Data-Driven Sentence Simplification: Survey
and Benchmark
Fernando Alva-Manchego
University of Sheffield
Departamento de Ciencias de la Computación
f.alva@sheffield.ac.uk
Carolina Scarton
University of Sheffield
Departamento de Ciencias de la Computación
c.scarton@sheffield.ac.uk
Lucia Specia
Imperial College London
Department of Computing
l.specia@imperial.ac.uk
Sentence Simplification (SS) aims to modify a sentence in order to make it easier to read and
understand. In order to do so, several rewriting transformations can be performed such as
replacement, reordering, and splitting. Executing these transformations while keeping sentences
grammatical, preserving their main idea, and generating simpler output, is a challenging and
still far from solved problem. In this article, we survey research on SS, focusing on approaches
that attempt to learn how to simplify using corpora of aligned original-simplified sentence
pairs in English, which is the dominant paradigm nowadays. We also include a benchmark of
different approaches on common data sets so as to compare them and highlight their strengths
and limitations. We expect that this survey will serve as a starting point for researchers interested
in the task and help spark new ideas for future developments.
1. Introducción
Text Simplification (TS) is the task of modifying the content and structure of a text in
order to make it easier to read and understand, while retaining its main idea and ap-
proximating its original meaning. A simplified version of a text could benefit users with
several reading difficulties, such as non-native speakers (Paetzold 2016), people with
aphasia (Carroll et al. 1998), dyslexia (Rello et al. 2013b), or autism (evans, Orasan, y
Dornescu 2014). Simplifying a text automatically could also help improve performance
Envío recibido: 8 Junio 2018; revise d version received: 9 Agosto 2019; accepted for publication:
15 Septiembre 2019.
https://doi.org/10.1162/COLI a 00370
© 2020 Asociación de Lingüística Computacional
Publicado bajo una Atribución Creative Commons-NoComercial-SinDerivadas 4.0 Internacional
(CC BY-NC-ND 4.0) licencia
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
on other language processing tasks, such as parsing (Chandrasekar, Doran, and Srinivas
1996), summarization (Vanderwende et al. 2007; Silveira and Branco 2012), información
extraction (evans 2011), etiquetado de roles semánticos (Vickrey and Koller 2008), and Machine
Translation (MONTE) (Hasler et al. 2017).
Most research on TS has focused on studying simplification of individual sentences.
Reducing the scope of the problem has allowed the easier collection and curation of
corpus, as well as adapting methods from other text generation tasks, mainly MT. Él
can be argued that “true” TS (es decir., nivel de documento) cannot be achieved by simplifying
sentences one at a time, and we make a call in Section 6 for the field to move in that
direction. Sin embargo, because the goal of this article is to review what has been done in
TS so far, our survey is limited to Sentence Simplification (SS).
When simplifying sentences, different rewriting transformations are performed,
which range from replacing complex words or phrases for simpler synonyms, to chang-
ing the syntactic structure of the sentence (p.ej., splitting or reordering components).
Modern SS approaches are data-driven; eso es, they attempt to learn these transfor-
mations using parallel corpora of aligned original-simplified sentences. This results in
general simplification models that could be used for any specific type of audience, de-
pending on the data used during training. Although significant progress has been made
in this direction, current models are not yet able to execute the task fully automatically
with the performance levels required to be directly useful for end users. Tal como, nosotros
believe it is important to review current research in the field, and to analyze it critically
and empirically to better identify areas that could be improved.
In this article, we present a survey of research on data-driven SS for English—
the dominant paradigm nowadays—and complement it with a benchmark of models
whose outputs on standard data sets are publicly available. Our survey differs from
other SS surveys in several aspects:
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
•
•
•
Shardlow (2014) overviews automatic SS with short notes on different
approaches for the task, whereas we provide a more in-depth explanation
of the mechanics of how the simplification models are learned, and review
the resources used to train and test them.
Siddharthan (2014) focuses on the motivations for TS and mostly provides
details for the earliest automatic SS approaches, which are not necessarily
data-driven. We review state-of-the-art models, focusing on those
that learn to rewrite a text from examples available in corpora
(es decir., data-driven), leaving aside approaches based on manually
constructed rules.
Saggion (2017) introduces data-driven SS in a Learning to Simplify book
capítulo. We provide a more extensive literature review of a larger number
of approaches and resources. Por ejemplo, we include models based on
neural sequence-to-sequence architectures (Sección 4.4).
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Finalmente, our survey introduces a benchmark with common data sets and met-
rics, so as to provide an empirical comparison between different approaches. Este
benchmark consists of commonly used evaluation metrics and novel measures of per-
transformation performance.
136
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
1.1 Motivation for Sentence Simplification
Different types of readers could benefit from a simplified version of a sentence. Mason
and Kendall (1978) report that separating a complex sentence into shorter structures
can improve comprehension in low literacy readers. Siddharthan (2014) refers to stud-
ies on deaf children that show their difficulty dealing with complex structures, como
coordination, subordination, and pronominalization (Quigley, Fuerza, and Steinkamp
1977), or passive voice and relative clauses (Robbins and Hatcher 1981). Shewan (1985)
states that aphasic adults reduce their comprehension of a sentence as its grammatical
complexity increases. An eye-tracking study by Rello et al. (2013a) determined that
people with dyslexia read faster if more frequent words are used in a sentence, and also
that their understanding of the text improves with shorter words. Crossley et al. (2007)
point out that simplified texts are the most commonly used for teaching beginners and
intermediate English learners.
Motivated by the potential benefits of simplified texts, research has been dedicated
to developing simplification methods for specific target audiences: escritores (Candido Jr.
et al. 2009), low literacy readers (Watanabe et al. 2009), English learners (Petersen 2007),
non-native English speakers (Paetzold 2016), niños (De Belder and Moens 2010), y
people suffering from aphasia (Devlin and Tait 1998; Carroll et al. 1998), dyslexia (Rello
et al. 2013b), or autism (evans, Orasan, and Dornescu 2014). Además, simplifying
sentences automatically could improve performance on other Natural Language Pro-
cessing tasks, which has become evident in parsing (Chandrasekar, Doran, and Srinivas
1996), summarization (Siddharthan, Nenkova, and McKeown 2004; Vanderwende et al.
2007; Silveira and Branco 2012), information extraction (Klebanov, Caballero, and Marcu
2004; evans 2011), relation extraction (Niklaus et al. 2016), semantic role labeling Vickrey
and Koller 2008, and MT (Mirkin, Venkatapathy, and Dymetman 2013; Mishra et al.
2014; ˇStajner and Popovi´c 2016; Hasler et al. 2017). We refer the interested reader to
Siddharthan (2014) for a more in-depth review of studies on the benefits of simplifica-
tion for different target audiences and Natural Language Processing applications.
1.2 Text Transformations for Simplification
A few corpus studies have been carried out to determine how humans simplify sen-
tenencias. These studies shed some light on the simplification transformations that an
automatic SS model should be expected to perform.
Petersen and Ostendorf (2007) analyzed a corpus of 104 original and manually
simplified news articles in English to understand how professional editors performed
the simplifications, so they can later propose ways to automate the process. For their
estudiar, every sentence in the simplified version of an article was manually aligned to a
corresponding sentence (or sentences) in the original version. Each original-simplified
alignment was then categorized as dropped (1 a 0), dividir (1 to ≥ 2), total (1 a 1), o
merged (2 a 1). Their analysis then focused on the split and dropped alignments. El
authors determined that the decision to split an original sentence depends on some
syntactic features (number of nouns, pronouns, verbos, etc.) y, most importantly, es
longitud. Por otro lado, the decision to drop a sentence may be influenced by its
position in the text and how redundant the information it contains is.
Alu´ısio et al. (2008) studied six corpora of simple texts (different genres) y
a corpus of non-simple news text in Brazilian Portuguese. Their analysis included
counting simple words and discourse markers; calculating average sentence lengths;
137
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
and counting prepositional phrases, adjectives, adverbs, clausulas, and other features.
Como resultado, a manual for Brazilian Portuguese SS was elaborated that contains a set
of rules to perform the task (Specia, Alu´ısio, and Pardo 2008). Además, as part of
the same project, Caseli et al. (2009) implemented a tool to aid manual SS considering
the following transformations: non-simplification, simple rewriting, strong rewriting
(similar content but very different writing), subject-verb-object reordering, passive to
active voice transformation, clause reordering, sentence splitting, sentence joining, y
full or partial sentence dropping.
Bott and Saggion (2011a) worked with a data set of 200 news articles in Spanish
with their corresponding manual simplifications. After automatically aligning the sen-
tenencias, the authors determined the simplification transformations performed: cambiar
(p.ej., difficult words, pronouns, voice of verb), delete (palabras, phrases or clauses), insert
(word or phrases), dividir (relative clauses, coordination, etc.), proximization (add locative
phrases, change from third to second person), reorder, select, and join (oraciones). El
first four transformations are the most common in their corpus.
1.3 Related Text Rewriting Tasks
From the definition of simplification, the task could easily be confused with summariza-
ción. As Shardlow (2014) points out, summarization focuses on reducing length and
content by removing unimportant or redundant information. In simplification, alguno
deletion of content can also be performed. Sin embargo, we could additionally replace
words by more explanatory phrases, make co-references explicit, add connectors to
improve fluency, Etcétera. Como consecuencia, a simplified text could end up be-
ing longer than its original version while still improving the readability of the text.
Por lo tanto, although summarization and simplification are related, they have different
objectives.
Another related task is sentence compression, which consists of reducing the length
of a sentence without losing its main idea and keeping it grammatical (Jing 2000). Mayoría
approaches focus on deleting unnecessary words. Tal como, this could be considered as
a subtask of the simplification process, which also encompasses more complex transfor-
mations. Abstractive sentence compression (Cohn and Lapata 2013), por otro lado,
does include transformations like substitution, reordering, and insertion. Sin embargo, el
goal is still to reduce content without necessarily improving readability.
Split-and-rephrase (Narayan et al. 2017) focuses on splitting a sentence into several
shorter ones, and making the necessary rephrasings to preserve meaning and gram-
maticality. Because SS could involve deletion, it would not always be able to preserve
significado. Bastante, its editing decisions may remove details that could distract the reader
from understanding the text’s central message. Tal como, split-and-rephrase could be
considered as another possible text transformation within simplification.
1.4 Structure of this Article
In the remainder of this article, Sección 2 details the most commonly used resources
for SS, with emphasis on corpora used to train SS models. Sección 3 explains how the
output of a simplification model is generally evaluated. The two main contributions of
this article are given in Section 4, which presents a critical summary of the different ap-
proaches that have been used to train data-driven sentence models, y Sección 5, cual
benchmarks most of these models using common metrics and data sets to compare them
138
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
and establish the advantages and disadvantages of each approach. Finalmente, based on the
literature review and analysis presented, en la sección 6 we provide directions for future
research in the area.
2. Corpora for Simplification
A data-driven SS model is one that learns to simplify from examples in corpora. en par-
particular, for learning sentence-level transformations, a model requires instances of origi-
nal sentences and their corresponding simplified versions. En esta sección, we present the
most commonly used resources for SS that provide these examples, including parallel
corpora and dictionary-like databases. For each parallel corpus, especially, we outline
the motivations behind it, how the much-necessary sentence alignments were extracted,
and report on studies about the suitability of the resource for SS research. We describe
resources for English in detail and give an overview of resources available for other
idiomas.
As presented in Section 1.2, an original sentence could be aligned to one (1-to-1) o
más (1-to-N) simplified sentences. Al mismo tiempo, several original sentences could
be aligned to a single simplified one (N-to-1). The corpora we describe in this section
contain many of these types of alignments. In the remainder of this article, we use the
term simplification instance to refer to any type of sentence alignment in a general way.
2.1 Main – Simple English Wikipedia
The Simple English Wikipedia (SEW)1 is a version of the online English Wikipedia
(EW)2 primarily aimed at English learners, but which can also be beneficial for stu-
abolladuras, niños, and adults with learning difficulties (Simple Wikipedia 2017b). Con
this purpose, articles in SEW use fewer words and simpler grammatical structures. Para
ejemplo, writers are encouraged to use the list of words of Basic English (Ogden 1930),
which contains 850 words presumed to be sufficient for everyday life communication.
Authors also have guidelines on how to create syntactically simple sentences by, para
ejemplo, giving preference to the subject-verb-object order for their sentences, y
avoiding compound sentences (Simple Wikipedia 2017a).
2.1.1 Simplification Instances. Much of the popularity of using Wikipedia for research in
SS comes from publicly available automatically collected alignments between sentences
of equivalent articles in EW and SEW. Several techniques have been explored to produce
such alignments with reasonable quality.
A first approach consists of aligning texts according to their term frequency–inverse
document frequency (tf-idf) cosine similarity. For the PWKP corpus, Zhu, Bernhard, y
Gurévich (2010) measured this directly at sentence-level between all sentences of each
article pair, and sentences whose similarity was above a certain threshold were aligned.
For the C&K-1 (Coster and Kauchak 2011b) and C&K-2 (Kauchak 2013) corpus, el
authors first aligned paragraphs with tf-idf cosine similarity, and then found the best
overall sentence alignment with the dynamic programming algorithm proposed by
Barzilay and Elhadad (2003). This algorithm takes context into consideration: The sim-
ilarity between two sentences is affected by their proximity to pairs of sentences with
1 https://simple.wikipedia.org.
2 https://wikipedia.org.
139
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Mesa 1
Summary of parallel corpora extracted from EW and SEW. An original sentence can be aligned
to one (1-to-1) or more (1-to-N) unique simplified sentences. A (*) indicates that some aligned
simplified sentences may not be unique.
corpus
Instances
Alignment Types
PWKP (Zhu, Bernhard, and Gurevych 2010)
C&K-1 (Coster and Kauchak 2011b)
RevisionWL (Woodsend and Lapata 2011a)
AlignedWL (Woodsend and Lapata 2011a)
C&K-2 (Kauchak 2013)
EW-SEW (Hwang et al. 2015)
sscorpus (Kajiwara and Komachi 2016)
WikiLarge (Zhang and Lapata 2017)
108k
137k
15k
142k
167k
392k
493k
286k
1-to-1, 1-to-N
1-to-1, 1-to-N
1-to-1*, 1-to-N*, N-to-1*
1-to-1, 1-to-N
1-to-1, 1-to-N
1-to-1
1-to-1
1-to-1*, 1-to-N*, N-to-1*
high similarity. Finalmente, Woodsend and Lapata (2011a) also adopt the two-step process
of Coster and Kauchak (2011b), using tf-idf when compiling the AlignedWL corpus.
Another approach is to take advantage of the revision histories in Wikipedia arti-
cles. When editors change the content of an article, they need to comment on what the
change was and the reason for it. For the RevisionWL corpus, Woodsend and Lapata
(2011a) looked for keywords simple, clarification, or grammar in the revision comments
of articles in SEW. Entonces, they used Unix commands diff and dwdiff to identify mod-
ified sections and sentences, respectivamente, to produce the alignments. This approach is
inspired by Yatskar et al. (2010), who used a similar method to automatically extract
high-quality lexical simplifications (p.ej., collaborate → work together).
More sophisticated techniques for measuring sentence similarity have also been
explored. For their EW-SEW corpus, Hwang et al. (2015) implemented an alignment
method using word-level semantic similarity based on Wiktionary.3 They first created
a graph using synonym information and word-definition co-occurrence in Wiktionary.
Entonces, similarity is measured based on the number of shared neighbors between words.
This word-level similarity metric is then combined with a similarity score between de-
pendency structures. This final similarity rate is used by a greedy algorithm that forces
1-to-1 matches between original and simplified sentences. Kajiwara and Komachi (2016)
propose several similarity measures based on word embeddings alignments. Given two
oraciones, their best metric (1) finds, for each word in one sentence, the word that is
most similar to it in the other sentence, y (2) averages the similarities for all words
in the sentence. For symmetry, this measure is calculated twice (simplified → original,
original → simplified) and their average is the final similarity measure between the two
oraciones. This metric was used to align original and simplified sentences from articles
en un 2016 Wikipedia dump and produce the sscorpus. It contains 1-to-1 alignments from
sentences whose similarity was above a certain threshold.
The alignment methods described have produced different versions of parallel cor-
pora from EW and SEW, which are currently used for research in SS. Mesa 1 resume
some of their characteristics.
3 Wiktionary is a free dictionary in the format of a wiki so that everyone can add and edit word definitions.
Available at https://en.wiktionary.org.
140
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
RevisionWL is the smallest parallel corpus listed and its instances may not be
as clean as those of the others. A 1-to-1* alignment means that an original sentence
can be aligned to a simplified one that appears more than once in the corpus. A
1-to-N* alignment means that an original sentence can be aligned to several simplified
oraciones, pero algunos (or all of them) repeat more than once in the corpus. Por último, a
N-to-1* alignment means that several original sentences can be aligned to one simplified
sentence that repeats more than once in the corpus. This sentence repetition is indicative
of misalignments, which makes this corpus noisy.
EW-SEW and sscorpus provide the largest number of instances. These corpora also
specify a similarity score per aligned sentence pair, which can help filter out instances
with less confidence to reduce noise. Desafortunadamente, they only contain 1-to-1 alignments.
Despite being smaller in size, PWKP, C&K-1, C&K-2, and AlignedWL also offer 1-to-N
alignments, which is desirable if we want an SS model to learn how to split sentences.
Finalmente, WikiLarge (Zhang and Lapata 2017) joins instances from four Wikipedia-
based data sets: PWKP, C&K-2, AlignedWL, and RevisionWL. It is the most common
corpus used for training neural sequence-to-sequence models for SS (see Sec. 4.4). Cómo-
alguna vez, it is not the biggest in size currently available, and can contain noisy alignments.
2.1.2 Suitability for Simplification Research. Several studies have been carried out to deter-
mine the characteristics that make Wikipedia-based corpora suitable (or unsuitable) para
the simplification task.
Some research has focused on determining if SEW is actually simple. Yasseri, Kornai,
and Kert´esz (2012) conducted a statistical analysis on a dump of the whole corpus
de 2010 and concluded that even though SEW articles use fewer complex words and
shorter sentences, their syntactic complexity is basically the same as EW (as compared
by part-of-speech n-gram distribution).
Other studies target the automatically produced alignments used to train SS mod-
los. Coster and Kauchak (2011b) found that in their corpus (C&K-1), the majority (65%)
of simple paragraphs do not align with an original one, and even between aligned
paragraphs not every sentence is aligned. También, alrededor 27% of instances are identical,
which could induce SS models to learn to not modify an original sentence, or to perform
very conservative rewriting transformations. Xu, Callison-Burch, and Napoles (2015)
analyzed 200 randomly selected instances of the PWKP corpus and found that around
50% of the alignments are not real simplifications. Some of them (17%) correspond to
misalignments and, on the others (33%), the simple sentence presents the same level of
complexity as its counterpart. Although instances formed by identical sentence pairs
are important for learning when not to simplify, misalignments add noise to the data
and prevent models from learning how to perform the task accurately.
Another line of research tries to determine the simplification transformations re-
alized in available parallel data. Coster and Kauchak (2011b) used word alignments on
C&K-1 and found rewordings (65%), deletions (47%), reorders (34%), merges (31%), y
se divide (27%). Amancio and Specia (2014) extraído 143 instances also from C&K-1, y
manually annotated the simplification transformations performed: sentence splitting,
paraphrasing (either single word or whole sentence), drop of information, sentence re-
ordering, information insertion, and misalignment. They found that the most common
operations were paraphrasing (39.8%) and drop of information (26.76%). Xu, Callison-
Burch, and Napoles (2015) categorized the real simplifications they encountered in
PWKP according to the simplification performed, and found: deletion only (21%),
paraphrase only (17%), and deletion+paraphrase (12%). These results show a tendency
toward lexical simplification and compression operations. También, Xu, Callison-Burch, y
141
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Napoles (2015) state that the simplifications found are not ideal, because many of them
are minimal: Just a few words are simplified (replaced or dropped) and the rest is left
sin alterar.
These studies evidence problems with instances in corpora extracted from EW and
SEW alignments. Noisy data in the form of misalignments as well as lack of variety of
simplification transformations can lead to suboptimal SS models that learn to simplify
from these corpora. Sin embargo, their scale and public availability are strong assets and
simplification models have been shown to learn to perform some simplifications (albeit
still with mistakes) from this data. Por lo tanto, this is still an important resource for
research in SS. One promising direction is to devise ways to mitigate the effects of the
noise in the data.
