teacher preparation programs] en un
estado. The true differences between most [teacher preparation programs] are too small
to matter, and the estimated differences consist mostly of noise” (pag. 13). But the von
Hippel and Bellows conclusion is based largely on the typical statistician’s standard of
evidencia, and a standard other than the 95 percent confidence level might yield a dif-
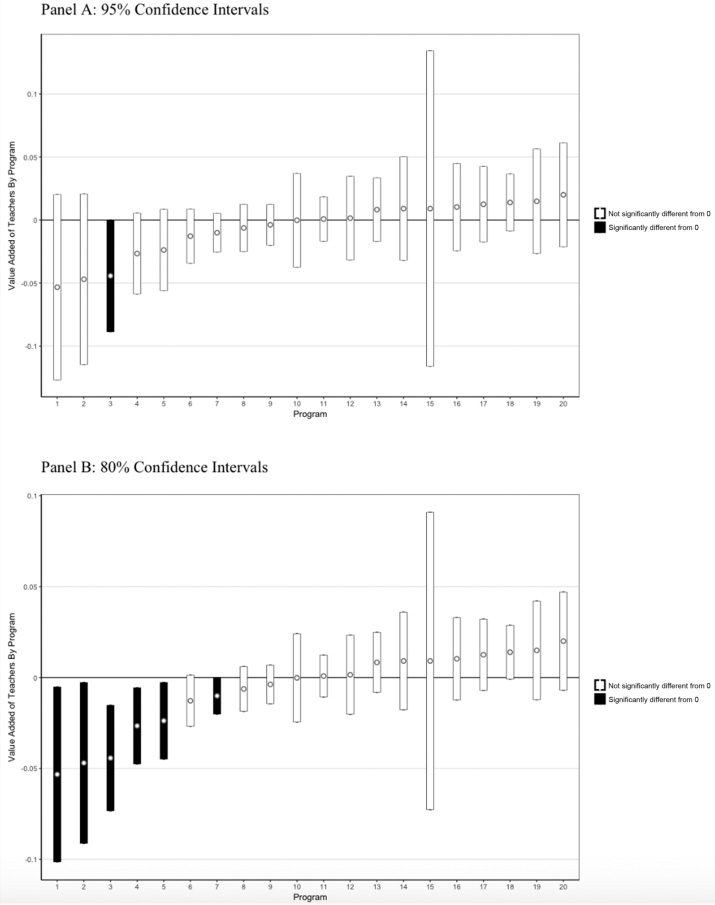
ferent conclusion. Cifra 1, which is based on analysis of teacher preparation programs
in Washington State (Goldhaber, Liddle, and Theobald 2013), illustrates this point.
Cifra 1 shows the estimated math value added of teachers from the twenty pro-
grams in Washington State.6 The 95 percent confidence intervals, which are shown
in panel A, often overlap across programs, suggesting those programs are not readily
distinguishable from one another, at least with 95 percent confidence. El 95 por ciento
confidence intervals often also include zero (cases where it does have white bars and
where it does not have black bars), here defined as the average effectiveness of teachers
who transfer in from out-of-state; when this happens, the program produces graduates
who are not statistically distinguishable from teachers imported from outside Washing-
tonelada. By this metric, no programs are significantly different from one another, y solo
on nonexperimental data where the sample is fixed, creating a tradeoff between Type I and Type II errors.
Studies testing against a null hypothesis using the 95 percent confidence standard often lack sufficient power
to detect what might be considered to be reasonably sized treatment effects.
5. For more on value added and other measures of teacher performance, see www.carnegieknowledgenetwork
.org/briefs/value-added/value-added-other-measures/.
6. The estimates reported in figure 1 are derived from the coefficients in column 1 de mesa 4 in Goldhaber, Liddle,
and Theobald (2013).
388
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
F
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Carrie Conaway and Dan Goldhaber
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
F
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
F
/
.
Nota: The estimates reported in figure 1 are derived from the coefficients in column 1 de mesa 4 in Goldhaber, Liddle, and Theobald
(2013).
