Encounters with Language
Charles J. Fillmore∗
Universidad de California, berkeley, y
International Computer Science Institute
First of all, I am overwhelmed and humbled by the honor the ACL Executive Committee
has shown me, an honor that should be shared by the colleagues and students I’ve been
lucky enough to have around me this past decade-and-a-half while I’ve been engaged
in the FrameNet Project at the International Computer Science Institute in Berkeley.
I’ve been asked to say something about the evolution of the ideas behind the work
with which I’ve been associated, so my remarks will be a bit more autobiographical than
I might like. I’d like to comment on my changing views of what language is like, y
how the facts of language can be represented. As I am sure the ACL Executive Com-
mittee knows, I have never been a direct participant in efforts in language engineering,
but I have been a witness to, a neighbor of, and an indirect participant in some parts of
él, and I have been pleased to learn that some of the resources my colleagues and I are
building have been found by some researchers to be useful.
I offer a record of my encounters with language and my changing views of what
one ought to believe about language and how one might represent its properties. En
the course of the narrative I will take note of changes I have observed over the past
seven decades or so in both technical and conceptual tools in linguistics and language
engineering. One theme in this essay is how these tools, and the representations they
apoyo, obscure or reveal the properties of language and therefore affect what one
might believe about language. The time frame my life occupies has presented many
opportunities to ponder this complex relationship.
1. Earliest Encounters
This story begins in the 1930s and 1940’s, in St. Pablo, Minnesota. There was nothing
linguistically exotic about growing up there, except perhaps the Norwegian-accented
English of some of my mother’s older relatives. But during much of my childhood I
was convinced that I personally had difficulties with language: The symptom was that I
could never think of anything to say. I was tongue-tied. I now suspect that it was mainly
a problem of the shyness and awkwardness that goes along with growing up confused,
and not an actual matter of language pathology. Sin embargo, it led me into my earliest
attempt to work with language data.
At around age 14, I presented my problem to a librarian in the St. Paul Public library,
and she found me a book called 5000 Useful Phrases for Writers and Speakers. A memorable
∗ International Computer Science Institute, 1947 Center St. Ste. 600, berkeley, California 94611, EE.UU. Correo electrónico:
fillmore@icsi.berkeley.edu. I am especially indebted to the three directors of the International Computer
Science Institute during the life of the FrameNet Project (Jerome Feldman, Nelson Morgan, and Roberto
Pieraccini) and to Collin Baker, FrameNet Project Manager, for keeping the project alive during the recent
years of my relative inactivity; to Mary Catherine O’Connor and Russell Lee Goldman for important
assistance in the preparation of the present document; and to Lily Wong Fillmore, videographer, editor,
and censor for the broadcast version of the acceptance speech.
© 2012 Asociación de Lingüística Computacional
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
example was “With a haggard lift of the upper lip . . . ” I took the book home, cut sheets
of typewriter paper into eight pieces to make file slips, chose phrases I thought I should
memorize, and copied them onto these slips. I held them together with rubber bands,
and I kept them in a secret place in my room. Thus supported with the early 1940s
technologies of paper, scissors, pencil, and rubber bands, my earliest theory of language
began to develop: Linguistic competence is having access to a large repertory of ready-made
things to say.
I added to the collection over the years, as I came upon clever or wise expressions,
and consulted a selection of them every night, scheming to create situations in which I
could use them, in speaking or writing. In later years I held on to the suspicion that
much of ordinary conversation in real life involves calling on remembered phrases
rather than creating novel expressions from rules. Much later I learned that in many
Eastern European countries influenced by the Moscow School, the divisions of the field
of Linguistics were Phonology, Morphology, Lexicology, Phraseology, and Syntax. El
study of phraseological units—phraseologisms—was seen as central, not peripheral, a
linguistic inquiry.
My first exposure to the actual field of Linguistics came a year later, around age
15, when a missionary lady on leave, living on my block in St. Pablo, gave me a copy of
Eugene Nida’s little book, Linguistic Interludes (Nida 1947). The text of this book takes
the form of conversations in a college campus co-op between a clever and wise linguist
and a caricatured collection of innocent and unsuspecting students and colleagues,
among them a classicist who strongly defended the logical perfection of the classical
languages Greek and Latin.
This book succeeded in conveying simply many of the things that linguists believe:
(cid:1)
(cid:1)
(cid:1)
Relevant linguistic generalizations are based on speech, not writing.
Almost all concepts of “correct grammar” are inventions, with no basis in
the history of the language.
There may be primitive communities, but there are no primitive languages.
The minor protagonists in the conversation contested each of these principles, y el
linguist hero, from his vast knowledge of the most exotic of the world’s languages,
kept showing them how wrong they were. I liked the idea of knowing things that most
gente, including college professors, had wrong opinions about. I also liked the idea of
being able to help them change their wrong opinions, so I decided to study Linguistics.
2. Formal Studies Begin
Before long I was enrolled in a fairly small linguistics program at the University of
Minnesota. I could live at home, take a streetcar to Minneapolis for classes, and take
another streetcar to Montgomery Wards in St. Pablo, where I wrapped venetian blinds to
support my studies.
In those days there were no linguistics textbooks in the modern sense; we studied
two books titled Language—one by Edward Sapir (1921) and the other by Leonard
Bloomfield (1933)—and we read grammars and treatises. I took two years of Arabic. I
supplemented my training in linguistic methods through Summer Linguistic Institutes
put on by the Linguistic Society of America, one in Michigan and one in Berkeley, dónde
I learned about Thai, Sanskrit, and Navajo with Mary Haas, Franklin Edgerton, y
Harry Hoijer.
702
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Fillmore
Ligüística computacional
2.1 First Research Experience: Concordance-Building
One of my professors at the University Minnesota was building concordances of some
of the minor Late Latin texts, and he permitted the students in his class to work with him
on these projects. For the advanced students this was a chance to get valuable hands-on
research experience; for the less advanced students it was an opportunity to get “extra
credit.”
This was in a sense my first exposure to corpus-based linguistics. For any given
documento, the professor would pass on the text to that year’s students. This “first
generation” of students copied word tokens onto separate index cards, together with
each word’s “parse” in the classical sense, and its location in the document.
Generation 2—the students in the next year’s class—alphabetized these cards and
typed up the concordances. Generación 3, in which I participated, took this same stack
of cards and reverse-alphabetized them, so they could be used for research on suffixes.