2.2 Newsela Corpus
In order to tackle some of the problems identified in EW and SEW alignments, Xu,
Callison-Burch, and Napoles (2015) introduced the Newsela corpus. It contains 1,130
news articles with up to five simplified versions each: The original text is version 0
and the most simplified version is 5. The target audience considered was children with
different education grade levels. These simplifications were produced manually by pro-
fessional editors, which is an improvement over SEW where volunteers performed the
tarea. A manual analysis of 50 random automatically aligned sentence pairs (reproduced
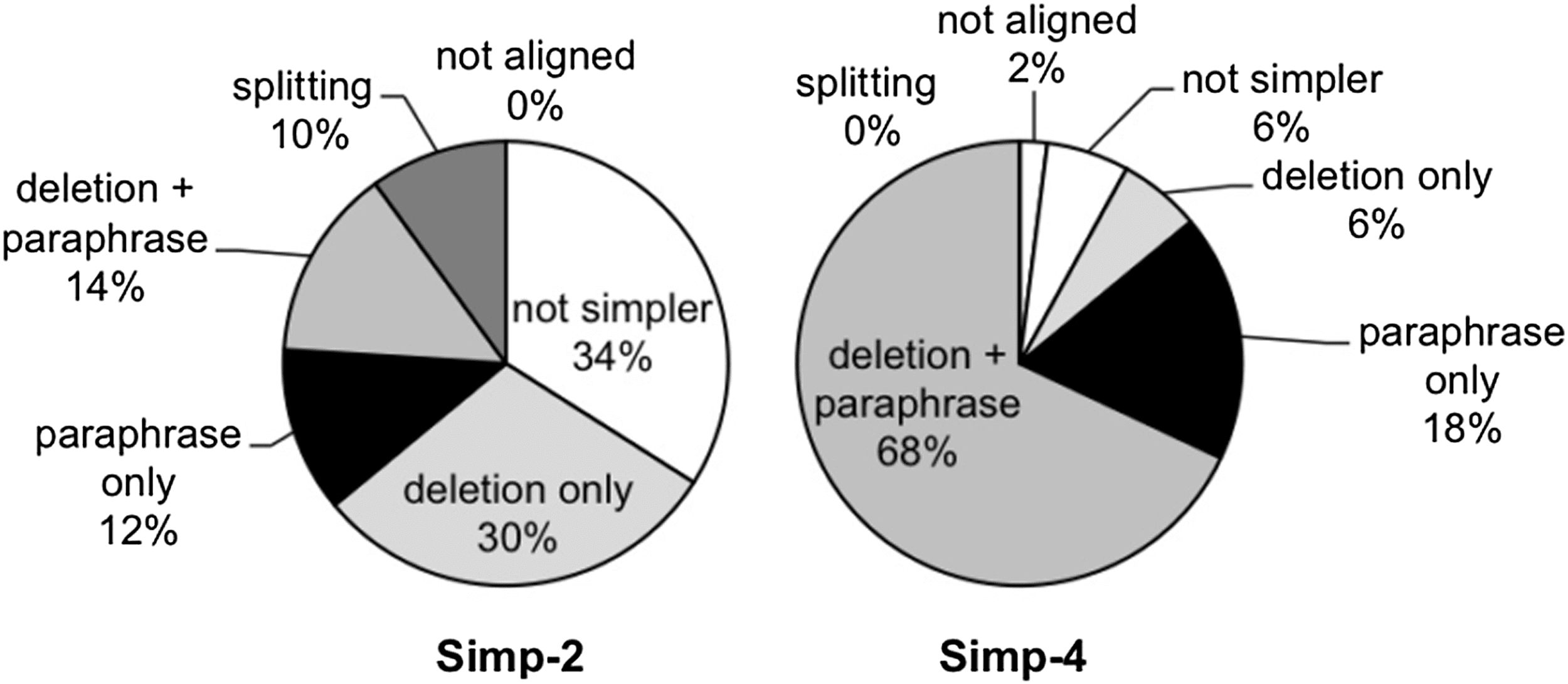
En figura 1) shows a better presence and distribution of simplification transformations
in the Newsela corpus.
The statistics of Figure 1 show that there is still a preference toward compression
and lexical substitution transformations, rather than more complex syntactic alterations.
Sin embargo, splitting starts to appear in early simplification versions. Además, just like
with EW and SEW, there are sentences that are not simpler than their counterparts
in the previous version. This is likely to be because they did not need any further
Cifra 1
Manual categorization of simplification transformations in sample sentences from two
simplified versions in the Newsela corpus. Simp-N means sentences from the original article
(versión 0) automatically aligned with sentences in version-N of the same article. Extracted from
Xu, Callison-Burch, and Napoles (2015).
142
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
simplifications to comply with the readability requirements of the grade level of the
current version.
Xu, Callison-Burch, and Napoles (2015) also presented an analysis of the most
frequent syntax patterns in original and simplified texts for PWKP and Newsela. Estos
patterns correspond to parent node (head node) → children node(s) estructuras. En general,
the Wikipedia corpus has a higher tendency to retain complex patterns in its simple
counterpart than Newsela. Finalmente, the authors present a study on discourse connectives
that are important for readability according to Siddharthan (2003). They report that
simple cue words are more likely to appear in Newsela’s simplifications, y eso
complex connectives have a higher probability to be retained in Wikipedia’s. This could
enable research on how discourse features influence simplification.
2.2.1 Simplification Instances. Newsela is a corpus that can be obtained for free for
research purposes,4 but it cannot be redistributed. Tal como, it is not possible to produce
and release sentence alignments for the research community in SS. This is certainly a
disadvantage, because it is difficult to compare SS models developed using this corpus
without a common split of the data and the same document, párrafo, and sentence
alignments.
Xu, Callison-Burch, and Napoles (2015) align sentences between consecutive
versions of articles in the corpus using Jaccard similarity (Jaccard 1912) based on over-
lapping word lemmas. Alignments with the highest similarity become simplification
instancias.
ˇStajner et al. (2017) explore three similarity metrics and two alignment methods
to produce paragraph and sentence alignments in Newsela. The first similarity metric
uses a character 3-gram model (Mcnamee and Mayfield 2004) with cosine similarity.
The second metric averages the word embeddings (trained in EW) of the text snip-
pet and then uses cosine similarity. The third metric computes the cosine similarity
between all word embeddings in the text snippet (instead of the average). Acerca de
the alignment methods, the first one uses any of the previous metrics to compute the
similarity between all possible sentence pairs in a text and chooses the pair of highest
similarity as the alignment. The second method uses the previous strategy first, pero
instead of choosing the pair with highest similarity, assumes that the order of sentences
of the original text is preserved in its simplified version, and thus chooses the sequence
of sentence alignments that best supports this assumption. The produced instances
were evaluated based on human judgments for 10 original texts with three of their
corresponding simplified versions. Their best method measures similarity between text
snippets with the character 3-gram model and aligns using the first strategy. Incluso
though the alignments are not publicly available, the algorithms and metrics to produce
them can be found in the CATS software (ˇStajner et al. 2018).5
The vicinity-driven algorithms of Paetzold and Specia (2016) are used in Alva-
Manchego et al. (2017) to generate paragraph and sentence alignments between con-
secutive versions of articles in the Newsela corpus. Given two documents/paragraphs,
their method first creates a similarity matrix between all paragraphs/sentences using
tf-idf cosine similarity. Entonces, it selects a coordinate in the matrix that is closest to the
beginning [0,0] and that corresponds to a pair of text snippets with a similarity score
above a certain threshold. From this point on, it iteratively searches for good alignments
4 https://newsela.com/data/.
5 https://github.com/neosyon/SimpTextAlign.
143
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
in a hierarchy of vicinities: V1 (1-1, 1-norte, N-1 alignments), V2 (skipping one snippet), y
V3 (long-distance skips). They first align paragraphs and then sentences within each
párrafo. The extracted sentence alignments correspond to 1-to-1, 1-to-N, and N-to-1
instancias. The alignment algorithms are publicly available as part of the MASSAlign
toolkit (Paetzold, Alva-Manchego, and Specia 2017).6
Because articles in the Newsela corpus have different simplified versions that
correspond to different grade levels, models using paragraph or sentence alignments
between consecutive versions (p.ej., 0-1, 1-2, 2-3) may learn different text transformations
than those using non-consecutive versions (p.ej., 0-2, 1-3, 2-4). This is important to keep
in mind when learning from automatic alignments of this corpus.
2.2.2 Suitability for Simplification Research. Scarton, Paetzold, and Specia (2018b) studied
automatically aligned sentences from the Newsela corpus in order to determine its suit-
ability for SS. They first analyzed the corpus in terms of readability and psycholinguistic
métrica, determining that each version of an article is indeed simpler than the previous
uno. They then used the sentences to train models for four tasks: complex vs. simple
classification, complexity prediction, lexical simplification, and sentence simplification.
The data set proved useful for the first three tasks, and helped achieve the highest
reported performance for a state-of-the-art lexical simplifier. Results for the last task
were inconclusive, indicating that more in-depth studies need to be performed, y
that research intending to use Newsela for SS needs to be mindful about the types of
sentence alignments to use for training models.
2.3 Other Resources for English
En esta sección, we describe some additional resources that are used for SS in English
with very specific reasons: tuning and testing of models in general purpose (Turk-
Cuerpo) and domain-specific (SimPA) datos, evaluation of sentence splitting (HSplit),
readability assessment (OneStopEnglish), training and testing of split-and-rephrase
(WEBSPLIT and WikiSplit), and learning paraphrases (PPDB and SPPDB).
2.3.1 TurkCorpus. Just like with other text rewriting tasks, there is no single correct
simplification possible for a given original sentence. Tal como, Xu et al. (2016) asked
workers on Amazon Mechanical Turk to simplify 2,350 sentences extracted from the
PWKP corpus to collect eight references for each one. This corpus was then randomly
split into two sets: one with 2,000 instances intended to be used for system tuning,
and one with 350 instances for measuring the performance of SS models using metrics
that rely on multiple references (see SARI in Sec. 3.2.3). Sin embargo, the instances chosen
from PWKP are those that focus on paraphrasing (1-to-1 alignments with almost similar
lengths), thus limiting the range of simplification operations that SS models can be
evaluated on using this multi-reference corpus. This corpus is the most commonly used
to evaluate and compare SS systems trained on English Wikipedia data.
2.3.2 HSplit. Sulem, Abend, and Rappoport (2018a) created a multi-reference corpus
specifically for assessing sentence splitting. They took the sentences from the test set
of TurkCorpus, and manually simplified them in two settings: (1) split the original
6 https://github.com/ghpaetzold/massalign.
144
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
sentence as much as possible, y (2) split only when it simplifies the original sentence.
Two annotators carried out the task in both settings.
2.3.3 SimPA. Scarton, Paetzold, and Specia (2018a) introduce a corpus that differs from
the previously described in two aspects: (1) it contains sentences from the Public
Administration domain instead of the more general (Wikipedia) and news (Newsela)
“domains”, y (2) lexical and syntactic simplifications were performed independently.
The former could be useful for validation and/or evaluation of SS models in a different
domain, whereas the latter allows the analysis of the performance of SS models in the
two subtasks in isolation. The current version of the corpus contains 1,100 original
oraciones, each with three references of lexical simplifications only, and one reference
of syntactic simplification. This syntactic simplification was performed starting from a
randomly selected lexical simplification reference for each original sentence.
2.3.4 OneStopEnglish. Vajjala and Luˇci´c (2018) compiled a parallel corpus of 189 noticias
articles that were rewritten by teachers to three levels of adult English as a Second Lan-
guage learners: elementary, intermediate, and advanced. Además, they used cosine
similarity to automatically align sentences between articles in all the levels, resulting
en 1,674 instances for ELE-INT, 2,166 for ELE-ADV, y 3,154 for INT-ADV. The initial
motivation for creating this corpus was to aid in automatic readability assessment at
document and sentence levels. Sin embargo, OneStopEnglish could also be used for testing
the generalization capabilities of models trained on bigger corpora with different target
audiences.
2.3.5 WebSplit. Narayan et al. (2017) introduced split-and-rephrase, and created a data
set for training and testing of models attempting this task. Extracting information from
the WEBNLG data set (Gardent et al. 2017), they collected WEBSPLIT. Each entry in the
data set contains: (1) a meaning representation (MR) of an original sentence, which is a
set of Resource Description Framework (RDF) triplets (subject—property—object); (2) el
original sentence to which the meaning representation corresponds; y (3) several MR-
sentence pairs that represent valid splits (“simple” sentences) of the original sentence.
After its first release, Aharoni and Goldberg (2018) found that around 90% of unique
“simple” sentences in the development and test sets also appeared in the training set.
This resulted in trained models performing well because of memorization rather than
learning to split properly. Por lo tanto, Aharoni and Goldberg proposed a new split of the
data ensuring that (1) every RDF relation is represented in the training set, y eso (2)
every RDF triplet appears in only one of the data splits. Más tarde, Narayan et al. released an
updated version of their original data set, with more data and following constraint (2).
2.3.6 WikiSplit. Botha et al. (2018) created a corpus for the split-and-rephrase task based
on English Wikipedia edit histories. en el conjunto de datos, each original sentence is only aligned
with two simpler ones. A simple heuristic was used for the alignment: the trigram prefix
and trigram suffix of the original sentence should match, respectivamente, the trigram prefix
of the first simple sentence and the trigram suffix of the second simple sentence. El
two simple sentences should not have the same trigram suffix either. The BLEU score
between the aligned pairs was also used to filter out misalignments according to an
empirical threshold. The final corpus contains one million instances.
2.3.7 Paraphrase Database. Ganitkevitch, Van Durme, and Callison-Burch (2013) released
the Paraphrase Database (PPDB), which contains 220 million paraphrases in English.
145
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
These paraphrases are lexical (one token), phrasal (multiple tokens), and syntactic
(tokens and non-terminals). To extract the paraphrases, they used bilingual corpora
with the following intuition: “two strings that translate to the same foreign string can
be assumed to have the same meaning.” The authors utilized the synchronous context-
free grammar formalism to collect paraphrases. Using MT technology, they extracted
grammar rules from foreign-to-English corpora. Entonces, the paraphrase is created from
rule pairs where the left-hand side and foreign string match. Each paraphrase in PPDB
has a similarity score, which was calculated using monolingual distributional similarity.
2.3.8 Simple Paraphrase Database. Pavlick and Callison-Burch (2016) created the Simple
PPDB, a subset of the PPDB tailored for SS. They used machine learning models to
select paraphrases that generate a simplification and preserve its meaning. Primero, ellos
selected 1,000 words from PPDB which also appear in the Newsela corpus. They then
selected up to 10 paraphrases for each word. Después, they crowd-sourced the manual
evaluation of these paraphrases in two stages: (1) rate their meaning preservation in a
scale of 1 a 5, y (2) label the ones with rates higher than 2 as simpler or not. Próximo,
these data were used to train a multi-class logistic regression model to predict whether
a paraphrase would produce simpler, more complex, or non-sense output. Finalmente, ellos
applied this model to PPDB and extracted 4.5 million simplifying paraphrases.
2.4 Resources for Other Languages
The most popular (and generally larger) resources available for simplification are in
Inglés. Sin embargo, some resources have been built for other languages:
Basque. Gonzalez-Dios et al. (2014) collected 200 articles of science and
technology texts from a science and technology magazine (complejo
cuerpo) and a Web site for children (simple corpus). They used these
corpora to analyze complexity, but the articles in the data set are not
parallel.
Brazilian Portuguese. Caseli et al. (2009) compiled 104 newspaper articles
(complex corpus), and a linguist simplified each of them following a
simplification manual (Specia, Alu´ısio, and Pardo 2008) and an annotation
editor that registers the simplification transformations performed. El
corpus contains 2,116 instancias.
Danish. Klerke and Søgaard (2012) introduced DSim, a parallel corpus of
news telegrams and their simplifications produced by trained journalists.
The corpus contains 3,701 artículos, out of which a total of 48,186
automatically aligned sentence pairs were selected.
Alemán. Klaper, Ebling, and Volk (2013) crawled articles from different
Web sites to collect a corpus of around 7K sentences, of which close to 78%
have automatic alignments.
italiano. Brunato et al. (2015) collected and manually aligned two corpora.
One contains 32 short novels for children and their manually simplified
versions, and the other is composed of 24 texts produced and simplified by
profesores. They also manually annotated the simplification transformations
•
•
•
•
•
146
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
performed. Tonelli, Aprosio, and Saltori (2016) introduced SIMPITIKI,7
extracting aligned original-simplified sentences from revision histories of
the Italian Wikipedia, and annotating them using the same scheme as
Brunato et al. (2015). The corpus described in their paper contains 345
instances with 575 annotations of simplification tranformations. As part of
SIMPITIKI, the authors also created a corpus of the Public Domain by
simplifying documents from the Trento Municipality with 591 anotaciones.
•
•
Japanese. Goto, Tanaka, and Kumano (2015) released a corpus of news
articles and their simplifications, produced by teachers of Japanese as a
foreign language. Their data set consists of 10,651 instances for training
(automatic alignments), 723 instances for development (manual
alignments), y 2,012 instances for testing (manual alignments).
Español. Bott and Saggion (2011a) describe a corpus of 200 news articles
and their simplifications, produced by trained experts and targeted at
people with learning disabilities. They produced automatic sentence
alignments (Bott and Saggion 2011b) and manually annotated the
simplification transformations performed in only a subset of the data set.
Newsela also provides a simplification corpus in Spanish which has been
used in ˇStajner et al. (2017, 2018).
3. Evaluation of Simplification Models
The main goal in SS is to improve the readability and understandability of the original
oración. Independently of the technique used to simplify a sentence, the evaluation
methods we use should allow us to determine how good the simplification output is for
that end goal. In this section we explain how the outputs of automatic SS models are
typically evaluated, based on human ratings and/or using automatic metrics.
3.1 Human Assessment
Arguably, the most reliable method to determine the quality of a simplification consists
of asking human judges to rate it. It is common practice to evaluate a model’s output on
three criteria: grammaticality, preservación del significado, and simplicity (ˇStajner et al. 2016).
For grammaticality (sometimes referred to as fluency), evaluators are presented with
a sentence and are asked to rate it using a Likert scale of 1–3 or 1–5 (most common).
The lowest score indicates that the sentence is completely ungrammatical, mientras
the highest score means that it is completely grammatical. Native or highly proficient
speakers of the language are ideal judges for this criterion.
For meaning preservation (sometimes referred to as adequacy), evaluators are pre-
sented with a pair of sentences (the original and the simplification), and are asked to
tasa (also using a Likert scale) the similarity of the meaning of the sentences. A low
score denotes that the meaning is not preserved, while a high score suggests that the
sentence pair share the same meaning.
Por simplicidad, evaluators are presented with an original–simplified sentence pair
and are asked to rate how much simpler (or easier to understand) the simplified version
is when compared with the original version, also using a Likert scale. Xu et al. (2016)
7 https://github.com/dhfbk/simpitiki.
147
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
differs from this standard, asking judges to evaluate simplicity gain, which means
to count the correct lexical and syntactic paraphrases performed. Sulem, Abend, y
Rappoport (2018b) introduce the notion of structural simplicity, which ignores lexical
simplifications and focuses on structural transformations with the question: Is the output
simpler than the input, ignoring the complexity of the words?
3.2 Automatic Metrics
Even though human evaluation is the preferred method for assessing the quality of
simplifications, they are costly to produce and may require expert annotators (linguists)
or end-users of a specific target audience (p.ej., children suffering from dyslexia). Allá-
delantero, researchers turn to automatic measures as a means of obtaining faster and cheaper
resultados. Some of these metrics are based on comparing the automatic simplifications
to manually produced references; others compute the readability of the text based on
psycholinguistic metrics; whereas others are trained on specially annotated data so as
to learn to predict the quality or usefulness of the simplification being evaluated.
3.2.1 String Similarity Metrics. These metrics are mostly borrowed from the MT literature,
since SS can be seen as translating a text from complex to simple. The most commonly
used are BLEU and TER.
AZUL (BiLingual Evaluation Understudy), proposed by Papineni et al. (2002), es un
precision-oriented metric, which means that it depends on the number of n-grams in the
candidate translation that match with n-grams of the reference, independent of position.
BLEU values range from 0 a 1 (or to 100); the higher the better.
BLEU calculates a modified n-gram precision: (i) count the maximum num-
ber of times that an n-gram occurs in any of the references, (ii) clip the total
count of each candidate n-gram by its maximum reference count (es decir, Countclip =
mín.(Count, MaxRefCount)), y (iii) add these clipped counts up, and divide by the total
(unclipped) number of candidate words. Short sentences (compared with the lengths
of the references) could inflate this modified precision. Tal como, BLEU uses a Brevity
Penalty (BP) factor, calculated as in Equation (1), where c is the length of the candidate
traducción, r is the reference corpus length, and r/c is used in a decaying exponential
(en este caso, c is the total length of the candidate translation corpus).
BP =
(cid:40)
1
mi(1−r/c)
if c > r
if c ≤ r
(1)
The final BLEU score is computed as in Equation (2). Traditionally, norte = 4 y
wn = 1/N.
BLEU = BP · exp
(cid:33)
wn log(pn)
(cid:32) norte
(cid:88)
norte=1
(2)
In simplification research, several studies (Wubben, van den Bosch, and Krahmer
2012; ˇStajner, Mitkov, and Saggion 2014; Xu et al. 2016) show that BLEU has high
correlation with human assessments of grammaticality and meaning preservation, pero
not simplicity. También, Sulem, Abend, and Rappoport (2018a) show that this correlation
is low or non-existent when sentence splitting has been performed. Tal como, AZUL
148
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
should not be used as the only metric for evaluation and comparison of SS models. En
addition, because of its definition, this metric is more useful with simplification corpora
that provides multiple references for each original sentence.
TER (Translation Edit Rate), designed by Snover et al. (2006), measures the min-
imum number of edits necessary to change a candidate translation so that it matches
perfectly to one of the references, normalized by the average length of the references.
Only the reference that is closest (according to TER) is considered for the final score. El
edits to be considered are insertions, deletions, substitutions of single words, and shifts
(positional changes) of word sequences. TER is an edit-distance metric Equation (3),
with values ranging from 0 a 100; lower values are better.
TER =
# of edits
promedio # of reference words
(3)
In order to calculate the number of shifts, TER follows a two-step process: (i) use dy-
namic programming to count insertions, deletions, and substitutions; and use a greedy
search to find the set of shifts that minimizes the number of insertions, deletions, y
substitutions; entonces (ii) calculate the optimal remaining edit distance using minimum-
edit-distance and dynamic programming.