Cifra 1. Estimated Mathematics Value Added by Teacher Preparation Programs, Washington State
one is different from zero, eso es, the average out-of-state prepared teacher receiving a
credential.7
But what if the standard were 80 percent confidence instead, as is shown in panel
B? Then twelve programs are different from one another (es decir., have nonoverlapping
7. The reality of this type of comparison is more complex than we present here (for the sake of parsimony) as it
involves multiple comparisons (von Hippel and Bellows 2018), but the general idea holds.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
389
Standards of Evidence for Decision Making
confidence intervals), and six are different from the impact of the average teacher who
comes into the Washington workforce from out-of-state. What level of confidence is the
right one for policy makers to use in this context? A pesar de 95 percent confidence is the
default figure, this is by no means a magic number. The right value depends critically
on contextual factors, such as the anticipated behavioral responses to the identifica-
tion of individual programs or the alternative policy options for judging the quality of
programs.We return to these points in the next subsection.
Exacerbating these issues, reporting only magnitudes and statistical significance of
findings neglects to provide other crucial information for decision making. Much of
the literature on how managers make decisions, por ejemplo, presumes the decision
maker is comparing discrete potential strategies and can make a decision by comparing
the probability of the outcomes from each. En realidad, this type of information is often
not available in a way that meets decision makers’ needs.
Por ejemplo, several well-executed studies now show that teachers certified by the
National Board for Professional Teaching Standards (NBPTS) are more effective on av-
erage than those who are not.8 This headline emphasizes the statistical significance
of these findings. But if a policy maker were considering highlighting specific NBPTS
teachers as exemplars of excellence in their community or providing them with greater
compensación, a more relevant question might be: What is the probability that recogniz-
ing NBPTS teachers in my district or state would be rewarding teachers who are more
effective than average? The answer to this question, at least in one context, is about 55
a 60 por ciento (Goldhaber 2006). Whether that rate is high or low is a value judgment,
but the framing around probabilities seems more in line with how this question might
be debated in policy terms than whether a finding is statistically significant.
The Policy-Making Context is Critical, Yet Frequently Overlooked
So, what standard of evidence should policy makers use when making policy decisions?
Looking at individual studies, por supuesto, policy makers should evaluate evidence by
the same criteria that researchers use, with consideration to reliability, validity, y el
appropriate standard of evidence. But policy makers also need to consider contextual
factores, such as the degree of uncertainty in findings across multiple studies and the
relevant policy alternatives.
A good place for policy makers to start is a careful consideration of the policy goal
and what it implies for the standard of evidence they should adopt. Por ejemplo, if the
goal is to inform individuals about the decisions they face, the standard of evidence
may not need to be terribly high. In an apt analogy, kane (2013) notes that a person on
the way to one of two hospitals for treatment for a heart attack may well care whether
the mortality rate for heart attack patients is 75 percent at one hospital versus 20 por-
cent at the other—even if the differences between the two hospitals are not statistically
significant. Similarmente, information about student test results is meant to describe and
contextualize a student’s performance. It could contribute one piece of data among
many that might inform parents’ decisions around, decir, placing their child in tutoring
services. This type of use doesn’t require much certainty in the test scores. One would
8. See Cowan and Goldhaber (2016) for evidence from Washington State and a review.
390
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
F
/
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
F
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Carrie Conaway and Dan Goldhaber
want to be much more certain, sin embargo, if those test results are the only factor being
used to make those decisions.
This same principle applies to decisions about institutions. Returning again to the
teacher preparation example: If the policy objective were to close low-performing pro-
grams solely on the basis of value-added measures (a policy, to be clear, that we are not
recommending), then policy makers might wish to seek very high levels of certainty
that a program is underperforming before taking such a drastic action. Por el contrario, si
the goal were to identify high-performing programs to study more closely for potential
effective practices to share with others, or to identify lower-performing programs that
might deserve a bit more scrutiny or review, then a lower bar for identifying outliers
might be more than sufficient.