(Personal note: alphabetizing words from right to left is stressful at first, but you get
used to it.) So with the tools of pre-cut index cards, a pencil, and a typewriter, nosotros
students constructed a concordance—we physically experienced that concordance.
So you can imagine my surprise when, thirty-some years later, I came upon UNIX
commands like sort, sort -r, and grep. I don’t remember if I actually wept. Y
these were nothing compared to the marvels I experienced later still, with key-word-in-
context extraction, lemmatizers, morphological parsers, part-of-speech tagging, sorting
by right and left context, and the full toolkit of corpus processing tools that exist today.
In those days it took a lot of patience and physical effort to build a concordance.
But it also took a lot of patience and physical effort to use a concordance. A printed
concordance to the Shakespeare corpus was a vast index in which, for each word,
you could find every line it occurred in, and you learned where that line appeared in
Shakespeare’s writings. You would then go to the actual physical source text, look it
arriba, and see it in its context. Por ejemplo, si, when studying the phrasal verb take upon I
want to find the full context of This way will I take upon me to wash your liver I only need
to open up As You Like It to Act 3, Scene 2, and hunt for it there. Compare that to the
fully-searchable Shakespeare app you can use while sitting on a bus holding your iPad.
3. Encounters Beyond College
President Truman’s Displaced Persons Act of 1948–1950 brought thousands of Eastern
European immigrants to Minnesota, enabling me to find work more satisfying than
venetian-blind-wrapping. I began to teach English to Russians, Poles, Ukrainians, y
Latvians. Depending on which of the daughters of the families in my classes I was trying
to impress, I was motivated to learn something about Slavic and Baltic languages.
Soon my student deferment would run out, and I had to decide between waiting for
the draft (two years) or enlisting (three years). A persuasive recruiting officer promised
me one year at the Army Language School in Monterey, California, (now the Defense Language
Instituto) for my first year. Shortly after that, my head got shaved and I was suddenly
a buck private. No one had any record of an offer to spend a year in sunny California
learning Polish. I was not allowed to examine my file.
So I took the U.S. Army Russian Language Proficiency Test instead. The questions
were in spoken Russian, played on a record player, and the answers were multiple
choice in English. In those days the art of designing guessproof multiple choice tests
had not yet been perfected. There was kind of a student sport to see how well you could
do in choosing answers without looking at the questions (you could usually at least get
703
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
a passing score); then you’d go back and read the questions to correct the choices that
weren’t obvious.
Although I didn’t fully understand any of the questions, my score came out as “high
fluent” based in large part on acquired test-taking skills. After basic training, I was sent
to Arlington, Virginia, for a few months in radio training, after which I was assigned to
Kioto, Japón, to a small field station of the Army Security Agency. My duty: “listening
to Ivan.” The Ivans I listened to on short wave radio never had anything interesting to
decir: They were Soviet Air Force men reading numbers, which I was supposed to write
abajo. Three days of the day shift, three days evening shift, three days night shift, tres
days off. I quickly acquired an uncanny ability to detect Russian numbers against noise
and static. They were, por supuesto, coded messages.
My job was to write the numbers down on the most modern typewriter of the day,
a model that had separate keys for zero and one! (The ordinary office typewriter at that
time had separate keys for only the numbers 2 a través de 9, since lower-case L could be
used for 1 and upper-case O could be used for zero.) For this work I needed a very
restricted vocabulary: the Russian long and short versions of the numbers 1–9,1 plus a
single version of zero, and the word for ‘mistake.’ If I had been permitted to say what
I was doing I would have said I was in cryptanalysis, but of course actually I was only
copying down the numbers I heard. Somebody smart, thousands of miles away, era
figuring out what they meant.
The limited demands on my time and intellect allowed me to wander around in
Kioto, with notebooks and dictionaries, trying to learn something about Japanese. El
linguistic methods I had learned back home stopped at morphology, the structure of
palabras. I hadn’t had any training in ways of representing the structure of a sentence,
but I worked out a do-it-yourself style of sentence diagrams, for both Japanese and
Inglés, and I was fascinated when I found the occasional sentence in Japanese which
could be translated into English word by word backwards, going from the end to the
beginning.
When it was time to be discharged, I believed—wrongly—that I was close to mas-
tering the language, and I wanted to stay another year or two, because I knew I couldn’t
afford to come back to Japan on my own. I managed, with the help of Senator Hubert
Humphrey, to be the first Army soldier to get a local discharge in Japan. As a civilian
allá, I supported myself by teaching English. With two other visiting Americans I was
permitted to work at Kyoto University with the endlessly kind and patient Professor
Endo Yoshimoto (
).
Professor Endo was the author of the main school grammar of Japanese and one
of the founders of an organization favoring Romanized spelling for Japanese. With his
ayuda, my fellow students and I stumbled through old texts and became acquainted with
the categories and terminology of the Japanese grammatical tradition.
One of the themes weaving through this essay is the reality that it is not possible to
represent—in a writing system, in a parse, or in a grammar—every aspect of a language
worth noticing. My study of Japanese confronted me with the realization that for any
given representation system, it’s important to understand what it represents, y qué
is missing. The Japanese kana syllabary presented me with an early experience of this.
The pronunciation of Japanese words is represented by the symbols of a syllabary, pero
unfortunately the components of complex words in this language, in particular the
inflected verbs, are not segmented at syllable boundaries.
1 The long form numbers were presumably more distinct in a noisy background.
704
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Fillmore
Ligüística computacional
Some verbs have consonant-final stems followed by vowel-initial suffixes, pero esto
fact is not apparent in the written language. In the examples in Table 1, the verb stem
means ‘move’ and it ends in a consonant, /k/. The suffixes all begin with vowels, pero
the red kana characters do not reveal the boundary between verb and suffix.
It struck me that the written form of a language should not prevent one from
discovering its boundaries. I later learned that in 1946 the American linguist Bernard
Bloch had published a ground-breaking description of Japanese verb morphology based
on a phonemic transcription (collected and republished as Bloch [1970]) , allowing the
regularities in the system to become apparent.
Everyone knows that English spelling is a poor representation for English pronun-
ciation, but it’s also true that it is a fairly good representation for recognizing derivation-
ally related words. Consider the second syllable in the three words compete, competitive,
competition. If we had to write these words with different letters for the different vowels,
we’d be missing something.