For simplification research, TER’s intermediate calculations (es decir., the edits counts)
have been used to show the simplification operations that an SS model is able to perform
(Zhang and Lapata 2017). Sin embargo, this is not a general practice and no studies have
been conducted to verify that the edits correlate with simplification transformations.
Scarton, Paetzold, and Specia (2018b) use TER to study the differences between different
simplification versions in articles of the Newsela corpus.
iBLEU is a variant of BLEU introduced by Sun and Zhou (2012) as a way to mea-
sure the quality of a candidate paraphrase. The metric balances the semantic similarity
between the candidate and the reference, with the dissimilarity between the candidate
and the source. Given a candidate paraphrase c, human references rs, and input text s,
iBLEU is computed as in Equation (4), with values ranging from 0 a 1 (or to 100); más alto
los valores son mejores.
iBLEU(s, rs, C) = α × BLEU(C, rs) − (1 − α) × BLEU(C, s)
(4)
After empirical evaluations, the authors recommend using a value of α between 0.7
y 0.9. Por ejemplo, Mallinson, Sennrich, and Lapata (2017) experiment with a value
de 0.8, while Xu et al. (2016) set it to 0.9.
3.2.2 Flesch-Based Metrics. Flesch Reading Ease (FRE, Flesch 1948) is a metric that
attempts to measure how easy a text is to understand. It is based on average sentence
length and average word length. Longer sentences could imply the use of more complex
syntactic structures (p.ej., subordinated clauses), which makes reading harder. The same
analogy applies to words: Longer words contain prefixes and suffixes that present more
difficulty to the reader. This metric Equation (5) gives a score between 0 y 100, con
lower values indicating a higher level of difficulty.
FRE = 206.835 − 1.015
(cid:16) number of words
(cid:17)
number of sentences
− 84.6
(cid:18) number of syllables
number of words
(cid:19)
(5)
149
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Flesch-Kincaid Grade Level (FKGL, Kincaid et al. 1975) is a recalculation of FRE, entonces
as to correspond to grade levels in the United States Equation (6). The coefficients were
derived from multiple regression procedures in reading tests of 531 Navy personnel.
The lowest possible value is −3.40 with no upper bound. The obtained score should
be interpreted in an inverse way as for FRE, so that lower values indicate a lower level of
difficulty.
FKGL = 0.39
(cid:16) number of words
(cid:17)
number of sentences
+ 11.8
(cid:18) number of syllables
number of words
(cid:19)
− 15.59
(6)
FKBLEU (Xu et al. 2016) combines iBLUE and FKGL to ensure grammaticality and
simplicity in the generated text. Given an output simplification O, a reference R, and an
input original sentence I, FKBLEU is calculated according to Equation (7); higher values
mean better simplifications.
FKBLEU = iBLEU(I, R, oh) × FKGLdiff(I, oh)
FKGLdiff = sigmod(FKGL(oh) − FKGL(I))
(7)
Because of the way these Flesch-based metrics are computed, short sentences could
obtain good scores, even if they are ungrammatical or non–meaning preserving. Como
semejante, their values could be used to measure superficial simplicity, but not as an overall
evaluation or for comparison of SS models (Wubben, van den Bosch, and Krahmer
2012). Many other metrics could be used for more advanced readability assessment
(McNamara et al. 2014); sin embargo, these are not commonly used in simplification research.
3.2.3 Simplification Metrics. SARI (System output Against References and Input sen-
tence) was introduced by Xu et al. (2016) as a means to measure “how good” the words
added, deleted, and kept by a simplification model are. This metric compares the output
of an SS model against multiple simplification references and the original sentence.
The intuition behind SARI is to reward models for adding n-grams that occur in
any of the references but not in the input, to reward keeping n-grams both in the output
and in the references, and to reward not over-deleting n-grams. SARI is the arithmetic
mean of n-gram precisions and recalls for add, keep, and delete; the higher the final
valor, the better. Xu et al. (2016) show that SARI correlates with human judgments of
simplicity gain. Tal como, this metric has become the standard measure for evaluating
and comparing SS models’ outputs.
Considering a model output O, the input sentence I, references R, and #g(·) as a
binary indicator of occurrence of n-grams g in a given set, we first calculate n-gram
precision p(norte) and recall r(norte) for the three operations listed (agregar, keep, and delete):
paddock(norte) =
radd(norte) =
(cid:80)
(cid:80)
g∈O min(#gramo(O∩ ¯I),#gramo(R))
g∈O #g(O∩ ¯I)
(cid:80)
g∈O min(#gramo(O∩ ¯I),#gramo(R))
g∈O #g(R∩ ¯I)
(cid:80)
, #gramo(O ∩ ¯I) = max(#gramo(oh) − #g(I), 0)
, #gramo(R ∩ ¯I) = max(#gramo(R) − #g(I), 0)
150
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
pkeep(norte) =
rkeep(norte) =
(cid:80)
(cid:80)
g∈I min(#gramo(I∩O),#gramo(I∩R(cid:48) ))
g∈I #g(I∩O)
(cid:80)
g∈I min(#gramo(I∩O),#gramo(I∩R(cid:48) ))
g∈I #g(I∩R(cid:48) )
(cid:80)
, #gramo(I ∩ O) = min(#gramo(I), #gramo(oh))
, #gramo(I ∩ R(cid:48)) = min(#gramo(I), #gramo(R)/r)
pdel(norte) =
(cid:80)
g∈I min(#gramo(I∩ ¯O),#gramo(I∩R(cid:48) ))
g∈I #g(I∩ ¯O)
(cid:80)
#gramo(I ∩ ¯O) = max(#gramo(I) − #g(oh), 0)
#gramo(I ∩ R(cid:48)) = max(#gramo(I) − #g(R)/r, 0)
For keep and delete, R(cid:48) marks n-gram counts over R with fractions. Por ejemplo, si
a unigram occurs 2 out of the total r references, then its count is weighted by 2/r when
computing precision and recall. Recall is not calculated for deletions to avoid rewarding
over-deleting. Finalmente, SARI is calculated as shown in Equation (8).
SARI = d1Fadd + d2Fkeep + d3Fdel
(8)
where d1 = d2 = d3 = 1/3 y
Poperation = 1
k
(cid:88)
n=[1,..,k]
poperation(norte)
Roperation = 1
k
(cid:88)
n=[1,..,k]
roperation(norte)
Foperation =
2 × Poperation × Roperation
Poperation + Roperation
operation ∈ [del, keep, agregar]
An advantage of SARI is considering both the input original sentence and the
references in its calculation. This is different from BLEU, which only ponders the
similarity of the output with the references. Although iBLEU also uses both input and
references, it compares the output against them independently, combining these scores
in a way that rewards outputs that are similar to the references, but not so similar to the
aporte. A diferencia de, SARI compares the output against the input sentence and references
simultaneously, and rewards outputs that modify the input in ways that are expressed
by the references. Además, not all n-gram matches are considered equal: The more
references “agree” with keeping/deleting certain n-gram, the higher the importance of
the match in the score computation.
One disadvantage of SARI is the limited number of simplification transformations
tenido en cuenta, restricting the evaluation to only 1-to-1 paraphrased sentences. Como
semejante, it needs to be used in conjunction with other metrics or evaluation procedures
when measuring the performance of an SS model. También, if only one reference exists that
is identical to the original sentence, and the model’s output does not change the original
oración, SARI would over-penalize it and give a low score. Por lo tanto, SARI requires
multiple references that are different from the original sentence to be reliable.
SAMSA (Simplification Automatic evaluation Measure through Semantic
Annotation) was introduced by Sulem, Abend, and Rappoport (2018b) to tackle some
of the shortcomings of reference-based simplicity metrics (es decir., SARI). The authors show
that SARI has low correlation with human judgments when the simplification of a
sentence involves structural changes, specifically sentence splitting. The new metric,
por otro lado, correlates with meaning preservation and structural simplicity.
151
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Como consecuencia, SARI and SAMSA should be used in conjunction to have a more complete
evaluation of different simplification transformations.
To calculate SAMSA, el original (source) sentence is semantically parsed using
the UCCA scheme (Abend and Rappoport 2013), either manually or by the automatic
parser TUPA (Hershcovich, Abend, and Rappoport 2017). The resulting graph contains
the Scenes in the sentence (p.ej., comportamiento), as well as their corresponding Participants.
SAMSA’s premise is that a correct splitting of an original sentence should create a sep-
arate simple sentence for each UCCA Scene and its Participants. To verify this, SAMSA
uses the word alignment between the original and the simplified output to count how
many Scenes and Participants hold the premise. This process does not require simplifica-
tion references (unlike SARI), and because the semantic parsing is only performed in the
original sentence, it prevents adding parser errors of (possibly) grammatically incorrect
simplified sentences produced by the SS model being evaluated.
3.2.4 Prediction-Based Metrics. If reference simplifications are not available, a possible
approach is to evaluate the simplicity of the simplified output sentence by itself, o
compare it to the one from the original sentence.
Most approaches in this line of research attempt to classify a given sentence into
categories that define its simplicity by extracting several features from the sentence and
training a classification model. Por ejemplo, Napoles and Dredze (2010) used lexical and
morpho-syntactic features to predict if a sentence was more likely to be from Main or
Simple English Wikipedia. Later on, inspired by work on Quality Estimation for MT,8
ˇStajner, Mitkov, and Saggion (2014) proposed training classifiers to predict the quality
of simplified sentences, with respect to grammaticality and meaning preservation. En
este caso, the features extracted correspond to values from metrics such as BLEU or
(components of) TER. The authors proposed two tasks: (1) to classify, independientemente, el
grammaticality and meaning preservation of sentences into three classes: bad, medio,
and good; y (2) to classify the overall quality of the simplification using either a set
of three classes (OK, needs post-editing, discard) or two classes (retain, discard). El
same approach was the main task in the 1st Quality Assessment for Text Simplification
Taller (QATS; ˇStajner et al. 2016), but automatic judgments of simplicity were also
consideró. There were promising results with respect to predicting grammaticality and
preservación del significado, but not for simplicity or an overall quality evaluation metric.
Afterwards, Martin et al. (2018) extended ˇStajner, Mitkov, and Saggion (2014)’s work
with features from ˇStajner, Popovi´c, and B´echera (2016) to analyze how different feature
groups correlate with human judgments on grammaticality, preservación del significado, y
simplicity using data from QATS. Using Quality Estimation research for reference-less
evaluation in simplification is still an area not sufficiently explored, mainly because it
requires human annotations on example instances that can be used as training data,
which can be expensive to collect.
Another group of approaches is interested in ranking sentences according to their
predicted reading levels. Vajjala and Meurers, (2014a,b) showed that, in the PWKP (Zhu,
Bernhard, and Gurevych 2010) data set and and earlier version of the OneStopEnglish
(Vajjala and Luˇci´c 2018) cuerpo, even if all simplified sentences were simpler than
their aligned original counterpart, some sentences in the “simple” section had a higher
reading level than some in the “original” section. Tal como, attempting to use binary
8 In Quality Estimation, the goal is to evaluate an output translation without comparing it to a reference.
For a comprehensive review of this area of research, please refer to Specia, Scarton, and Paetzold (2018).
152
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
classification approaches to determine if a sentence is simple or not may not be the
appropriate way to model the task. Como consecuencia, Vajjala and Meurers (2015) propuesto
using pair wise ranking to assess the readability of simplified sentences. They used the
same features of the document-level model of Vajjala and Meurers (2014a), but now
they attempt to learn to predict which of two given sentences is simpler than the other.
Ambati, Reddy, and Steedman (2016) tested the usefulness of syntactic features ex-
tracted from an incremental parser for the task, and Howcroft and Demberg (2017) ex-
plored using more psycholinguistic features, such as idea density, surprisal, integración
costo, and embedding depth.
Although not detailed in this section, some research has used METEOR (Denkowski
and Lavie 2014) from the MT literature, and ROUGE (lin 2004), borrowed from sum-
marization research.
3.3 Discusión
In this section we have described how the outputs of SS models are evaluated using
both human judgments and automatic metrics. We have attempted to not only explain
these methods, but also to point out their advantages and disadvantages.
In the case of human evaluation, one important but often overlooked aspect is that
it should be carried out by individuals from the same target audience of the data on
which the SS model was trained. This is especially relevant when collecting simplicity
judgments because of its subjective nature: What a non-native proficient adult speaker
considers “‘simple” may not hold for a native-speaking primary school student, para
ejemplo. Even within the same target group, differences in simplicity needs and judg-
ments may arise. This is why some researchers have started to focus on developing and
evaluating models for personalized simplification (Bingel, Paetzold, and Søgaard 2018;
Bingel, Barrett, and Klerke 2018). Además, we should think carefully whether the
quality of a simplified text is better judged as an intrinsic feature, or if we should assess
it depending on its usefulness to carry out another task. Hoy en día, quality judgments
focus on assessing the automatic output for what it is: is it grammatical?, does it still
express the same idea?, is it easier to read? Sin embargo, the goal of simplification is to modify
a text so that a reader can understand it better. With that in mind, a more functional eval-
uation of the generated text could be more informative of the understandability of the
producción. An example of such type of assessment is presented in Mandya, Nomoto, y
Siddharthan (2014), where human judges had to use the automatically simplified texts
in a reading comprehension test with multiple-choice questions. Entonces, the accuracy of
their responses is used to qualify the helpfulness of the simplified texts in the particular
comprehension task. This type of human evaluation could be more goal-oriented, pero
they are costly to create and execute.
Automatic metrics are useful for quickly assessing models and comparing different
architectures. They could even be considered more objective than humans since per-
sonal biases do not play a role. Sin embargo, the metrics used in SS research are flawed.
BLEU has been found to only be reliable for assessment in MT but not other Natural
Language Generation tasks (Reiter 2018), and it is not adequate for most rewriting
transformations in SS (Sulem, Abend, and Rappoport 2018a). SARI is only useful as
a proxy for simplicity gain assessment, limited to lexical simplifications and short-
distance reordering despite more text transformations being possible. Commonly-used
Flesch metrics were developed to assess complete documents and not sentences, cual
is the focus of most simplification research nowadays. Por lo tanto, when evaluating
models using these automatic scores, it is essential to keep all their particular limitations
153
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
in mind, to always look at all possible metrics and try to interpret them accordingly.
En general, what is the most reliable way of automatically evaluating system outputs, en el
right granularity and considering all characteristics of the task, is still an open question.
We comment on some possible future directions in Section 6.
4. Data-Driven Approaches to Sentence Simplification
En esta sección, we review research on SS aiming at learning simplifications from ex-
amples. More specifically, approaches that involve learning text transformations from
parallel corpora of aligned original-simplified sentences in English. Comparado con
approaches based on hand-crafted rules, data-driven approaches can perform multi-
ple simplification transformations simultaneously, as well as learn very specific and
complex rewriting patterns. Como resultado, they make it possible to model interdepen-
dencies among different transformations more naturally. Por lo tanto, we do not include
approaches to sentence simplification based on sets of hand-crafted rules, such as rules
for splitting and reordering sentences (Candido Jr. et al. 2009; Siddharthan 2011; Bott,
Saggion, and Mille 2012), nor approaches that only learn lexical simplifications, eso es,
which target one-word replacements (see Paetzold and Specia [2017b] for a survey).
We classify data-driven approaches for SS as relying on statistical MT techniques
(Sección 4.1), induction of synchronous grammars (Sección 4.2), semantics-assisted
(Sección 4.3), and neural sequence-to-sequence models (Sección 4.4).
4.1 Monolingual Statistical Machine Translation
Several approaches treat SS as a monolingual MT task, with original and simplified as
source and target languages, respectivamente. Whereas other translation methods exist, en
this section we focus on Statistical Machine Translation (SMT). Given a sentence f in the
source language, the goal of an SMT model is to produce a translation e in the target
idioma. This is modeled using the noisy channel framework Equation (9).
e∗ = arg max
pag(mi| F ) = arg máx
pag( F |mi)pag(mi)
e∈E
e∈E
(9)
This framework relies on a translation model p( F |mi) and a language model p(mi).
Además, a decoder is in charge of producing the most probable e given an f . El
language model is monolingual, and thus “easier” to generate. There are different
approaches for implementing the translation model and the decoder. En la práctica, ellos
all rely on a linear combination of these and additional features, which are directly
optimized to maximize translation quality, rather than on the generative noisy channel
modelo. In what follows, we review the most popular approaches and explain their
applications for SS.
4.1.1 Phrase-Based Approaches. The intuition behind Phrase-Based SMT (PBSMT) is to
use phrases (sequences of words) as the fundamental unit of translation. Por lo tanto,
the translation model p( F |mi) depends on the normalized count of the number of times
each possible phrase-pair occurs. These counts are extracted from parallel corpora and
automatic phrase alignments, cual, Sucesivamente, are obtained from word alignments.
Decoding is a search problem: Find the sentence that maximizes the translation and
language model probabilities. It could be solved using a best-first search algorithm, como
A*, but exploring the entire search space of possible translations is expensive. Por lo tanto,
154
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Mesa 2
Performance of PBSMT-based sentence simplification models as reported by their authors.
Modelo
Train Corpus Test Corpus BLEU ↑
FKGL ↓
Moses (Brazilian Portuguese)
Moses (Inglés)
Moses-Del
PBSMT-R
PorSimples
C&k
C&k
PWKP
PorSimples
C&k
C&k
PWKP
60.75
59.87
60.46
43.00
13.38
decoders use beam-search to only retain, at every step, the most promising states to
continue the search.
Moses (Koehn et al. 2007) is a popular PBSMT system, freely available.9 It provides
tools for easy training, tuning, and testing of translation models based on this SMT
acercarse. Specia (2010) was the first to use this toolkit, with no adaptations, para el
simplification task. Experiments were carried out on a parallel corpus of original and
manually simplified newspaper articles in Brazilian Portuguese (Caseli et al. 2009). El
trained model mostly executes lexical simplifications and simple rewritings. Sin embargo,
as expected, it is overcautious and cannot perform long distance operations like subject-
verb-object reordering or splitting.
Moses-Del: Coster and Kauchak (2011b) also used Moses as-is, and trained it on
their C&K corpus, obtaining slightly better results when compared with not doing
any simplification. In Coster and Kauchak (2011a), the authors modified Moses to
allow complex phrases to be aligned with NULL, thus implementing deletions during
simplification. To accomplish this, they modify the word alignments before the phrase
alignments are learned: (1) any complex unaligned word is now aligned with NULL,
y (2) if several complex words in a set align with only one simple word, and one of
the complex words is equal to the simple word, then the other complex words in the
set are aligned with NULL. Their model achieves better results than a standard Moses
implementación.
PBSMT-R: Wubben, van den Bosch, and Krahmer (2012) also used Moses but added
a post-processing step. They ask the decoder to generate the 10 best simplifications
(where possible), and then rank them according to their dissimilarity to the input
oración (measured by edit distance). The most dissimilar sentence is chosen as the
final output, and ties are resolved using the decoder score. This trained model achieves
a better BLEU score than more sophisticated approaches (Zhu, Bernhard, and Gurevych
2010; Woodsend and Lapata 2011a), explained in Section 4.2. When compared with such
approaches using human evaluation, PBSMT-R is better in grammaticality and meaning
preservación. Sin embargo, the results are limited to paraphrasing transformations.
Mesa 2 summarizes the performance of the models trained using the SS approaches
descrito, as reported in the original papers. The BLEU values are not directly compa-
rable, since each approach used a different corpus for testing. From a transformation
capability point of view, PBSMT-based simplification models are able to perform sub-
stitutions, short distance reorderings, and deletions, but fail to learn more sophisticated
operaciones (p.ej., splitting) that may require more information on the structure of the
sentences and relationships between their components.
9 http://www.statmt.org/moses/.
155
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
4.1.2 Syntax-Based Approaches. In Syntax-Based SMT (SBSMT), the basic unit for trans-
lation is no longer a phrase, but syntactic components in parse trees. In PBSMT, el
language model and the phrase alignments act as features that inform the model about
how likely the generated translation is (simplification, in our case). In SBSMT we can
extract more informed features, based on the structures of the parallel parse trees.
TSM: Zhu, Bernhard, and Gurevych (2010) proposed a Tree-based Simplification
Model that can perform four text transformations: splitting, dropping, reordering, y
substitution (of words and phrases). Given an original sentence c, the model attempts
to find a simplification s using Equation (10), with a language model P(s) and a direct
translation model P(s|C).
s = arg max
PAG(s|C)PAG(s)
s
(10)
For estimating P(s|C), the method traverses the original sentence parse tree from
top to bottom, extracting features from each node and for each of the four possible
transformations. These features are transformation-specific and are stored in feature
tables for each transformation. For each feature combination in each table, probabilities
are calculated during training. We will use the splitting transformation to explain this
process in more detail. A similar method is used for the other three transformations.
In TSM, sentence splitting is decomposed into two transformations: SEGMEN-
TATION (if a sentence is to be split or not) and COMPLETION (to make the splits
grammatical). The probability of a SEGMENTATION transformation is calculated using
Ecuación (11), where w is a word in the complex sentence c, and SFT(w|C) es el
probability of w in the Segmentation Feature Table (SFT).
PAG(seg|C) =
SFT(w|C)
(cid:89)
w:C
(11)
COMPLETION implies deciding whether the border word in the second split needs
to the dropped, and which parts of the first split need to be copied into the second.