Another contextual consideration is the weight of the evidence on an issue. Part of
what adds uncertainty to a policy decision is how confident policy makers can be in the
likely impact of a policy, based on prior research. But the research literature often does
not consistently point in the same direction regarding the likely impact of a policy, y
all evidence is contextually specific—generated from a particular group of students,
assigned to teachers with particular qualifications, in a particular type of school and
distrito, in a particular time period and policy environment. To decrease uncertainty in
a policy outcome, policy makers must weigh these factors to determine which findings
have greatest relevance for their needs. Por ejemplo, much of the national research on
charter schools suggests that charters, on average, have impacts on student outcomes
that are fairly similar to those of traditional public schools (Betts and Tang 2011; CREDO
2013). In Massachusetts, sin embargo, the impact of charters in urban areas appears to be
substantially larger, que van desde 0.2 a 0.4 standard deviations per year depending on
subject and grade level (Abdulkadiro˘glu et al. 2011). De este modo, if policy makers wish to be
more certain of a positive impact from introducing charters, they might consider how
well their context matches what makes urban charters successful in Massachusetts: a
strong state authorizing an accountability policy, particular approaches to pedagogy and
school climate, and so forth.9
The cost and reversibility of policy choices also matters. Choices are inherently
riskier when they are harder to reverse, whether because of the level of investment,
political considerations, o ambos. Class size reduction, Por ejemplo, is a risky invest-
ment from the point of view of likely impact on student achievement, as most recent
studies show little to no effect (Hoxby 2000; Rivkin, Hanushek, and Kain 2005; Dar,
Glewwe, and Whitler 2012; Bosworth 2014; Schwartz, Zabel, and Leardo 2017).10 Fur-
ther, it is expensive relative to the likely gain, and it can create unanticipated negative
impacts on average teacher quality as districts must dig deeper into their hiring pools
to employ sufficient teachers (Schrag 2006; Gilraine 2017). But it is also a policy that,
once implemented, is extremely hard to reverse, as it creates difficult conversations in
9. A related but subtler point is that an intervention may have positive effects across all contexts but be more suc-
cessful relative to some baselines than others. Confidence intervals are rarely reported in a way that quantifies
the variation across treatment effects, which may cause policy makers to underestimate the true riskiness of an
intervención.
10. Nota, sin embargo, that although class size reduction appears to have limited effects on student test scores, alguno
evidence suggests smaller classes may positively affect later life outcomes, such as college attendance (Chetty
et al. 2011).
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
F
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
391
Standards of Evidence for Decision Making
schools when parents see the number of chairs in their child’s classroom increasing
and worry about whether their child is receiving sufficient individual attention. Para todos
these reasons, policy makers should be more cautious when considering a class size re-
duction policy than another option that represents a smaller investment or is otherwise
easier to reverse.
Arguably the most important contextual feature is the relevant policy alternative.
De nuevo, consider the issue of rating teacher preparation programs. The AERA (2015)
statement about using value added to evaluate or rate programs notes, “There are
promising alternatives currently in use in the United States that merit attention . . .
[como] teacher observation data, peer assistance and review models” (pag. 451). Estos
methods may well have promise for characterizing the quality of teacher preparation
programas, but they also inherently involve uncertainty. The uncertainty inherent in
other forms of program evaluation may not be quantifiable but that does not mean it
does not exist.
The policy alternative that may be most frequently overlooked is sticking with the
status quo. When the status quo is the alternative, policy makers should be particu-
larly cautious about making changes to a successful status quo policy or program, y
they should tolerate a bit more risk when the status quo is likely to be yielding poor
resultados. Teacher compensation is an instance where the status quo has powerful iner-
tia but perhaps should not. The overwhelming majority of teachers are paid according
to a single salary schedule that rewards years of experience and, generally, having a
master’s degree (USDOE 2012). Presumiblemente, a goal of this policy is to pay more effec-
tive teachers more than less effective teachers, since they contribute more to student
mejora. But although research finds that teachers rapidly improve as they gain
experience early in their careers (p.ej., Rockoff 2004), strikingly little evidence supports
the notion that attaining a master’s degree has an impact on teacher effectiveness—
or even that teachers with master’s degrees tend to be more effective.11 Policy makers
wishing to compensate for teacher effectiveness—at least, as measured by impact on
student test scores—should therefore be more cautious about tinkering with changes to
rewards associated with teacher experience than they are about changing the master’s
premium. Despite this, sin embargo, most school systems in the country still pay teachers
with master’s degrees more than those with bachelor’s degrees.12
This highlights a final point: Because the purpose of education is to improve out-
comes for students, policy makers should make judgments about benefits, costos, y
uncertainty from a student perspective. But too often the focus is on the risks of a
change to the adults in the system rather than the risk of the status quo on students.