Yet of course some important generalizations about English can’t be captured in
the analysis of written English alone. Numerous phonological generalizations require a
reduction to phonetic features of various kinds, but there are also grammatical general-
izations that are hiding from us because of things like (1) cuyo (not who’s), (2) otro
(not an other), and the problems that text-to-speech researchers have to face related to the
pronunciation of large numbers and indications of currency, like the dollar sign. In post-
war Japan, the fact that the kana writing system obscured morphological boundaries
merely meant that linguists would use phonemic transcriptions. But as technology
has advanced beyond cards and typewriters, supporting efforts such as text-to-speech
and automatic speech recognition, we can see that written language obscurations (y
affordances) are ubiquitous.
4. Graduate Studies: Phonetics and Phonology
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
While living in Japan I had been keeping track of linguistics goings-on back home, y
had heard that one of the best graduate programs for linguistics was at the University of
Michigan in Ann Arbor. So when I finally came back to the States, that’s where I went.
There was a movement in linguistics in those days toward making linguistics more
“scientific” by designing so-called discovery procedures for linguistic analysis and I
wanted to participate in that work. The basic textbooks in beginning linguistics classes
at Michigan typically provided step-by-step procedures for going from data to units,
so this movement was well-supported there. Kenneth Pike’s Phonemics book had the
sub-title: A technique for reducing language to writing (Pike 1947).
I had noticed that there were alternative phonemic analyses for both English and
Japanese, analyses that resulted in different actual numbers of consonants and vowels.
If there’s no consistent way to do phonemic analysis, how can we compare different
languages with each other, or be confident in answering a simple question like, “how
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 1
Japanese kana and the obscuration of morpheme boundaries.
move (plain form)
ugok-u
ugok-imasu move (polite form)
ugok-anai
ugok-eru
does not move
can move
705
Ligüística computacional
Volumen 38, Número 4
many vowels does this language have?” I resolved to help design the correct discovery
procedure for phonemic analysis, founded on the distribution of phonetic primes. Para
that purpose I studied phonetics in the linguistics department and in the communica-
tion sciences program: practical phonetics for field linguistics, acoustic phonetics, y
physiological phonetics in the laboratory.
During those years I worked part-time on a Russian–English Machine Translation
(MONTE) project with Andreas Koutsoudas and met many MT researchers. I participated
in a memorable interview with Yehoshua Bar-Hillel (some of you will remember the
outcome of the nationwide tour that included this visit). I also worked with speech
researcher Gordon Peterson and mathematician Frank Harary on automatic discovery
procedures for phonemic analysis, a project that was eventually abandoned.
The speech lab was visited once by a group of engineers who proposed devising
automatic speech recognition by detecting the acoustic properties of individual phones
and mapping these to phonemes, and pairing phoneme sequences with English words.
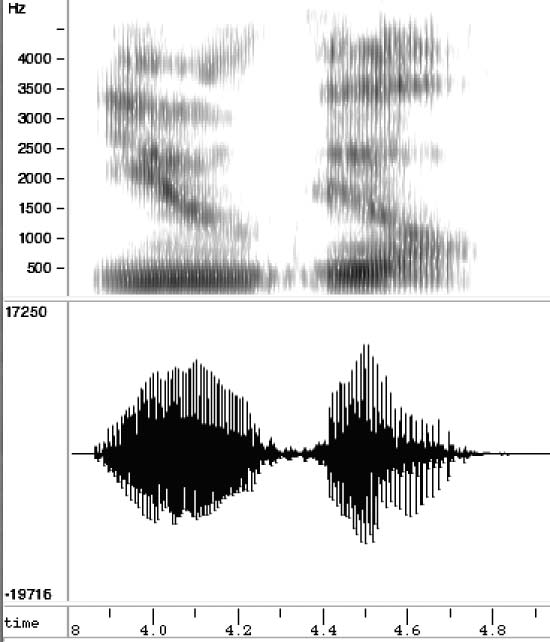
Ilse Lehiste put a damper on their enthusiasm by asking them to try to consistently
distinguish acoustic traces of the two phonemically different English words, “you” and
“ill.” They couldn’t do this (Cifra 1). The properties of the representational system
for individual phones would not allow them to get to the second step in their plan.
This was obviously before anybody thought of large-vocabulary recognizers based on
Hidden Markov Models or statistics-based guesses derived from language models.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1
Unrevealing spectrograms: you and ill, spoken by Keith Johnson.
706
Fillmore
Ligüística computacional
5. On to Syntax
Eventually it became necessary to take on syntax. At Michigan, sentences were spoken
of as having a horizontal (syntagmatic) and a vertical (paradigmatic) dimension. In its
horizontal aspect, a sentence could be seen as a sequence of positions. In its vertical
aspect, each position could be associated with a set of potential occupants of that
posición.
In the English Department at Michigan, Charles Fries was constructing a grammar
of English that was liberated from traditional notions of nouns and verbs and adjectives,
counting on purely distributional facts to discover the relevant word classes. En el
Linguistics Department, Kenneth Pike was elaborating an extremely ambitious view
of language in which, at every level of structure, one could speak of linear sequences of
positions, labeled roles naming the functions served by the occupants of these positions,
and defined sets of the potential occupants (Pike’s preliminary manuscripts appeared
in the 1950s and were eventually published as Pike [1967]). Slots, roles, and fillers—it
was all very procedural.
In the midst of all this, something big happened, and suddenly everything changed.
I was among the first in Ann Arbor to read Syntactic Structures (Chomsky 1957). I
became an instant convert, and I gave up all ideas of procedural linguistics. el nuevo
view was something like this:
(cid:1)
(cid:1)
(cid:1)
(cid:1)
(cid:1)
(cid:1)
The grammar of sentences is more than a set of linear structures separately
learned.
Sentences are generated by hierarchically organized phrase-defining rules.
Regularities in the grammar are evidence for rules in the minds of the
speakers.
The existence of a variety of sentence types is accounted for in terms of the
application of rules that move things within, add them to, or delete them
de, initial representations.
There is no procedural way to learn how language is structured; el
linguist’s job is to figure out what rules reside in the minds of speakers.
Por lo tanto, linguistics is theory construction.
The Chomskyan view flourished; universities that didn’t have linguistics programs
wanted one. After I finished my degree I joined William S.-Y. Wang in the brand new
program at The Ohio State University in Columbus. During my decade at Ohio State I
was completely committed to the new paradigm. Robert Lees, Chomsky’s first student,
visited Ohio State for a time, and I spent lots of time talking to him, working on
questions of rule ordering and conjunction. While discussing things with him, I wrote a
paper on “embedding rules in a transformational grammar” that was the first statement
of the transformational cycle (Fillmore 1963).