The probability of this operation is calculated as in Equation (12), where s are the split
oraciones, bw is a border word in s, w is a word in s, dep is a dependency of w that is out
of the scope of s, BDFT is the Border Drop Feature Table (BDFT), and CFT is the Copy
Feature Table.
PAG(com|seg) =
(cid:89)
bw:s
BDFT(bw|s)
(cid:89)
(cid:89)
w:s
dep:w
CFT(dep)
(12)
Finalmente, once similar computations are done for the other three transformations, todo
probabilities are combined to calculate the translation model. In Equation (13) dónde
PAG(dp|nodo), PAG(ro|nodo), y P(sub|nodo) correspond to dropping, reordering, and substi-
tuting non-terminal nodes, y P(sub|w) is for substitutions of terminal nodes.
PAG(s|C) =
(cid:88)
(cid:16)
PAG(seg|C)PAG(com|seg)
i:Str(i(C))=s
(cid:89)
PAG(dp|nodo)PAG(ro|nodo)PAG(sub|nodo)
(13)
nodo
(cid:89)
(sub|w)
(cid:17)
w
156
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
The model is trained using the Expectation-Maximization algorithm proposed by
Yamada and Knight (2001). This algorithm requires constructing a training tree to
calculate P(s|C), which corresponds to the probability of the root of the training tree.
For decoding, the inside and outside probabilities are calculated for each node in the
decoding tree, which is constructed in a similar fashion as the training tree. To simplify a
new original sentence, the algorithm starts from the root and greedily selects the branch
with highest outside probability.
The proposed approach used the PWKP corpus for training and testing, obtaining
higher readability scores (Flesch) than other baselines considered (Moses and the sen-
tence compression system of Filippova and Strube [2008] with variations). En general, TSM
showed good performance for word substitution and splitting.
TriS: Bach et al. (2011) proposed a method focused on splitting an original sentence
into several simpler ones. A sentence is considered simple if it is in the subject-verb-
object order (SVO), with one subject, one verb, and one object. Given a sentence c that
needs to be split into a set S of simple sentences, the objective is to select the set with the
highest probability Equation (14).
ˆS(C) = arg máx
PAG(S|C)
∀S
(14)
The language and translation models are combined using a log-linear model as in
Ecuación (15), where fm(S, C) are feature functions on each sentence, and wm are model
parameters to be learned.
pag(S|C) =
(cid:16)(cid:80)METRO
m=1 wm fm(S, C)
(cid:17)
exp.
(cid:80)
S(cid:48) exp.
(cid:16)(cid:80)METRO
m=1 wm fm(S(cid:48), C)
(cid:17)
(15)
For decoding, their method starts by listing all noun phrases and verbs of the
original sentence and generating simple sentences combining the lists in SVO form.
Entonces, it proceeds with a k-best stack decoding algorithm: It starts with a stack of
1-simple-sentence hypotheses (a hypothesis is a complete simplification of multiple
simple sentences), and at each step it pops a hypothesis of the stack and expands it (a
2-simple-sentence in the first iteration, etcétera) and puts the new hypotheses in an-
other stack, prunes them (according to some metric) and updates the original hypothe-
ses stack. After all steps (which corresponds to the number of verbs in the sentence), él
selects the k-best hypotheses in the stack. For training, they use the Margin Infused Re-
laxed Algorithm (Crammer and Singer 2003). For modeling, 177 feature functions were
designed to capture intra- and inter-sentential information (simple counts, distance in
the parse tree, readability measures, etc.).
To test their approach, a corpus of 854 sentences extracted from The New York
Times and Wikipedia was created, with one manual simplification each. Los autores
evaluate on 100 unseen sentences and compare against the rule-based approach of
Heilman and Smith (2010). Their model achieves better Flesch-Kincaid Grade Level
and ROUGE scores.
SBSMT (PPDB +
framework with rule-based features and tuning metrics specifically tailored for lexical
simplification. Two new “light weight” metrics are also introduced: FKBLEU and SARI,
both described in Section 3.2.
157
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Mesa 3
Performance of SBSMT-based sentence simplification models as reported by their authors.
Modelo
Train Corpus Test Corpus BLEU ↑
FKGL ↓ SARI ↑
TSM
PWKP
TriS
Own
TurkCorpus
SBSMT(PPDB+BLEU)
SBSMT(PPDB+FKBLEU) TurkCorpus
TurkCorpus
SBSMT(PPDB+SARI)
PWKP
Own
TurkCorpus
TurkCorpus
TurkCorpus
38.00
99.05
74.48
72.36
7.9
12.88
10.75
10.90
26.05
34.18
37.91
The proposed simplification model also relies on paraphrasing rules available in the
PPDB, which are expressed as a Synchronous Context-Free Grammar (SCFG). The au-
thors also added nine new features to each rule in the PPDB (each rule already contains
33). These new features are simplification-specific, Por ejemplo: length in characters,
length in words, number of syllables, among others.
These modifications were implemented in the SBSMT toolkit Joshua (Post et al.
2013) and performed experiments using TurkCorpus (descrito en la Sección 2.3) on three
versions of the SBSMT system, changing the tuning metric (AZUL, FKBLEU, and SARI).
Evaluations using human judgments show that all three models achieved better gram-
matically, preservación del significado, and simplicity gain than PBSMT-R (Wubben, van den
Bosch, and Krahmer 2012).
Mesa 3 summarizes the performance of the syntax-based models trained using
the SS approaches described. These values are not directly comparable, because each
approach used a different corpus for testing. In the case of the models based on Joshua
and PPDB, not surprisingly, each achieves the highest score according to the metric
for which it was optimized. Sin embargo, SBSMT (PPDB + SARI) seems to be the overall
best. From a transformations capability point of view, TSM and TriS are capable of
performing splitting, which is an advantage over SBSMT variations that only generate
paraphrases.
4.2 Grammar Induction
In this approach, SS is modeled as a tree-to-tree rewriting problem. Approaches typi-
cally follow a two-step process: (1) use parallel corpora of aligned original-simplified
sentence pairs to extract a set of tree transformation rules, y luego (2) learn how to
select which rule(s) to apply to unseen sentences to generate the best simplified output.
This is analogous to how a SBSMT approach works: The rules would be the features, y
the decoder applies the learned model deciding how to use these rules. In what follows,
we first provide some brief preliminary explanations on synchronous grammars, y
then proceed to explain how grammar-induction-based approaches have implemented
each of the aforementioned steps.
4.2.1 Preliminaries. A Context-Free Grammar (CFG) is a set of productions or rewriting
rules that describe how to generate strings in a formal language. Synchronous Context-
Free Grammars (SCFGs) are a generalization of CFGs able to generate pairs of related
strings and not just single strings (Chiang 2006). In a SCFG, each production has two
158
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
hand-sides (source and target) that are related. Por ejemplo, we show a SCFG for a
sentence in English and its translation to Japanese (Chiang 2006):
S → (cid:104)NP1VP2|NP1VP2(cid:105)
VP → (cid:104)V1NP2|NP2V1(cid:105)
NP → (cid:104)i|watashi wa(cid:105)
NP → (cid:104)the box|hako wo(cid:105)
V → (cid:104)abierto|akemasu(cid:105)
The numbers in the non-terminals serve as links between nodes in the source and
objetivo. These links are 1-to-1 and every non-terminal is always linked to another.
SCFGs have the limitation of only being able to relabel and reorder sibling nodes.
A diferencia de, Synchronous Tree Substitution Grammars (STSGs, Eisner 2003) are able to
perform more long-distance swapping. In a STSG, productions are pairs of elementary
árboles, which are tree fragments whose leaves can be non-terminal or terminal symbols:
S
S
notario público
notario público
NP1
vicepresidente
NP2
vicepresidente
John
Jean
V
NP2
V
notario público
misses
manque
PAG
NP1
notario público
notario público
`a
Mary
Marie
SCFGs impose an isomorphism constraint between the aligned trees. This requirement
is relaxed by the STSGs. Sin embargo, to account for all the different movement patterns
that could exist in a language would require powerful and, tal vez, slow grammars
(Smith and Eisner 2006). Quasi-synchronous Grammars (QG, Smith and Eisner 2006)
relax the isomorphism constraint further, following the intuition that one of the parallel
trees is inspired by the other. This means that any node in one tree can be linked to any
other node on the other tree. Observe that in STSGs, even though the linked nodes can
be in any part of the frontier of the trees, they still need to have the same syntactic tag.
This is not the case in QGs because anything can align to anything.
4.2.2 Simplification Models. The formalisms explained in the previous subsection have
been used to automatically extract rules that convey the rewriting operations required to
simplify sentences. Using these transformation rules, grammar-induction-based models
then decide, given an original sentence, which rule(s) to apply and how to generate the
final simplification output (often referred to as decoding).
QG+ILP: Woodsend and Lapata (2011a) use QGs to induce rewrite rules that can
perform sentence splitting, word substitution, and deletion. From word alignments
between source and target sentences, they first align non-terminal nodes where more
159
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
than one child node aligns. From these constituent alignments, they extract syntactic
simplification rules. Sin embargo, if a pair of trees have the same syntactic structure but
differ only because of a lexical substitution, a more general rule is extracted considering
only the words and their part-of-speech tags. To create the rules for sentence splitting,
a source sentence is aligned with two consecutive target sentences (named main and
auxiliary). They then select a split node, which is a source node that “contributes” (es decir.,
has aligned children nodes) to both main and auxiliary targets. This results in a rule with
three components: the source node, the node in the target main sentence, and the phrase
structure in the entire auxiliary sentence. Some examples of these rules are:
•
•
•
Lexical: (cid:104)[VBN discovered](cid:105) → (cid:104) [VBD was] [VBN found](cid:105)
Syntactic: (cid:104)notario público, ST(cid:105) → (cid:104)[NP PP1], [ST1](cid:105)
Split: (cid:104)notario público, notario público, ST(cid:105) → (cid:104)[NP1 SBAR2], [NP1], [ST2](cid:105)
With these transformation rules, Woodsend and Lapata (2011a) then use Integer
Linear Programming (ILP) to find the best candidate simplification. During decoding,
the original sentence’s parse tree is traversed from top to bottom, applying at each node
all the simplification rules that match. If more than one rule matches, each candidate
simplification is added to the target tree. Como resultado, a “super tree” is created, cual
contains all possible simplifications of each node of the source sentence. Entonces, an ILP
program decides which nodes should be kept and which would be removed. El
objective function of the ILP considers a penalty for substitutions and rewrites (favors
the more common transformations with less penalty), and tries to reduce the number of
words and syllables. The ILP has constraints to ensure grammaticality (if a phrase node
is chosen, the node it depends on is also chosen), coherencia (if one partition of a split
sentence is chosen, the other partition is also chosen), and always one (and only one)
simplification per sentence. The authors trained two models: one extracting rules from
the AlignedLP corpus (AlignILP) and the other using the RevisionWL corpus (RevILP).
For evaluation, they used the test split from the PWKP instances. RevILP was their
best model, achieving the closest scores to the references using both Flesh-Kincaid and
human judgments on simplicity, grammaticality, and meaning preservation.
T3+Rank: Paetzold and Specia (2013) extract candidate tree rewriting rules using T3
(Cohn and Lapata 2009), an abstractive sentence compression model that uses STSGs
for deletion, reordering, and substitution. Using word-aligned parallel sentences, el
model maps the word alignment into a constituent-level alignment between the source
and target trees by adapting the alignment template method of Och and Ney (2004).
These constituent alignments are then generalized (es decir., aligned nodes are replaced with
Enlaces) to extract rules. This generalization is performed by a recursive algorithm that
attempts to find the minimal most general set of synchronous rules. The recursive depth
allowed by the algorithm determines the specificity of the rules.
Once the rules have been extracted, Paetzold and Specia (2013) divide them into two
conjuntos: one with purely syntactic transformations, and the other with purely lexical trans-
formations. This process has two goals: (1) to filter out rules that are not simplification
transformations according to some pre-established criteria on what type of information
the rule contains, y (2) to be able to explore syntactic and lexical simplification
individually. Given an original sentence, the proposed approach applies both sets of
rewriting rules separately. The candidate simplifications are then ranked, in each set, en
order to determine the best syntactic and the best lexical simplifications. For ranking,
they measure the perplexity of the output using a language model built from SEW.
160
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Mesa 4
Performance of grammar-based sentence simplification models as reported by their authors. A
(*) indicates a test set different from the standard.
Modelo
Train Corpus Test Corpus BLEU ↑
FKGL ↓
QG+ILP
AlignedWL
RevisionWL
C&k
T3+Rank
SimpleTT C&k
PWKP
PWKP
C&K*
C&k
12.36
10.92
34.0
42.0
34.2
56.4
Evaluation results using human judgments on simplicity, grammaticality, and meaning
preservation showed that candidate simplifications were only encouraging for lexical
simplification, almost half of the automatically simplified sentences were considered
simpler, encima 80% were considered grammatical, and a little over 50% were identified
as meaning preserving.
SimpleTT: Feblowitz and Kauchak (2013) proposed an approach similar to T3
(Cohn and Lapata 2009) using STSGs. They modified the rule extraction process to
reduce the number of candidate rules that need to be generalized. También, instead of
controlling the rules’ specificity with the recursion depth, SimpleTT augments the rules
with more information, such as head’s lexicalization and part-of-speech tag.
During decoding, the model starts by trying to match the more specific rules up
to the most general. If no rule matches, then the source parse tree is just copied. El
model generates the 10,000 most probable simplifications for a given sentence according
to the STSG grammar, and the best one is determined using a log-linear combination
of features, such as rule probability and output length. For training and testing, el
authors used the C&K-1 corpus, and compared their model against PBSMT-R and
Moses-Del. Using human evaluation, SimpleTT obtains the highest scores for simplicity
and grammaticality among the tested models, with values comparable to those for
human simplifications. Sin embargo, it obtains the lowest score in meaning preservation,
presumably because SimpleTT tends to simplify by deleting a sentence’s elements. Este
approach does not explicitly model sentence splitting.
Mesa 4 summarizes the performance of the models trained with the SS approaches
descrito. Desafortunadamente, results are not directly comparable. En general, gramática-
induction-based approaches, because of their pipeline architecture, offer more flexibility
on how the rules are learned and how they are applied, as compared with end-to-
end approaches. Even though Woodsend and Lapata (2011a) were the only ones who
attempted model splitting, the other approaches could be modified in a similar way,
since the formalisms allow it.
4.3 Semantics-Assisted
Narayan and Gardent (2014) argue that the simplification transformation of splitting is
semantics-driven. In many cases, splitting occurs when an entity takes part in two (o
más) distinct events described in a single sentence. Por ejemplo, in Sentence (1), bricks
is involved in two events: “being resistant to cold” and “enabling the construction of
permanent buildings.”
(1)
Original: Being more resistant to cold, bricks enabled the construction of
permanent buildings.
161
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
(2)
Simplified: Bricks were more resistant to cold. Bricks enabled the
construction of permanent buildings.
Even though deciding when and where to split can be determined by syntax (p.ej.,
sentences with relative or subordinate clauses), constructing the second sentence in
the split by adding the shared element with the first split should be accomplished by
semantic information, because we need to identify the entity involved in both events.
Hybrid: Narayan and Gardent (2014) built an SS model by combining semantics-
driven splitting and deletion, with PBSMT-based substitution and reordering. La generación-
eral idea is to use semantic roles information to identify the events in a given original
oración, and those events would determine how to split the sentence. También, deletion
would be directed by this information, since mandatory arguments for each identified
verbal predicate should not be deleted. For substitution of complex words/phrases and
reordering, the authors rely on a PBSMT-based model.
The proposed method first uses Boxer (Curran, clark, and Bos 2007) to obtain
the semantic representation of the original sentences. From there, candidate splitting
pairs are selected from events that share a common core semantic role (p.ej., agent and
patient). The probability of a candidate being a split is determined by the semantic
roles associated with it. The probability of deleting a node is determined by its se-
mantic relations to the split events. Además, the probabilities for substitution and
reordering are determined by a PBSMT system. For training, they used the Expectation-
Maximization algorithm of Yamada and Knight (2001), in a similar fashion to Zhu,
Bernhard, and Gurevych (2010), but calculating probabilities over the semantic graph
produced by Boxer instead of a syntactic parse tree.
The SS model is trained and tested using the PWKP corpus. Sentences for which
Boxer failed to extract a semantic representation were excluded during training, y
directly passed to the PBSMT system in testing. For evaluation, the model is compared
against QG+ILP, PBSMT-R, and TSM. Hybrid performs splits closer in proportion to
those of the references. It also achieves the highest BLEU score and smaller edit distance
to references. With human evaluation, Hybrid obtains the highest score in simplicity,
and is a close second to PBSMT-R for grammaticality and meaning preservation.
UNSUP: Narayan and Gardent (2016) propose a method that does not require
aligned original-simplified sentences to train a TS model. Their approach first uses a
context-aware lexical simplifier (Biran, Brody, and Elhadad 2011) that learns simpli-
fication rules from articles of EW and SEW. Given an original sentence, these rules
are applied and the best combination of simplifications is found using dynamic pro-
gramming. Entonces, they use Boxer to extract the semantic representation of the sentence
and identify the events/predicates. Después, they estimate the maximum likelihood
of the sequences of semantic role sets that would result after each possible split (es decir.,
subsequence of events). To compute these probabilities, they only rely on data from
SEW. Finalmente, they use an ILP to determine which phrases in the sentence should be
deleted, similarly to the compression model of Filippova and Strube (2008).
For evaluation, they use the test set of PWKP, and compare against TSM, QG+ILP,
PBSMT-R, and Hybrid. The proposed unsupervised pipeline achieves results compara-
ble to those of the other models, but it is only better than TSM in terms of BLEU score. Él
produces more splits than Hybrid, but also more than the reference. There is no analysis
about the correctness of the splits produced. Using human evaluation, UNSUP achieves
the highest values in simplicity and grammaticality.
EvLex: ˇStajner and Glavaˇs (2017) introduce an SS model that can perform sentence
splitting, content reduction, and lexical simplifications. For the first two transformations,
162
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
they build on Glavaˇs and ˇStajner (2013) identifying events in a given sentence. Cada
identified event and its arguments constitute a new simpler sentence (splitting). Infor-
mation that does not correspond to any of the events is discarded (content reduction).
For event identification, they use EVGRAPH (Glavaˇs and ˇSnajder 2015), which relies
on a supervised classifier to identify events and a set of manually-constructed rules to
identify the arguments. Finalmente, the pipeline also incorporates an unsupervised lexical
simplification model (Glavaˇs and tajner 2015). The authors carried out tests to determine
whether the order of the components affects the resulting simplifications. They found
that the differences were minimal.
The proposed architecture is compared with QG+ILP (Woodsend and Lapata
2011a), testing in two data sets, one with news stories (NEWS) and one with Wikipedia
oraciones (WIKI). EvLex achieves the highest FRE score in the NEWS data set, mientras
QG+ILP is the best in this metric in WIKI. Regarding human evaluations, their model
achieves the best grammaticality and simplicity scores for both data sets.
Mesa 5 summarizes the results of the models trained with the SS approaches
presented in this section. Not all models are directly comparable because they were
tested in different corpora. The semantics-aided models presented resemble, en parte, el
research of Bach et al. (2011) explained in Section 4.1.2, focused on sentence splitting.
In that work, splitting is based on preserving a SVO order in each split, which could
be considered as an agent-verb-patient structure. These findings suggest that the split-
ting operation requires a more tailored modeling, different from standard MT-based
sequence-to-sequence approaches.
4.3.1 Split-and-Rephrase. Narayan et al. (2017) introduce a new task called split-and-
rephrase, focused on splitting a sentence into several others, and making the necessary
changes to ensure grammaticality. No deletions should be performed so as to preserve
significado. The authors use the WEBSPLIT data set (descrito en la Sección 2.3) to train and
test five models for the split-and-rephrase task: (1) Hybrid (Narayan and Gardent 2014);
(2) Seq2Seq, which is an encoder-decoder with local-p attention (Luong, Pham, y
Manning 2015); (3) MultiSeq2Seq, which is a multi-source sequence-to-sequence model
(Zoph and Knight 2016) that takes as input the original sentence and its MR triples;
y (4) one that models the problem in two steps: first learn to split, and then learn
to rephrase. In this last model, the splitting step uses the original sentence and its MR
to split the latter into several MR sets. Sin embargo, two variations are explored for the
rephrasing step: (1) Split-MultiSeq2Seq learns to rephrase from the split MRs and the
original sentence in a multi-source fashion, mientras (2) Split-Seq2Seq only uses the split
MRs and rephrases based on a sequence-to-sequence model.
All models were automatically evaluated using multi-reference BLEU, the average
number of simple sentences per complex sentence, and the average number of output
words per output simple sentence. Split-Seq2Seq achieved the best scores in all the
Mesa 5
Performance of semantics-assisted sentence simplification models as reported by their authors.
Modelo
Train Corpus Test Corpus BLEU ↑
FRE ↑
EVLEX
Hybrid
UNSUP
PWKP
PWKP
WIKI
NEWS
PWKP
PWKP
53.60
38.47
59.8
74.7
163
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
métrica. This result supports the idea that the split-and-rephrase task is better treated in
a pipeline. One could also hypothesize that the semantic information in the MRs helps in
the splitting step. Sin embargo, according to the paper, the authors “strip off named-entities
and properties from each triple and only keep the tree skeleton” when learning to split.
This suggests that it may not be the semantic information itself (es decir., the properties), pero
the groupings of semantically related elements in each triple that helps perform the splits.