This can cause inertia and ultimately may harm the students the education system is
intended to serve.
11. Note that this is the finding for master’s degrees in general (Ladd and Sorenson 2015; Goldhaber 2016). Evi-
dence does suggest that holding master’s degree in a subject, particularly math and science, predicts teacher
effectiveness in that subject area (Goldhaber and Brewer 1997; Coenen et al. 2017; Bastian 2019).
12. Why is the master’s pay premium sticky despite the empirical evidence that it is not well aligned with teacher
effectiveness? We believe one reason is that the risks involved are typically framed around the adults in the
system rather than the students that the school system is supposed to serve. It is pretty certain that paying
teachers more for master’s degrees will not enhance student learning. But from an adult perspective, qué
might replace the master’s premium, and therefore how one might earn future salary raises, is highly uncertain.
392
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
F
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Carrie Conaway and Dan Goldhaber
CONCLUSIÓN
All policy decisions require policy makers to make a bet on the future with the informa-
tion available today. Ignoring the nuances inherent in how information from research
will be used, and thereby holding all purposes to an equivalent, arbitrary standard of
statistical significance, does a disservice to both the research and policy-making com-
munities. It renders many research findings irrelevant for policy because too little in-
formation was provided about their context. And it may cause policy makers to err on
the side of inaction or to make uninformed bets.
How can researchers help? For starters, by not perpetuating the problem. por ejemplo-
amplio, they can report confidence intervals rather than up or down interpretations of
p-values (Amrhein, Greenland, and McShane 2019). They can show how their findings
might differ under different standards of evidence, as we demonstrated here with the
teacher preparation program example. They can also provide more information about
the reliability and validity of their findings and the context in which they were produced.
It is particularly important they do so in the more accessible versions of their work likely
to be seen directly by policy makers: abstracts, summaries, and policy briefs.
Asimismo, policy makers should recognize the statistician’s standard for statisti-
cal significance often results in a message of “this intervention works” or “it doesn’t
work”—but this message is oversimplified. Nothing about the 95 percent confidence
standard is special, and neither they nor researchers should blindly adhere to it. Bastante,
both should carefully consider the context in which decisions are made and the policy
alternative for the decision, as well as how both factors influence the level of confidence
they need for making policy choices. Sometimes context will call for making decisions
that research suggests will lead to (precisely estimated) marginal improvements, pero
other times it will be appropriate to go with the (underpowered) moonshot. Thinking
clearly about the full range of options and the standard of evidence each requires is
central to good policy making.
ACKNOWLEDGEMENTS
We are grateful to James Cowan, Bob Lee, Roddy Theobald, Katharine Strunk, and two anony-
mous referees for helpful comments on earlier drafts. Note that the views expressed are those of
the authors and do not necessarily reflect the views of the institutions with which the authors are
affiliated.
REFERENCIAS
Abdulkadiro˘glu, Atila, Joshua D. Angrist, Susan M. Dinarski, Tomas J.. kane, and Parag A.
Pathak. 2011. Accountability and flexibility in public schools: Evidence from Boston’s charters
and pilots. Revista trimestral de economía 126(2): 699–748.
American Educational Research Association (AERA). 2015. AERA issues statement on the use of
value-added models in evaluation of educators and educator preparation programs. https disponibles://
www.aera.net/Newsroom/News-Releases-and-Statements/AERA-Issues-Statement-on-the-Use
-of-Value-Added-Models-in-Evaluation-of-Educators-and-Educator-Preparation-Programs. Acc-
essed 10 Septiembre 2019.