The view represented in Chomsky’s Aspects of the Theory of Syntax (Chomsky
1965), with its sharp separation of deep structure and surface structure, became the
mainstream, and I worked within it faithfully, participating eagerly in efforts to com-
bine all the rules the young syntacticians had been writing into a single coherent
grammar of English, an effort heavily supported, for some reason, by the U.S. Air
Fuerza. During this period I felt I knew what to do, and I believed that I understood
707
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
everything that everybody else in the framework was doing. That feeling didn’t last
very long.
At one point I did a seminar in which a small group of students and I worked our
way through Lucien Tesni`ere’s ´El´ements de Syntaxe Structurale (Tesni`ere 1959), sin
necessarily understanding everything in it, and I became aware of a different way
of organizing and representing linguistic facts. Anyone who looks closely at syntax
knows that it becomes clear very quickly that you can never represent everything
about a sentence in a single diagram. Tesni`ere, my first exposure to what evolved
later on into dependency grammar, made me aware of the impossibility of displaying
simultaneously the functional relations connecting the words in the sentence, la izquierda-
to-right sequence of words as the sentence is spoken, and the grouping of words into
phonologically integrated phrases.
As an extreme example of the kinds of information a Tesni`ere-style dependency tree
could contain, I offer you his analysis of a complex sentence from the Latin of Cicero.
I’m certain many of you will remember this from your high school studies. Est enim in
manibus laudatio quam cum legimus quem philosophum non contemnimus? (“There is in our
hands an oration, which when we read (él), which philosopher do we not despise?") Él
has roughly the same structure as Here’s a sentence, while reading which, who wouldn’t get
confused? Cifra 2 presents the diagram, but I’ll only point out the connections assigned
to one word in it, the relative pronoun quam.
Instead of having lines pointing to a single token of the word, Tesni`ere breaks the
word quam into two pieces connected by the broken line at the bottom. The word agrees
with laudatio in gender and number and that connection is indicated by the upper
broken line; it is the marker of the relative clause headed by contemnimus, as shown in
the horizontal structure it is hanging from, and it is the direct object of legimus, abajo
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2
A Tesni`ere-style dependency tree.
708
Fillmore
Ligüística computacional
bien. This diagram shows more than simple dependency relations, and uses various
ingenious tricks and decorations to smuggle in other kinds of facts. The word-to-word
connections are shown, but it’s really clear that a system for projecting from such a
diagram to a linear string of words spread into phonologically separable phrases has to
be incredibly complex.
The fact that dependency diagrams do not show the linear organization of the con-
stituent words was presented by me as a representational problem, but in fact Tesni`ere
uses precisely this separation to propose a typology of languages according to whether
they tend to order dependents before heads or heads before dependents, and whether
within each language these tendencies vary within different kinds of constructions. En
a centripetal language the dependents precede the head, in a centrifugal language the
head precedes the dependents. There are extreme and moderated varieties of each of
these in his scheme.
Tesni`ere also described a number of conjoined structures in French for which he
used the terminology of embryological mistakes, one kind being monsters that have
one head and more than one tail. In general these correspond to Verb Gapping in our
terms (John likes apples and Mary oranges). Another kind of embryological mistake has
more than one head and a single tail, like Right Node Raising (John likes and Mary detests
anchovies), and the most monstrous of all are capital H-shaped monsters with two heads
and two tails, like the kinds of sentences Paul Kay and Mary Catherine O’Connor and
I played with in a paper (Fillmore, kay, and O’Connor 1988) on “let alone” (I wouldn’t
tocar, let alone eat, shrimp, let alone squid). I think these phenomena have more to do
with sequencing patterns than with dependency relations, but I found it interesting that
Tesni`ere delighted in exploring these kinds of structural complexities. (My sensitivity
to tone in French prose isn’t good enough to know whether in these descriptions of
syntactic monsters Tesni`ere was having fun. I’m not helped in that uncertainty by
photographs I’ve seen of the man.)
I ended up favoring phrase structure representations, partly because dependency
representations have no easy way to identify a predicate or verb phrase (vicepresidente) constituent,
and I’d like to believe that the VP can in general be treated as naming a familiar
categoría (eating meat, parking a car, being breakable, etc.). But I mainly preferred
phrase-structural representations because they offer more material upon which to as-
sign intonational contours.
6. What About Meaning?
When linguists turned to the predicate calculus as a representation for sentence mean-
En g, many were interested mainly in quantification and negation, where it’s possible to
show how complex logical structures can be formulated in ways that pay no attention
to the actual meanings of the words that name either the predicates or the arguments. I,
sin embargo, was specifically interested in the inner structure of the predicates themselves.
So I encountered a representational problem when working with the notation that was
common at the time.
When working on meaning, linguists often used prefix notation, allowing the
ordered list of symbols following the name of the predicate to stand for the “-arity”—
the number of arguments—of the particular predicate. Thus P(a) could represent an
adjective like hungry or a verb like vanish; PAG(a,b), relating two things to each other,
could stand for an adjective like different or a verb like love; y P(a,b,C) con tres
arguments could stand for an adjective like intermediate or a verb like give, espectáculo, o
709
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
tell. This notation also allowed one to represent cases in which the arguments could
themselves be predications, permitting recursion.
While working with the prefix notation I was struck by the fact that although
this representation afforded one the chance to make claims across diverse classes of
predicates, it simultaneously obscured certain information about the arguments of those
predicates—important semantic commonalities about classes of arguments.
There are centuries-old traditions by which schoolteachers explain that the subject
names the agent in an event and the object tells us what is affected by the agent’s actions,
but it’s trivially easy to find examples that show that such generalizations don’t hold.
Similarmente, in a predicate–argument formula, there is nothing meaningful about being the
first or second or third item in a list. Does it make sense to let the position in an ordered
list represent the semantic role of an argument in a predication? Consider the following
examples in which arguments are interchanged:
(1) He blamed the accident on me. ←→ He blamed me for the accident.
(2) He strikes me as a fool. ←→ I regard him as a fool.
(3) Chuck bought a car from Jerry. ←→ Jerry sold a car to Chuck.
In Example (1) the second and third arguments of blame are interchanged in their
grammatical realization. In Example (2), with the pair strike and regard, the first and
second arguments are interchanged. And in Example (3), with buy and sell, the first and
the third are interchanged.