Aharoni and Goldberg (2018) focus on the text-to-text setup of the task, eso es,
without using the MR information. They first propose a new split of the data set after
determining that around 90% of unique simple sentences in the original development
and test sets also appeared in the training set. With the new data splits, they train
a vanilla sequence-to-sequence model with attention, and incorporate a copy mecha-
nism inspired by work in abstractive text summarization (2016; Ver, Liu, and Manning
2017). This model achieves the best performance in both the original and new data set
se divide, but with a low BLEU score of 24.97.
Botha et al. (2018) argue that poor performance on the task may be due to WEBSPLIT
not being suitable for training models. According to the authors, because WEBSPLIT was
derived from the WEBNLG data set, it only contains artificial sentence splits created
from the RDF triples. Tal como, they introduce WikiSplit, a new data set for split-and-
rephrase based on English Wikipedia edit histories (see Sec. 2). Botha et al. use the same
model as Aharoni and Goldberg (2018) to experiment with different combinations of
training data: WEBSPLIT only, WikiSplit only, and both. The evaluation is performed on
WEBSPLIT. Results show that training using WikiSplit only or both improves perfor-
mance on the task in around 30 BLEU points.
4.4 Neural Sequence-to-Sequence
In this approach, SS is modeled as a sequence-to-sequence problem, and tackled
normally with an attention-based encoder-decoder architecture (Bahdanau, Dar, y
bengio 2014). The encoder projects the source sentence into a set of continuous vector
representations from which the decoder generates the target sentence. A major advan-
tage of this approach is that it allows training of end-to-end models without needing to
extract features or estimate individual model components, such as the language model.
Además, all simplification transformations can be learned simultaneously, instead of
developing individual mechanisms as in previous research.
4.4.1 RNN-Based Architectures. Most models are based on Recurrent Neural Networks
(RNNs) with long short term memory units (LSTMs, Hochreiter and Schmidhuber
1997). Given an original source sentence X = (x1, x2, . . . , X|X|), the model learns to pre-
dict its simplified version, Y = (y1, y2, . . . , y|Y|). It uses an encoder that transforms the
source sentence X into a sequence of hidden states (hS
|X|), from which the
decoder generates one word yt+1 at the time in target Y. The generation process is
conditioned on all the words generated so far y1:t and a dynamic context vector ct, cual
also encodes the source sentence:
2, . . . , hS
1, hS
PAG( Y|X) =
|Y|
(cid:89)
t=1
PAG( yt|y1:t−1, X)
PAG( yt+1|y1:t, X) = softmax( gramo(hT
t , ct))
(16)
(17)
164
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
where g(·) is a neural network with one hidden layer and parametrized as follows:
gramo(hT
t , ct) = Wo tanh(UhhT
t + Whct)
(18)
where Wo ∈ R|V|×d, Uh ∈ Rd×d, and Wh ∈ Rd×d; |V| is the output vocabulary size and d
is the hidden unit size. hT
t is the hidden state of the decoder LSTM that summarizes y1:t
(what has been generated so far):
t = LSTM(yt, hT
hT
t−1)
(19)
The dynamic context vector ct is a weighted sum of the hidden states of the source
oración, whose weights αti are determined by an attention mechanism:
ct =
|X|
(cid:88)
yo=1
α ti hS
i
α ti
=
exp.(hT
i exp(hT
t · hS
i )
t · hS
i )
(cid:80)
(20)
NTS: Nisioi et al. (2017) introduced the first Neural Text Simplification approach
using the encoder-decoder with attention architecture provided by OpenNMT (Klein
et al. 2017). They experimented with using the default system, and also with combining
pre-trained word2vec word embeddings (Mikolov et al. 2013) with locally trained ones.
They also generated two candidate hypotheses for each beam size, and used BLEU and
SARI to determine which hypothesis to choose from the n-best list of candidates. EW-SEW
was used for training, and TurkCorpus for validation and testing. When compared
against PBSMT-R and SBSMT (PPDB+SARI), NTS with its default features achieved the
highest grammaticality and meaning preservation scores in human evaluation. SBSMT
(PPDB+SARI) was still the best using SARI scores. En general, NTS is able to perform
simplifications limited to paraphrasing and deletion transformations. It is also apparent
that choosing the second hypothesis results in less conservative simplifications.
NematuSS: Alva-Manchego et al. (2017) also tested this standard neural architec-
ture for SS, but used the implementation provided by Nematus (Sennrich et al. 2017).
They experimented with different types of original-simplified sentence alignments ex-
tracted from the Newsela corpus. When experimenting with all possible sentence align-
mentos, the model tended to be too aggresive, mostly performing deletions. When using
only 1-to-1 alignments, the model became more conservative, and the simplifications
performed were restricted to deletions and one-word replacements.
targeTS: Inspired by the work of Johnson et al. (2017) on multilingual neural MT,
Scarton and Specia (2018) enriched the encoder’s input with information about the
target audience and the (predicted) simplification transformations to be performed.
Concretely, an artificial token was added to the beginning of the input sentences indi-
cating (1) the grade level of the simplification instance, and/or (2) one of four possible
text transformations: identical, elaboración, splitting, or joining. en el momento de la prueba, the text
transformation token is either predicted (using a simple features-based naive Bayes
clasificador) or an oracle label is used. They experimented using the standard neural
architecture available in OpenNMT and data from the Newsela corpus. Results showed
improvements in BLEU, SARI, and Flesch scores when using this extra information.
NSELSTM: Vu et al. (2018) used Neural Semantic Encoders (NSEs, Munkhdalai
and Yu 2017) instead of LSTMs for the encoder. At any encoding time step, a NSE has
access to all the tokens in the input sequence, and is thus able to capture more context
information while encoding the current token, instead of only relying on the previous
hidden state. Their approach is tested on PWKP, TurkCorpus, and Newsela. Two models
165
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
are presented, one tuned using BLEU (NSELSTM-B) and one using SARI (NSELSTM-S).
When compared against other models, NSELSTM-B achieved the best BLEU scores in
the Newsela and TurkCorpus data sets, while NSELSTM-S was second-best on SARI
scores in Newsela and PWKP. According to human evaluation, NSELSTM-B has the
best grammaticality for Newsela and PWKP, while NSELSTM-S is the best in meaning
preservation and simplicity for PWKP and TurkCorpus.
4.4.2 Modifying the Training Method. Without significantly changing the standard RNN-
based architecture described before, some research has experimented with alternative
learning algorithms with which the models are trained.
DRESS: Zhang and Lapata (2017) use the standard attention-based encoder-decoder
as an agent within a Reinforcement Learning (rl) architecture (Cifra 2). An advantage
of this approach is that the model can be trained end-to-end using SS-specific metrics.
The agent reads the original sentence and takes a series of actions (words in the
vocabulary) to generate the simplified output. Después, it receives a reward that
scores the output according to its simplicity, relevance (preservación del significado), y
fluency (grammaticality). To reward simplicity, they calculate SARI in both the expected
direction and in reverse (using the output as reference, and the reference as output) a
counteract the effect of having noisy data and a single reference; the reward is then the
weighted sum of both values. To reward relevance, they compute the cosine similarity
between the vector representations (obtained using a LSTM) of the source sentence and
the predicted output. To reward fluency, they calculate the probability of the predicted
output using an LSTM language model trained on simple sentences.
For learning, the authors used the REINFORCE algorithm (williams 1992), cuyo
goal is to find an agent that maximizes the expected reward. Tal como, the training loss
is given by the negative expected reward:
l(i) = −E
( ˆy1,…, ˆy| ˆY| ) ∼ PRL(·|X)[r( ˆy1, . . . , ˆy| ˆY|)]
(21)
where PRL is the policy, given in our case by the distribution produced by the
encoder-decoder Equation (17) and r(·) is the reward function. The authors followed
Ranzato et al. (2016) in first pre-training the agent by minimizing the negative log-
likelihood of the training source–target pairs, in order to avoid starting the process with
Cifra 2
Model architecture for DRESS. Extracted from Zhang and Lapata (2017).
166
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
a random policy. Entonces, for each target sequence, they used the same learning process to
train the first L tokens, and applied the RL algorithm in the remaining token.
Even though the model as-is can learn lexical simplifications, the authors state that
these are not always correct. Tal como, the model is modified to learn them explicitly. Un
encoder-decoder is trained in a parallel original-simplified corpus to obtain probabilistic
word alignments (attention scores αt) that help determine whether a word should or
should not be simplified. For these lexical simplifications to take context into con-
sideration, they are integrated into the RL model using linear interpolation following
Ecuación (22), where PLS is the probability of simplifying a word.
PAG(yt|y1:t−1, X) = (1 − η)PRL(yt|y1:t−1, X) + ηPLS(yt|X, αt)
(22)
The model that only uses the RL algorithm (DRESS) and the one that also incor-
porates the explicit lexical simplifications (DRESS-LS) are trained and tested on three
different data sets: PWKP, WikiLarge (with TurkCorpus for testing), and Newsela. El
authors compared their models against PBSMT-R, Hybrid, SBSMT (PPDB+SARI), y
a standard encoder-decoder with attention (EncDecA). In PWKP, DRESS has the lowest
FKGL followed by DRESS-LS. In the TurkCorpus, DRESS and DRESS-LS are second best
in FKGL and third best in SARI. In Newsela, DRESS-LS achieves the highest BLEU score.
En general, DRESS and DRESS-LS obtained better scores than EncDecA, with DRESS-LS
being the best of the three. It is worth noting that even though there were examples
of sentence splitting in the training corpora (p.ej., PWKP), the authors do not report on
their models being able to perform it.
PointerCopy+MTL: guo, Pasunuru, and Bansal (2018) worked with SS within a
Multi-Task Learning (MTL) estructura. Considering SS as the main task, they incor-
porated two auxiliary tasks to improve the model’s performance: paraphrase gener-
ation and entailment generation. The former helps with inducing word and phrase
replacements, reorderings, and deletions; while the latter ensures that the generated
simplified output logically follows the original sentence. The proposed MTL architec-
ture implements multi-level soft sharing (Cifra 3). Based on observations by Belinkov
et al. (2017), lower-level layers in the encoder/decoder (es decir., that are closer to the
input/output) are shared among tasks focused on word representations and syntactic-
información de nivel (es decir., SS and paraphrasing); whereas higher-level layers are shared
among tasks focused on semantics and meaning (es decir., SS and entailment). Además,
their RNN-based model is enhanced with a pointer-copy mechanism (Ver, Liu, y
Manning 2017), which allows deciding at decoding time whether to copy a token from
the input or generate one.
When training main and auxiliary tasks in parallel, a concern within MTL is how
to determine the appropriate number of iterations on each task relative to the others.
This is normally handled using a static hyperparameter. A diferencia de, guo, Pasunuru,
and Bansal (2018) proposed learning this mixing ratio dynamically using a multi-armed
bandits based controller. Basically, at each round, the controller selects a task based on
some noise value estimates, observes “rewards” for the selected task (in their case, el
reward was the negative validation loss of the main task), and switches accordingly.
The proposed model was trained and tested using PWKP, WikiLarge (with TurkCorpus
as test set), and Newsela for SS; the SNLI (Bowman et al. 2015) and the MultiNLI
(williams, Nangia, and Bowman 2018) corpora for entailment generation; and ParaNMT
(Wieting and Gimpel 2018) for paraphrase generation. Using automatic metrics,
PointerCopy+MTL achieved the highest SARI score only in the Newsela corpus. Con
human judgments, their model scored as the best in simplicity.
167
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Cifra 3
Model architecture for PointerCopy+MTL. Extracted from Guo, Pasunuru, and Bansal (2018).
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
4.4.3 Adding External Knowledge. The previously described models attempted to learn
how to simplify only using information from the training data sets. Zhao et al. (2018) ar-
gued that the relatively small size of these data sets prevents models from generalizing
Bueno, considering the vast amount of possible simplification transformations that exist.
Por lo tanto, they proposed to include human-curated paraphrasing rules from Simple
Paraphrase Database (SPPDB; Pavlick and Callison-Burch 2016) into a neural encoder-
decoder architecture. This intuition is similar to Xu et al. (2016), who incorporated those
rewriting rules into a SBSMT-based model. Además, the authors moved from the
RNN-based architecture to one based on the Transformer (Vaswani et al. 2017).
The rewriting rules from SPPDB were incorporated into the model using two
mechanisms. In Deep Critic Sentence Simplification (DCSS), the model uses a new
loss function that maximizes the probability of generating the simplified form of a
palabra, while minimizing the probability of generating its original one. In Deep Memory
Augmented Sentence Simplification (DMASS), the model has a built-in memory that
stores the rules from SPPDB in the form context vectors calculated from the hidden
states of the encoder, and corresponding generated outputs.
The model was trained only using WikiLarge, and tested on TurkCorpus and
Newsela. The authors evaluated using both mechanisms, DCSS and DMASS, india-
pendently, as well as in conjunction. Then compared to other models, DMASS+DCSS
achieved the highest SARI score in both test sets. They also estimated the correctness of
rule utilization based on ground-truth from SPPDB, and showed that their models also
improved compared to previous work.
168
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
4.4.4 Unsupervised Architectures. Surya et al. 2019 proposed an unsupervised approach
for developing a simplification system. Their motivation was to design an architecture
that could be exploited to train SS models for languages or domains that do not have
large resources of parallel original-simplified instances. Their proposal is based on a
modified auto encoder that uses a shared encoder E and two dedicated decoders: one for
generating complex sentences (Gd) and one for simple sentences (Gs). Además, su
model relies on Discriminator and Classifier modules. The Discriminator determines if a
given context vector sequence (from either complex or simple sentences) is close to one
extracted from simple sentences in the data set. It interacts with Gs using an adversarial
loss function Ladv, in a similar fashion as GANs (Goodfellow et al. 2014). The Classifier
is in charge of diversification by ensuring, through loss function Ldiv, that both Gd and
Gs attend differently to the hidden representations generated by the shared encoder.
Two additional loss functions, Lrec and Ldenoi, are used for reconstructing sentences and
denoising, respectivamente. The full architecture can be seen in Figure 4.
The proposed model (UNTS) was trained using an English Wikipedia dump that
was partitioned into Complex and Simple sets using a threshold based on Flesch
Reading Ease scores. They also used 10,000 sentence pairs from EW-SEW (Hwang
et al. 2015) and WebSplit (Narayan et al. 2017) data sets to train a model (UNTS+10K)
with minimal supervision. Their models were compared against unsupervised systems
from the MT literature (casa de arte, Labaka, and Agirre 2018; Artetxe et al. 2018), también
as SS models like NTS (Nisioi et al. 2017) and SBSMT (Xu et al. 2016), and using
TurkCorpus as test data. When evaluated using automatic metrics, SBSMT scored the
highest on SARI, but both UNTS and UNTS+10K were not far from the supervised
modelos. This same behavior was observed with human evaluations. Even though the
unsupervised model was trained using instances of sentence splitting from WebSplit,
the authors do not report testing it on data for that specific text transformation.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
169
Cifra 4
Model architecture for UNTS. Extracted from Surya et al. (2019).
Ligüística computacional
Volumen 46, Número 1
4.4.5 Simplification as Sequence Labeling. Alva-Manchego et al. (2017) model SS as a
Sequence Labeling problem, identifying simplification transformations at word or
phrase level. They use the token-level annotation algorithms of MASSAlign (Paetzold,
Alva-Manchego, and Specia 2017) to automatically generate annotated data from which
an LSTM learns to predict simplification transformations; more specifically, deletions
and replacements. During decoding, words labeled to be deleted are just not included
in the output. To produce replacements, they use the lexical simplifier of Paetzold and
Specia (2017a). The proposed approach is compared against MT-based models: Moses
(Koehn et al. 2007), Nematus (Sennrich et al. 2017), and NTS+word2vec (with default
settings) using data from the Newsela corpus. Alva-Manchego et al. (2017) achieve the
highest SARI score in the test set, and best simplicity score with human judgments.
This approach is inspired in the abstractive sentence compression model of Bingel and
Søgaard (2016), who propose a tree labeling approach to remove or paraphrase syntactic
units in the dependency tree of a given sentence, using a Conditional Random Fields
predictor.
Most sequence-to-sequence approaches for training SS models could be considered
as black boxes with respect to which simplification transformations should be applied
to a given sentence. That is a desirable feature for a holistic approach to SS, dónde
the rewriting operations interact with each other, and are not necessarily applied in
isolation (p.ej., a sentence can be split, and some of its components deleted/reordered
simultaneously). Sin embargo, it could also be desirable to have a more modular approach
to the problem: to first determine which simplifications should be performed in a given
oración, and then decide how to handle each transformation independently (poten-
tially using a different approach for each operation). Approaches based on labeling
could be helpful in such cases. A disadvantage, sin embargo, is collecting quality annotated
data from which to learn. Además, some simplification transformations are hard to
predict (p.ej., insertion of words that do not come from the original sentence).
Mesa 6 summarizes the performance of the models trained with the SS approaches
descrito. En este caso, some of the values can be compared on the test set used. De
all the sequence-to-sequence models tested in TurkCorpus, DMASS-DCSS obtains the
highest SARI score, with NSELSTM-B achieving the best BLEU. Both approaches used
WikiLarge for training. Regarding the transformations that they can perform, secuencia-
to-sequence models seem to be able to perform substitutions, deletions, and reorderings,
just like previous MT-based approaches. None of the papers reports if these architec-
tures are able to perform sentence splitting.
4.5 Discusión
In this section we have presented a summary of research in data-driven automatic
SS. This review has helped to understand the benefits and shortcomings of each ap-
proach to the task. Traditionally, SS has been reduced to four text transformations:
substituting complex words or phrases, deleting or reordering sentence components, y
splitting a complex sentence into several simpler ones (Zhu, Bernhard, and Gurevych
2010; Narayan and Gardent 2014). Mesa 7 lists the surveyed SS models (grouped by
acercarse), the techniques each of them explores, and the simplification transformations
that they can perform, considering the four traditional rewriting operations established.
En general, SMT-based methods can perform substitutions, short-distance reorderings,
and deletions, but fail to produce quality splits unless explicitly modeled using syntactic
170
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Mesa 6
Performance of sequence-to-sequence sentence simplification models as reported by their
autores.
Train Corpus Test Corpus BLEU ↑
FKGL ↓
SARI ↑
Modelo
NTS
NTS+SARI
DRESS
DRESS-LS
NSELSTM-B
NSELSTM-S
EW-SEW
EW-SEW
WikiSmall
WikiLarge
Newsela
WikiSmall
WikiLarge
Newsela
WikiSmall
WikiLarge
Newsela
WikiSmall
WikiLarge
Newsela
TurkCorpus
TurkCorpus
PWKP
TurkCorpus
Newsela
PWKP
TurkCorpus
Newsela
PWKP
TurkCorpus
Newsela
PWKP
TurkCorpus
Newsela
PWKP
TurkCorpus
Newsela
TurkCorpus
Newsela
84.51
80.69
34.53
77.18
23.21
36.32
80.12
24.30
53.42
92.02
26.31
29.72
80.43
22.62
29.70
81.49
11.86
30.65
37.25
27.48
37.08
27.37
27.24
37.27
26.63
17.47
33.43
27.42
29.75
36.88
29.58
28.24
37.45
32.98
40.45
27.28
7.48
6.58
4.13
7.55
6.62
4.21
6.93
7.41
1.38
8.04
5.17
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
POINTERCOPY+MTL WikiSmall
WikiLarge
Newsela
WikiLarge
WikiLarge
DMASS+DCSS
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
information or coupled with more expensive processes, such as semantic analysis.
Grammar-based approaches can model splits (and syntactic changes in general) más
naturally, but the critical process of selecting which rule(s) to apply, in which order,
and how to determine the best simplification output is complex. In this respect, se-
quence labeling seems more straightforward, and offers some flexibility in how each
identified transformation could be handled individually. Sin embargo, there is no available
manually produced corpus with the required annotations that could allow studying
the advantages and limitations of this approach. Además, there is little research on
dealing with discourse-related issues caused by the rewriting transformations, or on
considering more document-level constraints.
5. Benchmarking Sentence Simplification Models
So far in this article we have explained how several SS models were implemented,
and have commented on their performance based on the results reported by their
autores. Sin embargo, one problem we encountered was comparing these models against
one another objectively, since most authors used different corpora or (implementations
de) metrics for testing their models. Some researchers have realized this problem and
it is now more common to have access to their models’ outputs on some data sets.
También, some have reimplemented SS approaches that were not made available by their
original authors. En esta sección, we take advantage of this fact to use publicly available
outputs of SS models on commonly used data sets, and measure their simplification
performance using the same set of metrics and test data.
As shown in Section 3, in order to automatically evaluate the output of an SS model,
we normally use MT-inspired metrics (p.ej., AZUL), readability metrics (p.ej., Flesch
Kincaid), and simplicity metrics (p.ej., SARI). Automatic metrics are easy to compute,
171
SUB, DEL, REORD,
SPLIT
SPLIT
SUB, REORD
SUB, DEL, REORD,
SPLIT
SUB, DEL, REORD,
SPLIT*
SUB, DEL, REORD,
SPLIT*
SUB, DEL, REORD,
SPLIT
SUB, DEL, SPLIT
Ligüística computacional
Volumen 46, Número 1
Mesa 7
Summary of sentence-level text simplification approaches: SMT-based (first section),
grammar-based (second section), semantics-assisted (third section), and neural
sequence-to-sequence (fourth section). The transformations listed are the ones the authors
acknowledge that their models can perform. Transformations with * are found in some of the
outputs, but not explicitly modeled by the authors.