American Educational Research Association, American Psychological Association, and National
Council on Measurement in Education. 2014. Standards for educational and psychological testing.
Washington, corriente continua: AERA.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
/
F
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
F
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
393
Standards of Evidence for Decision Making
Amrhein, Valentin, Sander Greenland, and Blake Mcshane. 2019. Scientists rise up against sta-
tistical significance. Naturaleza 567(7748): 305–307. doi: 10.1038/d41586-019-00857-9.
Flecha, Kenneth J., and Robert C. Lind. 1978. Uncertainty and the evaluation of public investment
decisiones. In Uncertainty in economics, edited by Peter Diamond and Michael Rothschild, páginas. 403–
421. Nueva York: Prensa académica.
Bastian, Kevin C. 2019. A degree above? The value-added estimates and evaluation ratings of
teachers with a graduate degree. Education Finance and Policy 14(4): 652–678. doi: 10.1162/edfp
_a_00261.
apuestas, Julian R., and Y. Emily Tang. 2011. The effect of charter schools on student achievement:
A meta-analysis of the literature. seattle, Washington: National Charter School Research Project, Center
on Reinventing Public Education.
Bosworth, ryan. 2014. Class size, class composition, and the distribution of student achievement.
Education Economics 22(2): 141–165.
Bradley, Ricardo, and Mareile Drechsler. 2013. Types of uncertainty. Erkenntnis 79(6): 1225–1248.
Center for Research on Education Outcomes (CREDO). 2013. National charter school study. Palo
Alto: CREDO, Universidad Stanford.
Chetty, Raj, John N. Friedman, Nathaniel Hilger, Emmannuel Saez, Diane Whitmore Schanzen-
bach, and Danny Yagan. 2011. How does your kindergarten classroom affect your earnings? Evi-
dence from Project STAR. Revista trimestral de economía 126(4): 1593–1660.
Dar, Hyunkuk, Paul Glewwe, and Melissa Whitler. 2012. Do reductions in class size raise stu-
dents’ test scores? Evidence from population variation in Minnesota’s elementary schools. Eco-
nomics of Education Review 31(3): 77–95.
Coenen, johan, Ilja Cornelisz, Wim Groot, Henriette Maassen van denBrink, and Chris Van Klav-
eren. 2017. Teacher characteristics and their effects on student test scores: A systematic review.
Journal of Economic Surveys 32(3): 848–877. doi: 10.1111/joes.12210.
Cowan, Joshua, and Dan Goldhaber. 2016. National Board certification and teacher effectiveness:
Evidence from Washington State. Journal of Research on Educational Effectiveness 9(3): 233–258.
Gilraine, Miguel. 2017. Multiple treatments from a single discontinuity: An application to class
tamaño. Artículo inédito, universidad de toronto.
Goldhaber, Dan. 2006. National Board teachers are more effective, but are they in the classrooms
where they’re needed the most? Education Finance and Policy 1(3): 372–382.
Goldhaber, Dan. 2016. In schools, teacher quality matters most: Today’s research reinforces Cole-
man’s findings. Education Next 16(2): 56–62.
Goldhaber, Dan. 2019. Evidence-based teacher preparation: Policy context and what we know.
Revista de formación docente 70(2): 90–101.
Goldhaber, Dan, and Dominic Brewer. 1997. Why don’t schools and teachers seem to matter?
Assessing the impact of unobservables on educational productivity. Journal of Human Resources
32(3): 505–523. doi: 10.2307/146181
Goldhaber, Dan, Stephanie Liddle, and Roddy Theobald. 2013. The gateway to the profession:
Assessing teacher preparation programs based on student achievement. Economics of Education
Revisar 34:29–44.
394
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
/
.
F
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Carrie Conaway and Dan Goldhaber
Goldhaber, Dan, and Umut Özek. 2019. How much should we rely on student test achievement
as a measure of success? Investigador Educativo 48(7): 479–483. doi: 10.3102/0013189X19874061
Goodwin, Pablo, and George Wright. 2014. Decision analysis for management judgment, fifth edition.