I felt that there ought to be some way of recognizing the sameness of the semantic
functions of these arguments independently of where they happen to be sitting in an
ordered list. An alternative was spelled out in a rambling paper called “The Case for
Case” published in 1968 (Fillmore 1968). It proposed a universal list of semantic role
types (“cases”). Configurations of these cases could then characterize the semantic
structures of verb and adjective meanings. In this way, lexical predicates could be
shown as differing according to the collection of cases that they required (obligatory)
or welcomed (optional).
The theory embedded in this view is that semantic relations (“deep cases”) son
directly linked to argument meanings. (So in the sentence John gave Mary a rose, John
is the Agent, Mary is the Recipient, and a rose is the transmitted Object.) Grammatical
roles (sujeto, object) and markings (choice of preposition, etc.) are predicted from case
configurations. (So the Agent could be the subject, the Object could be the direct object,
and the Recipient could be introduced with the preposition to.) Generalizations are
formulated in terms of specific named cases, for which a hierarchy is defined, y el
list of cases is finite and universal.
The variable “valences” (a term from Tesni`ere) of a single verb can be explained in
terms of the cases available to it. The starting examples in this discussion were with the
verb open. Its valences correlate with the cases available to it:
(4) Agent>>>Instrument>>>Object hierarchy illustrated with V open
oh
= The door opened
AO = I opened the door
IO
= The key opened the door
AIO = I opened the door with the key
710
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Fillmore
Ligüística computacional
The occupants of nuclear syntactic slots (subject and object) are determined by the
hierarchy, the rest are marked by prepositions (or in the case of arguments whose shape
is a VP or a clause, various other markers or complementizers).
There was a time when Case Grammar, so-called, was very popular, and partly
because of that I ended up in Berkeley, California, and eventually participated in the
vibrant Cognitive Science Program there. When I first arrived, I continued to work on
Case Grammar and Transformational Grammar, disappointed that the former was not
accepted as a contribution to the latter.
Gradually, the theory and representation of Case Grammar revealed a way to define
entities at a different level: Given lists of cases, it was possible to define situation types
as assemblies of these. I referred to these assemblies as case frames. With a large number
of case or semantic role names, it should be possible to define a very large number of
situation types. Por ejemplo, Agent-Instrument-Object is some kind of caused change.
Object-Path-Goal is some kind of motion event, etcétera:
(5) Case Frame Situation Types exemplified
(cid:1)
(cid:1)
(cid:1)
(cid:1)
(cid:1)
Agent, Instrument, Object: I fixed it with a screwdriver.
Object, Path, Goal: The water flowed through the crack in the floor into
the storage room.
Experiencer, Contenido: I remember the accident.
Stimulus, Experiencer: The noise scared me.
Stimulus, Experiencer, Contenido: The noise reminded me of the accident.
Various proposals emerged (by John Sowa among others) that greatly increased
the number of cases, enabling descriptions of more and more kinds of situations and
events. Researchers working with semantic roles tend to think of them as identifying
the roles of participants in the event, in the case of verbs that describe events. Pero esto
conceptualization shed light on some problematic (and eventually revealing) casos. Uno
of the first to hit me involved some uses of the verb replace. Consider this sentence: Hoy
I finally replaced that bicycle that got stolen a year ago.
Notice that the bicycle that got stolen a year ago was not a participant in the Re-
placement event that happened today, at least not in the usual sense that is intended in
work on semantic roles or cases. The bicycle can be mentioned in the sentence, given the
grammatical requirements of the verb replace, because the bicycle was a participant in
the narrative that defines a replacement event.
This led to a conceptualization that will be familiar to readers of this journal. En cambio
of defining frames in terms of assemblies of roles, what about making frames primary, y
defining roles in terms of the frames? I then started thinking that the job of lexical semantics
is to characterize frames on their own, and work out the participant structures frame
by frame.
7. Beyond Syntax and Semantics
At some point I was invited to give some lectures at Roger Schank’s Artificial Intel-
ligence lab at Yale, where I witnessed work on information retrieval in the form of
a system that automatically collected information from newspaper accounts of traffic
accidents. My impression was that the system was given texts that were known to be
711
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
about traffic accidents, and it was already provided with a checklist of information
to look for, based ultimately on the style sheets used by reporters working on traffic
accident assignments, o, really, al final, on the reporting traditions of the local police
departments.
The checklist included names, siglos, and addresses of drivers, passengers, y
victims; the make, modelo, and year of the involved vehicles; location of the accident;
directions of moving vehicles; presence of injuries or fatalities; reports from police
autoridades, Etcétera. The system needed to recognize capital letters, punctuation,
numbers, and a set of words like driver, passenger, victim, ambulance, street, avenue,
highway, sheriff, officer, vehicle, etcétera, so that when it came upon something like
the following it would know what to do:
Walter O. Magnusson, 23, de 79 W.. Walnut St., Hartland, was westbound on 28th Street
near Blossom Road in a 1998 Chevrolet pickup when he and passenger, Wilma J. Alter,
27, same address, argumentó. According to Sheriff Deputy Carl Voegelin, Magnusson
grabbed the steering wheel, causing the vehicle to strike a tree on the south side of the
camino. Magnusson was taken by private vehicle to Hartland Community Hospital with
possible injuries. The pickup was registered to Clarence Barker of 66 Larkin Rd.,
Jarviston.
I wondered if a kind of general purpose information extraction process could be
designed in which the system didn’t know in advance what the text was about, pero en
which particular words in the text would evoke their own checklist—a list of things to look
for that come with the entry for the word. The presence in a text of a word like revenge, para
ejemplo, could initiate a search for the identity of the offender, the name of the injured
party and the avenger, the punishment inflicted or intended, Etcétera, a checklist
that would also be evoked by a dozen other words in the same frame. In a case like
the given text, the heading of a newspaper article such as “Fatal Accident on Highway
17” would get things started. Eso es, a word could evoke a frame, and the semantic
parser’s job would be to find the elements of that frame in the text, sometimes in the
same sentence, in positions determined by the grammar of the word, and sometimes in
neighboring sentences.
The idea behind frame semantics is that speakers are aware of possibly quite com-
plex situation types, packages of connected expectations, that go by various names—
marcos, schemas, escenarios, scripts, cultural narratives, memes—and the words in our
language are understood with such frames as their presupposed background. Por supuesto
these terms are used to designate concepts developed with slightly different meanings,
and for different purposes, en Inteligencia Artificial, Psicología cognitiva, and Sociol-
ogia. I use the word “frame” promiscuously to cover all of them. In “frame semantics,"
sin embargo, I’m particularly concerned with those that are clearly linked to items of
linguistic form: words or constructions.