Modelo
Acercarse
Transformations
Specia (2010)
Coster and Kauchak (2011b)
Coster and Kauchak (2011a)
Wubben, van den Bosch, y
Krahmer (2012)
Zhu, Bernhard, and Gurevych
(2010)
Bach et al. (2011)
Xu et al. (2016)
PBSMT (Moses)
PBSMT (Moses)
PBSMT (Moses) + Deletion
PBSMT (Moses) + Dissimilarity
SUB, REORD
SUB, REORD
SUB, DEL, REORD
SUB
Ranking
SBSMT
SBSMT
SBSMT (Joshua) + SPPDB +
SARI Optimization
Woodsend and Lapata (2011a)
QG + ILP
Paetzold and Specia (2013)
STSGs + Perplexity Ranking
Feblowitz and Kauchak (2013)
STSGs Backoff + Log-linear
Reranking
Narayan and Gardent (2014)
Deep Semantics (Boxer) +
PBSMT
Narayan and Gardent (2016)
Lexical Simp. + Deep Semantics
(Boxer) + ILP
ˇStajner and Glavaˇs (2017)
Event Detection for Splitting +
SUB, DEL, SPLIT
Unsupervised Lexical
Simplification
Narayan et al. (2017)
Semantics-aided Splitting + NTM SUB, REORD, SPLIT
Nisioi et al. (2017)
Zhang and Lapata (2017)
Vu et al. (2018)
guo, Pasunuru, and Bansal (2018)
Zhao et al. (2018)
Alva-Manchego et al. (2017)
Seq2Seq (RNN) + PPDB + SARI
Seq2Seq (RNN) + rl
Seq2Seq (RNN) with NSE
Seq2Seq (RNN) + MTL
Seq2Seq (Transformador) + SPPDB
Sequence Labeling
SUB, DEL, REORD
SUB, DEL, REORD
SUB, DEL, REORD
SUB, DEL, REORD
SUB, DEL, REORD
SUB, DEL
but they only provide overall performance scores that cannot explain specific strengths
and weaknesses of an SS approach. Por lo tanto, we propose to also evaluate SS models
based on how effective they are at executing specific simplification transformations. Nosotros
show how this per-transformation assessment contributes to a better understanding of
the automatic scores, and to an improved comparison between different SS models.
5.1 Evaluation Setting
En esta sección, we describe the test sets for which we collected SS models’ outputs. Después
eso, we specify how we compare them using a few of the automatic metrics previously
described and automatic identifications of a set of simplification transformations.
172
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Mesa 8
Characteristics of the tests sets on which SS models’ outputs were collected. An instance
corresponds to a source sentence with one or more possible references. Each reference can be
composed of one or more sentences.
Test data set
Instances Alignment type References
PWKP
TurkCorpus
93
7
359
1-to-1
1-to-N
1-to-1
1
1
8
5.1.1 Data sets. We compare the SS models’ outputs in two commonly used test sets
extracted from corpora based on EW and SEW: PWKP (Zhu, Bernhard, and Gurevych
2010) and TurkCorpus (Xu et al. 2016). Both test sets contain automatically generated
original-simplified sentence alignments (see Sections 2.1.1 y 2.3 for details). Mesa 8
lists some of their characteristics.
The 1-to-N alignments in PWKP mean that some instances of sentence splitting
are present in the data set. This is a limitation of TurkCorpus that only contains 1-to-1
alignments, mostly providing instances of paraphrasing and deletion operations. On
the other hand, each original sentence in TurkCorpus has eight simplified references
produced through crowdsourcing. This allows us to more confidently use metrics that
rely on multiple references, like SARI. We do not use the Newsela corpus in our bench-
mark because researchers are prohibited from publicly releasing models’ outputs on
these data.
5.1.2 Overall Performance Comparison. We first compare the models’ outputs using au-
tomatic metrics so as to obtain an overall measure of simplification quality. We cal-
culate BLEU, SARI, SAMSA, and FKGL. We compute the scores for these metrics
using EASSE (Alva-Manchego et al. 2019),10 a Python package for single access to
(re)implementations of these metrics. Específicamente, it uses SACREBLEU (Correo 2018)11
to calculate BLEU, a re-implementation of SARI’s corpus-level version in Python (él
was originally available in Java), a slightly modified version of the original SAMSA
implementation12 for improved execution speed, and a re-implementation of FKGL
based on publicly available scripts13 that fixes some edge case inconsistencies.
5.1.3 Transformation-Based Performance Comparison. We are also interested in an in-depth
study of the simplification capabilities of each model. En particular, we want to deter-
mine which simplification transformations each model performs more effectively.
In order to identify the simplification transformations that a model performed, él
would be ideal to have corpora with such type of annotations and compare against
a ellos. Sin embargo, there is no available simplification corpus with such a type of infor-
formación. As a work-around, we use the annotator module of MASSAlign (Paetzold,
Alva-Manchego, and Specia 2017). This tool provides algorithms to automatically label
the simplification transformations carried out in aligned original-simplified sentences.
10 https://github.com/feralvam/easse.
11 https://github.com/mjpost/sacreBLEU.
12 https://github.com/eliorsulem/SAMSA.
13 https://github.com/mmautner/readability.
173
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Based on word alignments, the algorithms attempt to identify copies, deletions, move-
mentos, and replacements.
Alva-Manchego et al. (2017) tested the quality of the automatically produced la-
bels, comparing them with manual annotations for 100 sentences from the Newsela
cuerpo. These annotations were performed by four proficient speakers of English. Para
30 of those sentences annotated by the four annotators, the pairwise inter-annotator
agreement between annotators yielded an average kappa value of 0.57. For all labels
(excluding copies), the algorithms achieved a micro-averaged F1 score of 0.61, ser
especially effective at identifying deletions and replacements.
MASSAlign’s annotation algorithms were integrated into EASSE, and are used
to generate two sets of automatic word-level annotations: (1) between the original
sentences and their reference simplifications, y (2) between the original sentences
and their automatic simplifications produced by an SS system. Considering (1) como
reference labels, we calculate the F1 score of each transformation in (2) to estimate their
correctness. When more than one reference simplification exists, we calculate the per-
transformation F1 scores of the output against each reference, and then keep the highest
one as the sentence-level score. The corpus-level scores are the average of sentence-level
puntuaciones.
5.2 Comparing Models in the PWKP Test Set
For the PWKP test set, the models that have publicly available outputs are: Moses
(released by Zhu, Bernhard, and Gurevych 2010), PBSMT-R, QG+ILP (released by
Narayan and Gardent 2014), Hybrid, TSM, UNSUP, EncDecA, DRESS, and DRESS-LS.
Overall scores using standard metrics are shown in Table 9 sorted by SARI.
According to the values of the automatic metrics, Hybrid is the model that produces
the simplest output as measured by SARI, followed by Moses. If we consider BLEU as
indicative of grammaticality, Moses produces the most fluent output, followed closely
by Hybrid. This is not surprising since MT-based models, en general, tend to produce
well-formed sentences. También, TSM achieves the lowest FKGL, which seems to be indica-
tive of shorter output, rather than simpler output (its SARI score is in the middle of
the pack). We also note that grammaticality has no impact on FKGL values; eso es, a
text with low grammaticality can still have a good FKGL score. Por lo tanto, since DRESS
Mesa 9
Performance measured with automatic metrics in the PWKP test set.
Modelo
SARI ↑
BLEU ↑
SAMSA ↑
FKGL ↓
Reference
100.00
100.00
Hybrid
Moses
DRESS-LS
DRESS
TSM
UNSUP
PBSMT-R
QG+ILP
EncDecA
54.67
48.99
40.44
40.04
39.02
38.41
35.49
35.24
32.26
53.94
55.83
36.32
34.53
37.69
38.28
46.31
41.76
47.93
29.91
36.04
34.53
29.43
28.92
37.39
35.81
35.63
41.71
35.28
8.07
10.29
11.58
8.52
8.40
6.40
7.75
12.26
7.08
12.12
174
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Mesa 10
Performance measured with transformation-specific F1 score in the PWKP test set.
Modelo
Delete Move Replace Copy
Moses
Hybrid
PBSMT-R
TSM
EncDecA
UNSUP
DRESS
DRESS-LS
QG+ILP
31.36
34.01
12.05
29.15
8.59
25.58
35.65
35.23
16.77
2.47
2.84
0.00
0.62
0.34
1.40
0.38
0.36
3.90
17.17
16.06
8.17
6.57
5.23
4.27
3.40
2.33
2.00
70.27
69.83
66.59
62.22
66.09
62.83
59.02
59.97
56.47
obtains the lowest BLEU score, its FKGL value is not reliable. In terms of SAMSA, el
best model is QG+ILP, followed by TSM and Hybrid. Because this metric focuses on
assessing sentence splitting, it is expected that the models that explicitly perform this
transformation scored best. From these results, we could conclude that Hybrid is the
overall best model, since it achieves the highest SARI, AZUL, and SAMSA scores close
to the highest, and a FKGL not too far from the reference.
It could be surprising to see that the SAMSA score for the reference is one of the
lowest. This is explained by the way the metric is computed. Because it relies on word
alignments, if the simplification significantly changes the original sentence, then these
alignments are not possible, resulting in a low score. Por ejemplo:
(3)
Original: Genetic engineering has expanded the genes available to
breeders to utilize in creating desired germlines for new crops.
(4)
Reference: New plants were created with genetic engineering.
This is the reason why SAMSA should only be used for evaluating instances of
sentence splitting that do not perform significant rephrasings of the sentence.
Mesa 10 presents the results of our transformation-based performance measures for
models’ outputs on PWKP. From Table 9, we saw that Hybrid got the highest SARI score.
With the results on Table 10 we can understand better why that happened. Because SARI
is a metric aimed mostly at lexical simplification, it rewards replacements and making
small changes to the original sentence. In this test set, Moses and Hybrid’s replacements
and copying operations are among the most accurate. EncDecA, which obtained the
worst SARI score, is only average in replacement and copy, and has the lowest deletion
exactitud, which points out to them mostly repeating the original sentence without
much modifications. Finalmente, DRESS and DRESS-LS are the best ones in deleting content,
which explains their low (and “good”) FKGL scores.
5.3 Comparing Models in the TurkCorpus Test Set
The models evaluated on this test set are almost the same ones as before, excepto por
Moses, QG+ILP, TSM, and UNSUP, for which we could not find available outputs on
this test set. Sin embargo, we now also include SBSMT (PPDB+SARI) and NTS+SARI.
Because the TurkCorpus has multiple simplified references for each original sentence,
175
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Mesa 11
Performance measured with automatic metrics in the TurkCorpus test set.
Modelo
Reference
DMASS-DCSS
SBSMT(PPDB+SARI)
PBSMT-R
NTS+SARI
DRESS-LS
DRESS
Hybrid
TurkCorpus
SARI ↑
BLEU ↑
HSplit
SAMSA ↑
FKGL ↓
49.88
40.42
39.96
38.56
37.30
37.27
37.08
31.40
97.41
73.29
73.08
81.11
79.82
80.12
77.18
48.97
54.00
35.45
41.41
47.59
45.52
45.94
44.47
46.68
8.76
7.66
7.89
8.78
8.11
7.58
7.45
5.12
Mesa 12
Performance measured with transformation-specific F1 score in the TurkCorpus test set.
Modelo
Delete Move Replace Copy
PBSMT-R
Hybrid
SBSMT-SARI
NTS-SARI
DRESS-LS
DMASS-DCSS
34.18
49.46
28.42
31.10
40.31
38.03
2.64
7.37
1.26
1.58
1.43
5.10
23.65
1.03
37.21
23.88
12.62
34.79
93.50
70.73
92.89
88.19
86.76
86.70
we use all of them for measuring BLEU and SARI. For calculating reference values,
we sample one of the eight human references for each instance as others have done
(Zhang and Lapata 2017). When reporting SAMSA scores, we only use the 70 oraciones
of TurkCorpus that also appear in HSplit.14 This allows us to compute reference scores
for instances that contain structural simplifications (es decir., sentence splits). We calculate
SAMSA for each of the four manual simplifications in HSplit, and choose the highest as
an upper-bound. Results are presented in Table 11 sorted by SARI score.
In this test set, the models that used external knowledge from Simple PPDB
achieved the highest scores in terms of SARI: DMASS-DCSS and SBSMT (PPDB+SARI).
The most fluent model according to BLEU is PBSMT-R, closely followed by DRESS-LS.
This could be due to MT-based models being capable of generating grammatical output
de alta calidad. Contrary to what was observed in the PWKP test set, Hybrid achieved
the worst scores in SARI and SAMSA. This could be explained by the low FKGL score.
It appears that Hybrid tends to modify the original sentence much more than other
modelos, potentially by deleting content and producing shorter outputs. In this test
colocar, this behavior is penalized since most references were only rewritten considering
paraphrases of words and phrases.
Mesa 12 presents the results of our transformation-based performance measures for
models’ outputs on the TurkCorpus test set. Similarly to the PWKP test set, the effec-
tiveness results on TurkCorpus support the scores of the automatic metrics (Mesa 11).
14 At the time of this submission only a subset of 70 sentences had been released from HSplit. Sin embargo,
the full corpus will soon be available in EASSE.
176
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
SBSMT (PPDB+SARI) is the best at performing replacements, which explains its high
SARI score. PBSMT-R obtained the best BLEU score, which is explained by the above-
average copy transformations. Even though Hybrid achieved the lowest FKGL value,
it is the best in deletions, has a below-average copying, and does not produce accurate
replacements. Este, de nuevo, suggests that a low FKGL score does not necessarily indicate
good simplifications. Finalmente, the origin of the TurkCorpus set itself could explain some
of these results. According to Xu et al. (2016), the participants performing the simpli-
fications were instructed to mostly produce paraphrases, eso es, mostly replacements
with virtually no deletions. Tal como, copying is a significant operation and, por lo tanto,
models that are good at performing it reflect better the characteristics of the human
simplifications in this data set.
6. Conclusiones y direcciones futuras
In this article we presented a survey of research in Text Simplification, focusing on mod-
els that perform the task at sentence-level. We limited our review to models that learn
to produce simplifications by using parallel corpora of original-simplified sentences.
We reviewed the main resources exploited by these approaches, detailed how models
are trained using these data sets, and explained how they are evaluated. Finalmente, nosotros
compared several SS models using standard overall-performance metrics, and proposed
a new operation-specific method for qualifying the simplification transformations that
each SS model performs. The former analysis provided us with insights about the sim-
plification capabilities of each approach, which help better explain the initial automatic
puntuaciones. Based on our review, we suggest the following as areas that are worth exploring.
Corpora Diversity. Most data sets used in data-driven SS research are based on EW and
SEW. Its quality has been questioned (mira la sección 2.1), but its public availability and
shareability makes it popular for research purposes. The Newsela corpus offers the
advantage of being produced by professionals, which ensures a higher quality across
all texts available. Sin embargo, the fact that common splits of the data cannot be publicly
shared hinders the development and objective comparison of models that use it. Nosotros
believe that our research area would benefit from data sets that combine the positive
features of both: high-quality professionally produced data that can be publicly shared.
Además, it would be desirable that these new data sets be as diverse as possible
in terms of application domains, target audiences, and text transformations realized.
Finalmente, it would also be valuable to follow Xu et al. (2016) by collecting multiple
simplification references per simplification, for a fairer evaluation.
Explanation Generation. Even though most current SS approaches do not focus on specific
simplification transformations, it is safe to say that they tackle the four main ones:
deletion, substitution, reordering, and splitting (ver tabla 7). Sin embargo, by definition,
simplifying a text could also involve further explaining complex terms or concepts. Este
is not merely replacing a word or phrase for a simpler synonym or its definition, but to
elaborate on the concept in a natural way that keeps the text grammatical, is meaning
preserving, and is simple. This is an important research area in SS where limited work
has been published (Damay et al. 2006; Watanabe et al. 2009; Kandula, Curtis, and Zeng-
Treitler 2010; Eom, Dickinson, and Sachs 2012).
Personalized Simplification. All SS approaches reviewed in this article are general purpose,
eso es, without a specific target audience. This is because current SS research focuses
177
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
on how to learn the simplification operations that are realized in the corpus being
usado, and not on the end-user of the model’s output. The simplification needs of a
non-native speaker are different from those of a person with autism or with a low-
literacy level. One possible solution could be to create target-audience-specific corpora
to learn from. Sin embargo, even within the same target group, individuals have specific
simplification needs and preferences. We believe it would be meaningful to develop
approaches that are capable of handling the specific needs of its user, and possibly learn
from its interactions as a way to generate more helpful simplifications for that particular
persona.
Document-level Approaches. Most TS models focus on simplifying sentences individually,
and there is little research on tackling the problem with a document-level perspective.
Woodsend and Lapata (2011b) and Mandya, Nomoto, and Siddharthan (2014) producir
simplifications at the sentence-level and try to globally optimize readability scores or
length of the document. Sin embargo, Siddharthan (2003) points out that syntactic alter-
ations to sentences (especially, splitting) can affect the rhetorical relations between them,
which can only be resolved going beyond sentence boundaries. This is an exciting area
of research, since simplifying a complete document is a more real use-case scenario
for a simplification model. This line of research should begin with identifying what
makes document simplification different from sentence simplification. It is likely that
transformations that span multiple sentences are performed, which could never be
tackled by a sentence-level model. Además, proper corpora should be curated for
training and testing of data-driven models, and new evaluation methodologies should
be devised. The Newsela corpus is a resource that could be exploited in this regard.
Hasta ahora, it has only been used for sentence-level TS, even though it contains original-
simplified aligned documents, with versions in several simplification levels.
Sentence Joining. Most current SS models perform sentence compression, in that they
may delete part of the content of a sentence that could be regarded as unimportant.
Sin embargo, as presented in Section 1.2, studies have shown that humans tend to join sen-
tences together while simplifying a text, and perform a form of abstractive summariza-
ción. No state-of-the-art TS model considers this type of operation while transforming a
texto, perhaps because they only process one sentence at a time. Incorporating sentence
joining could help in developing a document-level perspective into current TS systems.
Simplification Evaluation. For automatic evaluation of SS models, there are currently
only two simplification-specific metrics: SARI (focused on paraphrasing) and SAMSA
(focused on sentence splitting). Sin embargo, as mentioned in Section 1.2, humans per-
form several more transformations that we are not currently measured when assessing
a model’s output. The transformation-specific evaluation presented in this article is
merely a method for better understanding what the SS models are doing, but it is not a
metric in its whole sense. We believe that more work needs to be done in improving how
we evaluate and compare SS models automatically. Research on Quality Estimation has
shown promising results on using reference-less metrics to evaluate generated outputs,
allowing the automatic assessment to speed-up and scale. This line of work has started
to be applied for simplification (ˇStajner et al. 2016; Martin et al. 2018), and we believe it
needs to be explored further. Además, human-based evaluation has been limited to
three criteria: grammaticality, preservación del significado, and simplicity. Are these criteria
suficiente? Would they still be relevant if we moved to a document-level perspective?
178
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Would assessing the usefulness of the simplifications for target users (Mandya, Nomoto,
and Siddharthan 2014) be a more reliable quality measure? We believe these are ques-
tions that need to be addressed.
Text Simplification is a research area with significant application potential. It can
have a meaningful impact in people’s lives and help create a more inclusive society.
With the development of new Natural Language Processing technologies (especially
neural-based models), it is starting to receive more attention in recent years. Sin embargo,
there are still several open questions that pose challenges to our research community.
We hope that this article has helped provide an understanding of what has been done
so far in the area and, more importantly, has motivated more people to advance the
current state of the art.
Referencias
Abend, Omri and Ari Rappoport. 2013.
Universal conceptual cognitive annotation
(UCCA). In Proceedings of the 51st Annual
Meeting of the Association for Computational
Lingüística (Volumen 1: Artículos largos),
pages 228–238, Sofia.
Aharoni, Roee and Yoav Goldberg. 2018.
Split and rephrase: Better evaluation and
stronger baselines. En Actas de la
56ª Reunión Anual de la Asociación de
Ligüística computacional (Volumen 2: Short
Documentos), pages 719–724, Melbourne.
Alu´ısio, Sandra M., Lucia Specia, Thiago
A. S. Pardo, Erick G. Maziero, Helena M.
Caseli, and Renata P. METRO. Fortes. 2008. A
corpus analysis of simple account texts
and the proposal of simplification
estrategias: First steps towards text
simplification systems. En Actas de la
26th Annual ACM International Conference
on Design of Communication, SIGDOC ’08,
pages 15–22, Lisbon.
Alva-Manchego, Fernando, Joachim Bingel,
Gustavo Paetzold, Carolina Scarton,
and Lucia Specia. 2017. Learning how to
simplify from explicit labeling of complex-
simplified text pairs. En Actas de la
Eighth International Joint Conference on
Natural Language Processing (Volumen 1: Largo
Documentos), pages 295–305, Taipéi.
Alva-Manchego, Fernando, Louis Martin,
Carolina Scarton, and Lucia Specia. 2019.
EASSE: Easier Automatic Sentence
Simplification Evaluation. En procedimientos
del 2019 Conferencia sobre métodos empíricos
in Natural Language Processing and the 9th
International Joint Conference on Natural
Procesamiento del lenguaje (EMNLP-IJCNLP):
Demostraciones del sistema, pages 49–54,
Hong Kong.
Amancio, Marcelo and Lucia Specia. 2014.