Londres: John Wiley & Sons.
Holden, Kristian L. 2016. Buy the book? Evidence on the effect of textbook funding on school-level
logro. Revista económica americana: Economía Aplicada 8(4): 100–127.
Hoxby, Caroline M. 2000. The effects of class size on student achievement: New evidence from
population variation. Revista trimestral de economía 115(4): 1239–1285.
kane, Tomas J.. 2013. Presumed averageness: The mis-application of classical hypothesis
testing in education. https disponibles://www.brookings.edu/research/presumed-averageness-the
-mis-application-of-classical-hypothesis-testing-in-education/. Accedido 10 Septiembre 2019.
kane, Tomás J., y Douglas O.. Staiger. 2002. The promise and pitfalls of using imprecise
school accountability measures. Journal of Economic Perspectives 16(4): 91–114.
Koretz, Daniel. 2009. Measuring up: What educational testing really tells us. Cambridge, MAMÁ: Har-
vard University Press.
Koretz, Daniel. 2017. The testing charade: Pretending to make schools better. chicago: Universidad de
Chicago Press.
muchacho, Helen F., and Lucy C. Sorensen. 2015. Do Master’s degrees matter? Advanced degrees,
career paths, and the effectiveness of teachers. CALDER Working Paper No. 136, American In-
stitutes for Research.
Penuel, William R., Derek C. Briggs, Kristen L. Davidson, Corinne Herlihy, David Sherer,
Heather C. Colina, Caitlin Farrell, and Anna Ruth Allen. 2017. How school and district leaders
access, perceive, and use research. AERA Open 3(2): 1–17. doi: 10.1177/2332858417705370.
Rivkin, Steven G., eric a. Hanushek, and John F. Kain. 2005. Maestros, escuelas, y académico
logro. Econometrica 73(2): 417–458.
Rockoff, Jonah E. 2004. The impact of individual teachers on student achievement: Evidencia
from panel data. Revisión económica estadounidense 94(2): 247–252.
Rockoff, Jonah, and Lesley J. Tornero. 2010. Short-run impacts of accountability on school quality.
Revista económica americana: Economic Policy 2(4): 119–147.
Rouse, Cecilia Elena, Jane Hannaway, Dan Goldhaber, and David Figlio. 2013. Feeling the Florida
calor? How low-performing schools respond to voucher and accountability pressure. Americano
Economic Journal: Economic Policy 5(2): 251–281.
Schrag, Peter. 2006. Policy from the hip: Class-size reduction in California. Brookings Papers on
Education Policy 9(2006/2007): 229–243.
Schwartz, Amy Ellen, Jeffrey Zabel, and Michele Leardo. 2017. Class size and resource alloca-
ción. ESE Policy Brief. Malden, MAMÁ: Massachusetts Department of Elementary and Secondary
Educación.
Shober, Arnold F. 2016. Individuality or community? Bringing assessment and accountability to
K–16 education. In The convergence of K–12 and higher education: Policies and programs in a changing
era, edited by Christopher P. Loss and Patrick J. McGuinn, páginas. 67–86. Cambridge, MAMÁ: Harvard
Education Press.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
/
F
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
395
Standards of Evidence for Decision Making
United States Department of Education (USDOE). 2012. Schools and staffing survey. Washington,
corriente continua: National Center for Education Statistics.
von Hippel, Paul T., and Laura Bellows. 2018. How much does teacher quality vary across teacher
preparation programs? Reanalyses from six states. Revisión de la economía de la educación 64:298–312.
Wasserstein, Ronald L., and Nicole A. Lázaro. 2016. The ASA’s statement on p-values: Context,
proceso, and purpose. American Statistician 70(2): 129–133.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
F
/
mi
d
tu
mi
d
pag
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
5
2
3
8
3
1
6
9
3
4
9
4
mi
d
pag
_
a
_
0
0
3
0
1
pag
d
.
/
F
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
396