8. RISK: The Frame
En 1988, at a summer school in Pisa run by the late Antonio Zampolli, I met Sue Atkins,
the lexicographer. I was teaching a course on frame semantics, and she was teaching a
course on corpus-based lexicography that included an examination of concordance lines
for the verb risk. Sue and I decided to join forces and come up with a complete frame
description of risk, based on corpus evidence, that would show how the words that
belong to this frame work. The title of the first paper that resulted from this research was
“Toward a frame-based lexicon: The semantics of RISK and its neighbors.” We presented
712
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Fillmore
Ligüística computacional
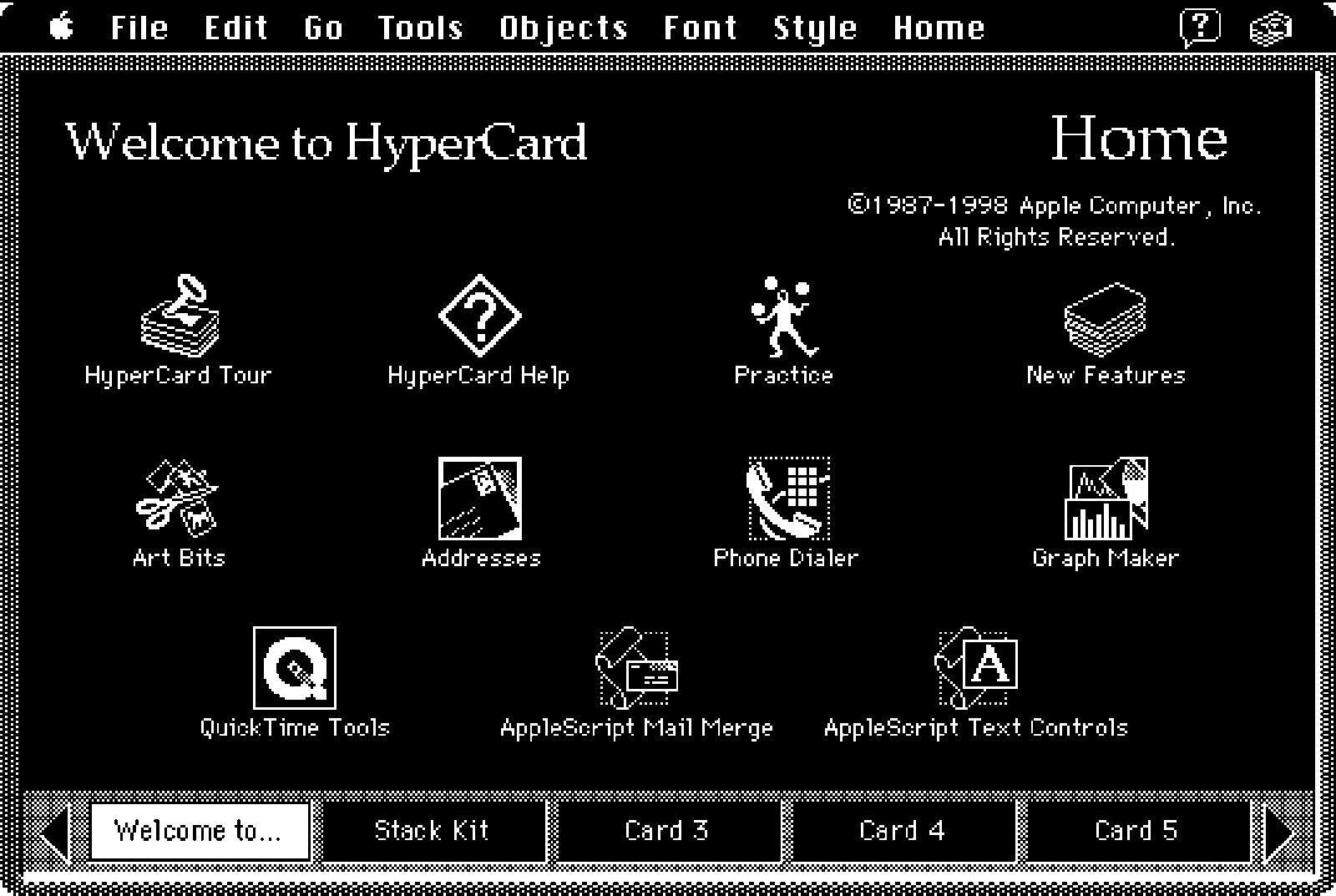
Cifra 3
HyperCard: Representational breakthrough.
the main arguments, jointly, en el 1991 meeting of the ACL in Berkeley. The paper was
published as Fillmore and Atkins (1992).
9. The Gradual Birth of FrameNet
Along with some colleagues, I decided to seek funding to build a resource that would
feature a large number of frames, along with the words that belong to those frames.
In any such funding request, the authors are challenged to represent the project in
compelling detail so as to allow reviewers to envision the possibilities. Our first attempt,
created by John B. Lowe, made use of a demo created using the new tool HyperCard
(Cifra 3). Sadly, the funders were not impressed.
Por supuesto, all of this work was carried out against the backdrop of George Miller’s
ground-breaking project, WordNet2 (Molinero 1995; Fellbaum 1998). Por 1992 the creators of
WordNet had demonstrated the power and utility of a searchable and open database of
English words, organized around core semantic relations such as synonymy, meronymy
and holonymy, hypernymy and hyponymy, etcétera. Although WordNet was an
inspiration to us, its purposes and structure are somewhat different from those of
FrameNet.
The goal of the FrameNet project3 (Fillmore, Johnson, and Petruck 2003) was to
create a database, to be used by humans and computers, that would include a list of all
2 http://wordnet.princeton.edu.
3 http://framenet.icsi.berkeley.edu.
713
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
COMPLIANCE
Definición: This frame concerns Acts and States of Affairs for which Protagonists
are responsible and which either follow or violate some set of rules or Norms .
Cifra 4
Definition of the Compliance frame.
of the Frames that we could possibly have time to describe. Frames are the cognitive
schemata that underlie the meanings of the words associated with that Frame. El
example of the frame Compliance is given in Figure 4. It begins with a definition of
the frame in terms of Frame Elements (FEs), which are the things worth talking about
when a given frame is relevant. (There are generally three to eight FEs per frame.)