An Analysis of Crowdsourced Text
Simplifications. In Third Workshop on
Predicting and Improving Text Readability for
Target Reader Populations, PITR 2014,
pages 123–130, Gothenburg.
Ambati, Bharat Ram, Siva Reddy, y
Marcos Steedman. 2016. Assessing relative
sentence complexity using an incremental
CCG parser. En Actas de la 2016
Conference of the North American Chapter of
la Asociación de Lingüística Computacional:
Tecnologías del lenguaje humano,
pages 1051–1057, San Diego, California.
casa de arte, Mikel, Gorka Lavaka, y eneko
aguirre. 2018. Unsupervised statistical
machine translation. En Actas de la
2018 Conference on Empirical Methods in
Natural Language Processing,
pages 3632–3642, Bruselas.
casa de arte, Mikel, Gorka Lavaka, Eneko Agirre,
and Kyunghyun Cho. 2018. Unsupervised
neural machine translation. En procedimientos
of the 6th International Conference on
Learning Representations, vancouver.
Bach, Nguyen, Qin Gao, Stephan Vogel, y
Alex Waibel. 2011. TriS: A statistical
sentence simplifier with log-linear models
and margin-based discriminative training.
In Proceedings of 5th International Joint
Conferencia sobre procesamiento del lenguaje natural,
pages 474–482, Chiang Mai.
Bahdanau, Dzmitry, Kyunghyun Cho, y
Yoshua Bengio. 2014. Neural machine
translation by jointly learning to align and
translate. CORR, abs/1409.0473.
Barzilay, Regina and Noemie Elhadad. 2003.
Sentence alignment for monolingual
comparable corpora. En Actas de la
2003 Conference on Empirical Methods in
Natural Language Processing, EMNLP ’03,
pages 25–32, Stroudsburg, Pensilvania.
Belinkov, Yonatan, Nadir Durrani, Fahim Dalvi,
Hassan Sajjad, and James Glass. 2017. Qué
do neural machine translation models
learn about morphology? En procedimientos de
the 55th Annual Meeting of the Association for
Ligüística computacional (Volumen 1: Largo
Documentos), pages 861–872, vancouver.
179
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Bingel, Joachim, Maria Barrett, and Sigrid
Klerke. 2018. Predicting misreadings from
gaze in children with reading difficulties.
In Proceedings of the Thirteenth Workshop on
Innovative Use of NLP for Building
Educational Applications, pages 24–34, Nuevo
Orleans, LA.
Bingel, Joachim, Gustavo Paetzold, y
Anders Sogaard. 2018. Lexi: A tool for
adaptive, personalized text simplification.
In Proceedings of the 27th International
Congreso sobre Lingüística Computacional,
pages 245–258, Santa Fe, NM.
Bingel, Joachim and Anders Søgaard. 2016.
Text simplification as tree labeling. En
Proceedings of the 54th Annual Meeting of the
Asociación de Lingüística Computacional
(Volumen 2: Artículos breves), pages 337–343,
Berlina.
Biran, O, Samuel Brody, and Noemie
Elhadad. 2011. Putting it simply: A
context-aware approach to lexical
simplification. In Proceedings of the 49th
Reunión Anual de la Asociación de
Ligüística computacional: Human Language
Technologies, pages 496–501, Portland, O.
Botha, Jan A., Manaal Faruqui, John Alex,
Jason Baldridge, and Dipanjan Das. 2018.
Learning to split and rephrase from Wikipedia
edit history. En Actas de la 2018
Jornada sobre Métodos Empíricos en Natural
Procesamiento del lenguaje, pages 732–737, Bruselas.
Bott, Stefan and Horacio Saggion. 2011a.
Spanish text simplification: An exploratory
estudiar. Procesamiento del Lenguaje Natural,
47:87–95.
Bott, Stefan and Horacio Saggion. 2011b. Un
unsupervised alignment algorithm for text
simplification corpus construction. En
Proceedings of the Workshop on Monolingual
Text-To-Text Generation, MTTG ’11,
pages 20–26, Stroudsburg, Pensilvania.
Bott, Stefan, Horacio Saggion, and Simon
Mille. 2012. Text simplification tools for
Español. In Proceedings of the Eight
International Conference on Language
Resources and Evaluation, LREC’12,
pages 1665–1671, Istanbul.
Bowman, Samuel R., Gabor Angeli,
Christopher Potts, and Christopher D.
Manning. 2015. A large annotated corpus
for learning natural language inference. En
Actas de la 2015 Conferencia sobre
Empirical Methods in Natural Language
Procesando, pages 632–642, Lisbon.
Brunato, Dominique, Felice Dell’Orletta,
Giulia Venturi, and Simonetta
Montemagni. 2015. Design and annotation
of the first Italian corpus for text
simplification. In Proceedings of the 9th
180
Linguistic Annotation Workshop, LAW IX,
pages 31–41, Denver, CO.
Candido Jr., Arnaldo, Erick Maziero,
Caroline Gasperin, Thiago A. S. Pardo,
Lucia Specia, and Sandra M. Aluisio. 2009.
Supporting the adaptation of texts for poor
literacy readers: A text simplification editor
for Brazilian Portuguese. En procedimientos de
the Fourth Workshop on Innovative Use of
NLP for Building Educational Applications,
BEA ’09, pages 34–42, Roca, CO.
Carroll, John, Guido Minnen, Yvonne
Canning, Siobhan Devlin, and John Tait.
1998. Practical simplification of English
newspaper text to assist aphasic readers.
In Proceedings of AAAI-98 Workshop on
Integrating Artificial Intelligence and Assistive
Tecnología, pages 7–10, Madison, Wisconsin.
Caseli, Helena M., Tiago F. Pereira, Lucia
Specia, Thiago A. S. Pardo, Caroline
Gasperin, and Sandra M. Aluisio. 2009.
Building a Brazilian Portuguese parallel
corpus of original and simplified texts.
In Proceedings of the 10th Conference on
Intelligent Text Processing and Computational
Lingüística, pages 59–70, México.
Chandrasekar, r., Cristina Doran, y B.
Srinivas. 1996. Motivations and methods
for text simplification. En Actas de la
16th Conference on Computational Linguistics,
COLING ’96, pages 1041–1044, Copenhague.
Chiang, David. 2006. An introduction to
synchronous grammars. Tutorial at ACL
2006. Available at http://www3.nd.edu/
~dchiang/papers/synchtut.pdf.
Cohn, Trevor and Mirella Lapata. 2009. Oración
compression as tree transduction. Diario de
Artificial Intelligence Research, 34:637–674.
Cohn, Trevor and Mirella Lapata. 2013. Un
abstractive approach to sentence compression.
ACM Transactions on Intelligent Systems and
Tecnología, 4(3):41:1–41:35.
Coster, William and David Kauchak. 2011a.
Learning to simplify sentences using
Wikipedia. In Proceedings of the Workshop
on Monolingual Text-To-Text Generation,
MTTG ’11, pages 1–9, Portland, O.
Coster, William and David Kauchak. 2011b.
Simple English Wikipedia: A new text
simplification task. En Actas de la
49ª Reunión Anual de la Asociación de
Ligüística computacional: Human Language
Technologies: Artículos breves – Volumen 2,
HLT ’11, pages 665–669, Stroudsburg, Pensilvania.
Crammer, Koby and Yoram Singer. 2003.
Ultraconservative Online Algorithms for
Multiclass Problems. Journal of Machine
Investigación del aprendizaje, 3:951–991.
crossley, Scott A., Max M. Louwerse,
Philip M. McCarthy, and Danielle S.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
McNamara. 2007. A linguistic analysis of
simplified and authentic texts. The Modern
Language Journal, 91(1):15–30.
Curran, James R., Stephen Clark, and Johan
jefe. 2007. Linguistically motivated
large-scale NLP with C&C and Boxer. En
Proceedings of the 45th Annual Meeting of the
ACL on Interactive Poster and Demonstration
Sessions, ACL ’07, pages 33–36, Prague.
Damay, Jerwin Jan S., Gerard Jaime D. Lojico,
Kimberly Amanda L. Lu, Dex B. Tarantan,
and Ethel C. Ong. 2006. SIMTEXT text simp-
lification of medical literature. En procedimientos
of the 3rd National Natural Language Processing
Symposium – Building Language Tools and
Recursos, pages 34–38, Manila.
De Belder, Jan and Marie-Francine Moens.
2010. Text simplification for children. En
Proceedings of the SIGIR 2010 Workshop on
Accessible Search Systems, pages 19–26,
Geneva.
Denkowski, Michael and Alon Lavie. 2014.
Meteor universal: Language specific
translation evaluation for any target
idioma. In Proceedings of the EACL 2014
Workshop on Statistical Machine Translation,
pages 376–380, baltimore, Maryland.
Devlin, Siobhan and John Tait. 1998. El
use of a psycholinguistic database in
the simplification of text for aphasic
readers. Linguistic Databases, 161–173,
stanford, California.
Eisner, Jason. 2003. Learning non-isomorphic
tree mappings for machine translation. En
Actas de la 41ª Reunión Anual de la
Asociación de Lingüística Computacional –
Volumen 2, ACL ’03, pages 205–208, Sapporo.
Eom, Soojeong, Markus Dickinson, y
Rebecca Sachs. 2012. Sense-specific lexical
information for reading assistance. En
Proceedings of the Seventh Workshop on
Building Educational Applications Using
NLP, pages 316–325, Montr´eal.
evans, Ricardo, Constantin Orasan, y
Iustin Dornescu. 2014. An evaluation of
syntactic simplification rules for people
with autism. In Proceedings of the 3rd
Workshop on Predicting and Improving Text
Readability for Target Reader Populations,
PIT 2014, pages 131–140, Gothenburg.
evans, Richard J. 2011. Comparing methods
for the syntactic simplification of sentences
in information extraction. Literary and
Linguistic Computing, 26(4):371–388.
Feblowitz, Dan and David Kauchak. 2013.
Sentence simplification as tree transduction.
In Proceedings of the Second Workshop on
Predicting and Improving Text Readability for
Target Reader Populations, pages 1–10,
Sofia.
Filippova, Katja and Michael Strube. 2008.
Dependency tree based sentence compression.
In Proceedings of the Fifth International Natural
Conferencia de Generación de Lenguas, INLG ’08,
pages 25–32, Stroudsburg, Pensilvania.
Flesch, Rudolph. 1948. A new readability
yardstick. Journal of Applied Psychology,
32(3):221.
Ganitkevitch, Juri, Benjamin Van Durme, y
Chris Callison Burch. 2013. PPDB: El
paraphrase database. En procedimientos de
NAACL-HLT, pages 758–764, Atlanta, Georgia.
Gardent, Claire, Anastasia Shimorina, Shashi
Narayan, and Laura Perez-Beltrachini. 2017.
Creating training corpora for NLG micro-
planners. In Proceedings of the 55th Annual
Meeting of the Association for Computational
Lingüística (Volumen 1: Artículos largos),
pages 179–188, vancouver.
Glavaˇs, Goran and Jan ˇSnajner. 2015.
Construction and evaluation of event
graphs. Natural Language Engineering,
21(4):607–652.
Glavaˇs, Goran and Sanja ˇStajner. 2013.
Event-centered simplification of news
stories. In Proceedings of the Student
Research Workshop associated with RANLP
2013, pages 71–78, Hissar.
Glavaˇs, Goran and Sanja ˇStajner. 2015.
Simplifying lexical simplification: Do we
need simplified corpora? En procedimientos de
the 53rd Annual Meeting of the Association
for Computational Linguistics and the 7th
International Joint Conference on Natural
Procesamiento del lenguaje (Volumen 2: Short
Documentos), pages 63–68, Beijing.
Gonzalez-Dios, Itziar, Mar´ıa Jes ´us Aranzabe,
Arantza D´ıaz de Ilarraza, and Haritz Salaberri.
2014. Simple or complex? Assessing the
readability of basque texts. En procedimientos
of COLING 2014, the 25th International
Congreso sobre Lingüística Computacional:
Technical Papers, pages 334–344, Dublín.
Goodfellow, Ian, Jean Pouget-Abadie, Mehdi
Mirza, Bing Xu, David Warde-Farley,
Sherjil Ozair, Aaron Courville, y yoshua
bengio. 2014. Generative adversarial nets.
In Z. Ghahramani, METRO. Welling, C. Cortes,
norte. D. lorenzo, and K. q. Weinberger,
editores, Advances in Neural Information
Sistemas de procesamiento 27. Asociados Curran,
Cª, pages 2672–2680.
Goto, Isao, Hideki Tanaka, and Tadashi
Kumano. 2015. Japanese news
simplification: Task design, data set
construction, and analysis of simplified
texto. In Proceedings of Machine Translation
Summit XV, volumen. 1: MT Researchers’ Track,
pages 17–31, Miami, Florida.
181
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Gu, Jiatao, Zhengdong Lu, Hang Li, y
Victor O.K. li. 2016. Incorporating copying
mechanism in sequence-to-sequence
aprendiendo. In Proceedings of the 54th Annual
Meeting of the Association for Computational
Lingüística (Volumen 1: Artículos largos),
pages 1631–1640, Berlina.
guo, Han, Ramakanth Pasunuru, and Mohit
Bansal. 2018. Dynamic multi-level
multi-task learning for sentence
simplification. In Proceedings of the 27th
International Conference on Computational
Lingüística, pages 462–476, Santa Fe, NM.
Hasler, Eva, Adri de Gispert, Felix Stahlberg,
Aurelien Waite, and Bill Byrne. 2017.
Source sentence simplification for
statistical machine translation. Computadora
Discurso & Idioma, 45(C):221–235.
Heilman, Michael and Noah A. Herrero. 2010.
Extracting simplified statements for
factual question generation. En procedimientos
of the Third Workshop on Question Generation,
pages 11–20, pittsburgh, Pensilvania.
Hershcovich, Daniel, Noche de Omrí, and Ari
Rappoport. 2017. A transition-based directed
acyclic graph parser for UCCA. En procedimientos
of the 55th Annual Meeting of the Association
para Lingüística Computacional (Volumen 1:
Artículos largos), pages 1127–1138, vancouver.
Hochreiter, Sepp and J ¨urgen Schmidhuber.
1997. Memoria larga a corto plazo. Neural
Cálculo, 9(8):1735–1780.
Howcroft, David M.. and Vera Demberg.
2017. Psycholinguistic models of sentence
processing improve sentence readability
ranking. In Proceedings of the 15th Conference
of the European Chapter of the Association for
Ligüística computacional: Volumen 1, Largo
Documentos, pages 958–968, Valencia.
Hwang, William, Hannaneh Hajishirzi, Mari
Ostendorf, and Wei Wu. 2015. Aligning
sentences from standard Wikipedia to
simple Wikipedia. En Actas de la
2015 Conference of the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
pages 211–217, Denver, CO.
Jaccard, Pablo. 1912. The distribution of the
flora in the alpine zone. The New Phytologist,
11(2):37–50.
Jing, Hongyan. 2000. Sentence reduction for
automatic text summarization. En
Proceedings of the Sixth Conference on Applied
Natural Language Processing, ANLC ’00,
pages 310–315, Stroudsburg, Pensilvania.
Johnson, Melvin, Mike Schuster, Quoc V. Le,
Maxim Krikun, Yonghui Wu, Zhifeng
Chen, Nikhil Thorat, Fernanda Vi´egas,
Martin Wattenberg, Greg Corrado,
Macduff Hughes, and Jeffrey Dean. 2017.
182
Google’s multilingual neural machine
translation system: Enabling zero-shot
traducción. Transacciones de la Asociación
para Lingüística Computacional, 5:339–351.
Kajiwara, Tomoyuki and Mamoru Komachi.
2016. Building a monolingual parallel
corpus for text simplification using
sentence similarity based on alignment
between word embeddings. En procedimientos
of COLING 2016, the 26th International
Congreso sobre Lingüística Computacional:
Technical Papers, pages 1147–1158, Osaka.
Kandula, Sasikiran, Dorothy Curtis, and Qing
Zeng-Treitler. 2010. A semantic and syntactic
text simplification tool for health content.
In AMIA Annual Symposium Proceedings,
pages 366–370, Washington, corriente continua.
Kauchak, David. 2013. Improving text
simplification language modeling using
unsimplified text data. En Actas de la
51st Annual Meeting of the Association for
Ligüística computacional (Volumen 1: Largo
Documentos), pages 1537–1546, Sofia.
Kincaid, j. PAG., R. PAG. Fishburne, R. l. Rogers,
y B. S. Chissom. 1975. Derivation of new
readability formulas (automated readability
índice, fog count and Flesch reading ease
formula) for Navy enlisted personnel,
Technical Report 8–75, Chief of Naval
Technical Training: Naval Air Station
Menfis.
Klaper, David, Sarah Ebling, and Martin
Volk. 2013. Building a German/simple
German parallel corpus for automatic text
simplification. In Proceedings of the Second
Workshop on Predicting and Improving Text
Readability for Target Reader Populations,
pages 11–19, Sofia.
Klebanov, Beata Beigman, Kevin Knight, y
Daniel Marcu. 2004. Text simplification
for information-seeking applications. En
Proceedings of On the Move to Meaningful
Internet Systems 2004: CoopIS, DOA, y
ODBASE, LNCS, number 3290, Saltador
Berlin Heidelberg, Berlin Heidelberg,
pages 735–747.
Klein, Guillaume, Yoon Kim, Yuntian Deng,
Jean Senellart, and Alexander M. Rush.
2017. OpenNMT: Open-source toolkit for
neural machine translation. CORR,
abs/1701.02810.
Klerke, Sigrid and Anders Søgaard. 2012.
DSIM, a Danish parallel corpus for text
simplification. In Proceedings of the Eight
International Conference on Language
Resources and Evaluation, LREC’12,
pages 4015–4018, Istanbul.
Koehn, Philipp, Hieu Hoang, alejandra
Birch, Chris Callison Burch, Marcello
Federico, Nicola Bertoldi, Brooke Cowan,
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Wade Shen, Christine Moran, Ricardo
Zens, Chris Dyer, Ondˇrej Bojar, alejandra
Constantin, and Evan Herbst. 2007. Moses:
Open source toolkit for statistical machine
traducción. In Proceedings of the 45th
Annual Meeting of the ACL on Interactive
Poster and Demonstration Sessions, ACL ’07,
pages 177–180, Stroudsburg, Pensilvania.
lin, Chin Yew. 2004. ROUGE: A package for
automatic evaluation of summaries. En
Workshop on Text Summarization Branches
Out, pages 74–81, Barcelona.
Luong, Thang, Hieu Pham, and Christopher
D. Manning. 2015. Effective approaches to
attention-based neural machine translation.
En Actas de la 2015 Conferencia sobre
Empirical Methods in Natural Language
Procesando, pages 1412–1421, Lisbon.
Mallinson, Jonathan, Rico Sennrich, y
Mirella Lapata. 2017. Paraphrasing
revisited with neural machine translation.
In Proceedings of the 15th Conference of the
European Chapter of the Association for
Ligüística computacional: Volumen 1, Largo
Documentos, pages 881–893, Valencia.
Mandya, Angrosh, Tadashi Nomoto, y
Advaith Siddharthan. 2014. Lexico-syntactic
text simplification and compression with
typed dependencies. En procedimientos de
COLECCIONAR 2014, the 25th International
Congreso sobre Lingüística Computacional:
Technical Papers, pages 1996–2006,
Dublín.
Martín, luis, Samuel Humeau,
Pierre-Emmanuel Mazar´e, ´Eric
de La Clergerie, Antonio Bordes, y
Benoˆıt Sagot. 2018. Reference-less quality
estimation of text simplification systems.
In Proceedings of the 1st Workshop on
Automatic Text Adaptation (ATA),
pages 29–38, Tilburg.
Mason, Jana M. and Janet R. Kendall. 1978.
Facilitating reading comprehension
through text structure manipulation, Bolt,
Beranek and Newman, Cª, Cambridge,
MAMÁ; Illinois University, Urbana. Center for
the Study of Reading.
McNamara, Danielle S., Arthur C. Graesser,
Philip M. McCarthy, and Zhiqiang Cai.
2014. Automated Evaluation of Text and
Discourse with Coh-Metrix. Cambridge
Prensa universitaria, Nueva York, Nueva York.
Mcnamee, Paul and James Mayfield. 2004.
Character n-gram tokenization for
European language text retrieval.
Information Retrieval, 7(1–2):73–97.
Mikolov, Tomas, Kai Chen, Greg Corrado,
and Jeffrey Dean. 2013. Efficient estimation
of word representations in vector space.
In Proceedings of Workshop at 2013
International Conference on Learning
Representaciones, Scottsdale, AZ.
Mirkin, Shachar, Sriram Venkatapathy, y
Marc Dymetman. 2013. Confidence-
driven rewriting for improved transla-
ción. In XIV MT Summit, pages 257–264,
Nice.
Mishra, Kshitij, Ankush Soni, Rahul Sharma,
and Dipti Sharma. 2014. Exploring the
effects of sentence simplification on
Hindi to English machine translation
sistema. In Proceedings of the Workshop on
Automatic Text Simplification – Methods and
Applications in the Multilingual Society
(ATS-MA 2014), pages 21–29,
Dublín.
Munkhdalai, Tsendsuren and Hong Yu. 2017.
Neural semantic encoders. En procedimientos de
the 15th Conference of the European Chapter of
la Asociación de Lingüística Computacional:
Volumen 1, Artículos largos, pages 397–407,
Valencia.
Napoles, Courtney and Mark Dredze. 2010.