We currently have about 1,200 Frames defined and described. A fragment of the
list of Frames alphabetically surrounding Compliance runs as follows: Compatibility,
Competition, Complaining, Completeness, Compliance, Concessive….
Próximo, we attempt to catalogue the Lexical Units (LUs) associated with the frame.
These are words which, when encountered in a written or spoken text, may “evoke”
the frame. Actualmente, our total number of Lexical Units across all 1,200 Frames is about
13,000. Ejemplo (6) lists a sample of the LUs tied to the Compliance frame.
(6) (in/out) line.n, abide.v, adhere.v, adherence.n, breach.n, breach.v, break.v,
by-pass.v, circumvent.v, compliance.n, compliant.a, comply.v, conform.v,
conformity.n, contrary.a, contravene.v, contravention.n, disobey.v, flout.v,
follow.v, honor.v, in accordance.a, keep.v, lawless.a, noncompliance.n,
obedient.a, obey.v, observance.n, observant.a, observe.v, play by the
rules.v, submit.v, transgress.v, transgression.n, violate.v, violation.n
Not all LUs are simple words. Many are phrasal words, such as take off, talk down,
work out, pick up. Some are idiomatic phrases: por supuesto, all of a sudden. Finalmente, some are
products of constructions: best friends, make one’s way.
Beyond the specification of cognitive and cultural frames, and their linguistic
triggers or anchors, FrameNet analyses endeavor to catalogue the ways that Frame
Elements of a Frame are linguistically expressed, specifically in terms of syntactic
estructuras. Por ejemplo, in the Compliance frame, what are the possible forms in which
the FEs can be expressed?
To begin to answer this question, we compile for each Frame a set of Annotations.
Each includes sentences that exemplify the Frame and its FEs, and demonstrate the
use of the relevant Lexical Units. Examples (7)–(9) illustrate how the subject of a sen-
tence can instantiate three of the FEs in the Compliance frame, given the lexical items
usado.
(7) The wiring in this room is in violation of the building code.
State of Affairs
(8) You have broken the rules.
Protagonist
(9) My action was in compliance with the school’s traditions.
Acto
714
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Fillmore
Ligüística computacional
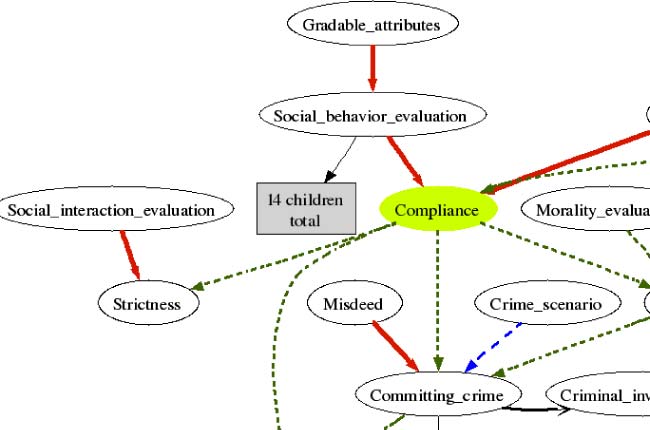
Cifra 5
Compliance frame in a network of frames.
Finalmente, lexical entries summarize the mappings of individual FEs, Lexical Unit by
Lexical Unit. Por ejemplo, for the FE Norm within the Compliance frame, we find the
following LUs, where “X” is the variable whose value will be the Norm for each LU:
(10) Lexical Units linked to the Frame Element Norm within Compliance
complies [with X]
is in breach [of X]
violates [X]
conforms [to X]
abides [by X]
adheres [to X]
Note that these Lexical Units (all of which would be linked to the Frame Element
NORM in the Compliance frame) include antonyms, and thus these sets of LUs differ
from synsets. Polysemous LUs can be linked to different frames. Por ejemplo, adhere
belongs not only to the Compliance frame but also to the Attaching frame.
The frames themselves are organized in a network, linked by various kinds of
relaciones, including inheritance, part-of, presupposes,4 etcétera. Cifra 5 is a glimpse
of the place held by the Compliance frame in the network.
Compliance inherits from both the Social-Behavior-Evaluation frame and the
Satisfying frame. The Satisfying frame includes satisfying desires, fulfilling ambi-
ciones, meeting one’s goals, Etcétera. Compliance elaborates on that by specifying
that the Norm FE is some kind of institutionalized rule or law or principle or practice,
and that the words in this frame evaluate people and their acts with reference to such
normas.
Frame-to-Frame relations also include FE-to-FE relations: Por ejemplo, the Buyer
FE of Commerce-buy is the Agent FE of Transfer. Linking generalizations familiar
4 Estrictamente hablando, the notion of frame presupposition is captured by several relations, including “Using”
and “Perspective on.”
715
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
from “standard” thematic roles can be captured by relating smaller frames to the more
schematic ones they inherit.
The FrameNet annotation sets include not only the “lexicographic” annotations,
but also a number of “full-text” annotations, where all words are annotated, eso es,
annotation layers are provided for each frame-relevant word. In such examples, nosotros
frequently encounter data that force us to expand and refine FrameNet.
In most examples we can see core FEs, those that are required by the frame, como
well as peripheral FEs, those that fill out the roles traditionally described as adjuncts
of time, lugar, manner, etcétera. But as we expand our catch to include sentences
beyond those that simply provide good examples of the Frames, we encounter FEs
that we label as extrathematic. This name is given to expressions that are syntacti-
cally governed by a frame-bearing element, but convey information that is outside
of the Frame. As Example (11) indicates, extrathematic elements frequently introduce
a new Frame, and thus are crucial for the enterprise of automatic understanding of
connected text.
(11) Types of FEs in a sentence.
The army
(CORE)
destroyed
[objetivo]
the village
(CORE)
yesterday
(PERIPHERAL)
in retaliation
(EXTRATHEMATIC)
In our annotation work it has become necessary to notice contexts in which the
semantic head of a phrase and the syntactic head of a phrase are not identical. Porque
we are interested in positioning frame-relevant words in their contexts, we have recog-
nized support verbs, support prepositions, and transparent nouns. What we find with
support verbs and prepositions is that the governed noun is the LU that evokes the
marco. In expressions like take a turn, make a decision, wreak havoc, lodge a complaint, say a
prayer, and give advice, the frame is evoked by the noun. The same can be observed with
in trouble, at risk, under arrest, under consideration, and at rest. The verb or preposition
determines the grammatical functioning, pero también (in the case of the verb) features of
aspect, tono, y voz.
Transparent nouns are nouns that intervene, en un [N1 of N2] estructura, between the
frame context and the frame-relevant noun. Eso es, in examples like wreak this KIND of
havoc, drink a DROP of vodka, divorce that JERK of a husband, it is the second (underlined)
noun that matters in our understanding of the semantic nature of the Frame Element.
These grammatical types may also be helpful in the enterprise of automatic understand-
ing of connected text.
We have noticed regularities that may be useful to expand upon for FEs: Ellos
can have “semantic types” associated with them, intended to say something about the
types of entities, and thus phrases, that can serve in those roles. Por ejemplo, Agents,
Experiences, and Recipients are of the semantic type “sentient.” This dimension is not
well-developed, currently, consisting mostly of categories such as artifact, container,
factive (for verbs), etcétera.
The FrameNet wordlist is mostly from the “general vocabulary” and for the most
part ignores the tens of thousands of words that either lack frames of their own or
that have specialist frames for which ordinary lexicographic inquiry cannot help. Estos
include artifact names, natural kinds, terrain features, etcétera. For these we would
like to make progress with what we call “Gov-X annotation”: annotating words with
respect to the frames they belong comfortably in. Por ejemplo, gun would be annotated
in sentences where it is governed by brandish, fire, shoot, load, Etcétera.
716
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Fillmore
Ligüística computacional
10. Constructions
In recent years we have added to the FrameNet database something we call the Con-
structicon, which is a list of grammatical constructions, descriptions of their compo-
nents, and descriptions of the properties and functions of the phrases or constituents
that they license (Fillmore, Lee-Goldman, and Rhodes 2012).
Some members of the team are participants in a movement called Construction
Grammar, supporting a view of grammar as a collection of constructions, donde cada
construction constitutes a way of assembling the meaning of the components into a
semantic whole, not obviously predictable, by familiar principles, from the meanings of
the parts.
This collection includes special constructions like the ones that license the bigger
they come the harder they fall, or rate expressions like twenty gallons an hour, or unusual
symmetric-relation expressions like I am friends with the President. The collection is
not limited to special-purpose or idiosyncratic constructions, but also includes major
constructions with broad semantic import and cross-linguistic relevance, como
conditional sentences, exclamations, a large variety of coordinating constructions, y
comparative constructions.
The constructions bring frames of their own, and the analysis task is to integrate
the information from the LUs embedded within their Frames with those contributed by
the constructions. The Construction is linked to a set of sentences annotated according
to the properties of the construction being analyzed. Professor Hiroaki Sato of Senshu
University in Japan has designed a temporary tool for viewing the constructional
información.
11. Conclusión
The ultimate goal is to be able to understand everything that can be known about a
palabra, or a sentence, or a language, or speakers’ knowledge of their language. This goal
can never be achieved, but one keeps trying, piece by piece. I recently came upon, in my
notas, a program from the 1988 Pisa Institute that showed I was on a panel one evening
addressing the question “What would a linguist like to find in the Dictionary of 2001?"
I don’t remember what I said, but I think that if everything could work the way we
planned it, and if the project ever gets the funds to complete the job, the ICSI FrameNet
database of 2020 will stand a chance of being close to that ideal dictionary of 2001. Quiero
to thank the ACL Executive Committee again for the recognition, and the conference
participants for listening.
Referencias
Bloch, Bernard. 1970. Bernard Bloch
on Japanese. Prensa de la Universidad de Yale,
nuevo refugio, CT.
Bloomfield, leonardo. 1933. Idioma.
Henry Holt, Nueva York.
Chomsky, Noam. 1957. Syntactic Structures.
Moutón, The Hague.
Chomsky, Noam. 1965. Aspects of the Theory of
Syntax. La prensa del MIT, Cambridge, MAMÁ.
Fellbaum, Christiane. 1998. WordNet:
An Electronic Lexical Database.
La prensa del MIT, Cambridge, MAMÁ.
Fillmore, Charles J. 1963. The position of
embedding transformations in a grammar.
Word, 18:208–231.
Fillmore, Charles J. 1968. The case for case. En
Emmond Werner Bach and Robert Thomas
Harms, editores, Universals in Linguistic
Teoría, Chapter 1. Holt, Rinehart, y
Winston, Nueva York, pages 1–88.
Fillmore, Charles J. and Beryl T. S. Atkins.
1992. Towards a frame-based organization
of the lexicon: The semantics of RISK and
its neighbors. In A. Lehrer and E. Kitay,
editores, Frames, Campos, and Contrast: Nuevo
717
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Ligüística computacional
Volumen 38, Número 4
Essays in Semantics and Lexical Organization.
Lawrence Erlbaum Associates, Hillsdale,
Nueva Jersey, pages 75–102.
Fillmore, Charles J., Christopher R.
Johnson, and Miriam R. l. Petruck.
2003. Background to Framenet.
International Journal of Lexicography,
16(3):297–333.
Fillmore, Charles J., Paul Kay, y
Mary Catherine O’Connor. 1988.
Regularity and idiomaticity in
grammatical constructions:
The case of ‘let alone’. Idioma,
64:501–538.
Fillmore, Charles J., Russell Lee-Goldman,
and Russell Rhodes. 2012. The FrameNet
constructicon. In Ivan A. Sag and Hans
C. Boas, editores, Sign-based Construction
Grammar. CSLI, stanford, California.
Molinero, George A. 1995. WordNet: A lexical
database for English. Comunicaciones
of the ACM, 38(11):39–41.
Nida, Eugene. 1947. Linguistic Interludes.
Summer Institute of Linguistics,
Glendale, California.
Pike, Kenneth L. 1947. Phonemics: A
Technique for Recuding Languages to Writing.
University of Michigan Publications
Lingüística 3, ann-arbor, MI.
Pike, Kenneth L. 1967. Language in Relation to
a Unified Theory of the Structure of Human
Comportamiento. Janua Linguarum, series maior,
24. Moutón, The Hague.
Sapir, Eduardo. 1921. Idioma: Un
Introduction to the Study of Speech.
Harcourt, Brace and Company, Nueva York.
Tesni`ere, l. 1959. ´El´ements de Syntaxe
Structurale. Klincksieck, París.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
yo
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
7
0
1
1
7
9
9
9
2
8
/
C
oh
yo
i
_
a
_
0
0
1
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
718