Learning simple Wikipedia: A cogitation
in ascertaining abecedarian language. En
Proceedings of the NAACL HLT 2010
Workshop on Computational Linguistics
and Writing: Writing Processes and Authoring
Aids, pages 42–50, Los Angeles, California.
Narayan, Shashi and Claire Gardent. 2014.
Hybrid simplification using deep
semantics and machine translation. En
Proceedings of the 52nd Annual Meeting of the
Asociación de Lingüística Computacional
(Volumen 1: Artículos largos), pages 435–445,
baltimore, Maryland.
Narayan, Shashi and Claire Gardent. 2016.
Unsupervised sentence simplification
using deep semantics. En Actas de la
9th International Natural Language
Generation conference, pages 111–120,
Edimburgo.
Narayan, Shashi, Claire Gardent, Shay B..
cohen, and Anastasia Shimorina. 2017.
Split and rephrase. CORR, abs/1707.06971.
Niklaus, Christina, Bernhard Bermeitinger,
Siegfried Handschuh, and Andr´e Freitas.
2016. A sentence simplification system for
improving relation extraction. En
Proceedings of COLING 2016, the 26th
International Conference on Computational
Lingüística: Demostraciones del sistema,
pages 170–174, Osaka.
Nisioi, Sergiu, Sanja ˇStajner, Simone Paolo
Ponzetto, and Liviu P. Dinu. 2017.
Exploring neural text simplification
modelos. In Proceedings of the 55th Annual
Meeting of the Association for Computational
Lingüística (Volumen 2: Artículos breves),
pages 85–91, vancouver.
183
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Och, Franz Josef and Hermann Ney. 2004.
The alignment template approach to
statistical machine translation. computacional
Lingüística, 30(4):417–449.
Ogden, Charles Kay. 1930. Basic English: A
General Introduction with Rules and Grammar.
Kegan Paul, Trench, Trubner & Co.
Paetzold, Gustavo and Lucia Specia. 2013.
Text simplification as tree transduction. En
Proceedings of the 9th Brazilian Symposium in
Information and Human Language
Tecnología, pages 116–125, Fortaleza.
Paetzold, Gustavo and Lucia Specia. 2017a.
Lexical simplification with neural
ranking. In Proceedings of the 15th
Conference of the European Chapter of the
Asociación de Lingüística Computacional:
Volumen 2, Artículos breves, pages 34–40,
Valencia.
Paetzold, Gustavo H., Fernando Alva-Manchego,
and Lucia Specia. 2017. Massalign: Alignment
and annotation of comparable documents.
In Proceedings of the IJCNLP 2017, Sistema
Demonstrations, pages 1–4, Taipéi.
Paetzold, Gustavo H. and Lucia Specia.
2017b. A survey on lexical simplification.
Journal of Artificial Intelligence Research,
60:549–593.
Paetzold, Gustavo Henrique. 2016. Lexical
Simplification for Non-Native English
Speakers. Doctor. tesis, Universidad de
Sheffield, Sheffield, Reino Unido.
Paetzold, Gustavo Henrique and Lucia
Specia. 2016. Vicinity-driven paragraph
and sentence alignment for comparable
corpus. CORR, abs/1612.04113.
Papineni, Kishore, Salim Roukos, Todd
Ward, y Wei-Jing Zhu. 2002. AZUL: A
method for automatic evaluation of
machine translation. En Actas de la
40th Annual Meeting on Association for
Ligüística computacional, ACL ’02,
páginas 311–318, Filadelfia, Pensilvania.
Pavlick, Ellie and Chris Callison-Burch. 2016.
Simple PPDB: A paraphrase database for
simplification. In Proceedings of the 54th
Reunión Anual de la Asociación de
Ligüística computacional (Volumen 2: Short
Documentos), pages 143–148, Berlina.
Petersen, Sarah E. 2007. Natural Language
Processing Tools for Reading Level
Assessment and Text Simplification for
Bilingual Education. Doctor. tesis,
University of Washington, AAI3275902.
Petersen, Sarah E. and Mari Ostendorf. 2007.
Text simplification for language learners: A
corpus analysis. In Proceedings of the Speech
and Language Technology for Education
Taller, SLaTE 2007, pages 69–72,
Farmington, Pensilvania.
184
Correo, Mate. 2018. A call for clarity in
reporting BLEU scores. En Actas de la
Third Conference on Machine Translation:
Research Papers, páginas 186–191,
Bruselas.
Correo, Mate, Juri Ganitkevitch, Luke Orland,
Jonathan Weese, Yuan Cao, and Chris
Callison-Burch. 2013. Joshua 5.0: Sparser,
mejor, faster, server. En Actas de la
Eighth Workshop on Statistical Machine
Translation, pages 206–212, Sofia.
Quigley, S. PAG., D. Fuerza, y M. Steinkamp.
1977. The language structure of deaf
niños. The Volta Review, 79(2):73–84.
Ranzato, Marc’Aurelio, Sumit Chopra,
Michael Auli, and Wojciech Zaremba.
2016. Sequence level training with
recurrent neural networks. In 4th
International Conference on Learning
Representaciones, ICLR 2016, San Juan.
Reiter, Aod. 2018. A structured review of
the validity of BLEU. computacional
Lingüística, 44(3):393–401.
Rello, Luz, Ricardo Baeza-Yates, laura
Dempere-Marco, and Horacio Saggion.
2013a. Frequent words improve
readability and short words improve
understandability for people with
dyslexia. In Human-Computer Interaction –
INTERACT 2013: 14th IFIP TC 13
International Conference, pages 203–219,
Ciudad del Cabo.
Rello, Luz, Clara Bayarri, Azuki G `orriz,
Ricardo Baeza-Yates, Saurabh Gupta,
Gaurang Kanvinde, Horacio Saggion,
Stefan Bott, Roberto Carlini, and Vasile
Topac. 2013b. “Dyswebxia 2.0!: Más
accessible text for people with dyslexia.”
In Proceedings of the 10th International
Cross-Disciplinary Conference on Web
Accessibility, W4A ’13, paginas 25:1–25:2,
Río de Janeiro.
robbins, norte. l. and C. Hatcher. 1981. El
effects of syntax on the reading
comprehension of hearing-impaired
niños. The Volta Review, 83(2):105–115.
Saggion, Horacio. 2017. Automatic text
simplification. Synthesis Lectures on Human
Language Technologies, 10(1):1–137.
Scarton, Carolina, Gustavo H. Paetzold, y
Lucia Specia. 2018a. SimPA: A
sentence-level simplification corpus for the
public administration domain. En
Proceedings of the Eleventh International
Conference on Language Resources and
Evaluation (LREC 2018), pages 4333–4338,
Miyazaki.
Scarton, Carolina, Gustavo H. Paetzold, y
Lucia Specia. 2018b. Text simplification
from professionally produced corpora.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
In Proceedings of the Eleventh International
Conference on Language Resources and
Evaluation (LREC 2018), pages 3504–3510,
Miyazaki.
Scarton, Carolina and Lucia Specia. 2018.
Learning simplifications for specific target
audiences. In Proceedings of the 56th Annual
Meeting of the Association for Computational
Lingüística (Volumen 2: Artículos breves),
pages 712–718, Melbourne.
Ver, Abigail, Peter J. Liu, and Christopher D.
Manning. 2017. Get to the point:
Summarization with pointer-generator
redes. In Proceedings of the 55th Annual
Meeting of the Association for Computational
Lingüística (Volumen 1: Artículos largos),
pages 1073–1083, vancouver.
Sennrich, Rico, Orhan Firat, Kyunghyun
Dar, Alexandra Birch, Barry Haddow,
Julian Hitschler, Marcin
Junczys-Dowmunt, Samuel L´’aubli,
Antonio Valerio Miceli Barone, Jozef
Mokry, and Maria Nadejde. 2017.
Nematus: A toolkit for neural machine
traducción. In Proceedings of the Software
Demonstrations of the 15th Conference of the
European Chapter of the Association for
Ligüística computacional, pages 65–68,
Valencia.
Shardlow, Matthew. 2014. A survey of
automated text simplification. Internacional
Journal of Advanced Computer Science and
Aplicaciones (IJACSA), Special Issue on
Natural Language Processing 2014,
pages 58–70, West Yorkshire, Reino Unido.
Shewan, Cynthia M. 1985. Auditory
comprehension problems in adult aphasic
individuos. Human Communication Canada,
9(5):151–155.
Siddharthan, Advaith. 2003. Preserving
discourse structure when simplifying text.
En Actas de la 2003 European Natural
Language Generation Workshop, ENLG 2003,
pages 103–110, Budapest.
Siddharthan, Advaith. 2011. Texto
simplification using typed dependencies:
A comparison of the robustness of
different generation strategies. En
Proceedings of the 13th European Workshop on
Generación de lenguaje natural, ENLG ’11,
pages 2–11, Stroudsburg, Pensilvania.
Siddharthan, Advaith. 2014. A survey of
research on text simplification. ITL –
International Journal of Applied Linguistics,
165(2):259–298.
Siddharthan, Advaith, Ani Nenkova, y
Kathleen McKeown. 2004. Syntactic
simplification for improving content
selection in multi-document
summarization. In Proceedings of the 20th
International Conference on Computational
Lingüística, COLING ’04, pages 896–902,
Geneva.
Silveira, Sara Botelho and Antnio Branco.
2012. Enhancing multi-document
summaries with sentence simplificatio. En
Proceedings of the 14th International
Conferencia sobre Inteligencia Artificial, ICAI
2012, pages 742–748, Las Vegas, NV.
Simple Wikipedia. 2017a. Wikipedia: Cómo
write Simple English pages. From https://
simple.wikipedia.org/wiki/Wikipedia:
How to write Simple English pages.
Retrieved January 23, 2017.
Simple Wikipedia. 2017b. Wikipedia:
Simple English Wikipedia. De
https://simple.wikipedia.org/wiki/
Wikipedia:Simple_English_Wikipedia.
Retrieved January 23, 2017.
Herrero, David A. and Jason Eisner. 2006.
Quasi-synchronous grammars: Alignment
by soft projection of syntactic dependencies.
In Proceedings of the Workshop on Statistical
Máquina traductora, StatMT ’06,
pages 23–30, Nueva York, Nueva York.
Snover, Matthew, Bonnie Dorr, Ricardo
Schwartz, Linnea Micciulla, y juan
Makhoul. 2006. A study of translation edit
rate with targeted human annotation. En
Proceedings of Association for Machine
Translation in the Americas, pages 223–231,
Cambridge, MAMÁ.
Specia, L ´ucia. 2010. Translating from complex
to simplified sentences. En Actas de la
9th International Conference on Computational
Processing of the Portuguese Language,
PROPOR’10, pages 30–39, Porto Alegre.
Specia, L ´ucia, Carolina Scarton, y
Gustavo Henrique Paetzold. 2018. Quality
estimation for machine translation.
Synthesis Lectures on Human Language
Technologies, 11(1):1–162.
Specia, L ´ucia, Sandra Maria Alu´ısio, y
Thiago A. Salgueiro Pardo. 2008. Manual
de simplificac¸ ˜ao sint´atica para o portuguˆes,
NILC–ICMC–USP, S˜ao Carlos, SP, Brasil.
Available at http://www.nilc.icmc.usp.
br/nilc/download/NILC_TR_08_06.pdf
Sulem, Elior, Noche de Omrí, and Ari
Rappoport. 2018a. BLEU is not suitable for
the evaluation of text simplification. En
Actas de la 2018 Conferencia sobre
Empirical Methods in Natural Language
Procesando, pages 738–744, Bruselas.
Sulem, Elior, Noche de Omrí, and Ari
Rappoport. 2018b. Semantic structural
evaluation for text simplification. En
Actas de la 2018 Conference of the
North American Chapter of the Association for
Ligüística computacional: Human Language
185
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 46, Número 1
Technologies, Volumen 1 (Artículos largos),
pages 685–696, Nueva Orleans, LA.
Sol, Hong and Ming Zhou. 2012. Joint
learning of a dual SMT system for
paraphrase generation. En Actas de la
50ª Reunión Anual de la Asociación de
Ligüística computacional: Artículos breves –
Volumen 2, ACL ’12, pages 38–42,
Stroudsburg, Pensilvania.
Surya, Sai, Abhijit Mishra, Anirban Laha,
Parag Jain, and Karthik Sankaranarayanan.
2019. Unsupervised neural text simplifi-
catión. In Proceedings of the 57th Annual
Meeting of the Association for Computa-
lingüística nacional, pages 2058–2068,
Florencia.
ˇStajner, Sanja, Marc Franco-Salvador,
Simone Paolo Ponzetto, Paolo Rosso, y
Heiner Stuckenschmidt. 2017. Oración
alignment methods for improving text
simplification systems. En Actas de la
55ª Reunión Anual de la Asociación de
Ligüística computacional (Volumen 2: Short
Documentos), pages 97–102, vancouver.
ˇStajner, Sanja, Marc Franco-Salvador, Paolo
Rosso, and Simone Paolo Ponzetto. 2018.
CATS: A tool for customized alignment of
text simplification corpora. En procedimientos
of the Eleventh International Conference on
Language Resources and Evaluation (LREC
2018), pages 3895–3903 Miyazaki.
ˇStajner, Sanja and Goran Glavaˇs. 2017.
Leveraging event-based semantics for
automated text simplification. Expert
Systems with Applications, 82:383–395.
ˇStajner, Sanja, Ruslan Mitkov, and Horacio
Saggion. 2014. One step closer to
automatic evaluation of text simplification
sistemas. In Proceedings of the 3rd Workshop
on Predicting and Improving Text Readability
for Target Reader Populations (PITR),
pages 1–10, Gothenburg.
ˇStajner, Sanja and Maja Popovic. 2016. Can
text simplification help machine
traducción? In Proceedings of the 19th
Annual Conference of the European
Association for Machine Translation,
pages 230–242, Riga.
ˇStajner, Sanja, Maja Popovi´c, and Hannah
B´echera. 2016. Quality estimation for text
simplification. En Actas de la
Workshop on Quality Assessment for Text
Simplification – LREC 2016, QATS 2016,
pages 15–21, Portoroˇz.
ˇStajner, Sanja, Maja Popovi´c, Horacio
Saggion, Lucia Specia, and Mark Fishel.
2016. Shared task on quality assessment
for text simplification. En Actas de la
Workshop on Quality Assessment for Text
186
Simplification – LREC 2016, QATS 2016,
pages 22–31, Portoroˇz.
Tonelli, Sara, Alessio Palmero Aprosio, y
Francesca Saltori. 2016. SIMPITIKI: A
Simplification corpus for Italian. En
Proceedings of Third Italian Conference on
Ligüística computacional (CLiC-it 2016) &
Fifth Evaluation Campaign of Natural
Language Processing and Speech Tools for
italiano. Final Workshop (EVALITA 2016),
Napoli.
Vajjala, Sowmya and Ivana Luˇci´c. 2018.
OneStopEnglish corpus: A new corpus for
automatic readability assessment and text
simplification. En Actas de la
Thirteenth Workshop on Innovative Use of
NLP for Building Educational Applications,
pages 297–304, Nueva Orleans, LA.
Vajjala, Sowmya and Detmar Meurers. 2014a.
Assessing the relative reading level of sentence
pairs for text simplification. En procedimientos
of the 14th Conference of the European Chapter
of the Association for Computational Linguistics,
pages 288–297, Gothenburg.
Vajjala, Sowmya and Detmar Meurers. 2014b.
Readability assessment for text
simplification: From analysing documents
to identifying sentential simplifications.
ITL – International Journal of Applied
Lingüística, 165(2):194–222.
Vajjala, Sowmya and Detmar Meurers. 2015.
Readability-based sentence ranking for
evaluating text simplification, Iowa State
Universidad.
Vanderwende, Lucy, Hisami Suzuki, cris
Brockett, and Ani Nenkova. 2007. Beyond
SumBasic: Task-focused summarization
with sentence simplification and lexical
expansion. Information Processing and
Management, 43(6):1606–1618.
Vaswani, Ashish, Noam Shazeer, Niki
Parmar, Jakob Uszkoreit, Leon Jones,
Aidan N.. Gómez, lucas káiser, and Illia
Polosukhin. 2017. Attention is all you
need. In I. Guyon, Ud.. V. Luxburg, S.
bengio, H.Wallach, R. Fergus, S.
Vishwanathan, y r. Garnett, editores,
Avances en el procesamiento de información neuronal
Sistemas 30, Asociados Curran, Cª,
pages 5998–6008.
Vickrey, David and Daphne Koller. 2008.
Sentence simplification for semantic role
labeling. In Proceedings of ACL-08: HLT,
pages 344–352, Columbus, OH.
Vu, Tu, Baotian Hu, Tsendsuren Munkhdalai,
and Hong Yu. 2018. Sentence simplification
with memory-augmented neural networks.
En Actas de la 2018 Conference of the
North American Chapter of the Association for
Ligüística computacional: Human Language
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Alva-Manchego, Scarton, and Specia
Data-Driven Sentence Simplification
Technologies, Volumen 2 (Artículos breves),
pages 79–85, Nueva Orleans, LA.
Watanabe, Willian Massami, Arnaldo Candido
Junior, Vin´ıcius Rodriguez Uzˆeda, Renata
Pontin de Mattos Fortes, Thiago Alexandre
Salgueiro Pardo, and Sandra Maria
Alu´ısio. 2009. Facilita: Reading assistance
for low-literacy readers. En procedimientos de
the 27th ACM International Conference on
Design of Communication, SIGDOC ’09,
pages 29–36, Bloomington, EN.
Wieting, John and Kevin Gimpel. 2018.
ParaNMT-50M: Pushing the limits of
paraphrastic sentence embeddings with
millions of machine translations. En
Proceedings of the 56th Annual Meeting of the
Asociación de Lingüística Computacional
(Volumen 1: Artículos largos), pages 451–462,
Melbourne.
williams, Adina, Nikita Nangia, and Samuel
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding
through inference. En Actas de la
2018 Conference of the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
Volumen 1 (Artículos largos), pages 1112–1122,
Nueva Orleans, LA.
williams, Ronald J. 1992. Simple statistical
gradient-following algorithms for
connectionist reinforcement learning.
Machine Learning, 8(3–4):229–256.
Woodsend, Kristian and Mirella Lapata. 2011a.
Learning to simplify sentences with quasi-
synchronous grammar and integer programming.
En Actas de la 2011 Conferencia sobre
Empirical Methods in Natural Language
Procesando, pages 409–420, Edimburgo.
Woodsend, Kristian and Mirella Lapata.
2011b. WikiSimple: Automatic simplification
of Wikipedia articles. En Actas de la
25th National Conference on Artificial Intelligence,
pages 927–932, San Francisco, California.
Wubben, Sander, Antal van den Bosch, y
Emiel Krahmer. 2012. Sentence simplification
by monolingual machine translation. En
Proceedings of the 50th Annual Meeting of the
Asociación de Lingüística Computacional:
Artículos largos – Volumen 1, ACL ’12,
pages 1015–1024, Stroudsburg, Pensilvania.
Xu, Wei, Chris Callison Burch, and Courtney
Napoles. 2015. Problems in current text
simplification research: New data can help.
Transactions of the Association for
Ligüística computacional, 3:283–297.
Xu, Wei, Courtney Napoles, Ellie Pavlick,
Quanze Chen, and Chris Callison-Burch.
2016. Optimizing statistical machine
translation for text simplification.
Transactions of the Association for
Ligüística computacional, 4:401–415.
Yamada, Kenji and Kevin Knight. 2001. A
syntax-based statistical translation model.
In Proceedings of the 39th Annual Meeting of
la Asociación de Lingüística Computacional,
ACL ’01, pages 523–530, Stroudsburg, Pensilvania.
Yasseri, Taha, Andr´as Kornai, and J´anos
Kertsz. 2012. A practical approach to
language complexity: A Wikipedia case
estudiar. MÁS UNO, 7(11):1–8.
Yatskar, Marca, Bo Pang, Cristian Danescu-
Niculescu-Mizil, and Lillian Lee. 2010.
For the sake of simplicity: Unsupervised
extraction of lexical simplifications from
Wikipedia. In Human Language Technologies:
El 2010 Annual Conference of the North
American Chapter of the Association for
Ligüística computacional, pages 365–368,
Los Angeles, California.
zhang, Xingxing and Mirella Lapata. 2017.
Sentence simplification with deep reinforce-
ment learning. En Actas de la 2017
Jornada sobre Métodos Empíricos en Natural
Procesamiento del lenguaje, pages 595–605,
Copenhague.
zhao, Sanqiang, Rui Meng, Daqing He,
Andi Saptono, and Bambang Parmanto.
2018. Integrating transformer and
paraphrase rules for sentence simplification.
En Actas de la 2018 Conferencia
sobre métodos empíricos en lenguaje natural
Procesando, pages 3164–3173, Bruselas.
Zhu, Zhemin, Delphine Bernhard, and Iryna
Gurévich. 2010. A monolingual tree-
based translation model for sentence
simplification. In Proceedings of the 23rd
International Conference on Computational
Lingüística, COLING ’10, pages 1353–1361,
Stroudsburg, Pensilvania.
Zoph, Barret and Kevin Knight. 2016.
Multi-source neural translation. En
Actas de la 2016 Conference of the
North American Chapter of the Association
para Lingüística Computacional: Humano
Language Technologies, pages 30–34,
San Diego, California.
187
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
6
1
1
3
5
1
8
4
7
7
6
0
/
C
oh
yo
i
_
a
_
0
0
3
7
0
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3